 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EAGAN: Efficient Two-stage Evolutionary Architecture Search for GANs
Nov 30, 2021
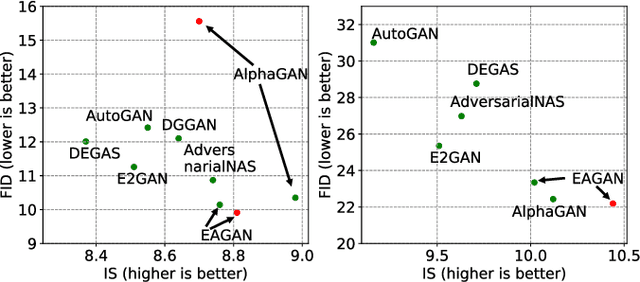
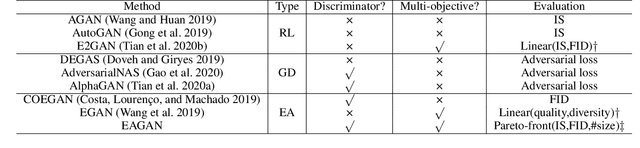
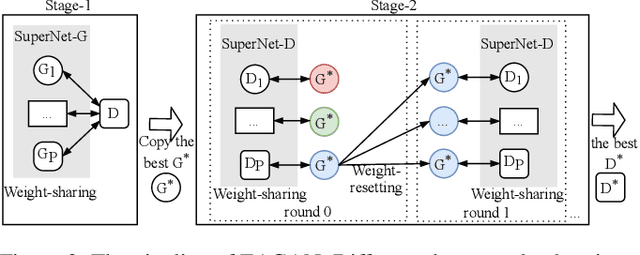
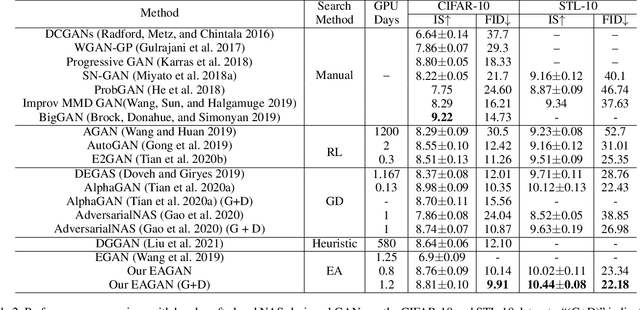
Generative Adversarial Networks (GANs) have been proven hugely successful in image generation tasks, but GAN training has the problem of instability. Many works have improved the stability of GAN training by manually modifying the GAN architecture, which requires human expertise and extensive trial-and-error. Thus, neural architecture search (NAS), which aims to automate the model design, has been applied to search GANs on the task of unconditional image generation. The early NAS-GAN works only search generators for reducing the difficulty. Some recent works have attempted to search both generator (G) and discriminator (D) to improve GAN performance, but they still suffer from the instability of GAN training during the search. To alleviate the instability issue, we propose an efficient two-stage evolutionary algorithm (EA) based NAS framework to discover GANs, dubbed \textbf{EAGAN}. Specifically, we decouple the search of G and D into two stages and propose the weight-resetting strategy to improve the stability of GAN training. Besides, we perform evolution operations to produce the Pareto-front architectures based on multiple objectives, resulting in a superior combination of G and D. By leveraging the weight-sharing strategy and low-fidelity evaluation, EAGAN can significantly shorten the search time. EAGAN achieves highly competitive results on the CIFAR-10 (IS=8.81$\pm$0.10, FID=9.91) and surpasses previous NAS-searched GANs on the STL-10 dataset (IS=10.44$\pm$0.087, FID=22.18).
