 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Expert Knowledge-guided Geometric Representation Learning for Magnetic Resonance Imaging-based Glioma Grading
Jan 08, 2022
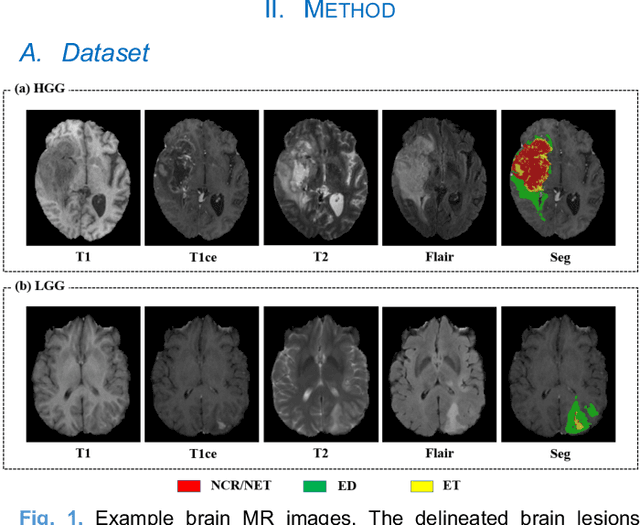
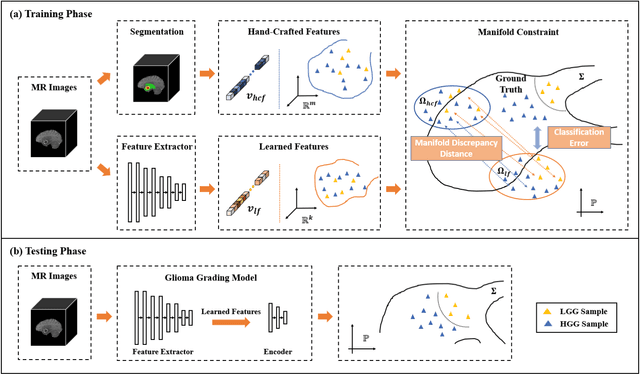
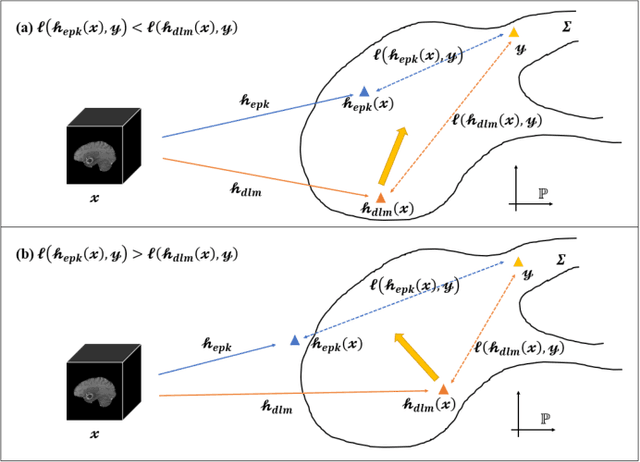
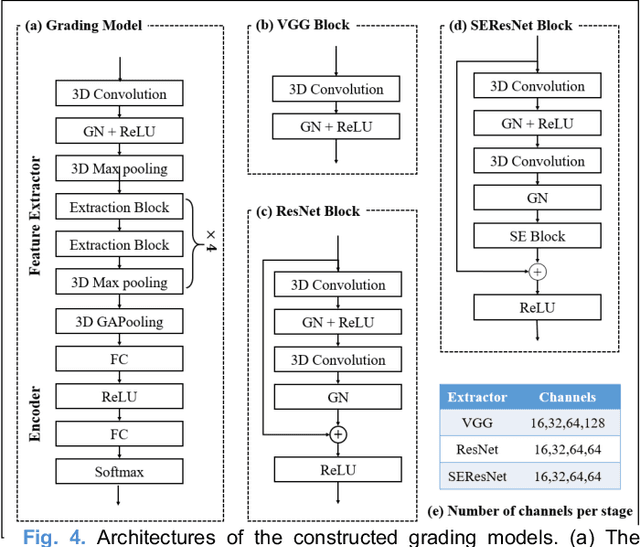
Radiomics and deep learning have shown high popularity in automatic glioma grading. Radiomics can extract hand-crafted features that quantitatively describe the expert knowledge of glioma grades, and deep learning is powerful in extracting a large number of high-throughput features that facilitate the final classification. However, the performance of existing methods can still be improved as their complementary strengths have not been sufficiently investigated and integrated. Furthermore, lesion maps are usually needed for the final prediction at the testing phase, which is very troublesome. In this paper, we propose an expert knowledge-guided geometric representation learning (ENROL) framework . Geometric manifolds of hand-crafted features and learned features are constructed to mine the implicit relationship between deep learning and radiomics, and therefore to dig mutual consent and essential representation for the glioma grades. With a specially designed manifold discrepancy measurement, the grading model can exploit the input image data and expert knowledge more effectively in the training phase and get rid of the requirement of lesion segmentation maps at the testing phase. The proposed framework is flexible regarding deep learning architectures to be utilized. Three different architectures have been evaluated and five models have been compared, which show that our framework can always generate promising results.
