 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AIDE: Annotation-efficient deep learning for automatic medical image segmentation
Dec 14, 2020
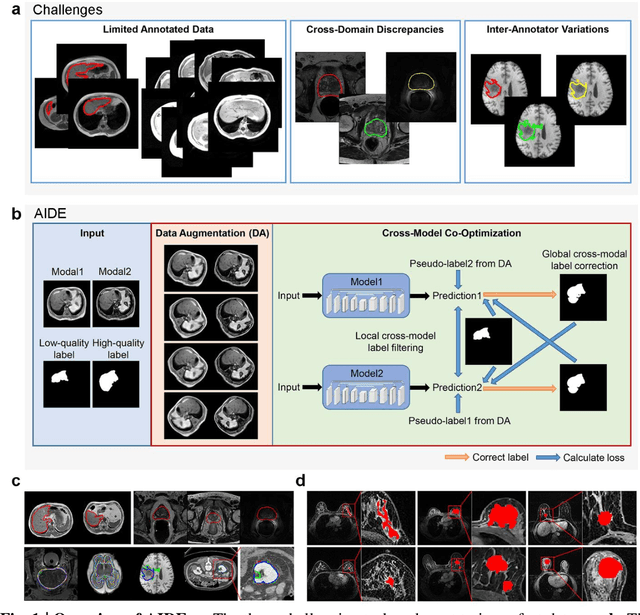
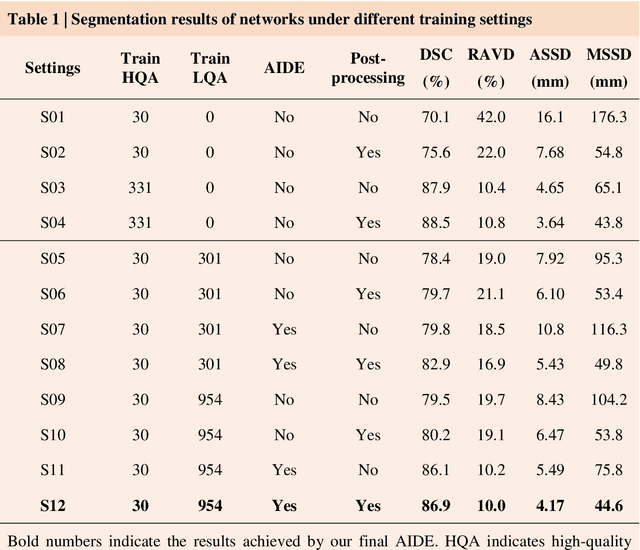
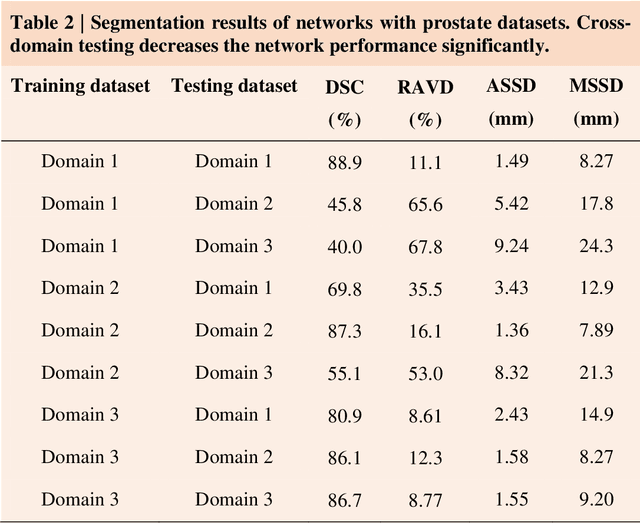
Accurate image segmentation is crucial for medical imaging applications. The prevailing deep learning approaches typically rely on very large training datasets with high-quality manual annotations, which are often not available in medical imaging. We introduce Annotation-effIcient Deep lEarning (AIDE) to handle imperfect datasets with an elaborately designed cross-model self-correcting mechanism. AIDE improves the segmentation Dice scores of conventional deep learning models on open datasets possessing scarce or noisy annotations by up to 30%. For three clinical datasets containing 11,852 breast images of 872 patients from three medical centers, AIDE consistently produces segmentation maps comparable to those generated by the fully supervised counterparts as well as the manual annotations of independent radiologists by utilizing only 10% training annotations. Such a 10-fold improvement of efficiency in utilizing experts' labels has the potential to promote a wide range of biomedical applications.
