 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Practical Transferability Estimation for Image Classification Tasks
Jun 30, 2021
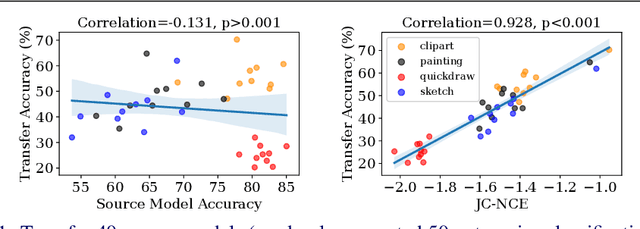
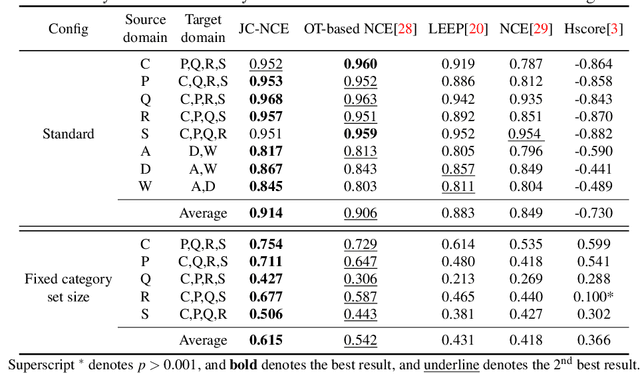
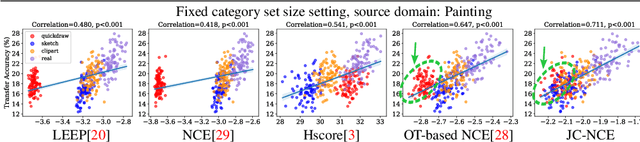
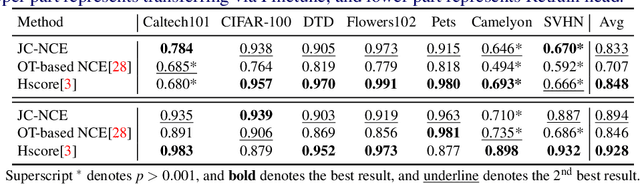
Transferability estimation is an essential problem in transfer learning to predict how good the performance is when transferring a source model (or source task) to a target task. Recent analytical transferability metrics have been widely used for source model selection and multi-task learning. A major challenge is how to make transfereability estimation robust under the cross-domain cross-task settings. The recently proposed OTCE score solves this problem by considering both domain and task differences, with the help of transfer experiences on auxiliary tasks, which causes an efficiency overhead. In this work, we propose a practical transferability metric called JC-NCE score that dramatically improves the robustness of the task difference estimation in OTCE, thus removing the need for auxiliary tasks. Specifically, we build the joint correspondences between source and target data via solving an optimal transport problem with a ground cost considering both the sample distance and label distance, and then compute the transferability score as the negative conditional entropy of the matched labels. Extensive validations under the intra-dataset and inter-dataset transfer settings demonstrate that our JC-NCE score outperforms the auxiliary-task free version of OTCE for 7% and 12%, respectively, and is also more robust than other existing transferability metrics on average.
SuperOCR: A Conversion from Optical Character Recognition to Image Captioning
Nov 21, 2020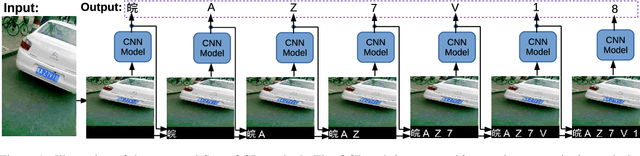
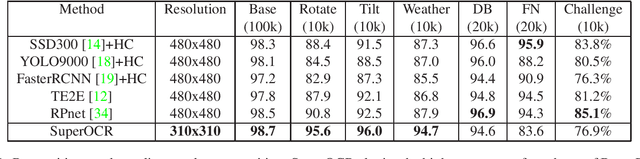
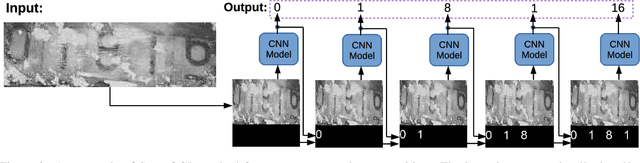
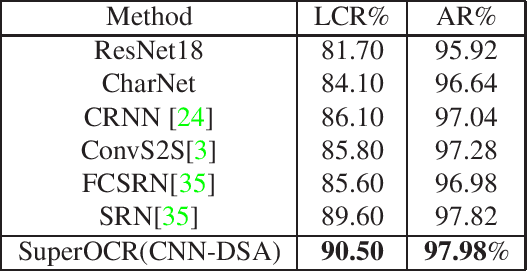
Optical Character Recognition (OCR) has many real world applications. The existing methods normally detect where the characters are, and then recognize the character for each detected location. Thus the accuracy of characters recognition is impacted by the performance of characters detection. In this paper, we propose a method for recognizing characters without detecting the location of each character. This is done by converting the OCR task into an image captioning task. One advantage of the proposed method is that the labeled bounding boxes for the characters are not needed during training. The experimental results show the proposed method outperforms the existing methods on both the license plate recognition and the watermeter character recognition tasks. The proposed method is also deployed into a low-power (300mW) CNN accelerator chip connected to a Raspberry Pi 3 for on-device applications.
