 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Emotion-Based End-to-End Matching Between Image and Music in Valence-Arousal Space
Aug 22, 2020
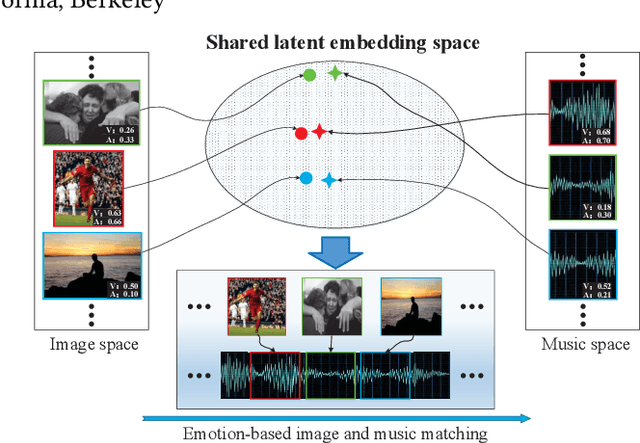
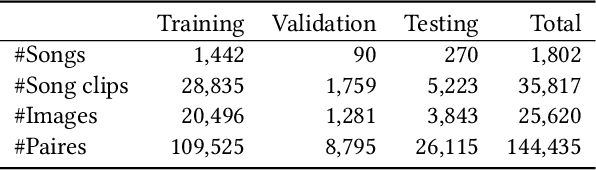
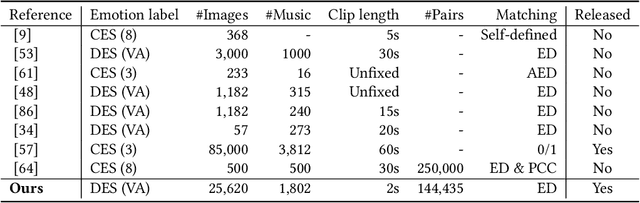
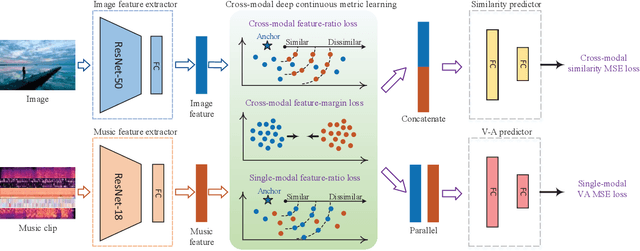
Both images and music can convey rich semantics and are widely used to induce specific emotions. Matching images and music with similar emotions might help to make emotion perceptions more vivid and stronger. Existing emotion-based image and music matching methods either employ limited categorical emotion states which cannot well reflect the complexity and subtlety of emotions, or train the matching model using an impractical multi-stage pipeline. In this paper, we study end-to-end matching between image and music based on emotions in the continuous valence-arousal (VA) space. First, we construct a large-scale dataset, termed Image-Music-Emotion-Matching-Net (IMEMNet), with over 140K image-music pairs. Second, we propose cross-modal deep continuous metric learning (CDCML) to learn a shared latent embedding space which preserves the cross-modal similarity relationship in the continuous matching space. Finally, we refine the embedding space by further preserving the single-modal emotion relationship in the VA spaces of both images and music. The metric learning in the embedding space and task regression in the label space are jointly optimized for both cross-modal matching and single-modal VA prediction. The extensive experiments conducted on IMEMNet demonstrate the superiority of CDCML for emotion-based image and music matching as compared to the state-of-the-art approaches.
