 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Single-Photon Image Classification
Aug 13, 2020
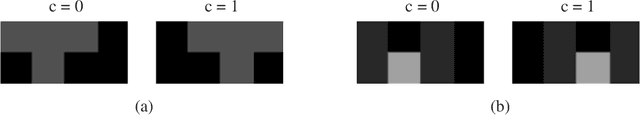
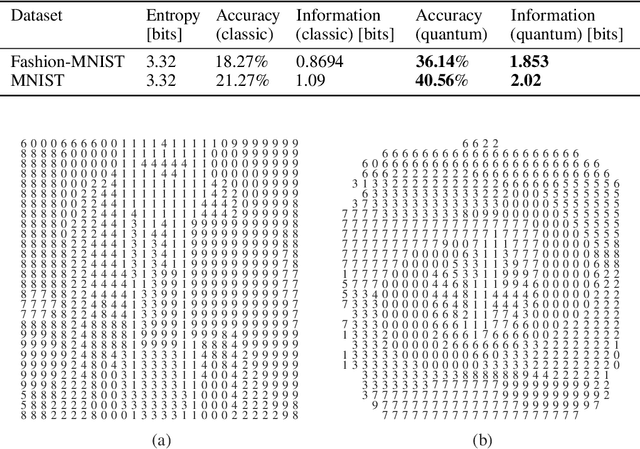
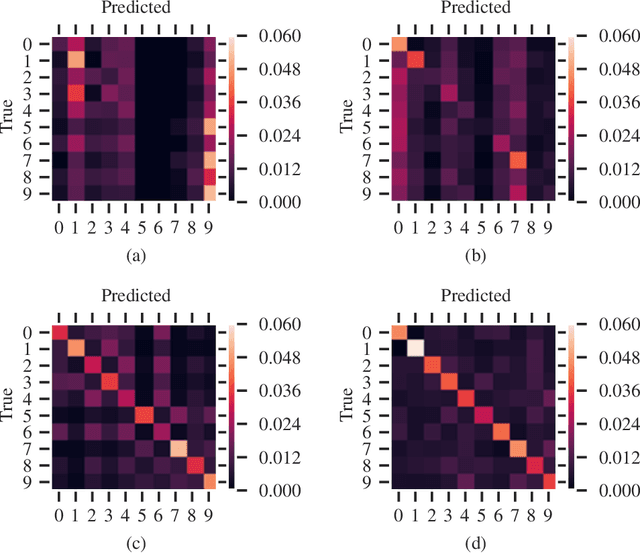

Quantum computing-based machine learning mainly focuses on quantum computing hardware that is experimentally challenging to realize due to requiring quantum gates that operate at very low temperature. Instead, we demonstrate the existence of a lower performance and much lower effort island on the accuracy-vs-qubits graph that may well be experimentally accessible with room temperature optics. This high temperature "quantum computing toy model" is nevertheless interesting to study as it allows rather accessible explanations of key concepts in quantum computing, in particular interference, entanglement, and the measurement process. We specifically study the problem of classifying an example from the MNIST and Fashion-MNIST datasets, subject to the constraint that we have to make a prediction after the detection of the very first photon that passed a coherently illuminated filter showing the example. Whereas a classical set-up in which a photon is detected after falling on one of the~$28\times 28$ image pixels is limited to a (maximum likelihood estimation) accuracy of~$21.27\%$ for MNIST, respectively $18.27\%$ for Fashion-MNIST, we show that the theoretically achievable accuracy when exploiting inference by optically transforming the quantum state of the photon is at least $41.27\%$ for MNIST, respectively $36.14\%$ for Fashion-MNIST. We show in detail how to train the corresponding transformation with TensorFlow and also explain how this example can serve as a teaching tool for the measurement process in quantum mechanics.
