 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Hole Image Inpainting With Compress-Decompression Network
Feb 01, 2020

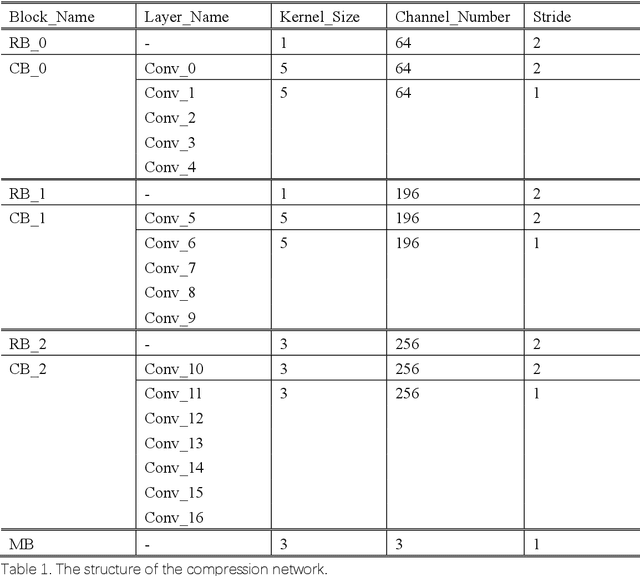
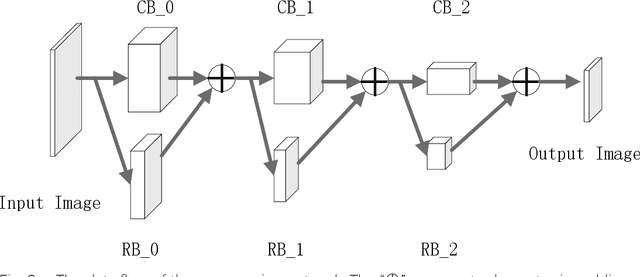
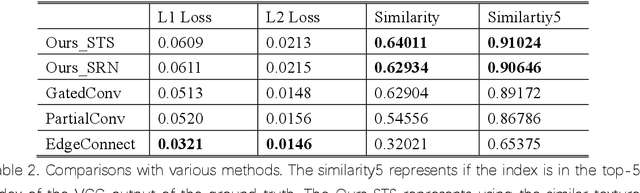
Image inpainting technology can patch images with missing pixels. Existing methods propose convolutional neural networks to repair corrupted images. The networks focus on the valid pixels around the missing pixels, use the encoder-decoder structure to extract valuable information, and use the information to fix the vacancy. However, if the missing part is too large to provide useful information, the result will exist blur, color mixing, and object confusion. In order to patch the large hole image, we study the existing approaches and propose a new network, the compression-decompression network. The compression network takes responsibility for inpainting and generating a down-sample image. The decompression network takes responsibility for extending the down-sample image into the original resolution. We construct the compression network with the residual network and propose a similar texture selection algorithm to extend the image that is better than using the super-resolution network. We evaluate our model over Places2 and CelebA data set and use the similarity ratio as the metric. The result shows that our model has better performance when the inpainting task has many conflicts.