Robust Scatterer Number Density Segmentation of Ultrasound Images
Jan 16, 2022
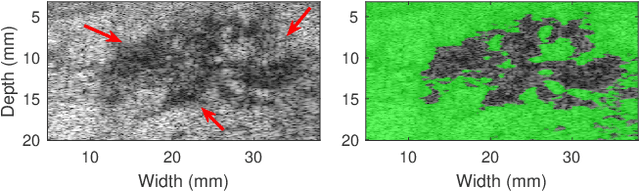
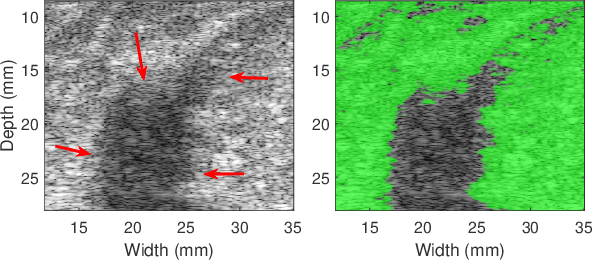
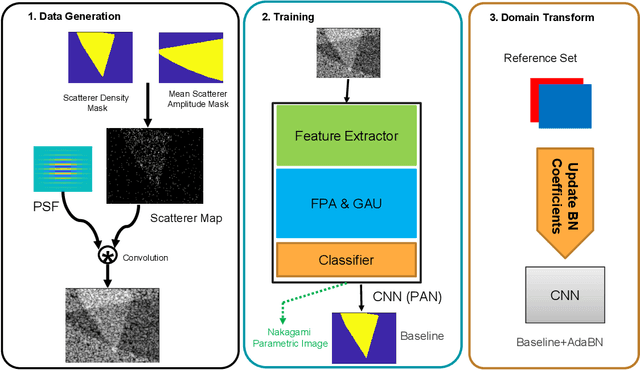
Quantitative UltraSound (QUS) aims to reveal information about the tissue microstructure using backscattered echo signals from clinical scanners. Among different QUS parameters, scatterer number density is an important property that can affect estimation of other QUS parameters. Scatterer number density can be classified into high or low scatterer densities. If there are more than 10 scatterers inside the resolution cell, the envelope data is considered as Fully Developed Speckle (FDS) and otherwise, as Under Developed Speckle (UDS). In conventional methods, the envelope data is divided into small overlapping windows (a strategy here we refer to as patching), and statistical parameters such as SNR and skewness are employed to classify each patch of envelope data. However, these parameters are system dependent meaning that their distribution can change by the imaging settings and patch size. Therefore, reference phantoms which have known scatterer number density are imaged with the same imaging settings to mitigate system dependency. In this paper, we aim to segment regions of ultrasound data without any patching. A large dataset is generated which has different shapes of scatterer number density and mean scatterer amplitude using a fast simulation method. We employ a convolutional neural network (CNN) for the segmentation task and investigate the effect of domain shift when the network is tested on different datasets with different imaging settings. Nakagami parametric image is employed for the multi-task learning to improve the performance. Furthermore, inspired by the reference phantom methods in QUS, A domain adaptation stage is proposed which requires only two frames of data from FDS and UDS classes. We evaluate our method for different experimental phantoms and in vivo data.