CBIR using Pre-Trained Neural Networks
Oct 27, 2021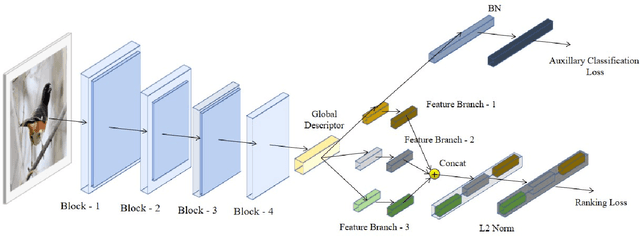

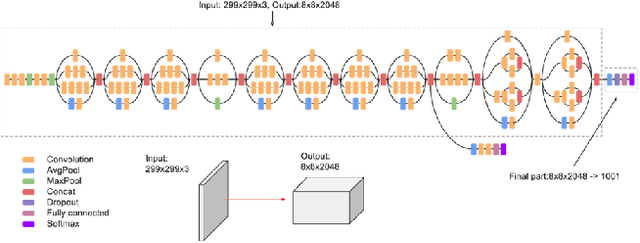
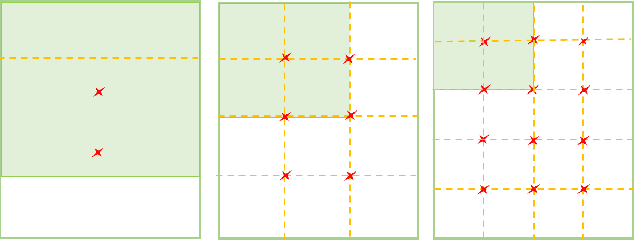
Much of the recent research work in image retrieval, has been focused around using Neural Networks as the core component. Many of the papers in other domain have shown that training multiple models, and then combining their outcomes, provide good results. This is since, a single Neural Network model, may not extract sufficient information from the input. In this paper, we aim to follow a different approach. Instead of the using a single model, we use a pretrained Inception V3 model, and extract activation of its last fully connected layer, which forms a low dimensional representation of the image. This feature matrix, is then divided into branches and separate feature extraction is done for each branch, to obtain multiple features flattened into a vector. Such individual vectors are then combined, to get a single combined feature. We make use of CUB200-2011 Dataset, which comprises of 200 birds classes to train the model on. We achieved a training accuracy of 99.46% and validation accuracy of 84.56% for the same. On further use of 3 branched global descriptors, we improve the validation accuracy to 88.89%. For this, we made use of MS-RMAC feature extraction method.
Interpretable Visual Understanding with Cognitive Attention Network
Aug 06, 2021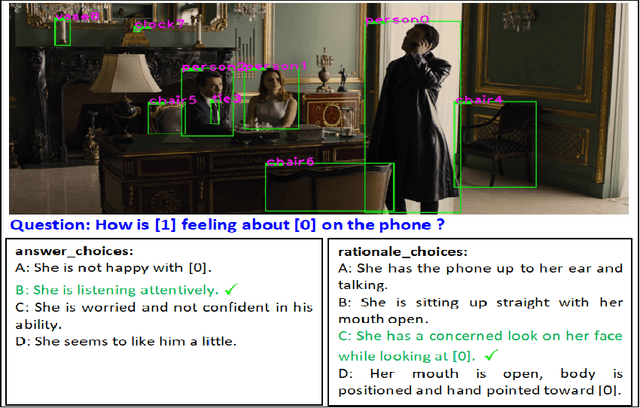
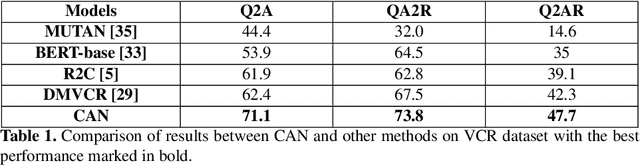
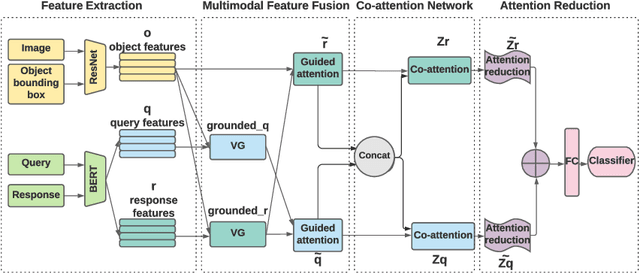
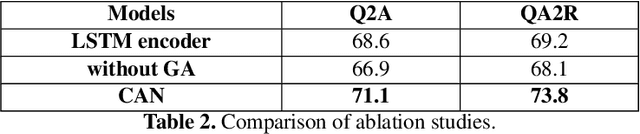
While image understanding on recognition-level has achieved remarkable advancements, reliable visual scene understanding requires comprehensive image understanding on recognition-level but also cognition-level, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge. In this paper, we propose a novel Cognitive Attention Network (CAN) for visual commonsense reasoning to achieve interpretable visual understanding. Specifically, we first introduce an image-text fusion module