 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Protection of SVM Model with Secret Key from Unauthorized Access
Nov 17, 2021
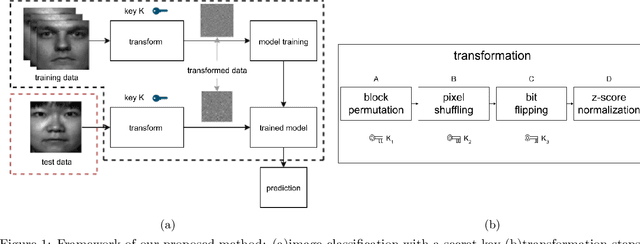


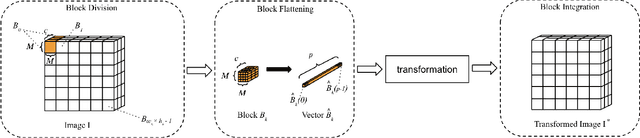
In this paper, we propose a block-wise image transformation method with a secret key for support vector machine (SVM) models. Models trained by using transformed images offer a poor performance to unauthorized users without a key, while they can offer a high performance to authorized users with a key. The proposed method is demonstrated to be robust enough against unauthorized access even under the use of kernel functions in a facial recognition experiment.
GoG: Relation-aware Graph-over-Graph Network for Visual Dialog
Sep 17, 2021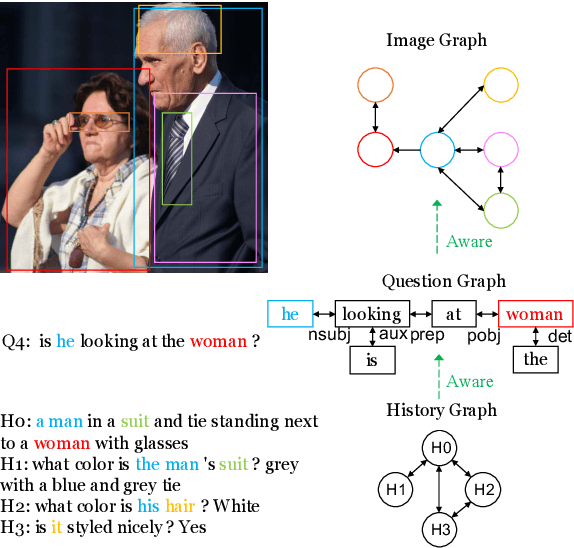
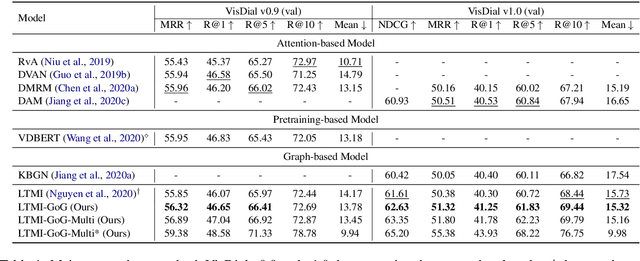
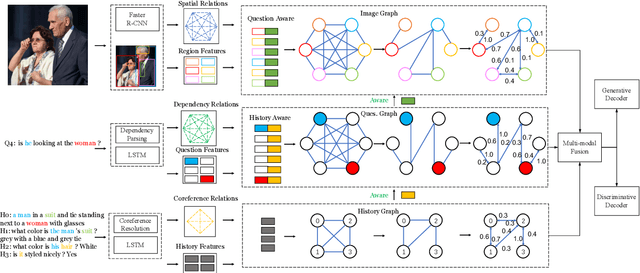
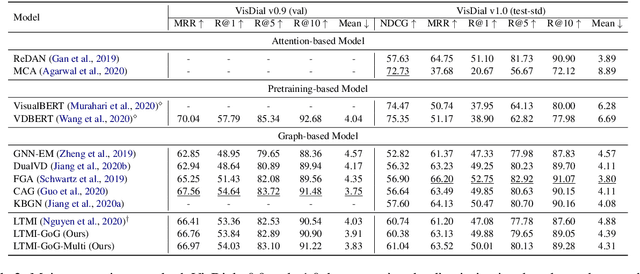
Visual dialog, which aims to hold a meaningful conversation with humans about a given image, is a challenging task that requires models to reason the complex dependencies among visual content, dialog history, and current questions. Graph neural networks are recently applied to model the implicit relations between objects in an image or dialog. However, they neglect the importance of 1) coreference relations among dialog history and dependency relations between words for the question representation; and 2) the representation of the image based on the fully represented question. Therefore, we propose a novel relation-aware graph-over-graph network (GoG) for visual dialog. Specifically, GoG consists of three sequential graphs: 1) H-Graph, which aims to capture coreference relations among dialog history; 2) History-aware Q-Graph, which aims to fully understand the question through capturing dependency relations between words based on coreference resolution on the dialog history; and 3) Question-aware I-Graph, which aims to capture the relations between objects in an image based on fully question representation. As an additional feature representation module, we add GoG to the existing visual dialogue model. Experimental results show that our model outperforms the strong baseline in both generative and discriminative settings by a significant margin.