A Novel BiLevel Paradigm for Image-to-Image Translation
Apr 18, 2019
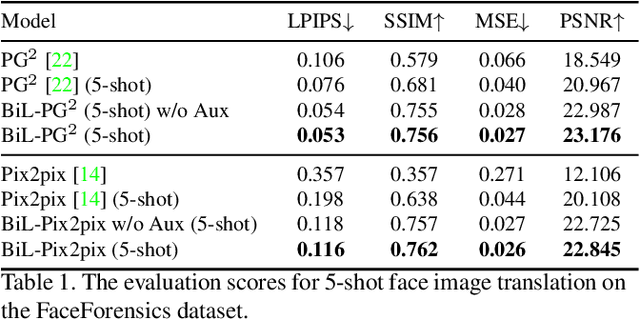
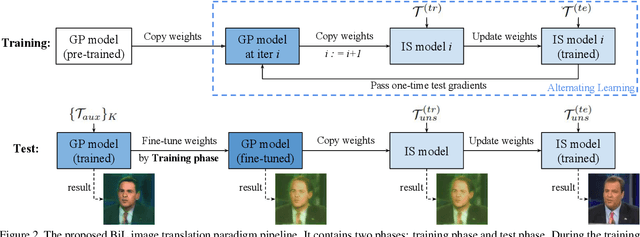
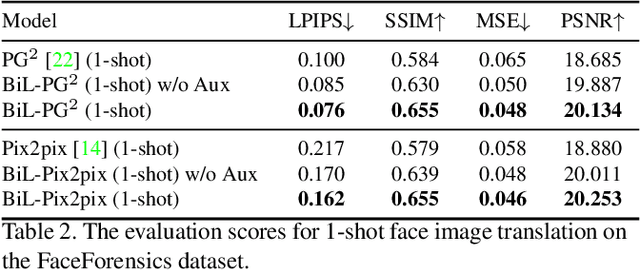
Image-to-image (I2I) translation is a pixel-level mapping that requires a large number of paired training data and often suffers from the problems of high diversity and strong category bias in image scenes. In order to tackle these problems, we propose a novel BiLevel (BiL) learning paradigm that alternates the learning of two models, respectively at an instance-specific (IS) and a general-purpose (GP) level. In each scene, the IS model learns to maintain the specific scene attributes. It is initialized by the GP model that learns from all the scenes to obtain the generalizable translation knowledge. This GP initialization gives the IS model an efficient starting point, thus enabling its fast adaptation to the new scene with scarce training data. We conduct extensive I2I translation experiments on human face and street view datasets. Quantitative results validate that our approach can significantly boost the performance of classical I2I translation models, such as PG2 and Pix2Pix. Our visualization results show both higher image quality and more appropriate instance-specific details, e.g., the translated image of a person looks more like that person in terms of identity.
Assessing learned features of Deep Learning applied to EEG
Nov 08, 2021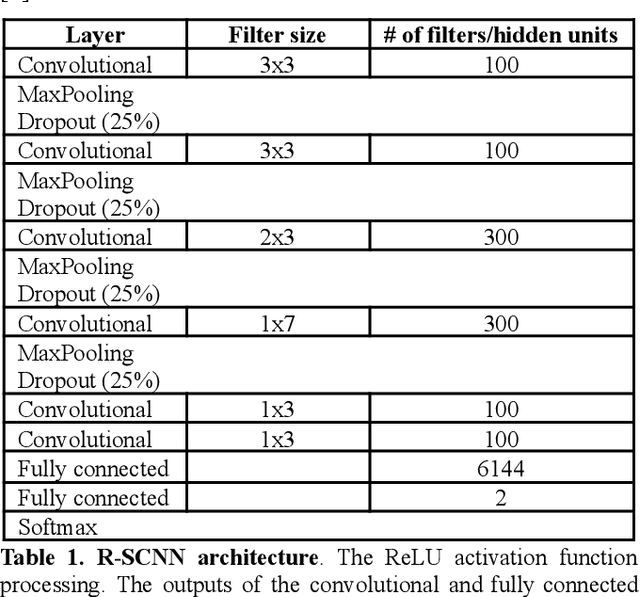
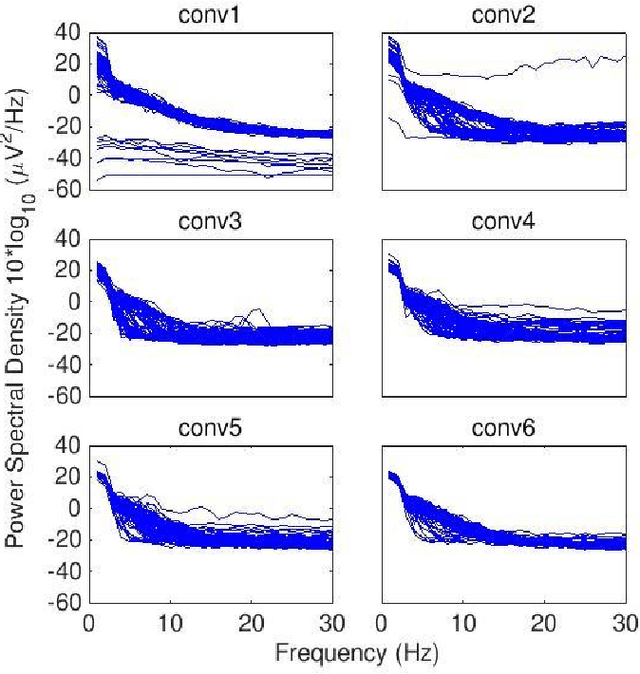
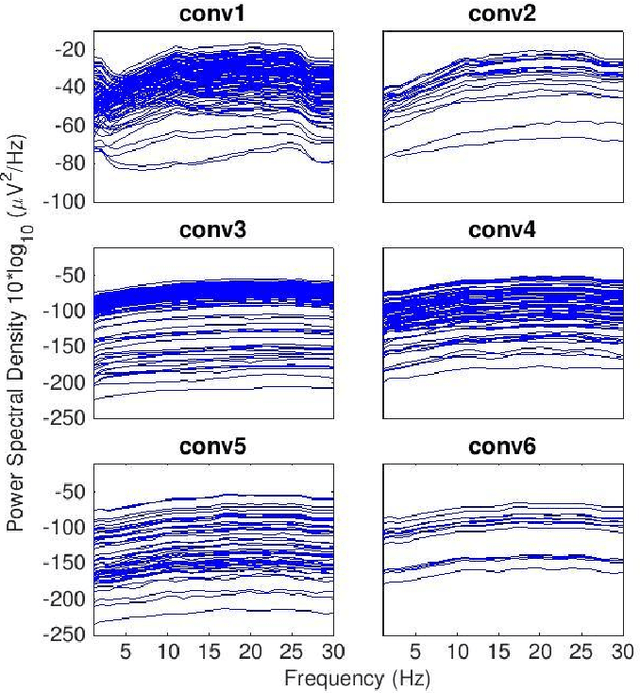
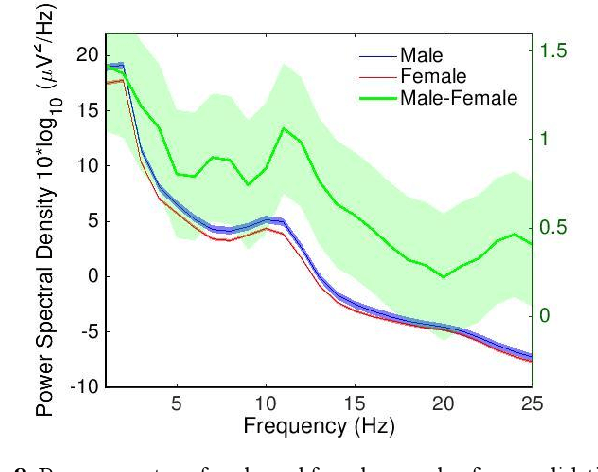
Convolutional Neural Networks (CNNs) have achieved impressive performance on many computer vision related tasks, such as object detection, image recognition, image retrieval, etc. These achievements benefit from the CNNs' outstanding capability to learn discriminative features with deep layers of neuron structures and iterative training process. This has inspired the EEG research community to adopt CNN in performing EEG classification tasks. However, CNNs learned features are not immediately interpretable, causing a lack of understanding of the CNNs' internal working mechanism. To improve CNN interpretability, CNN visualization methods are applied to translate the internal features into visually perceptible patterns for qualitative analysis of CNN layers. Many CNN visualization methods have been proposed in the Computer Vision literature to interpret the CNN network structure, operation, and semantic concept, yet applications to EEG data analysis have been limited. In this work we use 3 different methods to extract EEG-relevant features from a CNN trained on raw EEG data: optimal samples for each classification category, activation maximization, and reverse convolution. We applied these methods to a high-performing Deep Learning model with state-of-the-art performance for an EEG sex classification task, and show that the model features a difference in the theta frequency band. We show that visualization of a CNN model can reveal interesting EEG results. Using these tools, EEG researchers using Deep Learning can better identify the learned EEG features, possibly identifying new class relevant biomarkers.
