 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantically Tied Paired Cycle Consistency for Any-Shot Sketch-based Image Retrieval
Jun 20, 2020
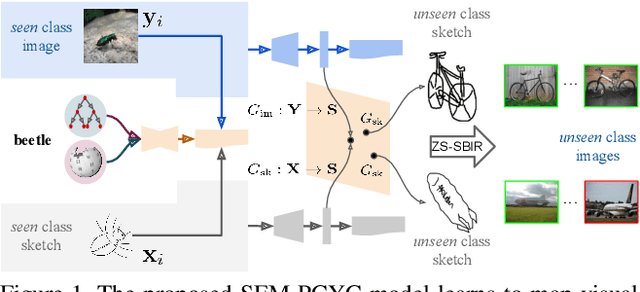
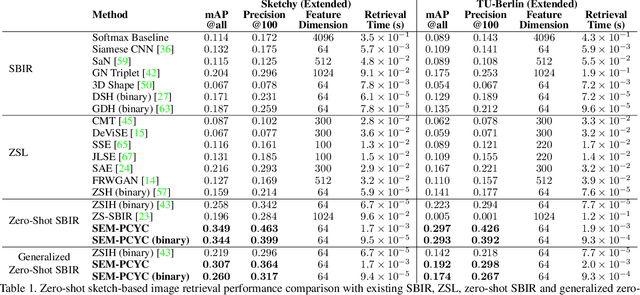
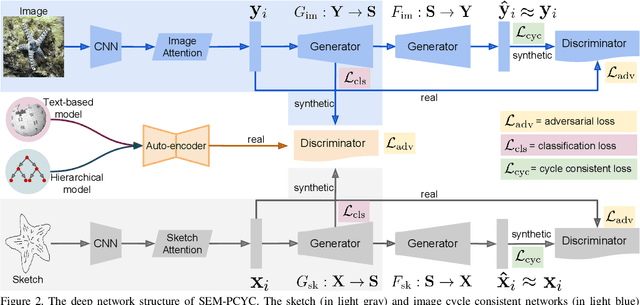

Low-shot sketch-based image retrieval is an emerging task in computer vision, allowing to retrieve natural images relevant to hand-drawn sketch queries that are rarely seen during the training phase. Related prior works either require aligned sketch-image pairs that are costly to obtain or inefficient memory fusion layer for mapping the visual information to a semantic space. In this paper, we address any-shot, i.e. zero-shot and few-shot, sketch-based image retrieval (SBIR) tasks, where we introduce the few-shot setting for SBIR. For solving these tasks, we propose a semantically aligned paired cycle-consistent generative adversarial network (SEM-PCYC) for any-shot SBIR, where each branch of the generative adversarial network maps the visual information from sketch and image to a common semantic space via adversarial training. Each of these branches maintains cycle consistency that only requires supervision at the category level, and avoids the need of aligned sketch-image pairs. A classification criteria on the generators' outputs ensures the visual to semantic space mapping to be class-specific. Furthermore, we propose to combine textual and hierarchical side information via an auto-encoder that selects discriminating side information within a same end-to-end model. Our results demonstrate a significant boost in any-shot SBIR performance over the state-of-the-art on the extended version of the challenging Sketchy, TU-Berlin and QuickDraw datasets.
Producing augmentation-invariant embeddings from real-life imagery
Dec 06, 2021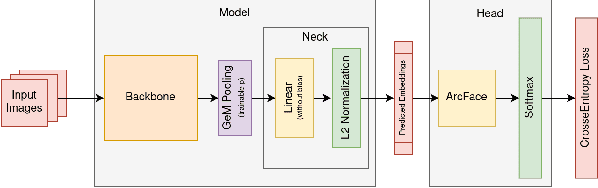
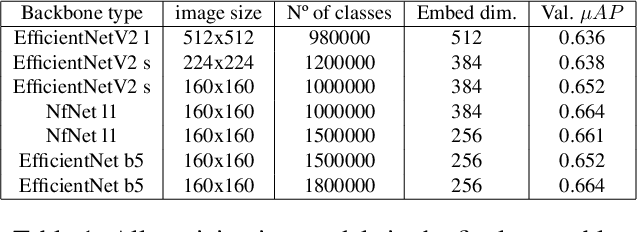


This article presents an efficient way to produce feature-rich, high-dimensionality embedding spaces from real-life images. The features produced are designed to be independent from augmentations used in real-life cases which appear on social media. Our approach uses convolutional neural networks (CNN) to produce an embedding space. An ArcFace head was used to train the model by employing automatically produced augmentations. Additionally, we present a way to make an ensemble out of different embeddings containing the same semantic information, a way to normalize the resulting embedding using an external dataset, and a novel way to perform quick training of these models with a high number of classes in the ArcFace head. Using this approach we achieved the 2nd place in the 2021 Facebook AI Image Similarity Challenge: Descriptor Track.