Deep clustering with fusion autoencoder
Jan 14, 2022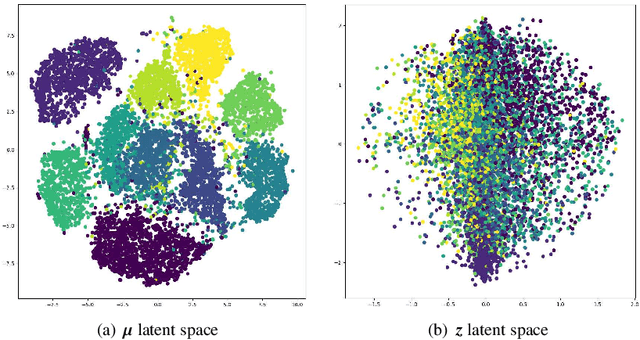
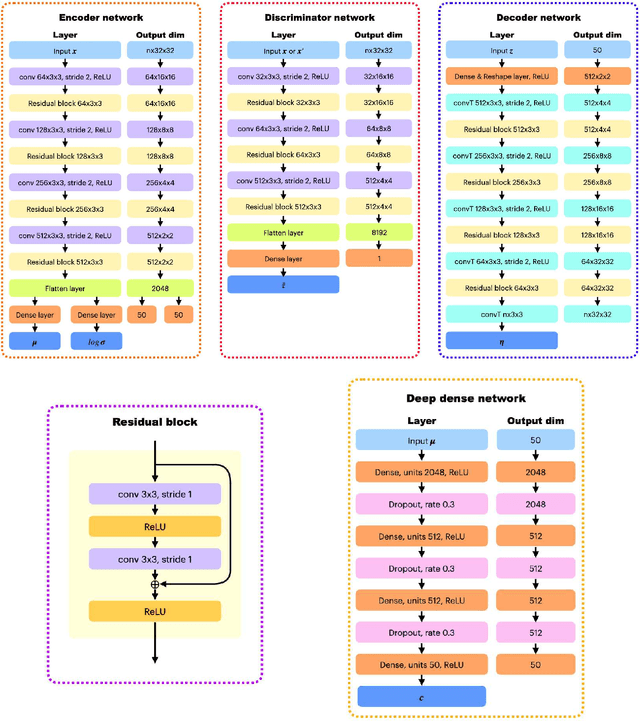
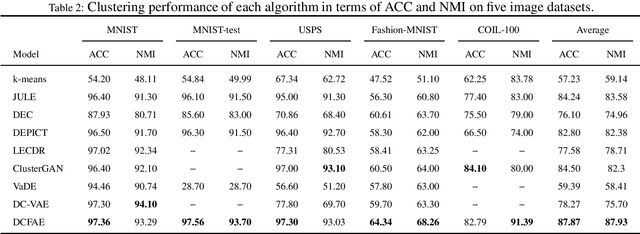
Embracing the deep learning techniques for representation learning in clustering research has attracted broad attention in recent years, yielding a newly developed clustering paradigm, viz. the deep clustering (DC). Typically, the DC models capitalize on autoencoders to learn the intrinsic features which facilitate the clustering process in consequence. Nowadays, a generative model named variational autoencoder (VAE) has got wide acceptance in DC studies. Nevertheless, the plain VAE is insufficient to perceive the comprehensive latent features, leading to the deteriorative clustering performance. In this paper, a novel DC method is proposed to address this issue. Specifically, the generative adversarial network and VAE are coalesced into a new autoencoder called fusion autoencoder (FAE) for discerning more discriminative representation that benefits the downstream clustering task. Besides, the FAE is implemented with the deep residual network architecture which further enhances the representation learning ability. Finally, the latent space of the FAE is transformed to an embedding space shaped by a deep dense neural network for pulling away different clusters from each other and collapsing data points within individual clusters. Experiment conducted on several image datasets demonstrate the effectiveness of the proposed DC model against the baseline methods.
