 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Better Understanding Hierarchical Visual Relationship for Image Caption
Dec 04, 2019
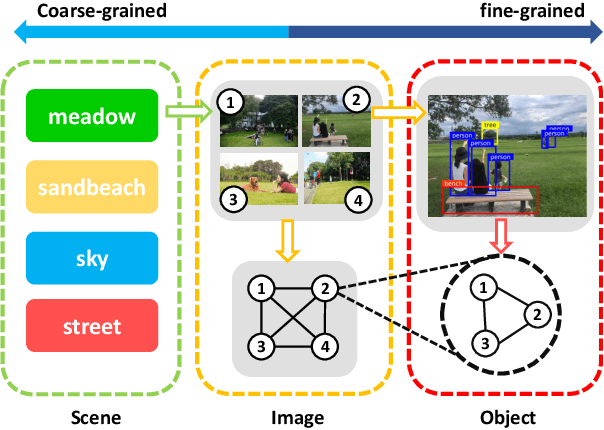
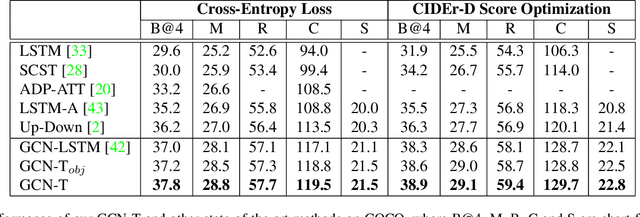

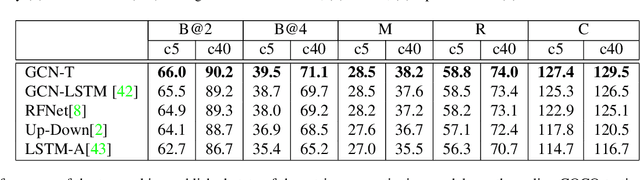
The Convolutional Neural Network (CNN) has been the dominant image feature extractor in computer vision for years. However, it fails to get the relationship between images/objects and their hierarchical interactions which can be helpful for representing and describing an image. In this paper, we propose a new design for image caption under a general encoder-decoder framework. It takes into account the hierarchical interactions between different abstraction levels of visual information in the images and their bounding-boxes. Specifically, we present CNN plus Graph Convolutional Network (GCN) architecture that novelly integrates both semantic and spatial visual relationships into image encoder. The representations of regions in an image and the connections between images are refined by leveraging graph structure through GCN. With the learned multi-level features, our model capitalizes on the Transformer-based decoder for description generation. We conduct experiments on the COCO image captioning dataset. Evaluations show that our proposed model outperforms the previous state-of-the-art models in the task of image caption, leading to a better performance in terms of all evaluation metrics.
CarveMix: A Simple Data Augmentation Method for Brain Lesion Segmentation
Aug 17, 2021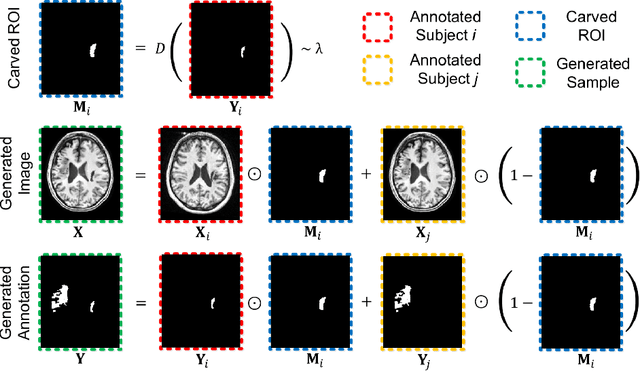

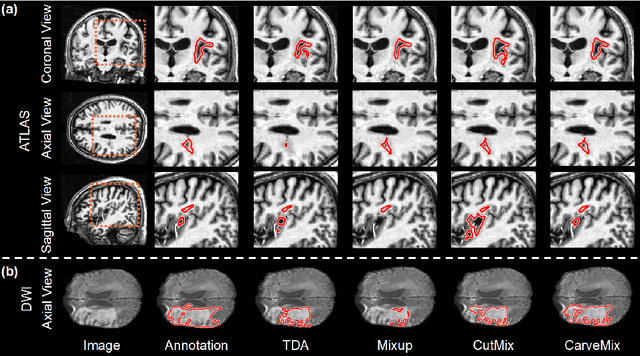
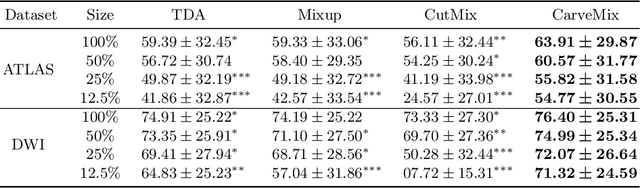
Brain lesion segmentation provides a valuable tool for clinical diagnosis, and convolutional neural networks (CNNs) have achieved unprecedented success in the task. Data augmentation is a widely used strategy that improves the training of CNNs, and the design of the augmentation method for brain lesion segmentation is still an open problem. In this work, we propose a simple data augmentation approach, dubbed as CarveMix, for CNN-based brain lesion segmentation. Like other "mix"-based methods, such as Mixup and CutMix, CarveMix stochastically combines two existing labeled images to generate new labeled samples. Yet, unlike these augmentation strategies based on image combination, CarveMix is lesion-aware, where the combination