 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DIB-R++: Learning to Predict Lighting and Material with a Hybrid Differentiable Renderer
Oct 30, 2021
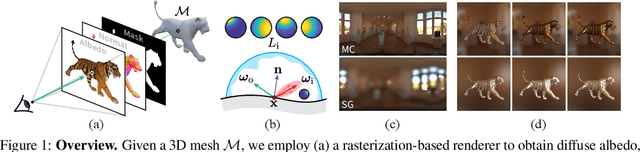
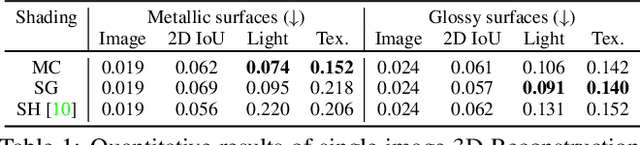
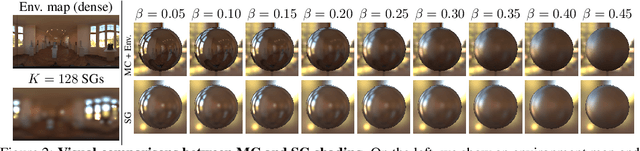

We consider the challenging problem of predicting intrinsic object properties from a single image by exploiting differentiable renderers. Many previous learning-based approaches for inverse graphics adopt rasterization-based renderers and assume naive lighting and material models, which often fail to account for non-Lambertian, specular reflections commonly observed in the wild. In this work, we propose DIBR++, a hybrid differentiable renderer which supports these photorealistic effects by combining rasterization and ray-tracing, taking the advantage of their respective strengths -- speed and realism. Our renderer incorporates environmental lighting and spatially-varying material models to efficiently approximate light transport, either through direct estimation or via spherical basis functions. Compared to more advanced physics-based differentiable renderers leveraging path tracing, DIBR++ is highly performant due to its compact and expressive shading model, which enables easy integration with learning frameworks for geometry, reflectance and lighting prediction from a single image without requiring any ground-truth. We experimentally demonstrate that our approach achieves superior material and lighting disentanglement on synthetic and real data compared to existing rasterization-based approaches and showcase several artistic applications including material editing and relighting.
w-Net: Dual Supervised Medical Image Segmentation Model with Multi-Dimensional Attention and Cascade Multi-Scale Convolution
Nov 15, 2020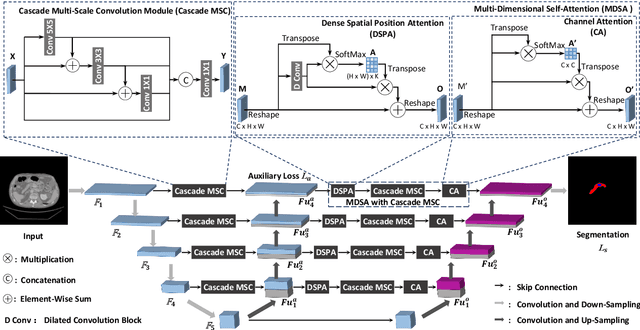
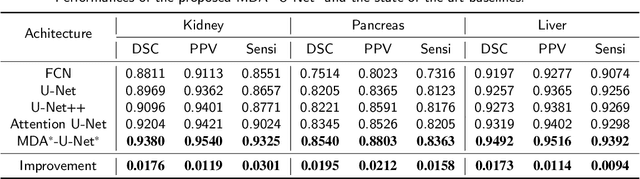
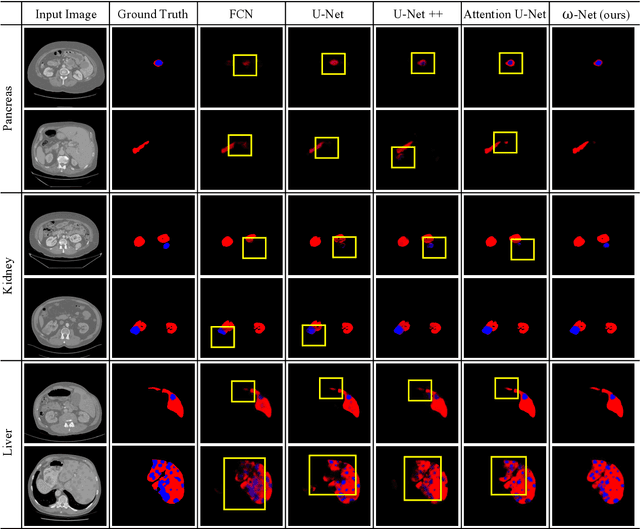
Deep learning-based medical image segmentation technology aims at automatic recognizing and annotating objects on the medical image. Non-local attention and feature learning by multi-scale methods are widely used to model network, which drives progress in medical image segmentation. However, those attention mechanism methods have weakly non-local receptive fields' strengthened