 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SwAMP: Swapped Assignment of Multi-Modal Pairs for Cross-Modal Retrieval
Nov 10, 2021
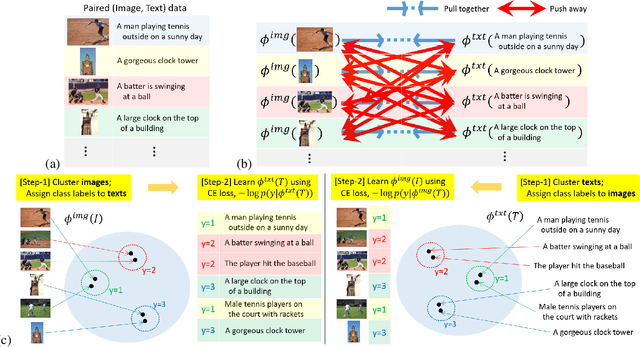
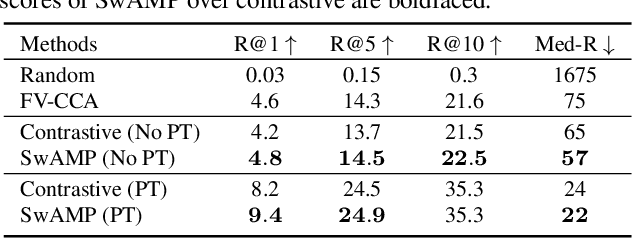
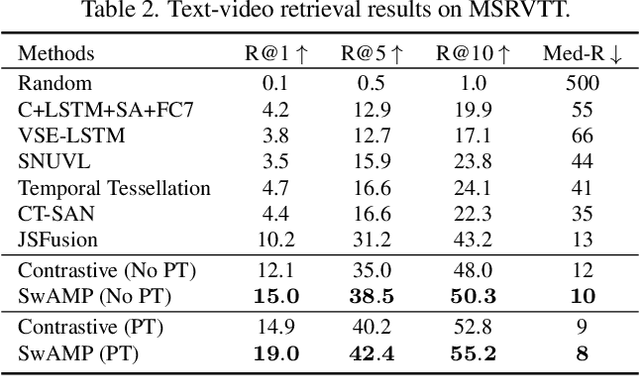
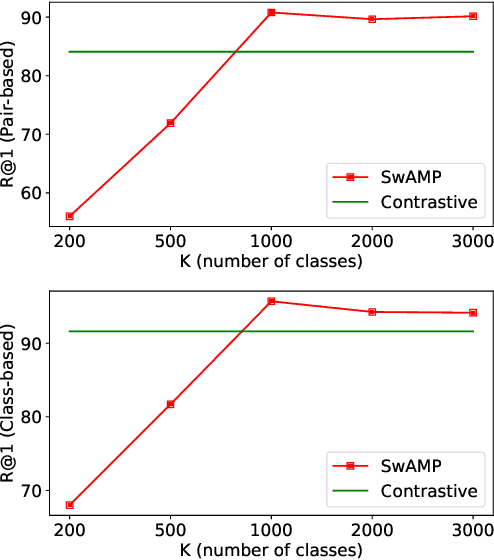
We tackle the cross-modal retrieval problem, where the training is only supervised by the relevant multi-modal pairs in the data. The contrastive learning is the most popular approach for this task. However, its sampling complexity for learning is quadratic in the number of training data points. Moreover, it makes potentially wrong assumption that the instances in different pairs are automatically irrelevant. To address these issues, we propose a novel loss function that is based on self-labeling of the unknown classes. Specifically, we aim to predict class labels of the data instances in each modality, and assign those labels to the corresponding instances in the other modality (i.e., swapping the pseudo labels). With these swapped labels, we learn the data embedding for each modality using the supervised cross-entropy loss, hence leading to linear sampling complexity. We also maintain the queues for storing the embeddings of the latest batches, for which clustering assignment and embedding learning are done at the same time in an online fashion. This removes computational overhead of injecting intermittent epochs of entire training data sweep for offline clustering. We tested our approach on several real-world cross-modal retrieval problems, including text-based video retrieval, sketch-based image retrieval, and image-text retrieval, and for all these tasks our method achieves significant performance improvement over the contrastive learning.