Conditional Image Generation and Manipulation for User-Specified Content
May 11, 2020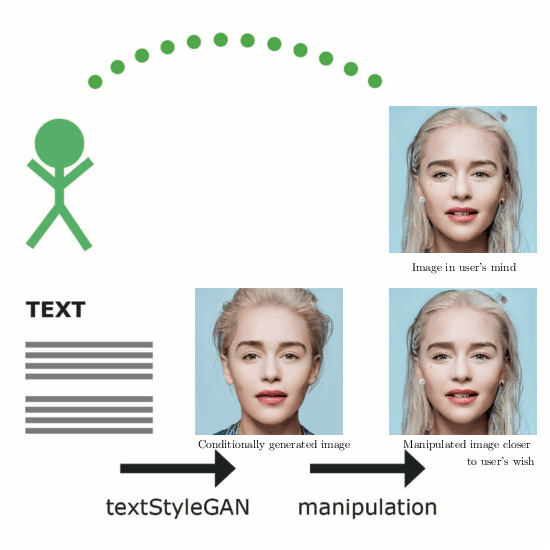
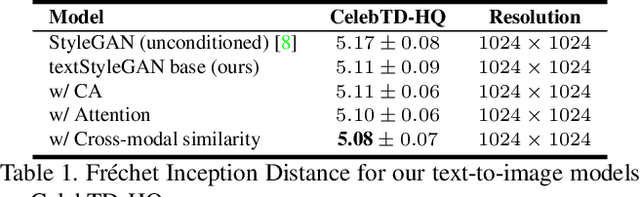
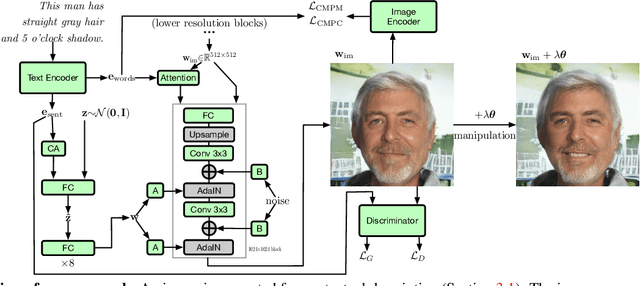
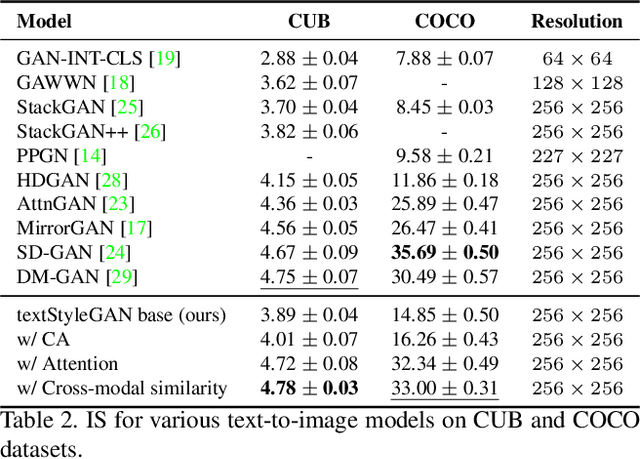
In recent years, Generative Adversarial Networks (GANs) have improved steadily towards generating increasingly impressive real-world images. It is useful to steer the image generation process for purposes such as content creation. This can be done by conditioning the model on additional information. However, when conditioning on additional information, there still exists a large set of images that agree with a particular conditioning. This makes it unlikely that the generated image is exactly as envisioned by a user, which is problematic for practical content creation scenarios such as generating facial composites or stock photos. To solve this problem, we propose a single pipeline for text-to-image generation and manipulation. In the first part of our pipeline we introduce textStyleGAN, a model that is conditioned on text. In the second part of our pipeline we make use of the pre-trained weights of textStyleGAN to perform semantic facial image manipulation. The approach works by finding semantic directions in latent space. We show that this method can be used to manipulate facial images for a wide range of attributes. Finally, we introduce the CelebTD-HQ dataset, an extension to CelebA-HQ, consisting of faces and corresponding textual descriptions.
MaskMTL: Attribute prediction in masked facial images with deep multitask learning