is performed with an attention on the lesions and a proper annotation is created for the generated image. Specifically, from one labeled image we carve a region of interest (ROI) according to the lesion location and geometry, and the size of the ROI is sampled from a probability distribution. The carved ROI then replaces the corresponding voxels in a second labeled image, and the annotation of the second image is replaced accordingly as well. In this way, we generate new labeled images for network training and the lesion information is preserved. To evaluate the proposed method, experiments were performed on two brain lesion datasets. The results show that our method improves the segmentation accuracy compared with other simple data augmentation approaches.
Region Normalization for Image Inpainting
Nov 23, 2019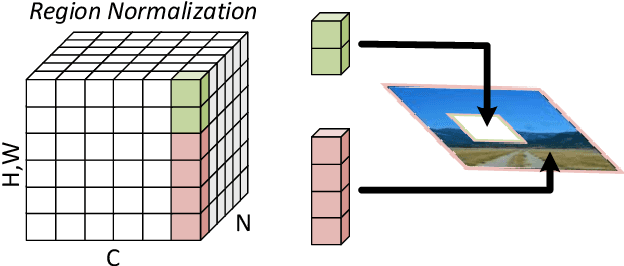
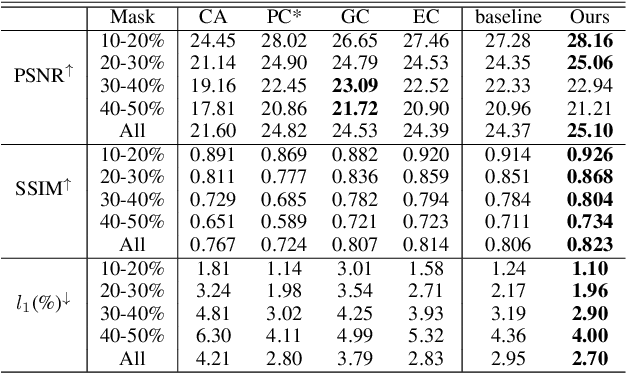
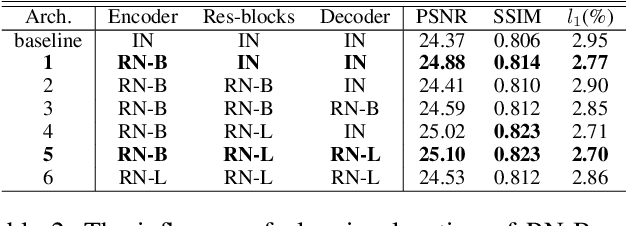
Feature Normalization (FN) is an important technique to help neural network training, which typically normalizes features across spatial dimensions. Most previous image inpainting methods apply FN in their networks without considering the impact of the corrupted regions of the input image on normalization, e.g. mean and variance shifts. In this work, we show that the mean and variance shifts caused by full-spatial FN limit the image inpainting network training and we propose a spatial region-wise normalization named Region Normalization (RN) to overcome the limitation. RN divides spatial pixels into different regions according to the input mask, and computes the mean and variance in each region for normalization. We develop two kinds of RN for our image inpainting network: (1) Basic RN (RN-B), which normalizes pixels from the corrupted and uncorrupted regions separately based on the original inpainting mask to solve the mean and variance shift problem; (2) Learnable RN (RN-L), which automatically detects potentially corrupted and uncorrupted regions for separate normalization, and performs global affine transformation to enhance their fusion. We apply RN-B in the early layers and RN-L in the latter layers of the network respectively. Experiments show that our method outperforms current state-of-the-art methods quantitatively and qualitatively. We further generalize RN to other inpainting networks and achieve consistent performance improvements.
