 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Projective Urban Texturing
Jan 25, 2022

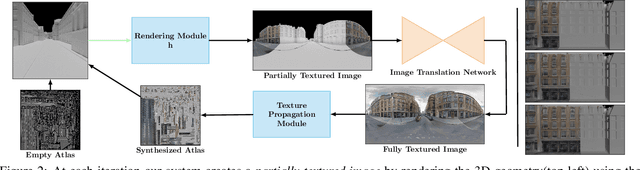
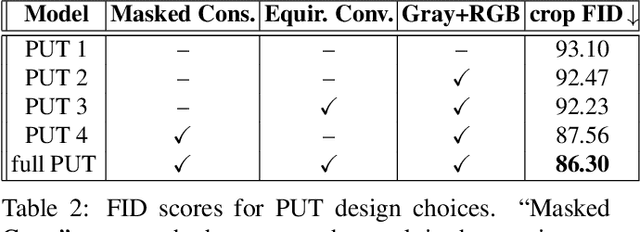

This paper proposes a method for automatic generation of textures for 3D city meshes in immersive urban environments. Many recent pipelines capture or synthesize large quantities of city geometry using scanners or procedural modeling pipelines. Such geometry is intricate and realistic, however the generation of photo-realistic textures for such large scenes remains a problem. We propose to generate textures for input target 3D meshes driven by the textural style present in readily available datasets of panoramic photos capturing urban environments. Re-targeting such 2D datasets to 3D geometry is challenging because the underlying shape, size, and layout of the urban structures in the photos do not correspond to the ones in the target meshes. Photos also often have objects (e.g., trees, vehicles) that may not even be present in the target geometry.To address these issues we present a method, called Projective Urban Texturing (PUT), which re-targets textural style from real-world panoramic images to unseen urban meshes. PUT relies on contrastive and adversarial training of a neural architecture designed for unpaired image-to-texture translation. The generated textures are stored in a texture atlas applied to the target 3D mesh geometry. To promote texture consistency, PUT employs an iterative procedure in which texture synthesis is conditioned on previously generated, adjacent textures. We demonstrate both quantitative and qualitative evaluation of the generated textures.
Warwick Image Forensics Dataset for Device Fingerprinting In Multimedia Forensics
Apr 22, 2020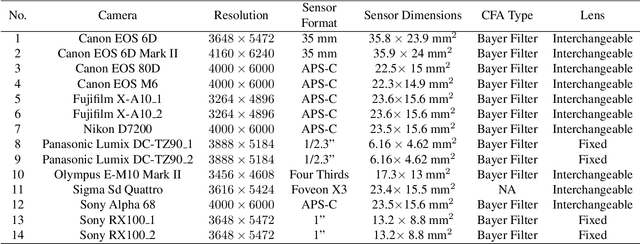

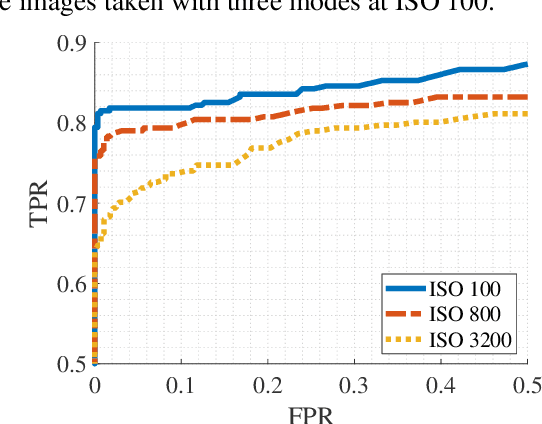
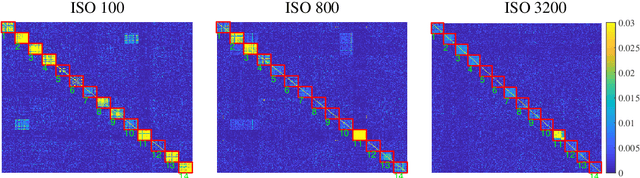
Device fingerprints like sensor pattern noise (SPN) are widely used for provenance analysis and image authentication. Over the past few years, the rapid advancement in digital photography has greatly reshaped the pipeline of image capturing process on consumer-level mobile devices. The flexibility of camera parameter settings and the emergence of multi-frame photography algorithms, especially high dynamic range (HDR) imaging, bring new challenges to device fingerprinting. The subsequent study on these topics requires a new purposefully built image dataset. In this paper, we present the Warwick Image Forensics Dataset, an image dataset of more than 58,600 images captured using 14 digital cameras with various exposure settings. Special attention to the exposure settings allows the images to be adopted by different multi-frame computational photography algorithms and for subsequent device fingerprinting. The dataset is released as an open-source, free for use for the digital forensic community.
