 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lacuna Reconstruction: Self-supervised Pre-training for Low-Resource Historical Document Transcription
Dec 16, 2021

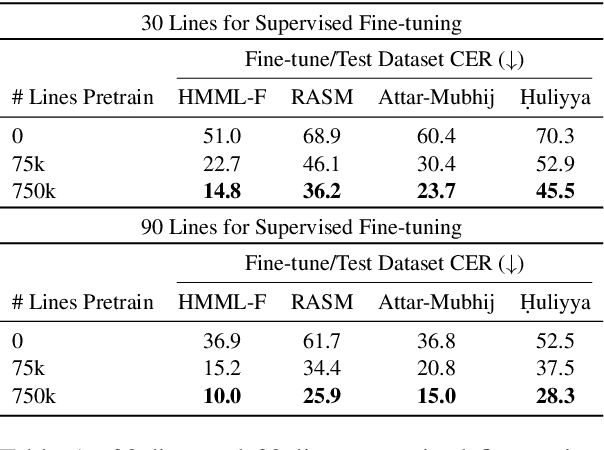
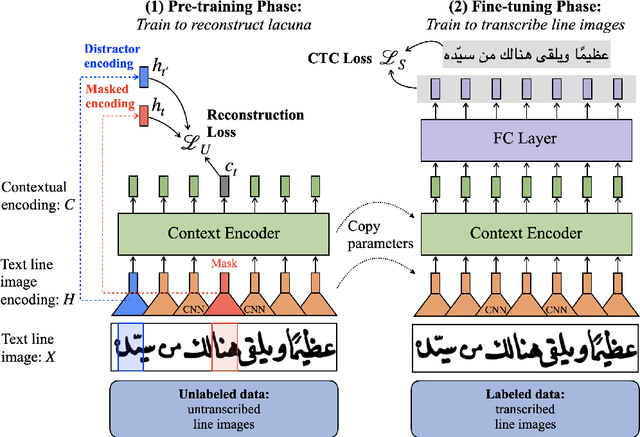

We present a self-supervised pre-training approach for learning rich visual language representations for both handwritten and printed historical document transcription. After supervised fine-tuning of our pre-trained encoder representations for low-resource document transcription on two languages, (1) a heterogeneous set of handwritten Islamicate manuscript images and (2) early modern English printed documents, we show a meaningful improvement in recognition accuracy over the same supervised model trained from scratch with as few as 30 line image transcriptions for training. Our masked language model-style pre-training strategy, where the model is trained to be able to identify the true masked visual representation from distractors sampled from within the same line, encourages learning robust contextualized language representations invariant to scribal writing style and printing noise present across documents.
Reversible adversarial examples against local visual perturbation
Oct 06, 2021
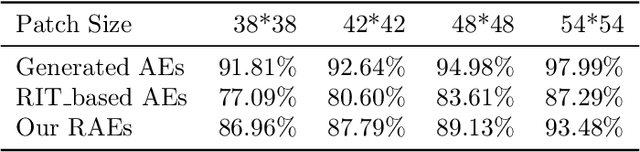
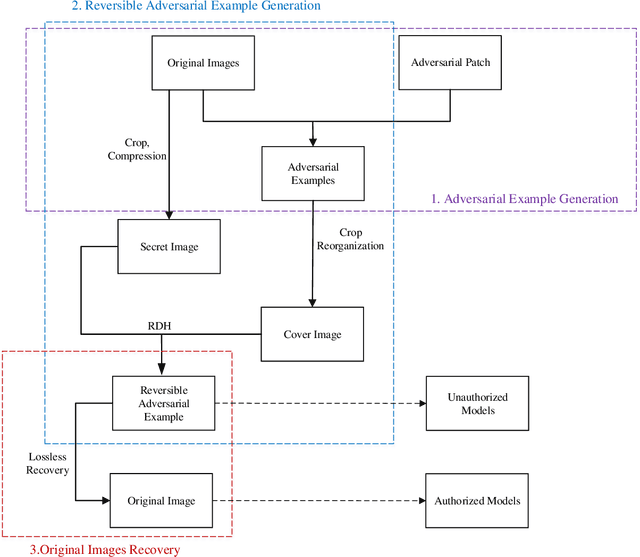

Recently, studies have indicated that adversarial attacks pose a threat to deep learning systems. However, when there are only adversarial examples, people cannot get the original images, so there is research on reversible adversarial attacks. However, the existing strategies are aimed at invisible adversarial perturbation, and do not consider the case of locally visible adversarial perturbation. In this article, we generate reversible adversarial examples for local visual adversarial perturbation, and use reversible data embedding technology to embed the information needed to restore the original image into the adversarial examples to generate examples that are both adversarial and reversible. Experiments on ImageNet dataset show that our method can restore the original image losslessly while ensuring the attack capability.
