 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
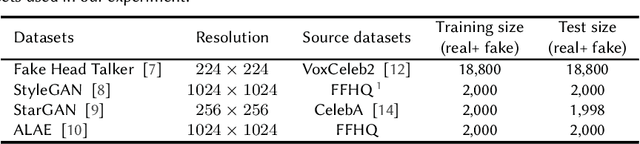
Source Feature Compression for Object Classification in Vision-Based Underwater Robotics
Dec 28, 2021
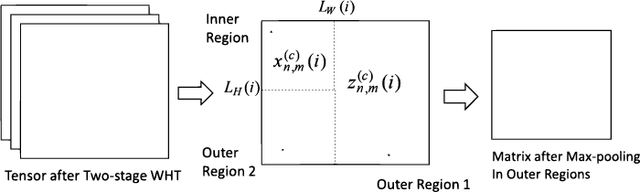
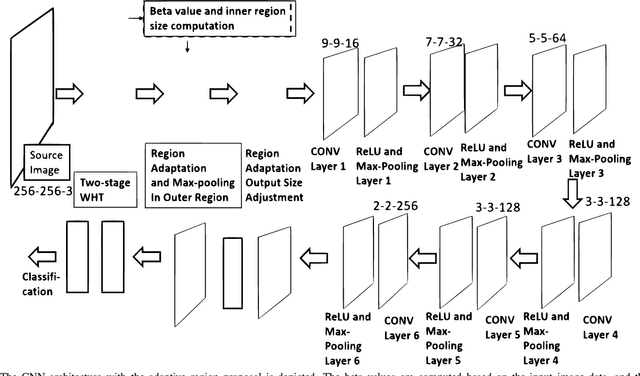

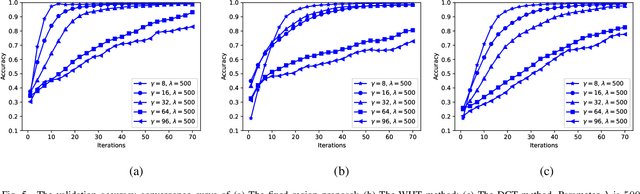
New efficient source feature compression solutions are proposed based on a two-stage Walsh-Hadamard Transform (WHT) for Convolutional Neural Network (CNN)-based object classification in underwater robotics. The object images are firstly transformed by WHT following a two-stage process. The transform-domain tensors have large values concentrated in the upper left corner of the matrices in the RGB channels. By observing this property, the transform-domain matrix is partitioned into inner and outer regions. Consequently, two novel partitioning methods are proposed in this work: (i) fixing the size of inner and outer regions; and (ii) adjusting the size of inner and outer regions adaptively per image. The proposals are evaluated with an underwater object dataset captured from the Raritan River in New Jersey, USA. It is demonstrated and verified that the proposals reduce the training time effectively for learning-based underwater object classification task and increase the accuracy compared with the competing methods. The object classification is an essential part of a vision-based underwater robot that can sense the environment and navigate autonomously. Therefore, the proposed method is well-suited for efficient computer vision-based tasks in underwater robotics applications.
Exploring the Asynchronous of the Frequency Spectra of GAN-generated Facial Images
Dec 15, 2021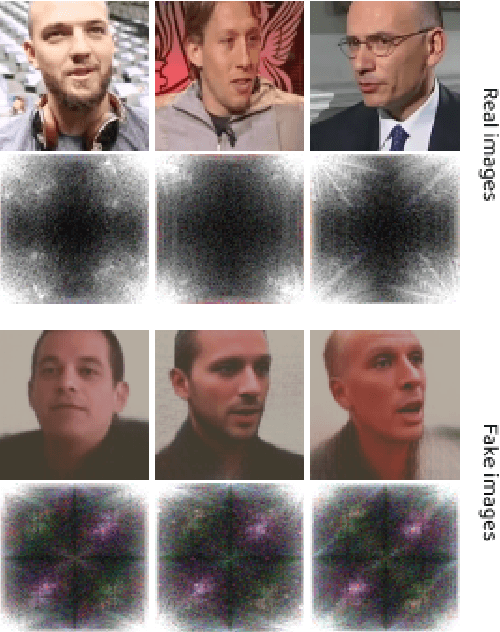
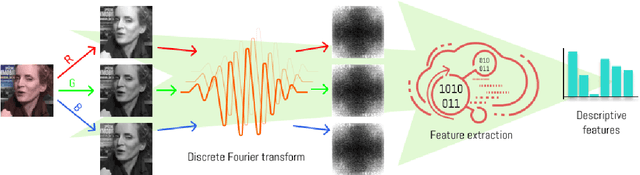

The rapid progression of Generative Adversarial Networks (GANs) has raised a concern of their misuse for malicious purposes, especially in creating fake face images. Although many proposed methods succeed in detecting GAN-based synthetic images, they are still limited by the need for large quantities of the training fake image dataset and challenges for the detector's generalizability to unknown facial images. In this paper, we propose a new approach that explores the asynchronous frequency spectra of color channels, which is simple but effective for training both unsupervised and supervised learning models to distinguish GAN-based synthetic images. We further investigate the transferability of a training model that learns from our suggested features in one source domain and validates on another target domains with prior knowledge of the features' distribution. Our experimental results show that the discrepancy of spectra in the frequency domain is a practical artifact to effectively detect various types of GAN-based generated images.