Mind the Gap: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks
Oct 15, 2021

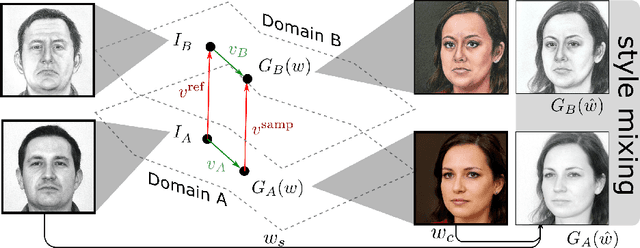
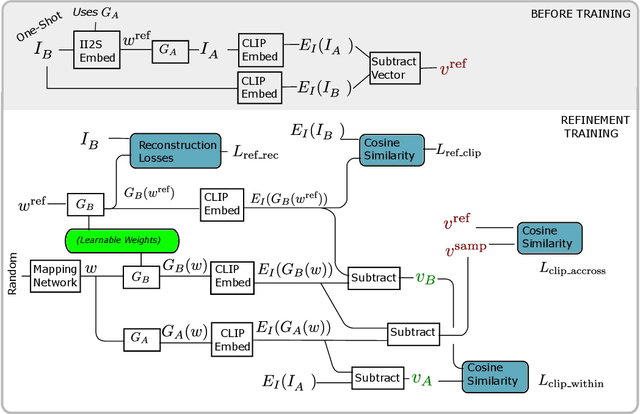
We present a new method for one shot domain adaptation. The input to our method is trained GAN that can produce images in domain A and a single reference image I_B from domain B. The proposed algorithm can translate any output of the trained GAN from domain A to domain B. There are two main advantages of our method compared to the current state of the art: First, our solution achieves higher visual quality, e.g. by noticeably reducing overfitting. Second, our solution allows for more degrees of freedom to control the domain gap, i.e. what aspects of image I_B are used to define the domain B. Technically, we realize the new method by building on a pre-trained StyleGAN generator as GAN and a pre-trained CLIP model for representing the domain gap. We propose several new regularizers for controlling the domain gap to optimize the weights of the pre-trained StyleGAN generator to output images in domain B instead of domain A. The regularizers prevent the optimization from taking on too many attributes of the single reference image. Our results show significant visual improvements over the state of the art as well as multiple applications that highlight improved control.
Web page classification with Google Image Search results
May 30, 2020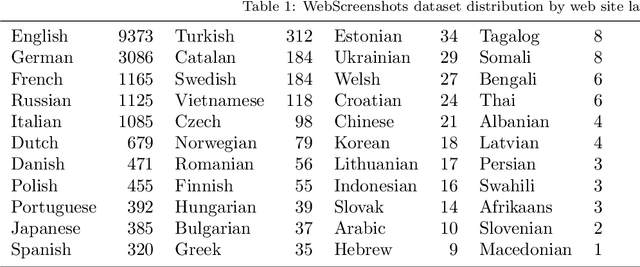

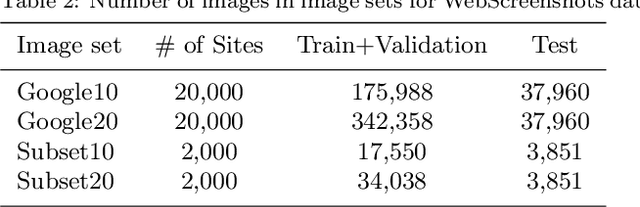
In this paper, we introduce a novel method that combines multiple neural network results to decide the class of the input. In our model, each element is represented by multiple descriptive images. After the training process of the neural network model, each element is classified by calculating its descriptive image results. We apply our idea to the web page classification problem using Google Image Search results as descriptive images. We obtained a classification rate of 94.90% on the WebScreenshots dataset that contains 20000 web sites in 4 classes. The method is easily applicable to similar problems.