Modal features for image texture classification
May 05, 2020
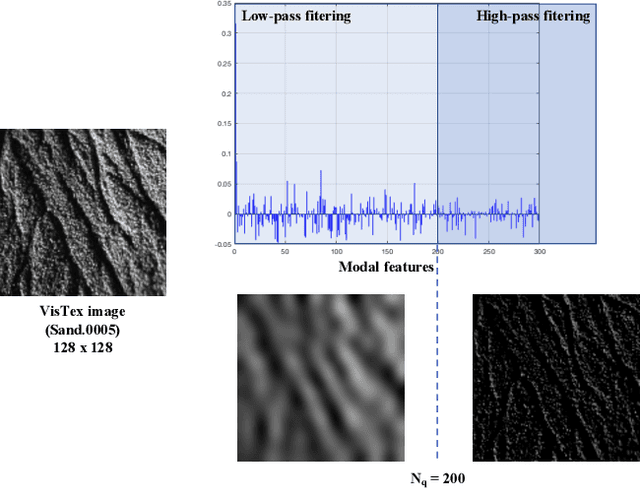
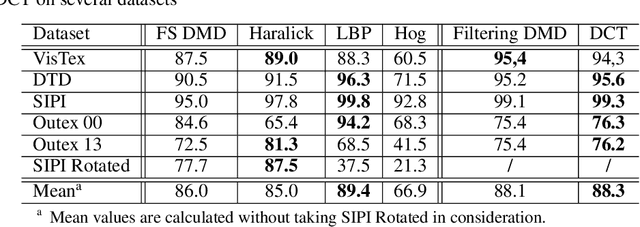

Feature extraction is a key step in image processing for pattern recognition and machine learning processes. Its purpose lies in reducing the dimensionality of the input data through the computing of features which accurately describe the original information. In this article, a new feature extraction method based on Discrete Modal Decomposition (DMD) is introduced, to extend the group of space and frequency based features. These new features are called modal features. Initially aiming to decompose a signal into a modal basis built from a vibration mechanics problem, the DMD projection is applied to images in order to extract modal features with two approaches. The first one, called full scale DMD, consists in exploiting directly the decomposition resulting coordinates as features. The second one, called filtering DMD, consists in using the DMD modes as filters to obtain features through a local transformation process. Experiments are performed on image texture classification tasks including several widely used data bases, compared to several classic feature extraction methods. We show that the DMD approach achieves good classification performances, comparable to the state of the art techniques, with a lower extraction time.
MonoLayout: Amodal scene layout from a single image
Feb 19, 2020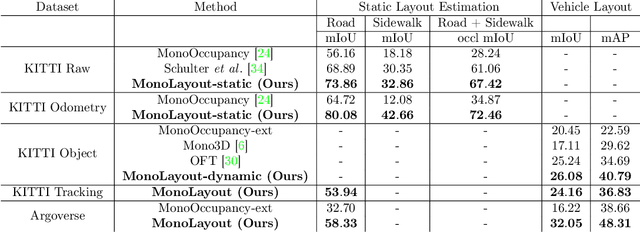
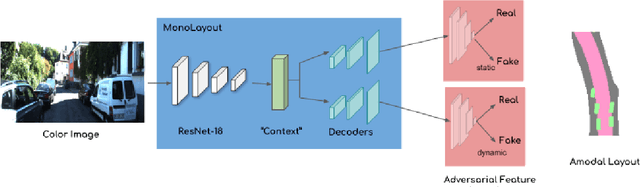
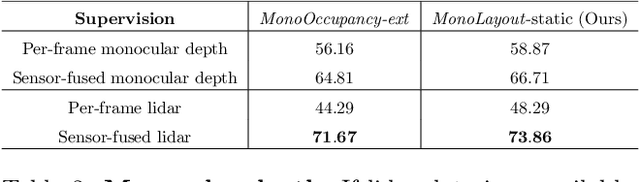
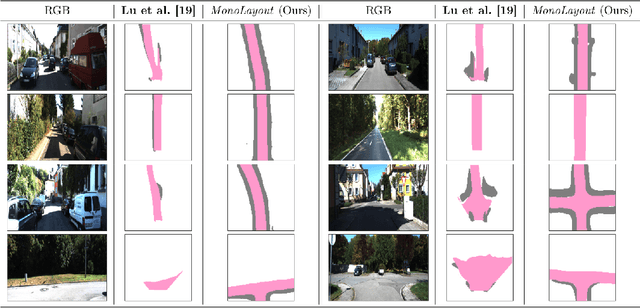
In this paper, we address the novel, highly challenging problem of estimating the layout of a complex urban driving scenario. Given a single color image captured from a driving platform, we aim to predict the bird's-eye view layout of the road and other traffic participants. The estimated layout should reason beyond what is visible in the image, and compensate for the loss of 3D information due to projection. We dub this problem amodal scene layout estimation, which involves "hallucinating" scene layout for even parts of the world that are occluded in the image. To this end, we present MonoLayout, a deep neural network for real-time amodal scene layout