Exploring and Distilling Cross-Modal Information for Image Captioning
Mar 15, 2020
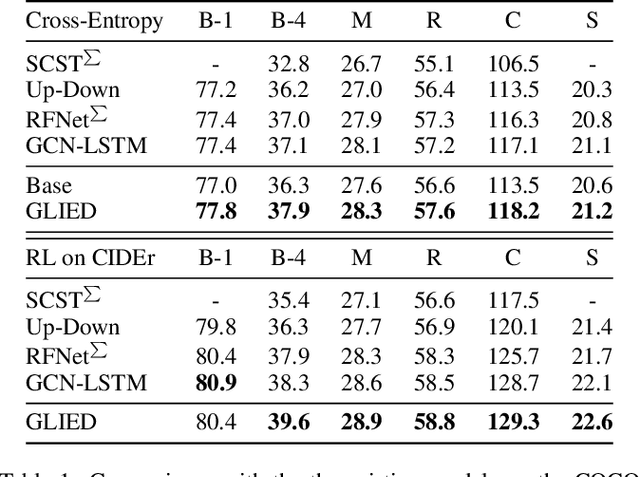
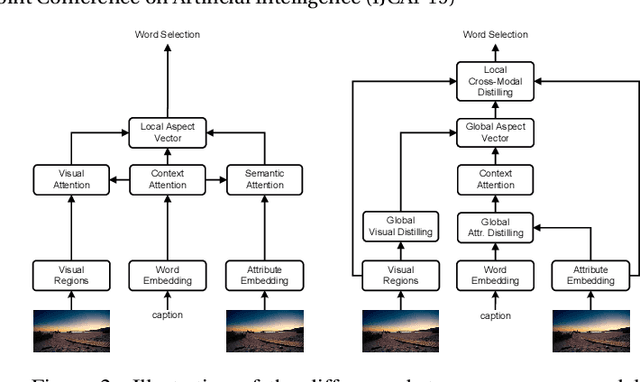
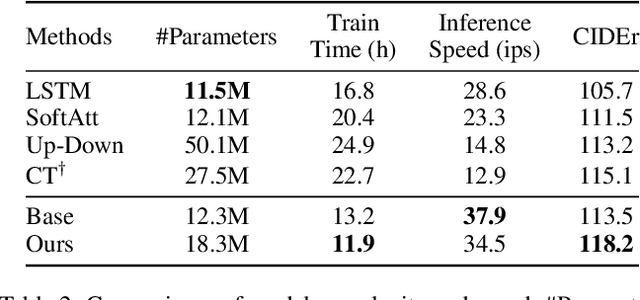
Recently, attention-based encoder-decoder models have been used extensively in image captioning. Yet there is still great difficulty for the current methods to achieve deep image understanding. In this work, we argue that such understanding requires visual attention to correlated image regions and semantic attention to coherent attributes of interest. Based on the Transformer, to perform effective attention, we explore image captioning from a cross-modal perspective and propose the Global-and-Local Information Exploring-and-Distilling approach that explores and distills the source information in vision and language. It globally provides the aspect vector, a spatial and relational representation of images based on caption contexts, through the extraction of salient region groupings and attribute collocations, and locally extracts the fine-grained regions and attributes in reference to the aspect vector for word selection. Our Transformer-based model achieves a CIDEr score of 129.3 in offline COCO evaluation on the COCO testing set with remarkable efficiency in terms of accuracy, speed, and parameter budget.
