 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Compact Reward for Image Captioning
Mar 24, 2020

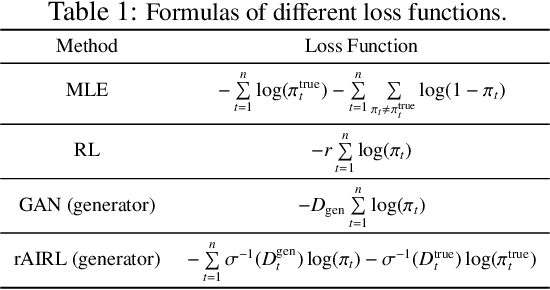

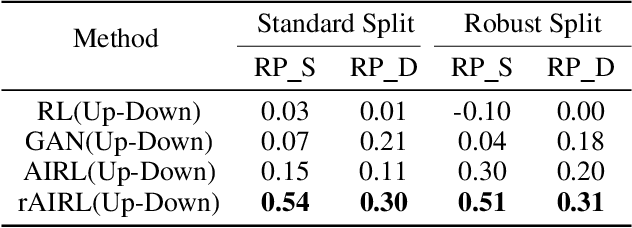
Adversarial learning has shown its advances in generating natural and diverse descriptions in image captioning. However, the learned reward of existing adversarial methods is vague and ill-defined due to the reward ambiguity problem. In this paper, we propose a refined Adversarial Inverse Reinforcement Learning (rAIRL) method to handle the reward ambiguity problem by disentangling reward for each word in a sentence, as well as achieve stable adversarial training by refining the loss function to shift the generator towards Nash equilibrium. In addition, we introduce a conditional term in the loss function to mitigate mode collapse and to increase the diversity of the generated descriptions. Our experiments on MS COCO and Flickr30K show that our method can learn compact reward for image captioning.
Self-Validation: Early Stopping for Single-Instance Deep Generative Priors
Oct 23, 2021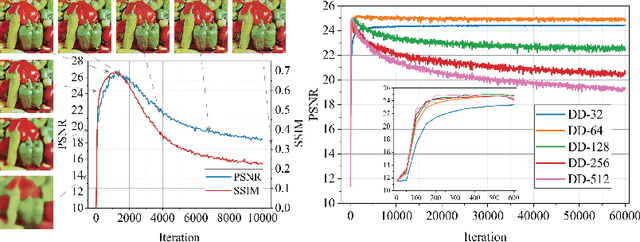
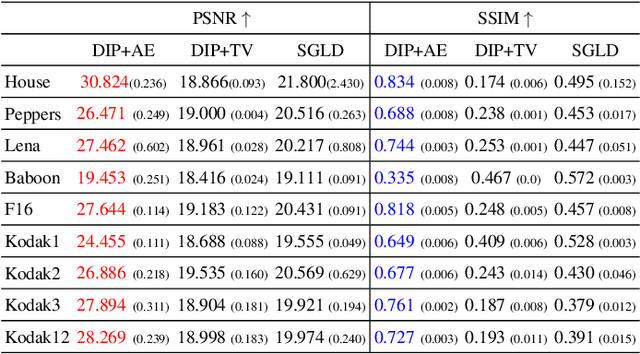
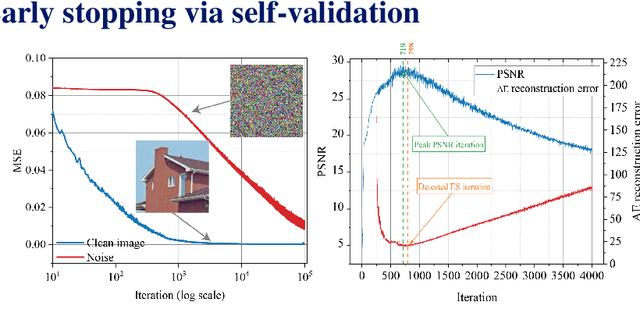
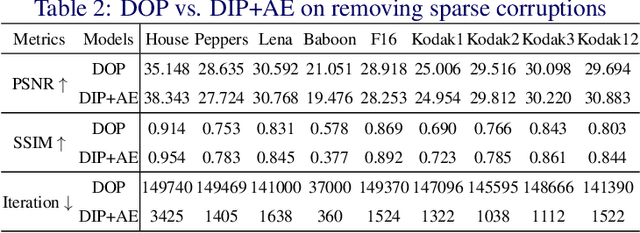
Recent works have shown the surprising effectiveness of deep generative models in solving numerous image reconstruction (IR) tasks, even without training data. We call these models, such as deep image prior and deep decoder, collectively as single-instance deep generative priors (SIDGPs). The successes, however, often hinge on appropriate early stopping (ES), which by far has largely been handled in an ad-hoc manner. In this paper, we propose the first principled method for ES when applying SIDGPs to IR, taking advantage of the typical bell trend of the reconstruction quality. In particular, our method is based on collaborative training and self-validation: the primal reconstruction process is monitored by a deep autoencoder, which is trained online with the historic reconstructed images and used to validate the reconstruction quality constantly. Experimentally, on several IR problems and different SIDGPs, our self-validation method is able to reliably detect near-peak performance and signal good ES points. Our code is available at https://sun-umn.github.io/Self-Validation/.