Unsupervised Brain Abnormality Detection Using High Fidelity Image Reconstruction Networks
May 26, 2020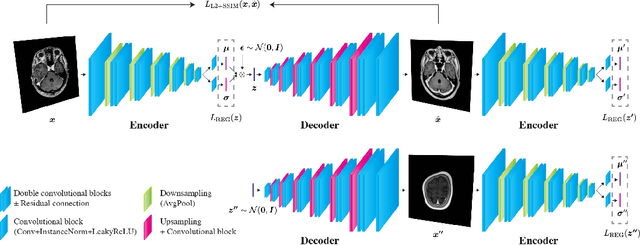

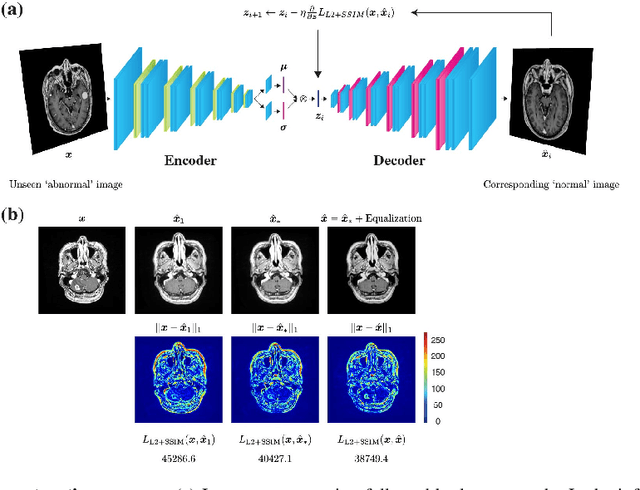
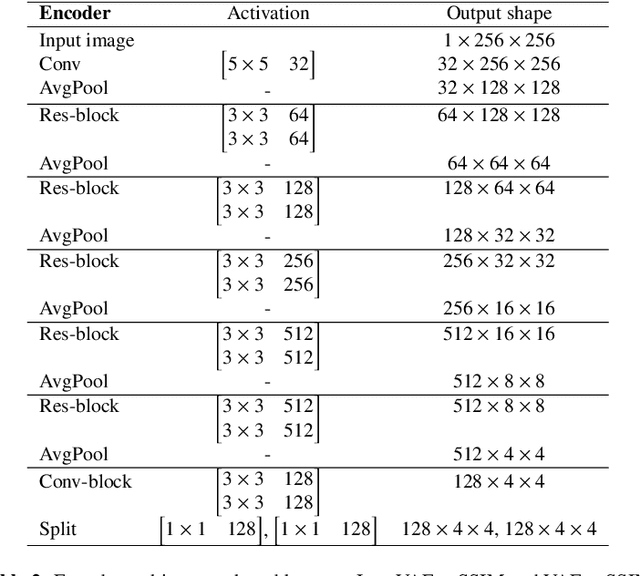
Recent advances in deep learning have facilitated near-expert medical image analysis. Supervised learning is the mainstay of current approaches, though its success requires the use of large, fully labeled datasets. However, in real-world medical practice, previously unseen disease phenotypes are encountered that have not been defined a priori in finite-size datasets. Unsupervised learning, a hypothesis-free learning framework, may play a complementary role to supervised learning. Here, we demonstrate a novel framework for voxel-wise abnormality detection in brain magnetic resonance imaging (MRI), which exploits an image reconstruction network based on an introspective variational autoencoder trained with a structural similarity constraint. The proposed network learns a latent representation for "normal" anatomical variation using a series of images that do not include annotated abnormalities. After training, the network can map unseen query images to positions in the latent space, and latent variables sampled from those positions can be mapped back to the image space to yield normal-looking replicas of the input images. Finally, the network considers abnormality scores, which are designed to reflect differences at several image feature levels, in order to locate image regions that may contain abnormalities. The proposed method is evaluated on a comprehensively annotated dataset spanning clinically significant structural abnormalities of the brain parenchyma in a population having undergone radiotherapy for brain metastasis, demonstrating that it is particularly effective for contrast-enhanced lesions, i.e., metastatic brain tumors and extracranial metastatic tumors.