Generating large labeled data sets for laparoscopic image processing tasks using unpaired image-to-image translation
Jul 05, 2019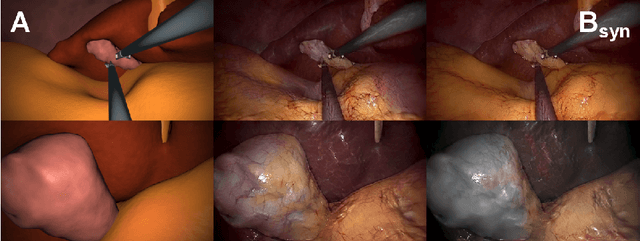
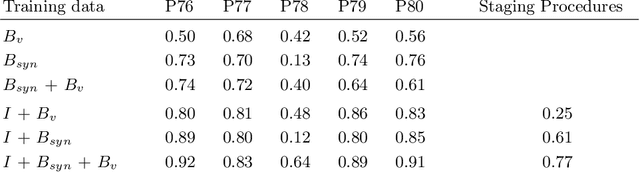
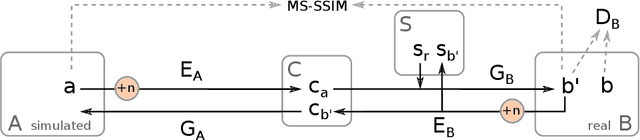
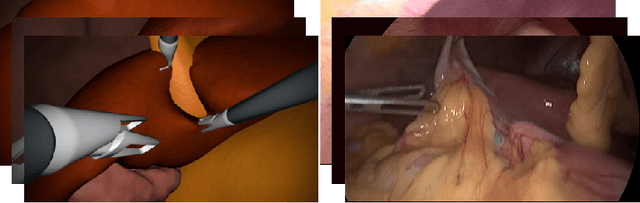
In the medical domain, the lack of large training data sets and benchmarks is often a limiting factor for training deep neural networks. In contrast to expensive manual labeling, computer simulations can generate large and fully labeled data sets with a minimum of manual effort. However, models that are trained on simulated data usually do not translate well to real scenarios. To bridge the domain gap between simulated and real laparoscopic images, we exploit recent advances in unpaired image-to-image translation. We extent an image-to-image translation method to generate a diverse multitude of realistically looking synthetic images based on images from a simple laparoscopy simulation. By incorporating means to ensure that the image content is preserved during the translation process, we ensure that the labels given for the simulated images remain valid for their realistically looking translations. This way, we are able to generate a large, fully labeled synthetic data set of laparoscopic images with realistic appearance. We show that this data set can be used to train models for the task of liver segmentation of laparoscopic images. We achieve average dice scores of up to 0.89 in some patients without manually labeling a single laparoscopic image and show that using our synthetic data to pre-train models can greatly improve their performance. The synthetic data set will be made publicly available, fully labeled with segmentation maps, depth maps, normal maps, and positions of tools and camera (http://opencas.dkfz.de/image2image).
Contextual Residual Aggregation for Ultra High-Resolution Image Inpainting
May 19, 2020
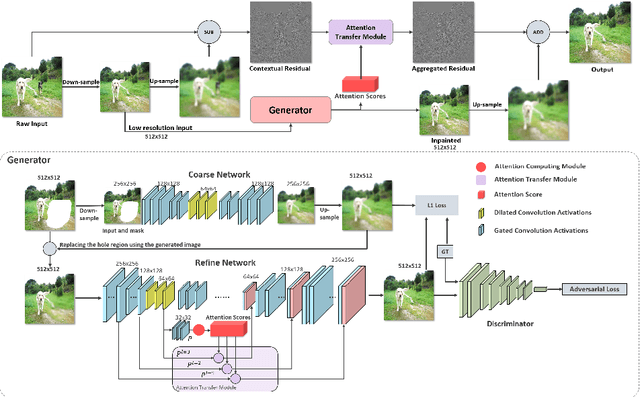


Recently data-driven image inpainting methods have made inspiring progress, impacting fundamental image editing tasks such as object removal and damaged image repairing. These methods are more effective than classic approaches, however, due to memory limitations they can only handle low-resolution inputs, typically smaller than 1K. Meanwhile, the resolution of photos captured with mobile devices increases up to 8K. Naive up-sampling of the low-resolution inpainted result can merely yield a large yet blurry result. Whereas, adding a high-frequency residual image onto the large blurry image can generate a sharp result, rich in details and textures. Motivated by this, we propose a Contextual Residual Aggregation (CRA) mechanism that can produce high-frequency residuals for missing contents by weighted aggregating residuals from contextual patches, thus only requiring a low-resolution prediction from the network. Since convolutional layers of the neural network only need to operate on low-resolution inputs and outputs, the cost of memory and computing power is thus well suppressed. Moreover, the need for high-resolution training datasets is alleviated. In our experiments, we train the proposed model on small images with resolutions 512x512 and perform inference on high-resolution images, achieving compelling inpainting quality. Our model can inpaint images as large as 8K with considerable hole sizes, which is intractable with previous learning-based approaches. We further elaborate on the light-weight design of the network architecture, achieving real-time performance on 2K images on a GTX 1080 Ti GPU. Codes are available at: Atlas200dk/sample-imageinpainting-HiFill.