GL-GAN: Adaptive Global and Local Bilevel Optimization model of Image Generation
Aug 06, 2020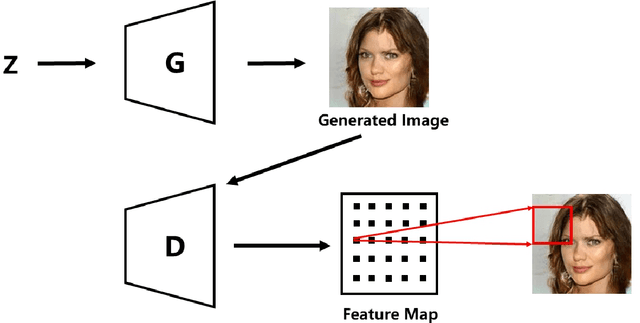


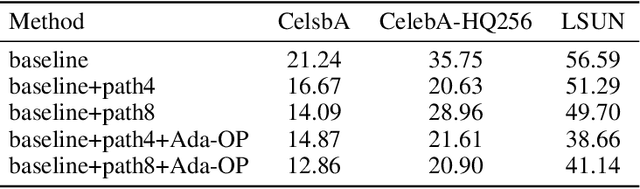
Although Generative Adversarial Networks have shown remarkable performance in image generation, there are some challenges in image realism and convergence speed. The results of some models display the imbalances of quality within a generated image, in which some defective parts appear compared with other regions. Different from general single global optimization methods, we introduce an adaptive global and local bilevel optimization model(GL-GAN). The model achieves the generation of high-resolution images in a complementary and promoting way, where global optimization is to optimize the whole images and local is only to optimize the low-quality areas. With a simple network structure, GL-GAN is allowed to effectively avoid the nature of imbalance by local bilevel optimization, which is accomplished by first locating low-quality areas and then optimizing them. Moreover, by using feature map cues from discriminator output, we propose the adaptive local and global optimization method(Ada-OP) for specific implementation and find that it boosts the convergence speed. Compared with the current GAN methods, our model has shown impressive performance on CelebA, CelebA-HQ and LSUN datasets.
Learning Interpretable Models Through Multi-Objective Neural Architecture Search
Dec 16, 2021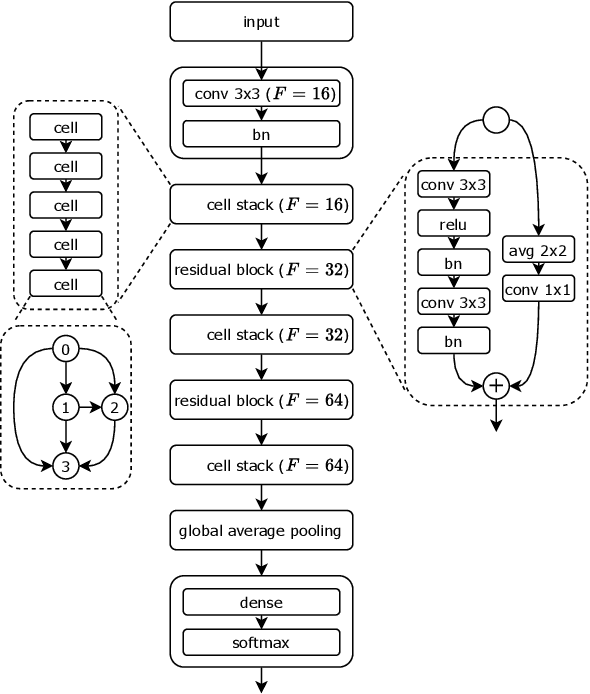
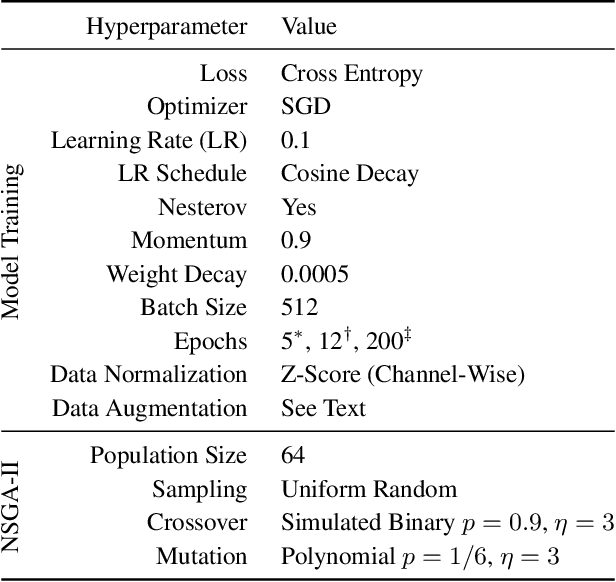
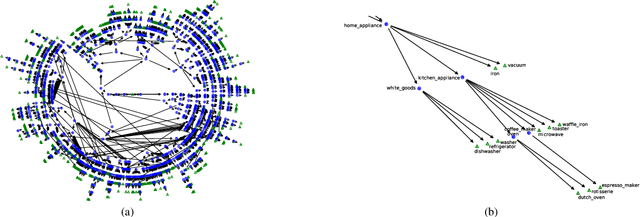
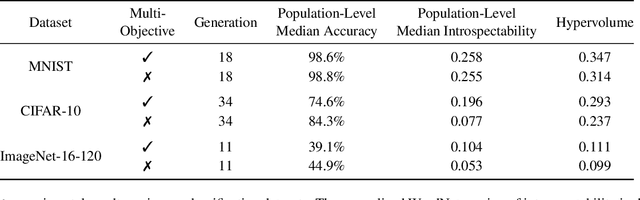
Monumental advances in deep learning have led to unprecedented achievements across a multitude of domains. While the performance of deep neural networks is indubitable, the architectural design and interpretability of such models are nontrivial. Research has been introduced to automate the design of neural network architectures through neural architecture search (NAS). Recent progress has made these methods more pragmatic by exploiting