Wav2CLIP: Learning Robust Audio Representations From CLIP
Oct 21, 2021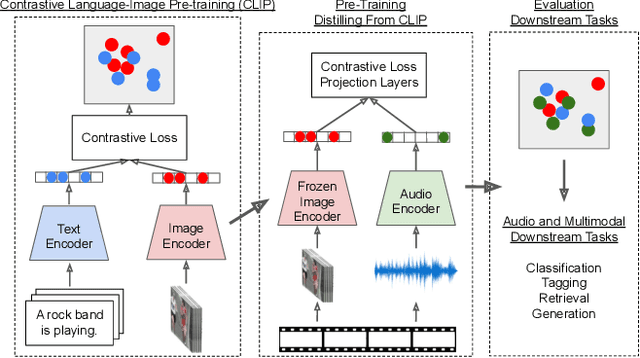
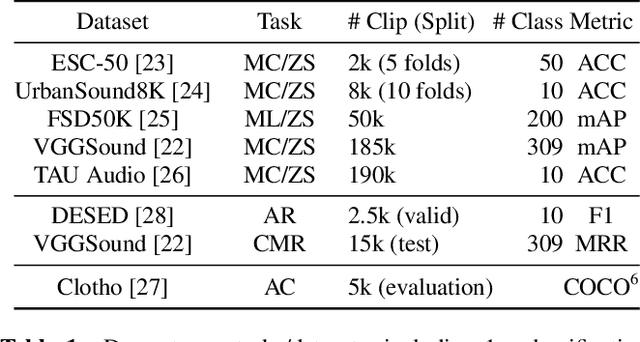
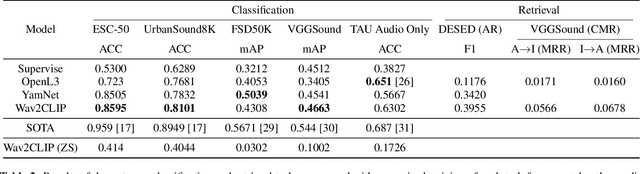
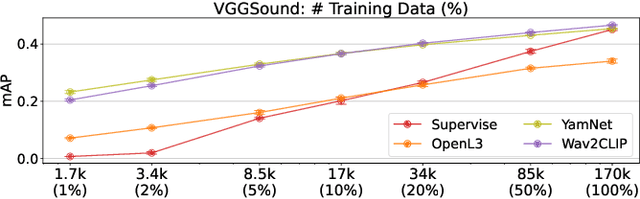
We propose Wav2CLIP, a robust audio representation learning method by distilling from Contrastive Language-Image Pre-training (CLIP). We systematically evaluate Wav2CLIP on a variety of audio tasks including classification, retrieval, and generation, and show that Wav2CLIP can outperform several publicly available pre-trained audio representation algorithms. Wav2CLIP projects audio into a shared embedding space with images and text, which enables multimodal applications such as zero-shot classification, and cross-modal retrieval. Furthermore, Wav2CLIP needs just ~10% of the data to achieve competitive performance on downstream tasks compared with fully supervised models, and is more efficient to pre-train than competing methods as it does not require learning a visual model in concert with an auditory model. Finally, we demonstrate image generation from Wav2CLIP as qualitative assessment of the shared embedding space. Our code and model weights are open sourced and made available for further applications.
