 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic fracture of a bicontinuously nanostructured copolymer: A deep learning analysis of big-data-generating experiment
Dec 03, 2021
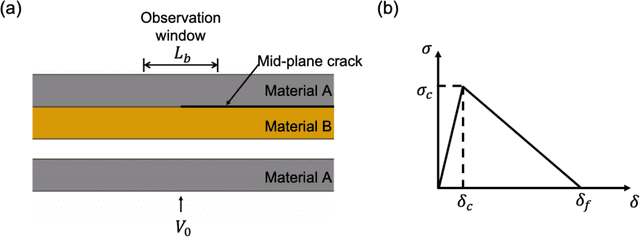

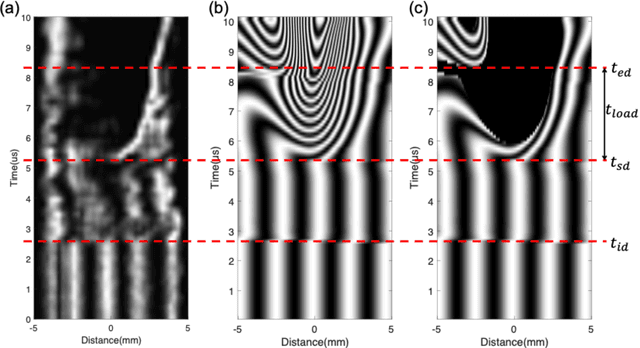
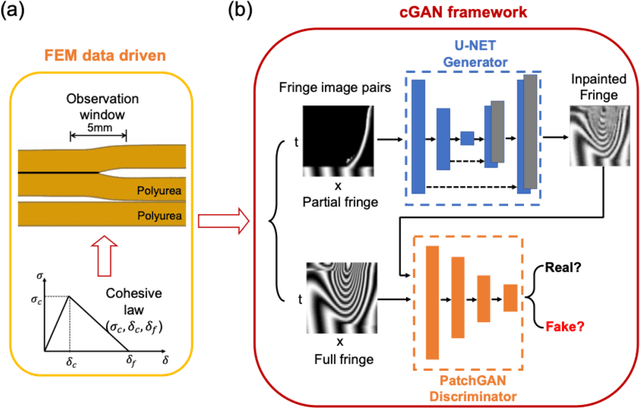
Here, we report the dynamic fracture toughness as well as the cohesive parameters of a bicontinuously nanostructured copolymer, polyurea, under an extremely high crack-tip loading rate, from a deep-learning analysis of a dynamic big-data-generating experiment. We first invented a novel Dynamic Line-Image Shearing Interferometer (DL-ISI), which can generate the displacement-gradient - time profiles along a line on a sample's back surface projectively covering the crack initiation and growth process in a single plate impact experiment. Then, we proposed a convolutional neural network (CNN) based deep-learning framework that can inversely determine the accurate cohesive parameters from DL-ISI fringe images. Plate-impact experiments on a polyurea sample with a mid-plane crack have been performed, and the generated DL-ISI fringe image has been inpainted by a Conditional Generative Adversarial Networks (cGAN). For the first time, the dynamic cohesive parameters of polyurea have been successfully obtained by the pre-trained CNN architecture with the computational dataset, which is consistent with the correlation method and the linear fracture mechanics estimation. Apparent dynamic toughening is found in polyurea, where the cohesive strength is found to be nearly three times higher than the spall strength under the symmetric impact with the same impact speed. These experimental results fill the gap in the current understanding of copolymer's cooperative-failure strength under extreme local loading conditions near the crack tip. This experiment also demonstrates the advantages of big-data-generating experiments, which combine innovative high-throughput experimental techniques with state-of-the-art machine learning algorithms.