Jan 11, 2022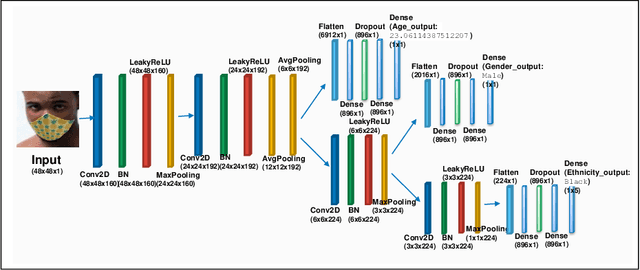
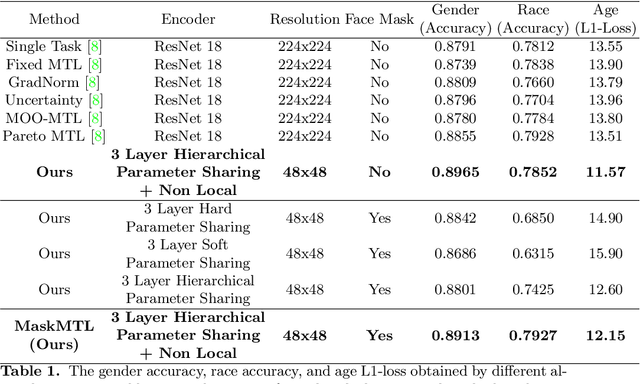

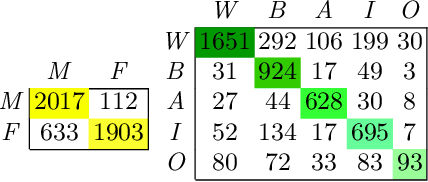
Predicting attributes in the landmark free facial images is itself a challenging task which gets further complicated when the face gets occluded due to the usage of masks. Smart access control gates which utilize identity verification or the secure login to personal electronic gadgets may utilize face as a biometric trait. Particularly, the Covid-19 pandemic increasingly validates the essentiality of hygienic and contactless identity verification. In such cases, the usage of masks become more inevitable and performing attribute prediction helps in segregating the target vulnerable groups from community spread or ensuring social distancing for them in a collaborative environment. We create a masked face dataset by efficiently overlaying masks of different shape, size and textures to effectively model variability generated by wearing mask. This paper presents a deep Multi-Task Learning (MTL) approach to jointly estimate various heterogeneous attributes from a single masked facial image. Experimental results on benchmark face attribute UTKFace dataset demonstrate that the proposed approach supersedes in performance to other competing techniques. The source code is available at https://github.com/ritikajha/Attribute-prediction-in-masked-facial-images-with-deep-multitask-learning
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020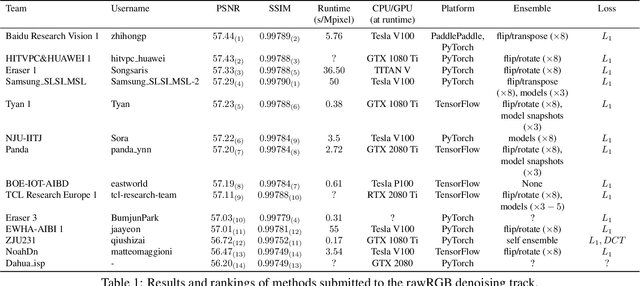