Context-aware Padding for Semantic Segmentation
Sep 16, 2021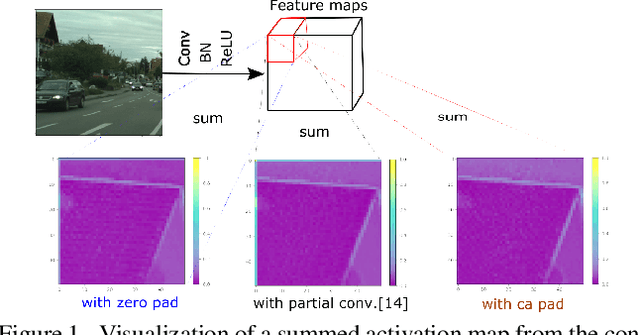

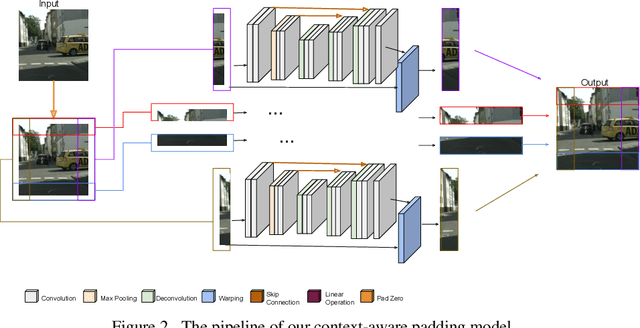

Zero padding is widely used in convolutional neural networks to prevent the size of feature maps diminishing too fast. However, it has been claimed to disturb the statistics at the border. As an alternative, we propose a context-aware (CA) padding approach to extend the image. We reformulate the padding problem as an image extrapolation problem and illustrate the effects on the semantic segmentation task. Using context-aware padding, the ResNet-based segmentation model achieves higher mean Intersection-Over-Union than the traditional zero padding on the Cityscapes and the dataset of DeepGlobe satellite imaging challenge. Furthermore, our padding does not bring noticeable overhead during training and testing.
AutoDC: Automated data-centric processing
Nov 23, 2021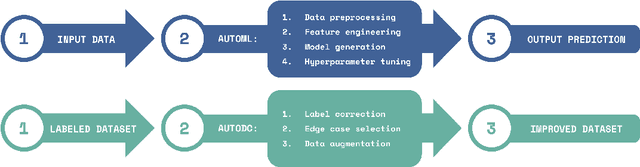

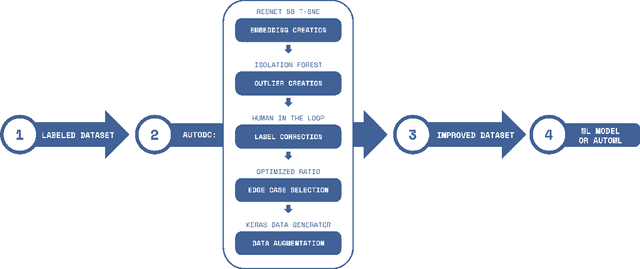
AutoML (automated machine learning) has been extensively developed in the past few years for the model-centric approach. As for the data-centric approach, the processes to improve the dataset, such as fixing incorrect labels, adding examples that represent edge cases, and applying data augmentation, are still very artisanal and expensive. Here we develop an automated data-centric tool (AutoDC), similar to the purpose of AutoML, aims to speed up the dataset improvement processes. In our preliminary tests on 3 open source image classification datasets, AutoDC is estimated to reduce roughly 80% of the manual time for data improvement tasks, at the same time, improve the model accuracy by 10-15% with the fixed ML code.