Automatic Detection of Injection and Press Mold Parts on 2D Drawing Using Deep Neural Network
Oct 22, 2021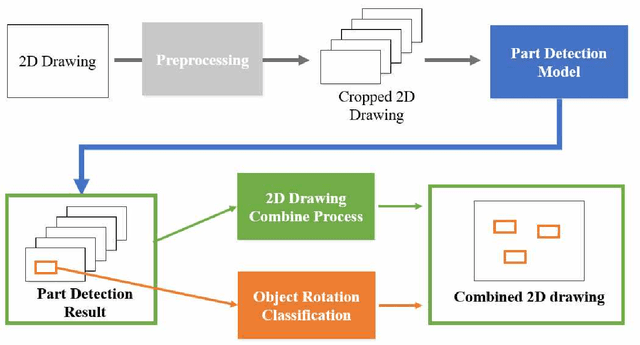

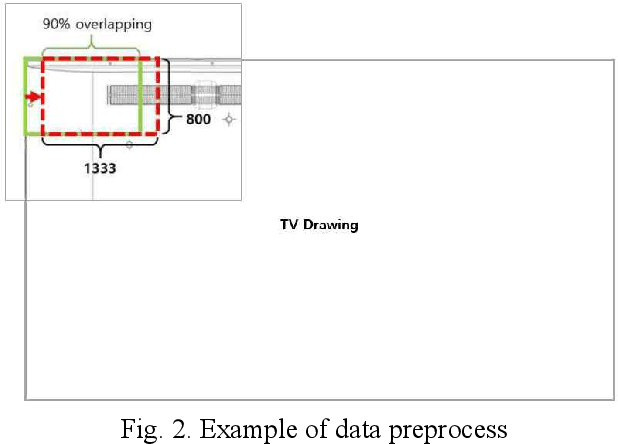
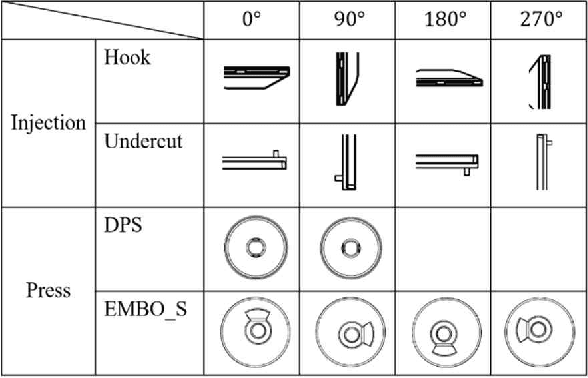
This paper proposes a method to automatically detect the key feature parts in a CAD of commercial TV and monitor using a deep neural network. We developed a deep learning pipeline that can detect the injection parts such as hook, boss, undercut and press parts such as DPS, Embo-Screwless, Embo-Burring, and EMBO in the 2D CAD drawing images. We first cropped the drawing to a specific size for the training efficiency of a deep neural network. Then, we use Cascade R-CNN to find the position of injection and press parts and use Resnet-50 to predict the orientation of the parts. Finally, we convert the position of the parts found through the cropped image to the position of the original image. As a result, we obtained detection accuracy of injection and press parts with 84.1% in AP (Average Precision), 91.2% in AR(Average Recall), 72.0% in AP, 87.0% in AR, and orientation accuracy of injection and press parts with 94.4% and 92.0%, which can facilitate the faster design in industrial product design.