An analysis of over-sampling labeled data in semi-supervised learning with FixMatch
Jan 03, 2022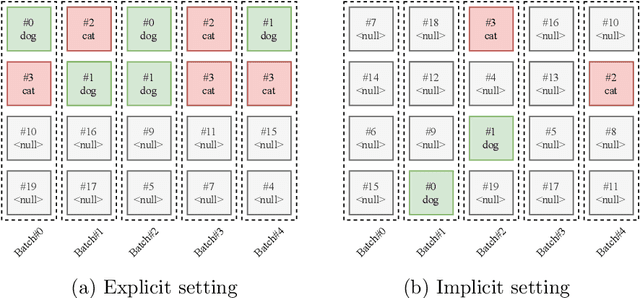
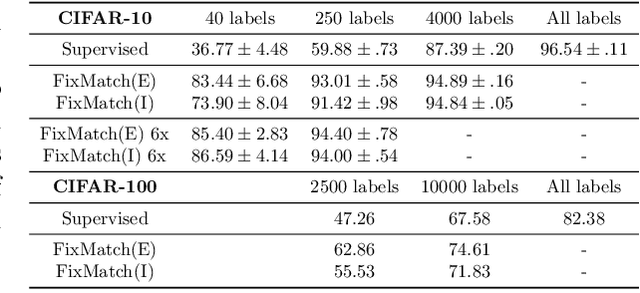
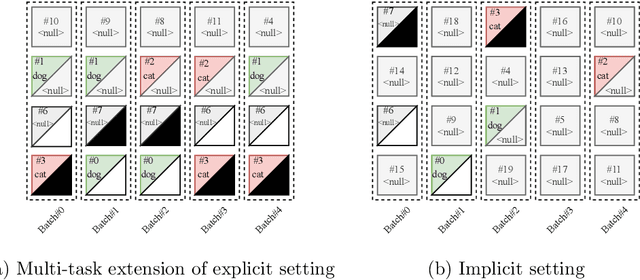
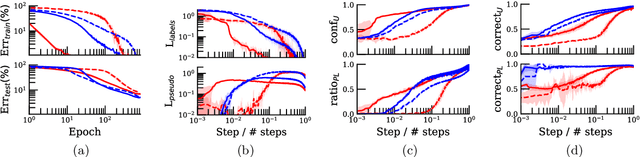
Most semi-supervised learning methods over-sample labeled data when constructing training mini-batches. This paper studies whether this common practice improves learning and how. We compare it to an alternative setting where each mini-batch is uniformly sampled from all the training data, labeled or not, which greatly reduces direct supervision from true labels in typical low-label regimes. However, this simpler setting can also be seen as more general and even necessary in multi-task problems where over-sampling labeled data would become intractable. Our experiments on semi-supervised CIFAR-10 image classification using FixMatch show a performance drop when using the uniform sampling approach which diminishes when the amount of labeled data or the training time increases. Further, we analyse the training dynamics to understand how over-sampling of labeled data compares to uniform sampling. Our main finding is that over-sampling is especially beneficial early in training but gets less important in the later stages when more pseudo-labels become correct. Nevertheless, we also find that keeping some true labels remains important to avoid the accumulation of confirmation errors from incorrect pseudo-labels.
Bounding Boxes Are All We Need: Street View Image Classification via Context Encoding of Detected Buildings
Oct 12, 2020
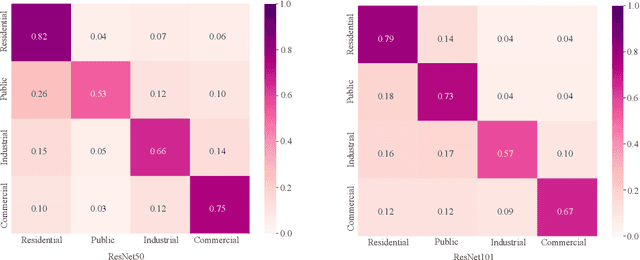
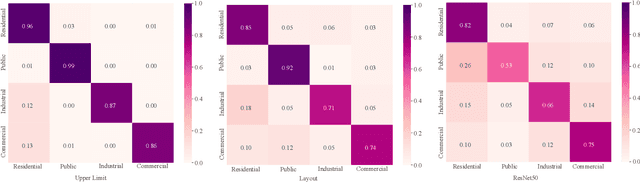

Street view images classification aiming at urban land use analysis is difficult because the class labels (e.g., commercial area), are concepts with higher abstract level compared to the ones of general visual tasks (e.g., persons and cars). Therefore, classification models using only visual features often fail to achieve satisfactory performance. In this paper, a novel approach based on a "Detector-Encoder-Classifier" framework is proposed. Instead of using visual features of the whole image directly as common image-level models based on convolutional neural networks (CNNs) do, the proposed framework firstly