 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditional Temporal Variational AutoEncoder for Action Video Prediction
Aug 12, 2021


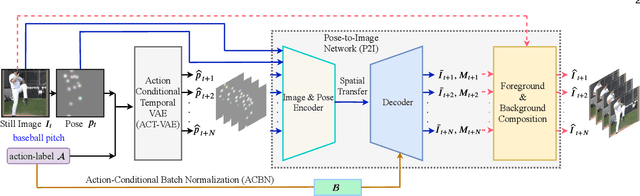

To synthesize a realistic action sequence based on a single human image, it is crucial to model both motion patterns and diversity in the action video. This paper proposes an Action Conditional Temporal Variational AutoEncoder (ACT-VAE) to improve motion prediction accuracy and capture movement diversity. ACT-VAE predicts pose sequences for an action clips from a single input image. It is implemented as a deep generative model that maintains temporal coherence according to the action category with a novel temporal modeling on latent space. Further, ACT-VAE is a general action sequence prediction framework. When connected with a plug-and-play Pose-to-Image (P2I) network, ACT-VAE can synthesize image sequences. Extensive experiments bear out our approach can predict accurate pose and synthesize realistic image sequences, surpassing state-of-the-art approaches. Compared to existing methods, ACT-VAE improves model accuracy and preserves diversity.
Unsupervised Image-to-Image Translation with Self-Attention Networks
Jan 24, 2019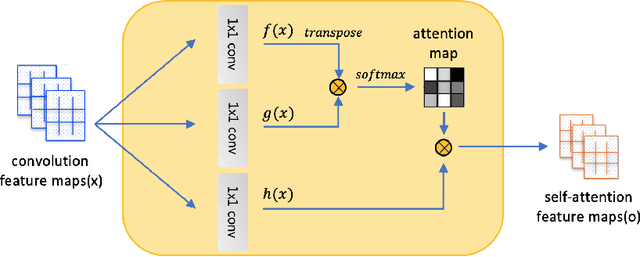
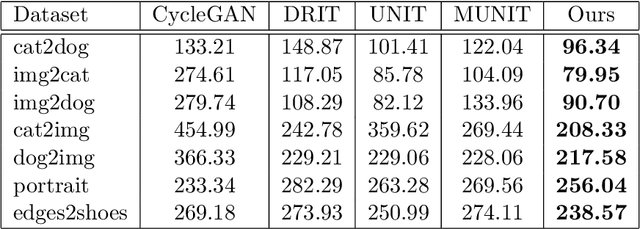
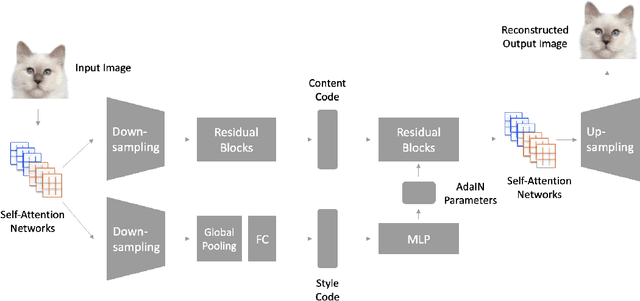

Unsupervised image translation aims to learn the transformation from a source domain to another target domain given unpaired training data. Several state-of-the-art works have yielded impressive results in the GANs-based unsupervised image-to-image translation. It fails to capture strong geometric or structural change between domains or is unsatisfactory for complex scenes, compared to texture change tasks such as style transfer. Recently, SAGAN (Han Zhang, 2018) showed that the self-attention network produces better results than the convolution-based GAN. However, the effectiveness of the self-attention network in unsupervised image-to-image translation tasks have not been verified. In this paper, we propose an unsupervised image-to-image translation with self-attention networks, in which long range dependency helps to not only capture strong geometric change but also generate details using cues from all feature locations. In experiments, we qualitatively and quantitatively show superiority of the proposed method compared to existing state-of-the-art unsupervised image-to-image translation task.