Frost filtered scale-invariant feature extraction and multilayer perceptron for hyperspectral image classification
Jun 18, 2020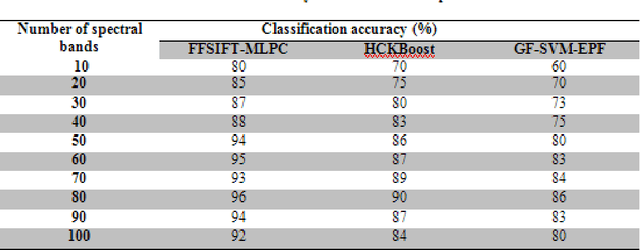
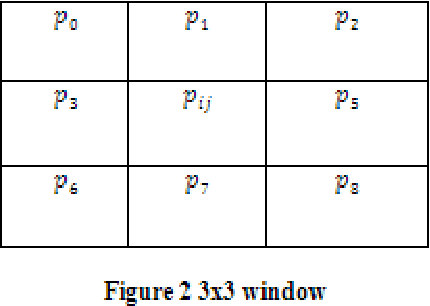
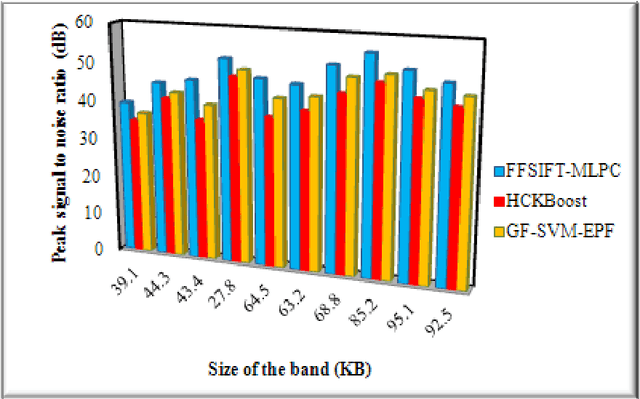
Hyperspectral image (HSI) classification plays a significant in the field of remote sensing due to its ability to provide spatial and spectral information. Due to the rapid development and increasing of hyperspectral remote sensing technology, many methods have been developed for HSI classification but still a lack of achieving the better performance. A Frost Filtered Scale-Invariant Feature Transformation based MultiLayer Perceptron Classification (FFSIFT-MLPC) technique is introduced for classifying the hyperspectral image with higher accuracy and minimum time consumption. The FFSIFT-MLPC technique performs three major processes, namely preprocessing, feature extraction and classification using multiple layers. Initially, the hyperspectral image is divided into number of spectral bands. These bands are given as input in the input layer of perceptron. Then the Frost filter is used in FFSIFT-MLPC technique for preprocessing the input bands which helps to remove the noise from hyper-spectral image at the first hidden layer. After preprocessing task, texture, color and object features of hyper-spectral image are extracted at second hidden layer using Gaussian distributive scale-invariant feature transform. At the third hidden layer, Euclidean distance is measured between the extracted features and testing features. Finally, feature matching is carried out at the output layer for hyper-spectral image classification. The classified outputs are resulted in terms of spectral bands (i.e., different colors). Experimental analysis is performed with PSNR, classification accuracy, false positive rate and classification time with number of spectral bands. The results evident that presented FFSIFT-MLPC technique improves the hyperspectral image classification accuracy, PSNR and minimizes false positive rate as well as classification time than the state-of-the-art methods.
