 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
spectrai: A deep learning framework for spectral data
Aug 17, 2021
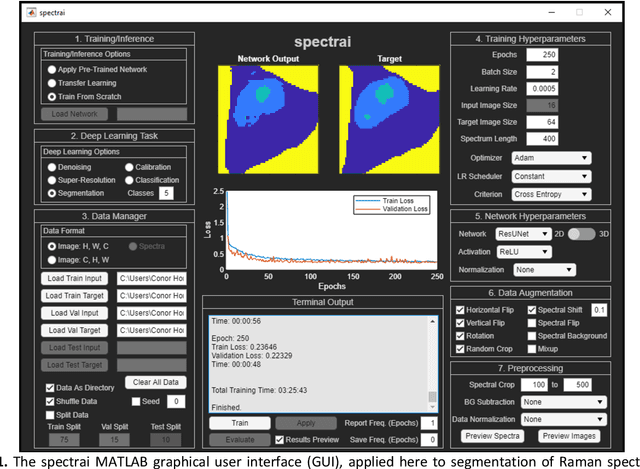

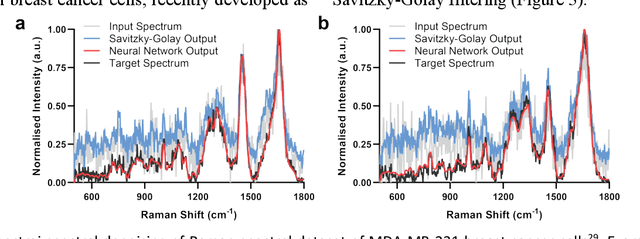
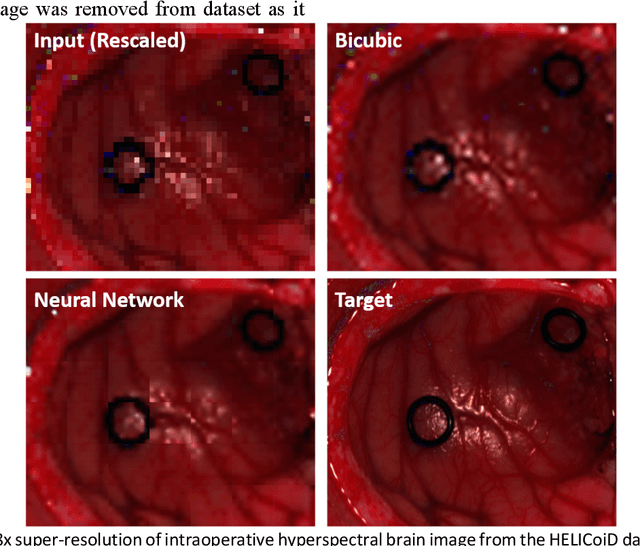
Deep learning computer vision techniques have achieved many successes in recent years across numerous imaging domains. However, the application of deep learning to spectral data remains a complex task due to the need for augmentation routines, specific architectures for spectral data, and significant memory requirements. Here we present spectrai, an open-source deep learning framework designed to facilitate the training of neural networks on spectral data and enable comparison between different methods. Spectrai provides numerous built-in spectral data pre-processing and augmentation methods, neural networks for spectral data including spectral (image) denoising, spectral (image) classification, spectral image segmentation, and spectral image super-resolution. Spectrai includes both command line and graphical user interfaces (GUI) designed to guide users through model and hyperparameter decisions for a wide range of applications.
