 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Domain aware medical image classifier interpretation by counterfactual impact analysis
Jul 13, 2020
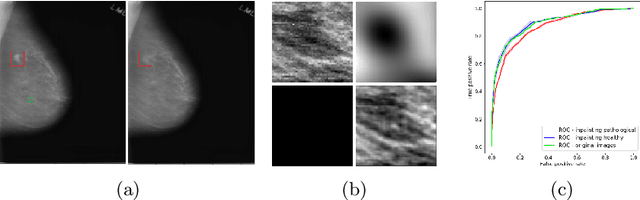

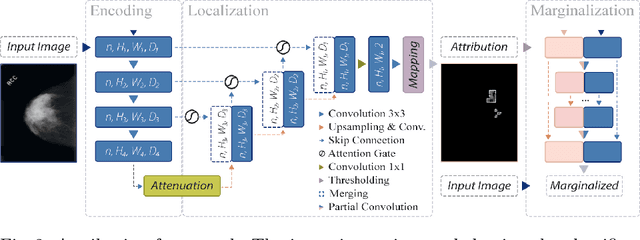
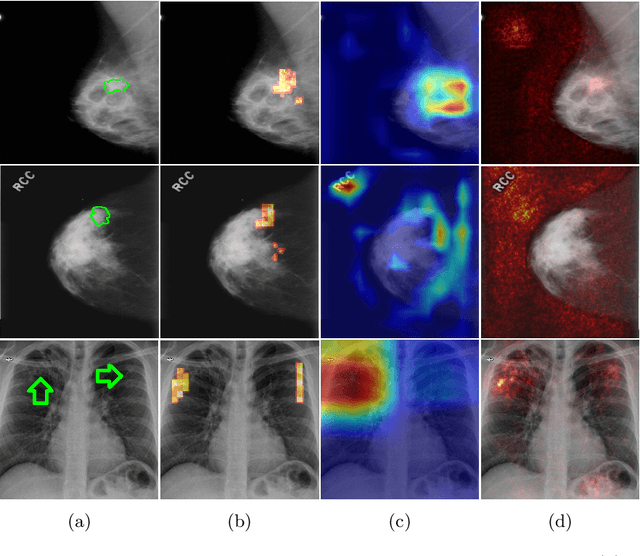
The success of machine learning methods for computer vision tasks has driven a surge in computer assisted prediction for medicine and biology. Based on a data-driven relationship between input image and pathological classification, these predictors deliver unprecedented accuracy. Yet, the numerous approaches trying to explain the causality of this learned relationship have fallen short: time constraints, coarse, diffuse and at times misleading results, caused by the employment of heuristic techniques like Gaussian noise and blurring, have hindered their clinical adoption. In this work, we discuss and overcome these obstacles by introducing a neural-network based attribution method, applicable to any trained predictor. Our solution identifies salient regions of an input image in a single forward-pass by measuring the effect of local image-perturbations on a predictor's score. We replace heuristic techniques with a strong neighborhood conditioned inpainting approach, avoiding anatomically implausible, hence adversarial artifacts. We evaluate on public mammography data and compare against existing state-of-the-art methods. Furthermore, we exemplify the approach's generalizability by demonstrating results on chest X-rays. Our solution shows, both quantitatively and qualitatively, a significant reduction of localization ambiguity and clearer conveying results, without sacrificing time efficiency.
A Full-Image Full-Resolution End-to-End-Trainable CNN Framework for Image Forgery Detection
Sep 15, 2019



Due to limited computational and memory resources, current deep learning models accept only rather small images in input, calling for preliminary image resizing. This is not a problem for high-level vision problems, where discriminative features are barely affected by resizing. On the contrary, in image forensics, resizing tends to destroy precious high-frequency details, impacting heavily on performance. One can avoid resizing by means of patch-wise processing, at the cost of renouncing whole-image analysis. In this work, we propose a CNN-based image forgery detection framework which makes decisions based on full-resolution information gathered from the whole image. Thanks to gradient checkpointing, the framework is trainable end-to-end with limited memory resources and weak (image-level) supervision, allowing for the joint optimization of all parameters. Experiments on widespread image forensics datasets prove the good performance of the proposed approach, which largely outperforms all baselines and all reference methods.