Blood vessel segmentation in en-face OCTA images: a frequency based method
Sep 13, 2021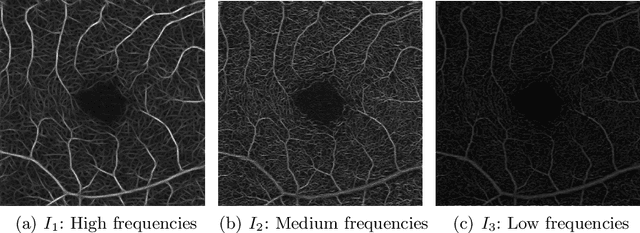
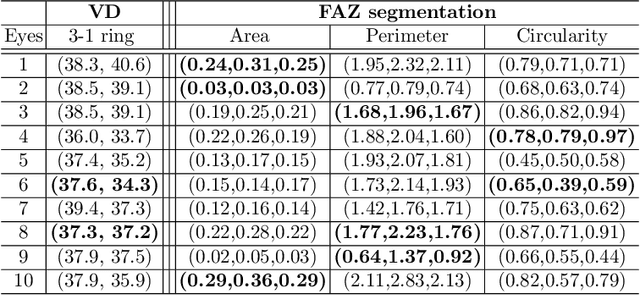
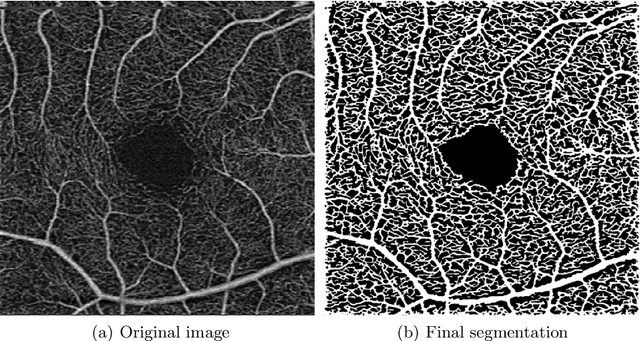
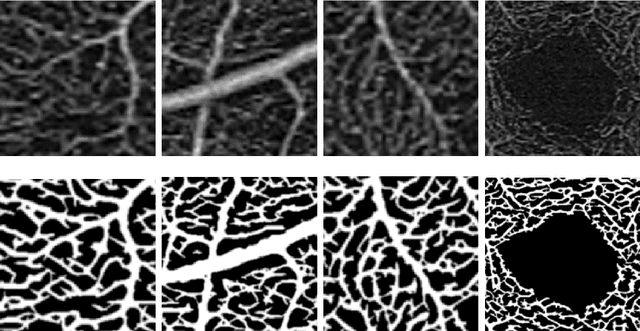
Optical coherence tomography angiography (OCTA) is a novel noninvasive imaging modality for visualization of retinal blood flow in the human retina. Using specific OCTA imaging biomarkers for the identification of pathologies, automated image segmentations of the blood vessels can improve subsequent analysis and diagnosis. We present a novel method for the vessel identification based on frequency representations of the image, in particular, using so-called Gabor filter banks. The algorithm is evaluated on an OCTA image data set from $10$ eyes acquired by a Cirrus HD-OCT device. The segmentation outcomes received very good qualitative visual evaluation feedback and coincide well with device-specific values concerning vessel density. Concerning locality our segmentations are even more reliable and accurate. Therefore, we suggest the computation of adaptive local vessel density maps that allow straightforward analysis of retinal blood flow.
