 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modal features for image texture classification
May 05, 2020

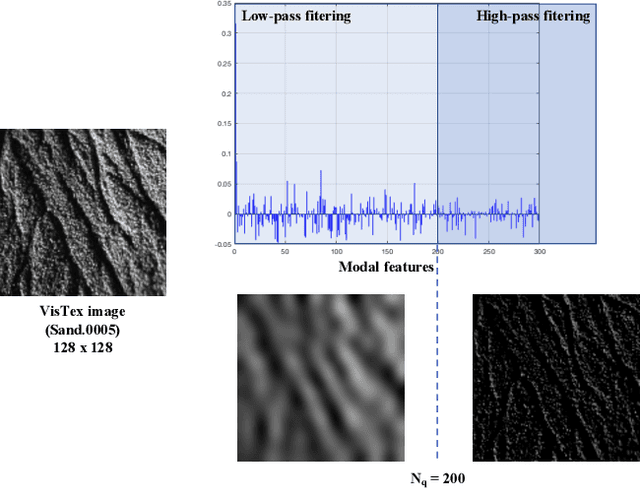
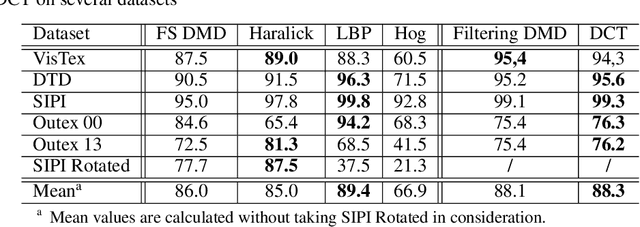

Feature extraction is a key step in image processing for pattern recognition and machine learning processes. Its purpose lies in reducing the dimensionality of the input data through the computing of features which accurately describe the original information. In this article, a new feature extraction method based on Discrete Modal Decomposition (DMD) is introduced, to extend the group of space and frequency based features. These new features are called modal features. Initially aiming to decompose a signal into a modal basis built from a vibration mechanics problem, the DMD projection is applied to images in order to extract modal features with two approaches. The first one, called full scale DMD, consists in exploiting directly the decomposition resulting coordinates as features. The second one, called filtering DMD, consists in using the DMD modes as filters to obtain features through a local transformation process. Experiments are performed on image texture classification tasks including several widely used data bases, compared to several classic feature extraction methods. We show that the DMD approach achieves good classification performances, comparable to the state of the art techniques, with a lower extraction time.
Through-Foliage Tracking with Airborne Optical Sectioning
Nov 12, 2021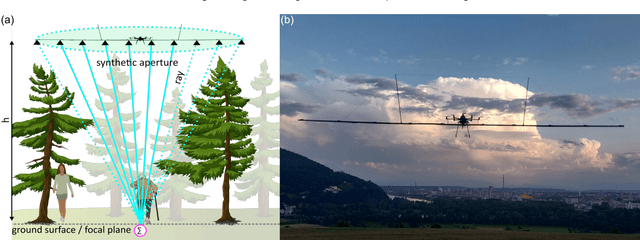
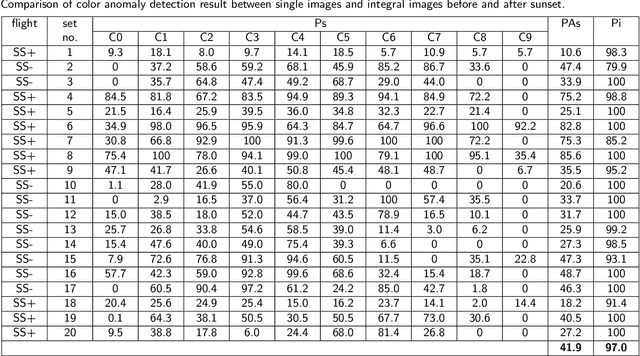
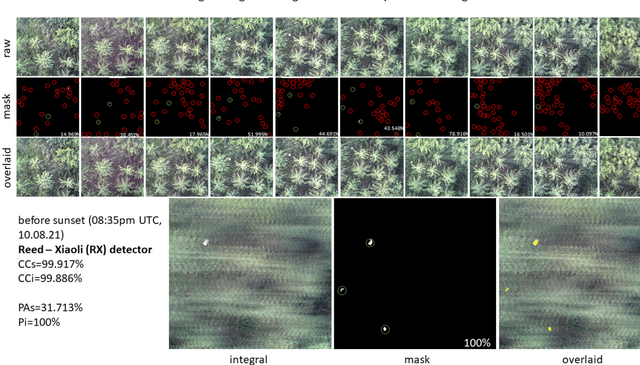
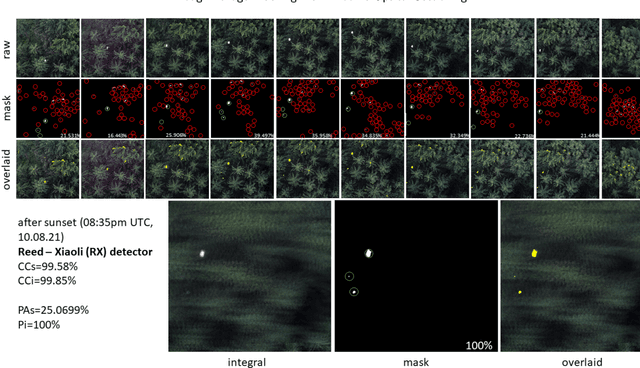