to fuse information from images and text collectively. Second, a novel inference module is designed to encode commonsense among image, query and response. Extensive experiments on large-scale Visual Commonsense Reasoning (VCR) benchmark dataset demonstrate the effectiveness of our approach. The implementation is publicly available at https://github.com/tanjatang/CAN
Progressively Volumetrized Deep Generative Models for Data-Efficient Contextual Learning of MR Image Recovery
Dec 03, 2020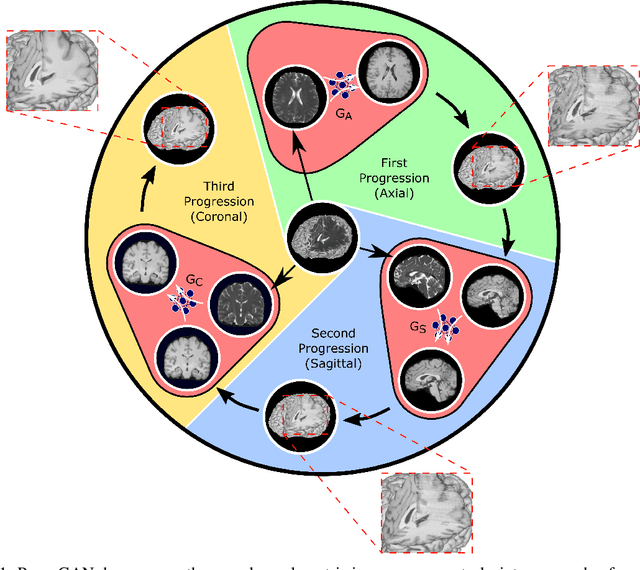
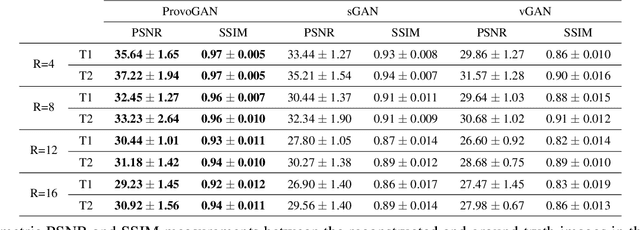

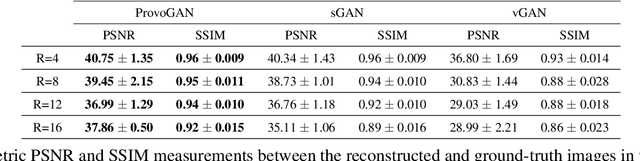
Magnetic resonance imaging (MRI) offers the flexibility to image a given anatomic volume under a multitude of tissue contrasts. Yet, scan time considerations put stringent limits on the quality and diversity of MRI data. The gold-standard approach to alleviate this limitation is to recover high-quality images from data undersampled across various dimensions such as the Fourier domain or contrast sets. A central divide among recovery methods is whether the anatomy is processed per volume or per cross-section. Volumetric models offer enhanced capture of global contextual information, but they can suffer from suboptimal learning due to elevated model complexity. Cross-sectional models with lower complexity offer improved learning behavior, yet they ignore contextual information across the longitudinal dimension of the volume. Here, we introduce a novel data-efficient progressively volumetrized generative model (ProvoGAN) that decomposes complex volumetric image recovery tasks into a series of simpler cross-sectional tasks across individual rectilinear dimensions. ProvoGAN effectively captures global context and recovers fine-structural details across all dimensions, while maintaining low model complexity and data-efficiency advantages of cross-sectional models. Comprehensive demonstrations on mainstream MRI reconstruction and synthesis tasks show that ProvoGAN yields superior performance to state-of-the-art volumetric and cross-sectional models.