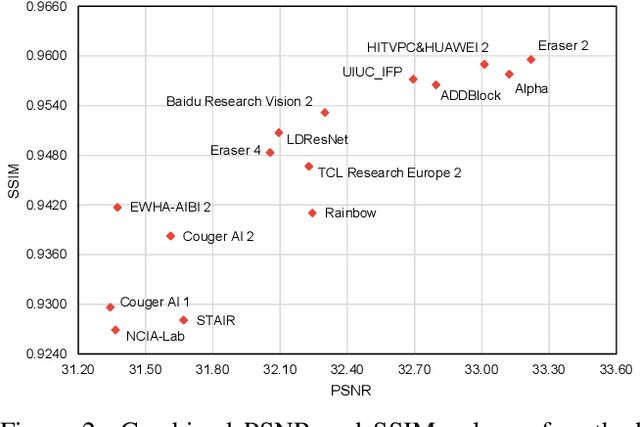
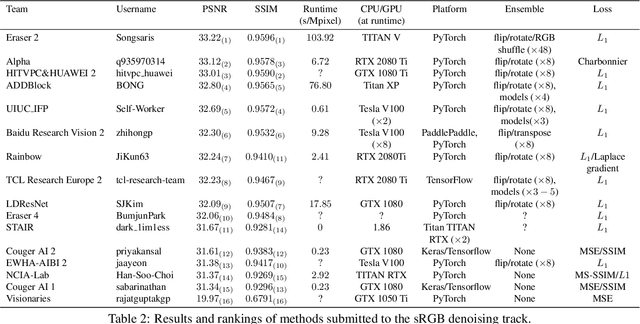
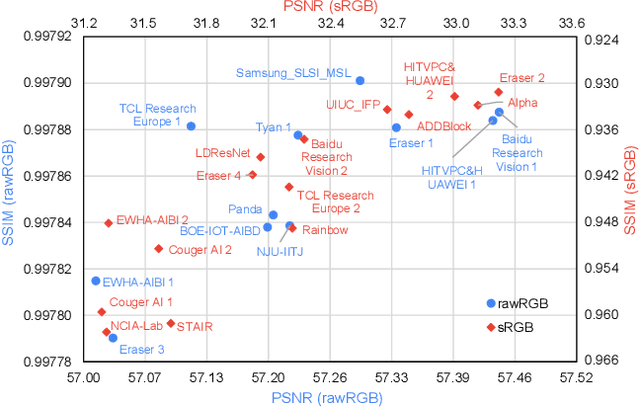
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Explanatory Analysis and Rectification of the Pitfalls in COVID-19 Datasets
Nov 10, 2021
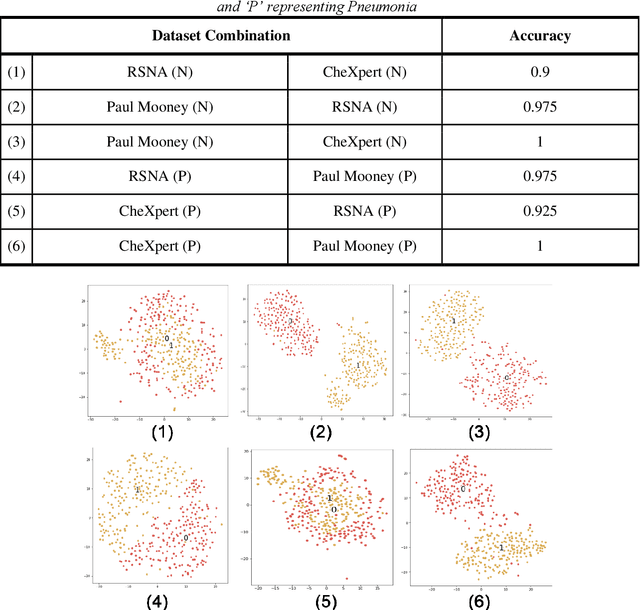
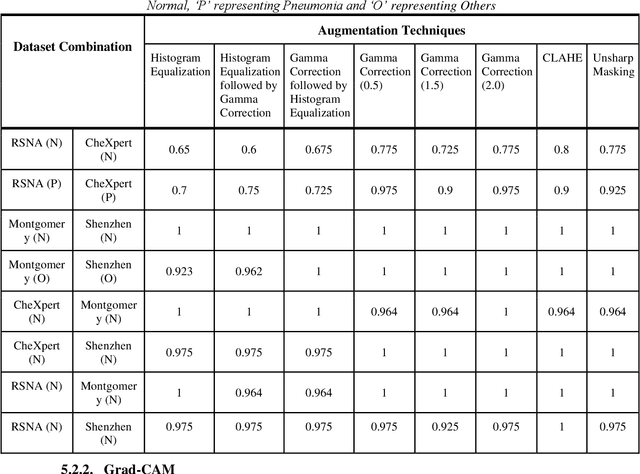
Since the onset of the COVID-19 pandemic in 2020, millions of people have succumbed to this deadly virus. Many attempts have been made to devise an automated method of testing that could detect the virus. Various researchers around the globe have proposed deep learning based methodologies to detect the COVID-19 using Chest X-Rays. However, questions have been raised on the presence of bias in the publicly available Chest X-Ray datasets which have been used by the majority of the researchers. In this paper, we propose a 2 staged methodology to address this topical issue. Two experiments have been conducted as a part of stage 1 of the methodology to exhibit the presence of bias in the datasets. Subsequently, an image segmentation, super-resolution and CNN based pipeline along with different image augmentation techniques have been proposed in stage 2 of the methodology to reduce the effect of bias. InceptionResNetV2 trained on Chest X-Ray images that were augmented with Histogram Equalization followed by Gamma Correction when passed through the pipeline proposed in stage 2, yielded a top accuracy of 90.47% for 3-class (Normal, Pneumonia, and COVID-19) classification task.
ArcFace Knows the Gender, Too!