distributed computation and novel optimization algorithms. However, there is little work in optimizing architectures for interpretability. To this end, we propose a multi-objective distributed NAS framework that optimizes for both task performance and introspection. We leverage the non-dominated sorting genetic algorithm (NSGA-II) and explainable AI (XAI) techniques to reward architectures that can be better comprehended by humans. The framework is evaluated on several image classification datasets. We demonstrate that jointly optimizing for introspection ability and task error leads to more disentangled architectures that perform within tolerable error.
Uncertainty-Aware Blind Image Quality Assessment in the Laboratory and Wild
Jun 10, 2020
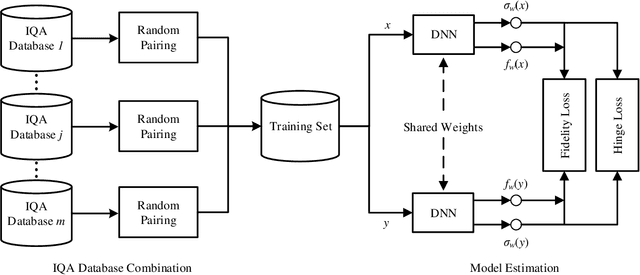
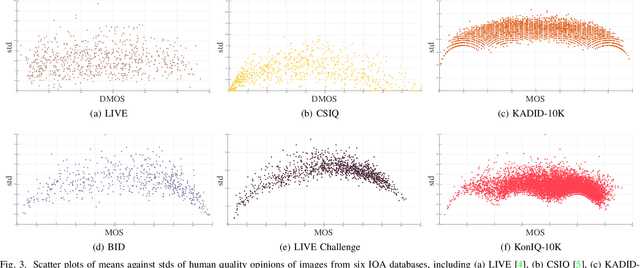

Performance of blind image quality assessment (BIQA) models has been significantly boosted by end-to-end optimization of feature engineering and quality regression. Nevertheless, due to the distributional shifts between images simulated in the laboratory and captured in the wild, models trained on databases with synthetic distortions remain particularly weak at handling realistic distortions (and vice versa). To confront the cross-distortion-scenario challenge, we develop a unified BIQA model and an effective approach of training it for both synthetic and realistic distortions. We first sample pairs of images from the same IQA databases and compute a probability that one image of each pair is of higher quality as the supervisory signal. We then employ the fidelity loss to optimize a deep neural network for BIQA over a large number of such image pairs. We also explicitly enforce a hinge constraint to regularize uncertainty estimation during optimization. Extensive experiments on six IQA databases show the promise of the learned method in blindly assessing image quality in the laboratory and wild. In addition, we demonstrate the universality of the proposed training strategy by using it to improve existing BIQA models.
