 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unique Geometry and Texture from Corresponding Image Patches
Mar 19, 2020

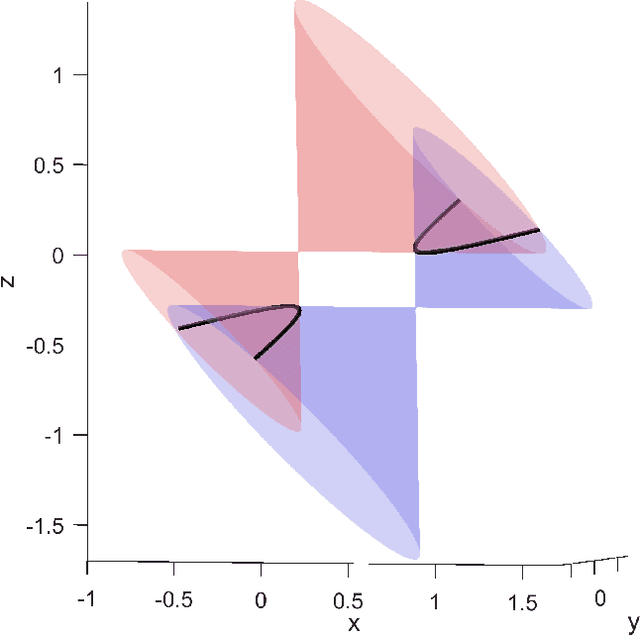
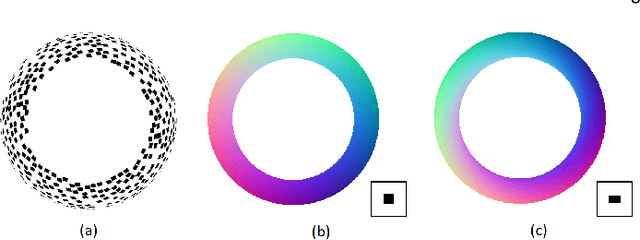
We present a sufficient condition for the recovery of a unique texture process and a unique set of viewpoints from a set of image patches that are generated by observing a flat texture process from unknown directions and orientations. We show that four image patches are sufficient in general, and we characterize the ambiguities that arise when this condition is not satisfied. The results are applicable to the perception of shape from texture and to texture-based structure from motion.
Image Fine-grained Inpainting
Feb 07, 2020


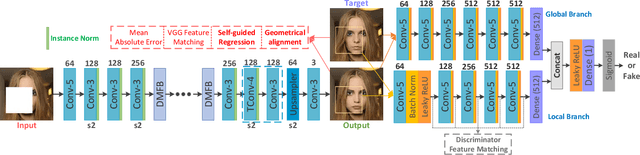
Image inpainting techniques have shown promising improvement with the assistance of generative adversarial networks (GANs) recently. However, most of them often suffered from completed results with unreasonable structure or blurriness. To mitigate this problem, in this paper, we present a one-stage model that utilizes dense combinations of dilated convolutions to obtain larger and more effective receptive fields. Benefited from the property of this network, we can more easily recover large regions in an incomplete image. To better train this efficient generator, except for frequently-used VGG feature matching loss, we design a novel self-guided regression loss for concentrating on uncertain areas and enhancing the semantic details. Besides, we devise a geometrical alignment constraint item to compensate for the pixel-based distance between prediction features and ground-truth ones. We also employ a discriminator with local and global branches to ensure local-global contents consistency. To further improve the quality of generated images, discriminator feature matching on the local branch is introduced, which dynamically minimizes the similarity of intermediate features between synthetic and ground-truth patches. Extensive experiments on several public datasets demonstrate that our approach outperforms current state-of-the-art methods. Code is available at~\url{https://github.com/Zheng222/DMFN}.
Wrong Colored Vermeer: Color-Symmetric Image Distortion
Jun 29, 2021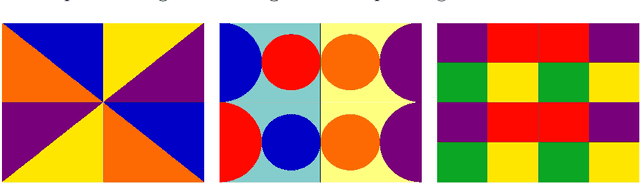


Color symmetry implies that the colors of geometrical objects are assigned according to their symmetry properties. It is defined by associating the elements of the symmetry group with a color permutation. I use this concept for generative art and apply symmetry-consistent color distortions to images of paintings by Johannes Vermeer. The color permutations are realized as mappings of the HSV color space onto itself.