Characterization of Semantic Segmentation Models on Mobile Platforms for Self-Navigation in Disaster-Struck Zones
Feb 03, 2022
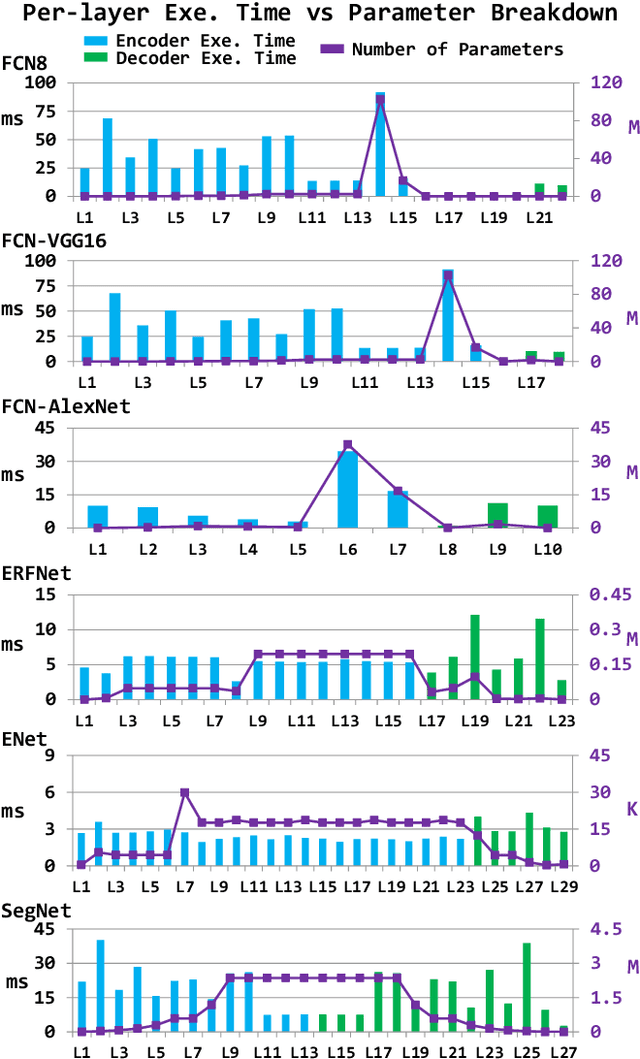
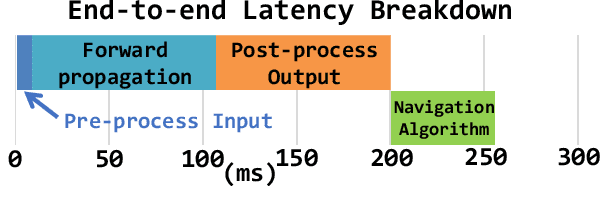
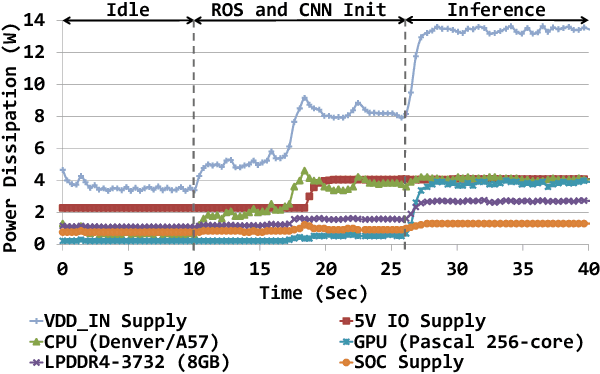
The role of unmanned vehicles for searching and localizing the victims in disaster impacted areas such as earthquake-struck zones is getting more important. Self-navigation on an earthquake zone has a unique challenge of detecting irregularly shaped obstacles such as road cracks, debris on the streets, and water puddles. In this paper, we characterize a number of state-of-the-art FCN models on mobile embedded platforms for self-navigation at these sites containing extremely irregular obstacles. We evaluate the models in terms of accuracy, performance, and energy efficiency. We present a few optimizations for our designed vision system. Lastly, we discuss the trade-offs of these models for a couple of mobile platforms that can each perform self-navigation. To enable vehicles to safely navigate earthquake-struck zones, we compiled a new annotated image database of various earthquake impacted regions that is different than traditional road damage databases. We train our database with a number of state-of-the-art semantic segmentation models in order to identify obstacles unique to earthquake-struck zones. Based on the statistics and tradeoffs, an optimal CNN model is selected for the mobile vehicular platforms, which we apply to both low-power and extremely low-power configurations of our design. To our best knowledge, this is the first study that identifies unique challenges and discusses the accuracy, performance, and energy impact of edge-based self-navigation mobile vehicles for earthquake-struck zones. Our proposed database and trained models are publicly available.
