 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AutoDC: Automated data-centric processing
Nov 23, 2021
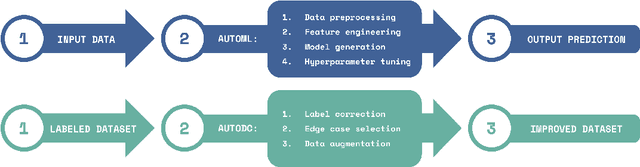

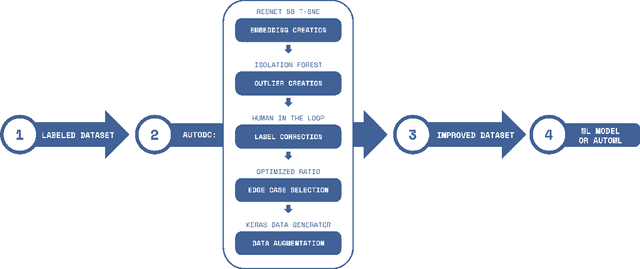
AutoML (automated machine learning) has been extensively developed in the past few years for the model-centric approach. As for the data-centric approach, the processes to improve the dataset, such as fixing incorrect labels, adding examples that represent edge cases, and applying data augmentation, are still very artisanal and expensive. Here we develop an automated data-centric tool (AutoDC), similar to the purpose of AutoML, aims to speed up the dataset improvement processes. In our preliminary tests on 3 open source image classification datasets, AutoDC is estimated to reduce roughly 80% of the manual time for data improvement tasks, at the same time, improve the model accuracy by 10-15% with the fixed ML code.
Online Continual Learning in Image Classification: An Empirical Survey
Jan 25, 2021
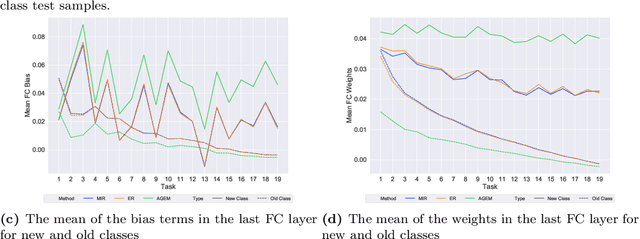
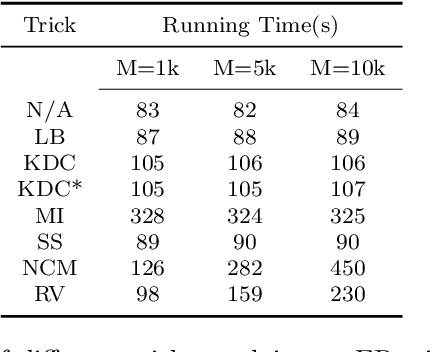
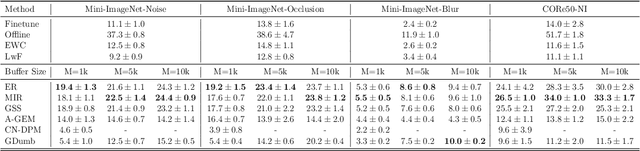
Online continual learning for image classification studies the problem of learning to classify images from an online stream of data and tasks, where tasks may include new classes (class incremental) or data nonstationarity (domain incremental). One of the key challenges of continual learning is to avoid catastrophic forgetting (CF), i.e., forgetting old tasks in the presence of more recent tasks. Over the past few years, many methods and tricks have been introduced to address this problem, but many have not been fairly and systematically compared under a variety of realistic and practical settings. To better understand the relative advantages of various approaches and the settings where they work best, this survey aims to (1) compare state-of-the-art methods such as MIR, iCARL, and GDumb and determine which works best at different experimental settings; (2) determine if the best class incremental methods are also competitive in domain incremental setting; (3) evaluate the performance of 7 simple but effective trick such as "review" trick and nearest class mean (NCM) classifier to assess their relative impact. Regarding (1), we observe earlier proposed iCaRL remains competitive when the memory buffer is small; GDumb outperforms many recently proposed methods in medium-size datasets and MIR performs the best in larger-scale datasets. For (2), we note that GDumb performs quite poorly while MIR -- already competitive for (1) -- is also strongly competitive in this very different but important setting. Overall, this allows us to conclude that MIR is overall a strong and versatile method across a wide variety of settings. For (3), we find that all 7 tricks are beneficial, and when augmented with the "review" trick and NCM classifier, MIR produces performance levels that bring online continual learning much closer to its ultimate goal of matching offline training.