Enabling Deep Learning on Edge Devices through Filter Pruning and Knowledge Transfer
Jan 22, 2022Deep learning models have introduced various intelligent applications to edge devices, such as image classification, speech recognition, and augmented reality. There is an increasing need of training such models on the devices in order to deliver personalized, responsive, and private learning. To address this need, this paper presents a new solution for deploying and training state-of-the-art models on the resource-constrained devices. First, the paper proposes a novel filter-pruning-based model compression method to create lightweight trainable models from large models trained in the cloud, without much loss of accuracy. Second, it proposes a novel knowledge transfer method to enable the on-device model to update incrementally in real time or near real time using incremental learning on new data and enable the on-device model to learn the unseen categories with the help of the in-cloud model in an unsupervised fashion. The results show that 1) our model compression method can remove up to 99.36% parameters of WRN-28-10, while preserving a Top-1 accuracy of over 90% on CIFAR-10; 2) our knowledge transfer method enables the compressed models to achieve more than 90% accuracy on CIFAR-10 and retain good accuracy on old categories; 3) it allows the compressed models to converge within real time (three to six minutes) on the edge for incremental learning tasks; 4) it enables the model to classify unseen categories of data (78.92% Top-1 accuracy) that it is never trained with.
Domain aware medical image classifier interpretation by counterfactual impact analysis
Jul 13, 2020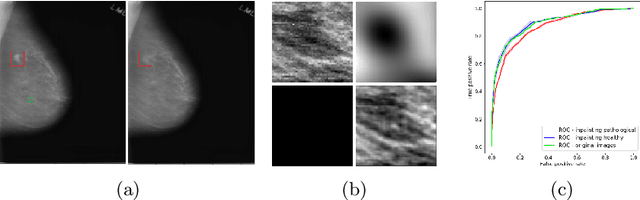

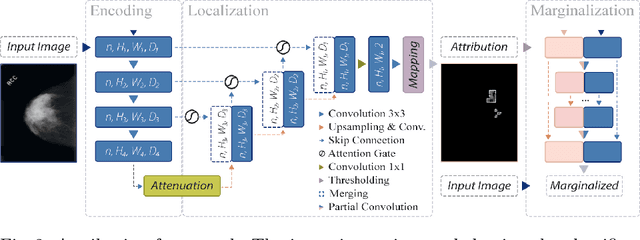
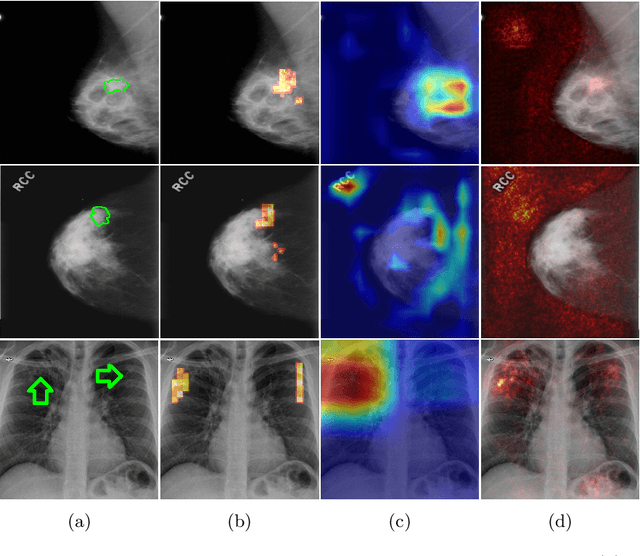
The success of machine learning methods for computer vision tasks has driven a surge in computer assisted prediction for medicine and biology. Based on a data-driven relationship between input image and pathological classification, these predictors deliver unprecedented accuracy. Yet, the numerous approaches trying to explain the causality of this learned relationship have fallen short: time constraints, coarse, diffuse and at times misleading results, caused by the employment of heuristic techniques like Gaussian noise and blurring, have hindered their