SUNet: Symmetric Undistortion Network for Rolling Shutter Correction
Aug 10, 2021
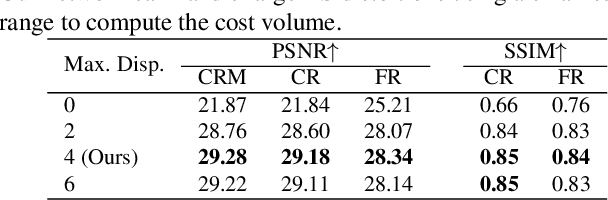
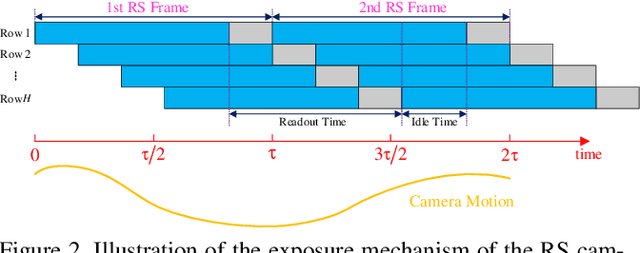
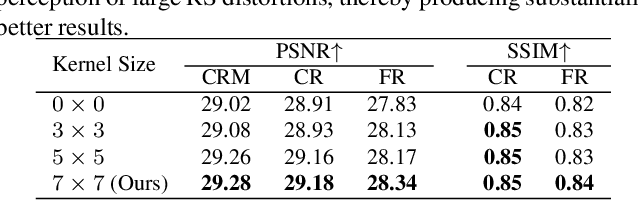
The vast majority of modern consumer-grade cameras employ a rolling shutter mechanism, leading to image distortions if the camera moves during image acquisition. In this paper, we present a novel deep network to solve the generic rolling shutter correction problem with two consecutive frames. Our pipeline is symmetrically designed to predict the global shutter image corresponding to the intermediate time of these two frames, which is difficult for existing methods because it corresponds to a camera pose that differs most from the two frames. First, two time-symmetric dense undistortion flows are estimated by using well-established principles: pyramidal construction, warping, and cost volume processing. Then, both rolling shutter images are warped into a common global shutter one in the feature space, respectively. Finally, a symmetric consistency constraint is constructed in the image decoder to effectively aggregate the contextual cues of two rolling shutter images, thereby recovering the high-quality global shutter image. Extensive experiments with both synthetic and real data from public benchmarks demonstrate the superiority of our proposed approach over the state-of-the-art methods.