Cubical Ripser: Software for computing persistent homology of image and volume data
May 23, 2020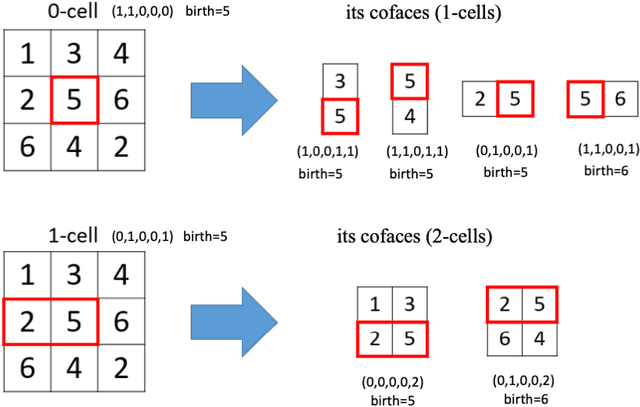



We introduce Cubical Ripser for computing persistent homology of image and volume data. To our best knowledge, Cubical Ripser is currently the fastest and the most memory-efficient program for computing persistent homology of image and volume data. We demonstrate our software with an example of image analysis in which persistent homology and convolutional neural networks are successfully combined. Our open-source implementation is available online.
Adversarial machine learning for protecting against online manipulation
Nov 23, 2021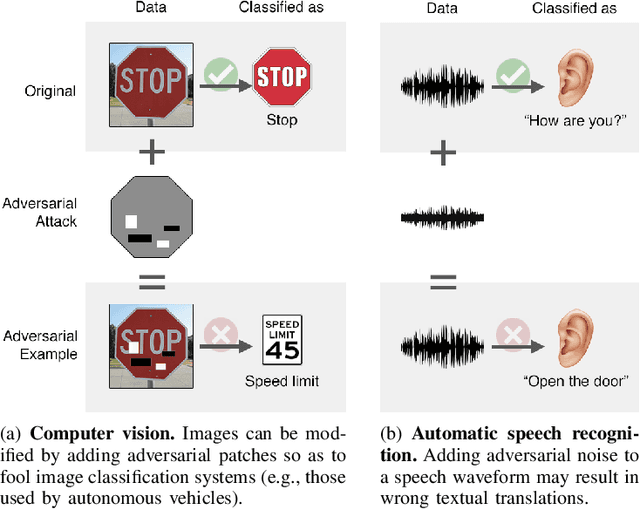
Adversarial examples are inputs to a machine learning system that result in an incorrect output from that system. Attacks launched through this type of input can cause severe consequences: for example, in the field of image recognition, a stop signal can be misclassified as a speed limit indication.However, adversarial examples also represent the fuel for a flurry of research directions in different domains and applications. Here, we give an overview of how they can be profitably exploited as powerful tools to build stronger learning models, capable of better-withstanding attacks, for two crucial tasks: fake news and social bot detection.
Riemannian Nearest-Regularized Subspace Classification for Polarimetric SAR images
Jan 02, 2022
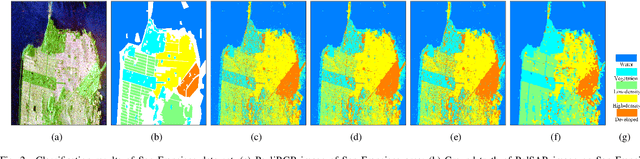
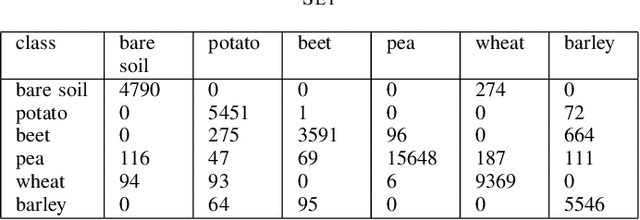
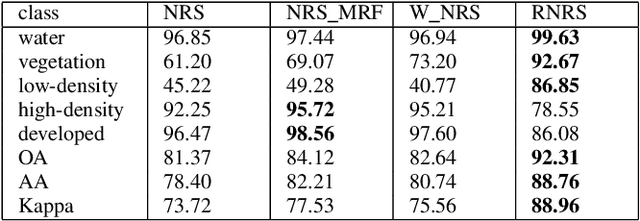
As a representation learning method, nearest regularized subspace(NRS) algorithm is an effective tool to obtain both accuracy and speed for PolSAR image classification. However, existing NRS methods use the polarimetric feature vector but the PolSAR original covariance matrix(known as Hermitian positive definite(HPD)matrix) as the input. Without considering the matrix structure, existing NRS-based methods cannot learn correlation among channels. How to utilize the original covariance matrix to NRS method is a key problem. To address this limit, a Riemannian NRS method is proposed, which consider the HPD matrices endow in the Riemannian space. Firstly, to utilize the PolSAR original data, a Riemannian NRS method(RNRS) is proposed by constructing HPD dictionary and HPD distance metric. Secondly, a new Tikhonov regularization term is designed to reduce the differences within the same class. Finally, the optimal method is developed and the first-order derivation is inferred. During the experimental test, only T matrix is used in the proposed method, while multiple of features are utilized for compared methods. Experimental results demonstrate the proposed method can outperform the state-of-art algorithms even using less features.