Cardiac and respiratory motion extraction for MRI using Pilot Tone-a patient study
Jan 31, 2022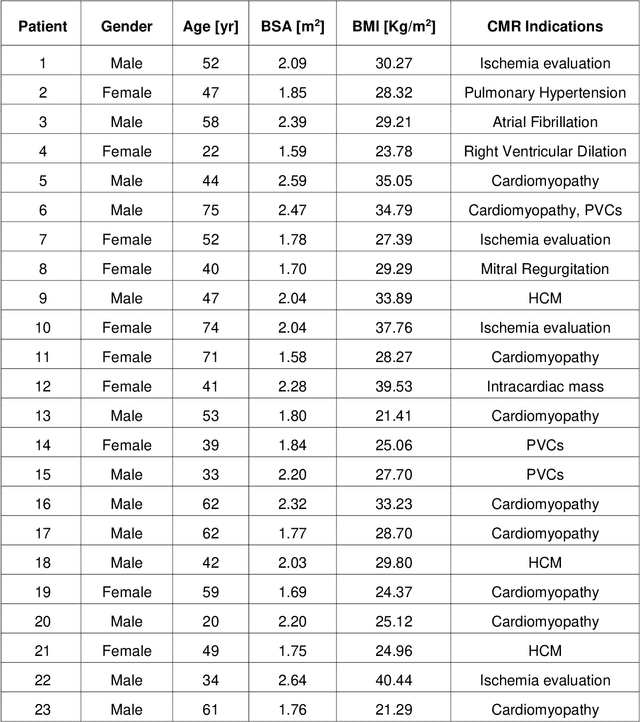
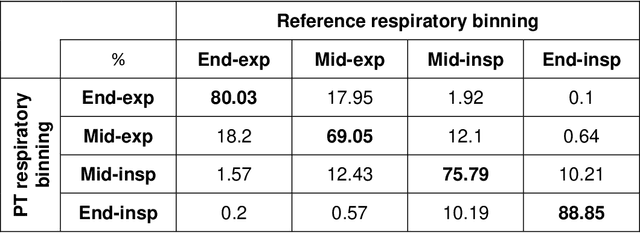
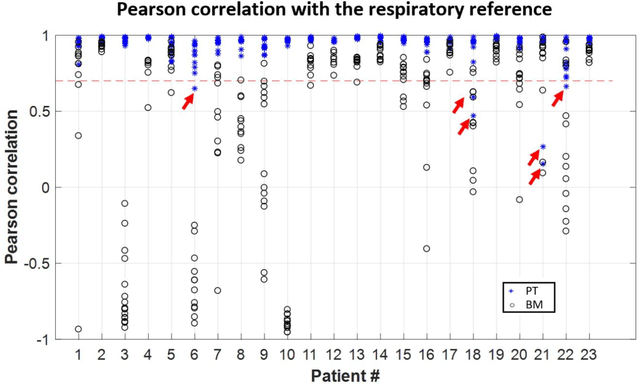
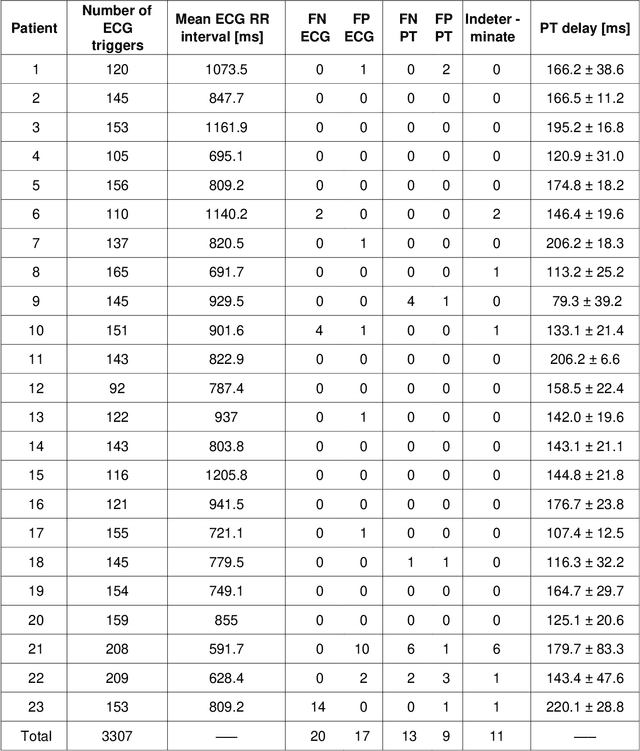
Background:The Pilot Tone (PT) technology allows contactless monitoring of physiological motion during the MRI scan. Several studies have shown that both respiratory and cardiac motion can be extracted from the PT signal successfully. However, most of these studies were performed in healthy volunteers. In this study, we seek to evaluate the accuracy and reliability of the cardiac and respiratory signals extracted from PT in patients clinically referred for cardiovascular MRI (CMR). Methods: Twenty-three patients were included in this study, each scanned under free-breathing conditions using a balanced steady-state free-precession real-time (RT) cine sequence on a 1.5T scanner. The PT signal was generated by a built-in PT transmitter integrated within the body array coil. For comparison, ECG and BioMatrix (BM) respiratory sensor signals were also synchronously recorded. To assess the performances of PT, ECG, and BM, cardiac and respiratory signals extracted from the RT cine images were used as the ground truth. Results: The respiratory motion extracted from PT correlated positively with the image-derived respiratory signal in all cases and showed a stronger correlation (absolute coefficient: 0.95-0.09) than BM (0.72-0.24). For the cardiac signal, the precision of PT-based triggers (standard deviation of PT trigger locations relative to ECG triggers) ranged from 6.6 to 81.2 ms (median 19.5 ms). Overall, the performance of PT-based trigger extraction was comparable to that of ECG. Conclusions: This study demonstrates the potential of PT to monitor both respiratory and cardiac motion in patients clinically referred for CMR.