Detecting and tracking moving targets through foliage is difficult, and for many cases even impossible in regular aerial images and videos. We present an initial light-weight and drone-operated 1D camera array that supports parallel synthetic aperture aerial imaging. Our main finding is that color anomaly detection benefits significantly from image integration when compared to conventional single images or video frames (on average 97% vs. 42% in precision in our field experiments). We demonstrate, that these two contributions can lead to the detection and tracking of moving people through densely occluding forest
A Novel BiLevel Paradigm for Image-to-Image Translation
Apr 18, 2019
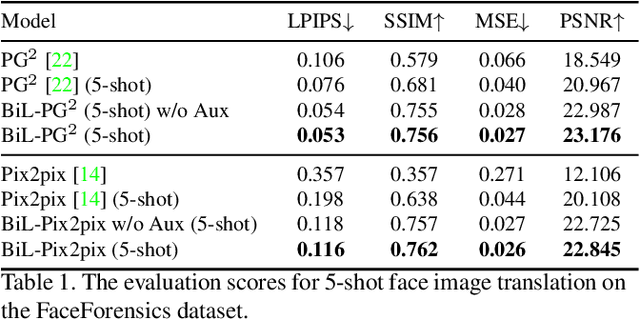
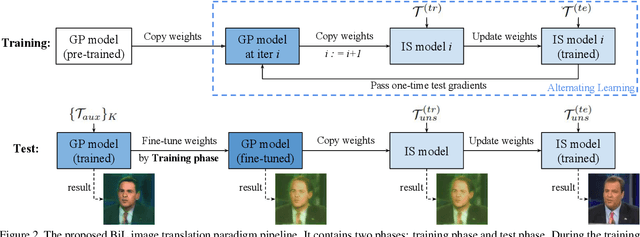
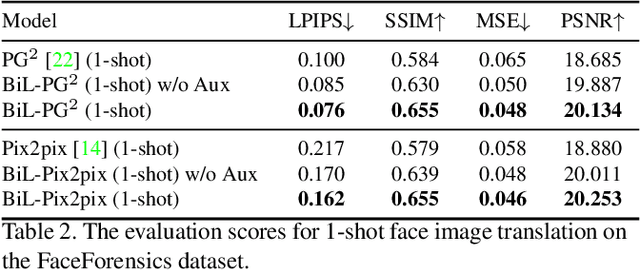
Image-to-image (I2I) translation is a pixel-level mapping that requires a large number of paired training data and often suffers from the problems of high diversity and strong category bias in image scenes. In order to tackle these problems, we propose a novel BiLevel (BiL) learning paradigm that alternates the learning of two models, respectively at an instance-specific (IS) and a general-purpose (GP) level. In each scene, the IS model learns to maintain the specific scene attributes. It is initialized by the GP model that learns from all the scenes to obtain the generalizable translation knowledge. This GP initialization gives the IS model an efficient starting point, thus enabling its fast adaptation to the new scene with scarce training data. We conduct extensive I2I translation experiments on human face and street view datasets. Quantitative results validate that our approach can significantly boost the performance of classical I2I translation models, such as PG2 and Pix2Pix. Our visualization results show both higher image quality and more appropriate instance-specific details, e.g., the translated image of a person looks more like that person in terms of identity.