Altitude Optimization of UAV Base Stations from Satellite Images Using Deep Neural Network
Dec 29, 2021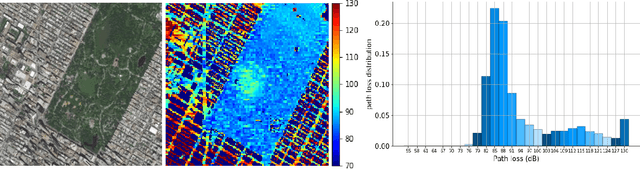
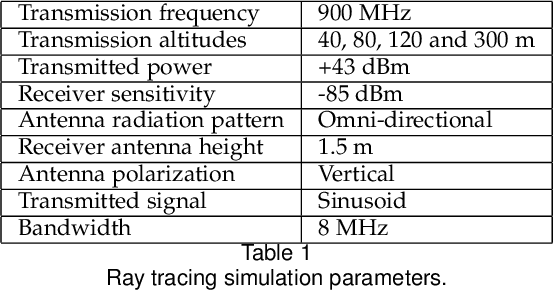
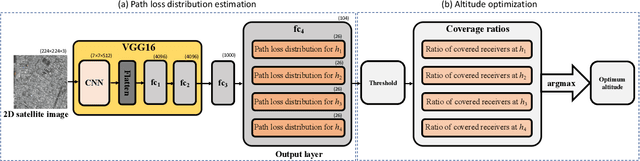
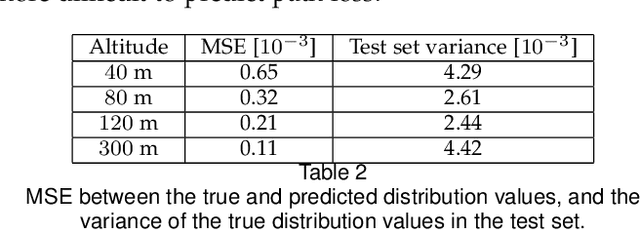
It is expected that unmanned aerial vehicles (UAVs) will play a vital role in future communication systems. Optimum positioning of UAVs, serving as base stations, can be done through extensive field measurements or ray tracing simulations when the 3D model of the region of interest is available. In this paper, we present an alternative approach to optimize UAV base station altitude for a region. The approach is based on deep learning; specifically, a 2D satellite image of the target region is input to a deep neural network to predict path loss distributions for different UAV altitudes. The predicted path distributions are used to calculate the coverage in the region; and the optimum altitude, maximizing the coverage, is determined. The neural network is designed and trained to produce multiple path loss distributions in a single inference; thus, it is not necessary to train a separate network for each altitude.
Transfer RL across Observation Feature Spaces via Model-Based Regularization
Jan 01, 2022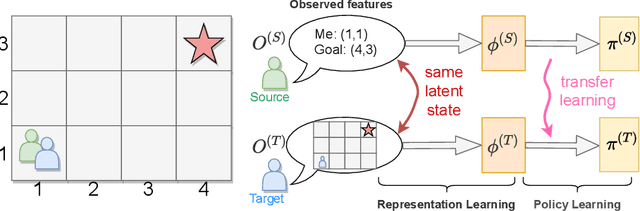
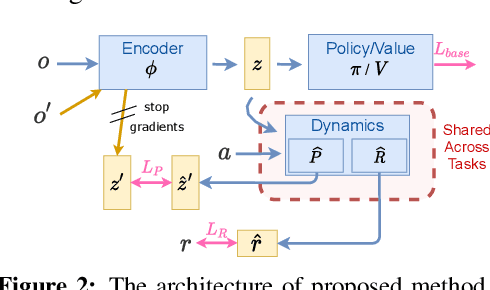
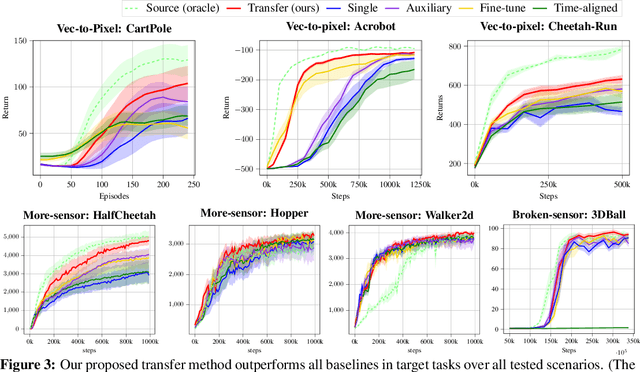
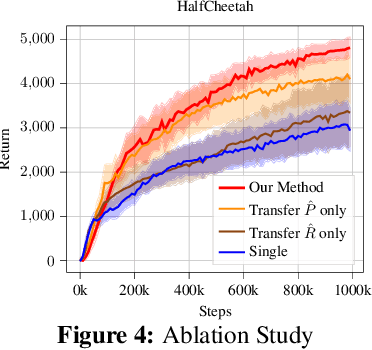