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
Sep 22, 2021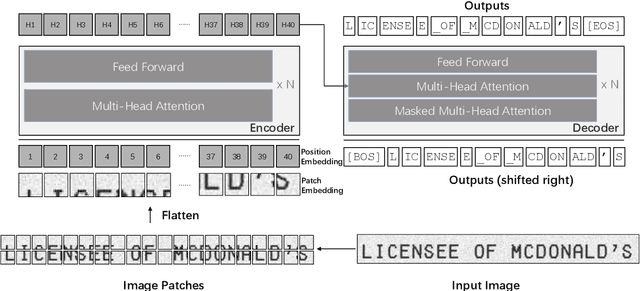

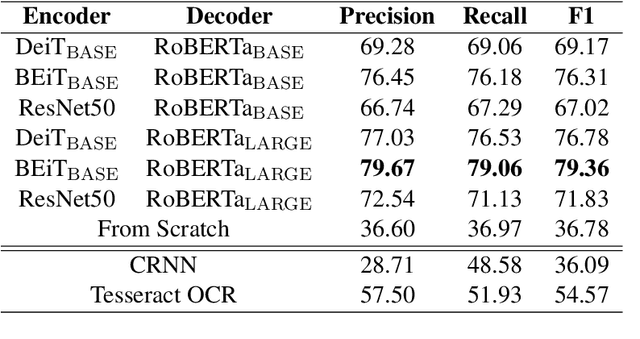
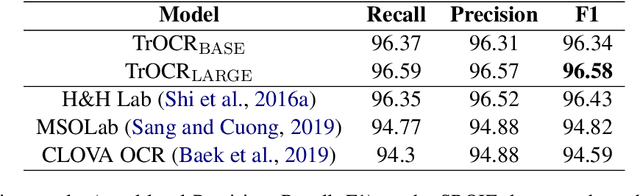
Text recognition is a long-standing research problem for document digitalization. Existing approaches for text recognition are usually built based on CNN for image understanding and RNN for char-level text generation. In addition, another language model is usually needed to improve the overall accuracy as a post-processing step. In this paper, we propose an end-to-end text recognition approach with pre-trained image Transformer and text Transformer models, namely TrOCR, which leverages the Transformer architecture for both image understanding and wordpiece-level text generation. The TrOCR model is simple but effective, and can be pre-trained with large-scale synthetic data and fine-tuned with human-labeled datasets. Experiments show that the TrOCR model outperforms the current state-of-the-art models on both printed and handwritten text recognition tasks. The code and models will be publicly available at https://aka.ms/TrOCR.
Dataset Bias in Few-shot Image Recognition
Sep 07, 2020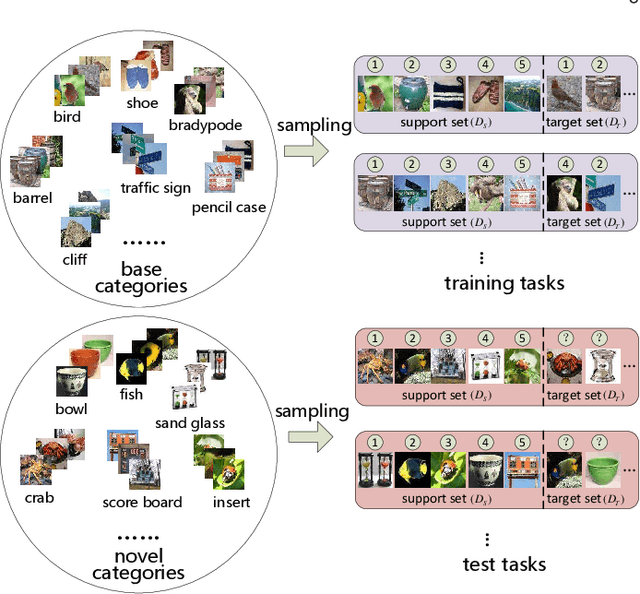
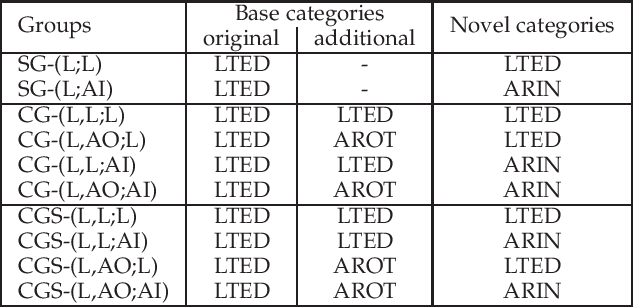
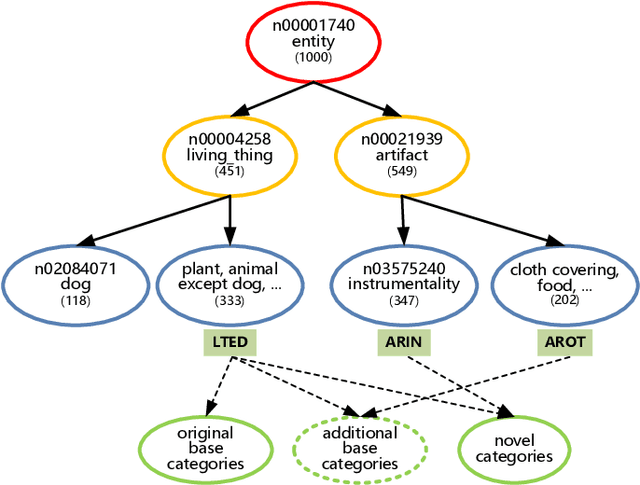
The goal of few-shot image recognition (FSIR) is to identify novel categories with a small number of annotated samples by exploiting transferable knowledge from training data (base categories). Most current studies assume that the transferable knowledge can be well used to identify novel categories. However, such transferable capability may be impacted by the dataset bias, and this problem has rarely been investigated before. Besides, most of few-shot learning methods are biased to different datasets, which is also an important issue that needs to be investigated deeply. In this paper, we first investigate the impact of transferable