Deep Ultrasound Denoising Without Clean Data
Jan 07, 2022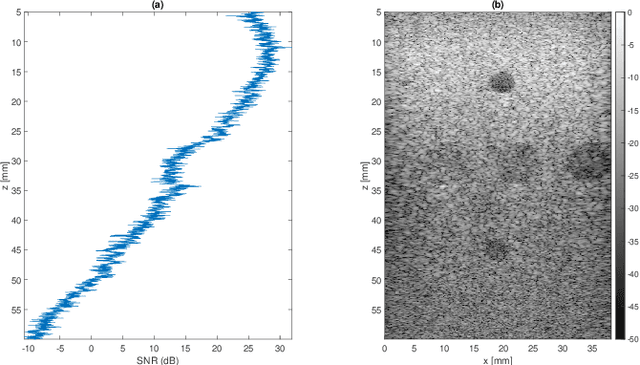
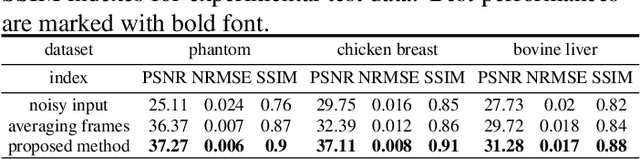

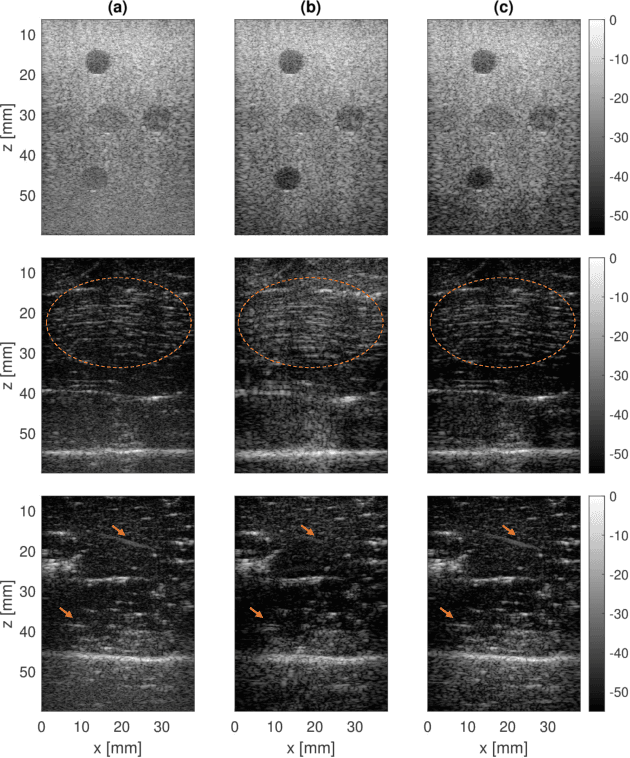
On one hand, the transmitted ultrasound beam gets attenuated as propagates through the tissue. On the other hand, the received Radio-Frequency (RF) data contains an additive Gaussian noise which is brought about by the acquisition card and the sensor noise. These two factors lead to a decreasing Signal to Noise Ratio (SNR) in the RF data with depth, effectively rendering deep regions of B-Mode images highly unreliable. There are three common approaches to mitigate this problem. First, increasing the power of transmitted beam which is limited by safety threshold. Averaging consecutive frames is the second option which not only reduces the framerate but also is not applicable for moving targets. And third, reducing the transmission frequency, which deteriorates spatial resolution. Many deep denoising techniques have been developed, but they often require clean data for training the model, which is usually only available in simulated images. Herein, a deep noise reduction approach is proposed which does not need clean training target. The model is constructed between noisy input-output pairs, and the training process interestingly converges to the clean image that is the average of noisy pairs. Experimental results on real phantom as well as ex vivo data confirm the efficacy of the proposed method for noise cancellation.