Self-Supervised Out-of-Distribution Detection and Localization with Natural Synthetic Anomalies (NSA)
Sep 30, 2021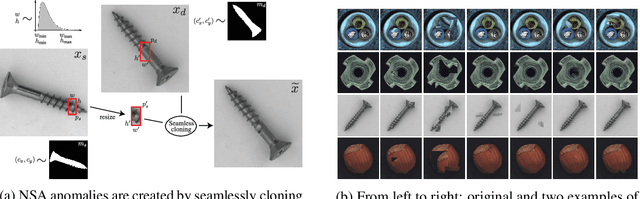
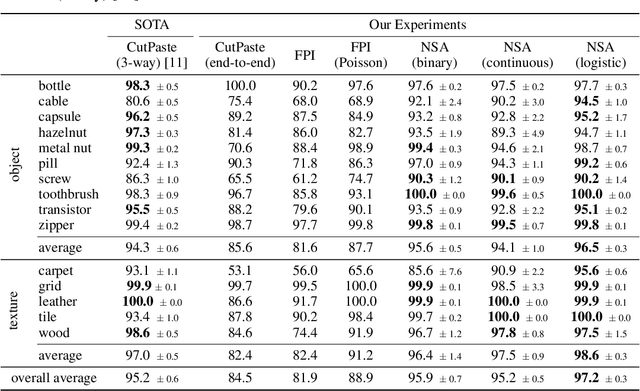
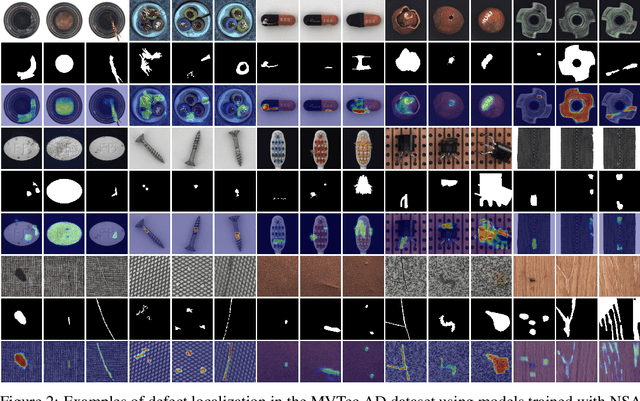
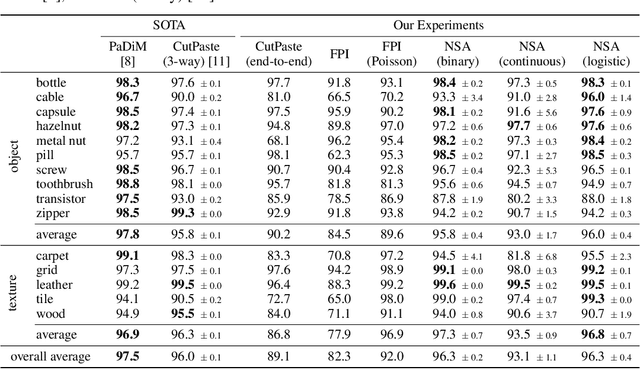
We introduce a new self-supervised task, NSA, for training an end-to-end model for anomaly detection and localization using only normal data. NSA uses Poisson image editing to seamlessly blend scaled patches of various sizes from separate images. This creates a wide range of synthetic anomalies which are more similar to natural sub-image irregularities than previous data-augmentation strategies for self-supervised anomaly detection. We evaluate the proposed method using natural and medical images. Our experiments with the MVTec AD dataset show that a model trained to localize NSA anomalies generalizes well to detecting real-world a priori unknown types of manufacturing defects. Our method achieves an overall detection AUROC of 97.2 outperforming all previous methods that learn from scratch without pre-training datasets.
VisImages: A Large-scale, High-quality Image Corpus in Visualization Publications
Jul 10, 2020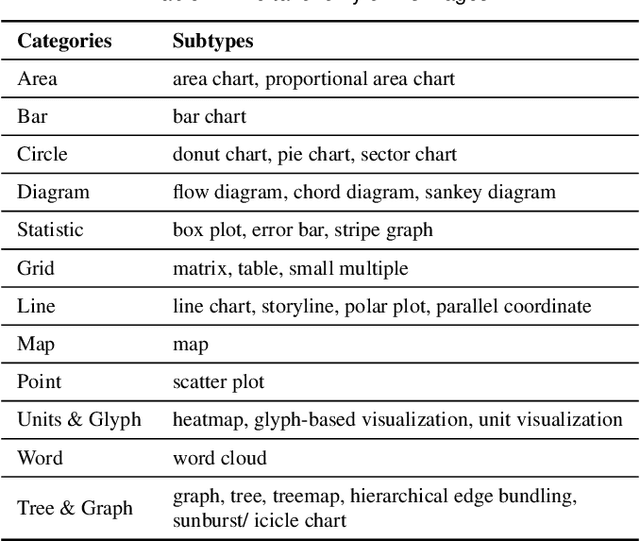
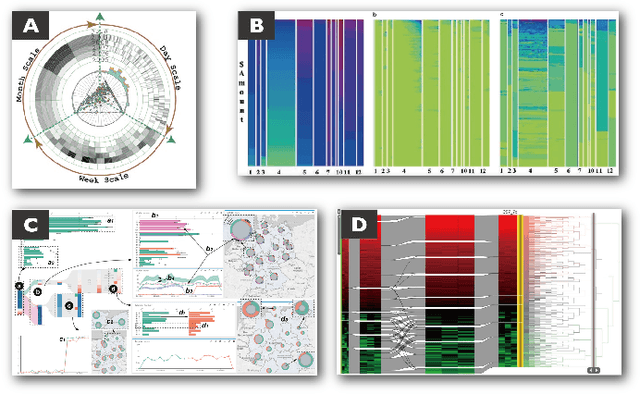

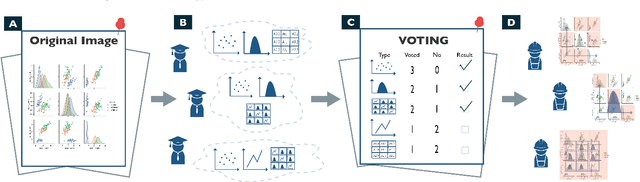
Images in visualization publications contain rich information, such as novel visual designs, model details, and experiment results. Constructing such an image corpus can contribute to the community in many aspects, including literature analysis from the perspective of visual representations, empirical studies on visual memorability, and machine learning research for chart detection. This study presents VisImages, a high-quality and large-scale image corpus collected from visualization publications. VisImages