obtains the bounding boxes of buildings in street view images from a detector. Their contextual information such as the co-occurrence patterns of building classes and their layout are then encoded into metadata by the proposed algorithm "CODING" (Context encOding of Detected buildINGs). Finally, these bounding box metadata are classified by a recurrent neural network (RNN). In addition, we made a dual-labeled dataset named "BEAUTY" (Building dEtection And Urban funcTional-zone portraYing) of 19,070 street view images and 38,857 buildings based on the existing BIC GSV [1]. The dataset can be used not only for street view image classification, but also for multi-class building detection. Experiments on "BEAUTY" show that the proposed approach achieves a 12.65% performance improvement on macro-precision and 12% on macro-recall over image-level CNN based models. Our code and dataset are available at https://github.com/kyle-one/Context-Encoding-of-Detected-Buildings/
Improving Tail-Class Representation with Centroid Contrastive Learning
Oct 19, 2021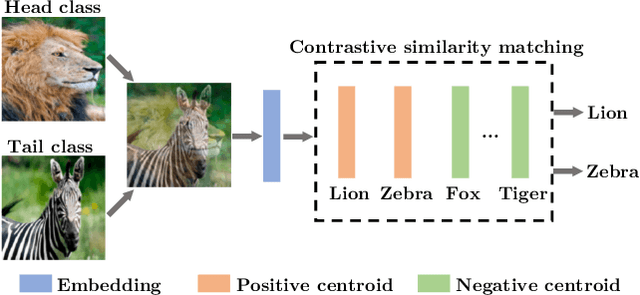
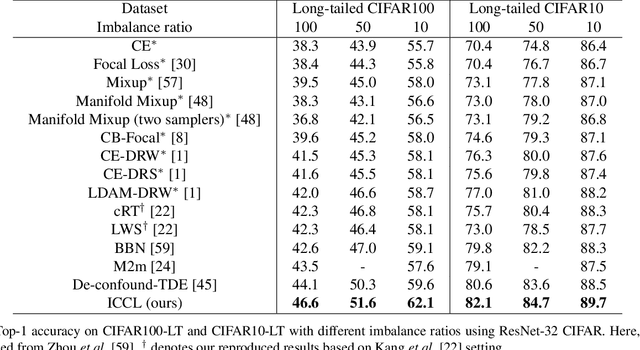
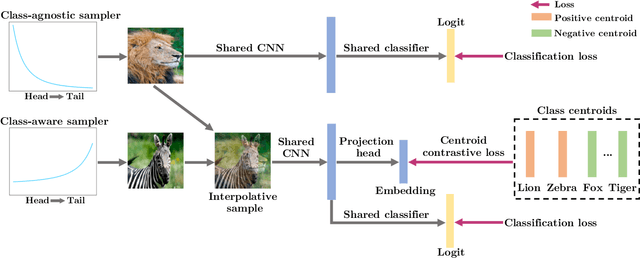
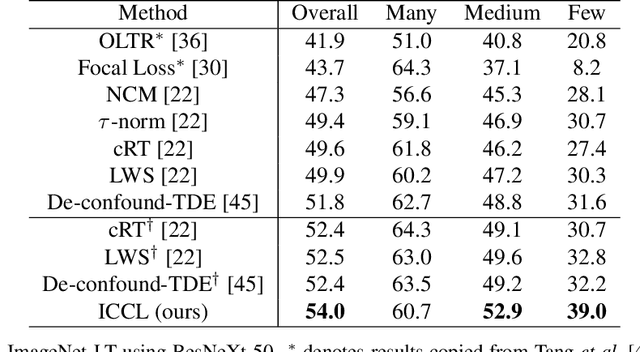
In vision domain, large-scale natural datasets typically exhibit long-tailed distribution which has large class imbalance between head and tail classes. This distribution poses difficulty in learning good representations for tail classes. Recent developments have shown good long-tailed model can be learnt by decoupling the training into representation learning and classifier balancing. However, these works pay insufficient consideration on the long-tailed effect on representation learning. In this work, we propose interpolative centroid contrastive learning (ICCL) to improve long-tailed representation learning. ICCL interpolates two images from a class-agnostic sampler and a class-aware sampler, and trains the model such that the representation of the interpolative image can be used to retrieve the centroids for both source classes. We demonstrate the effectiveness of our approach on multiple long-tailed image classification benchmarks. Our result shows a significant accuracy gain of 2.8% on the iNaturalist 2018 dataset with a real-world long-tailed distribution.