PERF: Performant, Explicit Radiance Fields
Dec 10, 2021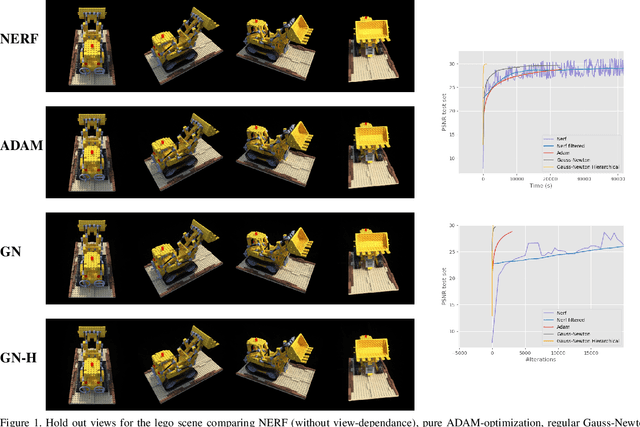

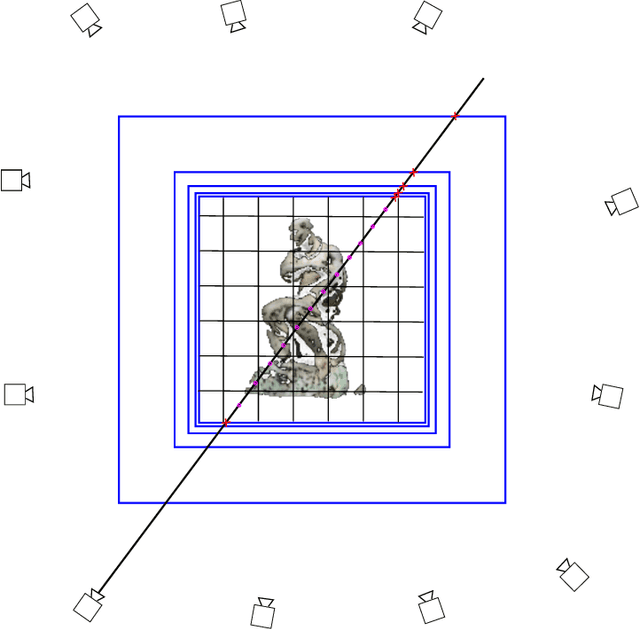

We present a novel way of approaching image-based 3D reconstruction based on radiance fields. The problem of volumetric reconstruction is formulated as a non-linear least-squares problem and solved explicitly without the use of neural networks. This enables the use of solvers with a higher rate of convergence than what is typically used for neural networks, and fewer iterations are required until convergence. The volume is represented using a grid of voxels, with the scene surrounded by a hierarchy of environment maps. This makes it possible to get clean reconstructions of 360{\deg} scenes where the foreground and background is separated. A number of synthetic and real scenes from well known benchmark-suites are successfully reconstructed with quality on par with state-of-the-art methods, but at significantly reduced reconstruction times.
Learning to Regress Bodies from Images using Differentiable Semantic Rendering
Oct 07, 2021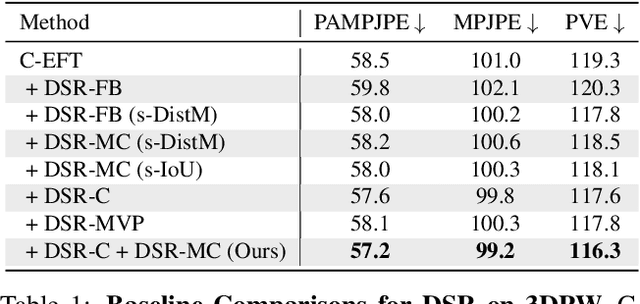
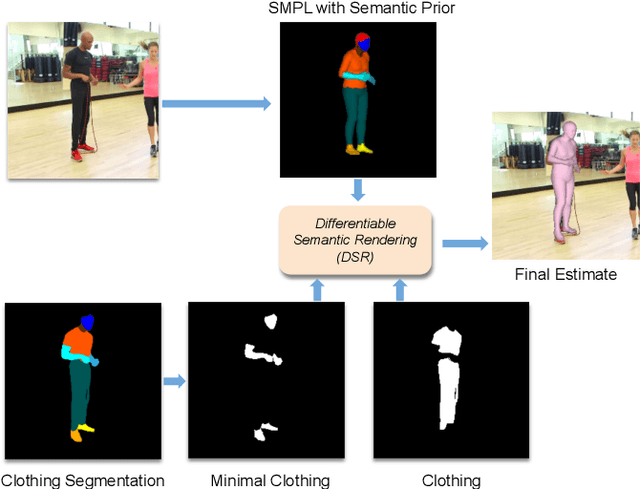
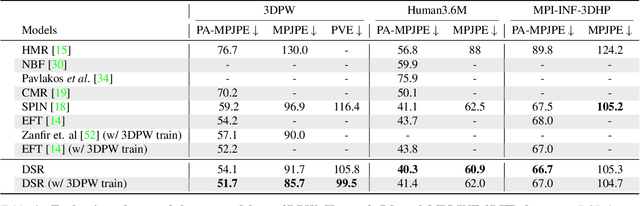
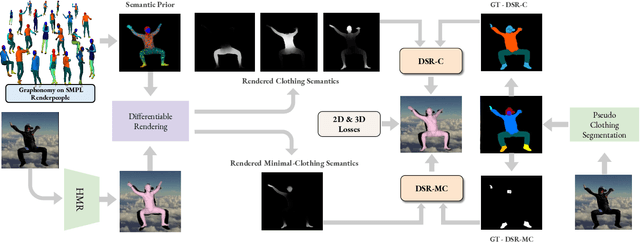
Learning to regress 3D human body shape and pose (e.g.~SMPL parameters) from monocular images typically exploits losses on 2D keypoints, silhouettes, and/or part-segmentation when 3D training data is not available. Such losses, however, are limited because 2D keypoints do not supervise body shape and segmentations of people in clothing do not match projected minimally-clothed SMPL shapes. To exploit richer image information about clothed people, we introduce higher-level semantic information about clothing to penalize clothed and non-clothed regions of the