contain fruitful and diverse annotations for each image, including captions, types of visual representations, and bounding boxes. First, we algorithmically extract the images associated with captions and manually correct the errors. Second, to categorize visualizations in publications, we extend and iteratively refine the existing taxonomy through a multi-round pilot study. Third, guided by this taxonomy, we invite senior visualization practitioners to annotate visual representations that appear in each image. In this process, we borrow techniques such as "gold standards" and majority voting for quality control. Finally, we recruit the crowd to draw bounding boxes for visual representations in the images. The resulting corpus contains 35,096 annotated visualizations from 12,267 images with 12,057 captions in 1397 papers from VAST and InfoVis. We demonstrate the usefulness of VisImages through the following four use cases: 1) analysis of color usage in VAST and InfoVis papers across years, 2) discussion of the researcher preference on visualization types, 3) spatial distribution analysis of visualizations in visual analytic systems, and 4) training visualization detection models.
Action Image Representation: Learning Scalable Deep Grasping Policies with Zero Real World Data
May 13, 2020

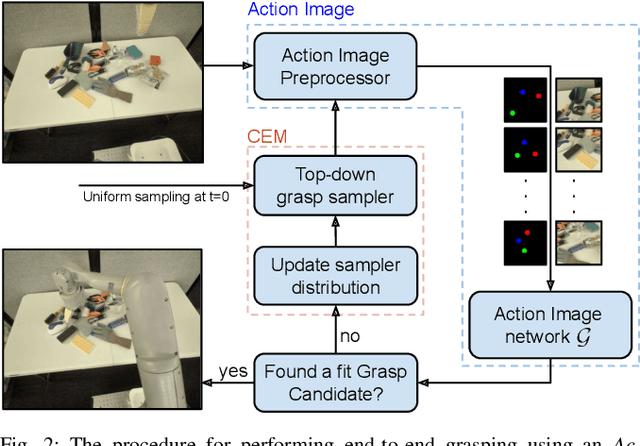
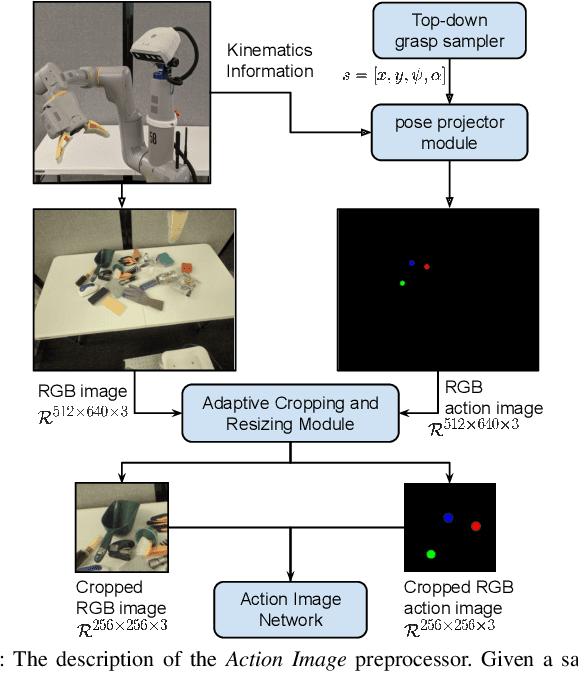
This paper introduces Action Image, a new grasp proposal representation that allows learning an end-to-end deep-grasping policy. Our model achieves $84\%$ grasp success on $172$ real world objects while being trained only in simulation on $48$ objects with just naive domain randomization. Similar to computer vision problems, such as object detection, Action Image builds on the idea that object features are invariant to translation in image