 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Damage Estimation and Localization from Sparse Aerial Imagery
Nov 05, 2021
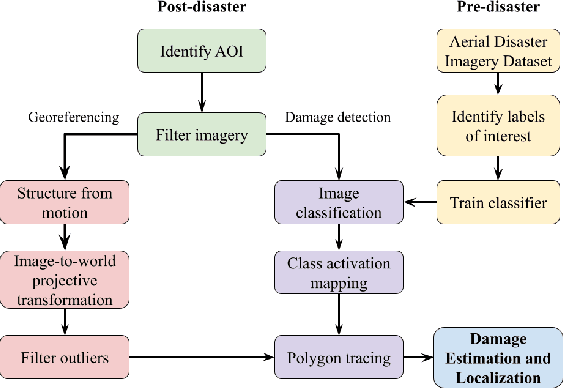

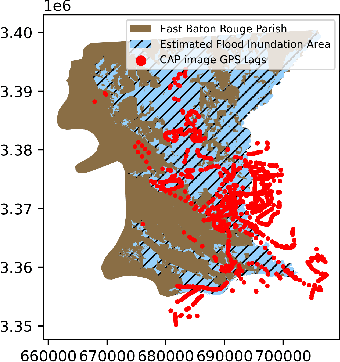
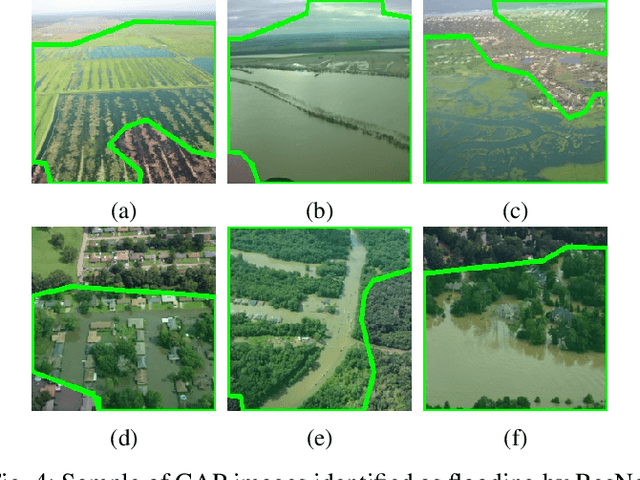
Aerial images provide important situational awareness for responding to natural disasters such as hurricanes. They are well-suited for providing information for damage estimation and localization (DEL); i.e., characterizing the type and spatial extent of damage following a disaster. Despite recent advances in sensing and unmanned aerial systems technology, much of post-disaster aerial imagery is still taken by handheld DSLR cameras from small, manned, fixed-wing aircraft. However, these handheld cameras lack IMU information, and images are taken opportunistically post-event by operators. As such, DEL from such imagery is still a highly manual and time-consuming process. We propose an approach to both detect damage in aerial images and localize it in world coordinates, with specific focus on detecting and localizing flooding. The approach is based on using structure from motion to relate image coordinates to world coordinates via a projective transformation, using class activation mapping to detect the extent of damage in an image, and applying the projective transformation to localize damage in world coordinates. We evaluate the performance of our approach on post-event data from the 2016 Louisiana floods, and find that our approach achieves a precision of 88%. Given this high precision using limited data, we argue that this approach is currently viable for fast and effective DEL from handheld aerial imagery for disaster response.