UniFormer: Unifying Convolution and Self-attention for Visual Recognition
Jan 24, 2022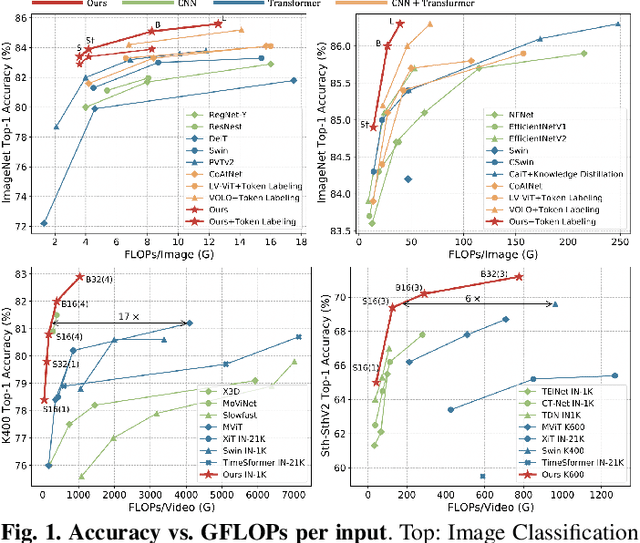
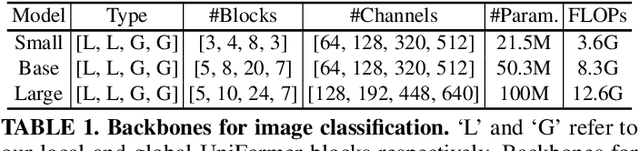

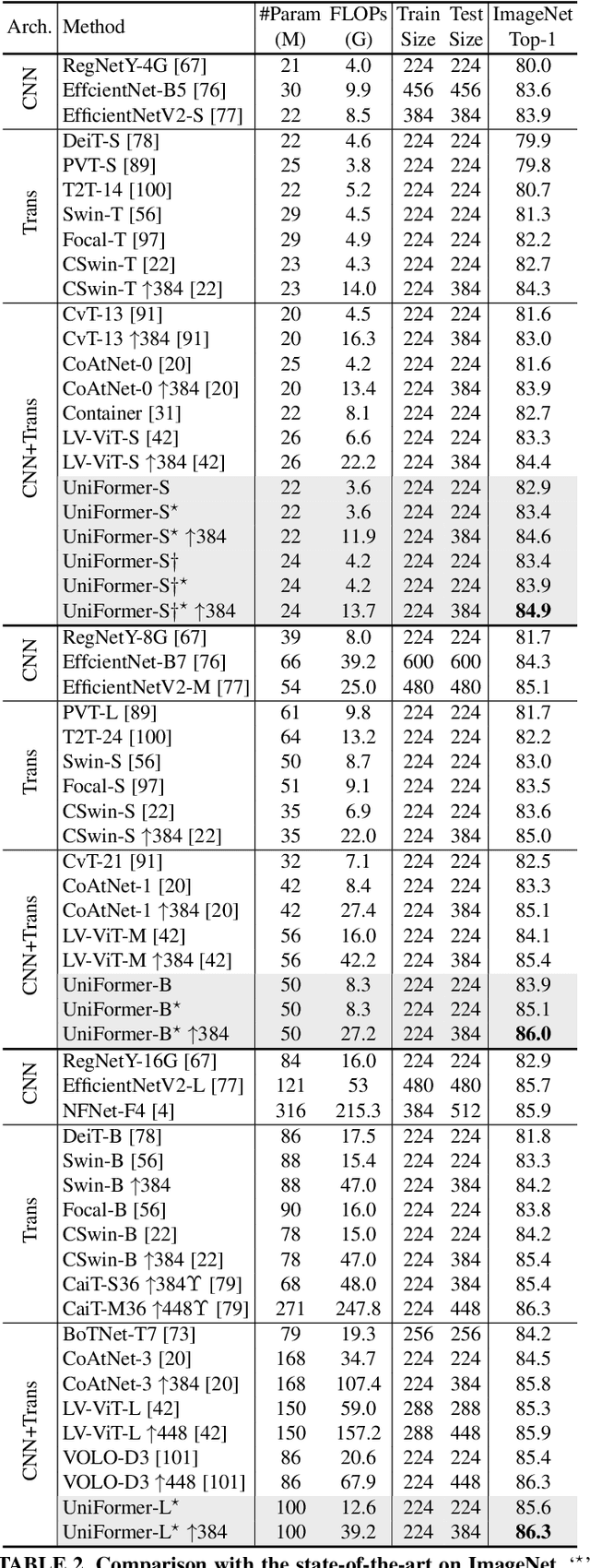
It is a challenging task to learn discriminative representation from images and videos, due to large local redundancy and complex global dependency in these visual data. Convolution neural networks (CNNs) and vision transformers (ViTs) have been two dominant frameworks in the past few years. Though CNNs can efficiently decrease local redundancy by convolution within a small neighborhood, the limited receptive field makes it hard to capture global dependency. Alternatively, ViTs can effectively capture long-range dependency via self-attention, while blind similarity comparisons among all the tokens lead to high redundancy. To resolve these problems, we propose a novel Unified transFormer (UniFormer), which can seamlessly integrate the merits of convolution and self-attention in a concise transformer format. Different from the typical transformer blocks, the relation aggregators in our UniFormer block are equipped with local and global token affinity respectively in shallow and deep layers, allowing to tackle both redundancy and dependency for efficient and effective representation learning. Finally, we flexibly stack our UniFormer blocks into a new powerful backbone, and adopt it for various vision tasks from image to video domain, from classification to dense prediction. Without any extra training data, our UniFormer achieves 86.3 top-1 accuracy on ImageNet-1K classification. With only ImageNet-1K pre-training, it can simply achieve state-of-the-art performance in a broad range of downstream tasks, e.g., it obtains 82.9/84.8 top-1 accuracy on Kinetics-400/600, 60.9/71.2 top-1 accuracy on Something-Something V1/V2 video classification tasks, 53.8 box AP and 46.4 mask AP on COCO object detection task, 50.8 mIoU on ADE20K semantic segmentation task, and 77.4 AP on COCO pose estimation task. Code is available at https://github.com/Sense-X/UniFormer.