clinical adoption. In this work, we discuss and overcome these obstacles by introducing a neural-network based attribution method, applicable to any trained predictor. Our solution identifies salient regions of an input image in a single forward-pass by measuring the effect of local image-perturbations on a predictor's score. We replace heuristic techniques with a strong neighborhood conditioned inpainting approach, avoiding anatomically implausible, hence adversarial artifacts. We evaluate on public mammography data and compare against existing state-of-the-art methods. Furthermore, we exemplify the approach's generalizability by demonstrating results on chest X-rays. Our solution shows, both quantitatively and qualitatively, a significant reduction of localization ambiguity and clearer conveying results, without sacrificing time efficiency.
De-rendering 3D Objects in the Wild
Jan 06, 2022



With increasing focus on augmented and virtual reality applications (XR) comes the demand for algorithms that can lift objects from images and videos into representations that are suitable for a wide variety of related 3D tasks. Large-scale deployment of XR devices and applications means that we cannot solely rely on supervised learning, as collecting and annotating data for the unlimited variety of objects in the real world is infeasible. We present a weakly supervised method that is able to decompose a single image of an object into shape (depth and normals), material (albedo, reflectivity and shininess) and global lighting parameters. For training, the method only relies on a rough initial shape estimate of the training objects to bootstrap the learning process. This shape supervision can come for example from a pretrained depth network or - more generically - from a traditional structure-from-motion pipeline. In our experiments, we show that the method can successfully de-render 2D images into a decomposed 3D representation and generalizes to unseen object categories. Since in-the-wild evaluation is difficult due to the lack of ground truth data, we also introduce a photo-realistic synthetic test set that allows for quantitative evaluation.
Self-Supervised 2D Image to 3D Shape Translation with Disentangled Representations
Mar 22, 2020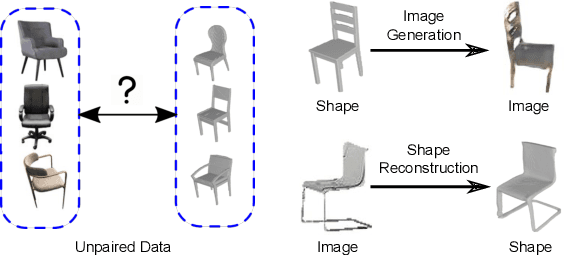
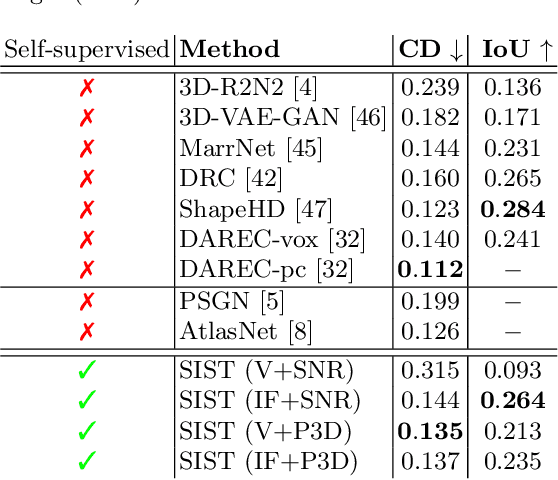

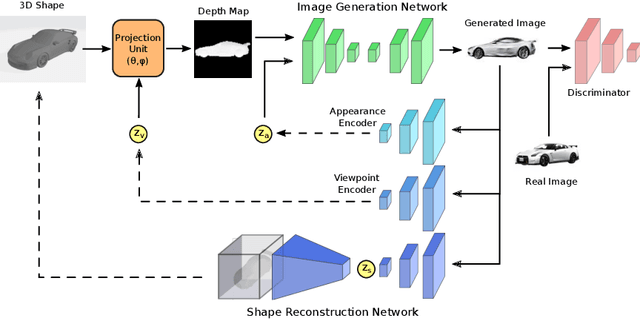