3D-StyleGAN: A Style-Based Generative Adversarial Network for Generative Modeling of Three-Dimensional Medical Images
Jul 20, 2021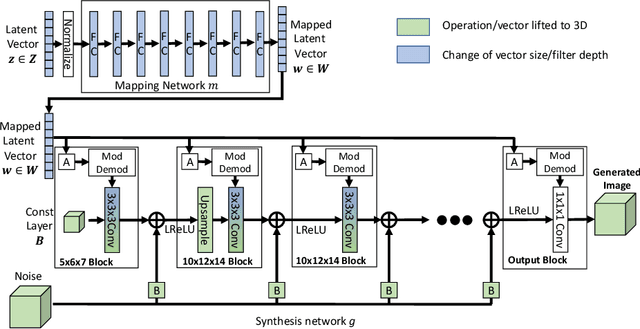
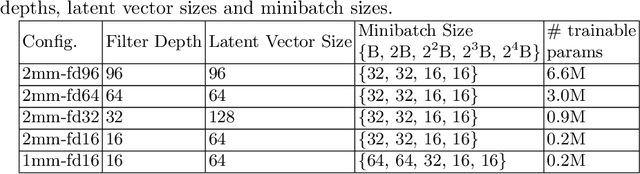
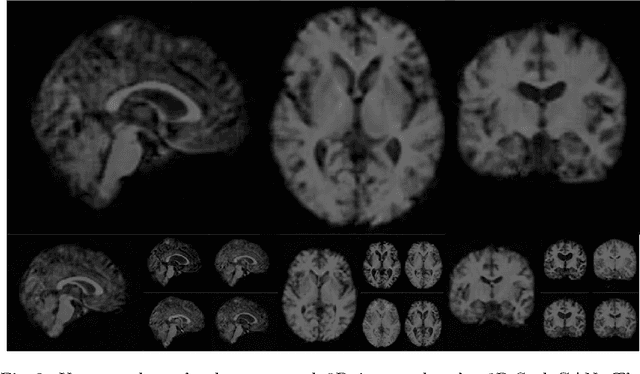
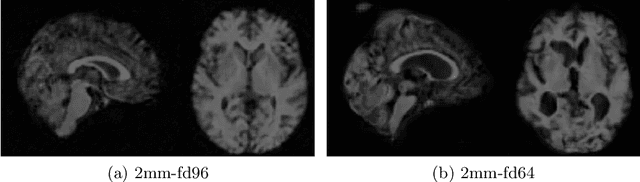
Image synthesis via Generative Adversarial Networks (GANs) of three-dimensional (3D) medical images has great potential that can be extended to many medical applications, such as, image enhancement and disease progression modeling. However, current GAN technologies for 3D medical image synthesis need to be significantly improved to be readily adapted to real-world medical problems. In this paper, we extend the state-of-the-art StyleGAN2 model, which natively works with two-dimensional images, to enable 3D image synthesis. In addition to the image synthesis, we investigate the controllability and interpretability of the 3D-StyleGAN via style vectors inherited form the original StyleGAN2 that are highly suitable for medical applications: (i) the latent space projection and reconstruction of unseen real images, and (ii) style mixing. We demonstrate the 3D-StyleGAN's performance and feasibility with ~12,000 three-dimensional full brain MR T1 images, although it can be applied to any 3D volumetric images. Furthermore, we explore different configurations of hyperparameters to investigate potential improvement of the image synthesis with larger networks. The codes and pre-trained networks are available online: https://github.com/sh4174/3DStyleGAN.