Creating A Coefficient of Change in the Built Environment After a Natural Disaster
Oct 31, 2021
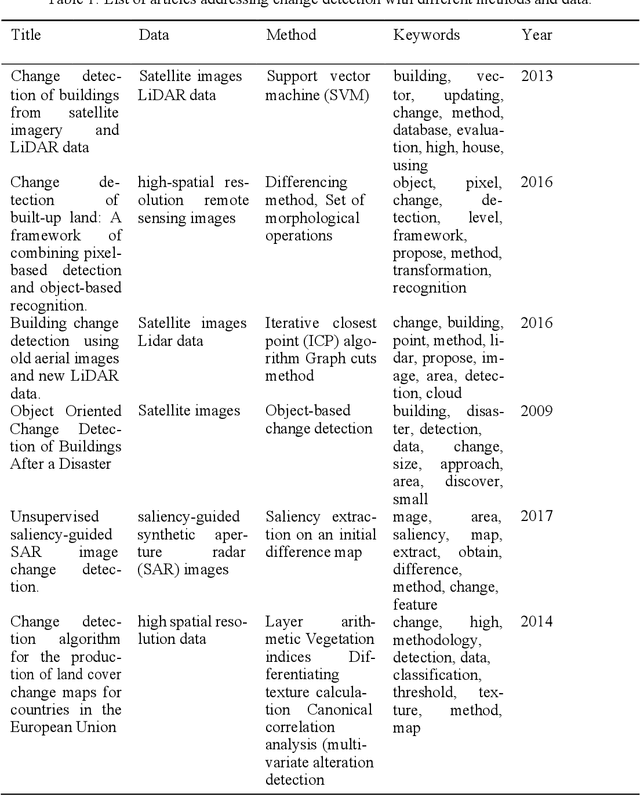

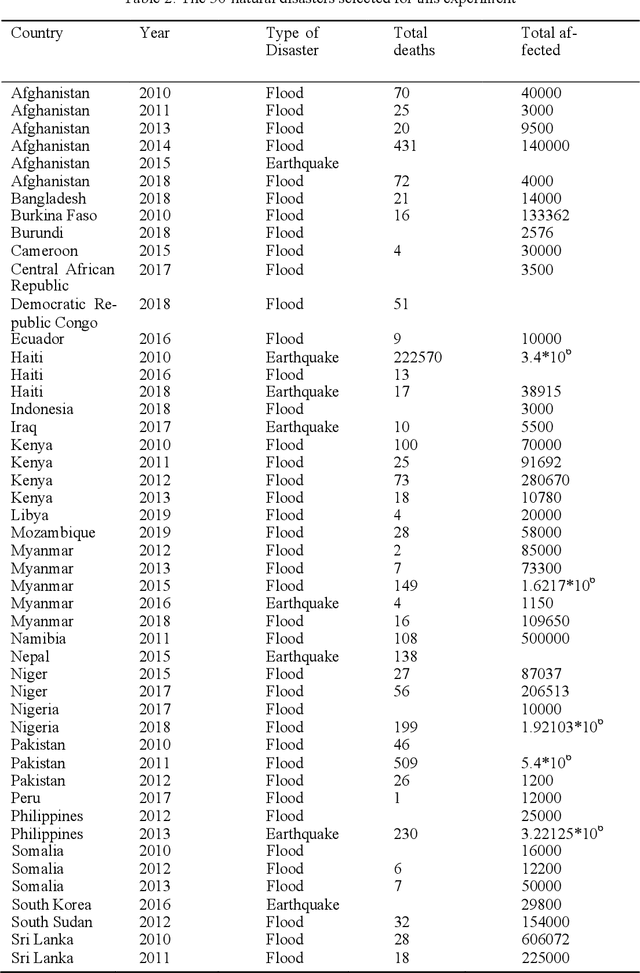
This study proposes a novel method to assess damages in the built environment using a deep learning workflow to quantify it. Thanks to an automated crawler, aerial images from before and after a natural disaster of 50 epicenters worldwide were obtained from Google Earth, generating a 10,000 aerial image database with a spatial resolution of 2 m per pixel. The study utilizes the algorithm Seg-Net to perform semantic segmentation of the built environment from the satellite images in both instances (prior and post-natural disasters). For image segmentation, Seg-Net is one of the most popular and general CNN architectures. The Seg-Net algorithm used reached an accuracy of 92% in the segmentation. After the segmentation, we compared the disparity between both cases represented as a percentage of change. Such coefficient of change represents the damage numerically an urban environment had to quantify the overall damage in the built environment. Such an index can give the government an estimate of the number of affected households and perhaps the extent of housing damage.