We present a framework to translate between 2D image views and 3D object shapes. Recent progress in deep learning enabled us to learn structure-aware representations from a scene. However, the existing literature assumes that pairs of images and 3D shapes are available for training in full supervision. In this paper, we propose SIST, a Self-supervised Image to Shape Translation framework that fulfills three tasks: (i) reconstructing the 3D shape from a single image; (ii) learning disentangled representations for shape, appearance and viewpoint; and (iii) generating a realistic RGB image from these independent factors. In contrast to the existing approaches, our method does not require image-shape pairs for training. Instead, it uses unpaired image and shape datasets from the same object class and jointly trains image generator and shape reconstruction networks. Our translation method achieves promising results, comparable in quantitative and qualitative terms to the state-of-the-art achieved by fully-supervised methods.
Adaptive Fractional Dilated Convolution Network for Image Aesthetics Assessment
Apr 06, 2020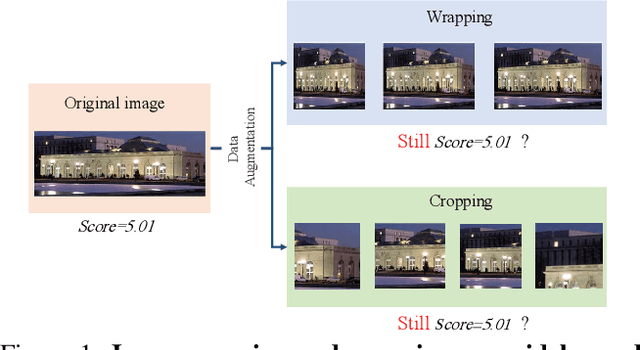
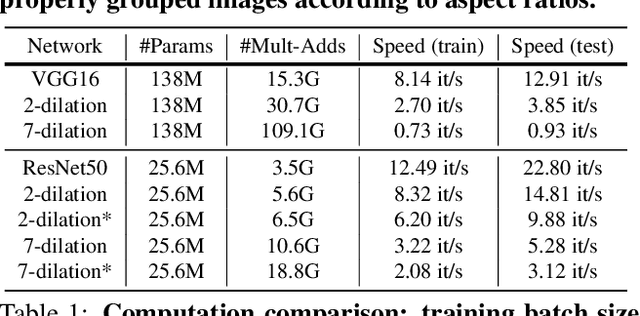
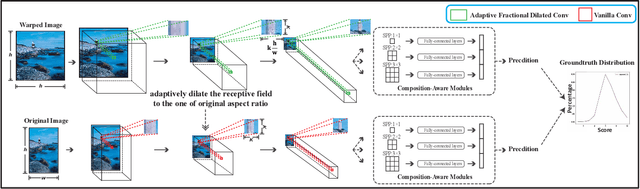
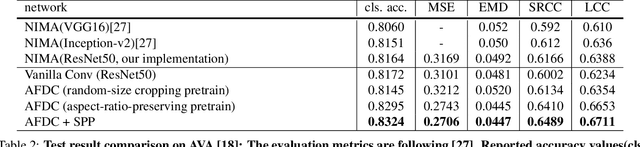
To leverage deep learning for image aesthetics assessment, one critical but unsolved issue is how to seamlessly incorporate the information of image aspect ratios to learn more robust models. In this paper, an adaptive fractional dilated convolution (AFDC), which is aspect-ratio-embedded, composition-preserving and parameter-free, is developed to tackle this issue natively in convolutional kernel level. Specifically, the fractional dilated kernel is adaptively constructed according to the image aspect ratios, where the interpolation of nearest two integers dilated kernels is used to cope with the misalignment of fractional sampling. Moreover, we provide a concise formulation for mini-batch training and utilize a grouping strategy to reduce computational overhead. As a result, it can be easily implemented by common deep learning libraries and plugged into popular CNN architectures in a computation-efficient manner. Our experimental results demonstrate that our proposed method achieves state-of-the-art performance on image aesthetics assessment over the AVA dataset.