Adaptive Fractional Dilated Convolution Network for Image Aesthetics Assessment
Apr 06, 2020
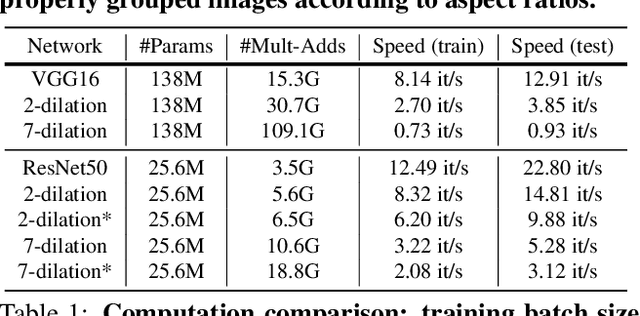
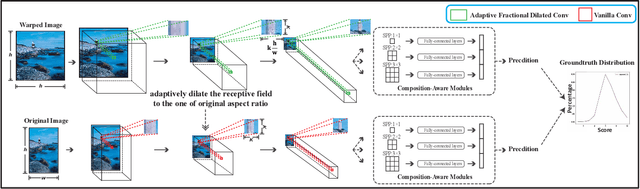
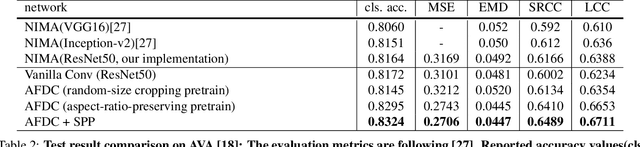
To leverage deep learning for image aesthetics assessment, one critical but unsolved issue is how to seamlessly incorporate the information of image aspect ratios to learn more robust models. In this paper, an adaptive fractional dilated convolution (AFDC), which is aspect-ratio-embedded, composition-preserving and parameter-free, is developed to tackle this issue natively in convolutional kernel level. Specifically, the fractional dilated kernel is adaptively constructed according to the image aspect ratios, where the interpolation of nearest two integers dilated kernels is used to cope with the misalignment of fractional sampling. Moreover, we provide a concise formulation for mini-batch training and utilize a grouping strategy to reduce computational overhead. As a result, it can be easily implemented by common deep learning libraries and plugged into popular CNN architectures in a computation-efficient manner. Our experimental results demonstrate that our proposed method achieves state-of-the-art performance on image aesthetics assessment over the AVA dataset.
A Model for Image Segmentation in Retina
May 06, 2020



While traditional feed-forward filter models can reproduce the rate responses of retinal ganglion neurons to simple stimuli, they cannot explain why synchrony between spikes is much higher than expected by Poisson firing [6], and can be sometimes rhythmic [25, 16]. Here we investigate the hypothesis that synchrony in periodic retinal spike trains could convey contextual information of the visual input, which is extracted by computations in the retinal network. We propose a computational model for image segmentation consisting of a Kuramoto model of coupled oscillators whose phases model the timing of individual retinal spikes. The phase couplings between oscillators are shaped by the stimulus structure, causing cells to synchronize if the local contrast in their receptive fields is similar. In essence, relaxation in the oscillator network solves a graph clustering problem with the graph representing feature similarity between different points in the image. We tested different model versions on the Berkeley Image Segmentation Data Set (BSDS). Networks with phase interactions set by standard representations of the feature graph (adjacency matrix, Graph Laplacian or modularity) failed to exhibit segmentation performance significantly over the baseline, a model of independent sensors. In contrast, a network with phase interactions that takes into account not only feature similarities but also geometric distances between receptive fields exhibited segmentation performance significantly above baseline.