Learning Semantically Enhanced Feature for Fine-Grained Image Classification
Jul 05, 2020
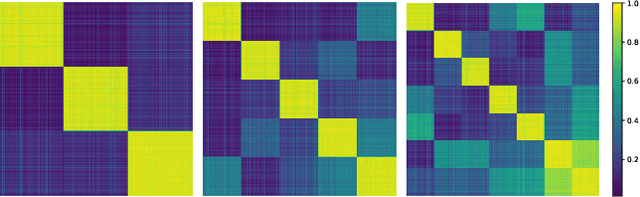
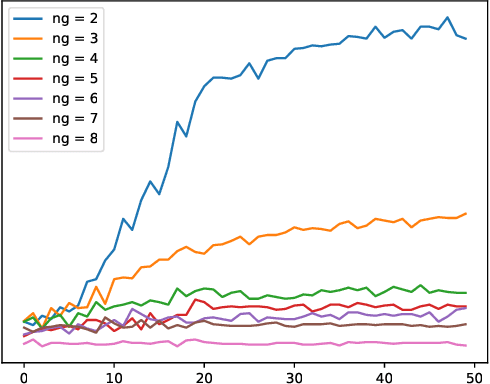

We aim to provide a computationally cheap yet effective approach for fine-grained image classification (FGIC) in this letter. Unlike previous methods that rely on complex part localization modules, our approach learns fine-grained features by improving the semantics of sub-features of a global feature. Specifically, we first achieve the sub-feature semantic by arranging feature channels of a CNN into different groups through channel permutation. Meanwhile, to enhance the discriminability of sub-features, the groups are guided to be activated on object parts with strong discriminability by a weighted combination regularization. This process brings only 1.7% additional parameters to its ResNet-50 backbone. Moreover, our approach can be easily integrated into the backbone model as a plug-and-play module for end-to-end training with only image-level supervision. Experiments verified the effectiveness of our approach and validated its comparable performance to the state-of-the-art methods. Code is available at https://github.com/cswluo/SEF
No-Reference Image Quality Assessment via Feature Fusion and Multi-Task Learning
Jun 06, 2020
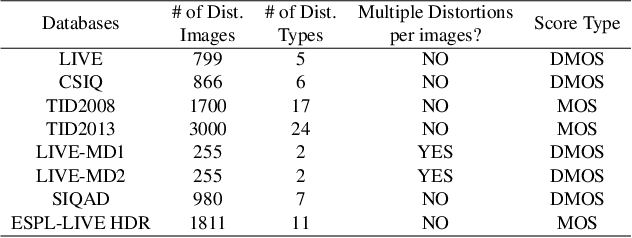
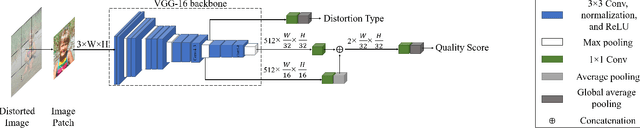
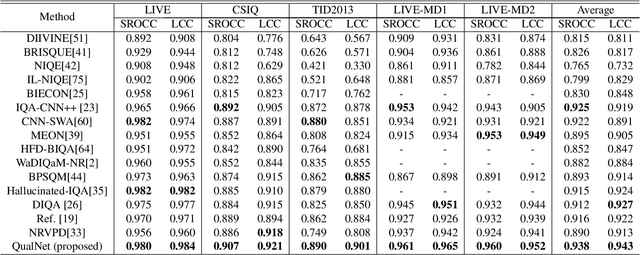
Blind or no-reference image quality assessment (NR-IQA) is a fundamental, unsolved, and yet challenging problem due to the unavailability of a reference image. It is vital to the streaming and social media industries that impact billions of viewers daily. Although previous NR-IQA methods leveraged different feature extraction approaches, the performance bottleneck still exists. In this paper, we propose a simple and yet effective general-purpose no-reference (NR) image quality assessment (IQA) framework based on multi-task learning. Our model employs distortion types as well as subjective human scores to predict image quality. We propose a feature fusion method to utilize distortion information to improve the quality score estimation task. In our experiments, we demonstrate that by utilizing multi-task learning and our proposed feature fusion method, our model yields better performance for the NR-IQA task. To demonstrate the effectiveness of our approach, we test our approach on seven standard datasets and show that we achieve state-of-the-art results on various datasets.