In many reinforcement learning (RL) applications, the observation space is specified by human developers and restricted by physical realizations, and may thus be subject to dramatic changes over time (e.g. increased number of observable features). However, when the observation space changes, the previous policy will likely fail due to the mismatch of input features, and another policy must be trained from scratch, which is inefficient in terms of computation and sample complexity. Following theoretical insights, we propose a novel algorithm which extracts the latent-space dynamics in the source task, and transfers the dynamics model to the target task to use as a model-based regularizer. Our algorithm works for drastic changes of observation space (e.g. from vector-based observation to image-based observation), without any inter-task mapping or any prior knowledge of the target task. Empirical results show that our algorithm significantly improves the efficiency and stability of learning in the target task.
Multiple Style Transfer via Variational AutoEncoder
Oct 13, 2021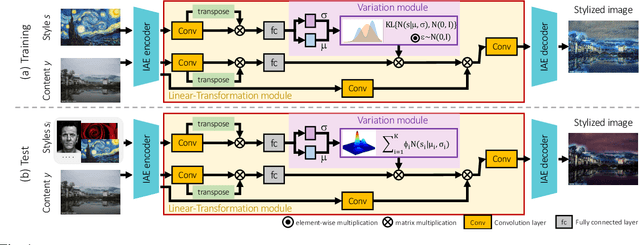
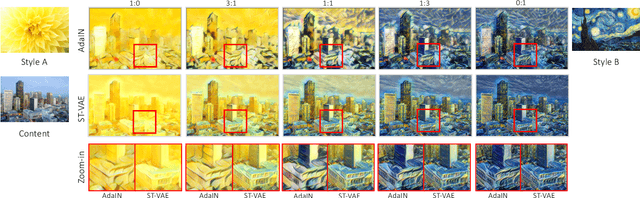


Modern works on style transfer focus on transferring style from a single image. Recently, some approaches study multiple style transfer; these, however, are either too slow or fail to mix multiple styles. We propose ST-VAE, a Variational AutoEncoder for latent space-based style transfer. It performs multiple style transfer by projecting nonlinear styles to a linear latent space, enabling to merge styles via linear interpolation before transferring the new style to the content image. To evaluate ST-VAE, we experiment on COCO for single and multiple style transfer. We also present a case study revealing that ST-VAE outperforms other methods while being faster, flexible, and setting a new path for multiple style transfer.