Margin Preserving Self-paced Contrastive Learning Towards Domain Adaptation for Medical Image Segmentation
Mar 15, 2021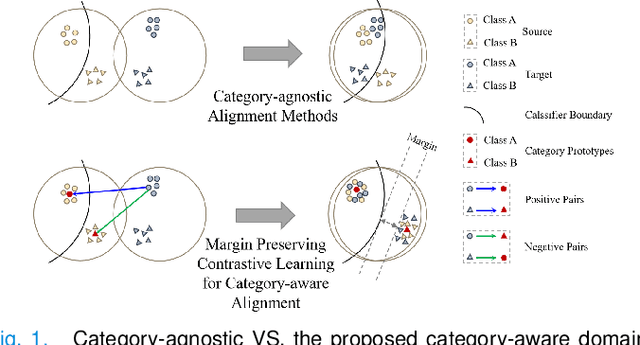
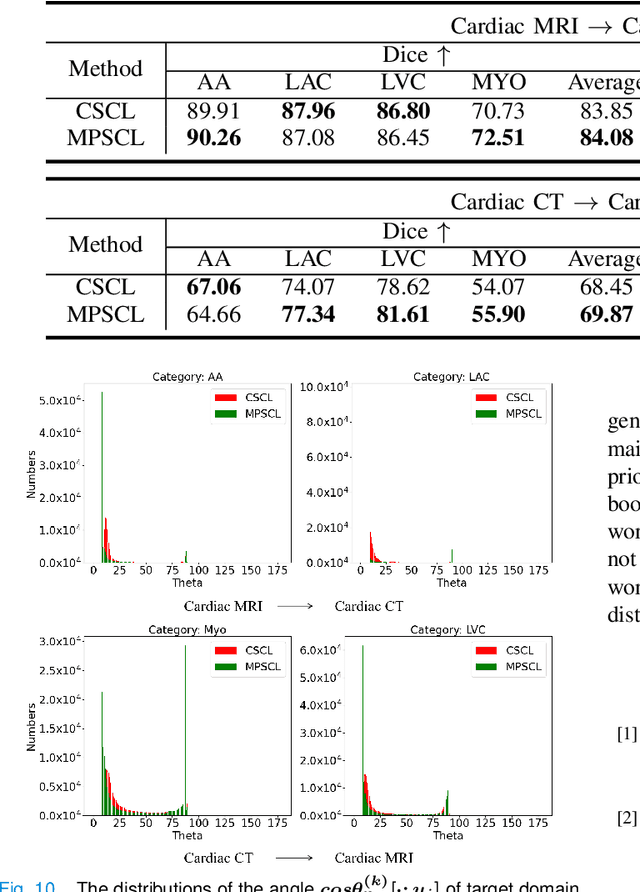
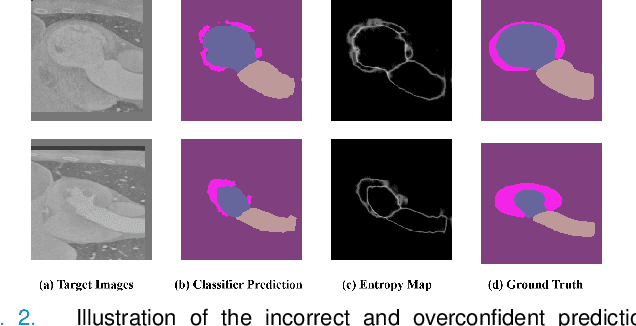
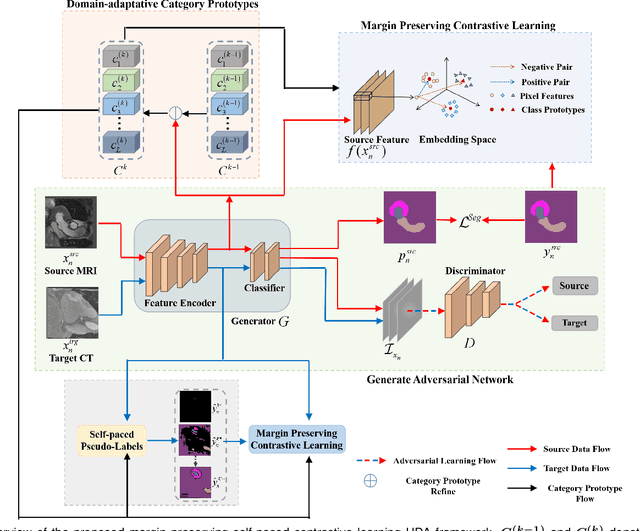
To bridge the gap between the source and target domains in unsupervised domain adaptation (UDA), the most common strategy puts focus on matching the marginal distributions in the feature space through adversarial learning. However, such category-agnostic global alignment lacks of exploiting the class-level joint distributions, causing the aligned distribution less discriminative. To address this issue, we propose in this paper a novel margin preserving self-paced contrastive Learning (MPSCL) model for cross-modal medical image segmentation. Unlike the conventional construction of contrastive pairs in contrastive learning, the domain-adaptive category prototypes are utilized to constitute the positive and negative sample pairs. With the guidance of progressively refined semantic prototypes, a novel margin preserving contrastive loss is proposed to boost the discriminability of embedded representation space. To enhance the supervision for contrastive learning, more informative pseudo-labels are generated in target domain in a self-paced way, thus benefiting the category-aware distribution alignment for UDA. Furthermore, the domain-invariant representations are learned through joint contrastive learning between the two domains. Extensive experiments on cross-modal cardiac segmentation tasks demonstrate that MPSCL significantly improves semantic segmentation performance, and outperforms a wide variety of state-of-the-art methods by a large margin.