Taylor-Lagrange Neural Ordinary Differential Equations: Toward Fast Training and Evaluation of Neural ODEs
Jan 14, 2022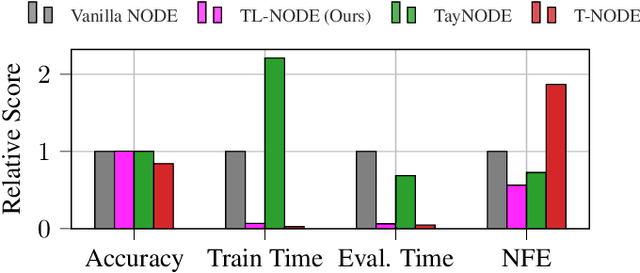


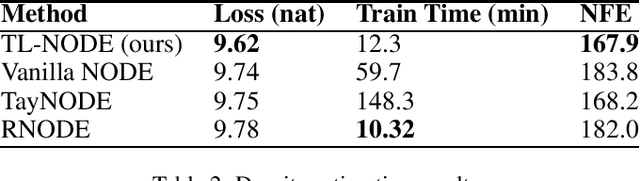
Neural ordinary differential equations (NODEs) -- parametrizations of differential equations using neural networks -- have shown tremendous promise in learning models of unknown continuous-time dynamical systems from data. However, every forward evaluation of a NODE requires numerical integration of the neural network used to capture the system dynamics, making their training prohibitively expensive. Existing works rely on off-the-shelf adaptive step-size numerical integration schemes, which often require an excessive number of evaluations of the underlying dynamics network to obtain sufficient accuracy for training. By contrast, we accelerate the evaluation and the training of NODEs by proposing a data-driven approach to their numerical integration. The proposed Taylor-Lagrange NODEs (TL-NODEs) use a fixed-order Taylor expansion for numerical integration, while also learning to estimate the expansion's approximation error. As a result, the proposed approach achieves the same accuracy as adaptive step-size schemes while employing only low-order Taylor expansions, thus greatly reducing the computational cost necessary to integrate the NODE. A suite of numerical experiments, including modeling dynamical systems, image classification, and density estimation, demonstrate that TL-NODEs can be trained more than an order of magnitude faster than state-of-the-art approaches, without any loss in performance.
ThreshNet: An Efficient DenseNet using Threshold Mechanism to Reduce Connections
Jan 09, 2022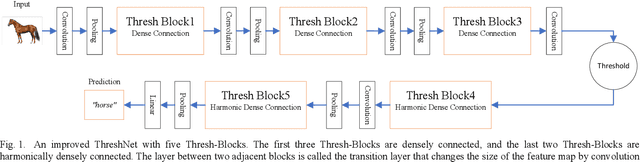
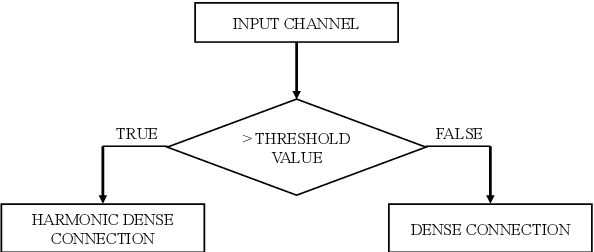
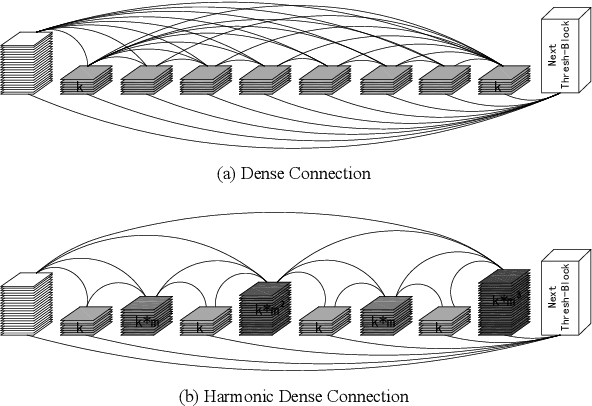
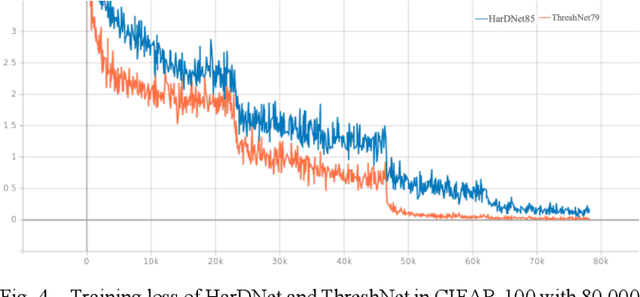
With the continuous development of neural networks in computer vision tasks, more and more network architectures have achieved outstanding success. As one of the most advanced neural network architectures, DenseNet shortcuts all feature maps to solve the problem of model depth. Although this network architecture has excellent accuracy at low MACs (multiplications and accumulations), it takes excessive inference time. To solve this problem, HarDNet reduces the connections between feature maps, making the remaining connections resemble harmonic waves. However, this compression method may result in decreasing model accuracy and increasing MACs and model size. This network architecture only reduces the memory access time, its overall performance still needs to be improved. Therefore, we propose a new network architecture using threshold mechanism to further optimize the method of connections. Different numbers of connections for different convolutional layers are discarded to compress the feature maps in ThreshNet. The proposed network architecture used three datasets, CIFAR-10, CIFAR-100, and SVHN, to evaluate the performance for image classifications. Experimental results show that ThreshNet achieves up to 60% reduction in inference time compared to DenseNet, and up to 35% faster training speed and 20% reduction in error rate compared to HarDNet on these datasets.