connection for small objects in medical images. Then, the features of important small objects in abstract or coarse feature maps may be deserted, which leads to unsatisfactory performance. Moreover, the existing multi-scale methods only simply focus on different sizes of view, whose sparse multi-scale features collected are not abundant enough for small objects segmentation. In this work, a multi-dimensional attention segmentation model with cascade multi-scale convolution is proposed to predict accurate segmentation for small objects in medical images. As the weight function, multi-dimensional attention modules provide coefficient modification for significant/informative small objects features. Furthermore, The cascade multi-scale convolution modules in each skip-connection path are exploited to capture multi-scale features in different semantic depth. The proposed method is evaluated on three datasets: KiTS19, Pancreas CT of Decathlon-10, and MICCAI 2018 LiTS Challenge, demonstrating better segmentation performances than the state-of-the-art baselines.
Resolving gas bubbles ascending in liquid metal from low-SNR neutron radiography images
Sep 08, 2021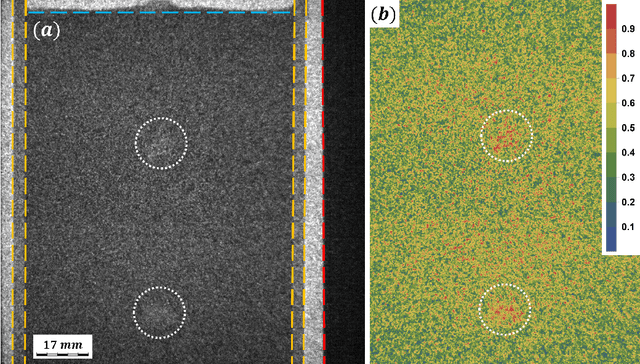
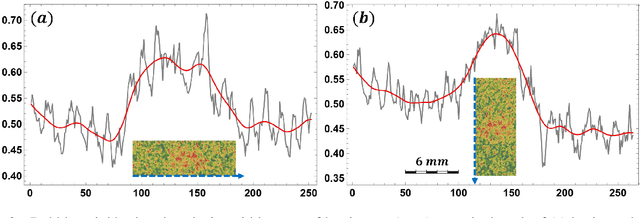

We demonstrate a new image processing methodology for resolving gas bubbles travelling through liquid metal from dynamic neutron radiography images with intrinsically low signal-to-noise ratio. Image pre-processing, denoising and bubble segmentation are described in detail, with practical recommendations. Experimental validation is presented - stationary and moving reference bodies with neutron-transparent cavities are radiographed with imaging conditions similar to the cases with bubbles in liquid metal. The new methods are applied to our experimental data from previous and recent imaging campaigns, and the performance of the methods proposed in this paper is compared against our previously developed methods. Significant improvements are observed as well as the capacity to reliably extract physically meaningful information from measurements performed under highly adverse imaging conditions. The showcased image processing solution and separate elements thereof are readily extendable beyond the present application, and have been made open-source.