capabilities learned from base categories. Specifically, we use the relevance to measure relationships between base categories and novel categories. Distributions of base categories are depicted via the instance density and category diversity. The FSIR model learns better transferable knowledge from relevant training data. In the relevant data, dense instances or diverse categories can further enrich the learned knowledge. Experimental results on different sub-datasets of ImagNet demonstrate category relevance, instance density and category diversity can depict transferable bias from base categories. Second, we investigate performance differences on different datasets from dataset structures and different few-shot learning methods. Specifically, we introduce image complexity, intra-concept visual consistency, and inter-concept visual similarity to quantify characteristics of dataset structures. We use these quantitative characteristics and four few-shot learning methods to analyze performance differences on five different datasets. Based on the experimental analysis, some insightful observations are obtained from the perspective of both dataset structures and few-shot learning methods. We hope these observations are useful to guide future FSIR research.
Quantitative Analysis of Image Classification Techniques for Memory-Constrained Devices
May 11, 2020
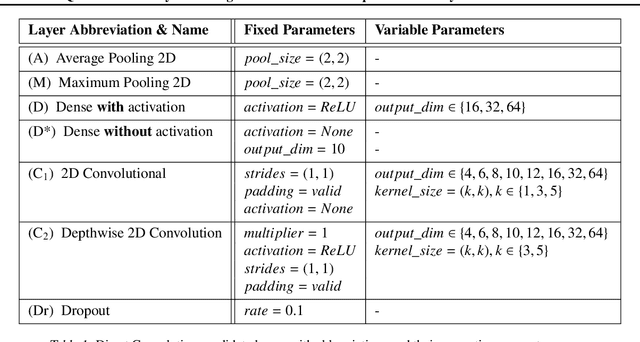
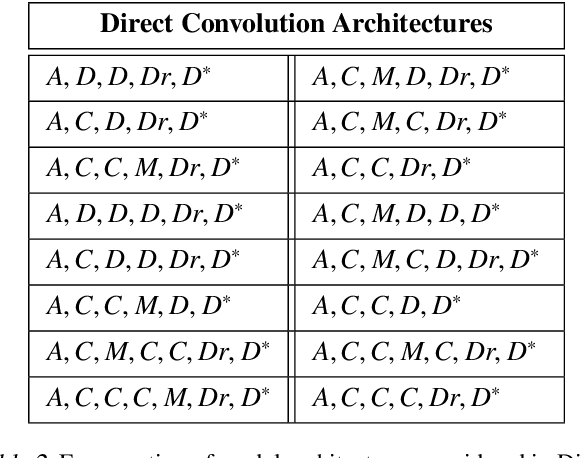
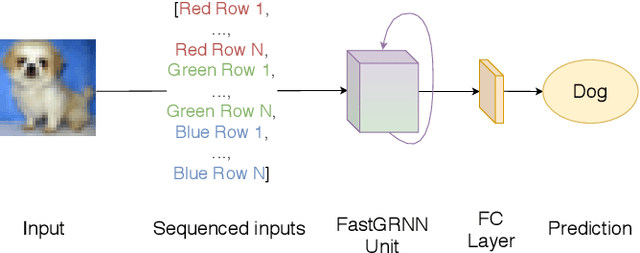
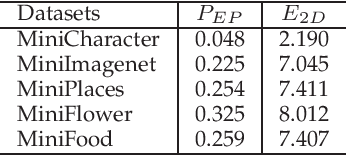
Convolutional Neural Networks, or CNNs, are undoubtedly the state of the art for image classification. However, they typically come with the cost of a large memory footprint. Recently, there has been significant progress in the field of image classification on memory-constrained devices, such as Arduino Unos, with novel contributions like the ProtoNN, Bonsai and FastGRNN models. These methods have