Assessing learned features of Deep Learning applied to EEG
Nov 08, 2021
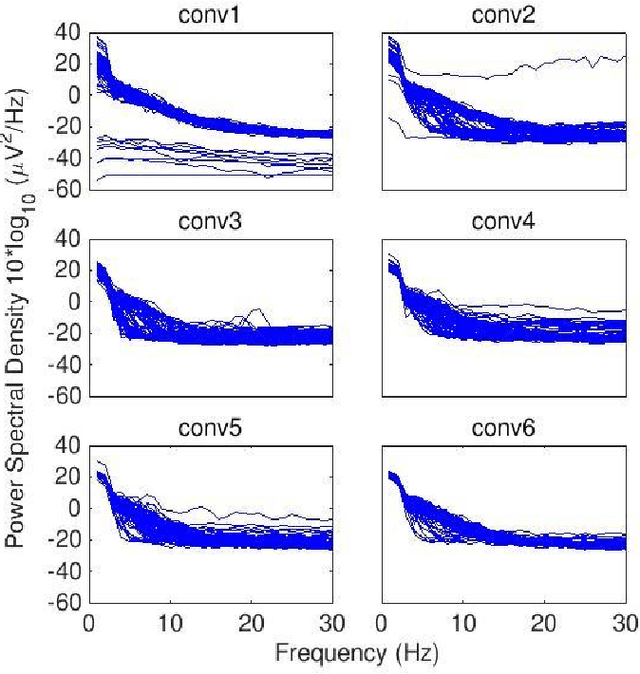
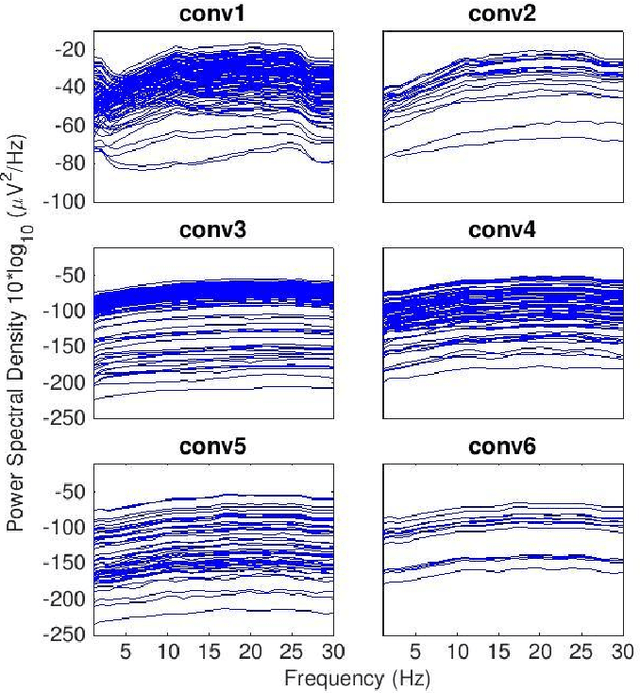
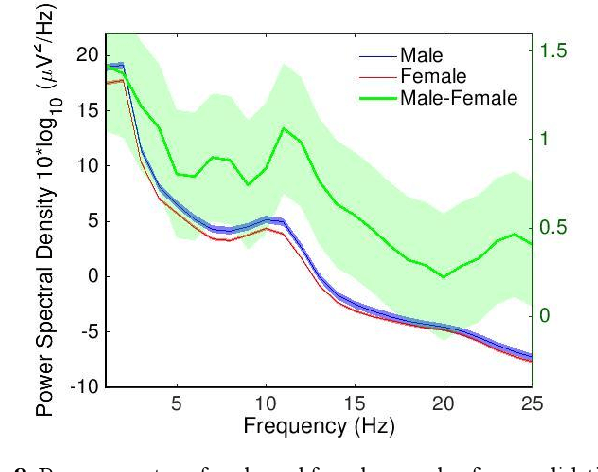
Convolutional Neural Networks (CNNs) have achieved impressive performance on many computer vision related tasks, such as object detection, image recognition, image retrieval, etc. These achievements benefit from the CNNs' outstanding capability to learn discriminative features with deep layers of neuron structures and iterative training process. This has inspired the EEG research community to adopt CNN in performing EEG classification tasks. However, CNNs learned features are not immediately interpretable, causing a lack of understanding of the CNNs' internal working mechanism. To improve CNN interpretability, CNN visualization methods are applied to translate the internal features into visually perceptible patterns for qualitative analysis of CNN layers. Many CNN visualization methods have been proposed in the Computer Vision literature to interpret the CNN network structure, operation, and semantic concept, yet applications to EEG data analysis have been limited. In this work we use 3 different methods to extract EEG-relevant features from a CNN trained on raw EEG data: optimal samples for each classification category, activation maximization, and reverse convolution. We applied these methods to a high-performing Deep Learning model with state-of-the-art performance for an EEG sex classification task, and show that the model features a difference in the theta frequency band. We show that visualization of a CNN model can reveal interesting EEG results. Using these tools, EEG researchers using Deep Learning can better identify the learned EEG features, possibly identifying new class relevant biomarkers.