Masked Feature Prediction for Self-Supervised Visual Pre-Training
Dec 16, 2021

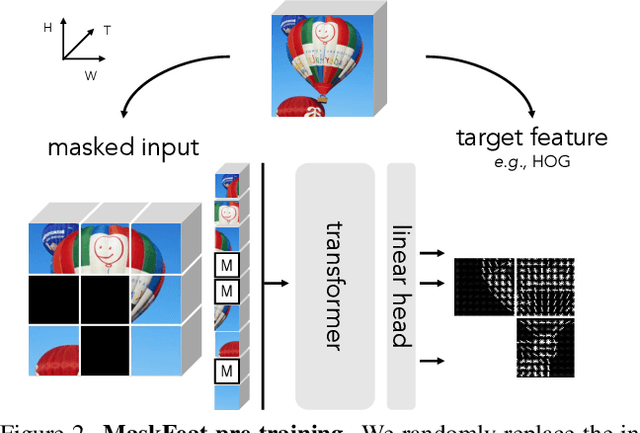
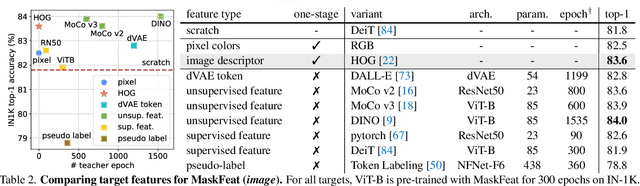
We present Masked Feature Prediction (MaskFeat) for self-supervised pre-training of video models. Our approach first randomly masks out a portion of the input sequence and then predicts the feature of the masked regions. We study five different types of features and find Histograms of Oriented Gradients (HOG), a hand-crafted feature descriptor, works particularly well in terms of both performance and efficiency. We observe that the local contrast normalization in HOG is essential for good results, which is in line with earlier work using HOG for visual recognition. Our approach can learn abundant visual knowledge and drive large-scale Transformer-based models. Without using extra model weights or supervision, MaskFeat pre-trained on unlabeled videos achieves unprecedented results of 86.7% with MViT-L on Kinetics-400, 88.3% on Kinetics-600, 80.4% on Kinetics-700, 38.8 mAP on AVA, and 75.0% on SSv2. MaskFeat further generalizes to image input, which can be interpreted as a video with a single frame and obtains competitive results on ImageNet.
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
Dec 16, 2021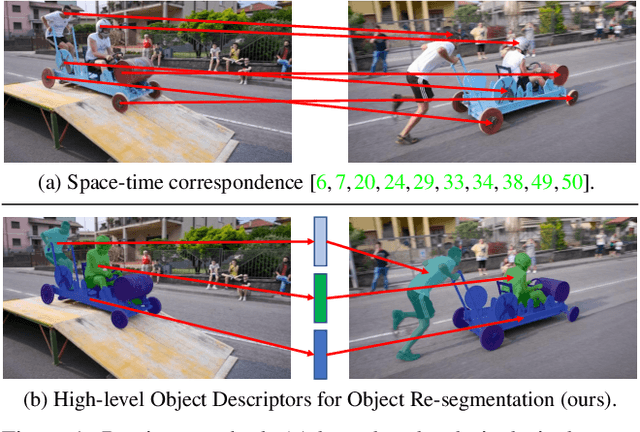
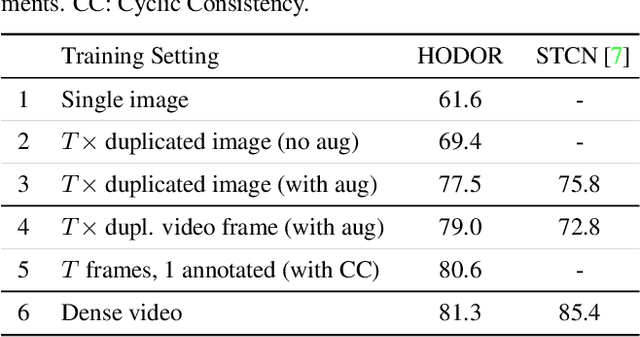

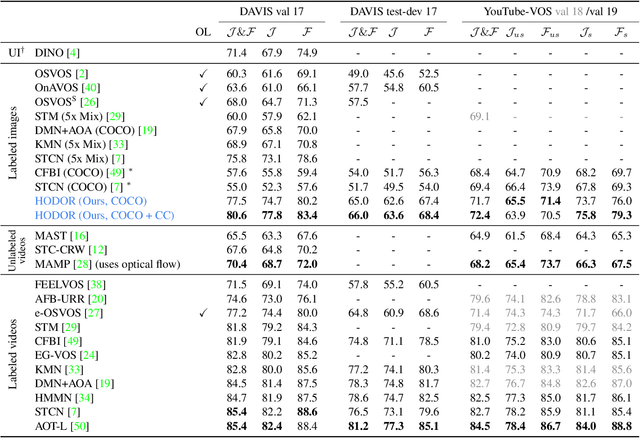
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
Hotel Recognition via Latent Image Embedding
Jun 15, 2021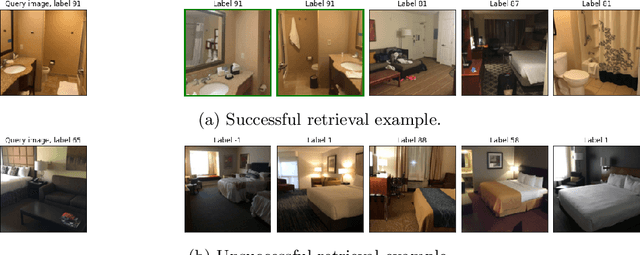
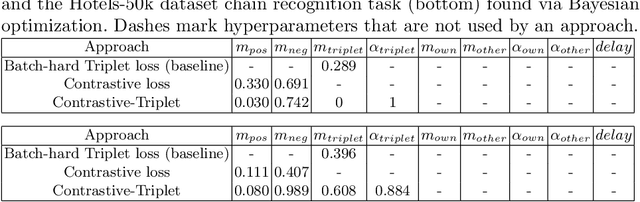
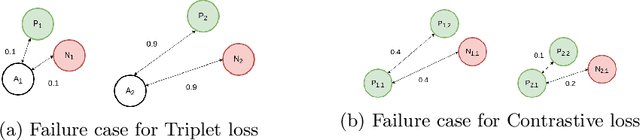