estimation from a single image. We represent scene layout as a multi-channel semantic occupancy grid, and leverage adversarial feature learning to hallucinate plausible completions for occluded image parts. Due to the lack of fair baseline methods, we extend several state-of-the-art approaches for road-layout estimation and vehicle occupancy estimation in bird's-eye view to the amodal setup for rigorous evaluation. By leveraging temporal sensor fusion to generate training labels, we significantly outperform current art over a number of datasets. On the KITTI and Argoverse datasets, we outperform all baselines by a significant margin. We also make all our annotations, and code publicly available. A video abstract of this paper is available https://www.youtube.com/watch?v=HcroGyo6yRQ .
Multimodal Incremental Transformer with Visual Grounding for Visual Dialogue Generation
Sep 17, 2021
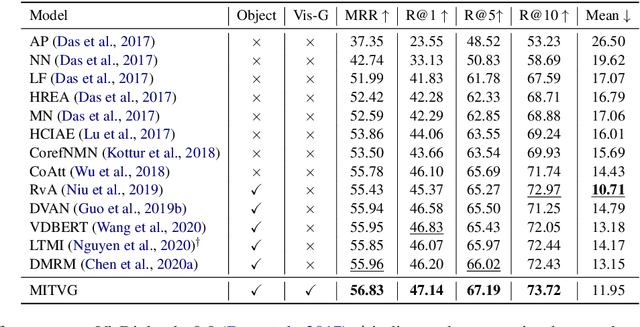
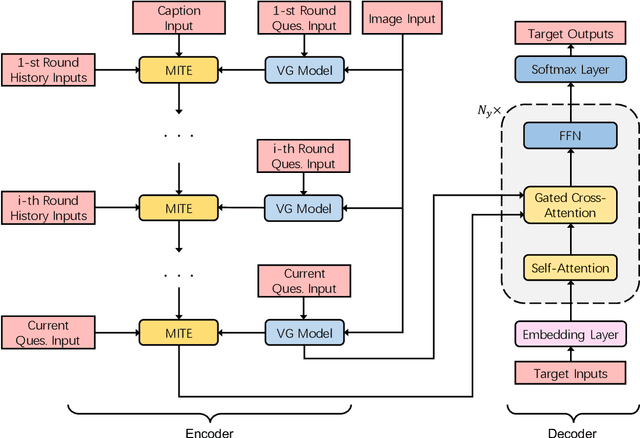
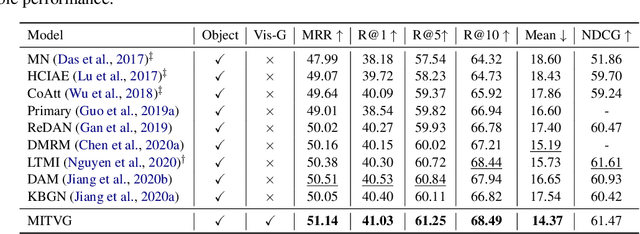
Visual dialogue is a challenging task since it needs to answer a series of coherent questions on the basis of understanding the visual environment. Previous studies focus on the implicit exploration of multimodal co-reference by implicitly attending to spatial image features or object-level image features but neglect the importance of locating the objects explicitly in the visual content, which is associated with entities in the textual content. Therefore, in this paper we propose a {\bf M}ultimodal {\bf I}ncremental {\bf T}ransformer with {\bf V}isual {\bf G}rounding, named MITVG, which consists of two key parts: visual grounding and multimodal incremental transformer. Visual grounding aims to explicitly locate related objects in the image guided by textual entities, which helps the model exclude the visual content that does not need attention. On the basis of visual grounding, the multimodal incremental transformer encodes the multi-turn dialogue history combined with visual scene step by step according to the order of the dialogue and then generates a contextually and visually coherent response. Experimental results on the VisDial v0.9 and v1.0 datasets demonstrate the superiority of the proposed model, which achieves comparable performance.