CellCycleGAN: Spatiotemporal Microscopy Image Synthesis of Cell Populations using Statistical Shape Models and Conditional GANs
Oct 22, 2020
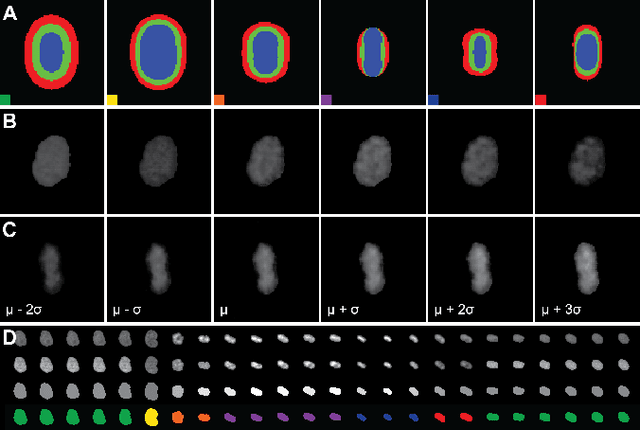
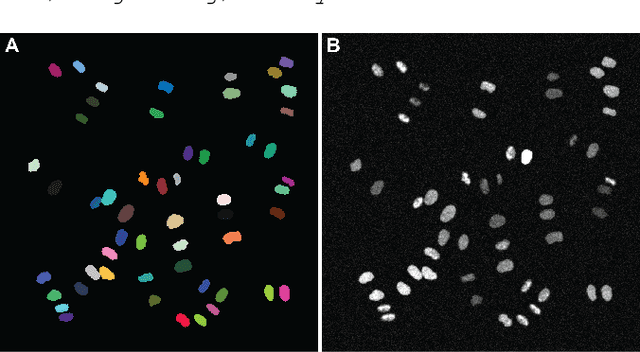
Automatic analysis of spatio-temporal microscopy images is inevitable for state-of-the-art research in the life sciences. Recent developments in deep learning provide powerful tools for automatic analyses of such image data, but heavily depend on the amount and quality of provided training data to perform well. To this end, we developed a new method for realistic generation of synthetic 2D+t microscopy image data of fluorescently labeled cellular nuclei. The method combines spatiotemporal statistical shape models of different cell cycle stages with a conditional GAN to generate time series of cell populations and provides instance-level control of cell cycle stage and the fluorescence intensity of generated cells. We show the effect of the GAN conditioning and create a set of synthetic images that can be readily used for training and benchmarking of cell segmentation and tracking approaches.
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 17, 2021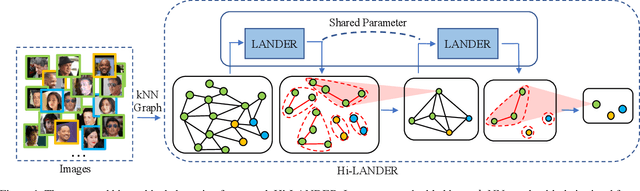
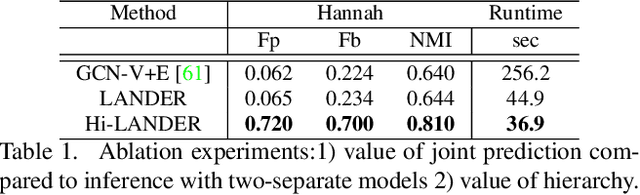
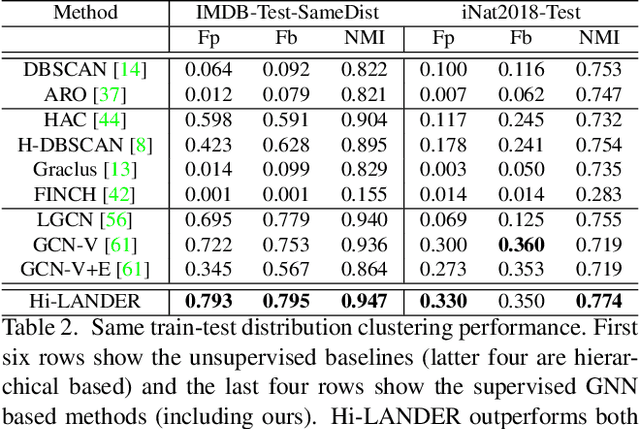
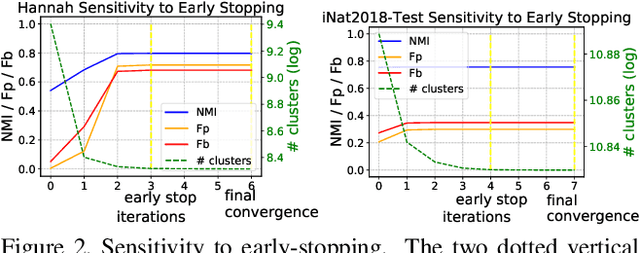
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
Neural Scene Decoration from a Single Photograph
Aug 04, 2021
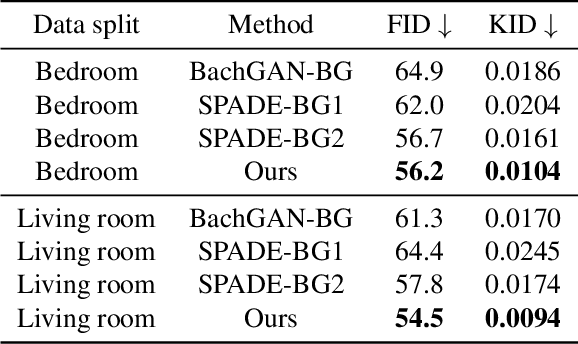
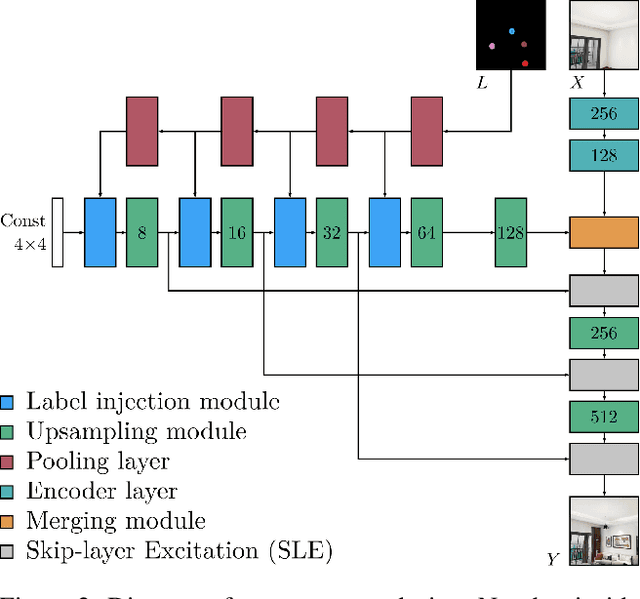
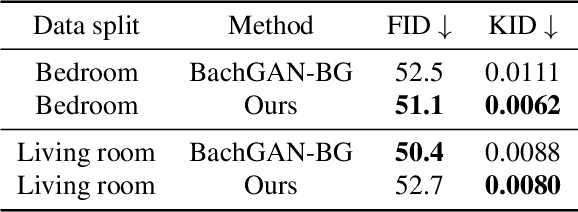
Furnishing and rendering an indoor scene is a common but tedious task for interior design: an artist needs to observe the space, create a conceptual design, build a 3D model, and perform rendering. In this paper, we introduce a new problem of domain-specific image synthesis using generative modeling, namely neural scene decoration. Given a photograph of an empty indoor space, we aim to synthesize a new image of the same space that is fully furnished and decorated. Neural scene decoration can be applied in practice to efficiently generate conceptual but realistic interior designs, bypassing the traditional multi-step and time-consuming pipeline. Our attempt to neural scene decoration in this paper is a generative adversarial neural network that takes the