image differently. To do so, we train a body regressor using a novel Differentiable Semantic Rendering - DSR loss. For Minimally-Clothed regions, we define the DSR-MC loss, which encourages a tight match between a rendered SMPL body and the minimally-clothed regions of the image. For clothed regions, we define the DSR-C loss to encourage the rendered SMPL body to be inside the clothing mask. To ensure end-to-end differentiable training, we learn a semantic clothing prior for SMPL vertices from thousands of clothed human scans. We perform extensive qualitative and quantitative experiments to evaluate the role of clothing semantics on the accuracy of 3D human pose and shape estimation. We outperform all previous state-of-the-art methods on 3DPW and Human3.6M and obtain on par results on MPI-INF-3DHP. Code and trained models are available for research at https://dsr.is.tue.mpg.de/.
DistillPose: Lightweight Camera Localization Using Auxiliary Learning
Aug 09, 2021
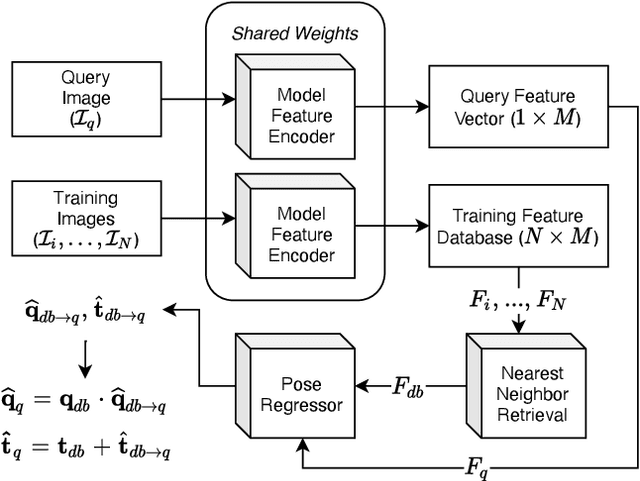
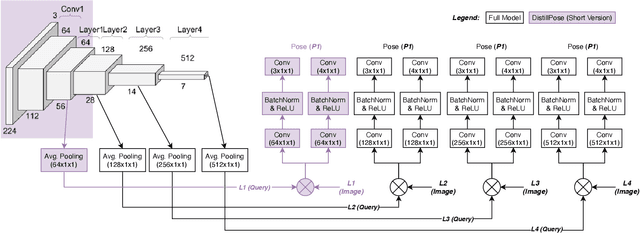
We propose a lightweight retrieval-based pipeline to predict 6DOF camera poses from RGB images. Our pipeline uses a convolutional neural network (CNN) to encode a query image as a feature vector. A nearest neighbor lookup finds the pose-wise nearest database image. A siamese convolutional neural network regresses the relative pose from the nearest neighboring database image to the query image. The relative pose is then applied to the nearest neighboring absolute pose to obtain the query image's final absolute pose prediction. Our model is a distilled version of NN-Net that reduces its parameters by 98.87%, information retrieval feature vector size by 87.5%, and inference time by 89.18% without a significant decrease in localization accuracy.