Gated Texture CNN for Efficient and Configurable Image Denoising
Mar 16, 2020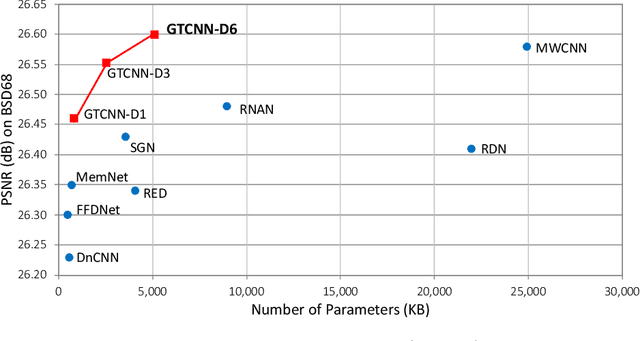
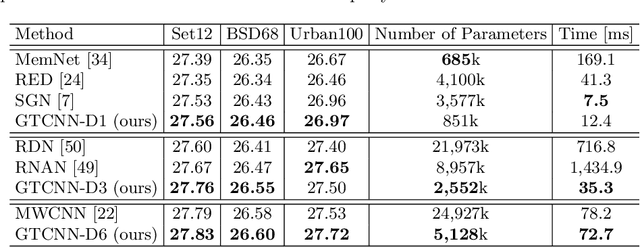
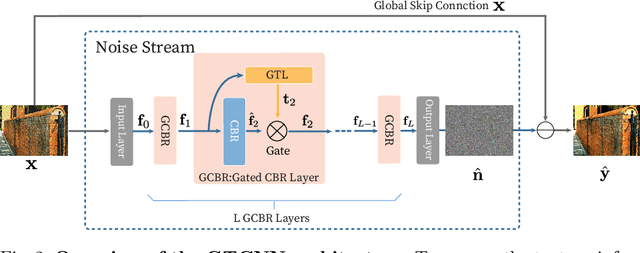
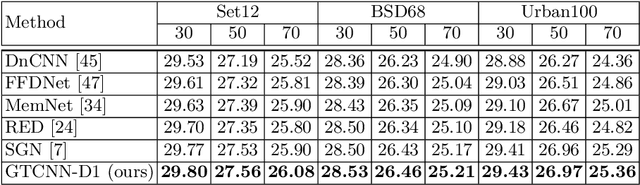
Convolutional neural network (CNN)-based image denoising methods typically estimate the noise component contained in a noisy input image and restore a clean image by subtracting the estimated noise from the input. However, previous denoising methods tend to remove high-frequency information (e.g., textures) from the input. It caused by intermediate feature maps of CNN contains texture information. A straightforward approach to this problem is stacking numerous layers, which leads to a high computational cost. To achieve high performance and computational efficiency, we propose a gated texture CNN (GTCNN), which is designed to carefully exclude the texture information from each intermediate feature map of the CNN by incorporating gating mechanisms. Our GTCNN achieves state-of-the-art performance with 4.8 times fewer parameters than previous state-of-the-art methods. Furthermore, the GTCNN allows us to interactively control the texture strength in the output image without any additional modules, training, or computational costs.