Multi-Level Graph Convolutional Network with Automatic Graph Learning for Hyperspectral Image Classification
Sep 19, 2020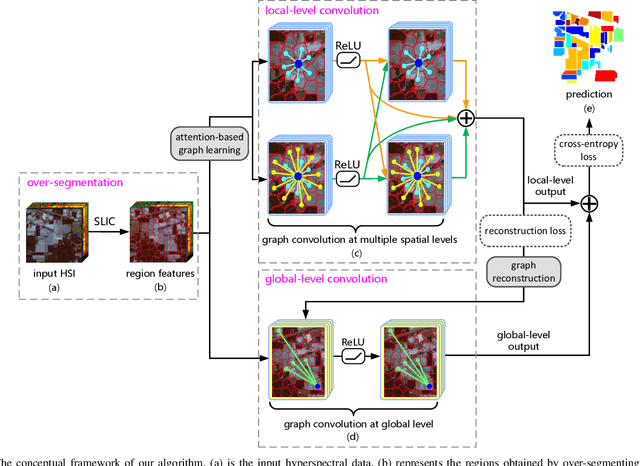
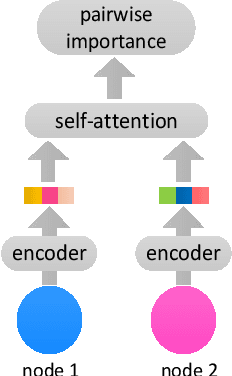
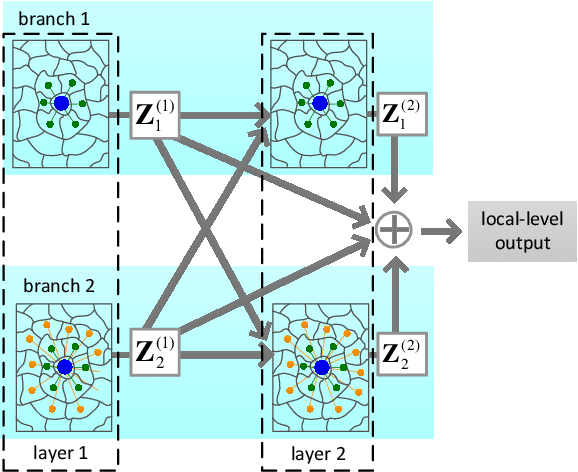
Nowadays, deep learning methods, especially the Graph Convolutional Network (GCN), have shown impressive performance in hyperspectral image (HSI) classification. However, the current GCN-based methods treat graph construction and image classification as two separate tasks, which often results in suboptimal performance. Another defect of these methods is that they mainly focus on modeling the local pairwise importance between graph nodes while lack the capability to capture the global contextual information of HSI. In this paper, we propose a Multi-level GCN with Automatic Graph Learning method (MGCN-AGL) for HSI classification, which can automatically learn the graph information at both local and global levels. By employing attention mechanism to characterize the importance among spatially neighboring regions, the most relevant information can be adaptively incorporated to make decisions, which helps encode the spatial context to form the graph information at local level. Moreover, we utilize multiple pathways for local-level graph convolution, in order to leverage the merits from the diverse spatial context of HSI and to enhance the expressive power of the generated representations. To reconstruct the global contextual relations, our MGCN-AGL encodes the long range dependencies among image regions based on the expressive representations that have been produced at local level. Then inference can be performed along the reconstructed graph edges connecting faraway regions. Finally, the multi-level information is adaptively fused to generate the network output. In this means, the graph learning and image classification can be integrated into a unified framework and benefit each other. Extensive experiments have been conducted on three real-world hyperspectral datasets, which are shown to outperform the state-of-the-art methods.