Unpaired Image Enhancement with Quality-Attention Generative Adversarial Network
Dec 30, 2020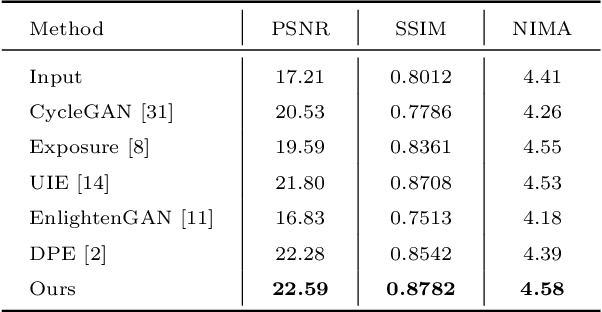
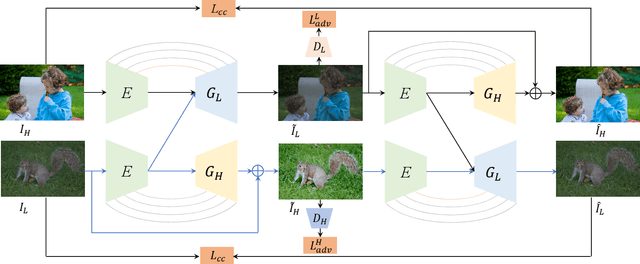
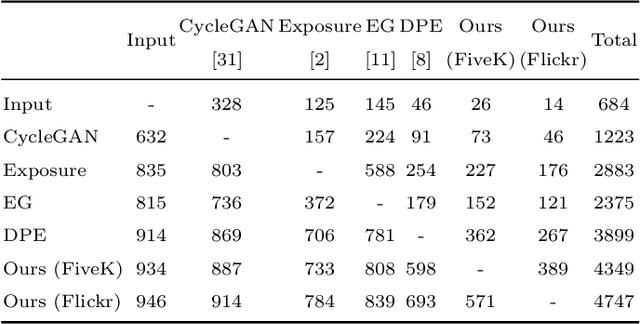
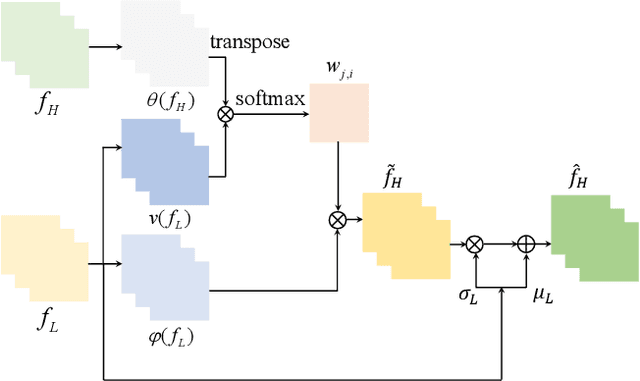
In this work, we aim to learn an unpaired image enhancement model, which can enrich low-quality images with the characteristics of high-quality images provided by users. We propose a quality attention generative adversarial network (QAGAN) trained on unpaired data based on the bidirectional Generative Adversarial Network (GAN) embedded with a quality attention module (QAM). The key novelty of the proposed QAGAN lies in the injected QAM for the generator such that it learns domain-relevant quality attention directly from the two domains. More specifically, the proposed QAM allows the generator to effectively select semantic-related characteristics from the spatial-wise and adaptively incorporate style-related attributes from the channel-wise, respectively. Therefore, in our proposed QAGAN, not only discriminators but also the generator can directly access both domains which significantly facilitates the generator to learn the mapping function. Extensive experimental results show that, compared with the state-of-the-art methods based on unpaired learning, our proposed method achieves better performance in both objective and subjective evaluations.
CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation
Oct 06, 2021
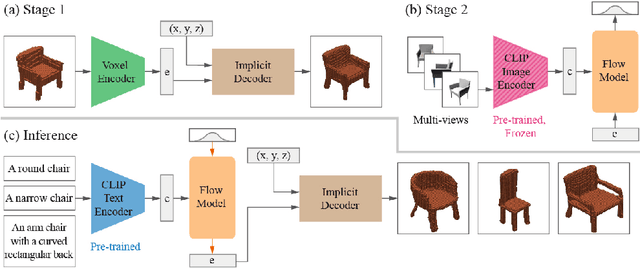


While recent progress has been made in text-to-image generation, text-to-shape generation remains a challenging problem due to the unavailability of paired text and shape data at a large scale. We present a simple yet effective method for zero-shot text-to-shape generation based on a two-stage training process, which only depends on an unlabelled shape dataset and a pre-trained image-text network such as CLIP. Our method not only demonstrates promising zero-shot generalization, but also avoids expensive inference time optimization and can generate multiple shapes for a given text.
Spectral Compressive Imaging Reconstruction Using Convolution and Spectral Contextual Transformer
Jan 15, 2022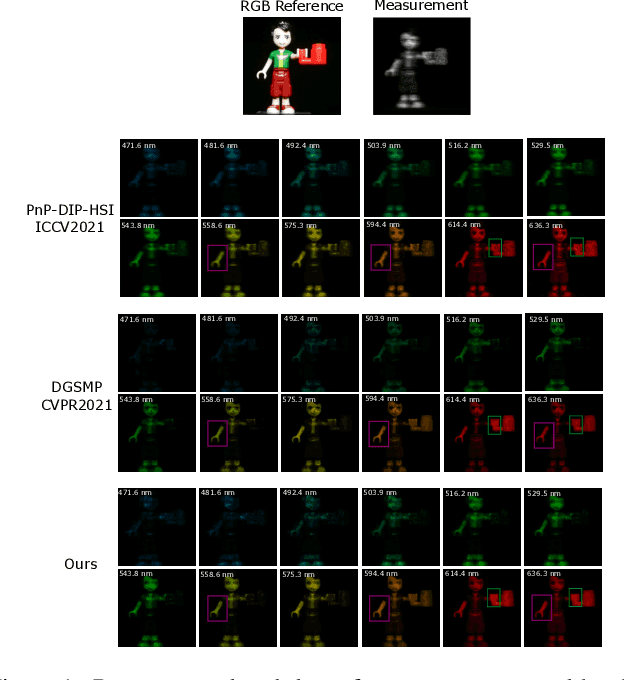
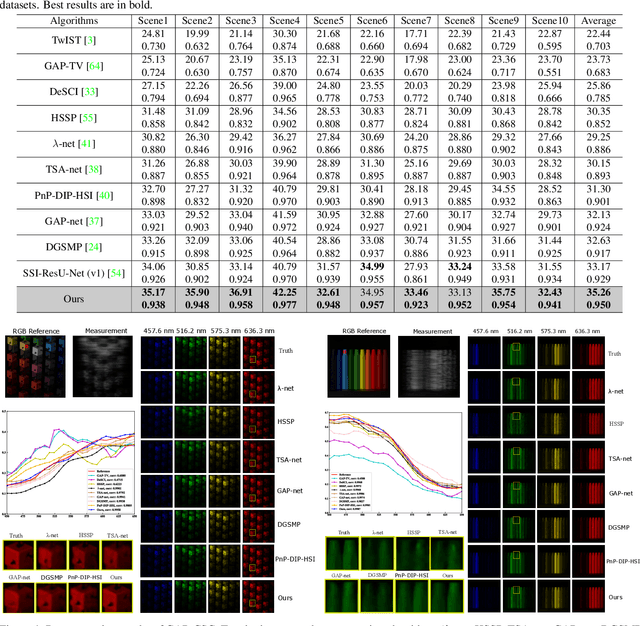
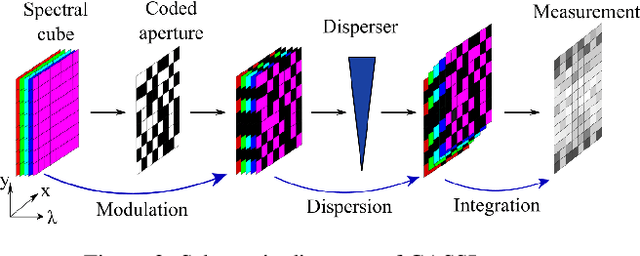

Spectral compressive imaging (SCI) is able to encode the high-dimensional hyperspectral image to a 2D measurement, and then uses algorithms to reconstruct the spatio-spectral data-cube. At present, the main bottleneck of SCI is the reconstruction algorithm, and the state-of-the-art (SOTA) reconstruction methods generally face the problem of long reconstruction time and/or poor detail recovery. In this paper, we propose a novel hybrid network module, namely CSCoT (Convolution and Spectral Contextual Transformer) block, which can acquire the local perception of convolution and the global perception