The Way to my Heart is through Contrastive Learning: Remote Photoplethysmography from Unlabelled Video
Nov 18, 2021



The ability to reliably estimate physiological signals from video is a powerful tool in low-cost, pre-clinical health monitoring. In this work we propose a new approach to remote photoplethysmography (rPPG) - the measurement of blood volume changes from observations of a person's face or skin. Similar to current state-of-the-art methods for rPPG, we apply neural networks to learn deep representations with invariance to nuisance image variation. In contrast to such methods, we employ a fully self-supervised training approach, which has no reliance on expensive ground truth physiological training data. Our proposed method uses contrastive learning with a weak prior over the frequency and temporal smoothness of the target signal of interest. We evaluate our approach on four rPPG datasets, showing that comparable or better results can be achieved compared to recent supervised deep learning methods but without using any annotation. In addition, we incorporate a learned saliency resampling module into both our unsupervised approach and supervised baseline. We show that by allowing the model to learn where to sample the input image, we can reduce the need for hand-engineered features while providing some interpretability into the model's behavior and possible failure modes. We release code for our complete training and evaluation pipeline to encourage reproducible progress in this exciting new direction.
* Code available at https://github.com/ToyotaResearchInstitute/RemotePPG
An Adversarial Learning Based Approach for Unknown View Tomographic Reconstruction
Aug 23, 2021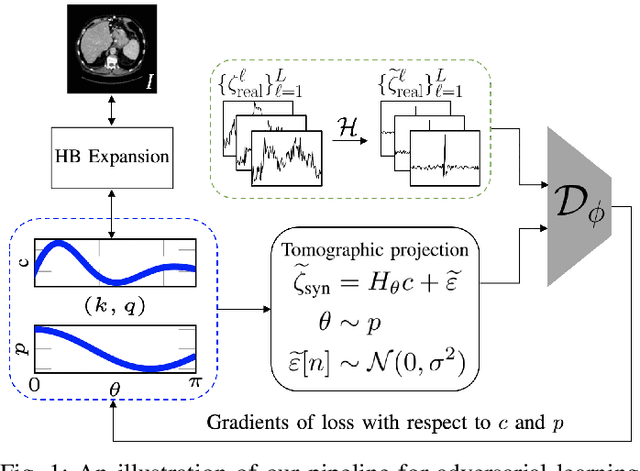
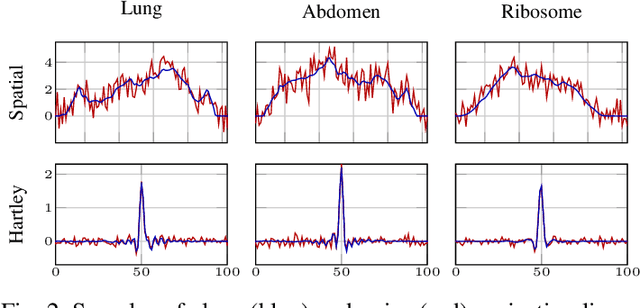

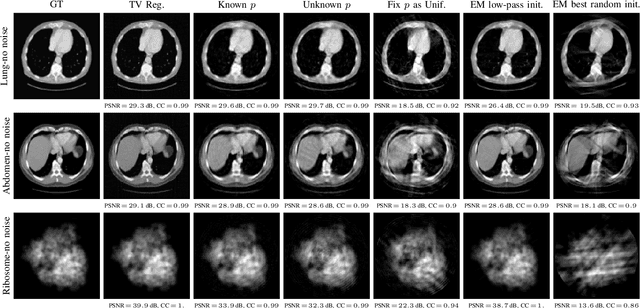
The goal of 2D tomographic reconstruction is to recover an image given its projection lines from various views. It is often presumed that projection angles associated with the projection lines are known in advance. Under certain situations, however, these angles are known only approximately or are completely unknown. It becomes more challenging to reconstruct the image from a collection of random projection lines. We propose an adversarial learning based approach to recover the image and the projection angle distribution by matching the empirical distribution of the measurements with the generated data. Fitting the distributions is achieved through solving a min-max game between a generator and a critic based on Wasserstein generative adversarial network structure. To accommodate the update of the projection angle distribution through gradient back propagation, we approximate the loss using the Gumbel-Softmax reparameterization of samples from discrete distributions. Our theoretical analysis verifies the unique recovery of the image and the projection distribution up to a rotation and reflection upon convergence. Our extensive numerical experiments showcase the potential of our method to accurately recover the image and the projection angle distribution under noise contamination.