A Data-Driven Reconstruction Technique based on Newton's Method for Emission Tomography
Oct 19, 2021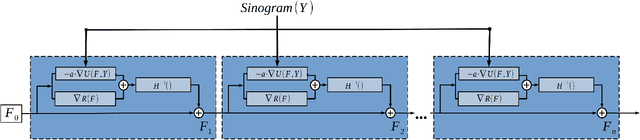
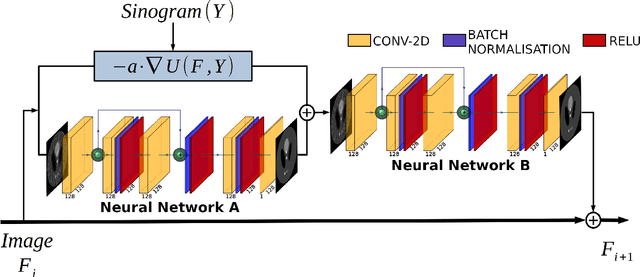
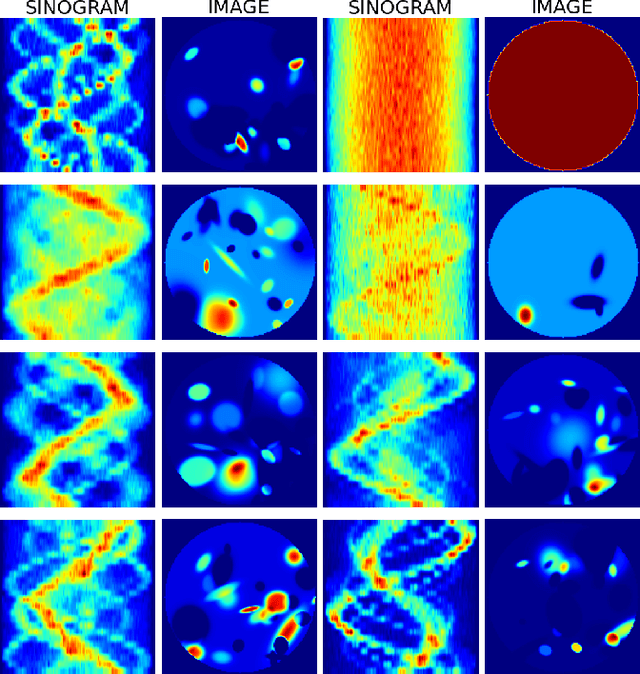
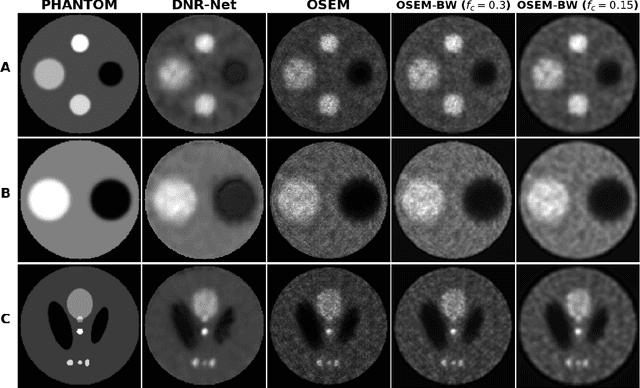
In this work, we present the Deep Newton Reconstruction Network (DNR-Net), a hybrid data-driven reconstruction technique for emission tomography inspired by Newton's method, a well-known iterative optimization algorithm. The DNR-Net employs prior information about the tomographic problem provided by the projection operator while utilizing deep learning approaches to a) imitate Newton's method by approximating the Newton descent direction and b) provide data-driven regularisation. We demonstrate that DNR-Net is capable of providing high-quality image reconstructions using data from SPECT phantom simulations by applying it to reconstruct images from noisy sinograms, each one containing 24 projections. The Structural Similarity Index (SSIM) and the Contrast-to-Noise ratio (CNR) were used to quantify the image quality. We also compare our results to those obtained by the OSEM method. According to the quantitative results, the DNR-Net produces reconstructions comparable to the ones produced by OSEM while featuring higher contrast and less noise.