Disentangled Image Matting
Sep 10, 2019
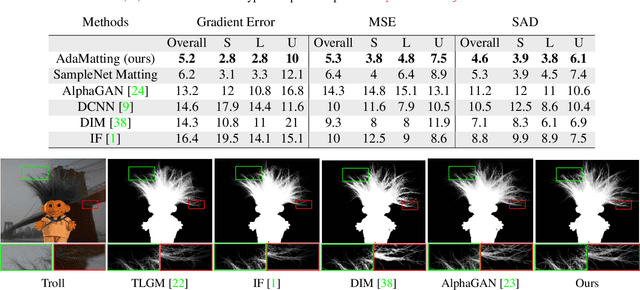
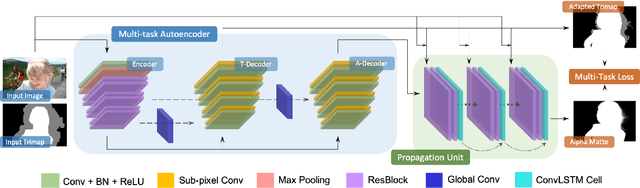
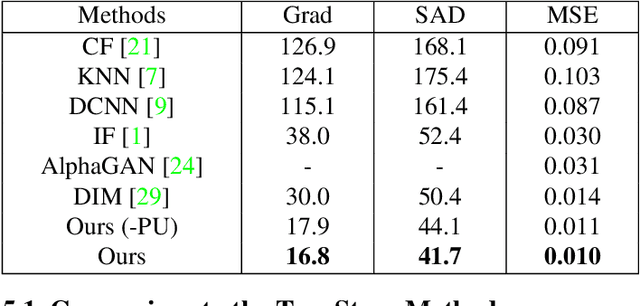
Most previous image matting methods require a roughly-specificed trimap as input, and estimate fractional alpha values for all pixels that are in the unknown region of the trimap. In this paper, we argue that directly estimating the alpha matte from a coarse trimap is a major limitation of previous methods, as this practice tries to address two difficult and inherently different problems at the same time: identifying true blending pixels inside the trimap region, and estimate accurate alpha values for them. We propose AdaMatting, a new end-to-end matting framework that disentangles this problem into two sub-tasks: trimap adaptation and alpha estimation. Trimap adaptation is a pixel-wise classification problem that infers the global structure of the input image by identifying definite foreground, background, and semi-transparent image regions. Alpha estimation is a regression problem that calculates the opacity value of each blended pixel. Our method separately handles these two sub-tasks within a single deep convolutional neural network (CNN). Extensive experiments show that AdaMatting has additional structure awareness and trimap fault-tolerance. Our method achieves the state-of-the-art performance on Adobe Composition-1k dataset both qualitatively and quantitatively. It is also the current best-performing method on the alphamatting.com online evaluation for all commonly-used metrics.