Zoom-to-Inpaint: Image Inpainting with High Frequency Details
Dec 17, 2020

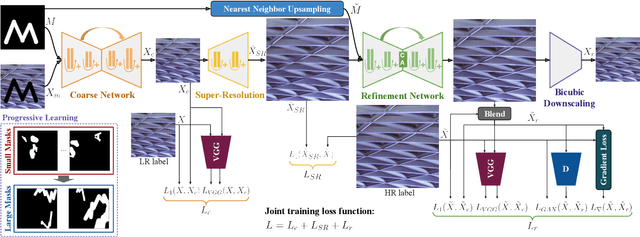
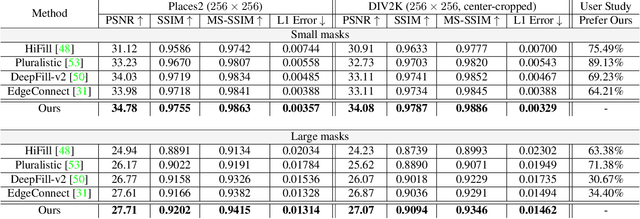
Although deep learning has enabled a huge leap forward in image inpainting, current methods are often unable to synthesize realistic high-frequency details. In this paper, we propose applying super resolution to coarsely reconstructed outputs, refining them at high resolution, and then downscaling the output to the original resolution. By introducing high-resolution images to the refinement network, our framework is able to reconstruct finer details that are usually smoothed out due to spectral bias - the tendency of neural networks to reconstruct low frequencies better than high frequencies. To assist training the refinement network on large upscaled holes, we propose a progressive learning technique in which the size of the missing regions increases as training progresses. Our zoom-in, refine and zoom-out strategy, combined with high-resolution supervision and progressive learning, constitutes a framework-agnostic approach for enhancing high-frequency details that can be applied to other inpainting methods. We provide qualitative and quantitative evaluations along with an ablation analysis to show the effectiveness of our approach, which outperforms state-of-the-art inpainting methods.
Best Practices and Scoring System on Reviewing A.I. based Medical Imaging Papers: Part 1 Classification
Feb 03, 2022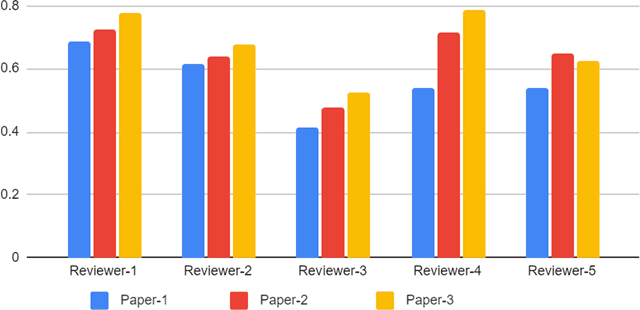
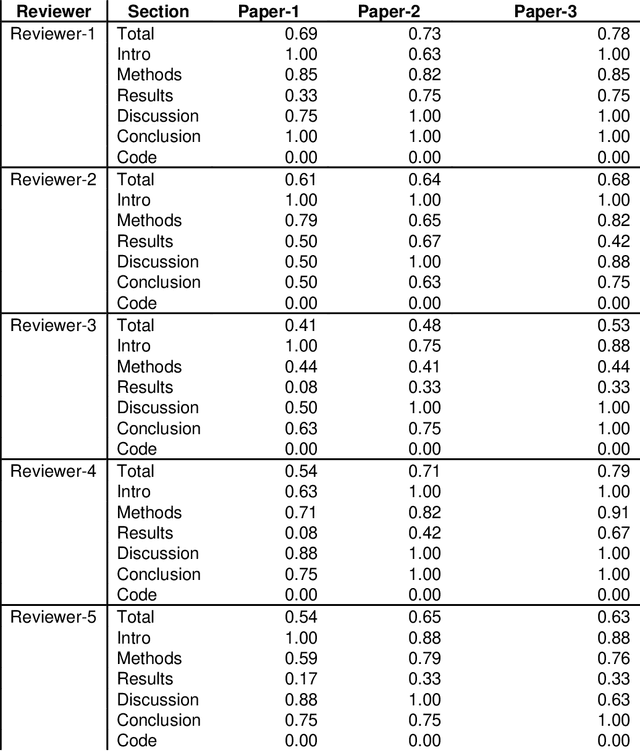
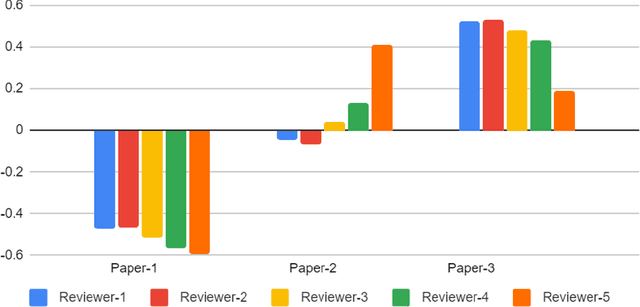
With the recent advances in A.I. methodologies and their application to medical imaging, there has been an explosion of related research programs utilizing these techniques to produce state-of-the-art classification performance. Ultimately, these research programs culminate in submission of their work for consideration in peer reviewed journals. To date, the criteria for acceptance vs. rejection is often subjective; however, reproducible science requires reproducible review. The Machine Learning Education Sub-Committee of SIIM has identified a knowledge gap and a serious need to establish guidelines for reviewing these studies. Although there have been several recent papers with this goal, this present work is written from the machine learning practitioners standpoint. In this series, the committee will address the best practices to be followed in an A.I.-based study and present the required sections in terms of examples and discussion of what should be included to make the studies cohesive, reproducible, accurate, and self-contained. This first entry in the series focuses on the task of image classification. Elements such as dataset curation, data pre-processing steps, defining an appropriate reference standard, data partitioning, model architecture and training are discussed. The sections are presented as they would be detailed in a typical manuscript, with content describing the necessary information that should be included to make sure the study is of sufficient quality to be considered for publication. The goal of this series is to provide resources to not only help improve the review process for A.I.-based medical imaging papers, but to facilitate a standard for the information that is presented within all components of the research study. We hope to provide quantitative metrics in what otherwise may be a qualitative review process.