space. Therefore, grasp quality is invariant when evaluating the object-gripper relationship; a successful grasp for an object depends on its local context, but is independent of the surrounding environment. Action Image represents a grasp proposal as an image and uses a deep convolutional network to infer grasp quality. We show that by using an Action Image representation, trained networks are able to extract local, salient features of grasping tasks that generalize across different objects and environments. We show that this representation works on a variety of inputs, including color images (RGB), depth images (D), and combined color-depth (RGB-D). Our experimental results demonstrate that networks utilizing an Action Image representation exhibit strong domain transfer between training on simulated data and inference on real-world sensor streams. Finally, our experiments show that a network trained with Action Image improves grasp success ($84\%$ vs. $53\%$) over a baseline model with the same structure, but using actions encoded as vectors.
Improved Multiscale Vision Transformers for Classification and Detection
Dec 02, 2021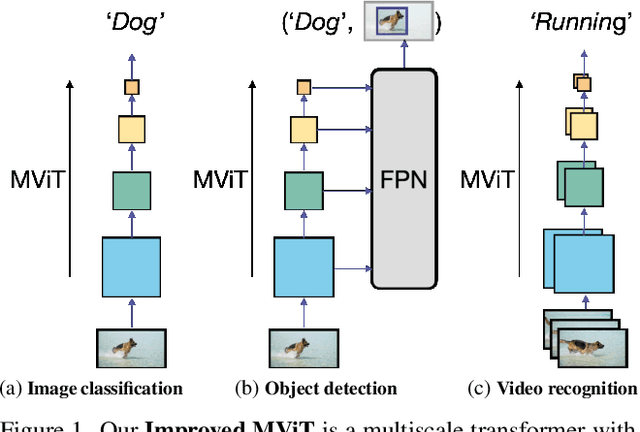
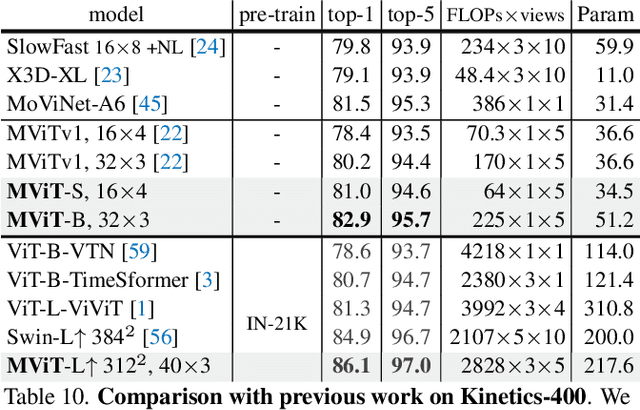
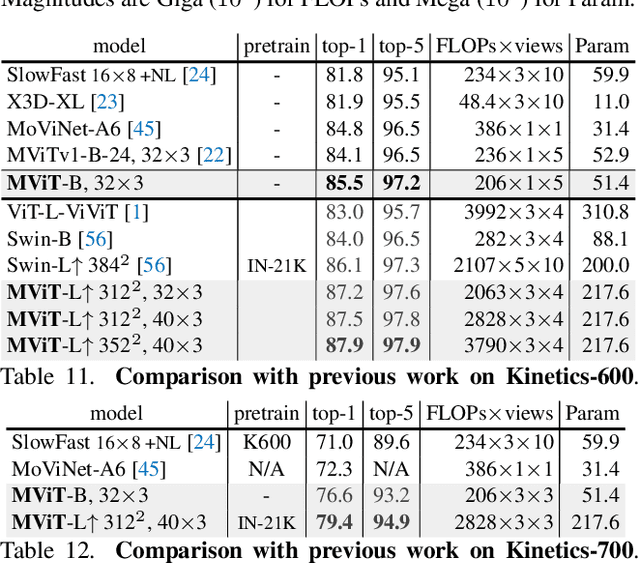
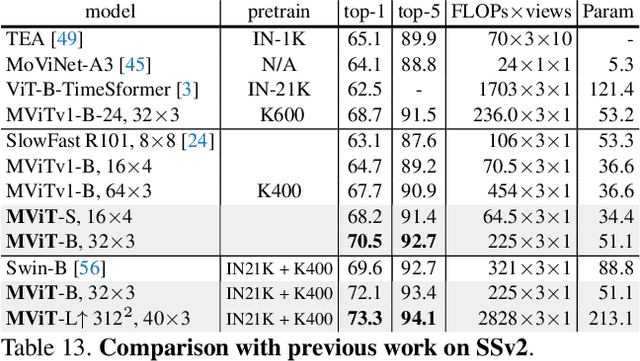
In this paper, we study Multiscale Vision Transformers (MViT) as a unified architecture for image and video classification, as well as object detection. We present an improved version of MViT that incorporates decomposed relative positional embeddings and residual pooling connections. We instantiate this architecture in five sizes and evaluate it for ImageNet classification, COCO detection and Kinetics video recognition where it outperforms prior work. We further compare MViTs' pooling attention to window attention mechanisms where