Deep Reinforcement Learning with Label Embedding Reward for Supervised Image Hashing
Aug 10, 2020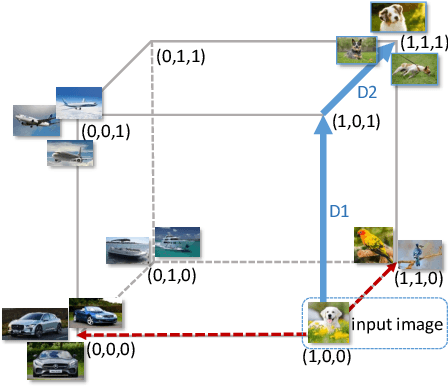
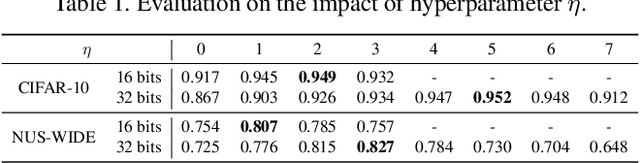
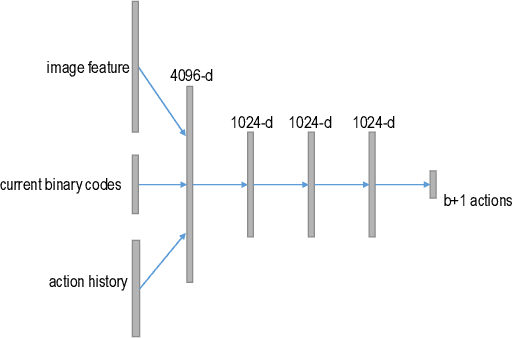
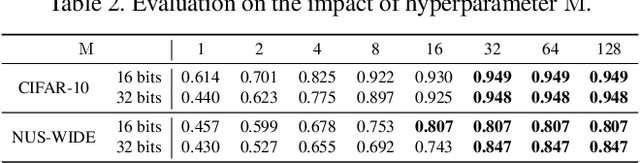
Deep hashing has shown promising results in image retrieval and recognition. Despite its success, most existing deep hashing approaches are rather similar: either multi-layer perceptron or CNN is applied to extract image feature, followed by different binarization activation functions such as sigmoid, tanh or autoencoder to generate binary code. In this work, we introduce a novel decision-making approach for deep supervised hashing. We formulate the hashing problem as travelling across the vertices in the binary code space, and learn a deep Q-network with a novel label embedding reward defined by Bose-Chaudhuri-Hocquenghem (BCH) codes to explore the best path. Extensive experiments and analysis on the CIFAR-10 and NUS-WIDE dataset show that our approach outperforms state-of-the-art supervised hashing methods under various code lengths.