ATSO: Asynchronous Teacher-Student Optimization for Semi-Supervised Medical Image Segmentation
Jul 16, 2020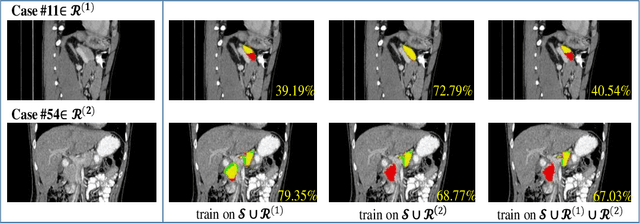
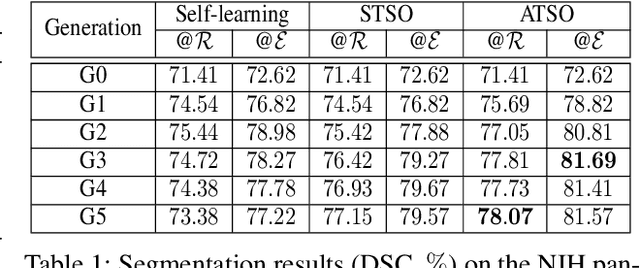
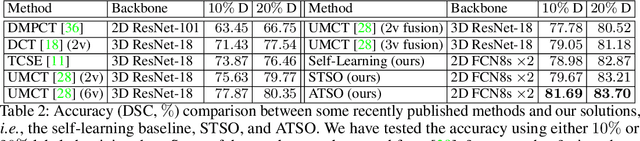
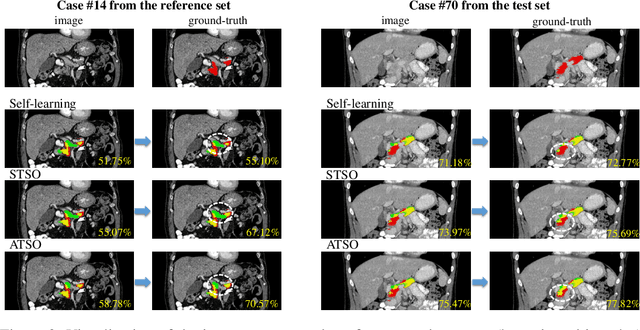
In medical image analysis, semi-supervised learning is an effective method to extract knowledge from a small amount of labeled data and a large amount of unlabeled data. This paper focuses on a popular pipeline known as self learning, and points out a weakness named lazy learning that refers to the difficulty for a model to learn from the pseudo labels generated by itself. To alleviate this issue, we propose ATSO, an asynchronous version of teacher-student optimization. ATSO partitions the unlabeled data into two subsets and alternately uses one subset to fine-tune the model and updates the label on the other subset. We evaluate ATSO on two popular medical image segmentation datasets and show its superior performance in various semi-supervised settings. With slight modification, ATSO transfers well to natural image segmentation for autonomous driving data.
Towards the Automation of Deep Image Prior
Nov 17, 2019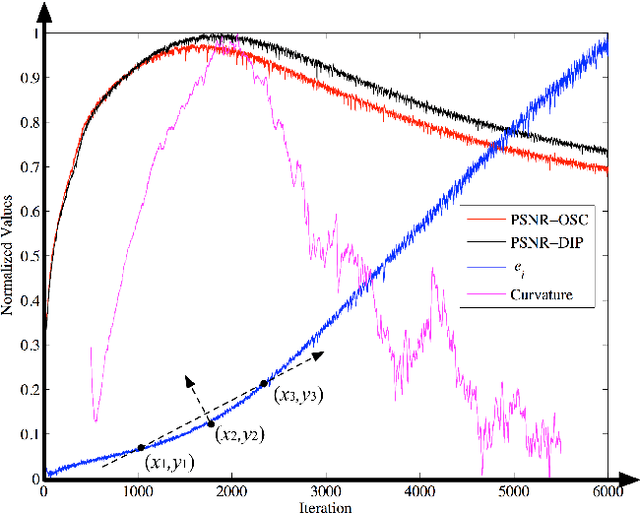
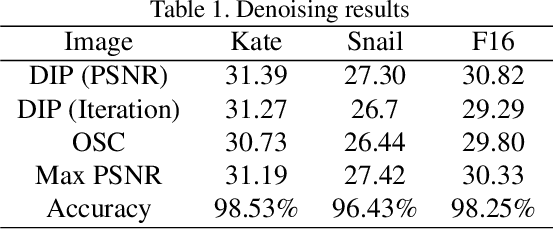
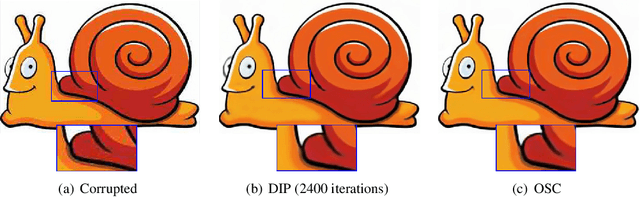

Single image inverse problem is a notoriously challenging ill-posed problem that aims to restore the original image from one of its corrupted versions. Recently, this field has been immensely influenced by the emergence of deep-learning techniques. Deep Image Prior (DIP) offers a new approach that forces the recovered image to be synthesized from a given deep architecture. While DIP is quite an effective unsupervised approach, it is deprecated in real-world applications because of the requirement of human assistance. In this work, we aim to find the best-recovered image without the assistance of humans by adding a stopping