Trilevel Neural Architecture Search for Efficient Single Image Super-Resolution
Jan 17, 2021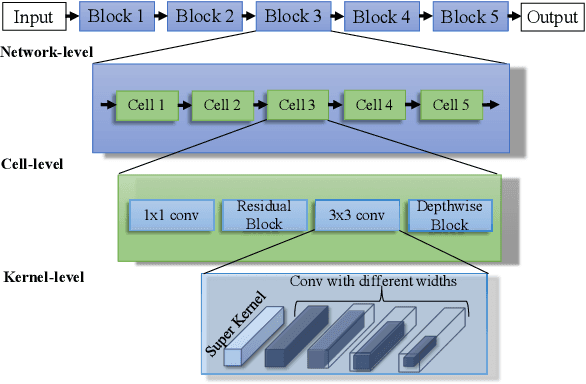
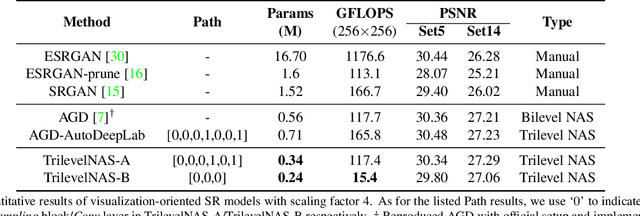
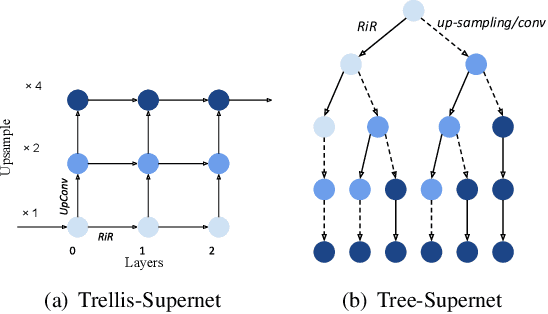
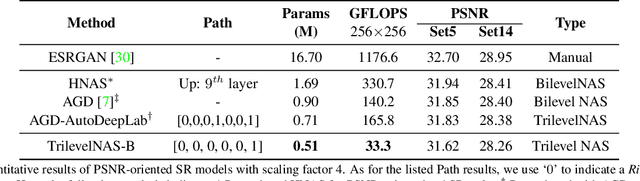
This paper proposes a trilevel neural architecture search (NAS) method for efficient single image super-resolution (SR). For that, we first define the discrete search space at three-level, i.e., at network-level, cell-level, and kernel-level (convolution-kernel). For modeling the discrete search space, we apply a new continuous relaxation on the discrete search spaces to build a hierarchical mixture of network-path, cell-operations, and kernel-width. Later an efficient search algorithm is proposed to perform optimization in a hierarchical supernet manner that provides a globally optimized and compressed network via joint convolution kernel width pruning, cell structure search, and network path optimization. Unlike current NAS methods, we exploit a sorted sparsestmax activation to let the three-level neural structures contribute sparsely. Consequently, our NAS optimization progressively converges to those neural structures with dominant contributions to the supernet. Additionally, our proposed optimization construction enables a simultaneous search and training in a single phase, which dramatically reduces search and train time compared to the traditional NAS algorithms. Experiments on the standard benchmark datasets demonstrate that our NAS algorithm provides SR models that are significantly lighter in terms of the number of parameters and FLOPS with PSNR value comparable to the current state-of-the-art.