MRI Reconstruction Using Deep Energy-Based Model
Sep 09, 2021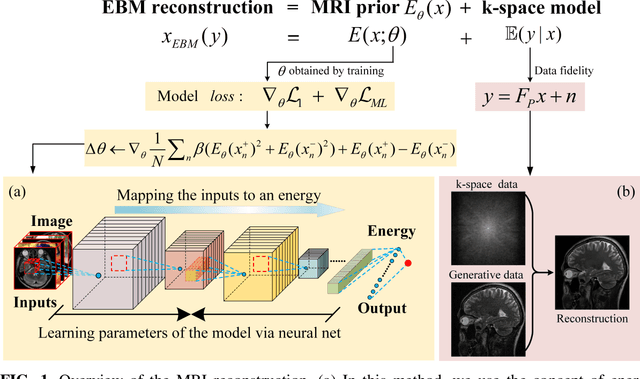
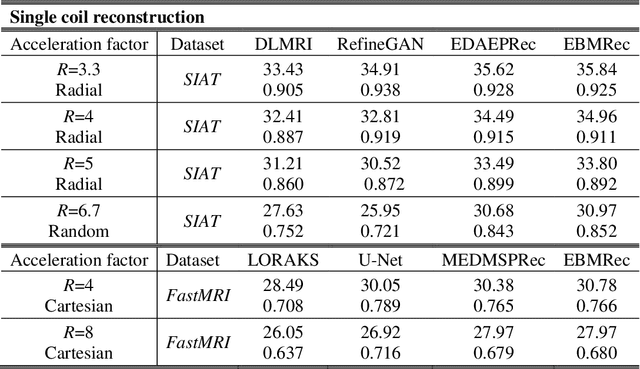
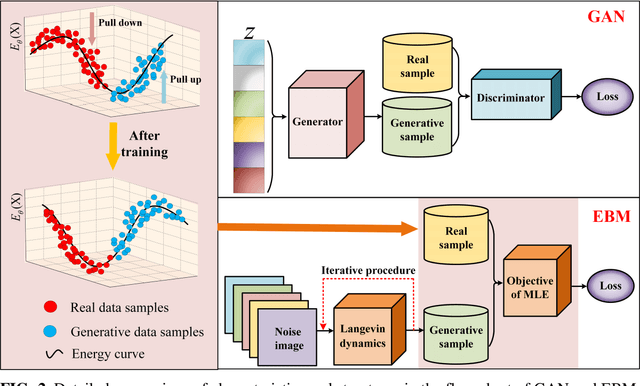
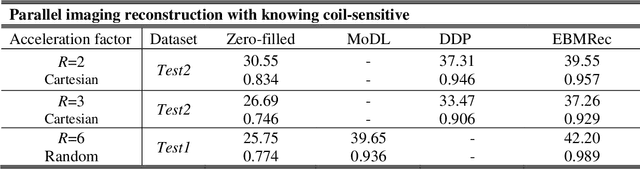
Purpose: Although recent deep energy-based generative models (EBMs) have shown encouraging results in many image generation tasks, how to take advantage of the self-adversarial cogitation in deep EBMs to boost the performance of Magnetic Resonance Imaging (MRI) reconstruction is still desired. Methods: With the successful application of deep learning in a wide range of MRI reconstruction, a line of emerging research involves formulating an optimization-based reconstruction method in the space of a generative model. Leveraging this, a novel regularization strategy is introduced in this article which takes advantage of self-adversarial cogitation of the deep energy-based model. More precisely, we advocate for alternative learning a more powerful energy-based model with maximum likelihood estimation to obtain the deep energy-based information, represented as image prior. Simultaneously, implicit inference with Langevin dynamics is a unique property of re-construction. In contrast to other generative models for reconstruction, the proposed method utilizes deep energy-based information as the image prior in reconstruction to improve the quality of image. Results: Experiment results that imply the proposed technique can obtain remarkable performance in terms of high reconstruction accuracy that is competitive with state-of-the-art methods, and does not suffer from mode collapse. Conclusion: Algorithmically, an iterative approach was presented to strengthen EBM training with the gradient of energy network. The robustness and the reproducibility of the algorithm were also experimentally validated. More importantly, the proposed reconstruction framework can be generalized for most MRI reconstruction scenarios.
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Sep 17, 2019
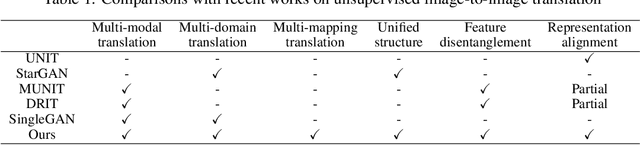

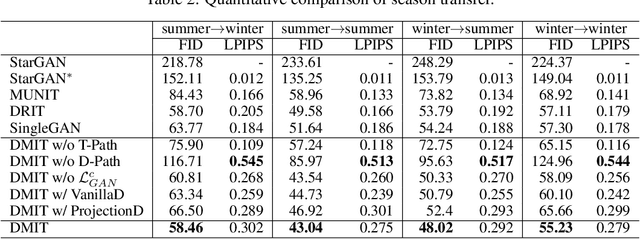
Recent advances of image-to-image translation focus on learning the one-to-many mapping from two aspects: multi-modal translation and multi-domain translation. However, the existing methods only consider one of the two perspectives, which makes them unable to solve each other's problem. To address this issue, we propose a novel unified model, which bridges these two objectives. First, we disentangle the input images into the latent representations by an encoder-decoder architecture with a conditional adversarial training in the feature space. Then, we encourage the generator to learn multi-mappings by a random cross-domain translation. As a result, we can manipulate different parts of the latent representations to perform multi-modal and multi-domain translations simultaneously. Experiments demonstrate that our method outperforms state-of-the-art methods.