Match Them Up: Visually Explainable Few-shot Image Classification
Nov 25, 2020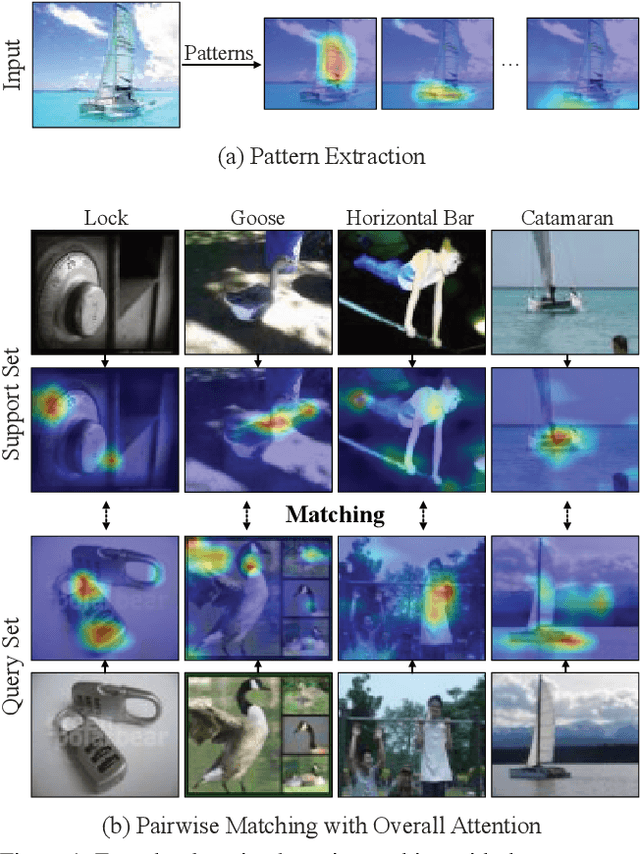
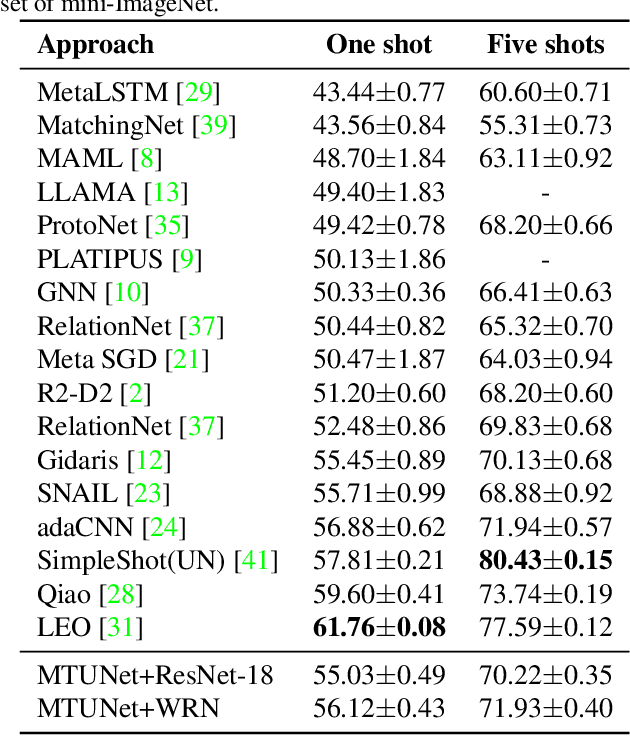
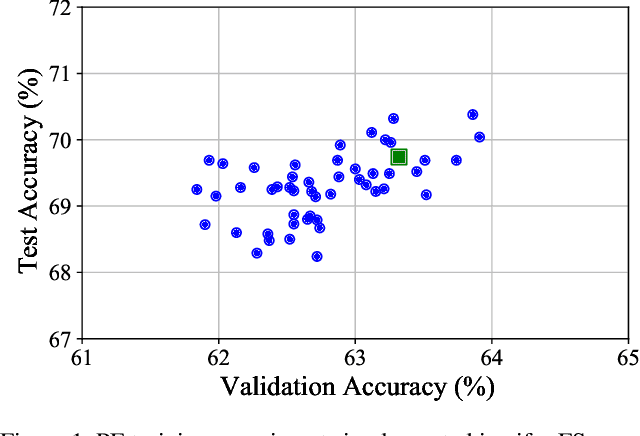
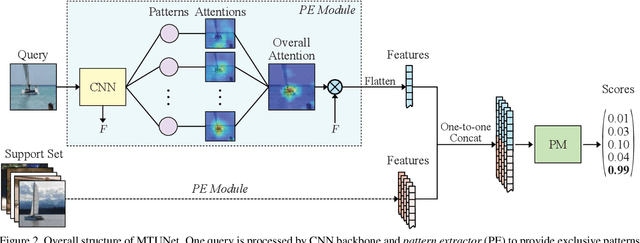
Few-shot learning (FSL) approaches are usually based on an assumption that the pre-trained knowledge can be obtained from base (seen) categories and can be well transferred to novel (unseen) categories. However, there is no guarantee, especially for the latter part. This issue leads to the unknown nature of the inference process in most FSL methods, which hampers its application in some risk-sensitive areas. In this paper, we reveal a new way to perform FSL for image classification, using visual representations from the backbone model and weights generated by a newly-emerged explainable classifier. The weighted representations only include a minimum number of distinguishable features and the visualized weights can serve as an informative hint for the FSL process. Finally, a discriminator will compare the representations of each pair of the images in the support set and the query set. Pairs with the highest scores will decide the classification results. Experimental results prove that the proposed method can achieve both good accuracy and satisfactory explainability on three mainstream datasets.