Compressive Scanning Transmission Electron Microscopy
Dec 22, 2021


Scanning Transmission Electron Microscopy (STEM) offers high-resolution images that are used to quantify the nanoscale atomic structure and composition of materials and biological specimens. In many cases, however, the resolution is limited by the electron beam damage, since in traditional STEM, a focused electron beam scans every location of the sample in a raster fashion. In this paper, we propose a scanning method based on the theory of Compressive Sensing (CS) and subsampling the electron probe locations using a line hop sampling scheme that significantly reduces the electron beam damage. We experimentally validate the feasibility of the proposed method by acquiring real CS-STEM data, and recovering images using a Bayesian dictionary learning approach. We support the proposed method by applying a series of masks to fully-sampled STEM data to simulate the expectation of real CS-STEM. Finally, we perform the real data experimental series using a constrained-dose budget to limit the impact of electron dose upon the results, by ensuring that the total electron count remains constant for each image.
Toward Realistic Single-View 3D Object Reconstruction with Unsupervised Learning from Multiple Images
Sep 07, 2021
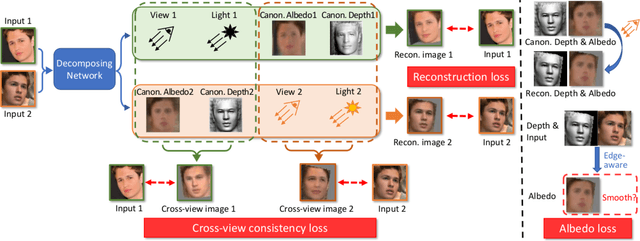
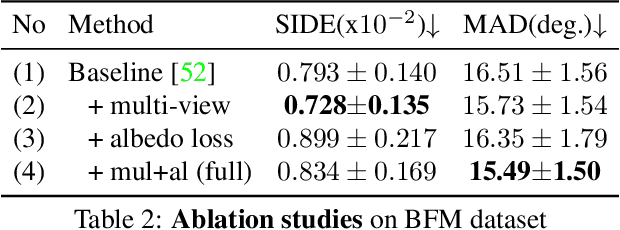

Recovering the 3D structure of an object from a single image is a challenging task due to its ill-posed nature. One approach is to utilize the plentiful photos of the same object category to learn a strong 3D shape prior for the object. This approach has successfully been demonstrated by a recent work of Wu et al. (2020), which obtained impressive 3D reconstruction networks with unsupervised learning. However, their algorithm is only applicable to symmetric objects. In this paper, we eliminate the symmetry requirement with a novel unsupervised algorithm that can learn a 3D reconstruction network from a multi-image dataset. Our algorithm is more general and covers the symmetry-required scenario as a special case. Besides, we employ a novel albedo loss that improves the reconstructed details and realisticity. Our method surpasses the previous work in both quality and robustness, as shown in experiments on datasets of various structures, including single-view, multi-view, image-collection, and video sets.