DIB-R++: Learning to Predict Lighting and Material with a Hybrid Differentiable Renderer
Oct 30, 2021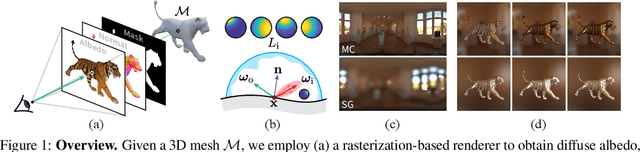
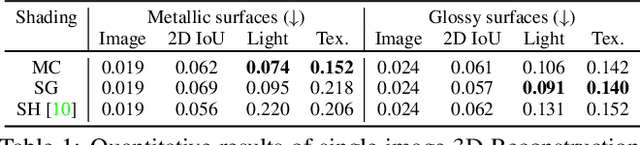
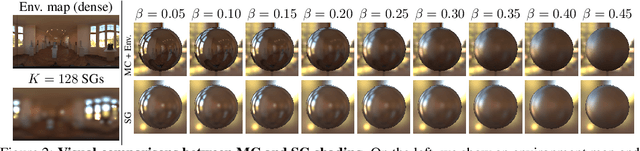

We consider the challenging problem of predicting intrinsic object properties from a single image by exploiting differentiable renderers. Many previous learning-based approaches for inverse graphics adopt rasterization-based renderers and assume naive lighting and material models, which often fail to account for non-Lambertian, specular reflections commonly observed in the wild. In this work, we propose DIBR++, a hybrid differentiable renderer which supports these photorealistic effects by combining rasterization and ray-tracing, taking the advantage of their respective strengths -- speed and realism. Our renderer incorporates environmental lighting and spatially-varying material models to efficiently approximate light transport, either through direct estimation or via spherical basis functions. Compared to more advanced physics-based differentiable renderers leveraging path tracing, DIBR++ is highly performant due to its compact and expressive shading model, which enables easy integration with learning frameworks for geometry, reflectance and lighting prediction from a single image without requiring any ground-truth. We experimentally demonstrate that our approach achieves superior material and lighting disentanglement on synthetic and real data compared to existing rasterization-based approaches and showcase several artistic applications including material editing and relighting.
Learning a Single Model with a Wide Range of Quality Factors for JPEG Image Artifacts Removal
Sep 15, 2020
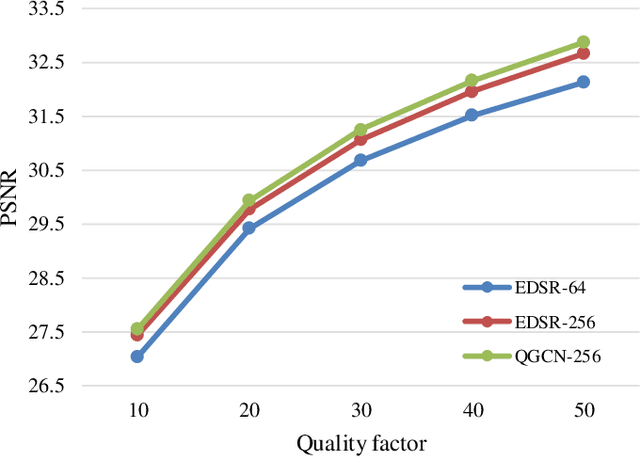
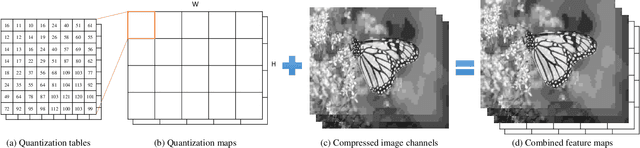
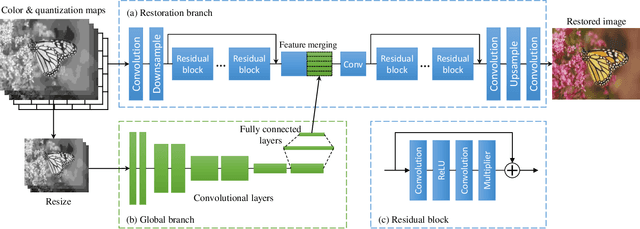
Lossy compression brings artifacts into the compressed image and degrades the visual quality. In recent years, many compression artifacts removal methods based on convolutional neural network (CNN) have been developed with great success. However, these methods usually train a model based on one specific value or a small range of quality factors. Obviously, if the test image's quality factor does not match to the assumed value range, then degraded performance will be resulted. With this motivation and further consideration of practical usage, a highly robust compression artifacts removal network is proposed in this paper. Our proposed network is a single model approach that can be trained for handling a wide range of quality factors while consistently delivering superior or comparable image artifacts removal performance. To demonstrate, we focus on the JPEG compression with quality factors, ranging from 1 to 60. Note that a turnkey success of our proposed network lies in the novel utilization of the quantization tables as part of the training data. Furthermore, it has two branches in parallel---i.e., the restoration branch and the global branch. The former effectively removes the local artifacts, such as ringing artifacts removal. On the other hand, the latter extracts the global features of the entire image that provides highly instrumental image quality improvement, especially effective on dealing with the global artifacts, such as blocking, color shifting. Extensive experimental results performed on color and grayscale images have clearly demonstrated the effectiveness and efficacy of our proposed single-model approach on the removal of compression artifacts from the decoded image.