Hyperspectral Image Super-resolution via Deep Spatio-spectral Convolutional Neural Networks
May 29, 2020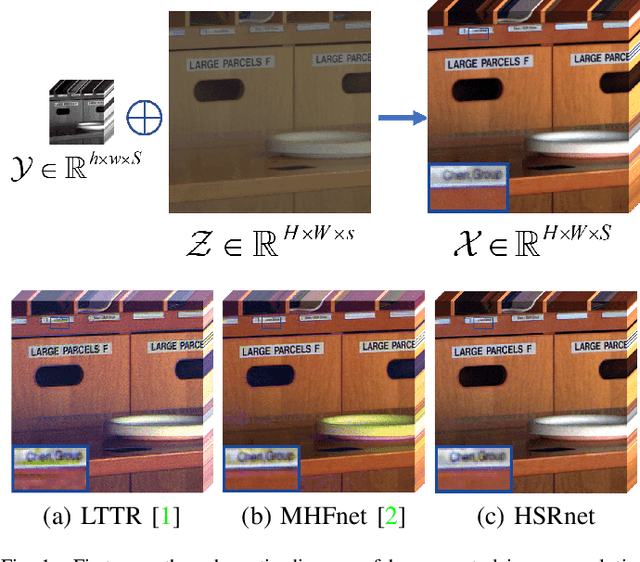

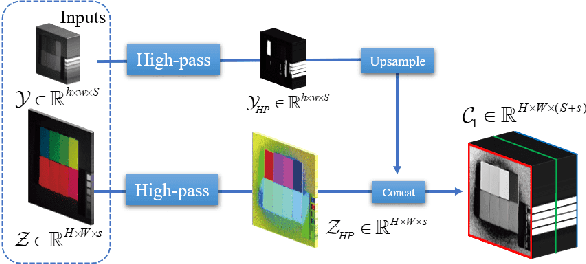
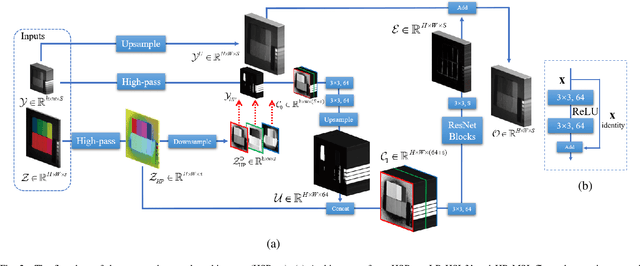
Hyperspectral images are of crucial importance in order to better understand features of different materials. To reach this goal, they leverage on a high number of spectral bands. However, this interesting characteristic is often paid by a reduced spatial resolution compared with traditional multispectral image systems. In order to alleviate this issue, in this work, we propose a simple and efficient architecture for deep convolutional neural networks to fuse a low-resolution hyperspectral image (LR-HSI) and a high-resolution multispectral image (HR-MSI), yielding a high-resolution hyperspectral image (HR-HSI). The network is designed to preserve both spatial and spectral information thanks to an architecture from two folds: one is to utilize the HR-HSI at a different scale to get an output with a satisfied spectral preservation; another one is to apply concepts of multi-resolution analysis to extract high-frequency information, aiming to output high quality spatial details. Finally, a plain mean squared error loss function is used to measure the performance during the training. Extensive experiments demonstrate that the proposed network architecture achieves best performance (both qualitatively and quantitatively) compared with recent state-of-the-art hyperspectral image super-resolution approaches. Moreover, other significant advantages can be pointed out by the use of the proposed approach, such as, a better network generalization ability, a limited computational burden, and a robustness with respect to the number of training samples.
Graph Convolutional Networks for Hyperspectral Image Classification
Aug 06, 2020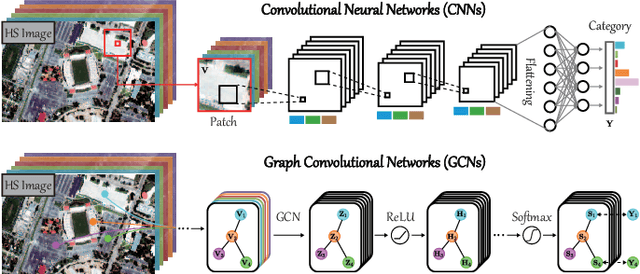
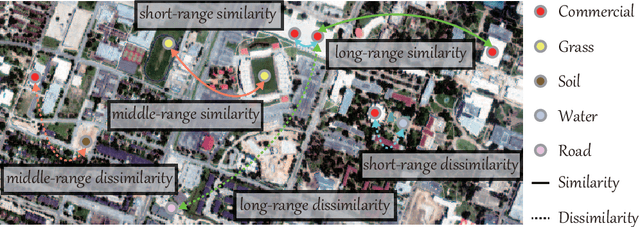
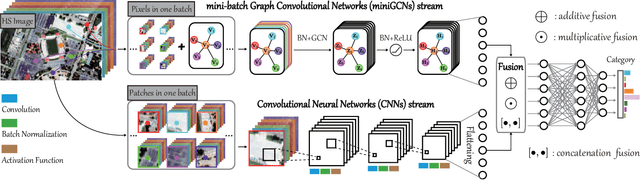