been shown to perform excellently on tasks such as speech recognition or optical character recognition using MNIST, but their potential on more complex, multi-channel and multi-class image classification has yet to be determined. This paper presents a comprehensive analysis that shows that even in memory-constrained environments, CNNs implemented memory-optimally using Direct Convolutions outperform ProtoNN, Bonsai and FastGRNN models on 3-channel image classification using CIFAR-10. For our analysis, we propose new methods of adjusting the FastGRNN model to work with multi-channel images and then evaluate each algorithm with a memory size budget of 8KB, 16KB, 32KB, 64KB and 128KB to show quantitatively that CNNs are still state-of-the-art in image classification, even when memory size is constrained.
Intrinsic Image Popularity Assessment
Jul 03, 2019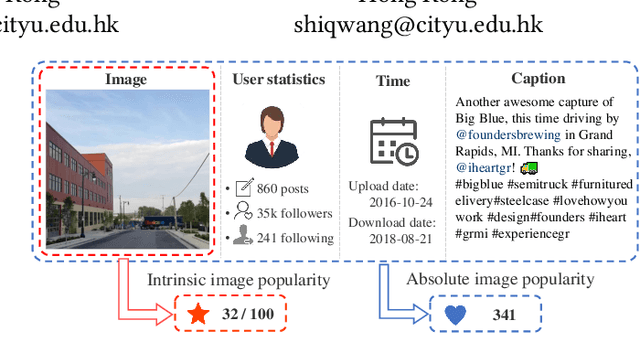
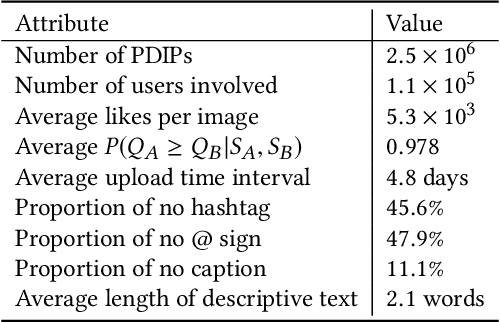


The goal of research in image popularity assessment (IPA) is to develop computational models that can automatically predict the potential of a social image being popular over the Internet. Here, we aim to single out the contribution of visual content to image popularity, i.e., intrinsic image popularity that is of great practical importance. Specifically, we first describe a probabilistic method to generate massive popularity-discriminable image pairs, based on which the first large-scale database for intrinsic IPA (I$^2$PA) is established. We then learn computational models for I$^2$PA by optimizing deep neural networks for ranking consistency with millions of popularity-discriminable image pairs. Experiments on Instagram and other social platforms demonstrate that the optimized model outperforms state-of-the-art methods and humans, and exhibits reasonable generalizability. Moreover, we conduct a psychophysical experiment to analyze various aspects of human behavior in I$^2$PA.