* 7 pages, 4 figures, Proceedings
Conditional Image-to-Image Translation
May 01, 2018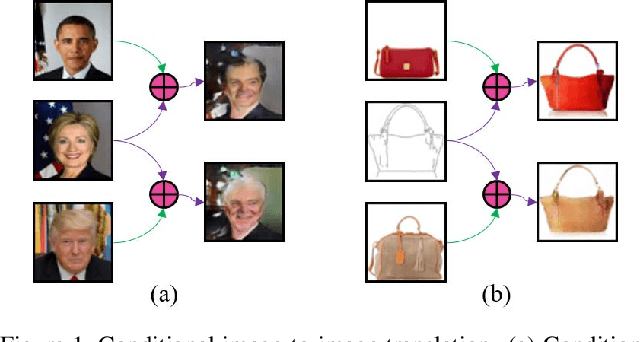
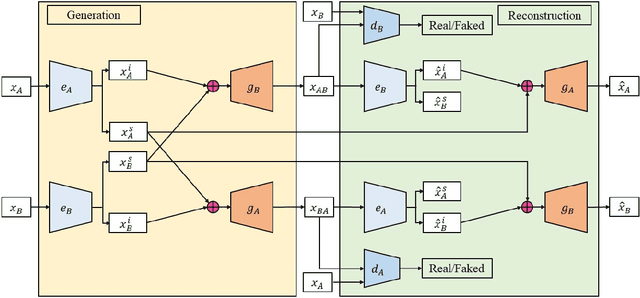


Image-to-image translation tasks have been widely investigated with Generative Adversarial Networks (GANs) and dual learning. However, existing models lack the ability to control the translated results in the target domain and their results usually lack of diversity in the sense that a fixed image usually leads to (almost) deterministic translation result. In this paper, we study a new problem, conditional image-to-image translation, which is to translate an image from the source domain to the target domain conditioned on a given image in the target domain. It requires that the generated image should inherit some domain-specific features of the conditional image from the target domain. Therefore, changing the conditional image in the target domain will lead to diverse translation results for a fixed input image from the source domain, and therefore the conditional input image helps to control the translation results. We tackle this problem with unpaired data based on GANs and dual learning. We twist two conditional translation models (one translation from A domain to B domain, and the other one from B domain to A domain) together for inputs combination and reconstruction while preserving domain independent features. We carry out experiments on men's faces from-to women's faces translation and edges to shoes&bags translations. The results demonstrate the effectiveness of our proposed method.