Towards continual task learning in artificial neural networks: current approaches and insights from neuroscience
Dec 28, 2021
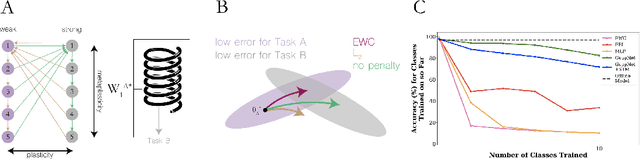
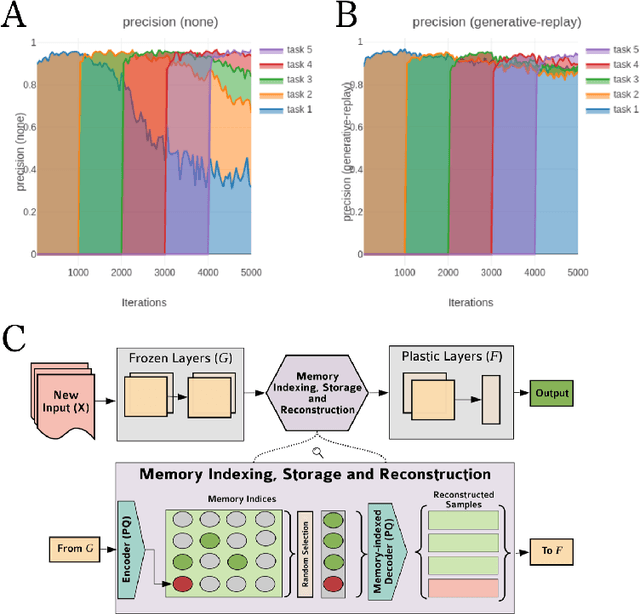
The innate capacity of humans and other animals to learn a diverse, and often interfering, range of knowledge and skills throughout their lifespan is a hallmark of natural intelligence, with obvious evolutionary motivations. In parallel, the ability of artificial neural networks (ANNs) to learn across a range of tasks and domains, combining and re-using learned representations where required, is a clear goal of artificial intelligence. This capacity, widely described as continual learning, has become a prolific subfield of research in machine learning. Despite the numerous successes of deep learning in recent years, across domains ranging from image recognition to machine translation, such continual task learning has proved challenging. Neural networks trained on multiple tasks in sequence with stochastic gradient descent often suffer from representational interference, whereby the learned weights for a given task effectively overwrite those of previous tasks in a process termed catastrophic forgetting. This represents a major impediment to the development of more generalised artificial learning systems, capable of accumulating knowledge over time and task space, in a manner analogous to humans. A repository of selected papers and implementations accompanying this review can be found at https://github.com/mccaffary/continual-learning.