criterion, which will reach maximum when the iteration no longer improves the image quality. More specifically, we propose to add a pseudo noise to the corrupted image and measure the pseudo-noise component in the recovered image by the orthogonality between signal and noise. The accuracy of the orthogonal stopping criterion has been demonstrated for several tested problems such as denoising, super-resolution, and inpainting, in which 38 out of 40 experiments are higher than 95%.
Learning Indoor Inverse Rendering with 3D Spatially-Varying Lighting
Sep 13, 2021

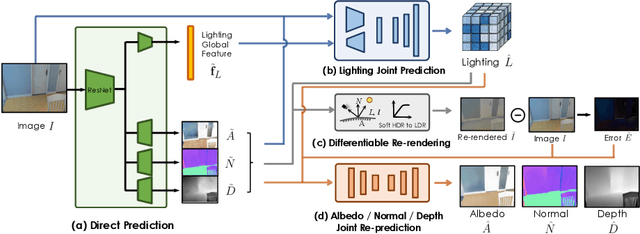
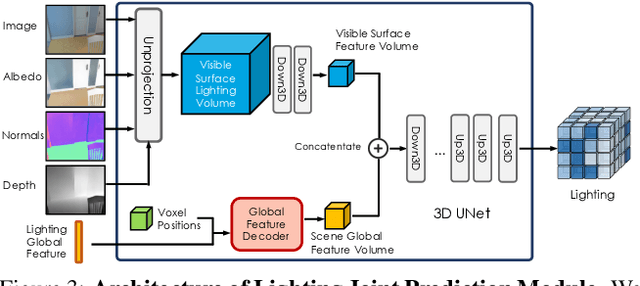
In this work, we address the problem of jointly estimating albedo, normals, depth and 3D spatially-varying lighting from a single image. Most existing methods formulate the task as image-to-image translation, ignoring the 3D properties of the scene. However, indoor scenes contain complex 3D light transport where a 2D representation is insufficient. In this paper, we propose a unified, learning-based inverse rendering framework that formulates 3D spatially-varying lighting. Inspired by classic volume rendering techniques, we propose a novel Volumetric Spherical Gaussian representation for lighting, which parameterizes the exitant radiance of the 3D scene surfaces on a voxel grid. We design a physics based differentiable renderer that utilizes our 3D lighting representation, and formulates the energy-conserving image formation process that enables joint training of all intrinsic properties with the re-rendering constraint. Our model ensures physically correct predictions and avoids the need for ground-truth HDR lighting which is not easily accessible. Experiments show that our method outperforms prior works both quantitatively and qualitatively, and is capable of producing photorealistic results for AR applications such as virtual object insertion even for highly specular objects.