Semantically Tied Paired Cycle Consistency for Any-Shot Sketch-based Image Retrieval
Jun 20, 2020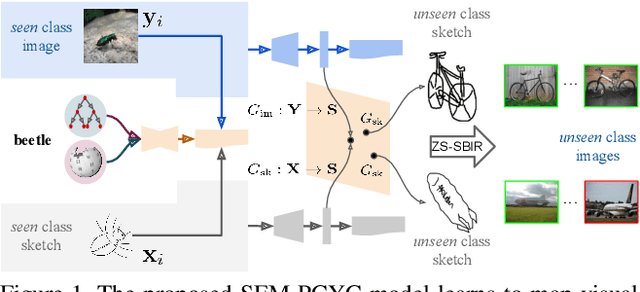
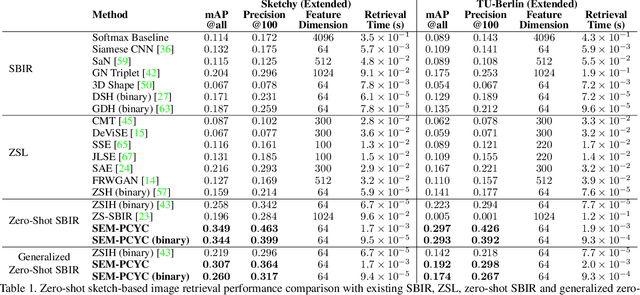
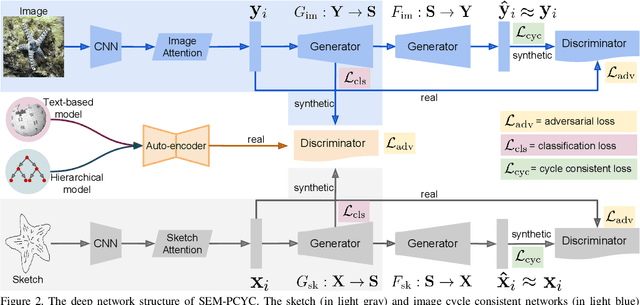

Low-shot sketch-based image retrieval is an emerging task in computer vision, allowing to retrieve natural images relevant to hand-drawn sketch queries that are rarely seen during the training phase. Related prior works either require aligned sketch-image pairs that are costly to obtain or inefficient memory fusion layer for mapping the visual information to a semantic space. In this paper, we address any-shot, i.e. zero-shot and few-shot, sketch-based image retrieval (SBIR) tasks, where we introduce the few-shot setting for SBIR. For solving these tasks, we propose a semantically aligned paired cycle-consistent generative adversarial network (SEM-PCYC) for any-shot SBIR, where each branch of the generative adversarial network maps the visual information from sketch and image to a common semantic space via adversarial training. Each of these branches maintains cycle consistency that only requires supervision at the category level, and avoids the need of aligned sketch-image pairs. A classification criteria on the generators' outputs ensures the visual to semantic space mapping to be class-specific. Furthermore, we propose to combine textual and hierarchical side information via an auto-encoder that selects discriminating side information within a same end-to-end model. Our results demonstrate a significant boost in any-shot SBIR performance over the state-of-the-art on the extended version of the challenging Sketchy, TU-Berlin and QuickDraw datasets.
What's in a Loss Function for Image Classification?
Oct 30, 2020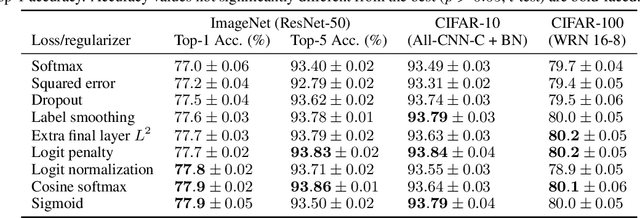
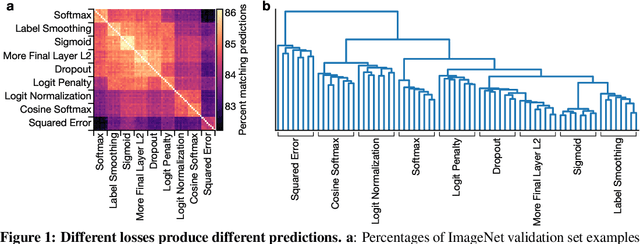
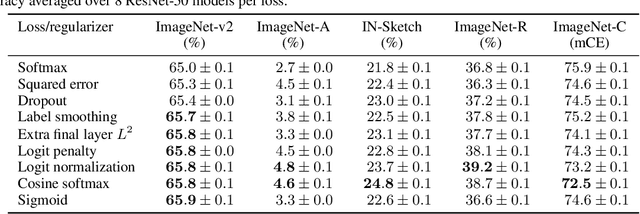
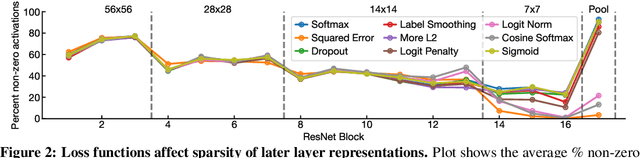
It is common to use the softmax cross-entropy loss to train neural networks on classification datasets where a single class label is assigned to each example. However, it has been shown that modifying softmax cross-entropy with label smoothing or regularizers such as dropout can lead to higher performance. This paper studies a variety of loss functions and output layer regularization strategies on image classification tasks. We observe meaningful differences in model predictions, accuracy, calibration, and out-of-distribution robustness for networks trained with different objectives. However, differences in hidden representations of networks trained with different objectives are restricted to the last few layers; representational similarity reveals no differences among network layers that are not close to the output. We show that all objectives that improve over vanilla softmax loss produce greater class separation in the penultimate layer of the network, which potentially accounts for improved performance on the original task, but results in features that transfer worse to other tasks.