Self-Supervised Deep Blind Video Super-Resolution
Jan 19, 2022
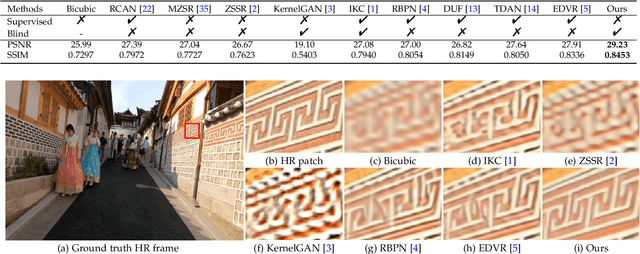
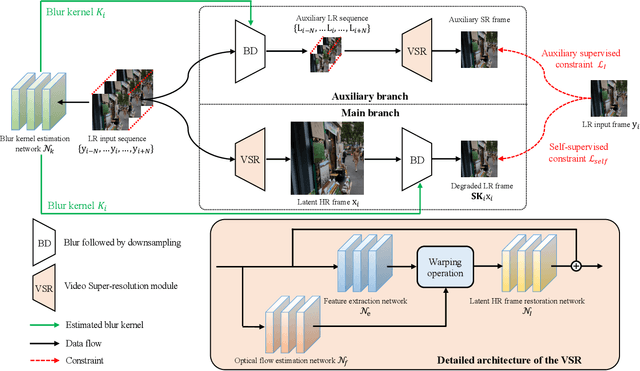
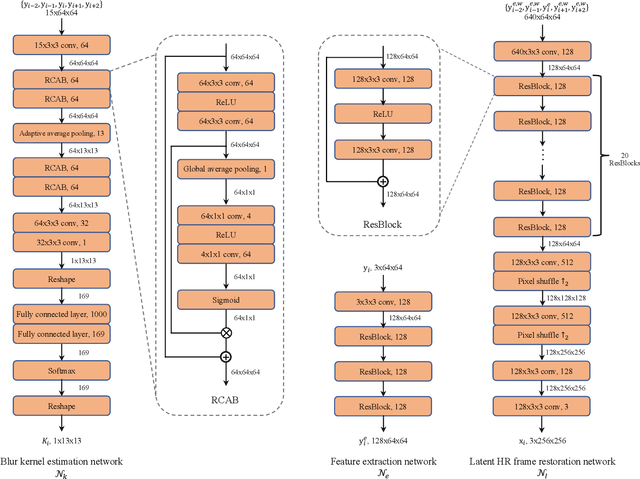
Existing deep learning-based video super-resolution (SR) methods usually depend on the supervised learning approach, where the training data is usually generated by the blurring operation with known or predefined kernels (e.g., Bicubic kernel) followed by a decimation operation. However, this does not hold for real applications as the degradation process is complex and cannot be approximated by these idea cases well. Moreover, obtaining high-resolution (HR) videos and the corresponding low-resolution (LR) ones in real-world scenarios is difficult. To overcome these problems, we propose a self-supervised learning method to solve the blind video SR problem, which simultaneously estimates blur kernels and HR videos from the LR videos. As directly using LR videos as supervision usually leads to trivial solutions, we develop a simple and effective method to generate auxiliary paired data from original LR videos according to the image formation of video SR, so that the networks can be better constrained by the generated paired data for both blur kernel estimation and latent HR video restoration. In addition, we introduce an optical flow estimation module to exploit the information from adjacent frames for HR video restoration. Experiments show that our method performs favorably against state-of-the-art ones on benchmarks and real-world videos.
Through-Foliage Tracking with Airborne Optical Sectioning
Nov 30, 2021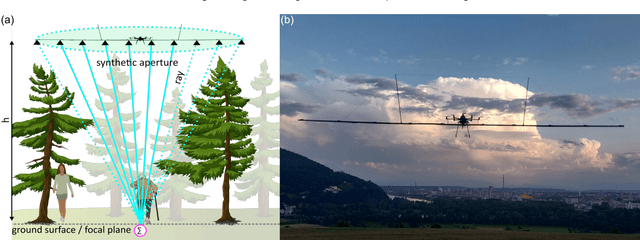