of transformer simultaneously, and is conducive to improving the quality of reconstruction to restore fine details. We integrate the proposed CSCoT block into deep unfolding framework based on the generalized alternating projection algorithm, and further propose the GAP-CSCoT network. Finally, we apply the GAP-CSCoT algorithm to SCI reconstruction. Through the experiments of extensive synthetic and real data, our proposed model achieves higher reconstruction quality ($>$2dB in PSNR on simulated benchmark datasets) and shorter running time than existing SOTA algorithms by a large margin. The code and models will be released to the public.
Compound eye inspired flat lensless imaging with spatially-coded Voronoi-Fresnel phase
Sep 28, 2021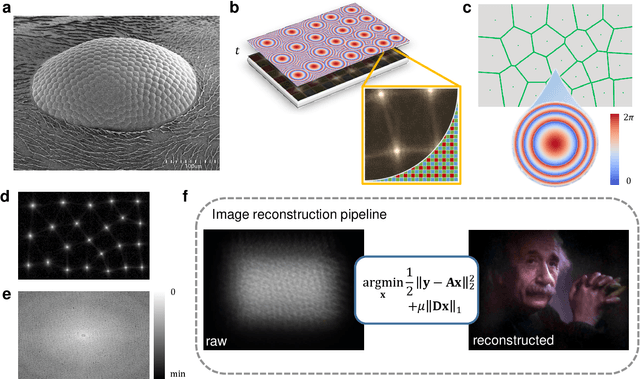
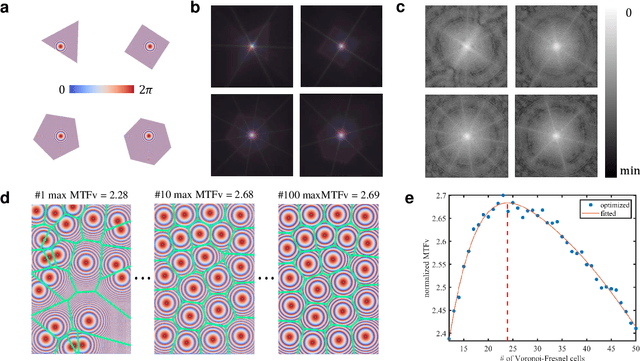

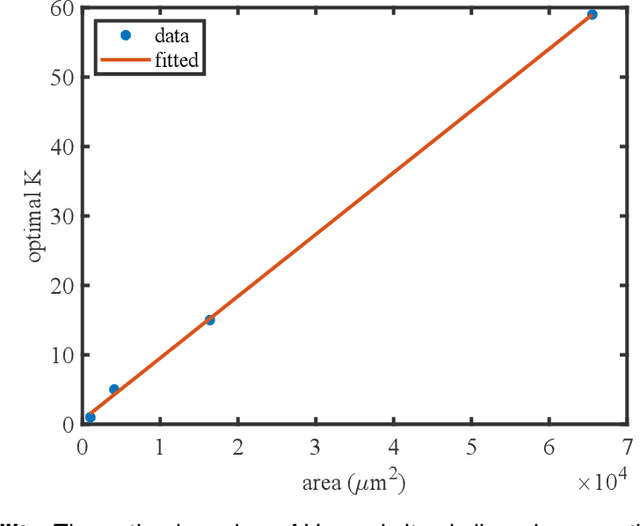
Lensless cameras are a class of imaging devices that shrink the physical dimensions to the very close vicinity of the image sensor by integrating flat optics and computational algorithms. Here we report a flat lensless camera with spatially-coded Voronoi-Fresnel phase, partly inspired by biological apposition compound eye, to achieve superior image quality. We propose a design principle of maximizing the information in optics to facilitate the computational reconstruction. By introducing a Fourier domain metric, Modulation Transfer Function volume (MTFv), we devise an optimization framework to guide the optimal design of the optical element. The resulting Voronoi-Fresnel