 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Spectral Bias of the Deep Image Prior
Dec 18, 2019
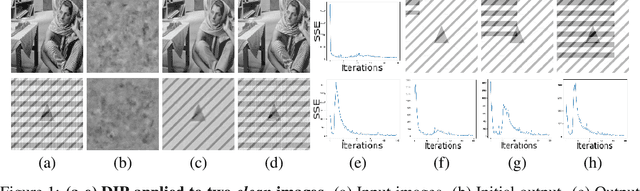

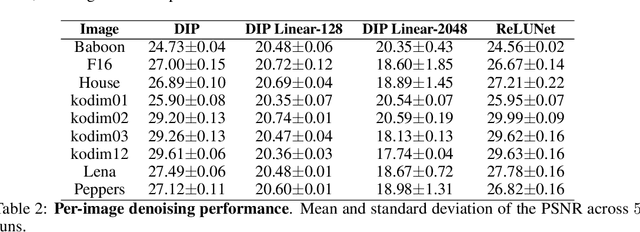
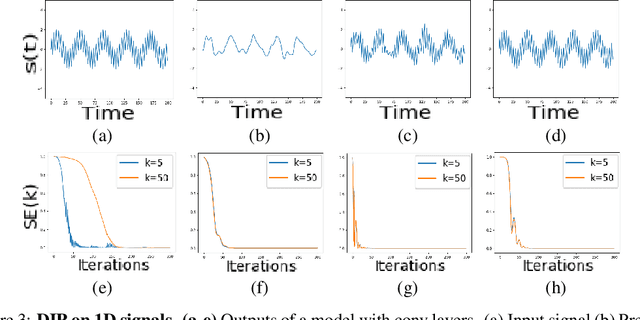
The "deep image prior" proposed by Ulyanov et al. is an intriguing property of neural nets: a convolutional encoder-decoder network can be used as a prior for natural images. The network architecture implicitly introduces a bias; If we train the model to map white noise to a corrupted image, this bias guides the model to fit the true image before fitting the corrupted regions. This paper explores why the deep image prior helps in denoising natural images. We present a novel method to analyze trajectories generated by the deep image prior optimization and demonstrate: (i) convolution layers of the an encoder-decoder decouple the frequency components of the image, learning each at different rates (ii) the model fits lower frequencies first, making early stopping behave as a low pass filter. The experiments study an extension of Cheng et al which showed that at initialization, the deep image prior is equivalent to a stationary Gaussian process.
SSCR: Iterative Language-Based Image Editing via Self-Supervised Counterfactual Reasoning
Sep 29, 2020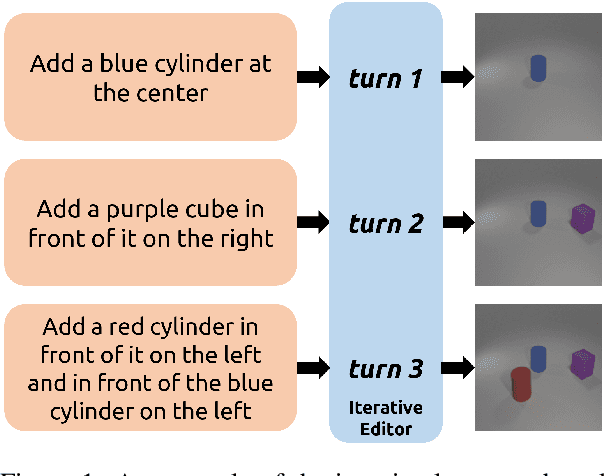

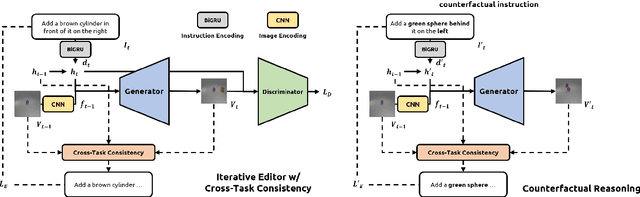
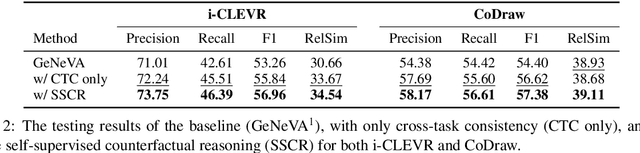
Iterative Language-Based Image Editing (IL-BIE) tasks follow iterative instructions to edit images step by step. Data scarcity is a significant issue for ILBIE as it is challenging to collect large-scale examples of images before and after instruction-based changes. However, humans still accomplish these editing tasks even when presented with an unfamiliar image-instruction pair. Such ability results from counterfactual thinking and the ability to think about alternatives to events that have happened already. In this paper, we introduce a Self-Supervised Counterfactual Reasoning (SSCR) framework that incorporates counterfactual thinking to overcome data scarcity. SSCR allows the model to consider out-of-distribution instructions paired with previous images. With the help of cross-task consistency (CTC), we train these counterfactual instructions in a self-supervised scenario. Extensive results show that SSCR improves the correctness of ILBIE in terms of both object identity and position, establishing a new state of the art (SOTA) on two IBLIE datasets (i-CLEVR and CoDraw). Even with only 50% of the training data, SSCR achieves a comparable result to using complete data.