Practical Transferability Estimation for Image Classification Tasks
Jun 30, 2021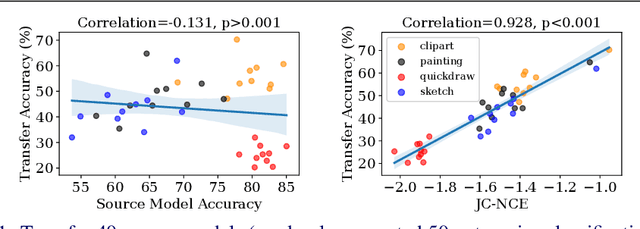
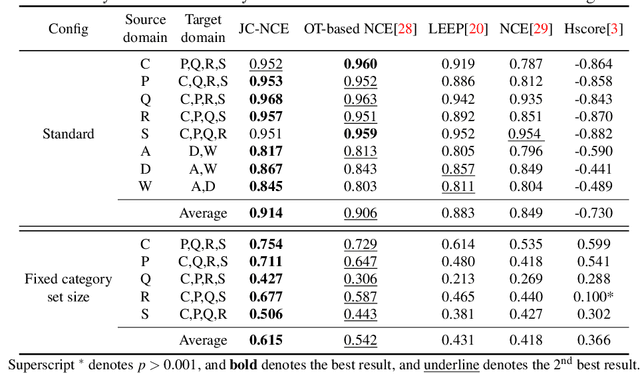
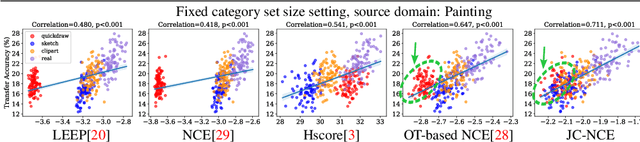
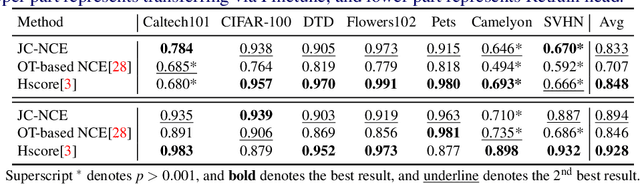
Transferability estimation is an essential problem in transfer learning to predict how good the performance is when transferring a source model (or source task) to a target task. Recent analytical transferability metrics have been widely used for source model selection and multi-task learning. A major challenge is how to make transfereability estimation robust under the cross-domain cross-task settings. The recently proposed OTCE score solves this problem by considering both domain and task differences, with the help of transfer experiences on auxiliary tasks, which causes an efficiency overhead. In this work, we propose a practical transferability metric called JC-NCE score that dramatically improves the robustness of the task difference estimation in OTCE, thus removing the need for auxiliary tasks. Specifically, we build the joint correspondences between source and target data via solving an optimal transport problem with a ground cost considering both the sample distance and label distance, and then compute the transferability score as the negative conditional entropy of the matched labels. Extensive validations under the intra-dataset and inter-dataset transfer settings demonstrate that our JC-NCE score outperforms the auxiliary-task free version of OTCE for 7% and 12%, respectively, and is also more robust than other existing transferability metrics on average.