Autoencoder-based background reconstruction and foreground segmentation with background noise estimation
Dec 15, 2021

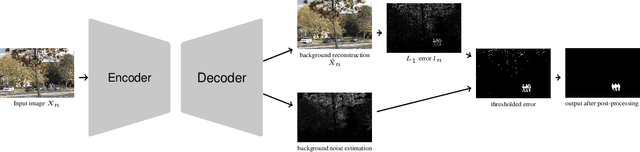
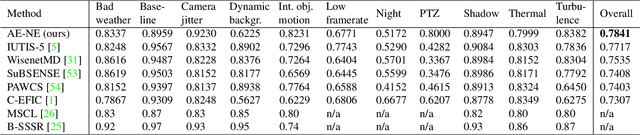
Even after decades of research, dynamic scene background reconstruction and foreground object segmentation are still considered as open problems due various challenges such as illumination changes, camera movements, or background noise caused by air turbulence or moving trees. We propose in this paper to model the background of a video sequence as a low dimensional manifold using an autoencoder and to compare the reconstructed background provided by this autoencoder with the original image to compute the foreground/background segmentation masks. The main novelty of the proposed model is that the autoencoder is also trained to predict the background noise, which allows to compute for each frame a pixel-dependent threshold to perform the background/foreground segmentation. Although the proposed model does not use any temporal or motion information, it exceeds the state of the art for unsupervised background subtraction on the CDnet 2014 and LASIESTA datasets, with a significant improvement on videos where the camera is moving.
Efficient Geometry-aware 3D Generative Adversarial Networks
Dec 15, 2021
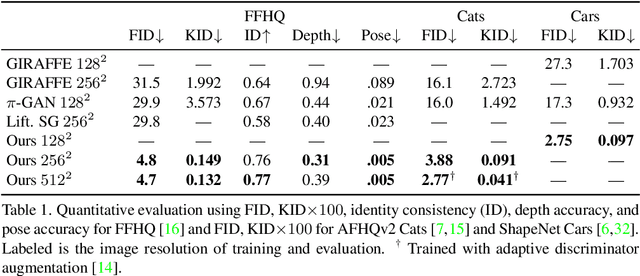
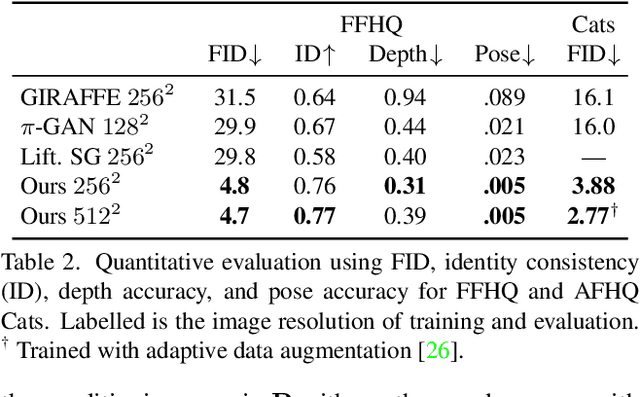
Unsupervised generation of high-quality multi-view-consistent images and 3D shapes using only collections of single-view 2D photographs has been a long-standing challenge. Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; the former limits quality and resolution of the generated images and the latter adversely affects multi-view consistency and shape quality. In this work, we improve the computational efficiency and image quality of 3D GANs without overly relying on these approximations. For this purpose, we introduce an expressive hybrid explicit-implicit network architecture that, together with other design choices, synthesizes not only high-resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling feature generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressiveness. We demonstrate state-of-the-art 3D-aware synthesis with FFHQ and AFHQ Cats, among other experiments.