X-Linear Attention Networks for Image Captioning
Mar 31, 2020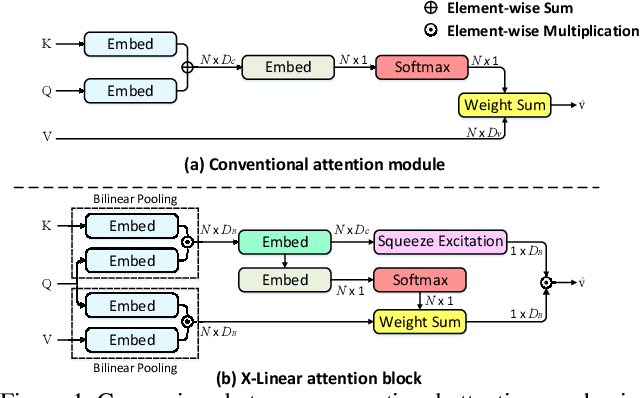
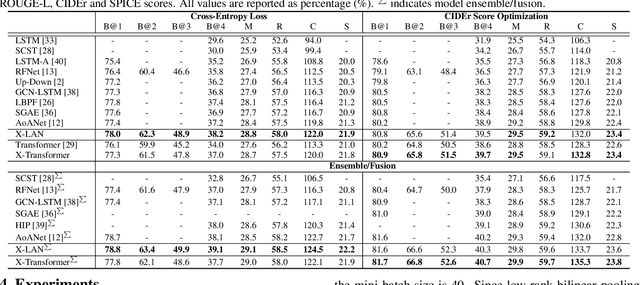
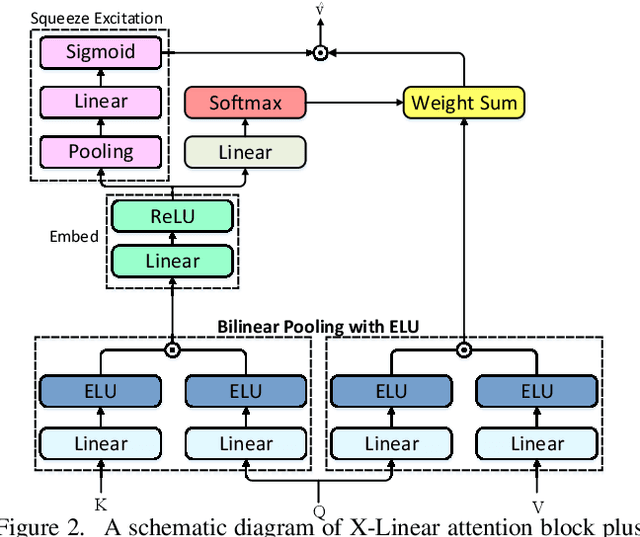
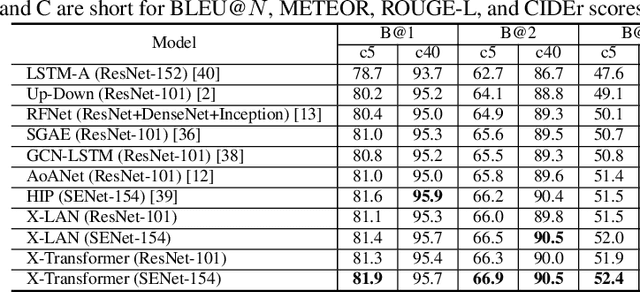
Recent progress on fine-grained visual recognition and visual question answering has featured Bilinear Pooling, which effectively models the 2$^{nd}$ order interactions across multi-modal inputs. Nevertheless, there has not been evidence in support of building such interactions concurrently with attention mechanism for image captioning. In this paper, we introduce a unified attention block -- X-Linear attention block, that fully employs bilinear pooling to selectively capitalize on visual information or perform multi-modal reasoning. Technically, X-Linear attention block simultaneously exploits both the spatial and channel-wise bilinear attention distributions to capture the 2$^{nd}$ order interactions between the input single-modal or multi-modal features. Higher and even infinity order feature interactions are readily modeled through stacking multiple X-Linear attention blocks and equipping the block with Exponential Linear Unit (ELU) in a parameter-free fashion, respectively. Furthermore, we present X-Linear Attention Networks (dubbed as X-LAN) that novelly integrates X-Linear attention block(s) into image encoder and sentence decoder of image captioning model to leverage higher order intra- and inter-modal interactions. The experiments on COCO benchmark demonstrate that our X-LAN obtains to-date the best published CIDEr performance of 132.0% on COCO Karpathy test split. When further endowing Transformer with X-Linear attention blocks, CIDEr is boosted up to 132.8%. Source code is available at \url{https://github.com/Panda-Peter/image-captioning}.