Learning End-to-End Lossy Image Compression: A Benchmark
Feb 10, 2020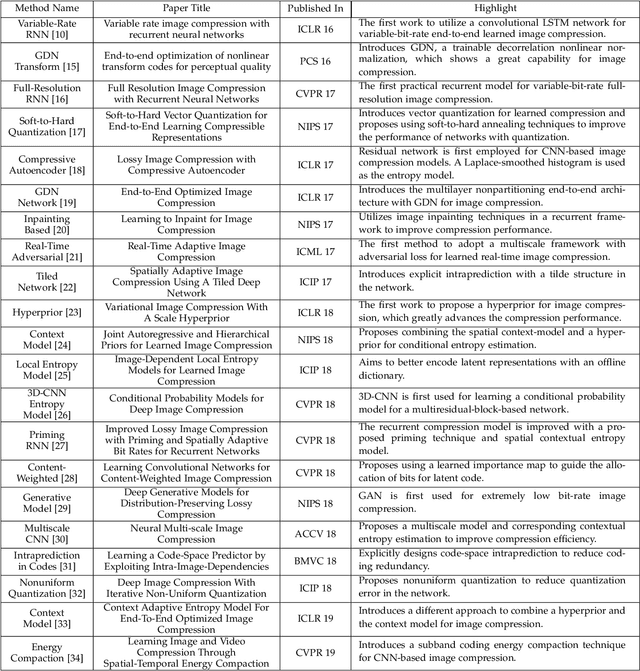
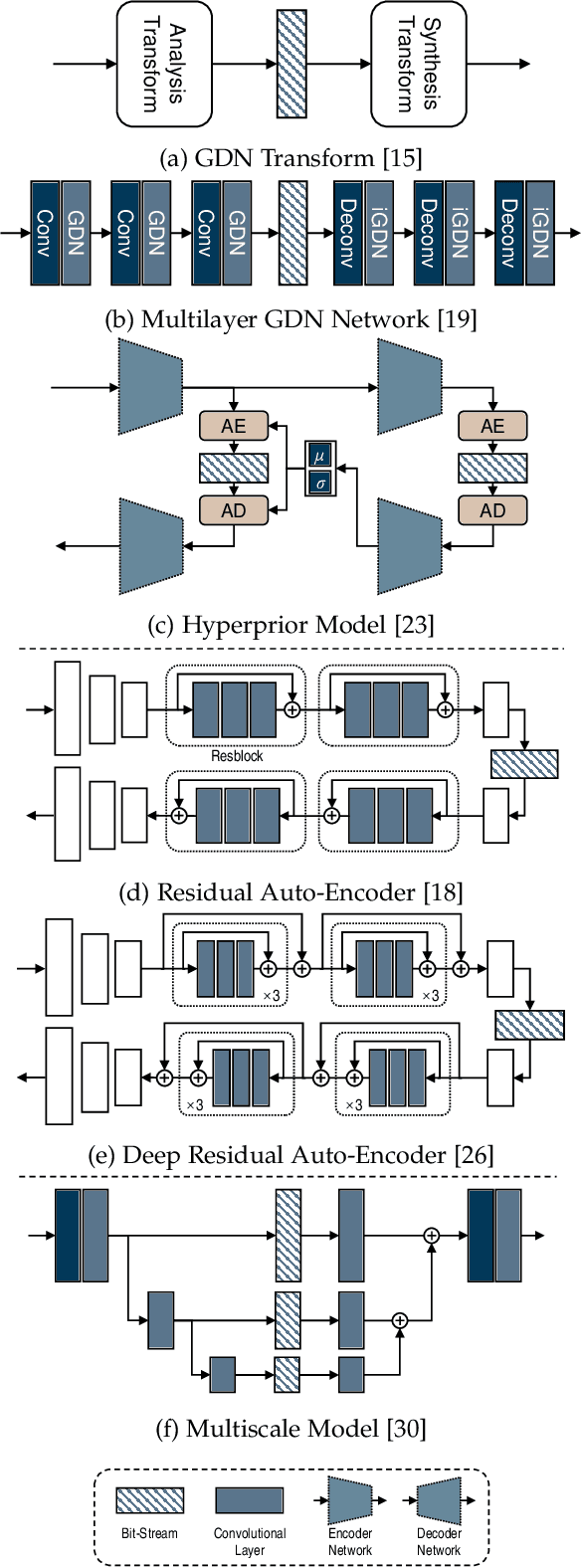
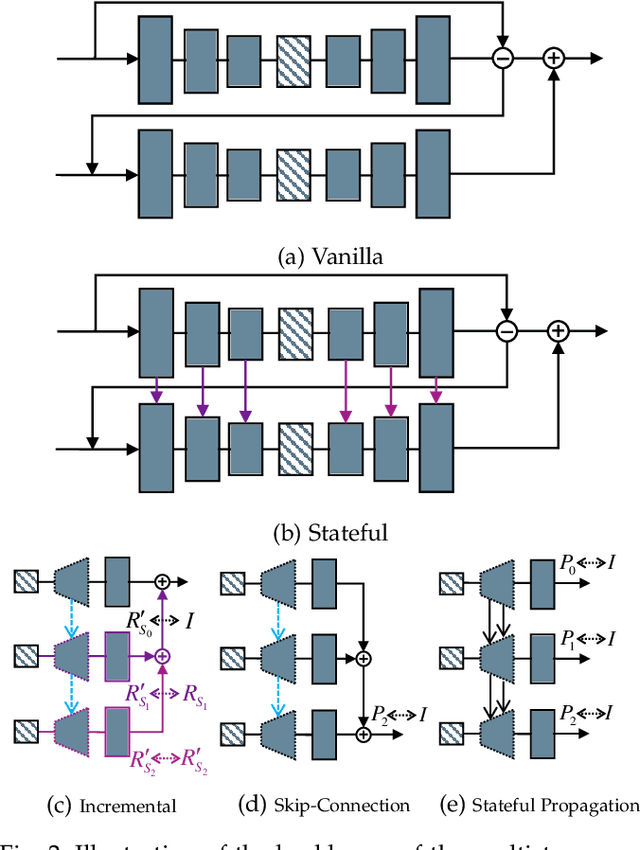
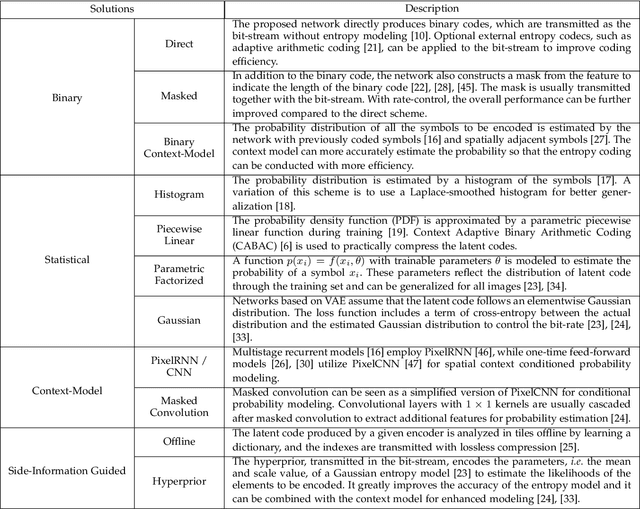
Image compression is one of the most fundamental techniques and commonly used applications in the image and video processing field. Earlier methods built a well-designed pipeline, and efforts were made to improve all modules of the pipeline by handcrafted tuning. Later, tremendous contributions were made, especially when data-driven methods revitalized the domain with their excellent modeling capacities and flexibility in incorporating newly designed modules and constraints. Despite great progress, a systematic benchmark and comprehensive analysis of end-to-end learned image compression methods are lacking. In this paper, we first conduct a comprehensive literature survey of learned image compression methods. The literature is organized based on several aspects to jointly optimize the rate-distortion performance with a neural network, i.e., network architecture, entropy model and rate control. We describe milestones in cutting-edge learned image-compression methods, review a broad range of existing works, and provide insights into their historical development routes. With this survey, the main challenges of image compression methods are revealed, along with opportunities to address the related issues with recent advanced learning methods. This analysis provides an