Convolutional neural networks (CNNs) have been attracting increasing attention in hyperspectral (HS) image classification, owing to their ability to capture spatial-spectral feature representations. Nevertheless, their ability in modeling relations between samples remains limited. Beyond the limitations of grid sampling, graph convolutional networks (GCNs) have been recently proposed and successfully applied in irregular (or non-grid) data representation and analysis. In this paper, we thoroughly investigate CNNs and GCNs (qualitatively and quantitatively) in terms of HS image classification. Due to the construction of the adjacency matrix on all the data, traditional GCNs usually suffer from a huge computational cost, particularly in large-scale remote sensing (RS) problems. To this end, we develop a new mini-batch GCN (called miniGCN hereinafter) which allows to train large-scale GCNs in a mini-batch fashion. More significantly, our miniGCN is capable of inferring out-of-sample data without re-training networks and improving classification performance. Furthermore, as CNNs and GCNs can extract different types of HS features, an intuitive solution to break the performance bottleneck of a single model is to fuse them. Since miniGCNs can perform batch-wise network training (enabling the combination of CNNs and GCNs) we explore three fusion strategies: additive fusion, element-wise multiplicative fusion, and concatenation fusion to measure the obtained performance gain. Extensive experiments, conducted on three HS datasets, demonstrate the advantages of miniGCNs over GCNs and the superiority of the tested fusion strategies with regards to the single CNN or GCN models. The codes of this work will be available at https://github.com/danfenghong/IEEE_TGRS_GCN for the sake of reproducibility.
A Novel Global Spatial Attention Mechanism in Convolutional Neural Network for Medical Image Classification
Jul 31, 2020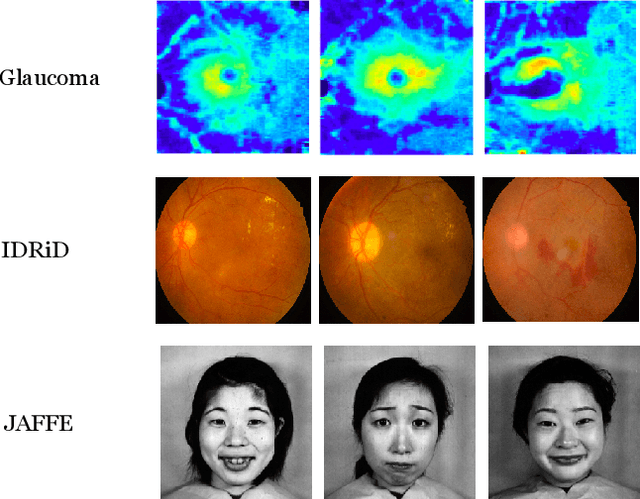

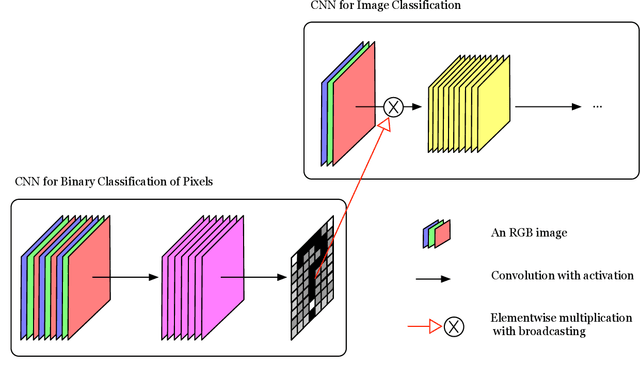
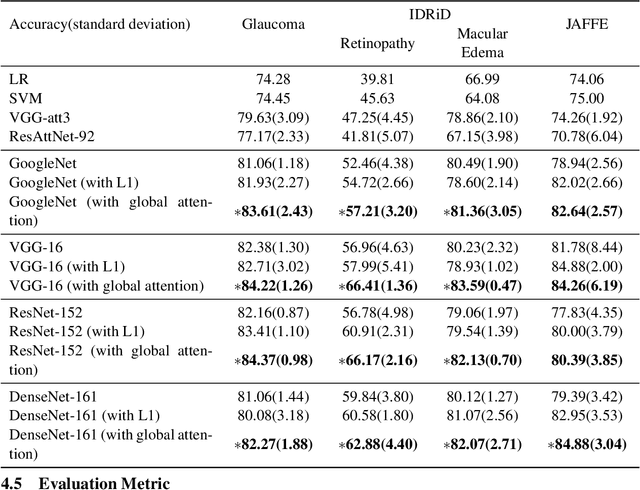