input photograph and directly produce the image of the desired furnishing and decorations. Our network contains a novel image generator that transforms an initial point-based object layout into a realistic photograph. We demonstrate the performance of our proposed method by showing that it outperforms the baselines built upon previous works on image translations both qualitatively and quantitatively. Our user study further validates the plausibility and aesthetics in the generated designs.
Adversarially Robust Classification by Conditional Generative Model Inversion
Jan 12, 2022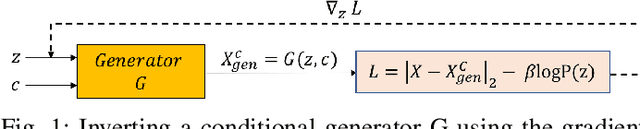

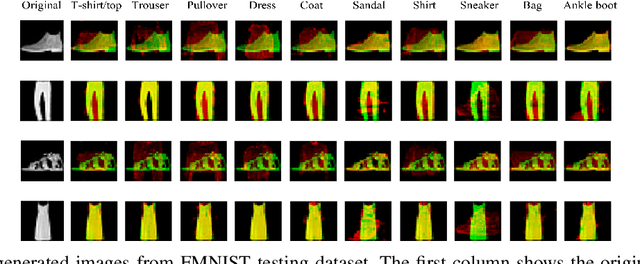

Most adversarial attack defense methods rely on obfuscating gradients. These methods are successful in defending against gradient-based attacks; however, they are easily circumvented by attacks which either do not use the gradient or by attacks which approximate and use the corrected gradient. Defenses that do not obfuscate gradients such as adversarial training exist, but these approaches generally make assumptions about the attack such as its magnitude. We propose a classification model that does not obfuscate gradients and is robust by construction without assuming prior knowledge about the attack. Our method casts classification as an optimization problem where we "invert" a conditional generator trained on unperturbed, natural images to find the class that generates the closest sample to the query image. We hypothesize that a potential source of brittleness against adversarial attacks is the high-to-low-dimensional nature of feed-forward classifiers which allows an adversary to find small perturbations in the input space that lead to large changes in the output space. On the other hand, a generative model is typically a low-to-high-dimensional mapping. While the method is related to Defense-GAN, the use of a conditional generative model and inversion in our model instead of the feed-forward classifier is a critical difference. Unlike Defense-GAN, which was shown to generate obfuscated gradients that are easily circumvented, we show that our method does not obfuscate gradients. We demonstrate that our model is extremely robust against black-box attacks and has improved robustness against white-box attacks compared to naturally trained, feed-forward classifiers.