Image Processing Failure and Deep Learning Success in Lawn Measurement
Apr 22, 2020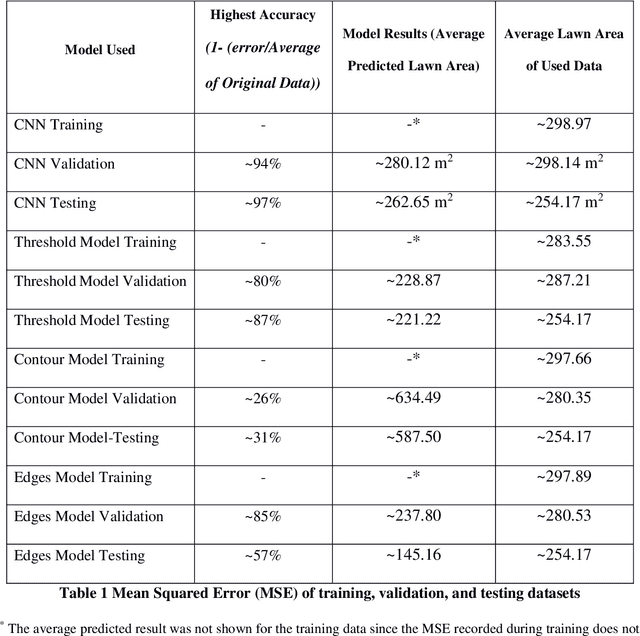
Lawn area measurement is an application of image processing and deep learning. Researchers have been used hierarchical networks, segmented images and many other methods to measure lawn area. Methods effectiveness and accuracy varies. In this project Image processing and deep learning methods has been compared to find the best way to measure the lawn area. Three Image processing methods using OpenCV has been compared to Convolutional Neural network which is one of the most famous and effective deep learning methods. We used Keras and TensorFlow to estimate the lawn area. Convolutional Neural Network or shortly CNN shows very high accuracy (94-97%) for this purpose. In image processing methods, Thresholding with 80-87% accuracy and Edge detection are effective methods to measure the lawn area but Contouring with 26-31% accuracy does not calculate the lawn area successfully. We may conclude that deep learning methods especially CNN could be the best detective method comparing to image processing and other deep learning techniques.
Automated Quality Control of Vacuum Insulated Glazing by Convolutional Neural Network Image Classification
Oct 15, 2021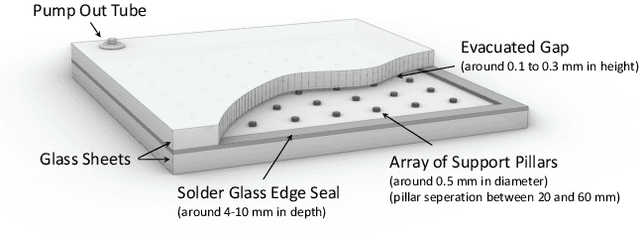


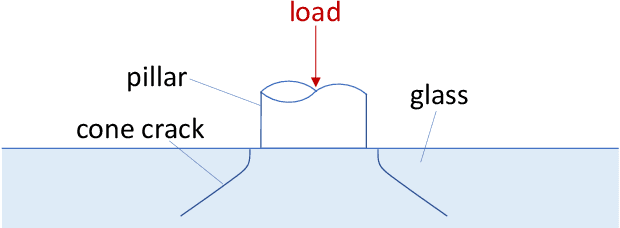
Vacuum Insulated Glazing (VIG) is a highly thermally insulating window technology, which boasts an extremely thin profile and lower weight as compared to gas-filled insulated glazing units of equivalent performance. The VIG is a double-pane configuration with a submillimeter vacuum gap between the panes and therefore under constant atmospheric pressure over their service life. Small pillars are positioned between the panes to maintain the gap, which can damage the glass reducing the lifetime of the VIG unit. To efficiently assess any surface damage on the glass, an automated damage detection system is highly desirable. For the purpose of classifying the damage, we have developed, trained, and tested a deep learning computer vision system using convolutional neural networks. The classification model flawlessly classified the test dataset with an area under the curve (AUC) for the receiver operating characteristic (ROC) of 100%. We have automatically cropped the images down to their relevant information by using Faster-RCNN to locate the position of the pillars. We employ the state-of-the-art methods Grad-CAM and Score-CAM of explainable Artificial Intelligence (XAI) to provide an understanding of the internal mechanisms and were able to show that our classifier outperforms ResNet50V2 for identification of crack locations and geometry. The proposed methods can therefore be used to detect systematic defects even without large amounts of training data. Further analyses of our model's predictive capabilities demonstrates its superiority over state-of-the-art models (ResNet50V2, ResNet101V2 and ResNet152V2) in terms of convergence speed, accuracy, precision at 100% recall and AUC for ROC.