Multi-Label Classification on Remote-Sensing Images
Jan 06, 2022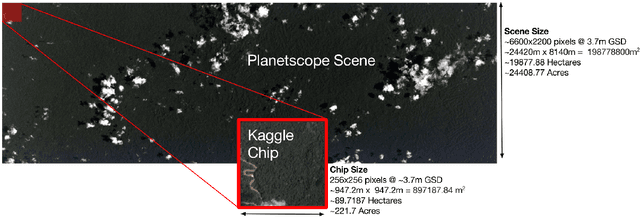

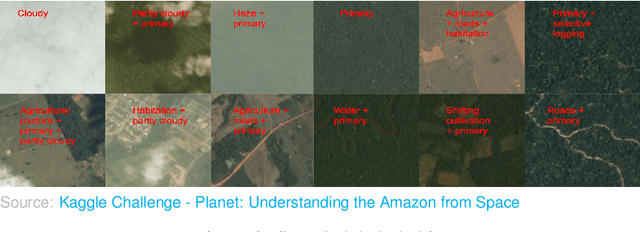
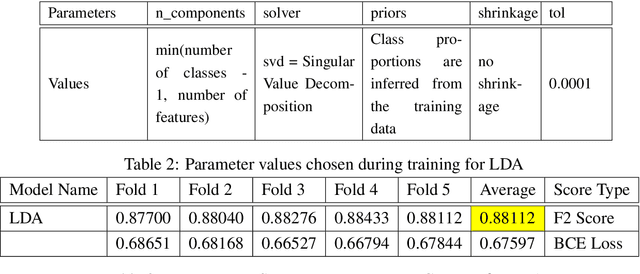
Acquiring information on large areas on the earth's surface through satellite cameras allows us to see much more than we can see while standing on the ground. This assists us in detecting and monitoring the physical characteristics of an area like land-use patterns, atmospheric conditions, forest cover, and many unlisted aspects. The obtained images not only keep track of continuous natural phenomena but are also crucial in tackling the global challenge of severe deforestation. Among which Amazon basin accounts for the largest share every year. Proper data analysis would help limit detrimental effects on the ecosystem and biodiversity with a sustainable healthy atmosphere. This report aims to label the satellite image chips of the Amazon rainforest with atmospheric and various classes of land cover or land use through different machine learning and superior deep learning models. Evaluation is done based on the F2 metric, while for loss function, we have both sigmoid cross-entropy as well as softmax cross-entropy. Images are fed indirectly to the machine learning classifiers after only features are extracted using pre-trained ImageNet architectures. Whereas for deep learning models, ensembles of fine-tuned ImageNet pre-trained models are used via transfer learning. Our best score was achieved so far with the F2 metric is 0.927.
Multi-Subspace Neural Network for Image Recognition
Jun 17, 2020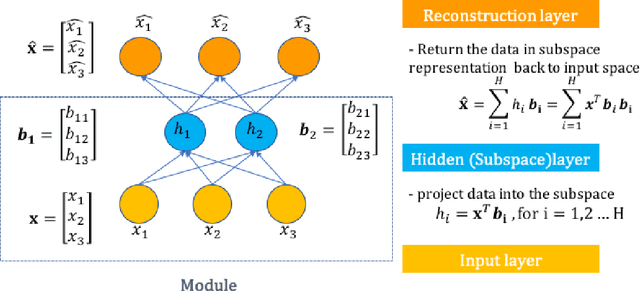
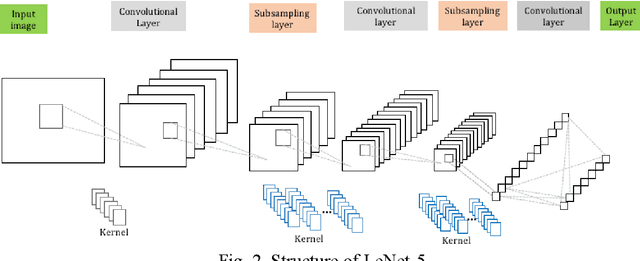
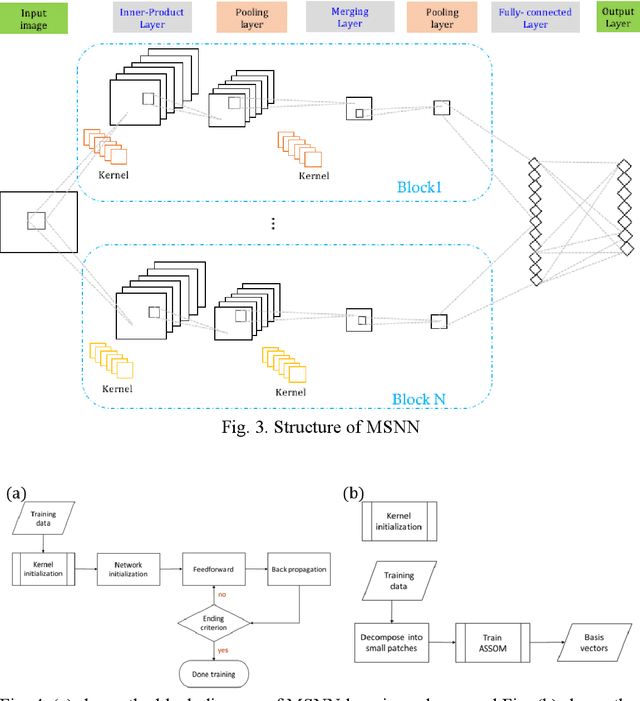
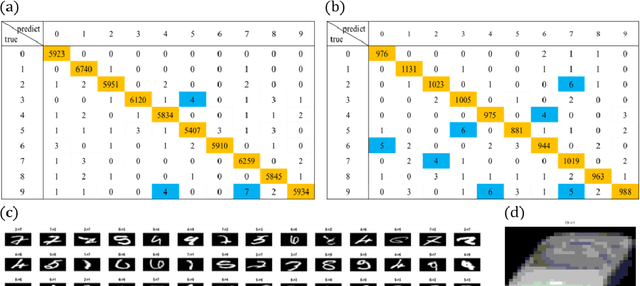