A Novel 3D-UNet Deep Learning Framework Based on High-Dimensional Bilateral Grid for Edge Consistent Single Image Depth Estimation
May 21, 2021

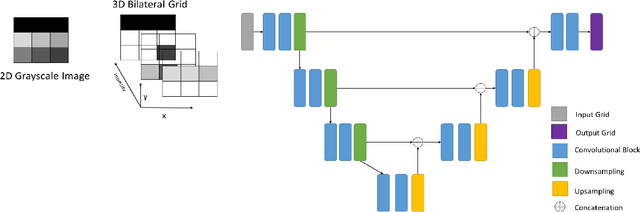
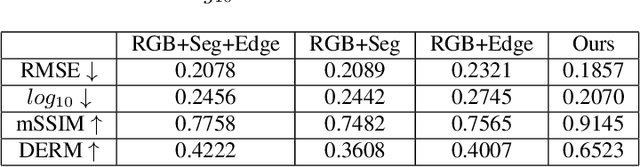
The task of predicting smooth and edge-consistent depth maps is notoriously difficult for single image depth estimation. This paper proposes a novel Bilateral Grid based 3D convolutional neural network, dubbed as 3DBG-UNet, that parameterizes high dimensional feature space by encoding compact 3D bilateral grids with UNets and infers sharp geometric layout of the scene. Further, another novel 3DBGES-UNet model is introduced that integrate 3DBG-UNet for inferring an accurate depth map given a single color view. The 3DBGES-UNet concatenates 3DBG-UNet geometry map with the inception network edge accentuation map and a spatial object's boundary map obtained by leveraging semantic segmentation and train the UNet model with ResNet backbone. Both models are designed with a particular attention to explicitly account for edges or minute details. Preserving sharp discontinuities at depth edges is critical for many applications such as realistic integration of virtual objects in AR video or occlusion-aware view synthesis for 3D display applications.The proposed depth prediction network achieves state-of-the-art performance in both qualitative and quantitative evaluations on the challenging NYUv2-Depth data. The code and corresponding pre-trained weights will be made publicly available.
* 8 pages, 5 figures, accepted at IC3D 2020
Adversarial attacks on deep learning models for fatty liver disease classification by modification of ultrasound image reconstruction method
Sep 07, 2020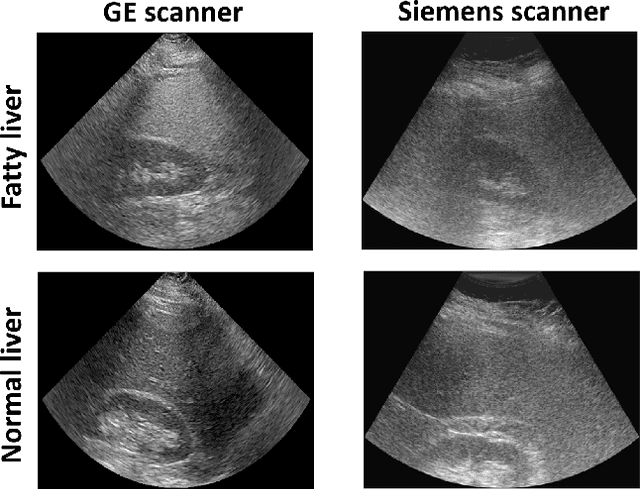
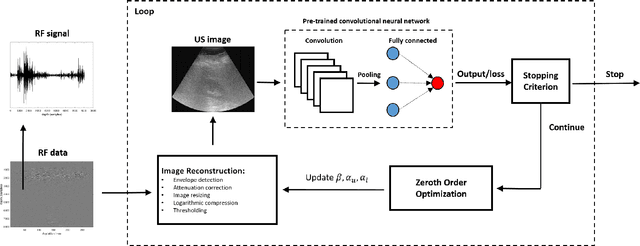
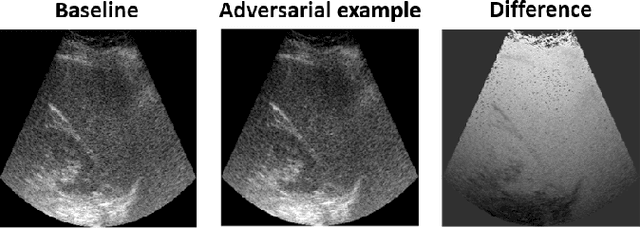
Convolutional neural networks (CNNs) have achieved remarkable success in medical image analysis tasks. In ultrasound (US) imaging, CNNs have been applied to object classification, image reconstruction and tissue characterization. However, CNNs can be vulnerable to adversarial attacks, even small perturbations applied to input data may significantly affect model performance and result in wrong output. In this work, we devise a novel adversarial attack, specific to ultrasound (US) imaging. US images are reconstructed based on radio-frequency signals. Since the appearance of US images depends on the applied image reconstruction method, we explore the possibility of fooling deep learning model by perturbing US B-mode image reconstruction method. We apply zeroth order optimization to find small perturbations of image reconstruction parameters, related to attenuation compensation and amplitude compression, which can result in wrong output. We illustrate our approach using a deep learning model developed for fatty liver disease diagnosis, where the proposed adversarial attack achieved success rate of 48%.