Dec 19, 2021
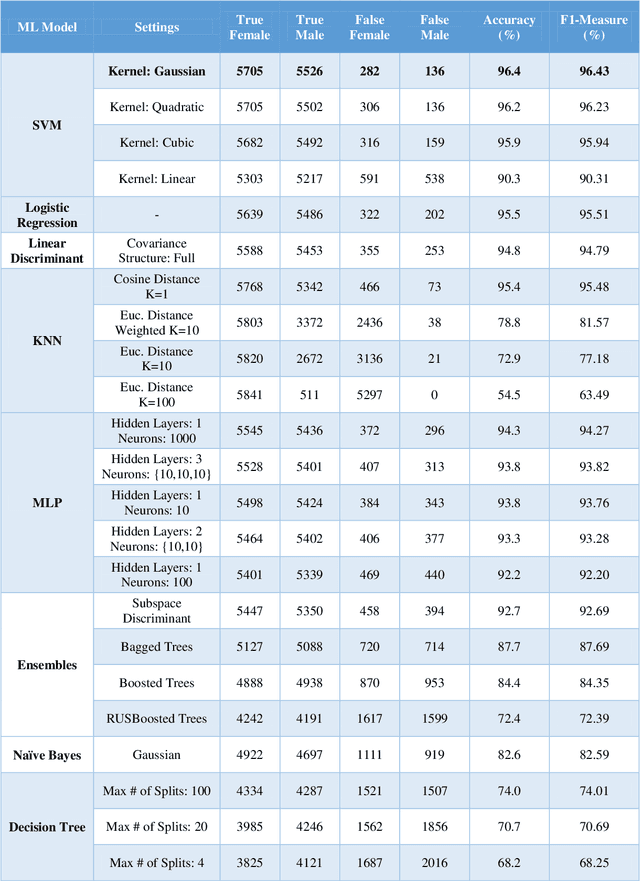
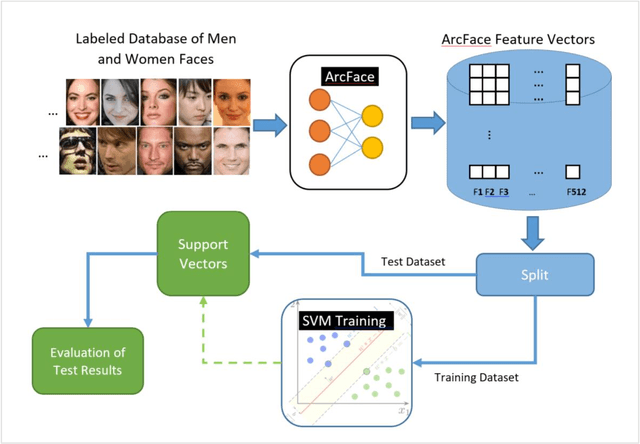
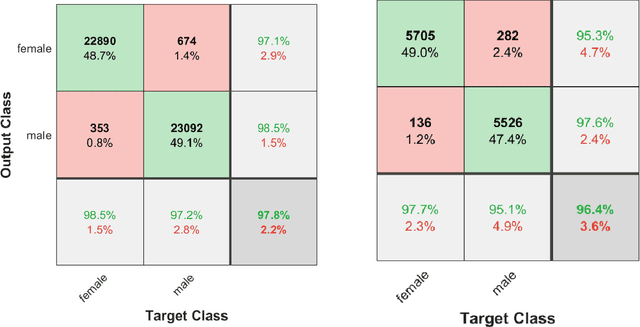
The main idea of this paper is that if a model can recognize a person, of course, it must be able to know the gender of that person, too. Therefore, instead of defining a new model for gender classification, this paper uses ArcFace features to determine gender, based on the facial features. A face image is given to ArcFace and 512 features are obtained for the face. Then, with the help of traditional machine learning models, gender is determined. Discriminative methods such as Support Vector Machine (SVM), Linear Discriminant, and Logistic Regression well demonstrate that the features extracted from the ArcFace create a remarkable distinction