phase features an irregular array of quasi-Centroidal Voronoi cells containing a base first-order Fresnel phase function. We demonstrate and verify the imaging performance with a prototype Voronoi-Fresnel lensless camera on a 1.6-megapixel image sensor in various illumination conditions. The proposed design could benefit the development of compact imaging systems working in extreme physical conditions.
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models
Aug 06, 2021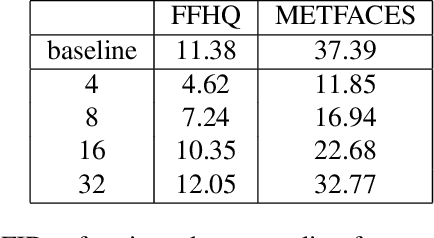
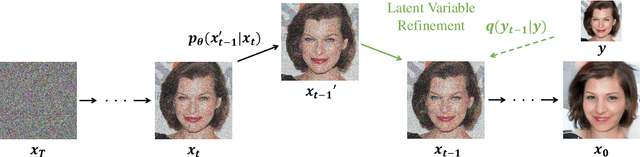

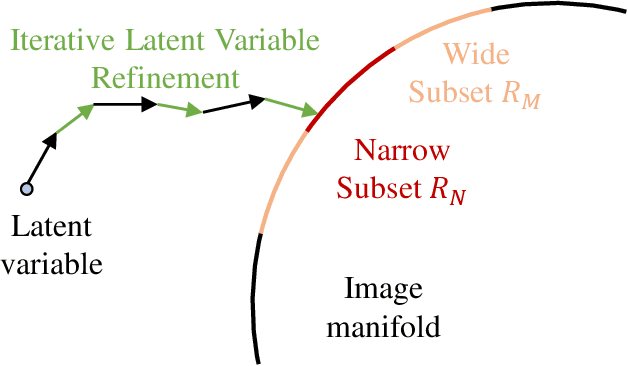
Denoising diffusion probabilistic models (DDPM) have shown remarkable performance in unconditional image generation. However, due to the stochasticity of the generative process in DDPM, it is challenging to generate images with the desired semantics. In this work, we propose Iterative Latent Variable Refinement (ILVR), a method to guide the generative process in DDPM to generate high-quality images based on a given reference image. Here, the refinement of the generative process in DDPM enables a single DDPM to sample images from various sets directed by the reference image. The proposed ILVR method generates high-quality images while controlling the generation. The controllability of our method allows adaptation of a single DDPM without any additional learning in various image generation tasks, such as generation from various downsampling factors, multi-domain image translation, paint-to-image, and editing with scribbles.