P2P-Loc: Point to Point Tiny Person Localization
Dec 31, 2021

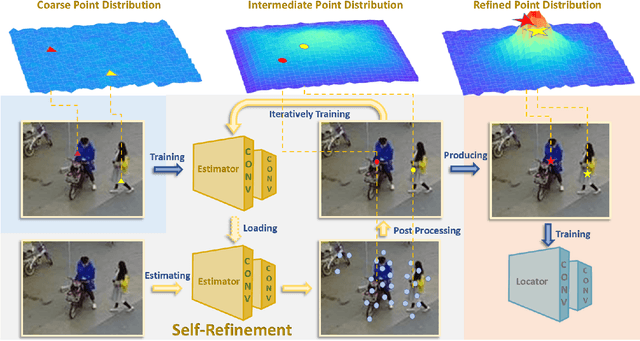

Bounding-box annotation form has been the most frequently used method for visual object localization tasks. However, bounding-box annotation relies on the large amounts of precisely annotating bounding boxes, which is expensive, laborious, thus impossible in practical scenarios, and even redundant for some applications caring not about size. Therefore, we propose a novel point-based framework for the person localization task by annotating each person as a coarse point (CoarsePoint) which can be any point within the object extent, instead of an accurate bounding box. And then predict the person's location as a 2D coordinate in the image. That greatly simplifies the data annotation pipeline. However, the CoarsePoint annotation inevitably causes the label reliability decrease (label uncertainty) and network confusion during training. As a result, we propose a point self-refinement approach, which iteratively updates point annotations in a self-paced way. The proposed refinement system alleviates the label uncertainty and progressively improves localization performance. Experiments show that our approach achieves comparable object localization performance while saving annotation cost up to 80$\%$. Code is enclosed in the supplementary materials.
Semi-supervised Cardiac Image Segmentation via Label Propagation and Style Transfer
Dec 29, 2020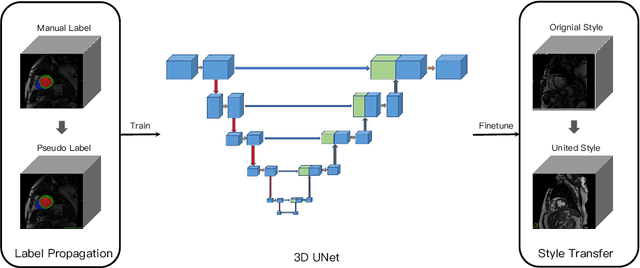
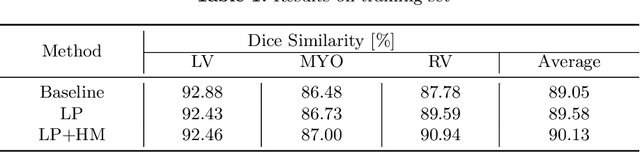
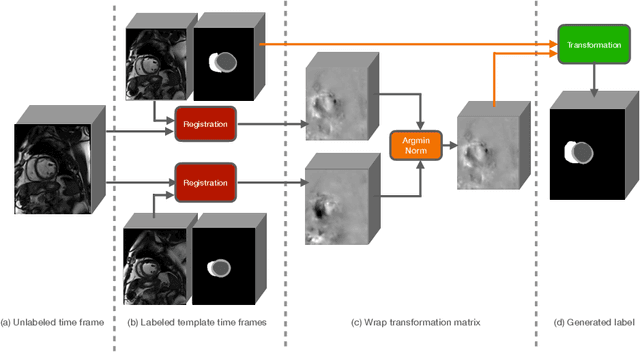

Accurate segmentation of cardiac structures can assist doctors to diagnose diseases, and to improve treatment planning, which is highly demanded in the clinical practice. However, the shortage of annotation and the variance of the data among different vendors and medical centers restrict the performance of advanced deep learning methods. In this work, we present a fully automatic method to segment cardiac structures including the left (LV) and right ventricle (RV) blood pools, as well as for the left ventricular myocardium (MYO) in MRI volumes. Specifically, we design a semi-supervised learning method to leverage unlabelled MRI sequence timeframes by label propagation. Then we exploit style transfer to reduce the variance among different centers and vendors for more robust cardiac image segmentation. We evaluate our method in the M&Ms challenge 7 , ranking 2nd place among 14 competitive teams.