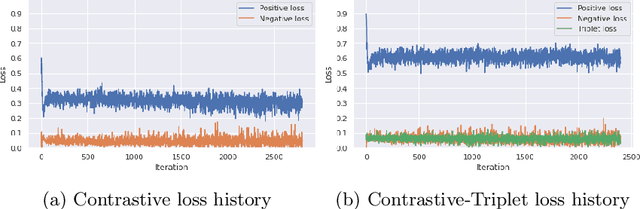
We approach the problem of hotel recognition with deep metric learning. We overview the existing approaches and propose a modification to Contrastive loss called Contrastive-Triplet loss. We construct a robust pipeline for benchmarking metric learning models and perform experiments on Hotels-50K and CUB200 datasets. Contrastive-Triplet loss is shown to achieve better retrieval on Hotels-50k. We open-source our code.
Solving Inverse Problems with NerfGANs
Dec 16, 2021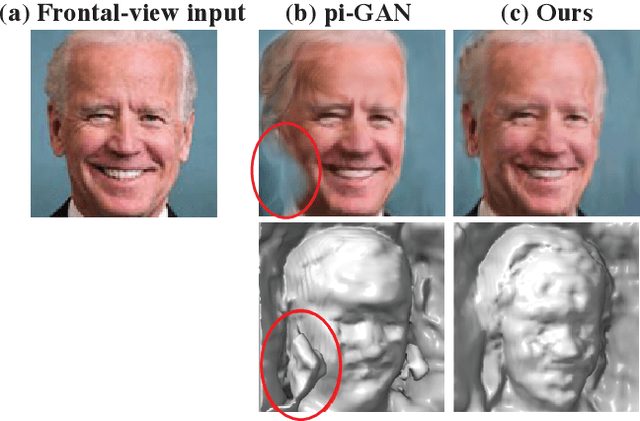
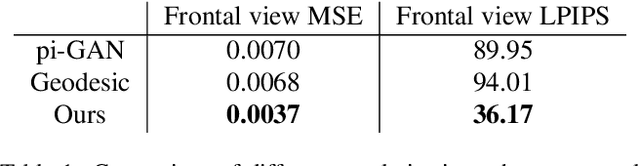

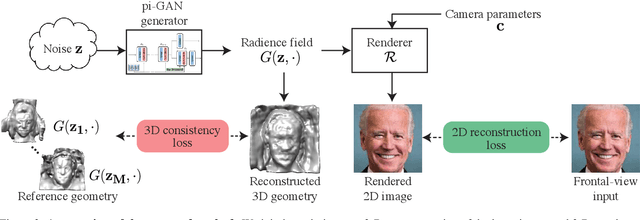
We introduce a novel framework for solving inverse problems using NeRF-style generative models. We are interested in the problem of 3-D scene reconstruction given a single 2-D image and known camera parameters. We show that naively optimizing the latent space leads to artifacts and poor novel view rendering. We attribute this problem to volume obstructions that are clear in the 3-D geometry and become visible in the renderings of novel views. We propose a novel radiance field regularization method to obtain better 3-D surfaces and improved novel views given single view observations. Our method naturally extends to general inverse problems including inpainting where one observes only partially a single view. We experimentally evaluate our method, achieving visual improvements and performance boosts over the baselines in a wide range of tasks. Our method achieves $30-40\%$ MSE reduction and $15-25\%$ reduction in LPIPS loss compared to the previous state of the art.