In image classification task, feature extraction is always a big issue. Intra-class variability increases the difficulty in designing the extractors. Furthermore, hand-crafted feature extractor cannot simply adapt new situation. Recently, deep learning has drawn lots of attention on automatically learning features from data. In this study, we proposed multi-subspace neural network (MSNN) which integrates key components of the convolutional neural network (CNN), receptive field, with subspace concept. Associating subspace with the deep network is a novel designing, providing various viewpoints of data. Basis vectors, trained by adaptive subspace self-organization map (ASSOM) span the subspace, serve as a transfer function to access axial components and define the receptive field to extract basic patterns of data without distorting the topology in the visual task. Moreover, the multiple-subspace strategy is implemented as parallel blocks to adapt real-world data and contribute various interpretations of data hoping to be more robust dealing with intra-class variability issues. To this end, handwritten digit and object image datasets (i.e., MNIST and COIL-20) for classification are employed to validate the proposed MSNN architecture. Experimental results show MSNN is competitive to other state-of-the-art approaches.
Identity-Preserving Pose-Robust Face Hallucination Through Face Subspace Prior
Nov 20, 2021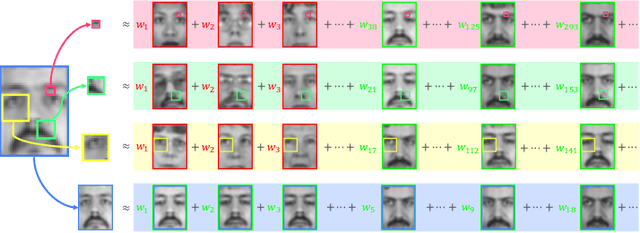
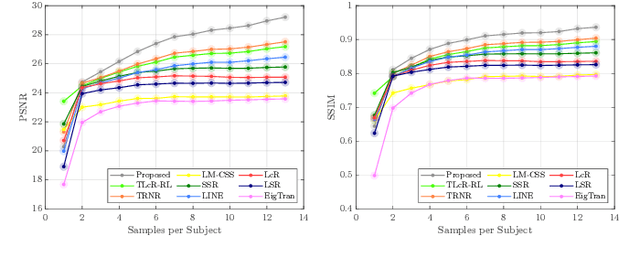

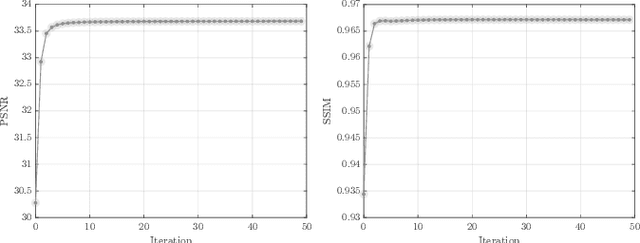
Over the past few decades, numerous attempts have been made to address the problem of recovering a high-resolution (HR) facial image from its corresponding low-resolution (LR) counterpart, a task commonly referred to as face hallucination. Despite the impressive performance achieved by position-patch and deep learning-based methods, most of these techniques are still unable to recover identity-specific features of faces. The former group of algorithms often produces blurry and oversmoothed outputs particularly in the presence of higher levels of degradation, whereas the latter generates faces which sometimes by no means resemble the individuals in the input images. In this paper, a novel face super-resolution approach will be introduced, in which the hallucinated face is forced to lie in a subspace spanned by the available