Spatial attention has been introduced to convolutional neural networks (CNNs) for improving both their performance and interpretability in visual tasks including image classification. The essence of the spatial attention is to learn a weight map which represents the relative importance of activations within the same layer or channel. All existing attention mechanisms are local attentions in the sense that weight maps are image-specific. However, in the medical field, there are cases that all the images should share the same weight map because the set of images record the same kind of symptom related to the same object and thereby share the same structural content. In this paper, we thus propose a novel global spatial attention mechanism in CNNs mainly for medical image classification. The global weight map is instantiated by a decision boundary between important pixels and unimportant pixels. And we propose to realize the decision boundary by a binary classifier in which the intensities of all images at a pixel are the features of the pixel. The binary classification is integrated into an image classification CNN and is to be optimized together with the CNN. Experiments on two medical image datasets and one facial expression dataset showed that with the proposed attention, not only the performance of four powerful CNNs which are GoogleNet, VGG, ResNet, and DenseNet can be improved, but also meaningful attended regions can be obtained, which is beneficial for understanding the content of images of a domain.
Image-driven discriminative and generative machine learning algorithms for establishing microstructure-processing relationships
Jul 27, 2020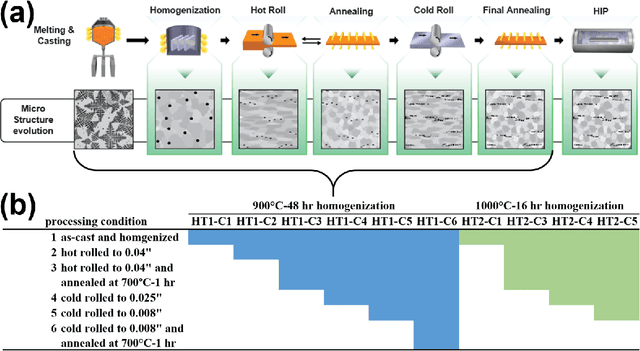

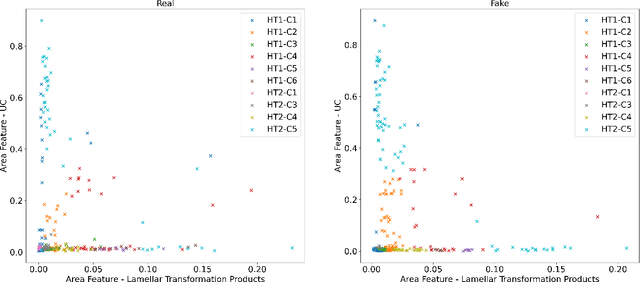
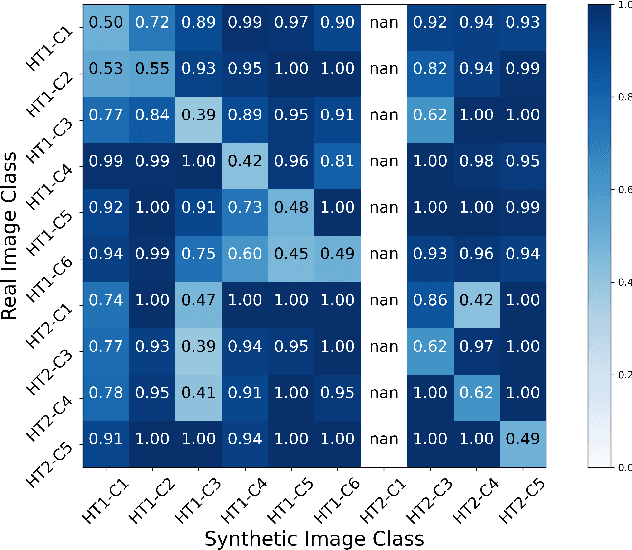
We investigate methods of microstructure representation for the purpose of predicting processing condition from microstructure image data. A binary alloy (uranium-molybdenum) that is currently under development as a nuclear fuel was studied for the purpose of developing an improved machine learning approach to image recognition, characterization, and building predictive capabilities linking microstructure to processing conditions. Here, we test different microstructure