Detecting Patch Adversarial Attacks with Image Residuals
Mar 02, 2020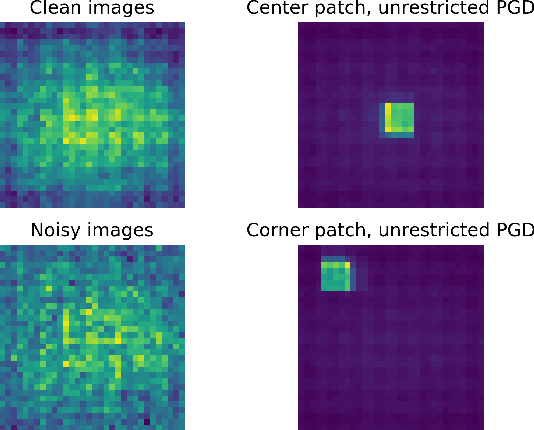
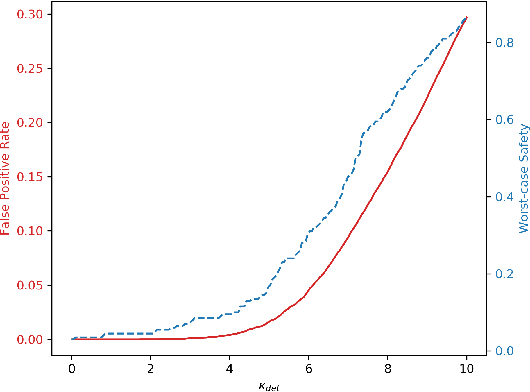


We introduce an adversarial sample detection algorithm based on image residuals, specifically designed to guard against patch-based attacks. The image residual is obtained as the difference between an input image and a denoised version of it, and a discriminator is trained to distinguish between clean and adversarial samples. More precisely, we use a wavelet domain algorithm for denoising images and demonstrate that the obtained residuals act as a digital fingerprint for adversarial attacks. To emulate the limitations of a physical adversary, we evaluate the performance of our approach against localized (patch-based) adversarial attacks, including in settings where the adversary has complete knowledge about the detection scheme. Our results show that the proposed detection method generalizes to previously unseen, stronger attacks and that it is able to reduce the success rate (conversely, increase the computational effort) of an adaptive attacker.