training faces. Therefore, in contrast to the majority of existing face hallucination techniques and thanks to this face subspace prior, the reconstruction is performed in favor of recovering person-specific facial features, rather than merely increasing image quantitative scores. Furthermore, inspired by recent advances in the area of 3D face reconstruction, an efficient 3D dictionary alignment scheme is also presented, through which the algorithm becomes capable of dealing with low-resolution faces taken in uncontrolled conditions. In extensive experiments carried out on several well-known face datasets, the proposed algorithm shows remarkable performance by generating detailed and close to ground truth results which outperform the state-of-the-art face hallucination algorithms by significant margins both in quantitative and qualitative evaluations.
TextCaps: a Dataset for Image Captioning with Reading Comprehension
Mar 24, 2020
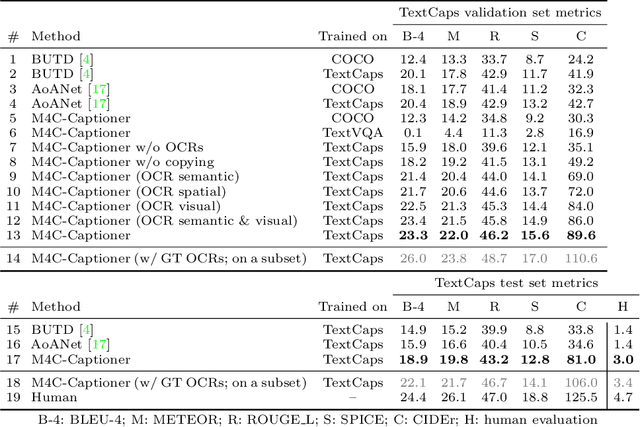

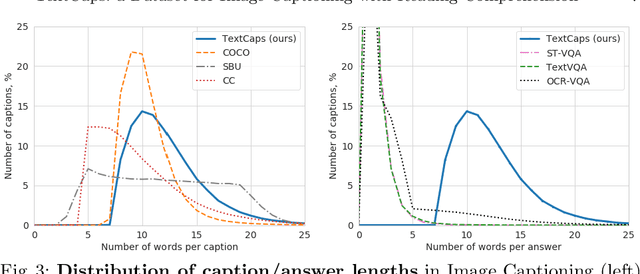
Image descriptions can help visually impaired people to quickly understand the image content. While we made significant progress in automatically describing images and optical character recognition, current approaches are unable to include written text in their descriptions, although text is omnipresent in human environments and frequently critical to understand our surroundings. To study how to comprehend text in the context of an image we collect a novel dataset, TextCaps, with 145k captions for 28k images. Our dataset challenges a model to recognize text, relate it to its visual context, and decide what part of the text to copy or paraphrase, requiring spatial, semantic, and visual reasoning between multiple text tokens and visual entities, such as objects. We study baselines and adapt existing approaches to this new task, which we refer to as image captioning with reading comprehension. Our analysis with automatic and human studies shows that our new TextCaps dataset provides many new technical challenges over previous datasets.