Investigating Shifts in GAN Output-Distributions
Dec 28, 2021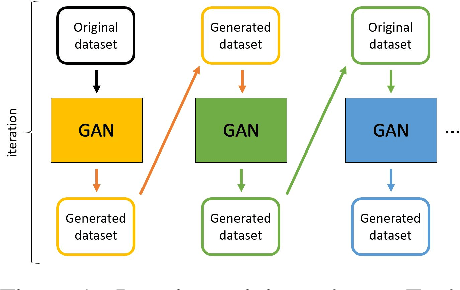

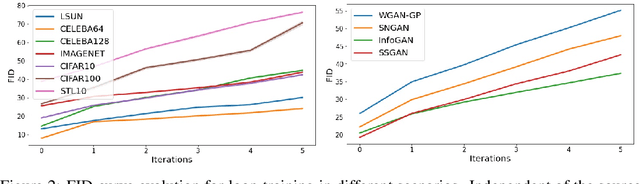
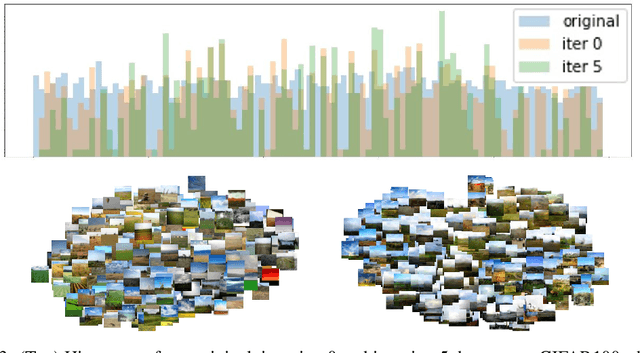
A fundamental and still largely unsolved question in the context of Generative Adversarial Networks is whether they are truly able to capture the real data distribution and, consequently, to sample from it. In particular, the multidimensional nature of image distributions leads to a complex evaluation of the diversity of GAN distributions. Existing approaches provide only a partial understanding of this issue, leaving the question unanswered. In this work, we introduce a loop-training scheme for the systematic investigation of observable shifts between the distributions of real training data and GAN generated data. Additionally, we introduce several bounded measures for distribution shifts, which are both easy to compute and to interpret. Overall, the combination of these methods allows an explorative investigation of innate limitations of current GAN algorithms. Our experiments on different data-sets and multiple state-of-the-art GAN architectures show large shifts between input and output distributions, showing that existing theoretical guarantees towards the convergence of output distributions appear not to be holding in practice.