Foreground-aware Semantic Representations for Image Harmonization
Jun 01, 2020

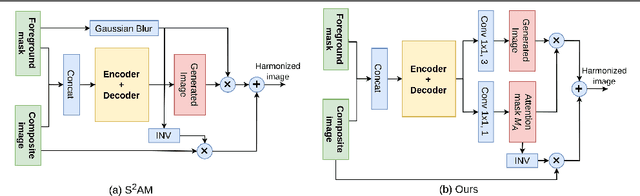
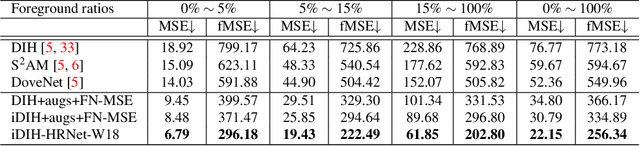
Image harmonization is an important step in photo editing to achieve visual consistency in composite images by adjusting the appearances of foreground to make it compatible with background. Previous approaches to harmonize composites are based on training of encoder-decoder networks from scratch, which makes it challenging for a neural network to learn a high-level representation of objects. We propose a novel architecture to utilize the space of high-level features learned by a pre-trained classification network. We create our models as a combination of existing encoder-decoder architectures and a pre-trained foreground-aware deep high-resolution network. We extensively evaluate the proposed method on existing image harmonization benchmark and set up a new state-of-the-art in terms of MSE and PSNR metrics. The code and trained models are available at \url{https://github.com/saic-vul/image_harmonization}.
HyperionSolarNet: Solar Panel Detection from Aerial Images
Jan 06, 2022

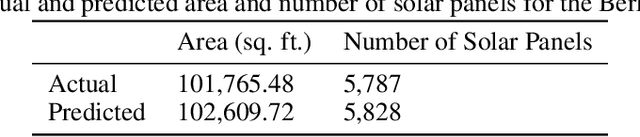
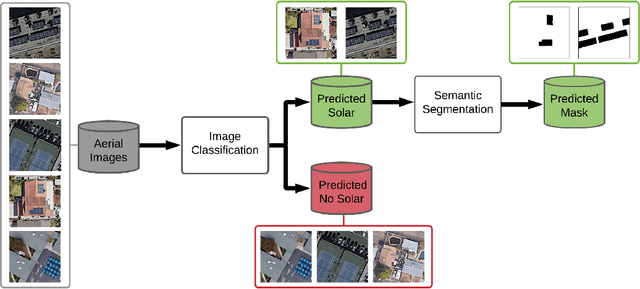
With the effects of global climate change impacting the world, collective efforts are needed to reduce greenhouse gas emissions. The energy sector is the single largest contributor to climate change and many efforts are focused on reducing dependence on carbon-emitting power plants and moving to renewable energy sources, such as solar power. A comprehensive database of the location of solar panels is important to assist analysts and policymakers in defining strategies for further expansion of solar energy. In this paper we focus on creating a world map of solar panels. We identify locations and total surface area of solar panels within a given geographic area. We use deep learning methods for automated detection of solar panel locations and their surface area using aerial imagery. The framework, which consists of a two-branch model using an image classifier in tandem with a semantic segmentation model, is trained on our created dataset of satellite images. Our work provides an efficient and scalable method for detecting solar panels, achieving an accuracy of 0.96 for classification and an IoU score of 0.82 for segmentation performance.