Event-based Action Recognition Using Timestamp Image Encoding Network
Sep 28, 2020

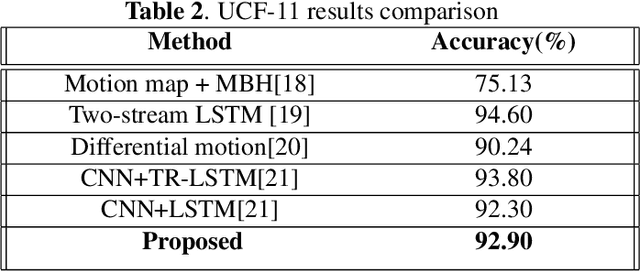
Event camera is an asynchronous, high frequency vision sensor with low power consumption, which is suitable for human action recognition task. It is vital to encode the spatial-temporal information of event data properly and use standard computer vision tool to learn from the data. In this work, we propose a timestamp image encoding 2D network, which takes the encoded spatial-temporal images of the event data as input and output the action label. Experiment results show that our method can achieve the same level of performance as those RGB-based benchmarks on real world action recognition, and also achieve the SOTA result on gesture recognition.
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Sep 17, 2019
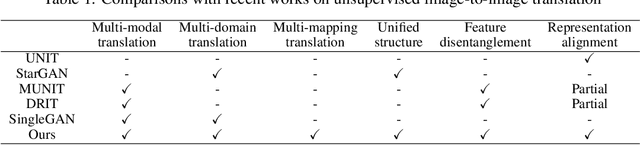

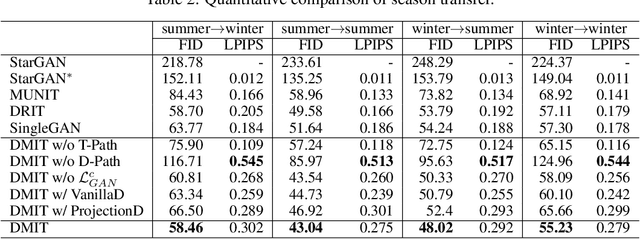
Recent advances of image-to-image translation focus on learning the one-to-many mapping from two aspects: multi-modal translation and multi-domain translation. However, the existing methods only consider one of the two perspectives, which makes them unable to solve each other's problem. To address this issue, we propose a novel unified model, which bridges these two objectives. First, we disentangle the input images into the latent representations by an encoder-decoder architecture with a conditional adversarial training in the feature space. Then, we encourage the generator to learn multi-mappings by a random cross-domain translation. As a result, we can manipulate different parts of the latent representations to perform multi-modal and multi-domain translations simultaneously. Experiments demonstrate that our method outperforms state-of-the-art methods.
Adaptively Multi-view and Temporal Fusing Transformer for 3D Human Pose Estimation
Oct 11, 2021
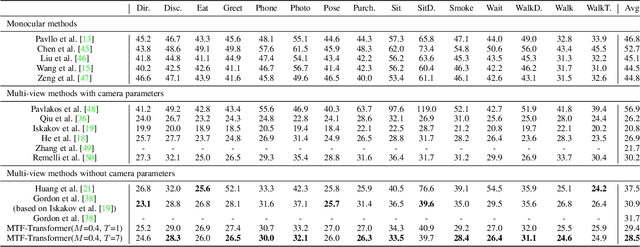


In practical application, 3D Human Pose Estimation (HPE) is facing with several variable elements, involving the number of views, the length of the video sequence, and whether using camera calibration. To this end, we propose a unified framework named Multi-view and Temporal Fusing Transformer (MTF-Transformer) to adaptively handle varying view numbers and video length without calibration. MTF-Transformer consists of Feature Extractor, Multi-view Fusing Transformer (MFT), and Temporal Fusing Transformer (TFT). Feature Extractor estimates the 2D pose from each image and encodes the predicted coordinates and confidence into feature embedding for further 3D pose inference. It discards the image features and focuses on lifting the 2D pose into the 3D pose, making the subsequent modules computationally lightweight enough to handle videos. MFT fuses the features of a varying number of views with a relative-attention block. It adaptively measures the implicit relationship between each pair of views and reconstructs the features. TFT aggregates the features of the whole sequence and predicts 3D pose via a transformer, which is adaptive to the length of the video and takes full advantage of the temporal information. With these modules, MTF-Transformer handles different application scenes, varying from a monocular-single-image to multi-view-video, and the camera calibration is avoidable. We demonstrate quantitative and qualitative results on the Human3.6M, TotalCapture, and KTH Multiview Football II. Compared with state-of-the-art methods with camera parameters, experiments show that MTF-Transformer not only obtains comparable results but also generalizes well to dynamic capture with an arbitrary number of unseen views. Code is available in https://github.com/lelexx/MTF-Transformer.