opportunity to take a further step towards higher-efficiency image compression. By introducing a coarse-to-fine hyperprior model for entropy estimation and signal reconstruction, we achieve improved rate-distortion performance, especially on high-resolution images. Extensive benchmark experiments demonstrate the superiority of our model in coding efficiency and the potential for acceleration by large-scale parallel computing devices.
Highly precise AMCW time-of-flight scanning sensor based on digital-parallel demodulation
Dec 16, 2021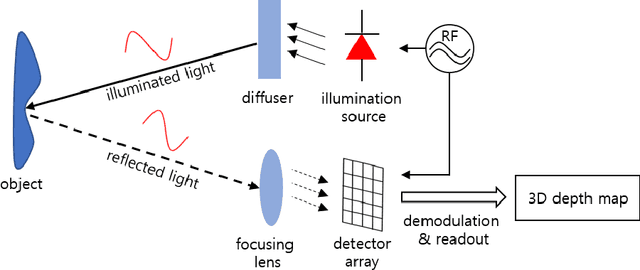
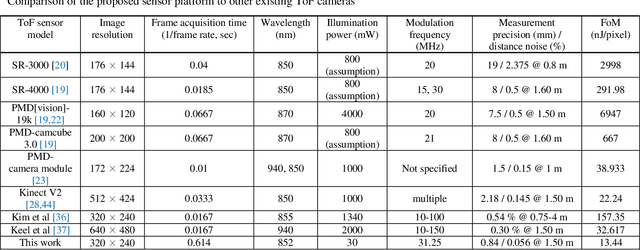
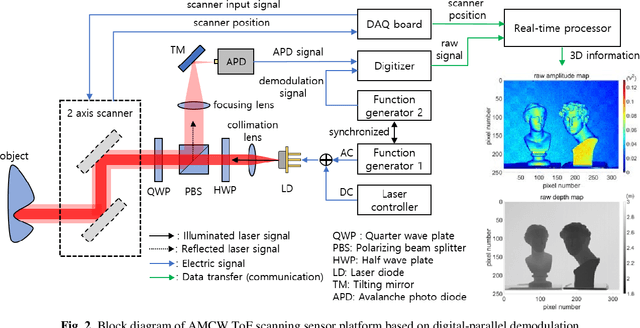
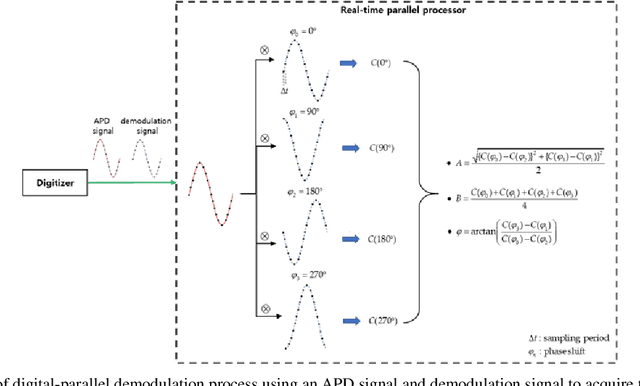
In this paper, a novel amplitude-modulated continuous wave (AMCW) time-of-flight (ToF) scanning sensor based on digital-parallel demodulation is proposed and demonstrated in the aspect of distance measurement precision. Since digital-parallel demodulation utilizes a high-amplitude demodulation signal with zero-offset, the proposed sensor platform can maintain extremely high demodulation contrast. Meanwhile, as all cross correlated samples are calculated in parallel and in extremely short integration time, the proposed sensor platform can utilize a 2D laser scanning structure with a single photo detector, maintaining a moderate frame rate. This optical structure can increase the received optical SNR and remove the crosstalk of image pixel array. Based on these measurement properties, the proposed AMCW ToF scanning sensor shows