Inducing Functions through Reinforcement Learning without Task Specification
Nov 23, 2021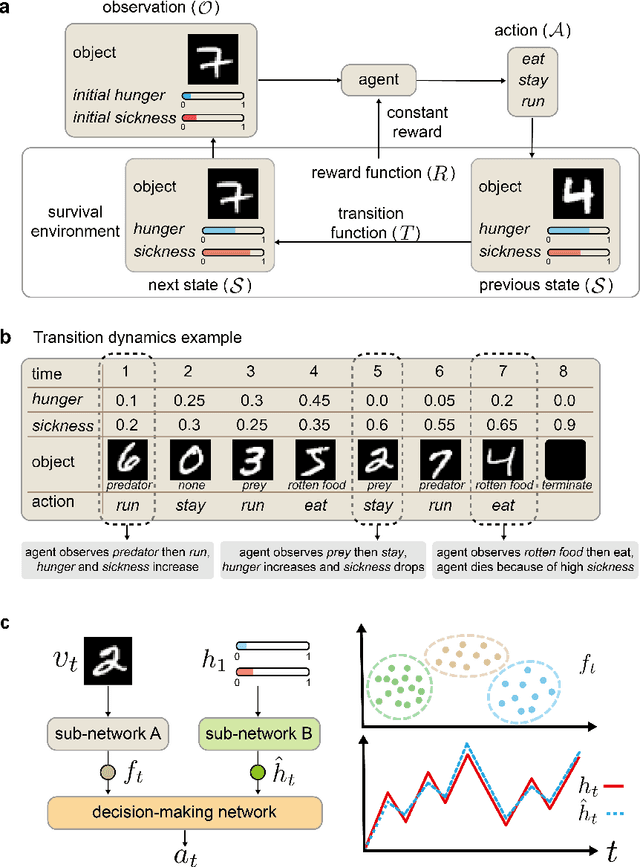
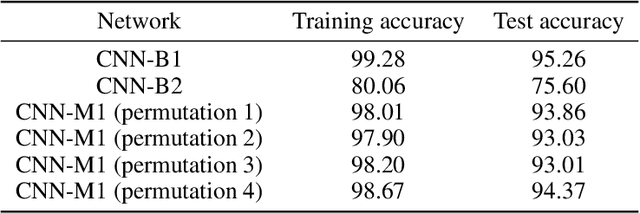
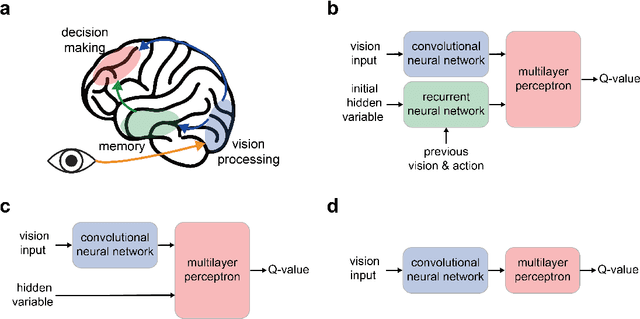
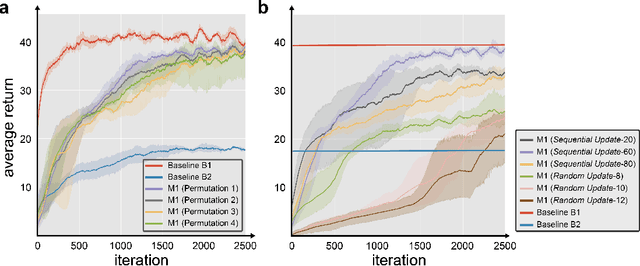
We report a bio-inspired framework for training a neural network through reinforcement learning to induce high level functions within the network. Based on the interpretation that animals have gained their cognitive functions such as object recognition - without ever being specifically trained for - as a result of maximizing their fitness to the environment, we place our agent in an environment where developing certain functions may facilitate decision making. The experimental results show that high level functions, such as image classification and hidden variable estimation, can be naturally and simultaneously induced without any pre-training or specifying them.