Conditional De-Identification of 3D Magnetic Resonance Images
Oct 18, 2021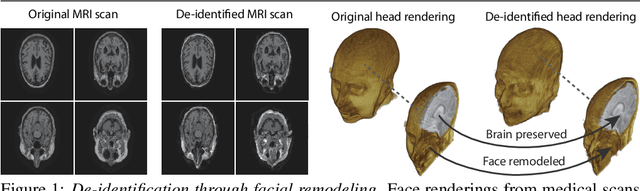
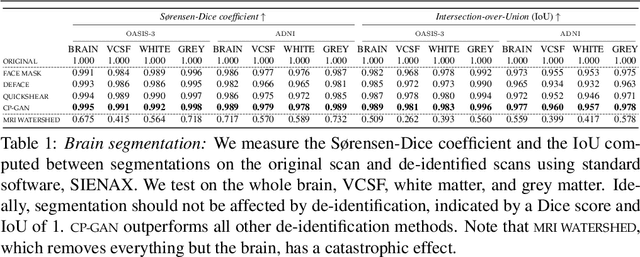
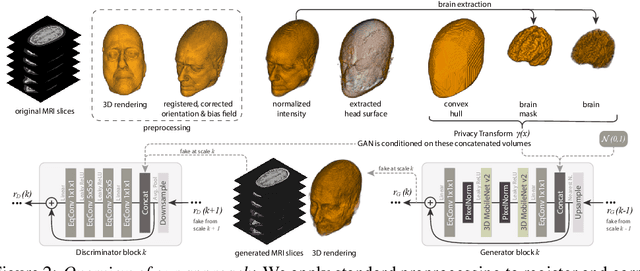
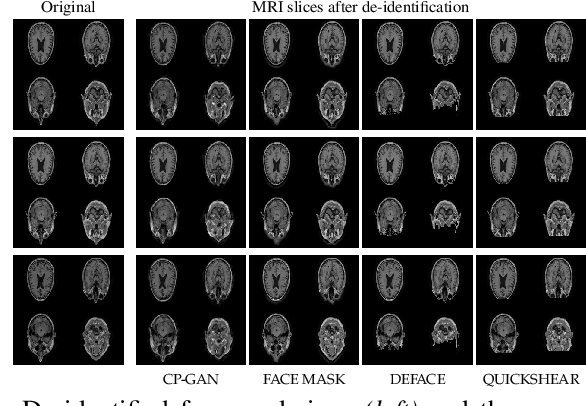
Privacy protection of medical image data is challenging. Even if metadata is removed, brain scans are vulnerable to attacks that match renderings of the face to facial image databases. Solutions have been developed to de-identify diagnostic scans by obfuscating or removing parts of the face. However, these solutions either fail to reliably hide the patient's identity or are so aggressive that they impair further analyses. We propose a new class of de-identification techniques that, instead of removing facial features, remodels them. Our solution relies on a conditional multi-scale GAN architecture. It takes a patient's MRI scan as input and generates a 3D volume conditioned on the patient's brain, which is preserved exactly, but where the face has been de-identified through remodeling. We demonstrate that our approach preserves privacy far better than existing techniques, without compromising downstream medical analyses. Analyses were run on the OASIS-3 and ADNI corpora.