Conditional Variational Autoencoder with Balanced Pre-training for Generative Adversarial Networks
Jan 13, 2022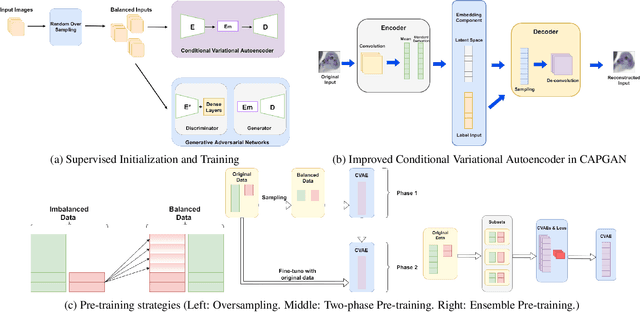
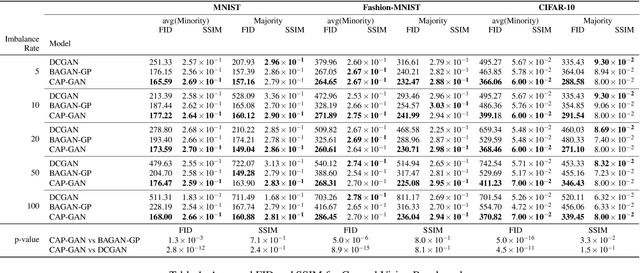
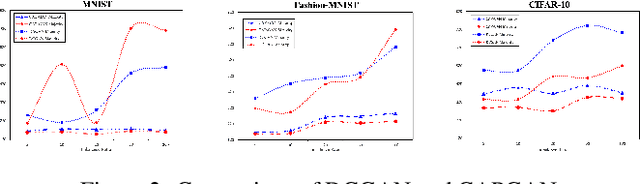
Class imbalance occurs in many real-world applications, including image classification, where the number of images in each class differs significantly. With imbalanced data, the generative adversarial networks (GANs) leans to majority class samples. The two recent methods, Balancing GAN (BAGAN) and improved BAGAN (BAGAN-GP), are proposed as an augmentation tool to handle this problem and restore the balance to the data. The former pre-trains the autoencoder weights in an unsupervised manner. However, it is unstable when the images from different categories have similar features. The latter is improved based on BAGAN by facilitating supervised autoencoder training, but the pre-training is biased towards the majority classes. In this work, we propose a novel Conditional Variational Autoencoder with Balanced Pre-training for Generative Adversarial Networks (CAPGAN) as an augmentation tool to generate realistic synthetic images. In particular, we utilize a conditional convolutional variational autoencoder with supervised and balanced pre-training for the GAN initialization and training with gradient penalty. Our proposed method presents a superior performance of other state-of-the-art methods on the highly imbalanced version of MNIST, Fashion-MNIST, CIFAR-10, and two medical imaging datasets. Our method can synthesize high-quality minority samples in terms of Fr\'echet inception distance, structural similarity index measure and perceptual quality.
SubOmiEmbed: Self-supervised Representation Learning of Multi-omics Data for Cancer Type Classification
Feb 03, 2022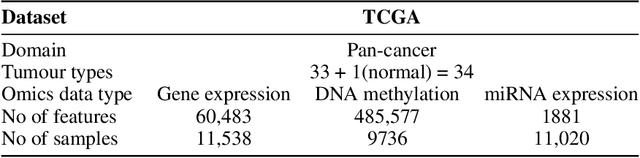
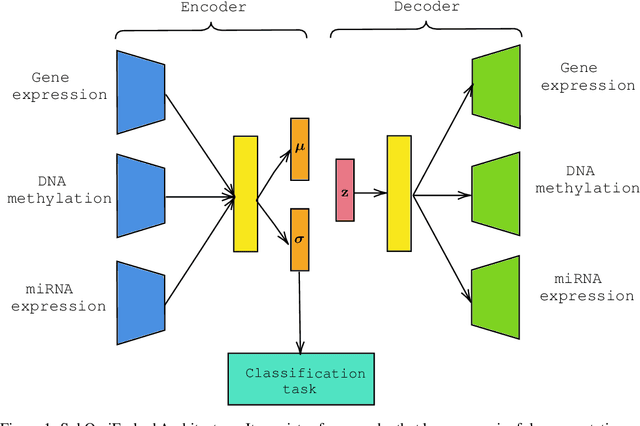
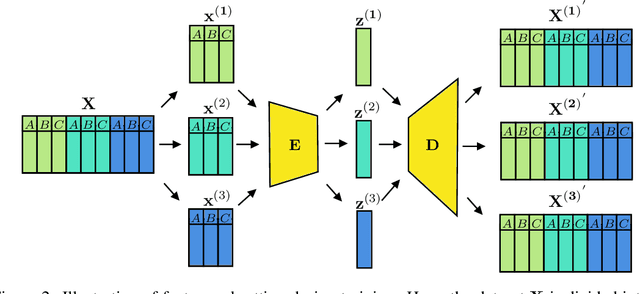

For personalized medicines, very crucial intrinsic information is present in high dimensional omics data which is difficult to capture due to the large number of molecular features and small number of available samples. Different types of omics data show various aspects of samples. Integration and analysis of multi-omics data give us a broad view of tumours, which can improve clinical decision making. Omics data, mainly DNA methylation and gene expression profiles are usually high dimensional data with a lot of molecular features. In recent years, variational autoencoders (VAE) have been extensively used in embedding image and text data into lower dimensional latent spaces. In our project, we