Robust Segmentation of Cell Nuclei in 3-D Microscopy Images
Oct 07, 2021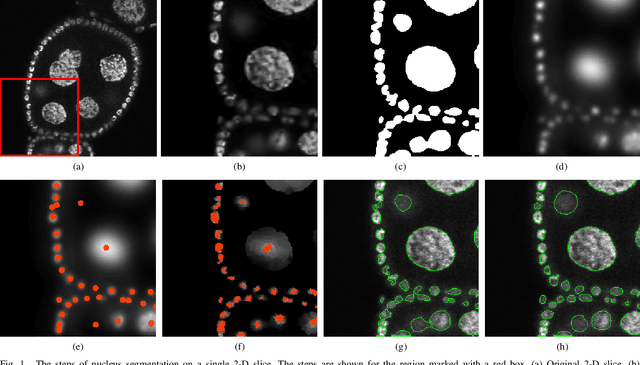
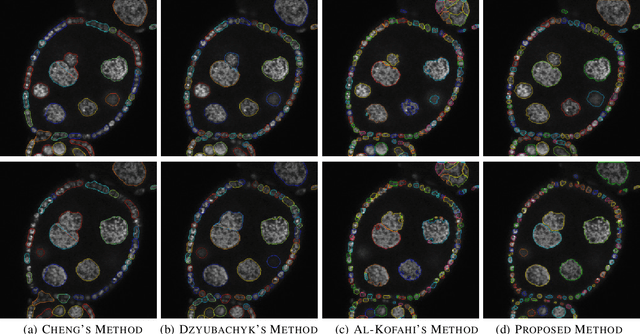
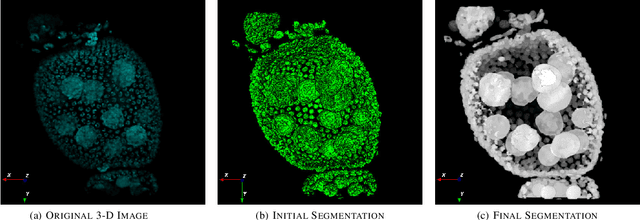
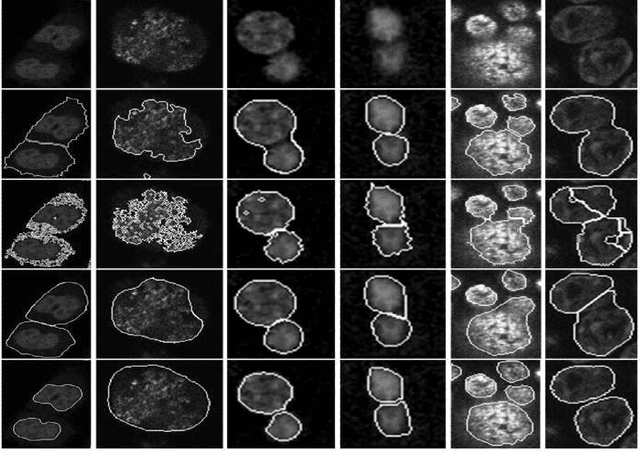
Accurate segmentation of 3-D cell nuclei in microscopy images is essential for the study of nuclear organization, gene expression, and cell morphodynamics. Current image segmentation methods are challenged by the complexity and variability of microscopy images and often over-segment or under-segment the cell nuclei. Thus, there is a need to improve segmentation accuracy and reliability, as well as the level of automation. In this paper, we propose a new automated algorithm for robust segmentation of 3-D cell nuclei using the concepts of random walk, graph theory, and mathematical morphology as the foundation. Like other segmentation algorithms, we first use a seed detection/marker extraction algorithm to find a seed voxel for each individual cell nucleus. Next, using the concept of random walk on a graph we find the probability of all the pixels in the 3-D image to reach the seed pixels of each nucleus identified by the seed detection algorithm. We then generate a 3-D response image by combining these probabilities for each voxel and use the marker controlled watershed transform on this response image to obtain an initial segmentation of the cell nuclei. Finally, we apply local region-based active contours to obtain final segmentation of the cell nuclei. The advantage of using such an approach is that it is capable of accurately segmenting highly textured cells having inhomogeneous intensities and varying shapes and sizes. The proposed algorithm was compared with three other automated nucleus segmentation algorithms for segmentation accuracy using overlap measure, Tanimoto index, Rand index, F-score, and Hausdorff distance measure. Quantitative and qualitative results show that our algorithm provides improved segmentation accuracy compared to existing algorithms.