Variable Augmented Network for Invertible Modality Synthesis-Fusion
Sep 02, 2021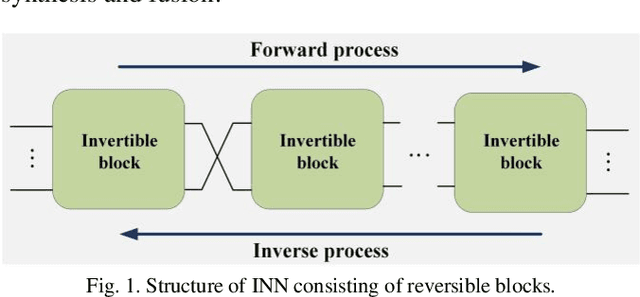
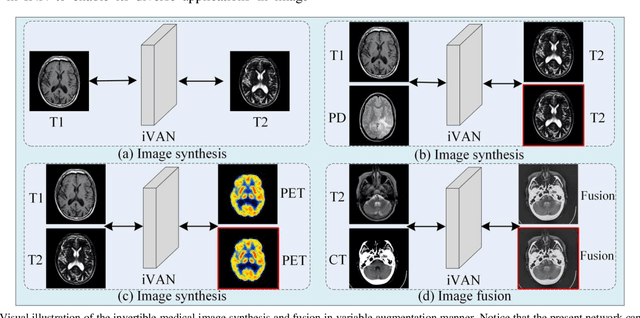
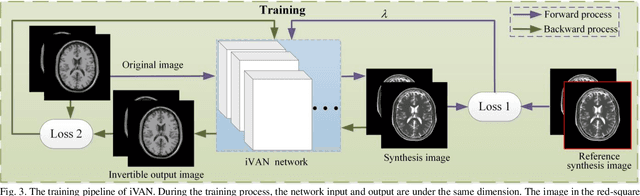
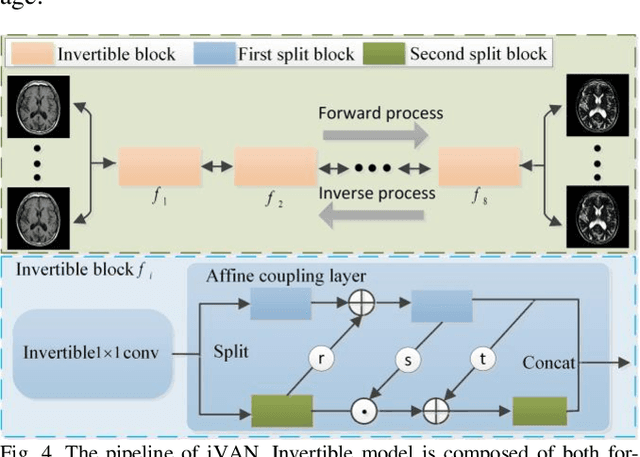
As an effective way to integrate the information contained in multiple medical images under different modalities, medical image synthesis and fusion have emerged in various clinical applications such as disease diagnosis and treatment planning. In this paper, an invertible and variable augmented network (iVAN) is proposed for medical image synthesis and fusion. In iVAN, the channel number of the network input and output is the same through variable augmentation technology, and data relevance is enhanced, which is conducive to the generation of characterization information. Meanwhile, the invertible network is used to achieve the bidirectional inference processes. Due to the invertible and variable augmentation schemes, iVAN can not only be applied to the mappings of multi-input to one-output and multi-input to multi-output, but also be applied to one-input to multi-output. Experimental results demonstrated that the proposed method can obtain competitive or superior performance in comparison to representative medical image synthesis and fusion methods.