highly precise 3D depth measurement performance. In this study, this precise measurement performance is explained in detail. Additionally, the actual measurement performance of the proposed sensor platform is experimentally validated under various conditions.
Gated Texture CNN for Efficient and Configurable Image Denoising
Mar 16, 2020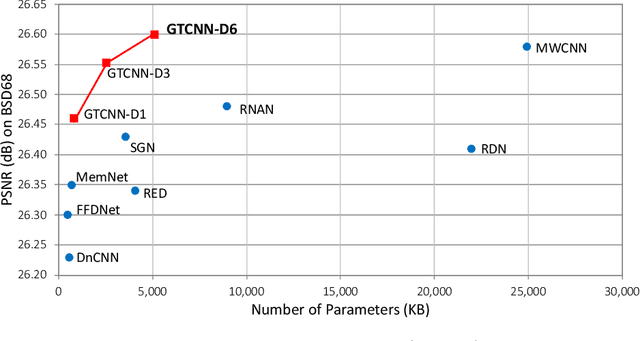
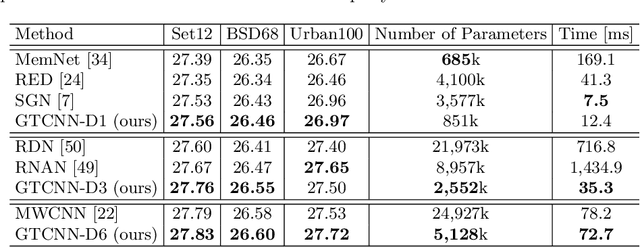
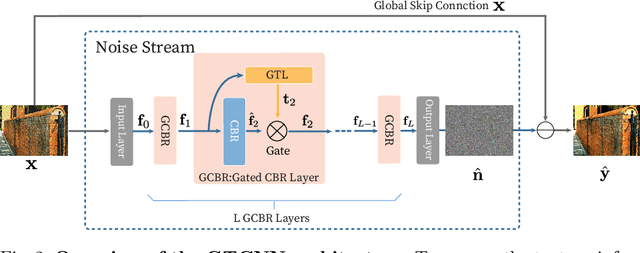
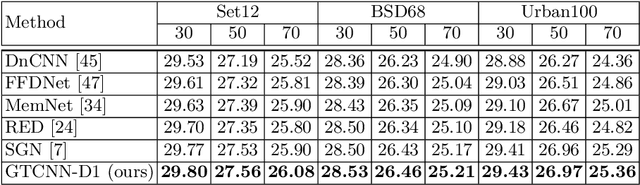
Convolutional neural network (CNN)-based image denoising methods typically estimate the noise component contained in a noisy input image and restore a clean image by subtracting the estimated noise from the input. However, previous denoising methods tend to remove high-frequency information (e.g., textures) from the input. It caused by intermediate feature maps of CNN contains texture information. A straightforward approach to this problem is stacking numerous layers, which leads to a high computational cost. To achieve high performance and computational efficiency, we propose a gated texture CNN (GTCNN), which is designed to carefully exclude the texture information from each intermediate feature map of the CNN by incorporating gating mechanisms. Our GTCNN achieves state-of-the-art performance with 4.8 times fewer parameters than previous state-of-the-art methods. Furthermore, the GTCNN allows us to interactively control the texture strength in the output image without any additional modules, training, or computational costs.