Distilling Image Classifiers in Object Detectors
Jun 09, 2021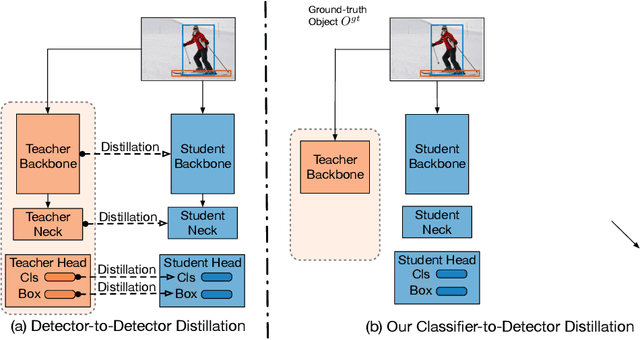
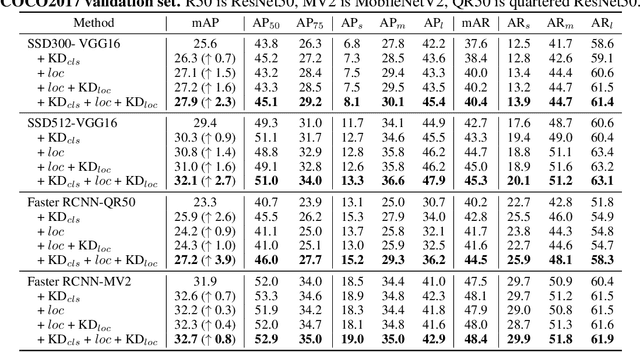
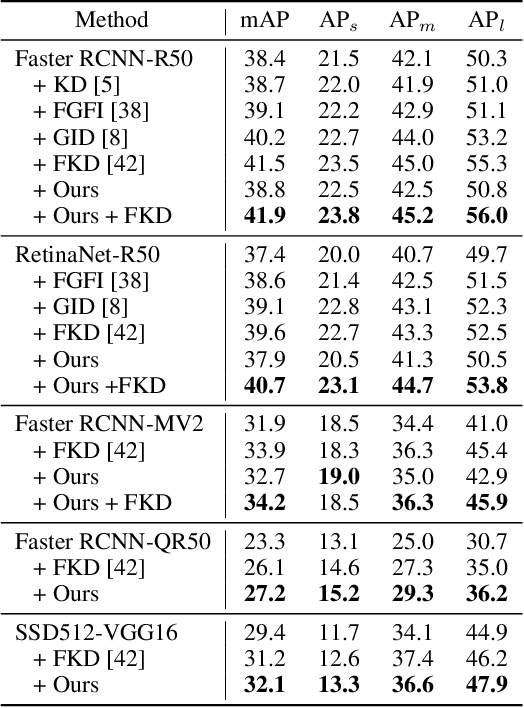

Knowledge distillation constitutes a simple yet effective way to improve the performance of a compact student network by exploiting the knowledge of a more powerful teacher. Nevertheless, the knowledge distillation literature remains limited to the scenario where the student and the teacher tackle the same task. Here, we investigate the problem of transferring knowledge not only across architectures but also across tasks. To this end, we study the case of object detection and, instead of following the standard detector-to-detector distillation approach, introduce a classifier-to-detector knowledge transfer framework. In particular, we propose strategies to exploit the classification teacher to improve both the detector's recognition accuracy and localization performance. Our experiments on several detectors with different backbones demonstrate the effectiveness of our approach, allowing us to outperform the state-of-the-art detector-to-detector distillation methods.