Image Colorization By Capsule Networks
Aug 22, 2019
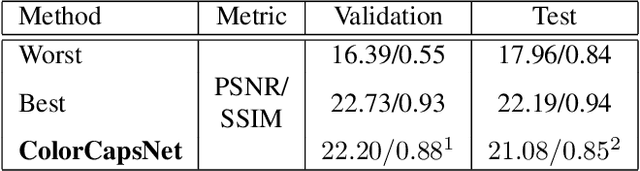
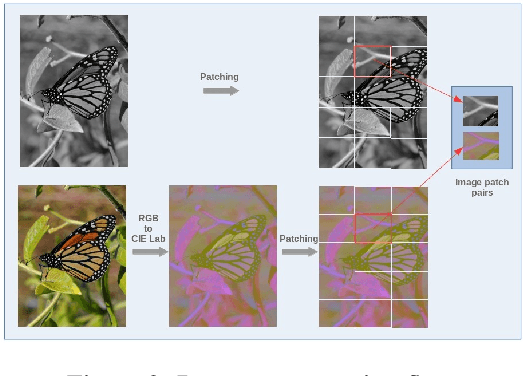
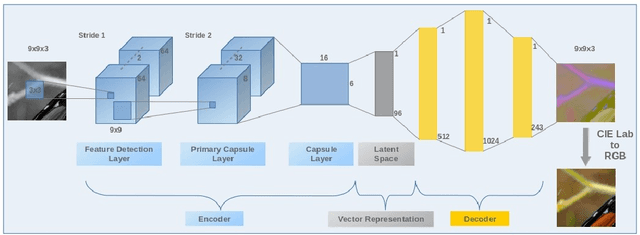
In this paper, a simple topology of Capsule Network (CapsNet) is investigated for the problem of image colorization. The generative and segmentation capabilities of the original CapsNet topology, which is proposed for image classification problem, is leveraged for the colorization of the images by modifying the network as follows:1) The original CapsNet model is adapted to map the grayscale input to the output in the CIE Lab colorspace, 2) The feature detector part of the model is updated by using deeper feature layers inherited from VGG-19 pre-trained model with weights in order to transfer low-level image representation capability to this model, 3) The margin loss function is modified as Mean Squared Error (MSE) loss to minimize the image-to-imagemapping. The resulting CapsNet model is named as Colorizer Capsule Network (ColorCapsNet).The performance of the ColorCapsNet is evaluated on the DIV2K dataset and promising results are obtained to investigate Capsule Networks further for image colorization problem.
Boosting segmentation with weak supervision from image-to-image translation
Apr 04, 2019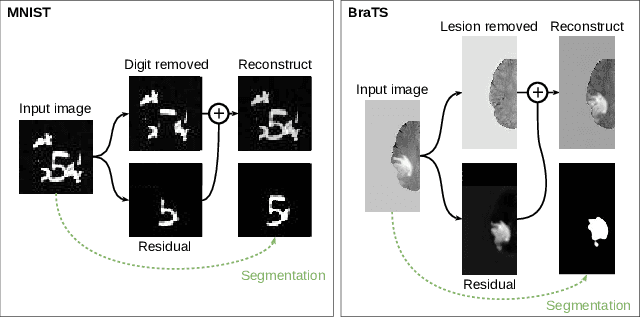

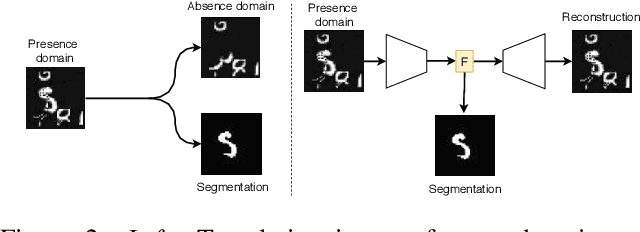
In many cases, especially with medical images, it is prohibitively challenging to produce a sufficiently large training sample of pixel-level annotations to train deep neural networks for semantic image segmentation. On the other hand, some information is often known about the contents of images. We leverage information on whether an image presents the segmentation target or whether it is absent from the image to improve segmentation performance by augmenting the amount of data usable for model training. Specifically, we propose a semi-supervised framework that employs image-to-image translation between weak labels (e.g., presence vs. absence of cancer), in addition to fully supervised segmentation on some examples. We conjecture that this translation objective is well aligned with the segmentation objective as both require the same disentangling of image variations. Building on prior image-to-image translation work, we re-use the encoder and decoders for translating in either direction between two domains, employing a strategy of selectively decoding domain-specific variations. For presence vs. absence domains, the encoder produces variations that are common to both and those unique to the presence domain. Furthermore, we successfully re-use one of the decoders used in translation for segmentation. We validate the proposed method on synthetic tasks of varying difficulty as well as on the real task of brain tumor segmentation in magnetic resonance images, where we show significant improvements over standard semi-supervised training with autoencoding.