On Salience-Sensitive Sign Classification in Autonomous Vehicle Path Planning: Experimental Explorations with a Novel Dataset
Dec 02, 2021
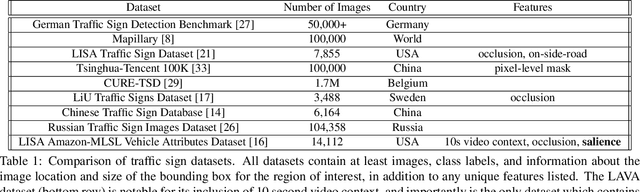

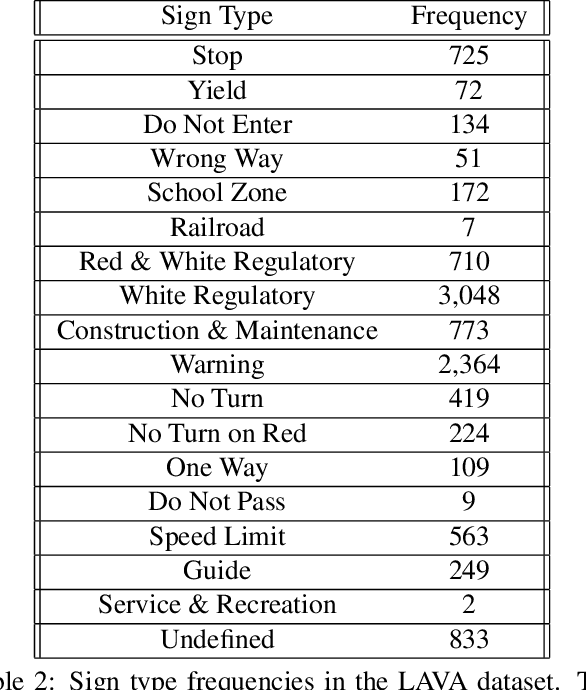
Safe path planning in autonomous driving is a complex task due to the interplay of static scene elements and uncertain surrounding agents. While all static scene elements are a source of information, there is asymmetric importance to the information available to the ego vehicle. We present a dataset with a novel feature, sign salience, defined to indicate whether a sign is distinctly informative to the goals of the ego vehicle with regards to traffic regulations. Using convolutional networks on cropped signs, in tandem with experimental augmentation by road type, image coordinates, and planned maneuver, we predict the sign salience property with 76% accuracy, finding the best improvement using information on vehicle maneuver with sign images.
Frost filtered scale-invariant feature extraction and multilayer perceptron for hyperspectral image classification
Jun 18, 2020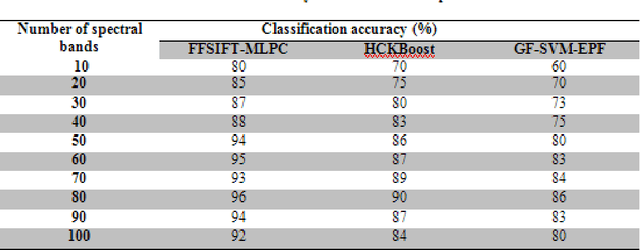
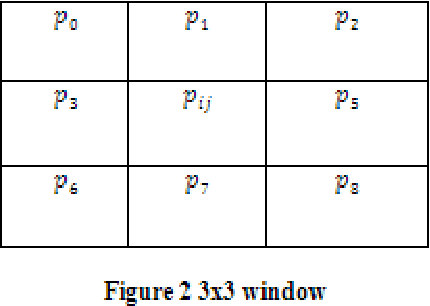
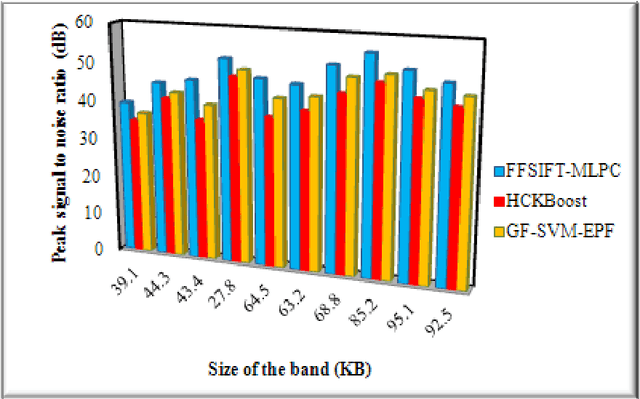
Hyperspectral image (HSI) classification plays a significant in the field of remote sensing due to its ability to provide spatial and spectral information. Due to the rapid development and increasing of hyperspectral remote sensing technology, many methods have been developed for HSI classification but still a lack of achieving the better performance. A Frost Filtered Scale-Invariant Feature Transformation based MultiLayer Perceptron Classification (FFSIFT-MLPC) technique is introduced for classifying the hyperspectral image with higher accuracy and minimum time consumption. The FFSIFT-MLPC technique performs three major processes, namely preprocessing, feature extraction and classification using multiple layers. Initially, the hyperspectral image is divided into number of spectral bands. These bands are given as input in the input layer of perceptron. Then the Frost filter is used in FFSIFT-MLPC