Vision Transformer with Deformable Attention
Jan 03, 2022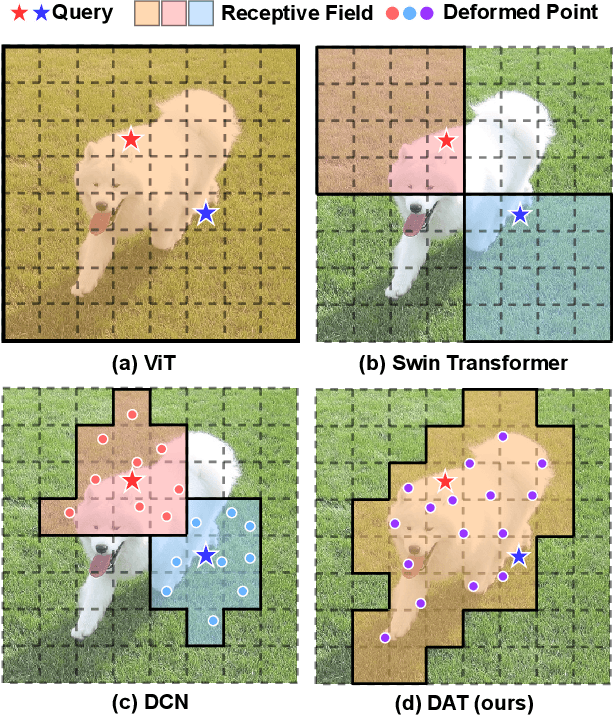
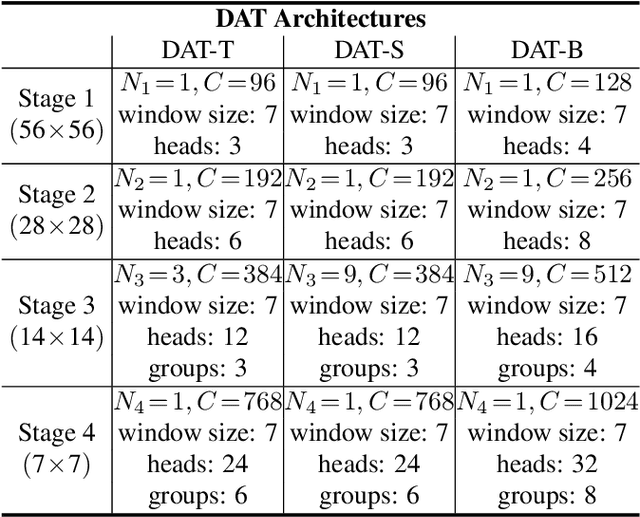
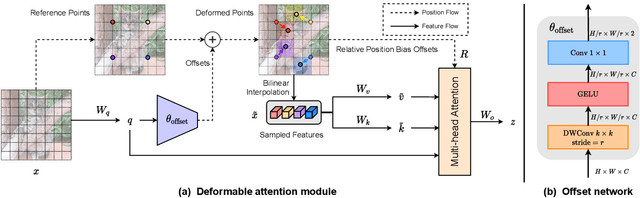
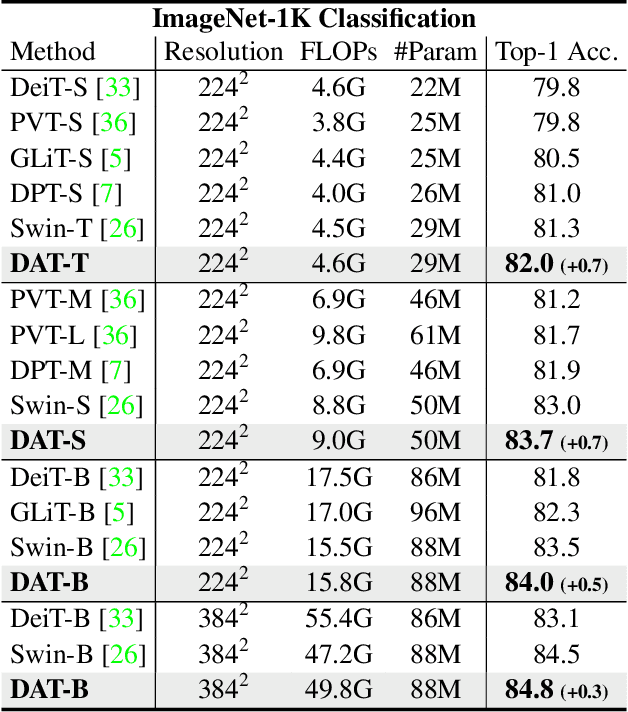
Transformers have recently shown superior performances on various vision tasks. The large, sometimes even global, receptive field endows Transformer models with higher representation power over their CNN counterparts. Nevertheless, simply enlarging receptive field also gives rise to several concerns. On the one hand, using dense attention e.g., in ViT, leads to excessive memory and computational cost, and features can be influenced by irrelevant parts which are beyond the region of interests. On the other hand, the sparse attention adopted in PVT or Swin Transformer is data agnostic and may limit the ability to model long range relations. To mitigate these issues, we propose a novel deformable self-attention module, where the positions of key and value pairs in self-attention are selected in a data-dependent way. This flexible scheme enables the self-attention module to focus on relevant regions and capture more informative features. On this basis, we present Deformable Attention Transformer, a general backbone model with deformable attention for both image classification and dense prediction tasks. Extensive experiments show that our models achieve consistently improved results on comprehensive benchmarks. Code is available at https://github.com/LeapLabTHU/DAT.