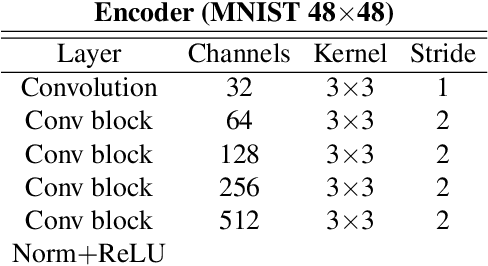
Variational autoencoders in the presence of low-dimensional data: landscape and implicit bias
Dec 13, 2021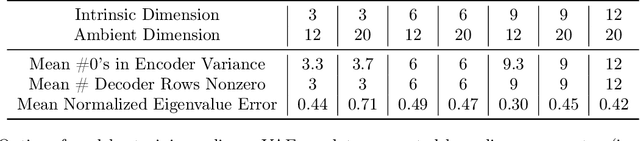
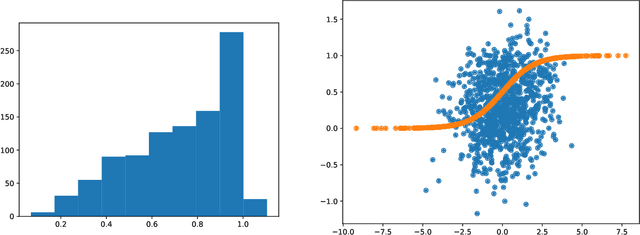
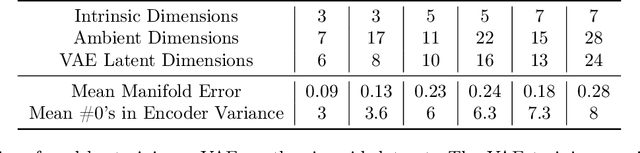

Variational Autoencoders (VAEs) are one of the most commonly used generative models, particularly for image data. A prominent difficulty in training VAEs is data that is supported on a lower dimensional manifold. Recent work by Dai and Wipf (2019) suggests that on low-dimensional data, the generator will converge to a solution with 0 variance which is correctly supported on the ground truth manifold. In this paper, via a combination of theoretical and empirical results, we show that the story is more subtle. Precisely, we show that for linear encoders/decoders, the story is mostly true and VAE training does recover a generator with support equal to the ground truth manifold, but this is due to the implicit bias of gradient descent rather than merely the VAE loss itself. In the nonlinear case, we show that the VAE training frequently learns a higher-dimensional manifold which is a superset of the ground truth manifold.
Generating Photo-realistic Images from LiDAR Point Clouds with Generative Adversarial Networks
Dec 20, 2021



We examined the feasibility of generative adversarial networks (GANs) to generate photo-realistic images from LiDAR point clouds. For this purpose, we created a dataset of point cloud image pairs and trained the GAN to predict photorealistic images from LiDAR point clouds containing reflectance and distance information. Our models learned how to predict realistically looking images from just point cloud data, even images with black cars. Black cars are difficult to detect directly from point clouds because of their low level of reflectivity. This approach might be used in the future to perform visual object recognition on photorealistic images generated from LiDAR point clouds. In addition to the conventional LiDAR system, a second system that generates photorealistic images from LiDAR point clouds would run simultaneously for visual object recognition in real-time. In this way, we might preserve the supremacy of LiDAR and benefit from using photo-realistic images for visual object recognition without the usage of any camera. In addition, this approach could be used to colorize point clouds without the usage of any camera images.