MODNet-V: Improving Portrait Video Matting via Background Restoration
Sep 24, 2021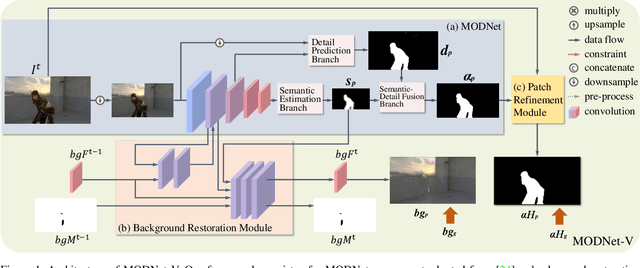

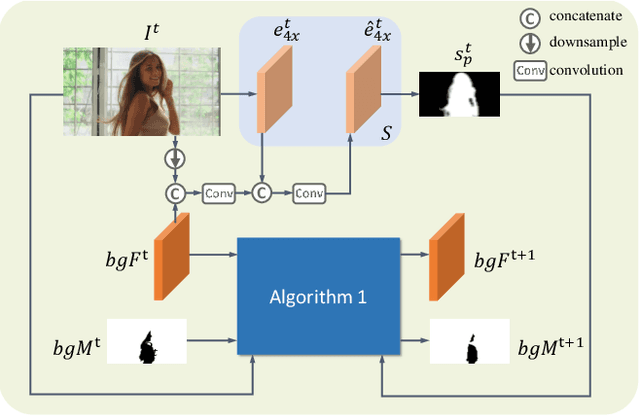
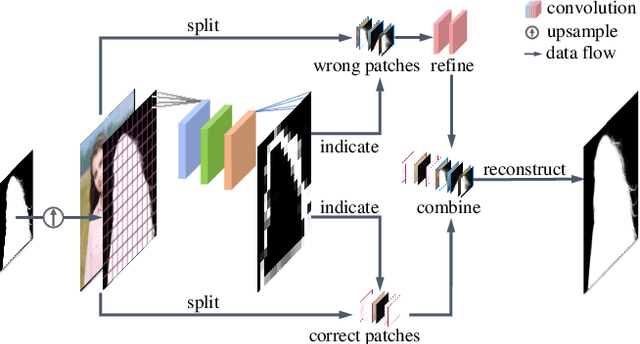
To address the challenging portrait video matting problem more precisely, existing works typically apply some matting priors that require additional user efforts to obtain, such as annotated trimaps or background images. In this work, we observe that instead of asking the user to explicitly provide a background image, we may recover it from the input video itself. To this end, we first propose a novel background restoration module (BRM) to recover the background image dynamically from the input video. BRM is extremely lightweight and can be easily integrated into existing matting models. By combining BRM with a recent image matting model, MODNet, we then present MODNet-V for portrait video matting. Benefited from the strong background prior provided by BRM, MODNet-V has only 1/3 of the parameters of MODNet but achieves comparable or even better performances. Our design allows MODNet-V to be trained in an end-to-end manner on a single NVIDIA 3090 GPU. Finally, we introduce a new patch refinement module (PRM) to adapt MODNet-V for high-resolution videos while keeping MODNet-V lightweight and fast.