Learning Signal-Agnostic Manifolds of Neural Fields
Nov 11, 2021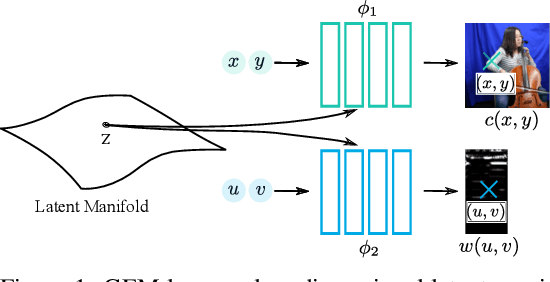

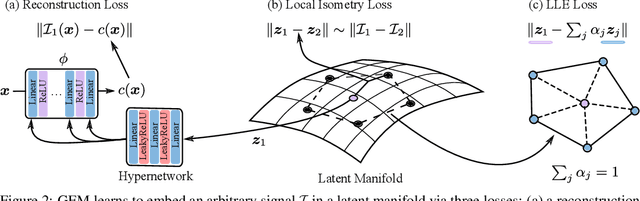

Deep neural networks have been used widely to learn the latent structure of datasets, across modalities such as images, shapes, and audio signals. However, existing models are generally modality-dependent, requiring custom architectures and objectives to process different classes of signals. We leverage neural fields to capture the underlying structure in image, shape, audio and cross-modal audiovisual domains in a modality-independent manner. We cast our task as one of learning a manifold, where we aim to infer a low-dimensional, locally linear subspace in which our data resides. By enforcing coverage of the manifold, local linearity, and local isometry, our model -- dubbed GEM -- learns to capture the underlying structure of datasets across modalities. We can then travel along linear regions of our manifold to obtain perceptually consistent interpolations between samples, and can further use GEM to recover points on our manifold and glean not only diverse completions of input images, but cross-modal hallucinations of audio or image signals. Finally, we show that by walking across the underlying manifold of GEM, we may generate new samples in our signal domains. Code and additional results are available at https://yilundu.github.io/gem/.
GloFlow: Global Image Alignment for Creation of Whole Slide Images for Pathology from Video
Nov 12, 2020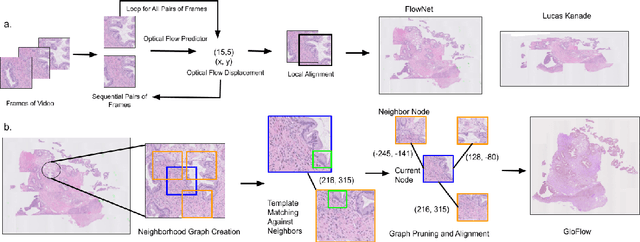
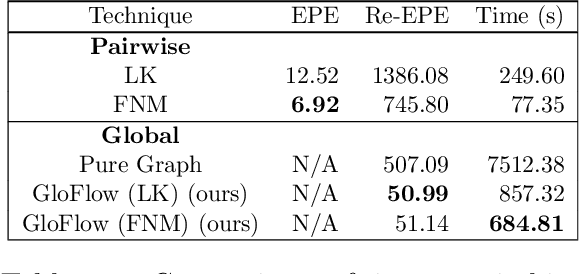
The application of deep learning to pathology assumes the existence of digital whole slide images of pathology slides. However, slide digitization is bottlenecked by the high cost of precise motor stages in slide scanners that are needed for position information used for slide stitching. We propose GloFlow, a two-stage method for creating a whole slide image using optical flow-based image registration with global alignment using a computationally tractable graph-pruning approach. In the first stage, we train an optical flow predictor to predict pairwise translations between successive video frames to approximate a stitch. In the second stage, this approximate stitch is used to create a neighborhood graph to produce a corrected stitch. On a simulated dataset of video scans of WSIs, we find that our method outperforms known approaches to slide-stitching, and stitches WSIs resembling those produced by slide scanners.