Uncertainty quantification and inverse modeling for subsurface flow in 3D heterogeneous formations using a theory-guided convolutional encoder-decoder network
Nov 14, 2021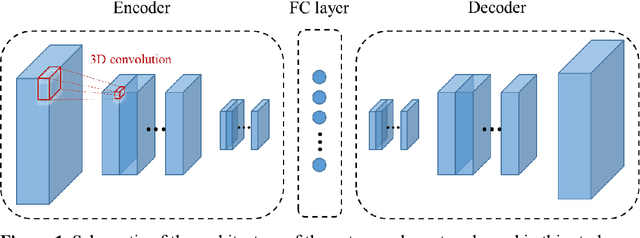
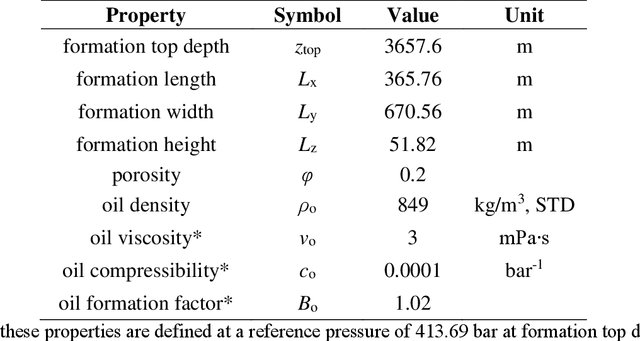
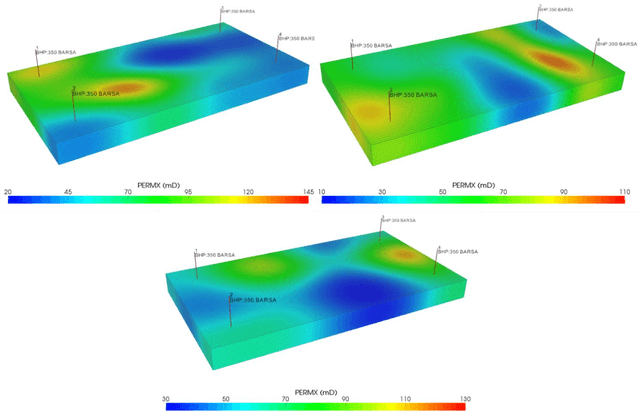
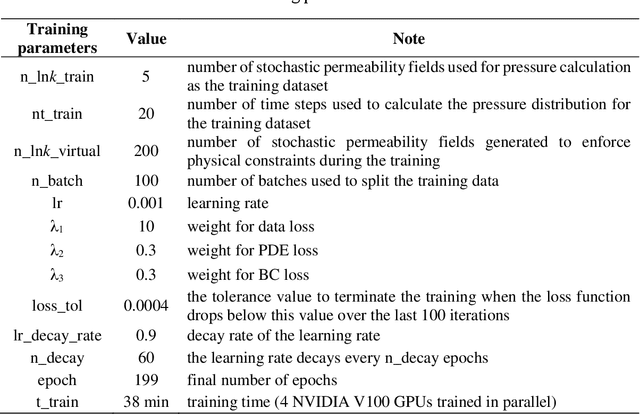
We build surrogate models for dynamic 3D subsurface single-phase flow problems with multiple vertical producing wells. The surrogate model provides efficient pressure estimation of the entire formation at any timestep given a stochastic permeability field, arbitrary well locations and penetration lengths, and a timestep matrix as inputs. The well production rate or bottom hole pressure can then be determined based on Peaceman's formula. The original surrogate modeling task is transformed into an image-to-image regression problem using a convolutional encoder-decoder neural network architecture. The residual of the governing flow equation in its discretized form is incorporated into the loss function to impose theoretical guidance on the model training process. As a result, the accuracy and generalization ability of the trained surrogate models are significantly improved compared to fully data-driven models. They are also shown to have flexible extrapolation ability to permeability fields with different statistics. The surrogate models are used to conduct uncertainty quantification considering a stochastic permeability field, as well as to infer unknown permeability information based on limited well production data and observation data of formation properties. Results are shown to be in good agreement with traditional numerical simulation tools, but computational efficiency is dramatically improved.