On Salience-Sensitive Sign Classification in Autonomous Vehicle Path Planning: Experimental Explorations with a Novel Dataset
Dec 02, 2021
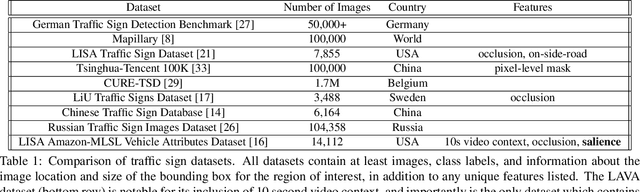

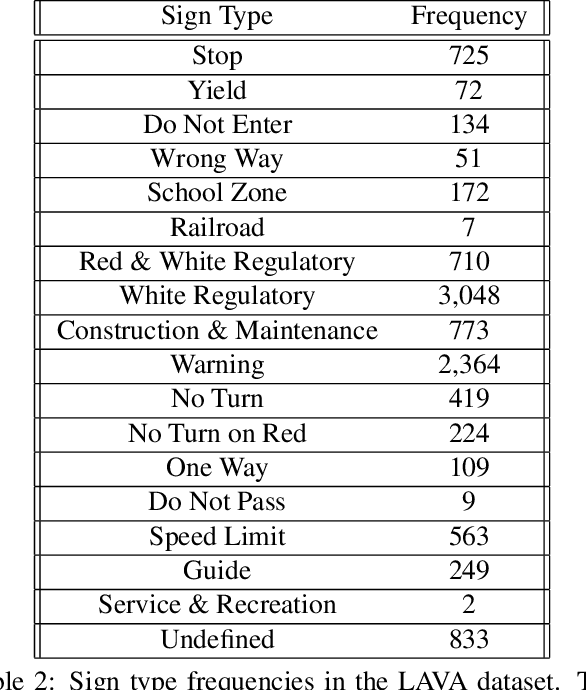
Safe path planning in autonomous driving is a complex task due to the interplay of static scene elements and uncertain surrounding agents. While all static scene elements are a source of information, there is asymmetric importance to the information available to the ego vehicle. We present a dataset with a novel feature, sign salience, defined to indicate whether a sign is distinctly informative to the goals of the ego vehicle with regards to traffic regulations. Using convolutional networks on cropped signs, in tandem with experimental augmentation by road type, image coordinates, and planned maneuver, we predict the sign salience property with 76% accuracy, finding the best improvement using information on vehicle maneuver with sign images.
Accurate and Lightweight Image Super-Resolution with Model-Guided Deep Unfolding Network
Sep 14, 2020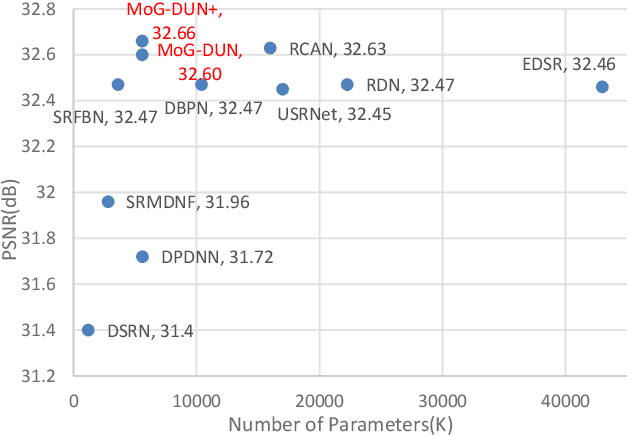



Deep neural networks (DNNs) based methods have achieved great success in single image super-resolution (SISR). However, existing state-of-the-art SISR techniques are designed like black boxes lacking transparency and interpretability. Moreover, the improvement in visual quality is often at the price of increased model complexity due to black-box design. In this paper, we present and advocate an explainable approach toward SISR named model-guided deep unfolding network (MoG-DUN). Targeting at breaking the coherence barrier, we opt to work with a well-established image prior named nonlocal auto-regressive model and use it to guide our DNN design. By integrating deep denoising and nonlocal regularization as trainable modules within a deep learning framework, we can unfold the iterative process of model-based SISR into a multi-stage concatenation of building blocks with three interconnected modules (denoising, nonlocal-AR, and reconstruction). The design of all three modules leverages the latest advances including dense/skip connections as well as fast nonlocal implementation. In addition to explainability, MoG-DUN is accurate (producing fewer aliasing artifacts), computationally efficient (with reduced model parameters), and versatile (capable of handling multiple degradations). The superiority of the proposed MoG-DUN method to existing state-of-the-art image SR methods including RCAN, SRMDNF, and SRFBN is substantiated by extensive experiments on several popular datasets and various degradation scenarios.