Simple and Robust Loss Design for Multi-Label Learning with Missing Labels
Dec 27, 2021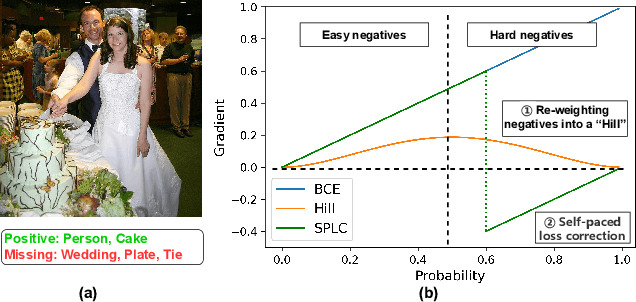
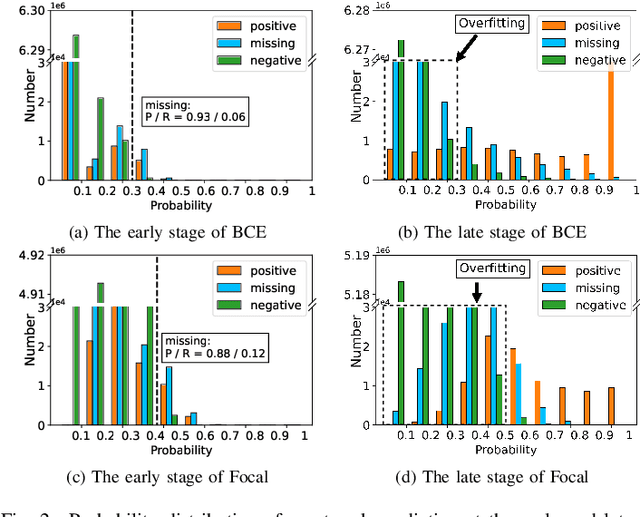
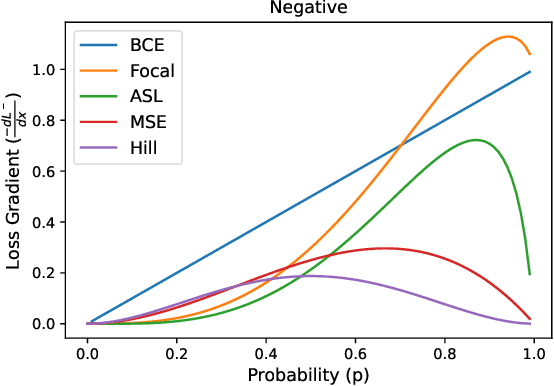
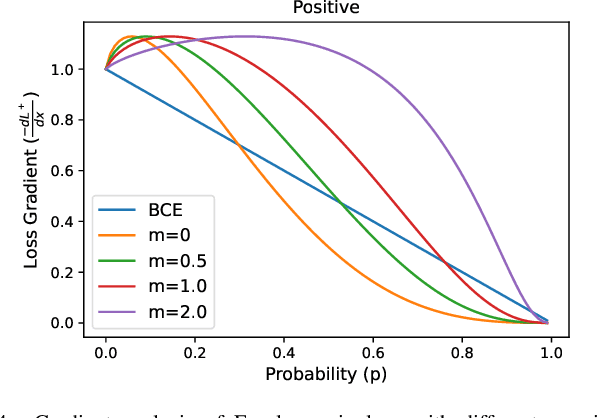
Multi-label learning in the presence of missing labels (MLML) is a challenging problem. Existing methods mainly focus on the design of network structures or training schemes, which increase the complexity of implementation. This work seeks to fulfill the potential of loss function in MLML without increasing the procedure and complexity. Toward this end, we propose two simple yet effective methods via robust loss design based on an observation that a model can identify missing labels during training with a high precision. The first is a novel robust loss for negatives, namely the Hill loss, which re-weights negatives in the shape of a hill to alleviate the effect of false negatives. The second is a self-paced loss correction (SPLC) method, which uses a loss derived from the maximum likelihood criterion under an approximate distribution of missing labels. Comprehensive experiments on a vast range of multi-label image classification datasets demonstrate that our methods can remarkably boost the performance of MLML and achieve new state-of-the-art loss functions in MLML.