Photoacoustic digital brain: numerical modelling and image reconstruction via deep learning
Sep 19, 2021
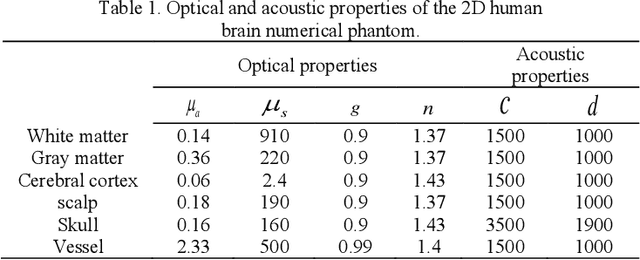
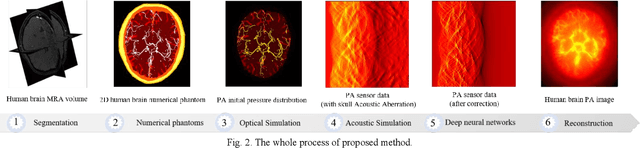
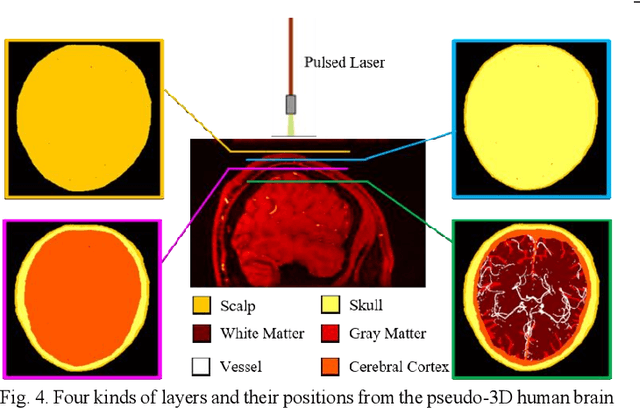
Photoacoustic tomography (PAT) is a newly developed medical imaging modality, which combines the advantages of pure optical imaging and ultrasound imaging, owning both high optical contrast and deep penetration depth. Very recently, PAT is studied in human brain imaging. Nevertheless, while ultrasound waves are passing through the human skull tissues, the strong acoustic attenuation and aberration will happen, which causes photoacoustic signals' distortion. In this work, we use 10 magnetic resonance angiography (MRA) human brain volumes, and manually segment them to obtain the 2D human brain numerical phantoms for PAT. The numerical phantoms contain six kinds of tissues which are scalp, skull, white matter, gray matter, blood vessel and cerebral cortex. For every numerical phantom, optical properties are assigned to every kind of tissues. Then, Monte-Carlo based optical simulation is deployed to obtain the photoacoustic initial pressure. Then, we made two k-wave simulation cases: one takes inhomogeneous medium and uneven sound velocity into consideration, and the other not. Then we use the sensor data of the former one as the input of U-net, and the sensor data of the latter one as the output of U-net to train the network. We randomly choose 7 human brain PA sinograms as the training dataset and 3 human brain PA sinograms as the testing set. The testing result shows that our method could correct the skull acoustic aberration and obtain the blood vessel distribution inside the human brain satisfactorily.
A Pixel-Level Meta-Learner for Weakly Supervised Few-Shot Semantic Segmentation
Nov 02, 2021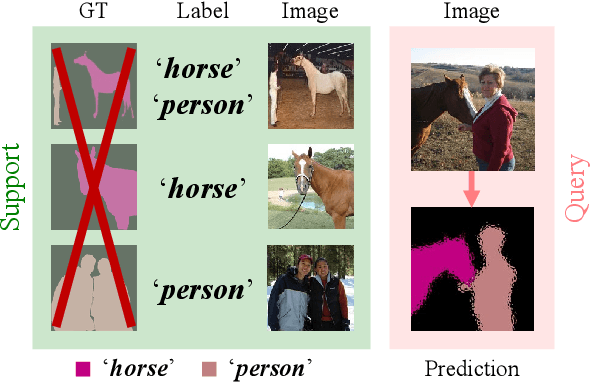
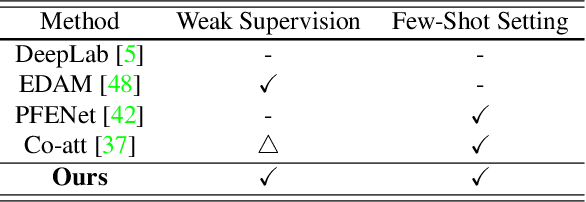
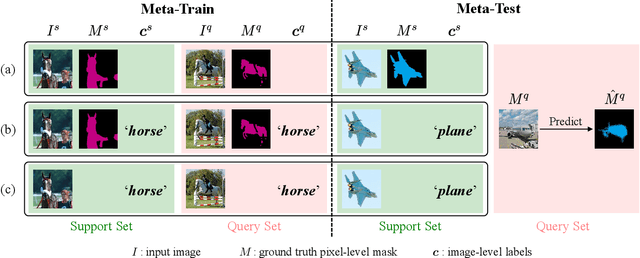
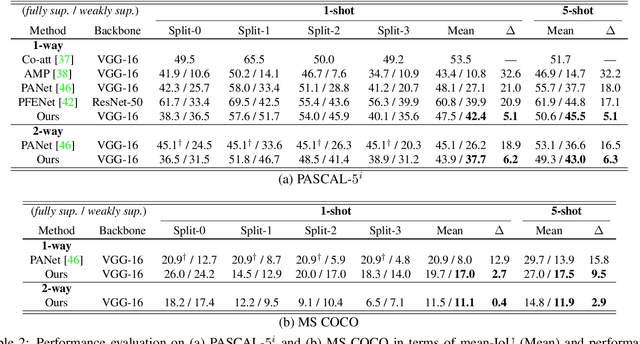
Few-shot semantic segmentation addresses the learning task in which only few images with ground truth pixel-level labels are available for the novel classes of interest. One is typically required to collect a large mount of data (i.e., base classes) with such ground truth information, followed by meta-learning strategies to address the above learning task. When only image-level semantic labels can be observed during both training and testing, it is considered as an even more challenging task of weakly supervised few-shot semantic segmentation. To address this problem, we propose a novel meta-learning framework, which predicts pseudo pixel-level segmentation masks from a limited amount of data and their semantic labels. More importantly, our learning scheme further exploits the produced pixel-level information for query image inputs with segmentation guarantees. Thus, our proposed learning model can be viewed as a pixel-level meta-learner. Through extensive experiments on benchmark datasets, we show that our model achieves satisfactory performances under fully supervised settings, yet performs favorably against state-of-the-art methods under weakly supervised settings.