it outperforms the latter in accuracy/compute. Without bells-and-whistles, MViT has state-of-the-art performance in 3 domains: 88.8% accuracy on ImageNet classification, 56.1 box AP on COCO object detection as well as 86.1% on Kinetics-400 video classification. Code and models will be made publicly available.
Instance Segmentation for Direct Measurements of Satellites in Metal Powders and Automated Microstructural Characterization from Image Data
Jan 05, 2021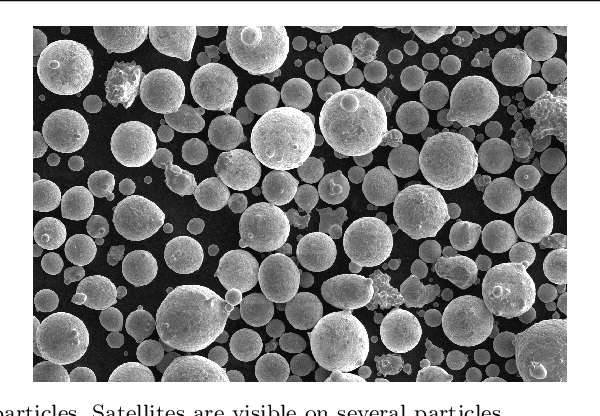
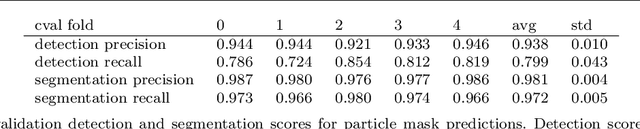


We propose instance segmentation as a useful tool for image analysis in materials science. Instance segmentation is an advanced technique in computer vision which generates individual segmentation masks for every object of interest that is recognized in an image. Using an out-of-the-box implementation of Mask R-CNN, instance segmentation is applied to images of metal powder particles produced through gas atomization. Leveraging transfer learning allows for the analysis to be conducted with a very small training set of labeled images. As well as providing another method for measuring the particle size distribution, we demonstrate the first direct measurements of the satellite content in powder samples. After analyzing the results for the labeled data dataset, the trained model was used to generate measurements for a much larger set of unlabeled images. The resulting particle size measurements showed reasonable agreement with laser scattering measurements. The satellite measurements were self-consistent and showed good agreement with the expected trends for different samples. Finally, we provide a small case study showing how instance segmentation can be used to measure spheroidite content in the UltraHigh Carbon Steel Database, demonstrating the flexibility of the technique.