Vision Transformer for Small-Size Datasets
Dec 27, 2021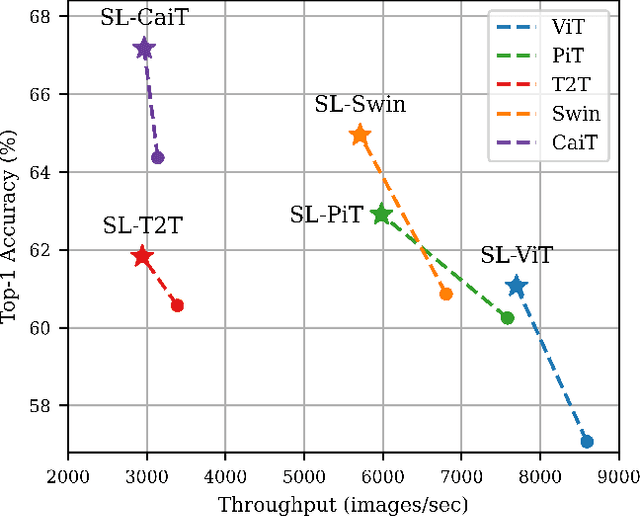
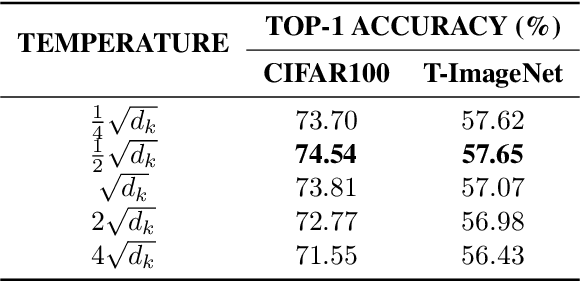

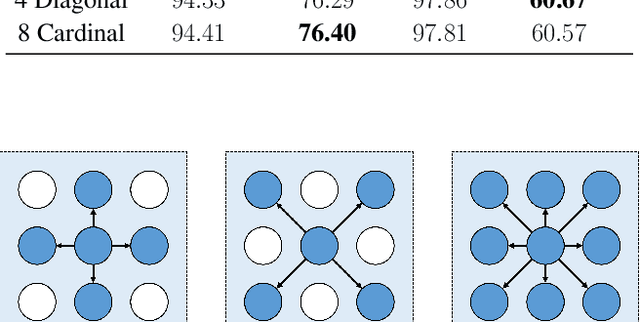
Recently, the Vision Transformer (ViT), which applied the transformer structure to the image classification task, has outperformed convolutional neural networks. However, the high performance of the ViT results from pre-training using a large-size dataset such as JFT-300M, and its dependence on a large dataset is interpreted as due to low locality inductive bias. This paper proposes Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA), which effectively solve the lack of locality inductive bias and enable it to learn from scratch even on small-size datasets. Moreover, SPT and LSA are generic and effective add-on modules that are easily applicable to various ViTs. Experimental results show that when both SPT and LSA were applied to the ViTs, the performance improved by an average of 2.96% in Tiny-ImageNet, which is a representative small-size dataset. Especially, Swin Transformer achieved an overwhelming performance improvement of 4.08% thanks to the proposed SPT and LSA.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
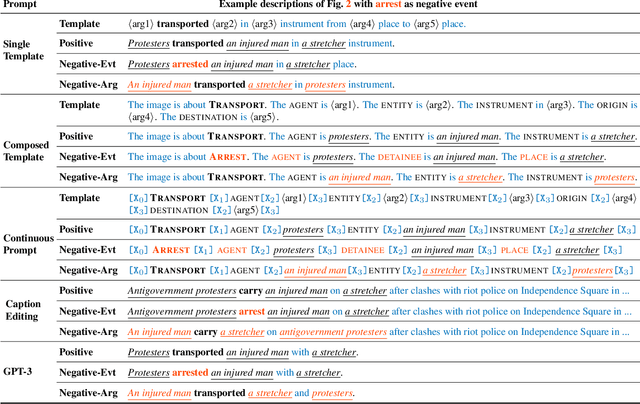
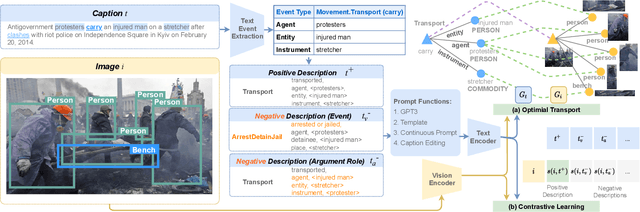

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
Deep Tactile Experience: Estimating Tactile Sensor Output from Depth Sensor Data
Oct 17, 2021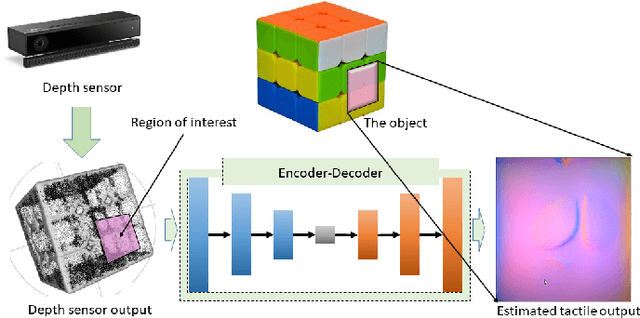

Tactile sensing is inherently contact based. To use tactile data, robots need to make contact with the surface of an object. This is inefficient in applications where an agent needs to make a decision between multiple alternatives that depend the physical properties of the contact location. We propose a method to get tactile data in a non-invasive manner. The proposed method estimates the output of a tactile sensor from the depth data of the surface of the object based on past experiences. An experience dataset is built by allowing the robot to interact with various objects, collecting tactile data and the corresponding object surface depth data. We use the experience dataset to train a neural network to estimate the tactile output from depth data alone. We use GelSight tactile sensors, an image-based sensor, to generate images that capture detailed surface features at the contact location. We train a network with a dataset containing 578 tactile-image to depthmap correspondences. Given a depth-map of the surface of an object, the network outputs an estimate of the response of the tactile sensor, should it make a contact with the object. We evaluate the method with structural similarity index matrix (SSIM), a similarity metric between two images commonly used in image processing community. We present experimental results that show the proposed method outperforms a baseline that uses random images with statistical significance getting an SSIM score of 0.84 +/- 0.0056 and 0.80 +/- 0.0036, respectively.