Are Large-scale Datasets Necessary for Self-Supervised Pre-training?
Dec 20, 2021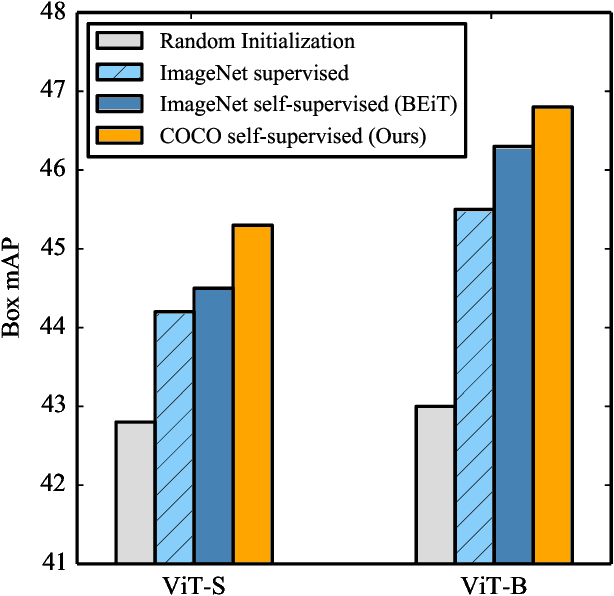
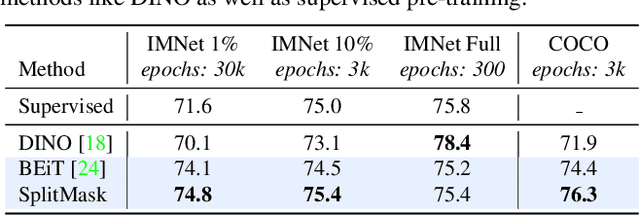
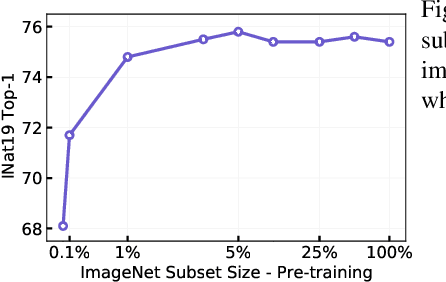

Pre-training models on large scale datasets, like ImageNet, is a standard practice in computer vision. This paradigm is especially effective for tasks with small training sets, for which high-capacity models tend to overfit. In this work, we consider a self-supervised pre-training scenario that only leverages the target task data. We consider datasets, like Stanford Cars, Sketch or COCO, which are order(s) of magnitude smaller than Imagenet. Our study shows that denoising autoencoders, such as BEiT or a variant that we introduce in this paper, are more robust to the type and size of the pre-training data than popular self-supervised methods trained by comparing image embeddings.We obtain competitive performance compared to ImageNet pre-training on a variety of classification datasets, from different domains. On COCO, when pre-training solely using COCO images, the detection and instance segmentation performance surpasses the supervised ImageNet pre-training in a comparable setting.