Image Colorization By Capsule Networks
Aug 22, 2019
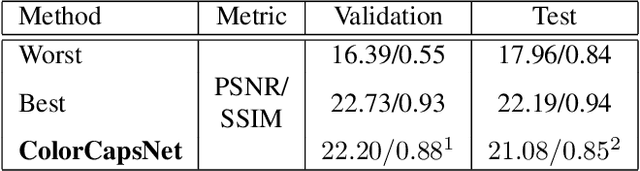
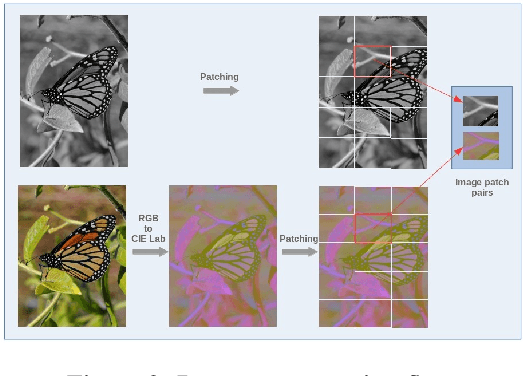
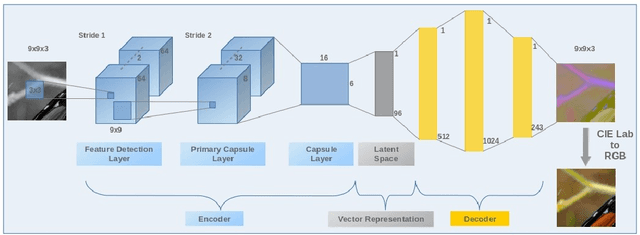
In this paper, a simple topology of Capsule Network (CapsNet) is investigated for the problem of image colorization. The generative and segmentation capabilities of the original CapsNet topology, which is proposed for image classification problem, is leveraged for the colorization of the images by modifying the network as follows:1) The original CapsNet model is adapted to map the grayscale input to the output in the CIE Lab colorspace, 2) The feature detector part of the model is updated by using deeper feature layers inherited from VGG-19 pre-trained model with weights in order to transfer low-level image representation capability to this model, 3) The margin loss function is modified as Mean Squared Error (MSE) loss to minimize the image-to-imagemapping. The resulting CapsNet model is named as Colorizer Capsule Network (ColorCapsNet).The performance of the ColorCapsNet is evaluated on the DIV2K dataset and promising results are obtained to investigate Capsule Networks further for image colorization problem.
Context-aware Padding for Semantic Segmentation
Sep 16, 2021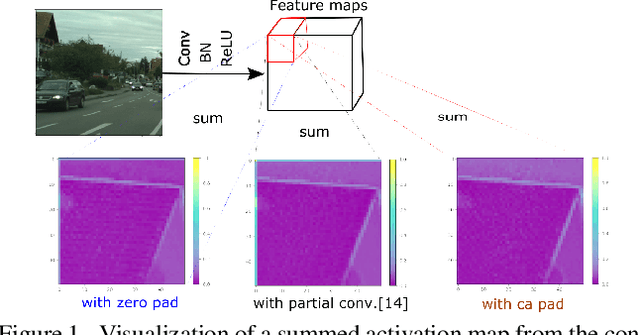

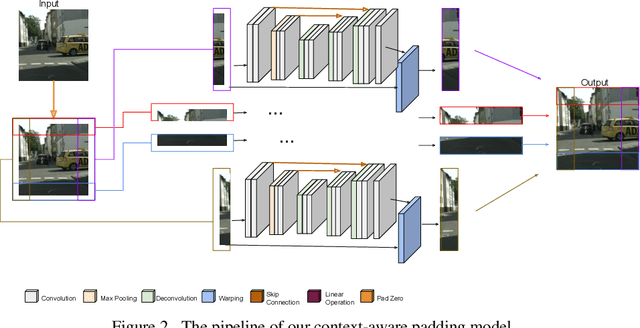

Zero padding is widely used in convolutional neural networks to prevent the size of feature maps diminishing too fast. However, it has been claimed to disturb the statistics at the border. As an alternative, we propose a context-aware (CA) padding approach to extend the image. We reformulate the padding problem as an image extrapolation problem and illustrate the effects on the semantic segmentation task. Using context-aware padding, the ResNet-based segmentation model achieves higher mean Intersection-Over-Union than the traditional zero padding on the Cityscapes and the dataset of DeepGlobe satellite imaging challenge. Furthermore, our padding does not bring noticeable overhead during training and testing.