SegAttnGAN: Text to Image Generation with Segmentation Attention
May 25, 2020
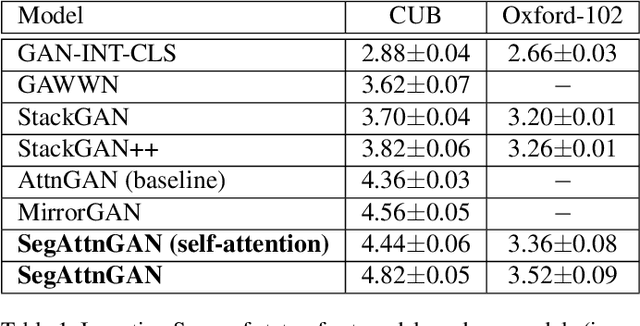
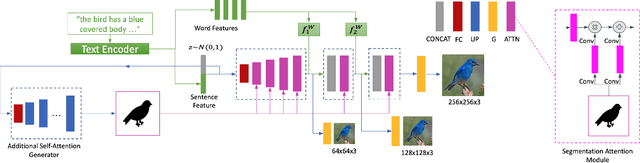

In this paper, we propose a novel generative network (SegAttnGAN) that utilizes additional segmentation information for the text-to-image synthesis task. As the segmentation data introduced to the model provides useful guidance on the generator training, the proposed model can generate images with better realism quality and higher quantitative measures compared with the previous state-of-art methods. We achieved Inception Score of 4.84 on the CUB dataset and 3.52 on the Oxford-102 dataset. Besides, we tested the self-attention SegAttnGAN which uses generated segmentation data instead of masks from datasets for attention and achieved similar high-quality results, suggesting that our model can be adapted for the text-to-image synthesis task.
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
Sep 10, 2021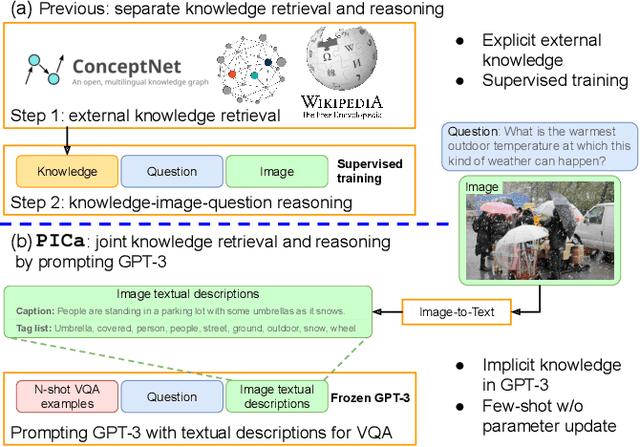

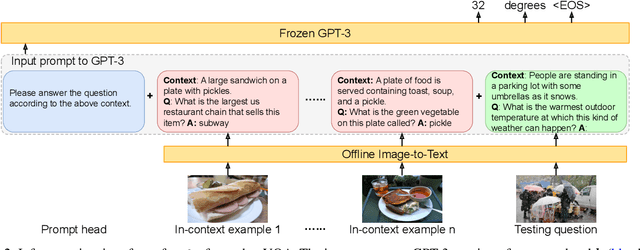

Knowledge-based visual question answering (VQA) involves answering questions that require external knowledge not present in the image. Existing methods first retrieve knowledge from external resources, then reason over the selected knowledge, the input image, and question for answer prediction. However, this two-step approach could lead to mismatches that potentially limit the VQA performance. For example, the retrieved knowledge might be noisy and irrelevant to the question, and the re-embedded knowledge features during reasoning might deviate from their original meanings in the knowledge base (KB). To address this challenge, we propose PICa, a simple yet effective method that Prompts GPT3 via the use of Image Captions, for knowledge-based VQA. Inspired by GPT-3's power in knowledge retrieval and question answering, instead of using structured KBs as in previous work, we treat GPT-3 as an implicit and unstructured KB that can jointly acquire and process relevant knowledge. Specifically, we first convert the image into captions (or tags) that GPT-3 can understand, then adapt GPT-3 to solve the VQA task in a few-shot manner by just providing a few in-context VQA examples. We further boost performance by carefully investigating: (i) what text formats best describe the image content, and (ii) how in-context examples can be better selected and used. PICa unlocks the first use of GPT-3 for multimodal tasks. By using only 16 examples, PICa surpasses the supervised state of the art by an absolute +8.6 points on the OK-VQA dataset. We also benchmark PICa on VQAv2, where PICa also shows a decent few-shot performance.