technique for preprocessing the input bands which helps to remove the noise from hyper-spectral image at the first hidden layer. After preprocessing task, texture, color and object features of hyper-spectral image are extracted at second hidden layer using Gaussian distributive scale-invariant feature transform. At the third hidden layer, Euclidean distance is measured between the extracted features and testing features. Finally, feature matching is carried out at the output layer for hyper-spectral image classification. The classified outputs are resulted in terms of spectral bands (i.e., different colors). Experimental analysis is performed with PSNR, classification accuracy, false positive rate and classification time with number of spectral bands. The results evident that presented FFSIFT-MLPC technique improves the hyperspectral image classification accuracy, PSNR and minimizes false positive rate as well as classification time than the state-of-the-art methods.
First Order Motion Model for Image Animation
Mar 06, 2020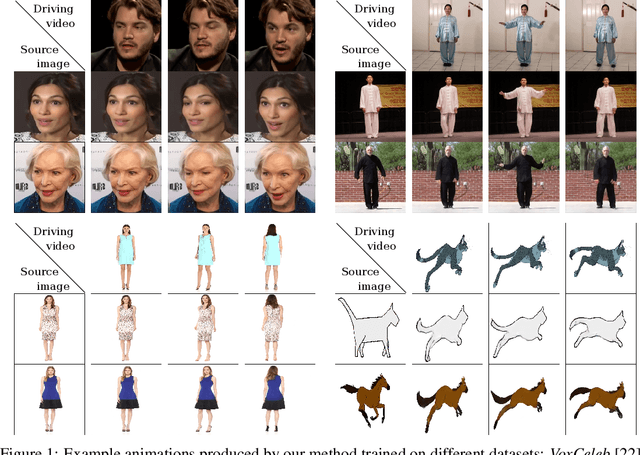
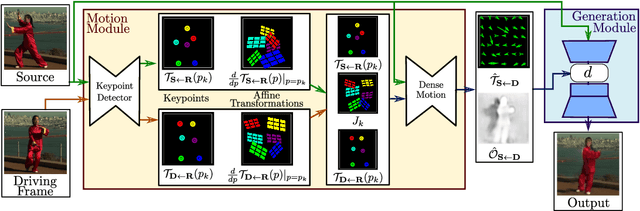

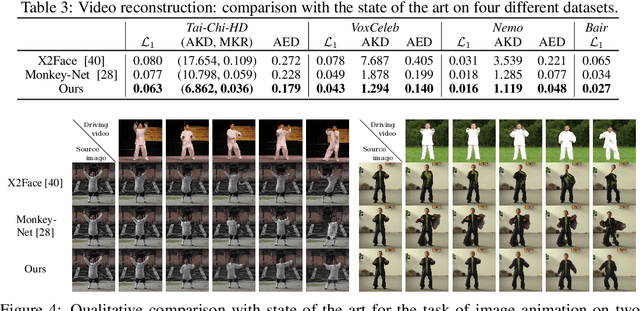
Image animation consists of generating a video sequence so that an object in a source image is animated according to the motion of a driving video. Our framework addresses this problem without using any annotation or prior information about the specific object to animate. Once trained on a set of videos depicting objects of the same category (e.g. faces, human bodies), our method can be applied to any object of this class. To achieve this, we decouple appearance and motion information using a self-supervised formulation. To support complex motions, we use a representation consisting of a set of learned keypoints along with their local affine transformations. A generator network models occlusions arising during target motions and combines the appearance extracted from the source image and the motion derived from the driving video. Our framework scores best on diverse benchmarks and on a variety of object categories. Our source code is publicly available.