Self-Supervised 2D Image to 3D Shape Translation with Disentangled Representations
Mar 22, 2020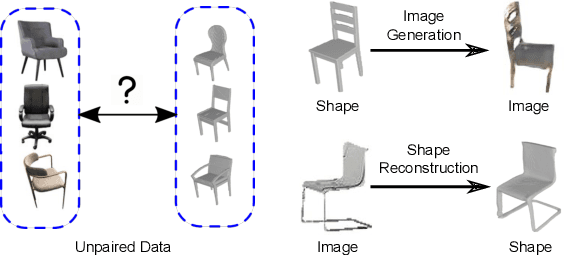
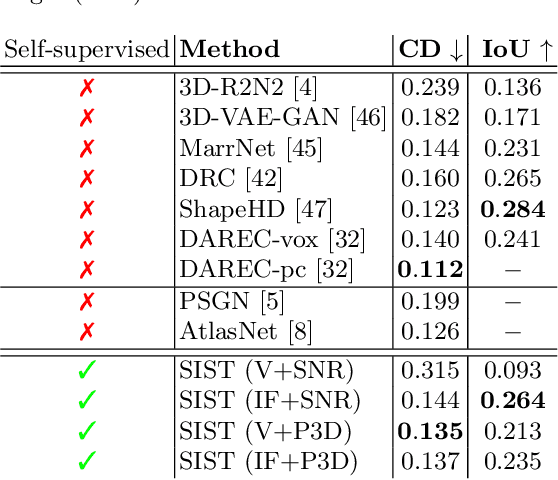

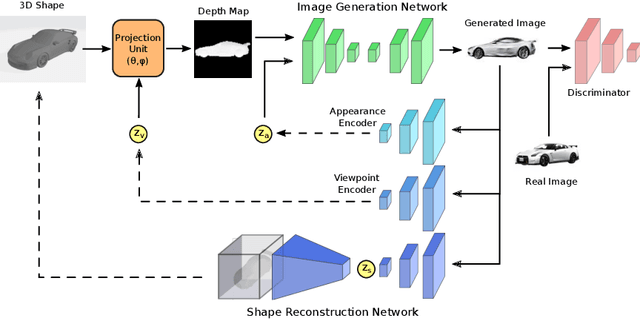
We present a framework to translate between 2D image views and 3D object shapes. Recent progress in deep learning enabled us to learn structure-aware representations from a scene. However, the existing literature assumes that pairs of images and 3D shapes are available for training in full supervision. In this paper, we propose SIST, a Self-supervised Image to Shape Translation framework that fulfills three tasks: (i) reconstructing the 3D shape from a single image; (ii) learning disentangled representations for shape, appearance and viewpoint; and (iii) generating a realistic RGB image from these independent factors. In contrast to the existing approaches, our method does not require image-shape pairs for training. Instead, it uses unpaired image and shape datasets from the same object class and jointly trains image generator and shape reconstruction networks. Our translation method achieves promising results, comparable in quantitative and qualitative terms to the state-of-the-art achieved by fully-supervised methods.
Learning Joint Embedding with Modality Alignments for Cross-Modal Retrieval of Recipes and Food Images
Aug 09, 2021

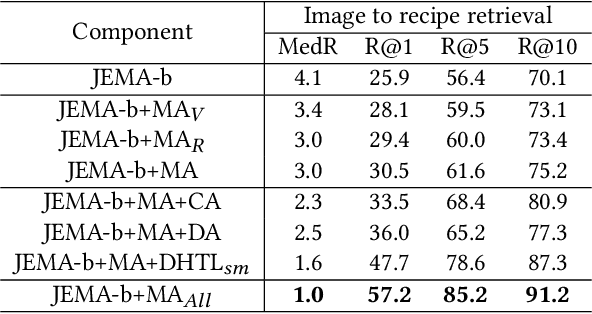

This paper presents a three-tier modality alignment approach to learning text-image joint embedding, coined as JEMA, for cross-modal retrieval of cooking recipes and food images. The first tier improves recipe text embedding by optimizing the LSTM networks with term extraction and ranking enhanced sequence patterns, and optimizes the image embedding by combining the ResNeXt-101 image encoder with the category embedding using wideResNet-50 with word2vec. The second tier modality alignment optimizes the textual-visual joint embedding loss function using a double batch-hard triplet loss with soft-margin optimization. The third modality alignment incorporates two types of cross-modality alignments as the auxiliary loss regularizations to further reduce the alignment errors in the joint learning of the two modality-specific embedding functions. The category-based cross-modal alignment aims to align the image category with the recipe category as a loss regularization to the joint embedding. The cross-modal discriminator-based alignment aims to add the visual-textual embedding distribution alignment to further regularize the joint embedding loss. Extensive experiments with the one-million recipes benchmark dataset Recipe1M demonstrate that the proposed JEMA approach outperforms the state-of-the-art cross-modal embedding methods for both image-to-recipe and recipe-to-image retrievals.