Sequence Information Channel Concatenation for Improving Camera Trap Image Burst Classification
Apr 30, 2020
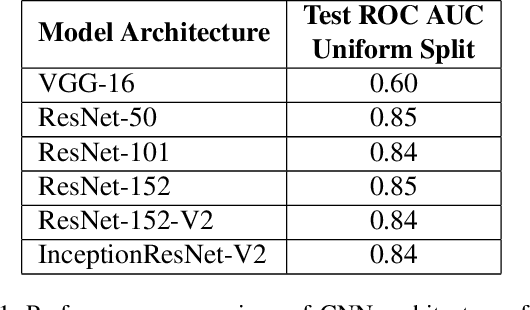
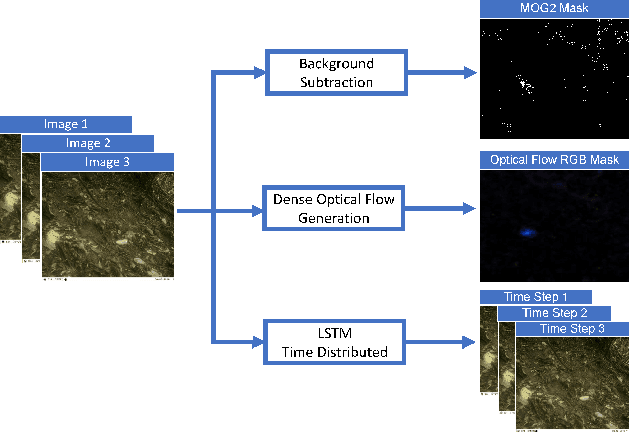
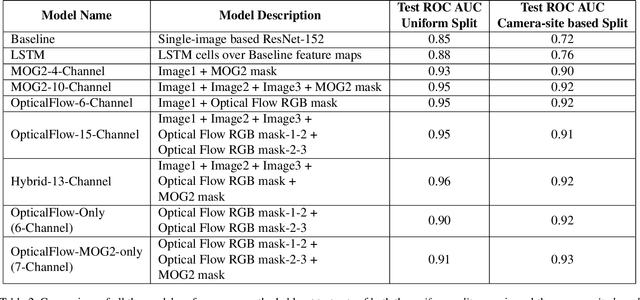
Camera Traps are extensively used to observe wildlife in their natural habitat without disturbing the ecosystem. This could help in the early detection of natural or human threats to animals, and help towards ecological conservation. Currently, a massive number of such camera traps have been deployed at various ecological conservation areas around the world, collecting data for decades, thereby requiring automation to detect images containing animals. Existing systems perform classification to detect if images contain animals by considering a single image. However, due to challenging scenes with animals camouflaged in their natural habitat, it sometimes becomes difficult to identify the presence of animals from merely a single image. We hypothesize that a short burst of images instead of a single image, assuming that the animal moves, makes it much easier for a human as well as a machine to detect the presence of animals. In this work, we explore a variety of approaches, and measure the impact of using short image sequences (burst of 3 images) on improving the camera trap image classification. We show that concatenating masks containing sequence information and the images from the 3-image-burst across channels, improves the ROC AUC by 20% on a test-set from unseen camera-sites, as compared to an equivalent model that learns from a single image.
Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection
Dec 09, 2021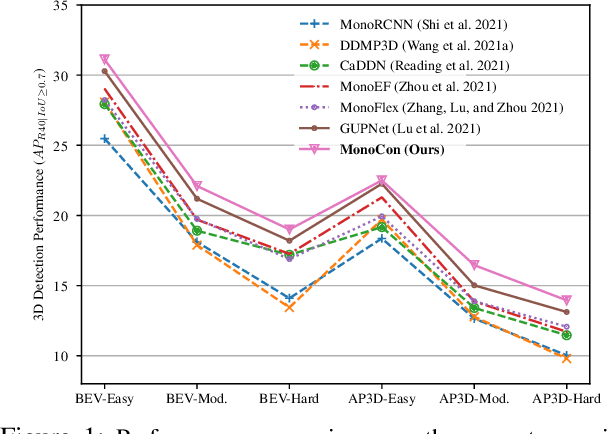
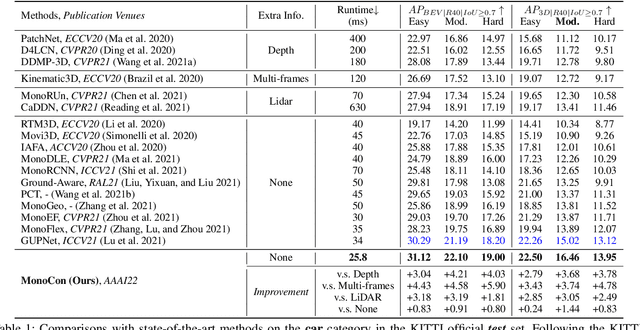
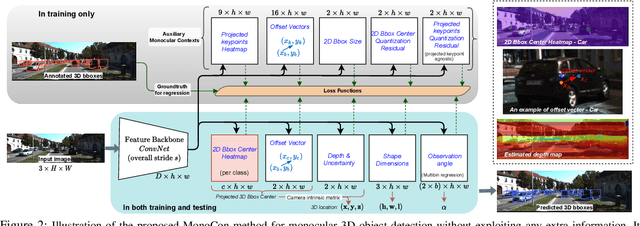
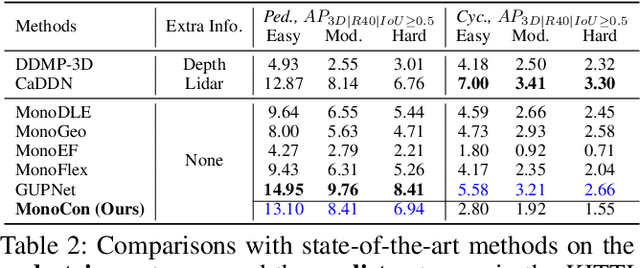
Monocular 3D object detection aims to localize 3D bounding boxes in an input single 2D image. It is a highly challenging problem and remains open, especially when no extra information (e.g., depth, lidar and/or multi-frames) can be leveraged in training and/or inference. This paper proposes a simple yet effective formulation for monocular 3D object detection without exploiting any extra information. It presents the MonoCon method which learns Monocular Contexts, as auxiliary tasks in training, to help monocular 3D object detection. The key idea is that with the annotated 3D bounding boxes of objects in an image, there is a rich set of well-posed projected 2D supervision signals available in training, such as the projected corner keypoints and their associated offset vectors with respect to the center of 2D bounding box, which should be exploited as auxiliary tasks in training. The proposed MonoCon is motivated by the Cramer-Wold theorem in measure theory at a high level. In implementation, it utilizes a very simple end-to-end design to justify the effectiveness of learning auxiliary monocular contexts, which consists of three components: a Deep Neural Network (DNN) based feature backbone, a number of regression head branches for learning the essential parameters used in the 3D bounding box prediction, and a number of regression head branches for learning auxiliary contexts. After training, the auxiliary context regression branches are discarded for better inference efficiency. In experiments, the proposed MonoCon is tested in the KITTI benchmark (car, pedestrain and cyclist). It outperforms all prior arts in the leaderboard on car category and obtains comparable performance on pedestrian and cyclist in terms of accuracy. Thanks to the simple design, the proposed MonoCon method obtains the fastest inference speed with 38.7 fps in comparisons