Action Image Representation: Learning Scalable Deep Grasping Policies with Zero Real World Data
May 13, 2020

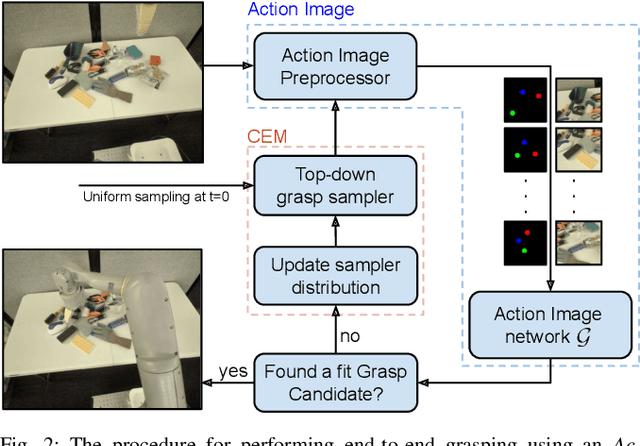
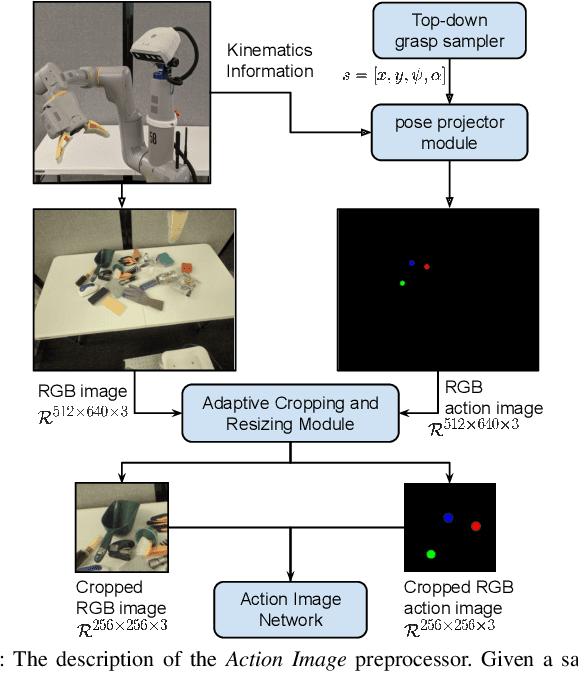
This paper introduces Action Image, a new grasp proposal representation that allows learning an end-to-end deep-grasping policy. Our model achieves $84\%$ grasp success on $172$ real world objects while being trained only in simulation on $48$ objects with just naive domain randomization. Similar to computer vision problems, such as object detection, Action Image builds on the idea that object features are invariant to translation in image space. Therefore, grasp quality is invariant when evaluating the object-gripper relationship; a successful grasp for an object depends on its local context, but is independent of the surrounding environment. Action Image represents a grasp proposal as an image and uses a deep convolutional network to infer grasp quality. We show that by using an Action Image representation, trained networks are able to extract local, salient features of grasping tasks that generalize across different objects and environments. We show that this representation works on a variety of inputs, including color images (RGB), depth images (D), and combined color-depth (RGB-D). Our experimental results demonstrate that networks utilizing an Action Image representation exhibit strong domain transfer between training on simulated data and inference on real-world sensor streams. Finally, our experiments show that a network trained with Action Image improves grasp success ($84\%$ vs. $53\%$) over a baseline model with the same structure, but using actions encoded as vectors.