Contrastive Rendering for Ultrasound Image Segmentation
Oct 10, 2020
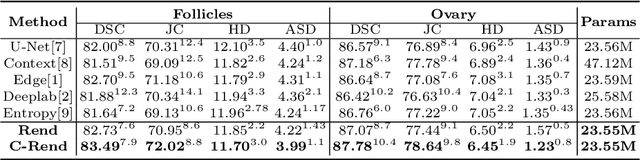
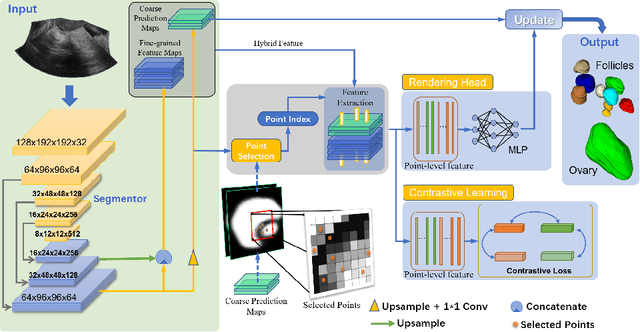
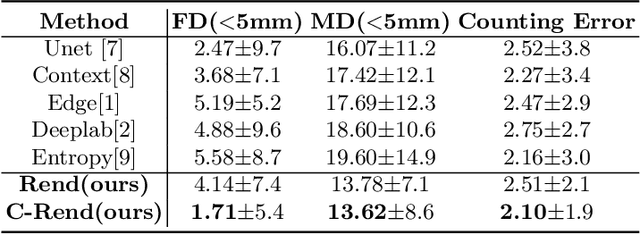
Ultrasound (US) image segmentation embraced its significant improvement in deep learning era. However, the lack of sharp boundaries in US images still remains an inherent challenge for segmentation. Previous methods often resort to global context, multi-scale cues or auxiliary guidance to estimate the boundaries. It is hard for these methods to approach pixel-level learning for fine-grained boundary generating. In this paper, we propose a novel and effective framework to improve boundary estimation in US images. Our work has three highlights. First, we propose to formulate the boundary estimation as a rendering task, which can recognize ambiguous points (pixels/voxels) and calibrate the boundary prediction via enriched feature representation learning. Second, we introduce point-wise contrastive learning to enhance the similarity of points from the same class and contrastively decrease the similarity of points from different classes. Boundary ambiguities are therefore further addressed. Third, both rendering and contrastive learning tasks contribute to consistent improvement while reducing network parameters. As a proof-of-concept, we performed validation experiments on a challenging dataset of 86 ovarian US volumes. Results show that our proposed method outperforms state-of-the-art methods and has the potential to be used in clinical practice.
Performance or Trust? Why Not Both. Deep AUC Maximization with Self-Supervised Learning for COVID-19 Chest X-ray Classifications
Dec 14, 2021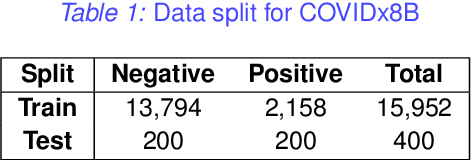
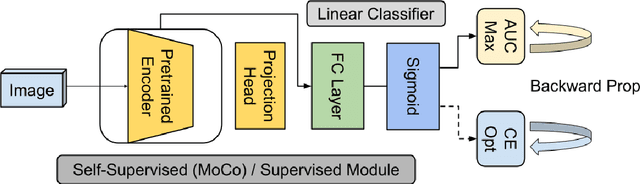
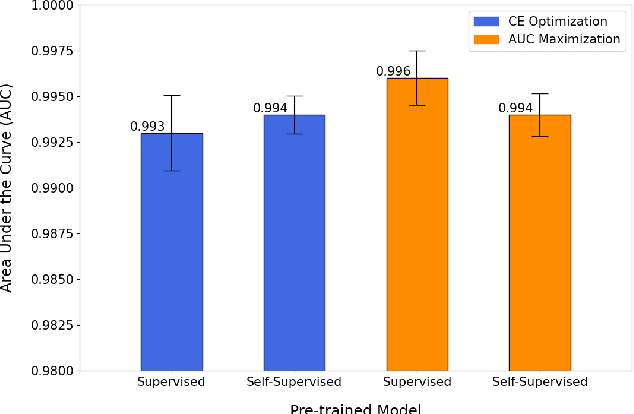
Effective representation learning is the key in improving model performance for medical image analysis. In training deep learning models, a compromise often must be made between performance and trust, both of which are essential for medical applications. Moreover, models optimized with cross-entropy loss tend to suffer from unwarranted overconfidence in the majority class and over-cautiousness in the minority class. In this work, we integrate a new surrogate loss with self-supervised learning for computer-aided screening of COVID-19 patients using radiography images. In addition, we adopt a new quantification score to measure a model's trustworthiness. Ablation study is conducted for both the performance and the trust on feature learning methods and loss functions. Comparisons show that leveraging the new surrogate loss on self-supervised models can produce label-efficient networks that are both high-performing and trustworthy.