Skin lesion segmentation and classification using deep learning and handcrafted features
Dec 20, 2021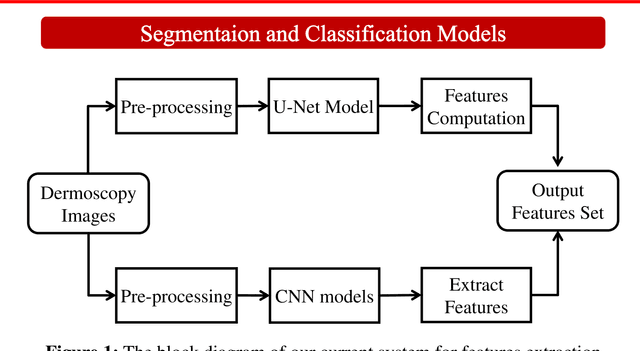
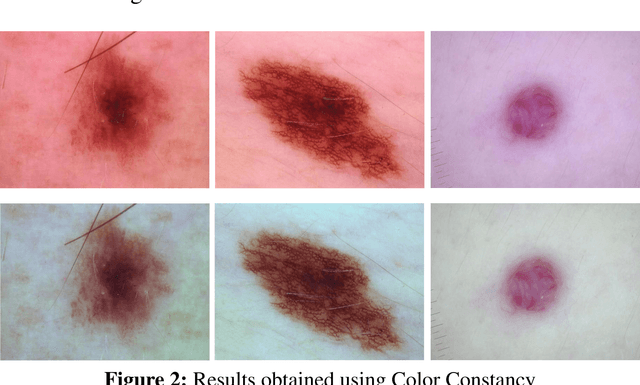

Accurate diagnostics of a skin lesion is a critical task in classification dermoscopic images. In this research, we form a new type of image features, called hybrid features, which has stronger discrimination ability than single method features. This study involves a new technique where we inject the handcrafted features or feature transfer into the fully connected layer of Convolutional Neural Network (CNN) model during the training process. Based on our literature review until now, no study has examined or investigated the impact on classification performance by injecting the handcrafted features into the CNN model during the training process. In addition, we also investigated the impact of segmentation mask and its effect on the overall classification performance. Our model achieves an 92.3% balanced multiclass accuracy, which is 6.8% better than the typical single method classifier architecture for deep learning.
Lacuna Reconstruction: Self-supervised Pre-training for Low-Resource Historical Document Transcription
Dec 16, 2021
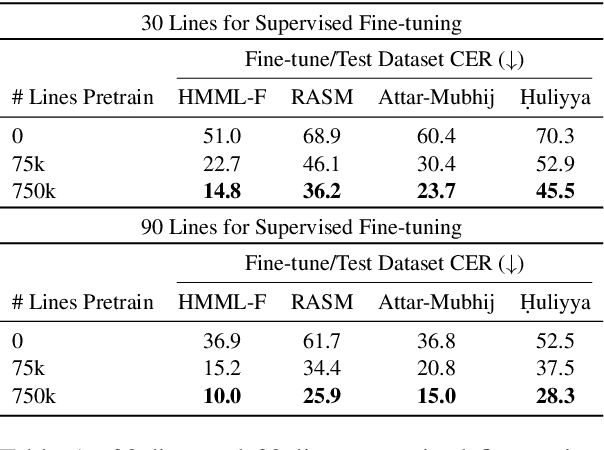
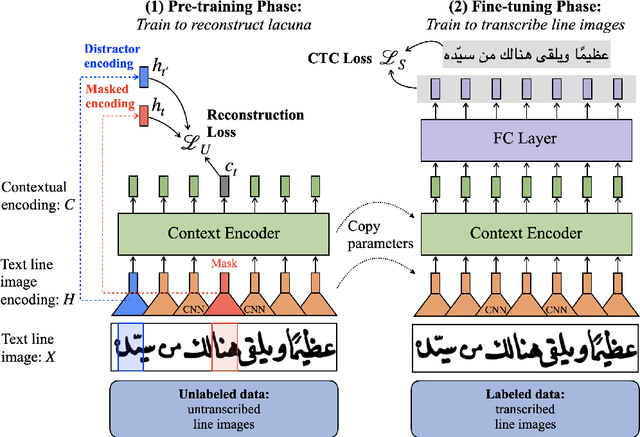

We present a self-supervised pre-training approach for learning rich visual language representations for both handwritten and printed historical document transcription. After supervised fine-tuning of our pre-trained encoder representations for low-resource document transcription on two languages, (1) a heterogeneous set of handwritten Islamicate manuscript images and (2) early modern English printed documents, we show a meaningful improvement in recognition accuracy over the same supervised model trained from scratch with as few as 30 line image transcriptions for training. Our masked language model-style pre-training strategy, where the model is trained to be able to identify the true masked visual representation from distractors sampled from within the same line, encourages learning robust contextualized language representations invariant to scribal writing style and printing noise present across documents.