between the gender classes. Experiments on the Gender Classification Dataset show that SVM with Gaussian kernel is able to classify gender with an accuracy of 96.4% using ArcFace features.
Learning Enriched Features for Real Image Restoration and Enhancement
Mar 15, 2020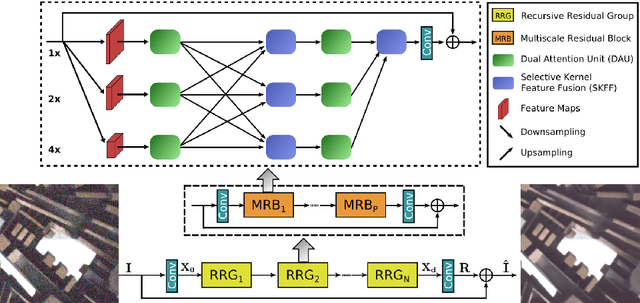

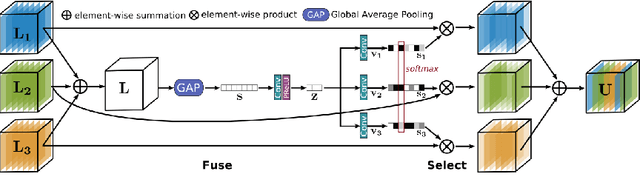
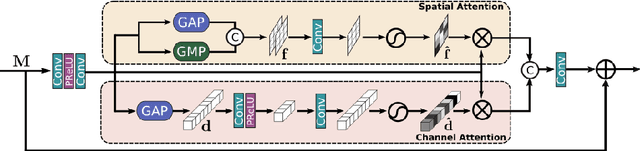
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography, medical imaging, and remote sensing. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present a novel architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In the nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for a variety of image processing tasks, including image denoising, super-resolution and image enhancement.