A Contrastive Learning Approach to Auroral Identification and Classification
Sep 29, 2021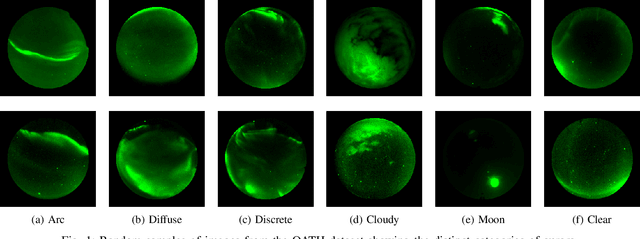
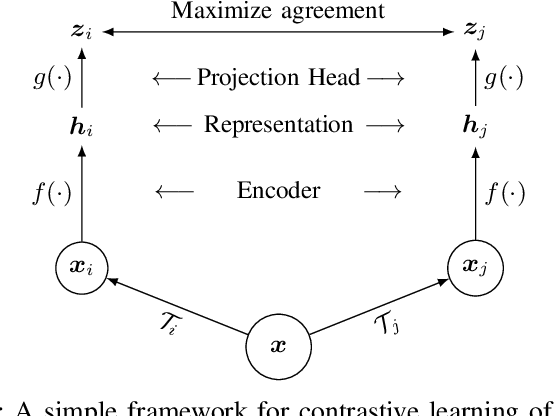
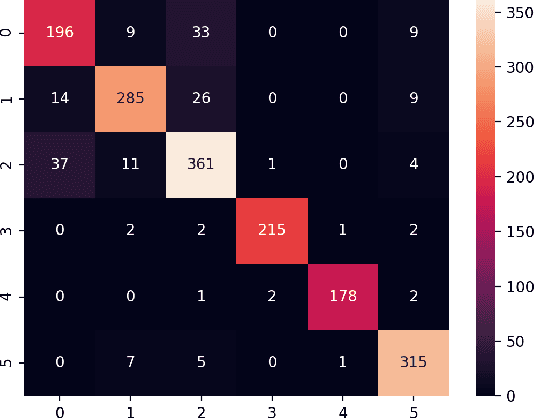
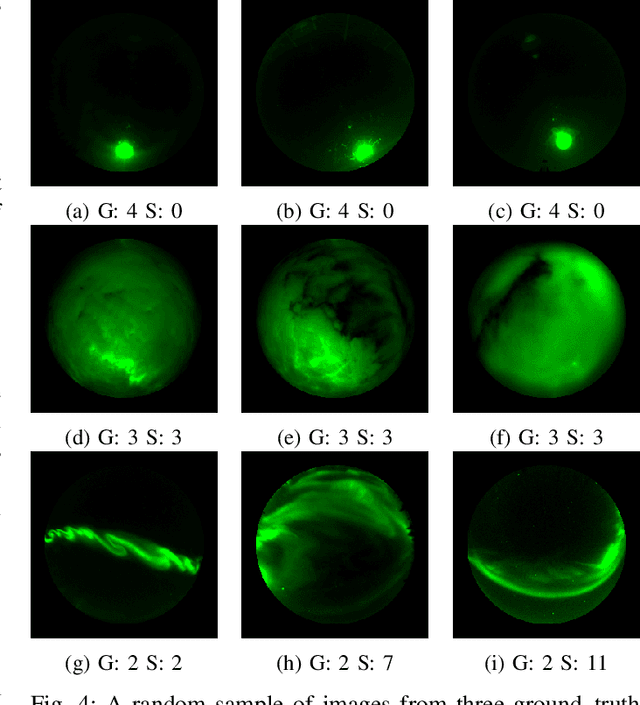
Unsupervised learning algorithms are beginning to achieve accuracies comparable to their supervised counterparts on benchmark computer vision tasks, but their utility for practical applications has not yet been demonstrated. In this work, we present a novel application of unsupervised learning to the task of auroral image classification. Specifically, we modify and adapt the Simple framework for Contrastive Learning of Representations (SimCLR) algorithm to learn representations of auroral images in a recently released auroral image dataset constructed using image data from Time History of Events and Macroscale Interactions during Substorms (THEMIS) all-sky imagers. We demonstrate that (a) simple linear classifiers fit to the learned representations of the images achieve state-of-the-art classification performance, improving the classification accuracy by almost 10 percentage points over the current benchmark; and (b) the learned representations naturally cluster into more clusters than exist manually assigned categories, suggesting that existing categorizations are overly coarse and may obscure important connections between auroral types, near-earth solar wind conditions, and geomagnetic disturbances at the earth's surface. Moreover, our model is much lighter than the previous benchmark on this dataset, requiring in the area of fewer than 25\% of the number of parameters. Our approach exceeds an established threshold for operational purposes, demonstrating readiness for deployment and utilization.