representations and evaluate model performance based on the F1 score. A F1 score of 95.1% was achieved for distinguishing between micrographs corresponding to ten different thermo-mechanical material processing conditions. We find that our newly developed microstructure representation describes image data well, and the traditional approach of utilizing area fractions of different phases is insufficient for distinguishing between multiple classes using a relatively small, imbalanced original data set of 272 images. To explore the applicability of generative methods for supplementing such limited data sets, generative adversarial networks were trained to generate artificial microstructure images. Two different generative networks were trained and tested to assess performance. Challenges and best practices associated with applying machine learning to limited microstructure image data sets is also discussed. Our work has implications for quantitative microstructure analysis, and development of microstructure-processing relationships in limited data sets typical of metallurgical process design studies.
MRI Reconstruction Using Deep Energy-Based Model
Sep 09, 2021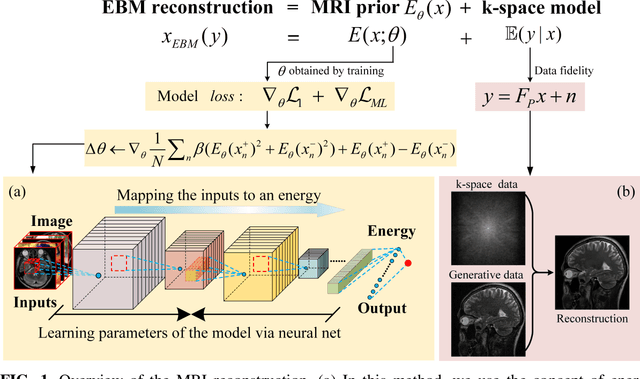
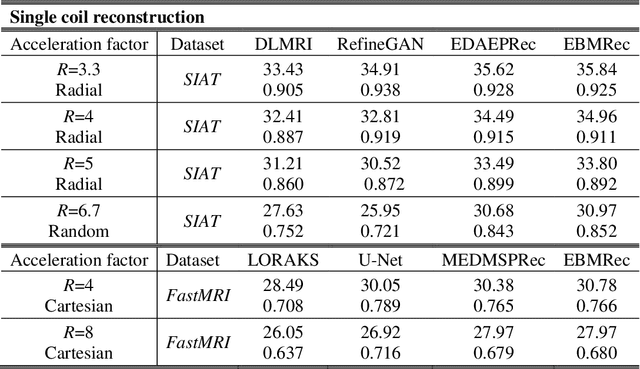
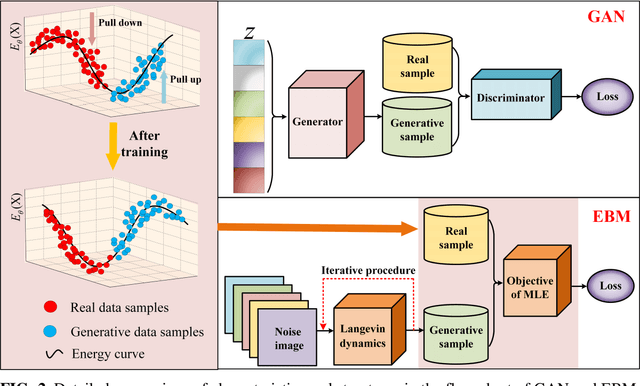
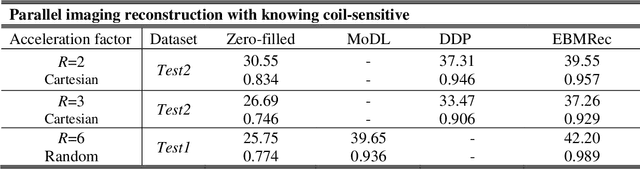
Purpose: Although recent deep energy-based generative models (EBMs) have shown encouraging results in many image generation tasks, how to take advantage of the self-adversarial cogitation in deep EBMs to boost the performance of Magnetic Resonance Imaging (MRI) reconstruction is still desired. Methods: With the successful application of deep learning in a wide range of MRI reconstruction, a line of emerging research involves formulating an optimization-based reconstruction method in the space of a generative model. Leveraging this, a novel regularization strategy is introduced in this article which takes advantage of self-adversarial cogitation of the deep energy-based model. More precisely, we advocate for alternative learning a more powerful