Fast and Light-Weight Network for Single Frame Structured Illumination Microscopy Super-Resolution
Nov 17, 2021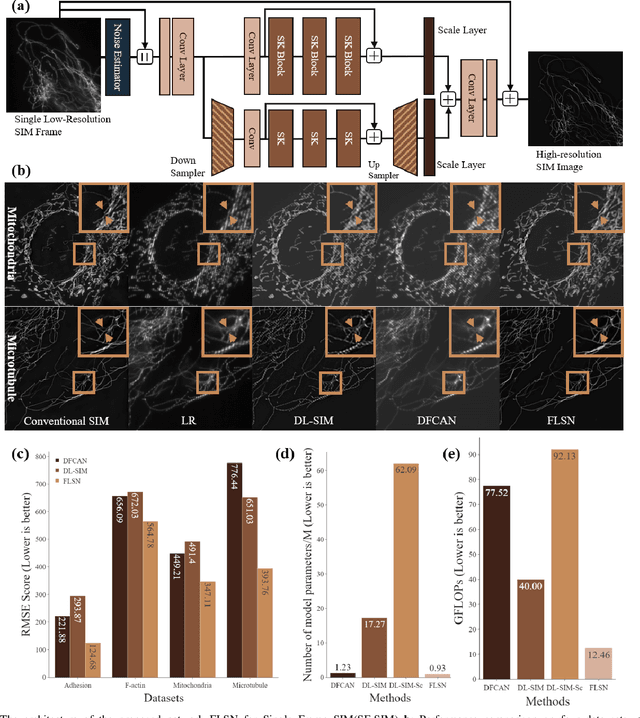
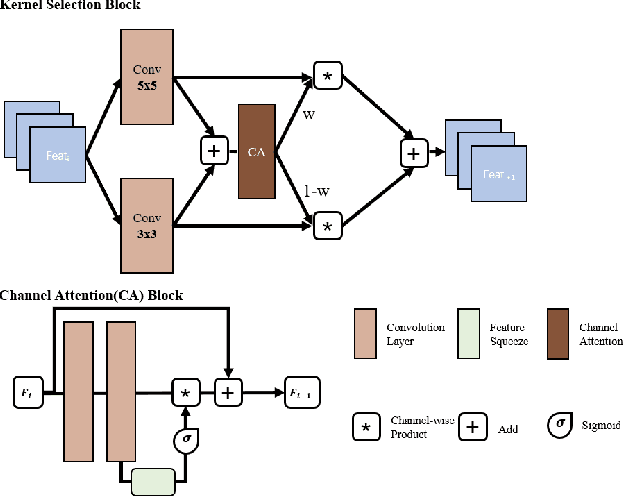
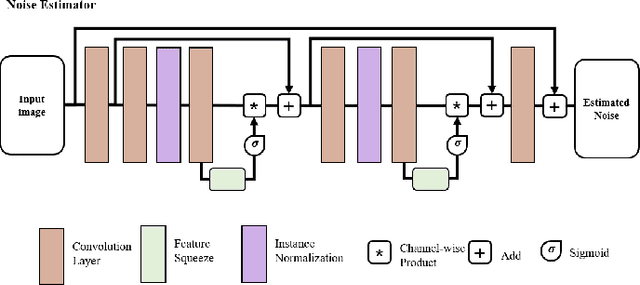
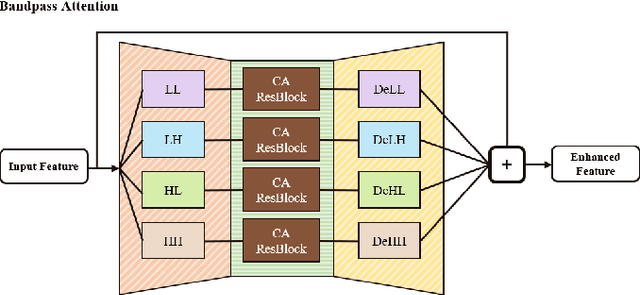
Structured illumination microscopy (SIM) is an important super-resolution based microscopy technique that breaks the diffraction limit and enhances optical microscopy systems. With the development of biology and medical engineering, there is a high demand for real-time and robust SIM imaging under extreme low light and short exposure environments. Existing SIM techniques typically require multiple structured illumination frames to produce a high-resolution image. In this paper, we propose a single-frame structured illumination microscopy (SF-SIM) based on deep learning. Our SF-SIM only needs one shot of a structured illumination frame and generates similar results compared with the traditional SIM systems that typically require 15 shots. In our SF-SIM, we propose a noise estimator which can effectively suppress the noise in the image and enable our method to work under the low light and short exposure environment, without the need for stacking multiple frames for non-local denoising. We also design a bandpass attention module that makes our deep network more sensitive to the change of frequency and enhances the imaging quality. Our proposed SF-SIM is almost 14 times faster than traditional SIM methods when achieving similar results. Therefore, our method is significantly valuable for the development of microbiology and medicine.