Instance Segmentation for Direct Measurements of Satellites in Metal Powders and Automated Microstructural Characterization from Image Data
Jan 05, 2021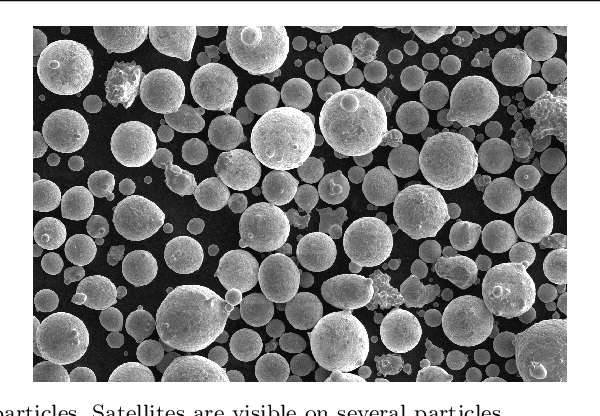
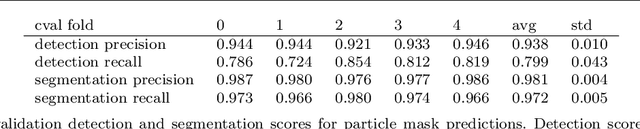


We propose instance segmentation as a useful tool for image analysis in materials science. Instance segmentation is an advanced technique in computer vision which generates individual segmentation masks for every object of interest that is recognized in an image. Using an out-of-the-box implementation of Mask R-CNN, instance segmentation is applied to images of metal powder particles produced through gas atomization. Leveraging transfer learning allows for the analysis to be conducted with a very small training set of labeled images. As well as providing another method for measuring the particle size distribution, we demonstrate the first direct measurements of the satellite content in powder samples. After analyzing the results for the labeled data dataset, the trained model was used to generate measurements for a much larger set of unlabeled images. The resulting particle size measurements showed reasonable agreement with laser scattering measurements. The satellite measurements were self-consistent and showed good agreement with the expected trends for different samples. Finally, we provide a small case study showing how instance segmentation can be used to measure spheroidite content in the UltraHigh Carbon Steel Database, demonstrating the flexibility of the technique.
Multi-Label Classification on Remote-Sensing Images
Jan 06, 2022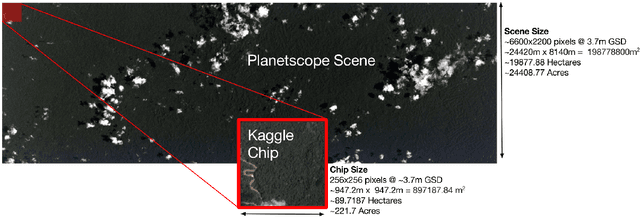

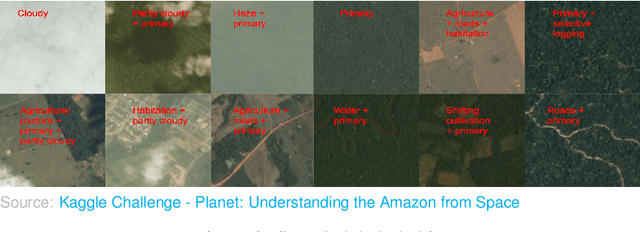
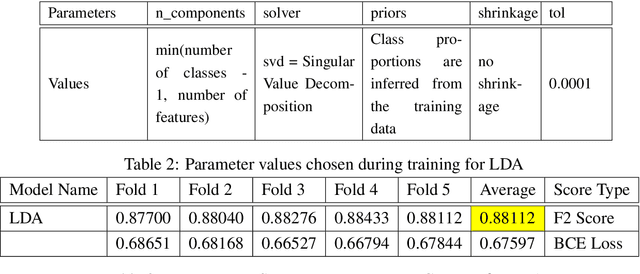
Acquiring information on large areas on the earth's surface through satellite cameras allows us to see much more than we can see while standing on the ground. This assists us in detecting and monitoring the physical characteristics of an area like land-use patterns, atmospheric conditions, forest cover, and many unlisted aspects. The obtained images not only keep track of continuous natural phenomena but are also crucial in tackling the global challenge of severe deforestation. Among which Amazon basin accounts for the largest share every year. Proper data analysis would help limit detrimental effects on the ecosystem and biodiversity with a sustainable healthy atmosphere. This report aims to label the satellite image chips of the Amazon rainforest with atmospheric and various classes of land cover or land use through different machine learning and superior deep learning models. Evaluation is done based on the F2 metric, while for loss function, we have both sigmoid cross-entropy as well as softmax cross-entropy. Images are fed indirectly to the machine learning classifiers after only features are extracted using pre-trained ImageNet architectures. Whereas for deep learning models, ensembles of fine-tuned ImageNet pre-trained models are used via transfer learning. Our best score was achieved so far with the F2 metric is 0.927.