Spectral analysis of re-parameterized light fields
Oct 12, 2021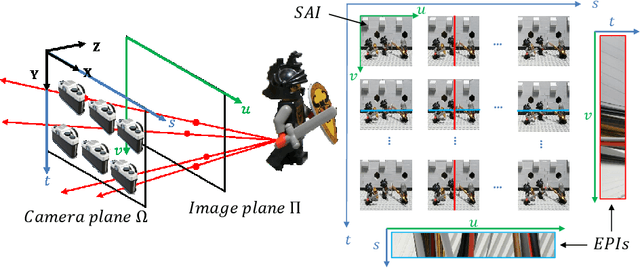
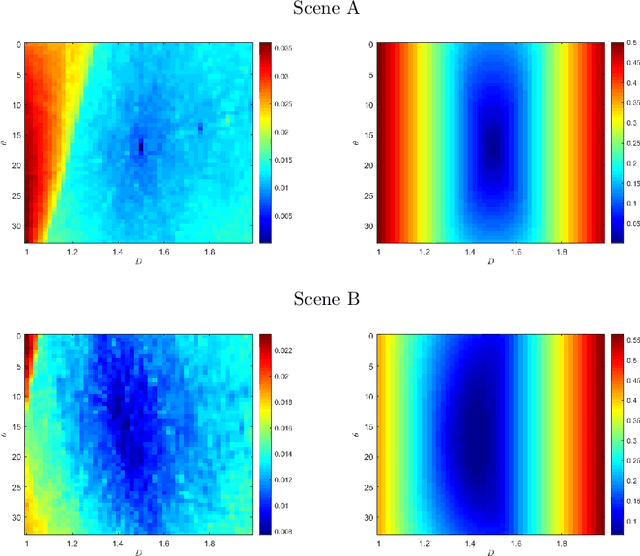
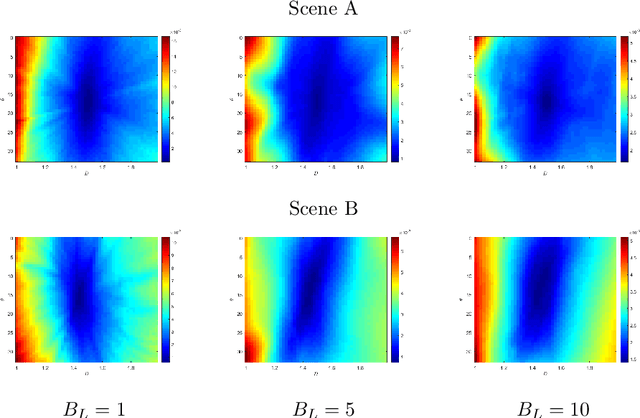
In this paper, we study the spectral properties of re-parameterized light field. Following previous studies of the light field spectrum, which notably provided sampling guidelines, we focus on the two plane parameterization of the light field. However, we introduce additional flexibility by allowing the image plane to be tilted and not only parallel. A formal theoretical analysis is first presented, which shows that more flexible sampling guidelines (i.e. wider camera baselines) can be used to sample the light field when adapting the image plane orientation to the scene geometry. We then present our simulations and results to support these theoretical findings. While the work introduced in this paper is mostly theoretical, we believe these new findings open exciting avenues for more practical application of light fields, such as view synthesis or compact representation.