Multiscale Softmax Cross Entropy for Fovea Localization on Color Fundus Photography
Dec 08, 2021
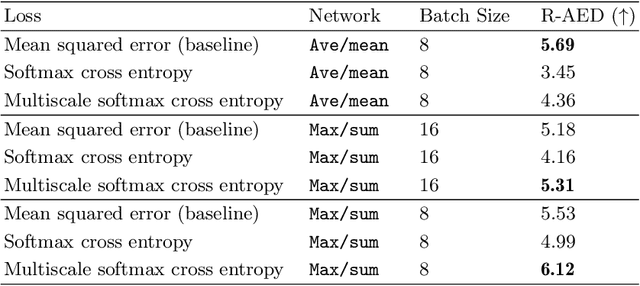
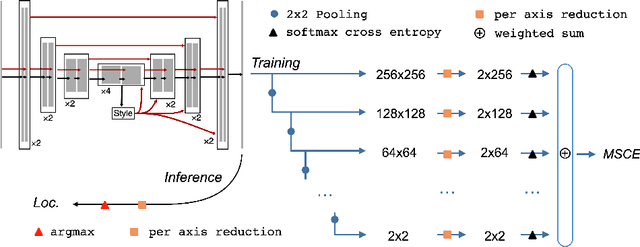
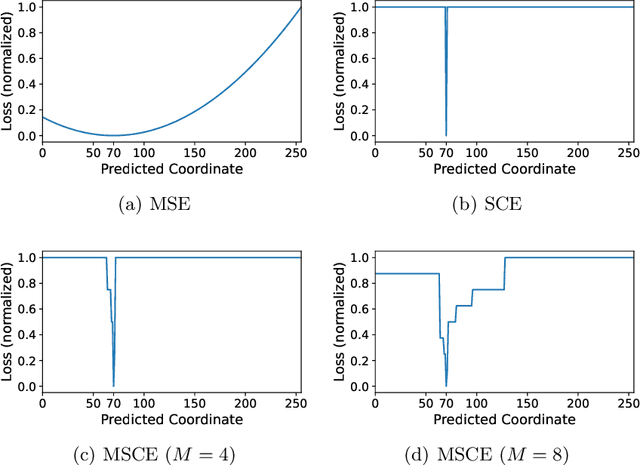
Fovea localization is one of the most popular tasks in ophthalmic medical image analysis, where the coordinates of the center point of the macula lutea, i.e. fovea centralis, should be calculated based on color fundus images. In this work, we treat the localization problem as a classification task, where the coordinates of the x- and y-axis are considered as the target classes. Moreover, the combination of the softmax activation function and the cross entropy loss function is modified to its multiscale variation to encourage the predicted coordinates to be located closely to the ground-truths. Based on color fundus photography images, we empirically show that the proposed multiscale softmax cross entropy yields better performance than the vanilla version and than the mean squared error loss with sigmoid activation, which provides a novel approach for coordinate regression.