extend the idea of using a VAE model for low dimensional latent space extraction with the self-supervised learning technique of feature subsetting. With VAEs, the key idea is to make the model learn meaningful representations from different types of omics data, which could then be used for downstream tasks such as cancer type classification. The main goals are to overcome the curse of dimensionality and integrate methylation and expression data to combine information about different aspects of same tissue samples, and hopefully extract biologically relevant features. Our extension involves training encoder and decoder to reconstruct the data from just a subset of it. By doing this, we force the model to encode most important information in the latent representation. We also added an identity to the subsets so that the model knows which subset is being fed into it during training and testing. We experimented with our approach and found that SubOmiEmbed produces comparable results to the baseline OmiEmbed with a much smaller network and by using just a subset of the data. This work can be improved to integrate mutation-based genomic data as well.
Illegible Text to Readable Text: An Image-to-Image Transformation using Conditional Sliced Wasserstein Adversarial Networks
Oct 11, 2019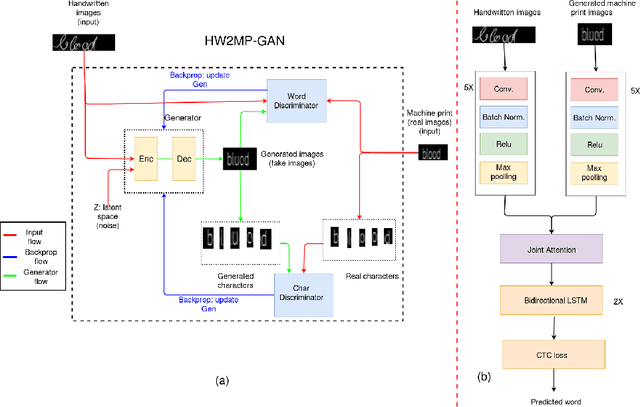
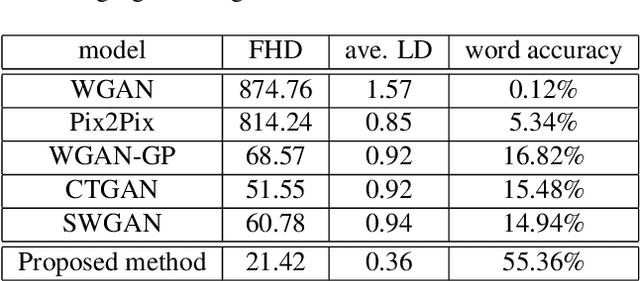


Automatic text recognition from ancient handwritten record images is an important problem in the genealogy domain. However, critical challenges such as varying noise conditions, vanishing texts, and variations in handwriting make the recognition task difficult. We tackle this problem by developing a handwritten-to-machine-print conditional Generative Adversarial network (HW2MP-GAN) model that formulates handwritten recognition as a text-Image-to-text-Image translation problem where a given image, typically in an illegible form, is converted into another image, close to its machine-print form. The proposed model consists of three-components including a generator, and word-level and character-level discriminators. The model incorporates Sliced Wasserstein distance (SWD) and U-Net architectures in HW2MP-GAN for better quality image-to-image transformation. Our experiments reveal that HW2MP-GAN outperforms state-of-the-art baseline cGAN models by almost 30 in Frechet Handwritten Distance (FHD), 0.6 on average Levenshtein distance and 39% in word accuracy for image-to-image translation on IAM database. Further, HW2MP-GAN improves handwritten recognition word accuracy by 1.3% compared to baseline handwritten recognition models on the IAM database.