energy-based model with maximum likelihood estimation to obtain the deep energy-based information, represented as image prior. Simultaneously, implicit inference with Langevin dynamics is a unique property of re-construction. In contrast to other generative models for reconstruction, the proposed method utilizes deep energy-based information as the image prior in reconstruction to improve the quality of image. Results: Experiment results that imply the proposed technique can obtain remarkable performance in terms of high reconstruction accuracy that is competitive with state-of-the-art methods, and does not suffer from mode collapse. Conclusion: Algorithmically, an iterative approach was presented to strengthen EBM training with the gradient of energy network. The robustness and the reproducibility of the algorithm were also experimentally validated. More importantly, the proposed reconstruction framework can be generalized for most MRI reconstruction scenarios.
You Can't See the Forest for Its Trees: Assessing Deep Neural Network Testing via NeuraL Coverage
Dec 03, 2021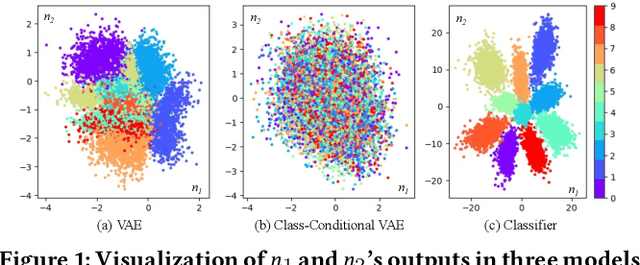
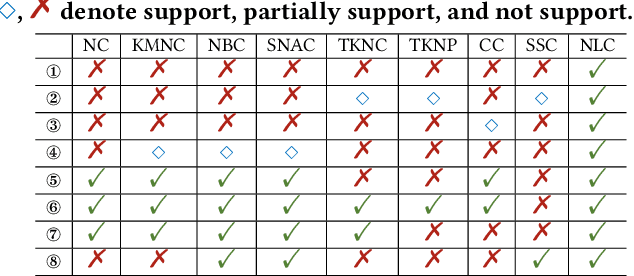

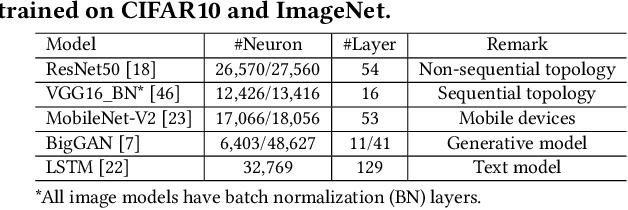
This paper summarizes eight design requirements for DNN testing criteria, taking into account distribution properties and practical concerns. We then propose a new criterion, NLC, that satisfies all of these design requirements. NLC treats a single DNN layer as the basic computational unit (rather than a single neuron) and captures four critical features of neuron output distributions. Thus, NLC is denoted as NeuraL Coverage, which more accurately describes how neural networks comprehend inputs via approximated distributions rather than neurons. We demonstrate that NLC is significantly correlated with the diversity of a test suite across a number of tasks (classification and generation) and data formats (image and text). Its capacity to discover DNN prediction errors is promising. Test input mutation guided by NLC result in a greater quality and diversity of exposed erroneous behaviors.
Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation
Oct 23, 2019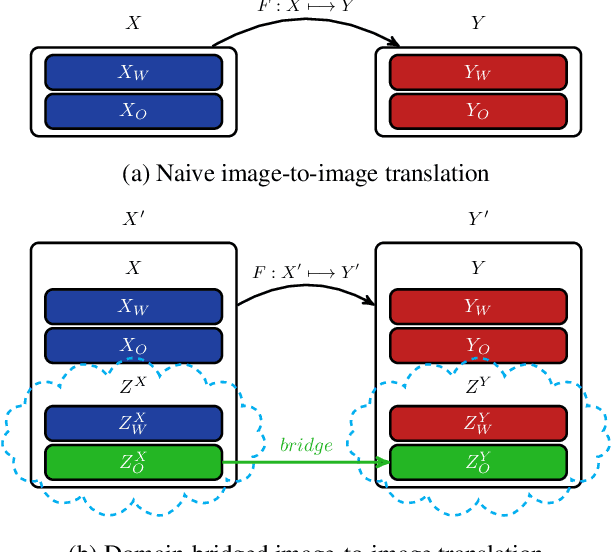
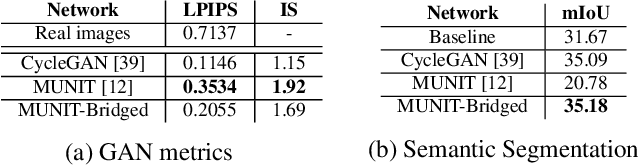
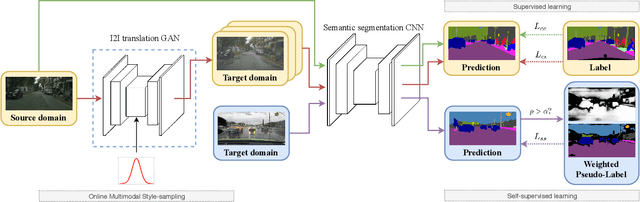

Image-to-image translation architectures may have limited effectiveness in some circumstances. For example, while generating rainy scenarios, they may fail to model typical traits of rain as water drops, and this ultimately impacts the synthetic images realism. With our method, called domain bridge, web-crawled data are exploited to reduce the domain gap, leading to the inclusion of previously ignored elements in the generated images. We make use of a network for clear to rain translation trained with the domain bridge to extend our work to Unsupervised Domain Adaptation (UDA). In that context, we introduce an online multimodal style-sampling strategy, where image translation multimodality is exploited at training time to improve performances. Finally, a novel approach for self-supervised learning is presented, and used to further align the domains. With our contributions, we simultaneously increase the realism of the generated images, while reaching on par performances w.r.t. the UDA state-of-the-art, with a simpler approach.
Channel-Level Variable Quantization Network for Deep Image Compression
Jul 15, 2020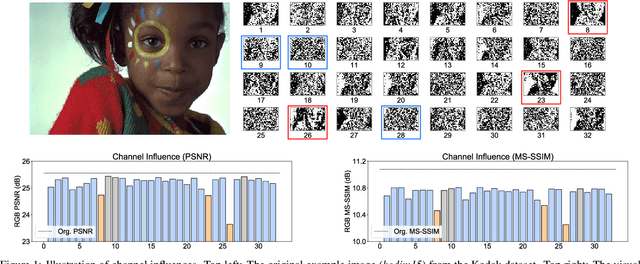
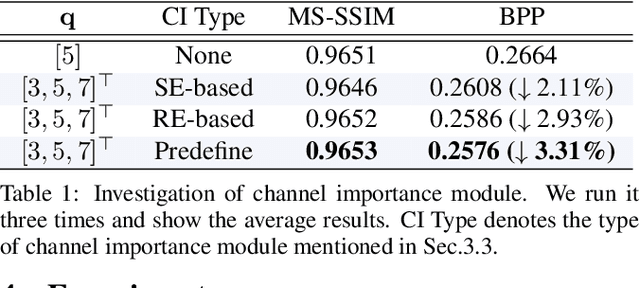
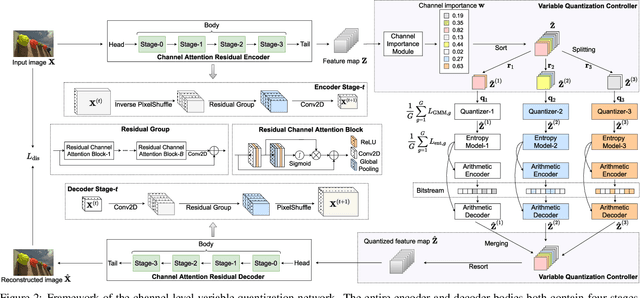
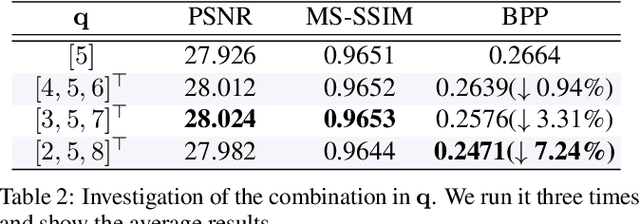
Deep image compression systems mainly contain four components: encoder, quantizer, entropy model, and decoder. To optimize these four components, a joint rate-distortion framework was proposed, and many deep neural network-based methods achieved great success in image compression. However, almost all convolutional neural network-based methods treat channel-wise feature maps equally, reducing the flexibility in handling different types of information. In this paper, we propose a channel-level variable quantization network to dynamically allocate more bitrates for significant channels and withdraw bitrates for negligible channels. Specifically, we propose a variable quantization controller. It consists of two key components: the channel importance module, which can dynamically learn the importance