GhostSR: Learning Ghost Features for Efficient Image Super-Resolution
Jan 21, 2021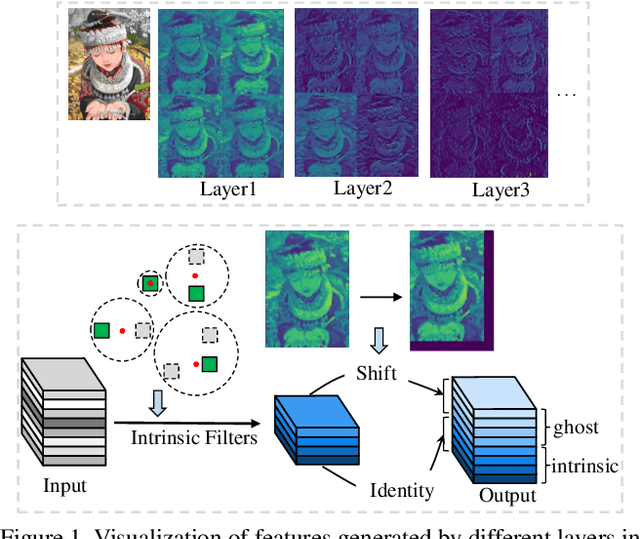
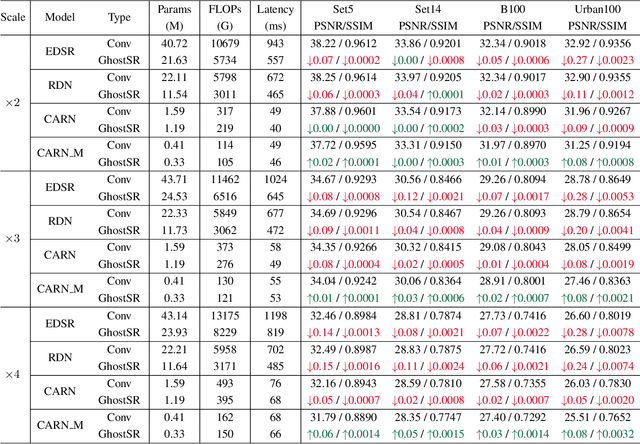
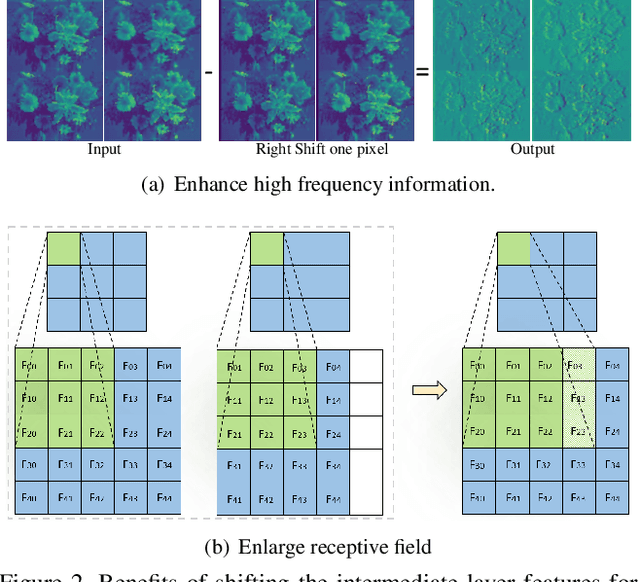
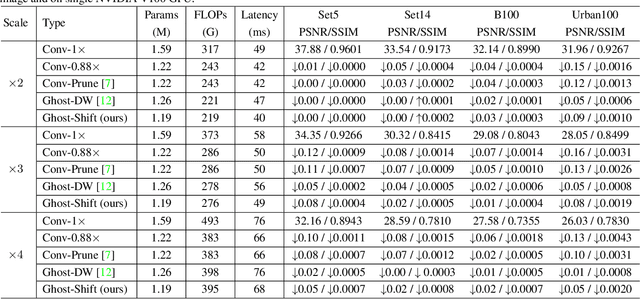
Modern single image super-resolution (SISR) system based on convolutional neural networks (CNNs) achieves fancy performance while requires huge computational costs. The problem on feature redundancy is well studied in visual recognition task, but rarely discussed in SISR. Based on the observation that many features in SISR models are also similar to each other, we propose to use shift operation to generate the redundant features (i.e., Ghost features). Compared with depth-wise convolution which is not friendly to GPUs or NPUs, shift operation can bring practical inference acceleration for CNNs on common hardware. We analyze the benefits of shift operation for SISR and make the shift orientation learnable based on Gumbel-Softmax trick. For a given pre-trained model, we first cluster all filters in each convolutional layer to identify the intrinsic ones for generating intrinsic features. Ghost features will be derived by moving these intrinsic features along a specific orientation. The complete output features are constructed by concatenating the intrinsic and ghost features together. Extensive experiments on several benchmark models and datasets demonstrate that both the non-compact and lightweight SISR models embedded in our proposed module can achieve comparable performance to that of their baselines with large reduction of parameters, FLOPs and GPU latency. For instance, we reduce the parameters by 47%, FLOPs by 46% and GPU latency by 41% of EDSR x2 network without significant performance degradation.