Detecting Patch Adversarial Attacks with Image Residuals
Mar 02, 2020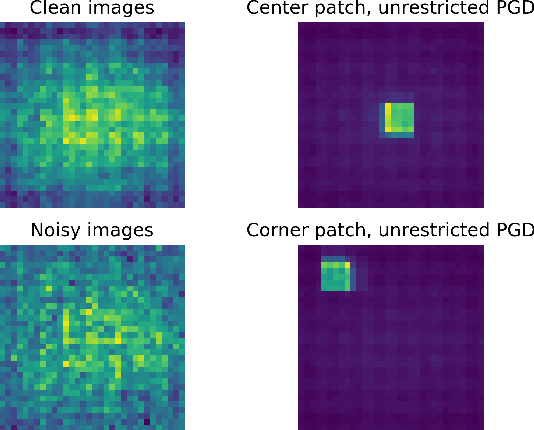
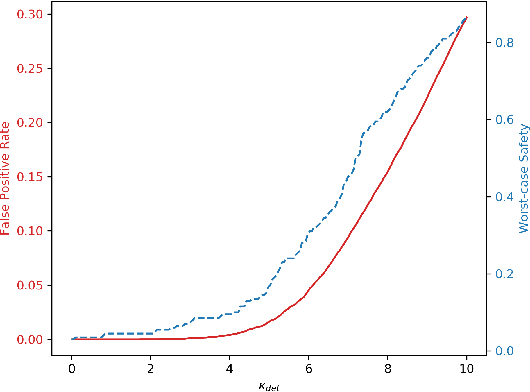


We introduce an adversarial sample detection algorithm based on image residuals, specifically designed to guard against patch-based attacks. The image residual is obtained as the difference between an input image and a denoised version of it, and a discriminator is trained to distinguish between clean and adversarial samples. More precisely, we use a wavelet domain algorithm for denoising images and demonstrate that the obtained residuals act as a digital fingerprint for adversarial attacks. To emulate the limitations of a physical adversary, we evaluate the performance of our approach against localized (patch-based) adversarial attacks, including in settings where the adversary has complete knowledge about the detection scheme. Our results show that the proposed detection method generalizes to previously unseen, stronger attacks and that it is able to reduce the success rate (conversely, increase the computational effort) of an adaptive attacker.
GloFlow: Global Image Alignment for Creation of Whole Slide Images for Pathology from Video
Oct 28, 2020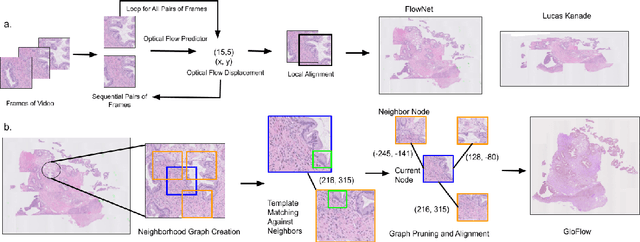
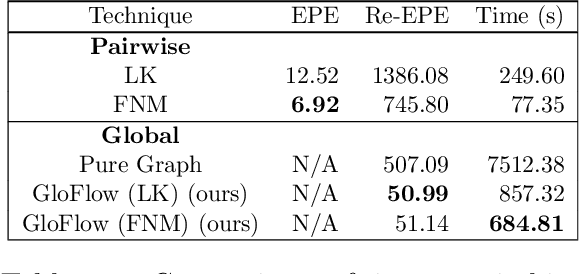
The application of deep learning to pathology assumes the existence of digital whole slide images of pathology slides. However, slide digitization is bottlenecked by the high cost of precise motor stages in slide scanners that are needed for position information used for slide stitching. We propose GloFlow, a two-stage method for creating a whole slide image using optical flow-based image registration with global alignment using a computationally tractable graph-pruning approach. In the first stage, we train an optical flow predictor to predict pairwise translations between successive video frames to approximate a stitch. In the second stage, this approximate stitch is used to create a neighborhood graph to produce a corrected stitch. On a simulated dataset of video scans of WSIs, we find that our method outperforms known approaches to slide-stitching, and stitches WSIs resembling those produced by slide scanners.