Deep Denoising Method for Side Scan Sonar Images without High-quality Reference Data
Aug 27, 2021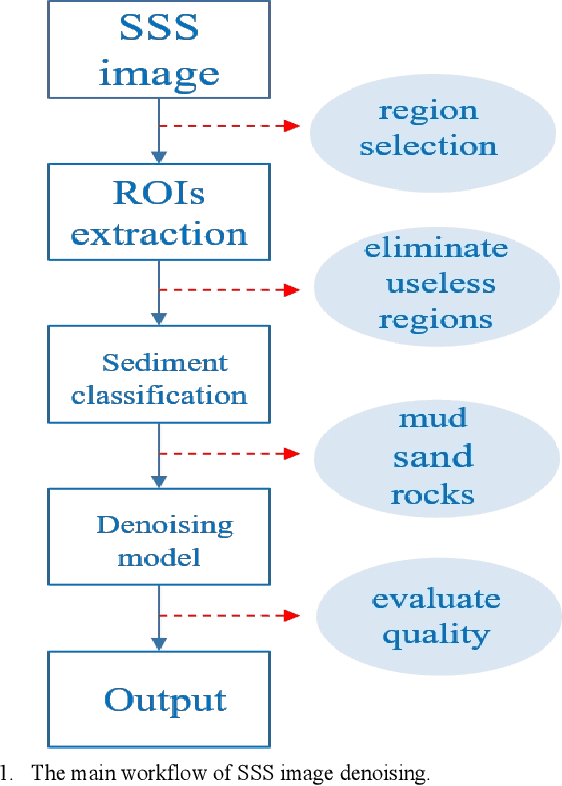
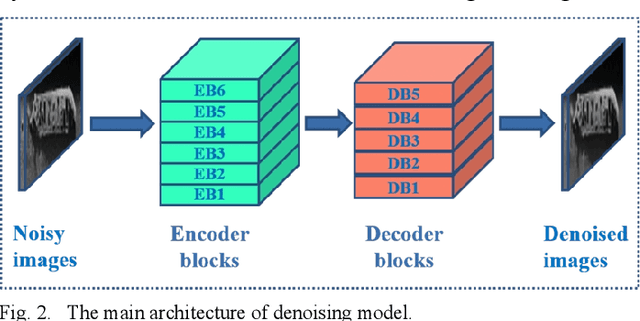


Subsea images measured by the side scan sonars (SSSs) are necessary visual data in the process of deep-sea exploration by using the autonomous underwater vehicles (AUVs). They could vividly reflect the topography of the seabed, but usually accompanied by complex and severe noise. This paper proposes a deep denoising method for SSS images without high-quality reference data, which uses one single noise SSS image to perform self-supervised denoising. Compared with the classical artificially designed filters, the deep denoising method shows obvious advantages. The denoising experiments are performed on the real seabed SSS images, and the results demonstrate that our proposed method could effectively reduce the noise on the SSS image while minimizing the image quality and detail loss.