A Relational Model for One-Shot Classification
Nov 08, 2021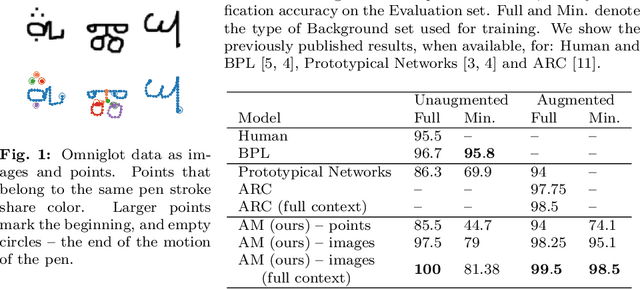
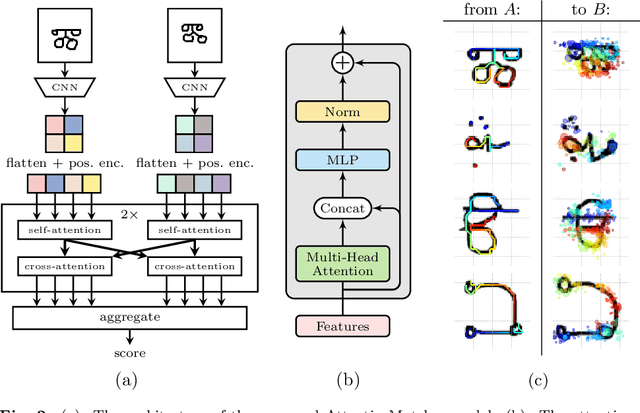
We show that a deep learning model with built-in relational inductive bias can bring benefits to sample-efficient learning, without relying on extensive data augmentation. The proposed one-shot classification model performs relational matching of a pair of inputs in the form of local and pairwise attention. Our approach solves perfectly the one-shot image classification Omniglot challenge. Our model exceeds human level accuracy, as well as the previous state of the art, with no data augmentation.
Statistical Analysis of Signal-Dependent Noise: Application in Blind Localization of Image Splicing Forgery
Nov 02, 2020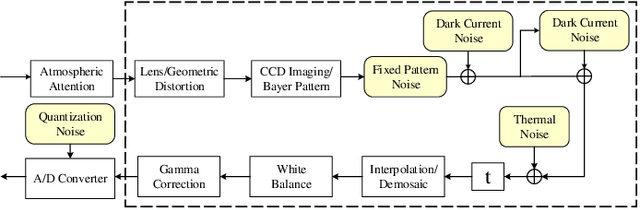
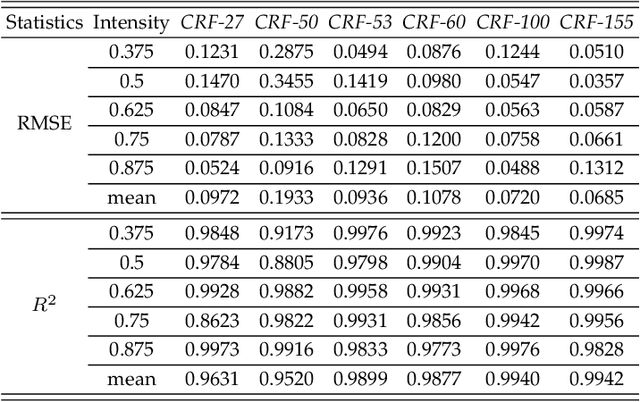
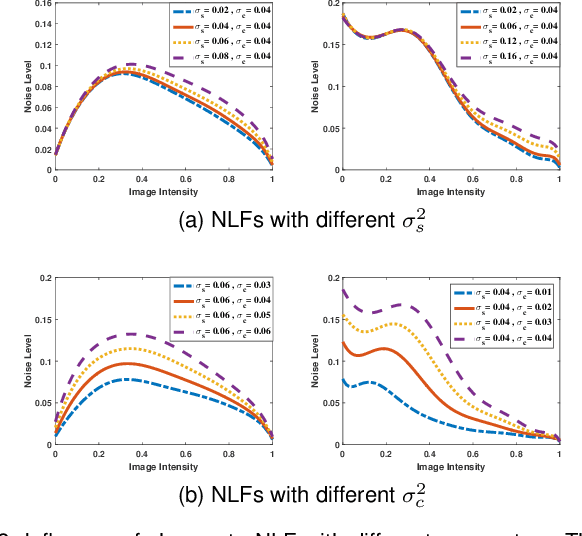
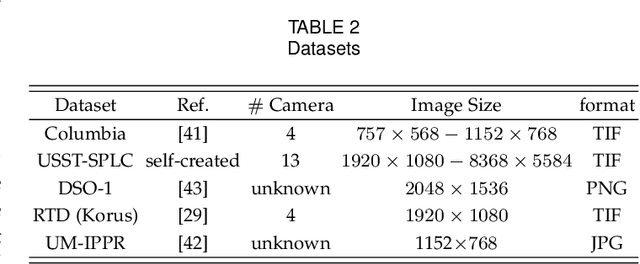
Visual noise is often regarded as a disturbance in image quality, whereas it can also provide a crucial clue for image-based forensic tasks. Conventionally, noise is assumed to comprise an additive Gaussian model to be estimated and then used to reveal anomalies. However, for real sensor noise, it should be modeled as signal-dependent noise (SDN). In this work, we apply SDN to splicing forgery localization tasks. Through statistical analysis of the SDN model, we assume that noise can be modeled as a Gaussian approximation for a certain brightness and propose a likelihood model for a noise level function. By building a maximum a posterior Markov random field (MAP-MRF) framework, we exploit the likelihood of noise to reveal the alien region of spliced objects, with a probability combination refinement strategy. To ensure a completely blind detection, an iterative alternating method is adopted to estimate the MRF parameters. Experimental results demonstrate that our method is effective and provides a comparative localization performance.