of channels during training, and the splitting-merging module, which can allocate different bitrates for different channels. We also formulate the quantizer into a Gaussian mixture model manner. Quantitative and qualitative experiments verify the effectiveness of the proposed model and demonstrate that our method achieves superior performance and can produce much better visual reconstructions.
Towards Scalable Unpaired Virtual Try-On via Patch-Routed Spatially-Adaptive GAN
Nov 20, 2021
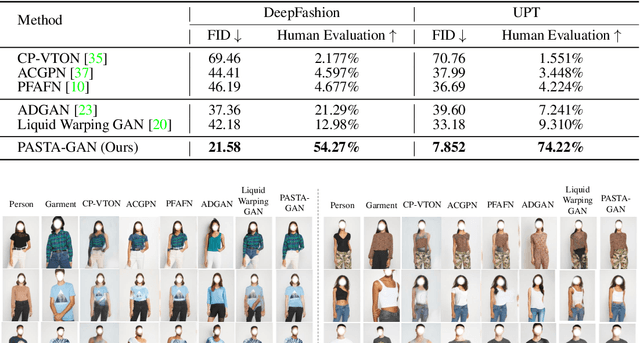
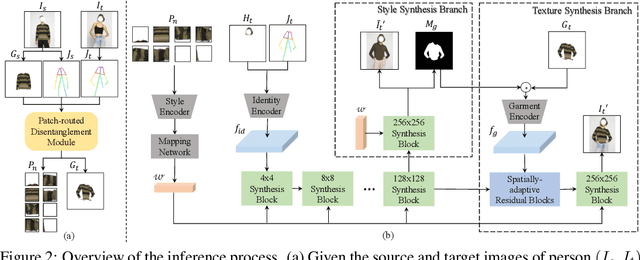

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. Yet, as most try-on approaches fit in-shop garments onto a target person, they require the laborious and restrictive construction of a paired training dataset, severely limiting their scalability. While a few recent works attempt to transfer garments directly from one person to another, alleviating the need to collect paired datasets, their performance is impacted by the lack of paired (supervised) information. In particular, disentangling style and spatial information of the garment becomes a challenge, which existing methods either address by requiring auxiliary data or extensive online optimization procedures, thereby still inhibiting their scalability. To achieve a \emph{scalable} virtual try-on system that can transfer arbitrary garments between a source and a target person in an unsupervised manner, we thus propose a texture-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN (PASTA-GAN), that facilitates real-world unpaired virtual try-on. Specifically, to disentangle the style and spatial information of each garment, PASTA-GAN consists of an innovative patch-routed disentanglement module for successfully retaining garment texture and shape characteristics. Guided by the source person keypoints, the patch-routed disentanglement module first decouples garments into normalized patches, thus eliminating the inherent spatial information of the garment, and then reconstructs the normalized patches to the warped garment complying with the target person pose. Given the warped garment, PASTA-GAN further introduces novel spatially-adaptive residual blocks that guide the generator to synthesize more realistic garment details.