Learning Joint Embedding with Modality Alignments for Cross-Modal Retrieval of Recipes and Food Images
Aug 18, 2021

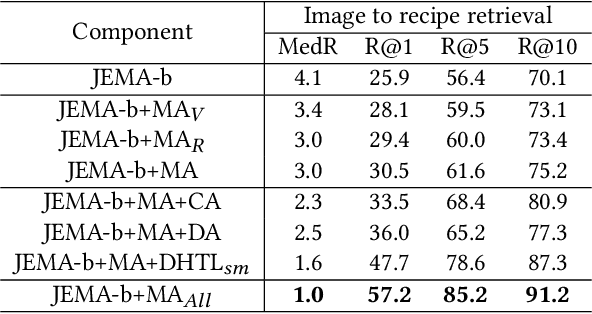

This paper presents a three-tier modality alignment approach to learning text-image joint embedding, coined as JEMA, for cross-modal retrieval of cooking recipes and food images. The first tier improves recipe text embedding by optimizing the LSTM networks with term extraction and ranking enhanced sequence patterns, and optimizes the image embedding by combining the ResNeXt-101 image encoder with the category embedding using wideResNet-50 with word2vec. The second tier modality alignment optimizes the textual-visual joint embedding loss function using a double batch-hard triplet loss with soft-margin optimization. The third modality alignment incorporates two types of cross-modality alignments as the auxiliary loss regularizations to further reduce the alignment errors in the joint learning of the two modality-specific embedding functions. The category-based cross-modal alignment aims to align the image category with the recipe category as a loss regularization to the joint embedding. The cross-modal discriminator-based alignment aims to add the visual-textual embedding distribution alignment to further regularize the joint embedding loss. Extensive experiments with the one-million recipes benchmark dataset Recipe1M demonstrate that the proposed JEMA approach outperforms the state-of-the-art cross-modal embedding methods for both image-to-recipe and recipe-to-image retrievals.