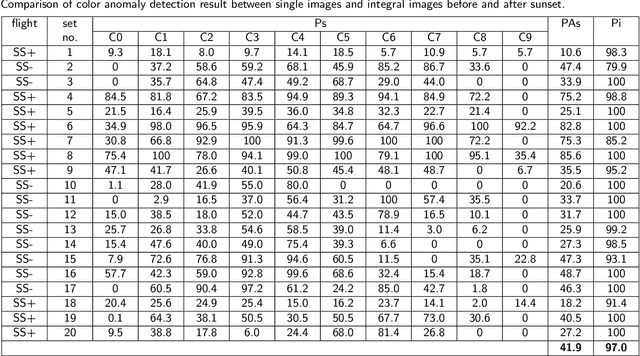
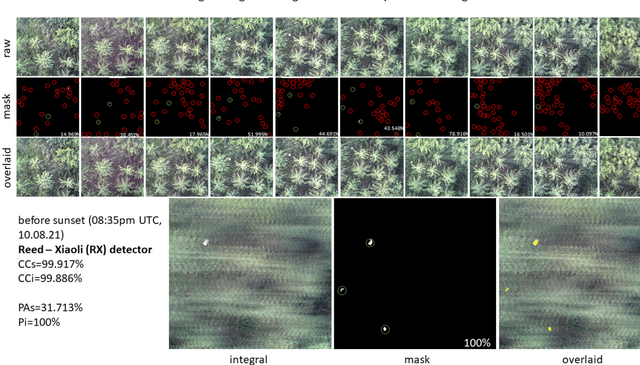
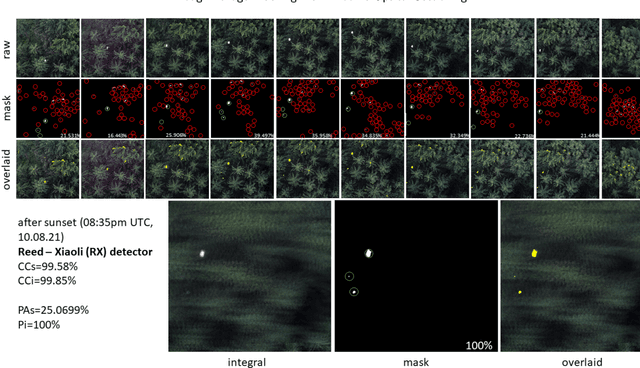
Detecting and tracking moving targets through foliage is difficult, and for many cases even impossible in regular aerial images and videos. We present an initial light-weight and drone-operated 1D camera array that supports parallel synthetic aperture aerial imaging. Our main finding is that color anomaly detection benefits significantly from image integration when compared to conventional raw images or video frames (on average 97% vs. 42% in precision in our field experiments). We demonstrate, that these two contributions can lead to the detection and tracking of moving people through densely occluding forest.
Critical configurations for two projective views, a new approach
Dec 09, 2021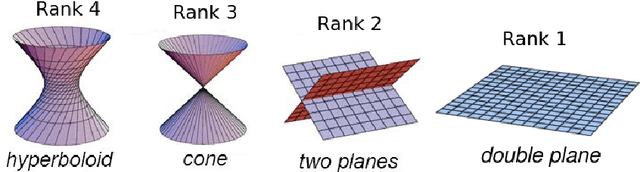
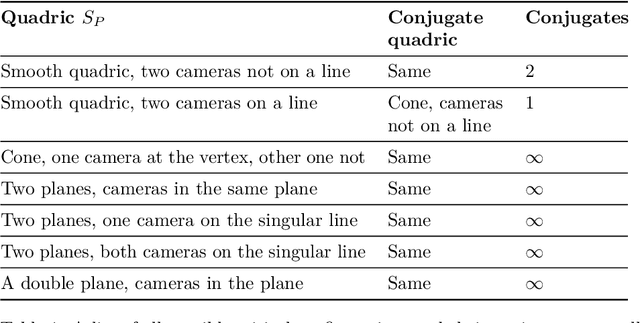
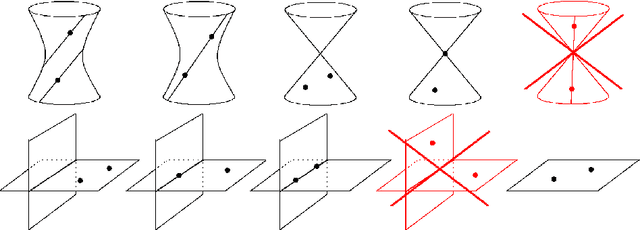

The problem of structure from motion is concerned with recovering 3-dimensional structure of an object from a set of 2-dimensional images. Generally, all information can be uniquely recovered if enough images and image points are provided, but there are certain cases where unique recovery is impossible; these are called critical configurations. In this paper we use an algebraic approach to study the critical configurations for two projective cameras. We show that all critical configurations lie on quadric surfaces, and classify exactly which quadrics constitute a critical configuration. The paper also describes the relation between the different reconstructions when unique reconstruction is impossible.