Unsupervised Deep-Learning Based Deformable Image Registration: A Bayesian Framework
Aug 10, 2020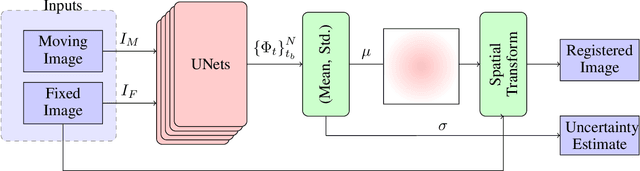

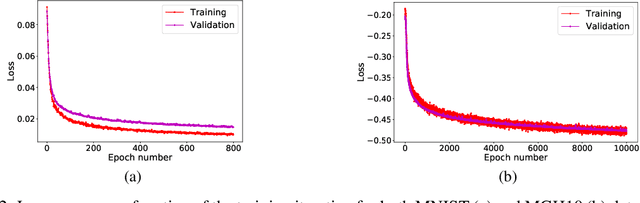
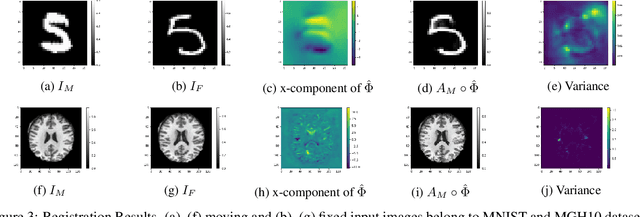
Unsupervised deep-learning (DL) models were recently proposed for deformable image registration tasks. In such models, a neural-network is trained to predict the best deformation field by minimizing some dissimilarity function between the moving and the target images. After training on a dataset without reference deformation fields available, such a model can be used to rapidly predict the deformation field between newly seen moving and target images. Currently, the training process effectively provides a point-estimate of the network weights rather than characterizing their entire posterior distribution. This may result in a potential over-fitting which may yield sub-optimal results at inference phase, especially for small-size datasets, frequently present in the medical imaging domain. We introduce a fully Bayesian framework for unsupervised DL-based deformable image registration. Our method provides a principled way to characterize the true posterior distribution, thus, avoiding potential over-fitting. We used stochastic gradient Langevin dynamics (SGLD) to conduct the posterior sampling, which is both theoretically well-founded and computationally efficient. We demonstrated the added-value of our Basyesian unsupervised DL-based registration framework on the MNIST and brain MRI (MGH10) datasets in comparison to the VoxelMorph unsupervised DL-based image registration framework. Our experiments show that our approach provided better estimates of the deformation field by means of improved mean-squared-error ($0.0063$ vs. $0.0065$) and Dice coefficient ($0.73$ vs. $0.71$) for the MNIST and the MGH10 datasets respectively. Further, our approach provides an estimate of the uncertainty in the deformation-field by characterizing the true posterior distribution.