Learning End-to-End Lossy Image Compression: A Benchmark
Feb 19, 2020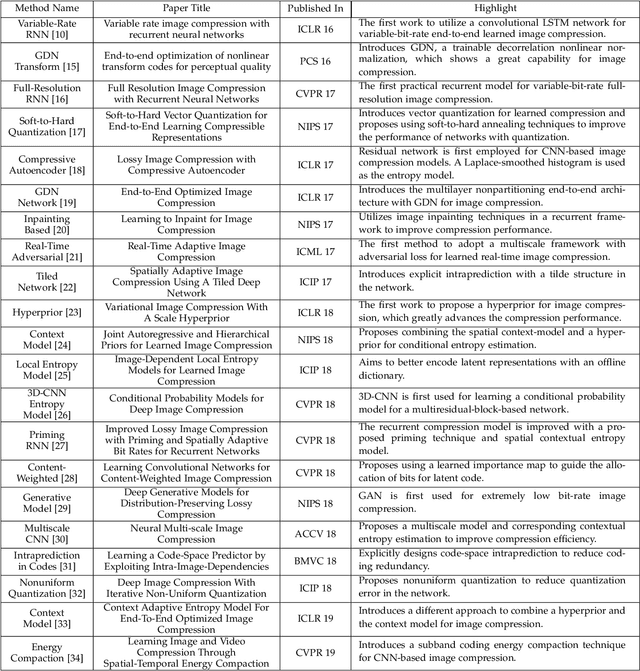
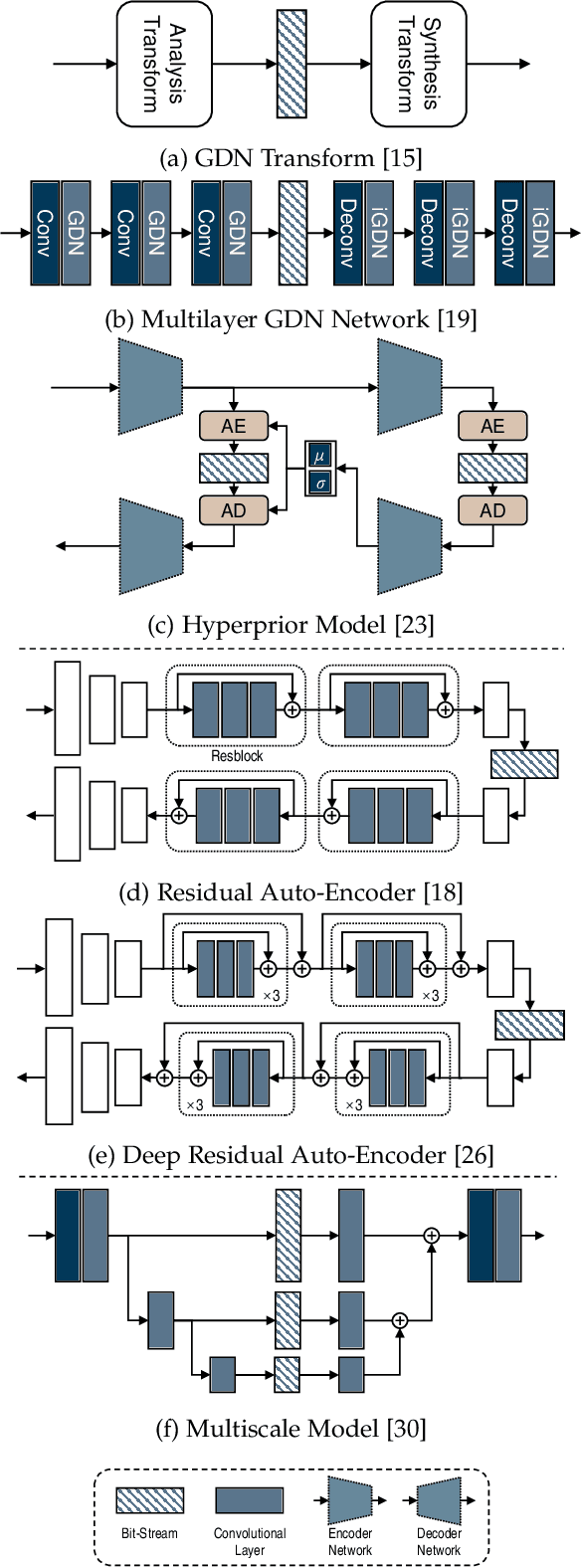
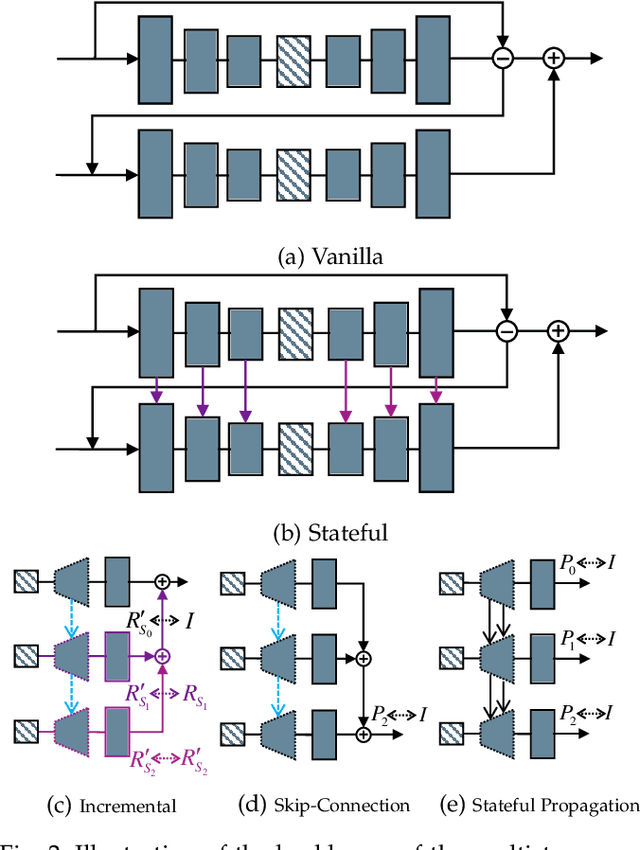
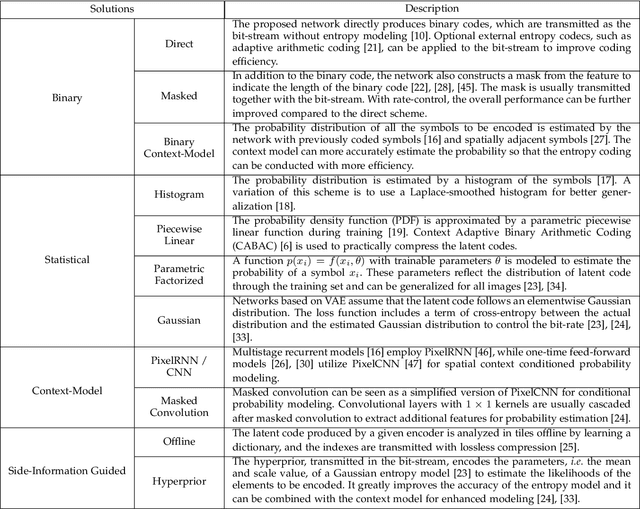
Image compression is one of the most fundamental techniques and commonly used applications in the image and video processing field. Earlier methods built a well-designed pipeline, and efforts were made to improve all modules of the pipeline by handcrafted tuning. Later, tremendous contributions were made, especially when data-driven methods revitalized the domain with their excellent modeling capacities and flexibility in incorporating newly designed modules and constraints. Despite great progress, a systematic benchmark and comprehensive analysis of end-to-end learned image compression methods are lacking. In this paper, we first conduct a comprehensive literature survey of learned image compression methods. The literature is organized based on several aspects to jointly optimize the rate-distortion performance with a neural network, i.e., network architecture, entropy model and rate control. We describe milestones in cutting-edge learned image-compression methods, review a broad range of existing works, and provide insights into their historical development routes. With this survey, the main challenges of image compression methods are revealed, along with opportunities to address the related issues with recent advanced learning methods. This analysis provides an opportunity to take a further step towards higher-efficiency image compression. By introducing a coarse-to-fine hyperprior model for entropy estimation and signal reconstruction, we achieve improved rate-distortion performance, especially on high-resolution images. Extensive benchmark experiments demonstrate the superiority of our model in coding efficiency and the potential for acceleration by large-scale parallel computing devices.