Certifiable Artificial Intelligence Through Data Fusion
Nov 03, 2021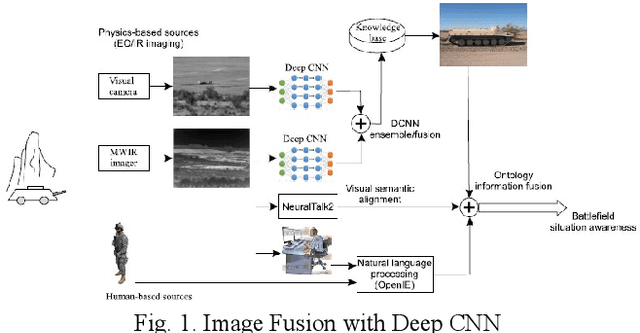
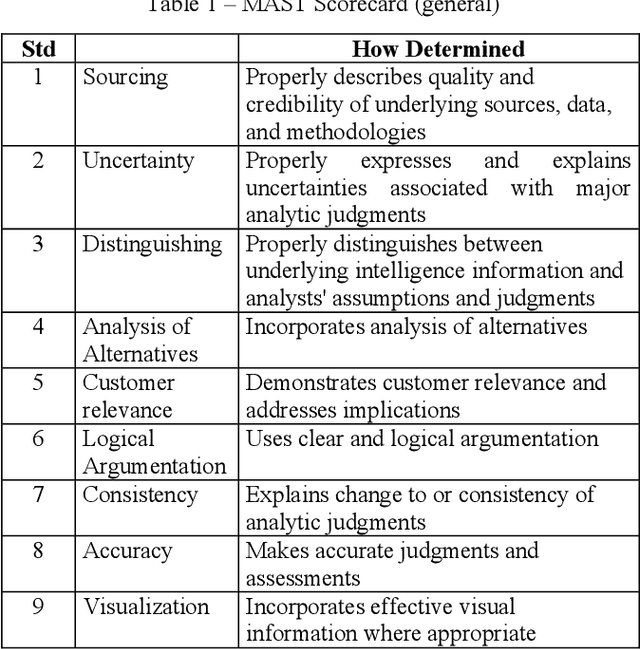
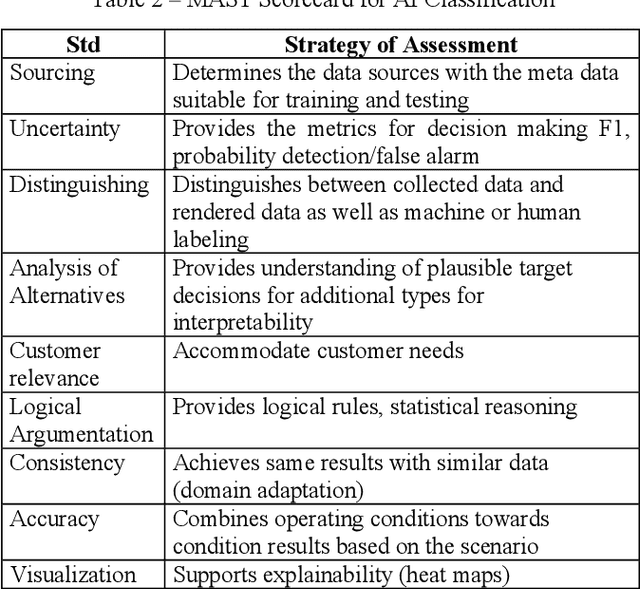
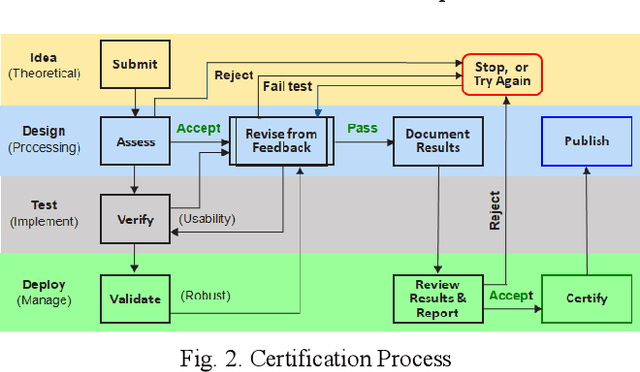
This paper reviews and proposes concerns in adopting, fielding, and maintaining artificial intelligence (AI) systems. While the AI community has made rapid progress, there are challenges in certifying AI systems. Using procedures from design and operational test and evaluation, there are opportunities towards determining performance bounds to manage expectations of intended use. A notional use case is presented with image data fusion to support AI object recognition certifiability considering precision versus distance.