Aligning Domain-specific Distribution and Classifier for Cross-domain Classification from Multiple Sources
Jan 04, 2022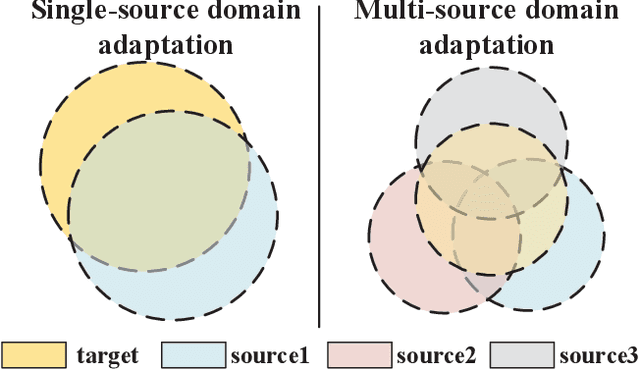
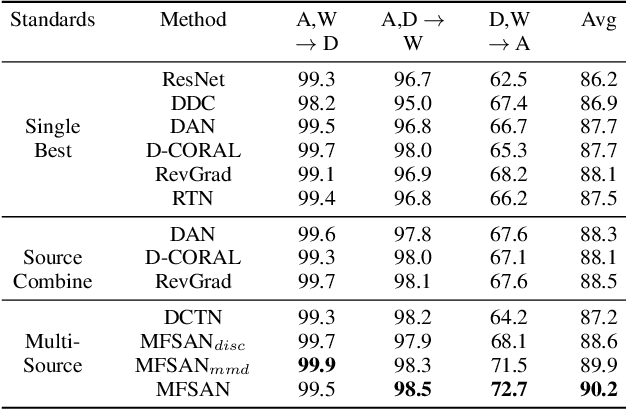
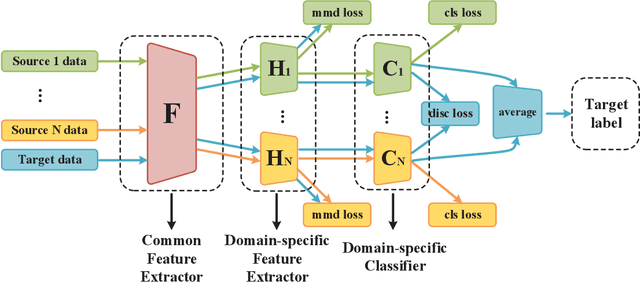
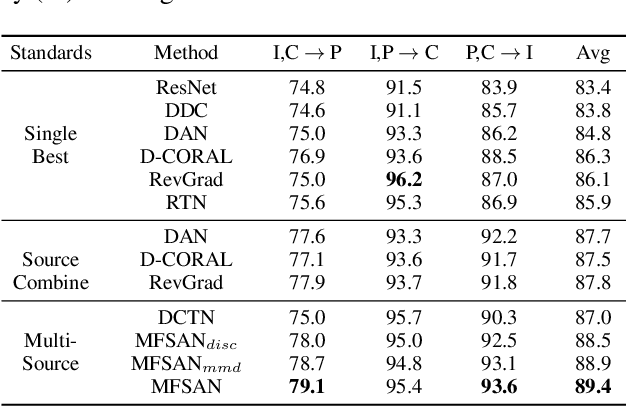
While Unsupervised Domain Adaptation (UDA) algorithms, i.e., there are only labeled data from source domains, have been actively studied in recent years, most algorithms and theoretical results focus on Single-source Unsupervised Domain Adaptation (SUDA). However, in the practical scenario, labeled data can be typically collected from multiple diverse sources, and they might be different not only from the target domain but also from each other. Thus, domain adapters from multiple sources should not be modeled in the same way. Recent deep learning based Multi-source Unsupervised Domain Adaptation (MUDA) algorithms focus on extracting common domain-invariant representations for all domains by aligning distribution of all pairs of source and target domains in a common feature space. However, it is often very hard to extract the same domain-invariant representations for all domains in MUDA. In addition, these methods match distributions without considering domain-specific decision boundaries between classes. To solve these problems, we propose a new framework with two alignment stages for MUDA which not only respectively aligns the distributions of each pair of source and target domains in multiple specific feature spaces, but also aligns the outputs of classifiers by utilizing the domain-specific decision boundaries. Extensive experiments demonstrate that our method can achieve remarkable results on popular benchmark datasets for image classification.