* 3 pages
Guiding GANs: How to control non-conditional pre-trained GANs for conditional image generation
Jan 04, 2021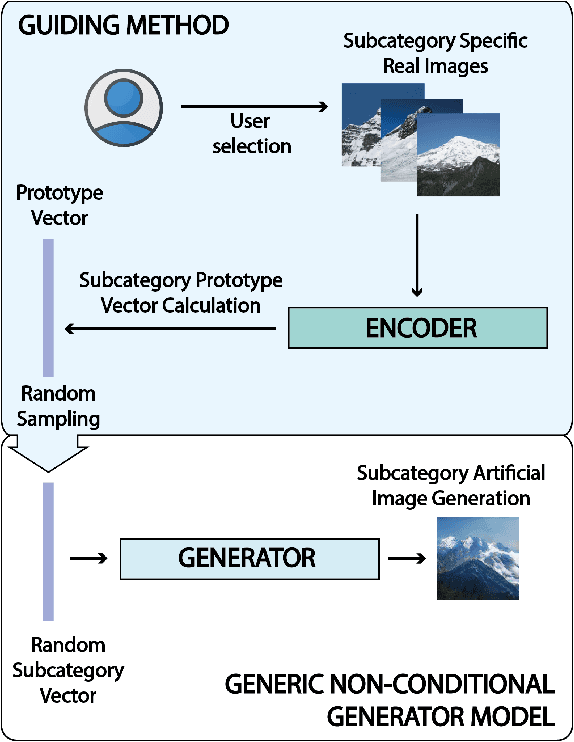
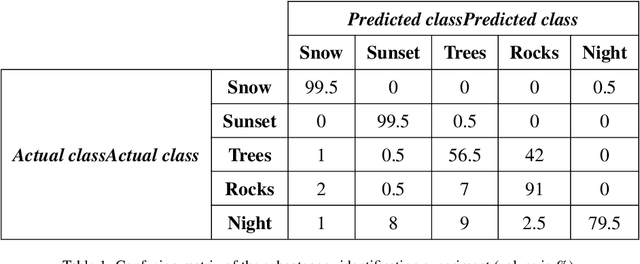
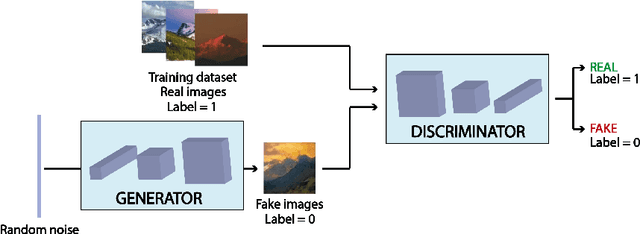
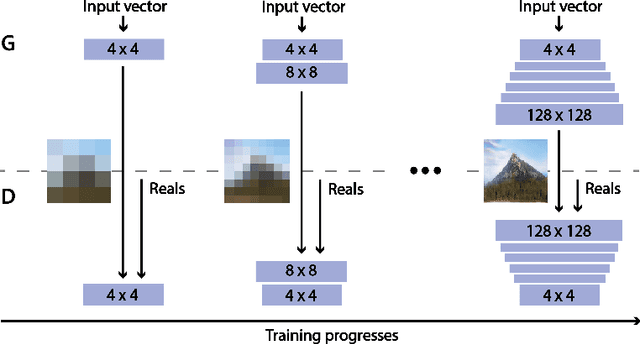
Generative Adversarial Networks (GANs) are an arrange of two neural networks -- the generator and the discriminator -- that are jointly trained to generate artificial data, such as images, from random inputs. The quality of these generated images has recently reached such levels that can often lead both machines and humans into mistaking fake for real examples. However, the process performed by the generator of the GAN has some limitations when we want to condition the network to generate images from subcategories of a specific class. Some recent approaches tackle this \textit{conditional generation} by introducing extra information prior to the training process, such as image semantic segmentation or textual descriptions. While successful, these techniques still require defining beforehand the desired subcategories and collecting large labeled image datasets representing them to train the GAN from scratch. In this paper we present a novel and alternative method for guiding generic non-conditional GANs to behave as conditional GANs. Instead of re-training the GAN, our approach adds into the mix an encoder network to generate the high-dimensional random input vectors that are fed to the generator network of a non-conditional GAN to make it generate images from a specific subcategory. In our experiments, when compared to training a conditional GAN from scratch, our guided GAN is able to generate artificial images of perceived quality comparable to that of non-conditional GANs after training the encoder on just a few hundreds of images, which substantially accelerates the process and enables adding new subcategories seamlessly.