Optimal Estimation and Computational Limit of Low-rank Gaussian Mixtures
Jan 22, 2022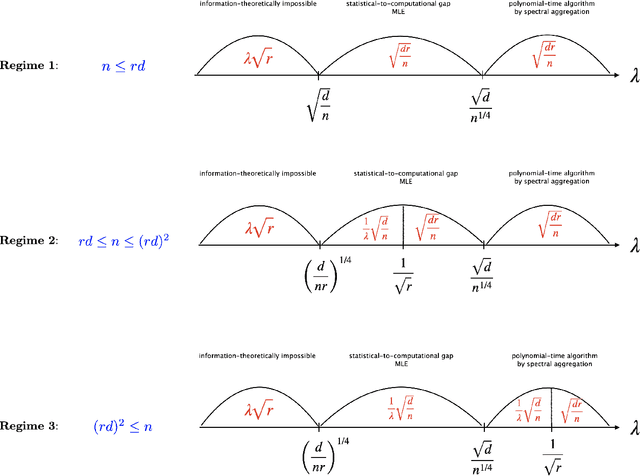
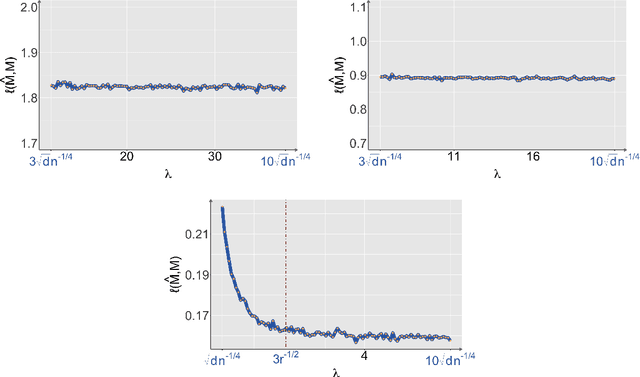
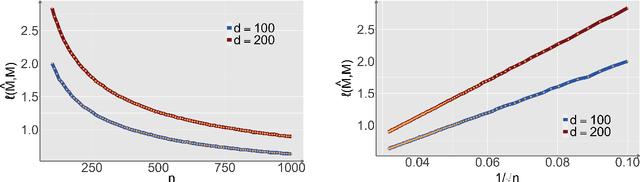
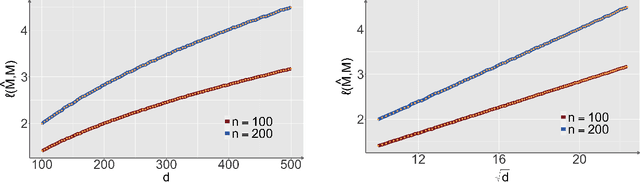
Structural matrix-variate observations routinely arise in diverse fields such as multi-layer network analysis and brain image clustering. While data of this type have been extensively investigated with fruitful outcomes being delivered, the fundamental questions like its statistical optimality and computational limit are largely under-explored. In this paper, we propose a low-rank Gaussian mixture model (LrMM) assuming each matrix-valued observation has a planted low-rank structure. Minimax lower bounds for estimating the underlying low-rank matrix are established allowing a whole range of sample sizes and signal strength. Under a minimal condition on signal strength, referred to as the information-theoretical limit or statistical limit, we prove the minimax optimality of a maximum likelihood estimator which, in general, is computationally infeasible. If the signal is stronger than a certain threshold, called the computational limit, we design a computationally fast estimator based on spectral aggregation and demonstrate its minimax optimality. Moreover, when the signal strength is smaller than the computational limit, we provide evidences based on the low-degree likelihood ratio framework to claim that no polynomial-time algorithm can consistently recover the underlying low-rank matrix. Our results reveal multiple phase transitions in the minimax error rates and the statistical-to-computational gap. Numerical experiments confirm our theoretical findings. We further showcase the merit of our spectral aggregation method on the worldwide food trading dataset.