 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Virtual Adversarial Training for Semi-supervised Breast Mass Classification
Jan 25, 2022
This study aims to develop a novel computer-aided diagnosis (CAD) scheme for mammographic breast mass classification using semi-supervised learning. Although supervised deep learning has achieved huge success across various medical image analysis tasks, its success relies on large amounts of high-quality annotations, which can be challenging to acquire in practice. To overcome this limitation, we propose employing a semi-supervised method, i.e., virtual adversarial training (VAT), to leverage and learn useful information underlying in unlabeled data for better classification of breast masses. Accordingly, our VAT-based models have two types of losses, namely supervised and virtual adversarial losses. The former loss acts as in supervised classification, while the latter loss aims at enhancing model robustness against virtual adversarial perturbation, thus improving model generalizability. To evaluate the performance of our VAT-based CAD scheme, we retrospectively assembled a total of 1024 breast mass images, with equal number of benign and malignant masses. A large CNN and a small CNN were used in this investigation, and both were trained with and without the adversarial loss. When the labeled ratios were 40% and 80%, VAT-based CNNs delivered the highest classification accuracy of 0.740 and 0.760, respectively. The experimental results suggest that the VAT-based CAD scheme can effectively utilize meaningful knowledge from unlabeled data to better classify mammographic breast mass images.
Twitter-COMMs: Detecting Climate, COVID, and Military Multimodal Misinformation
Dec 16, 2021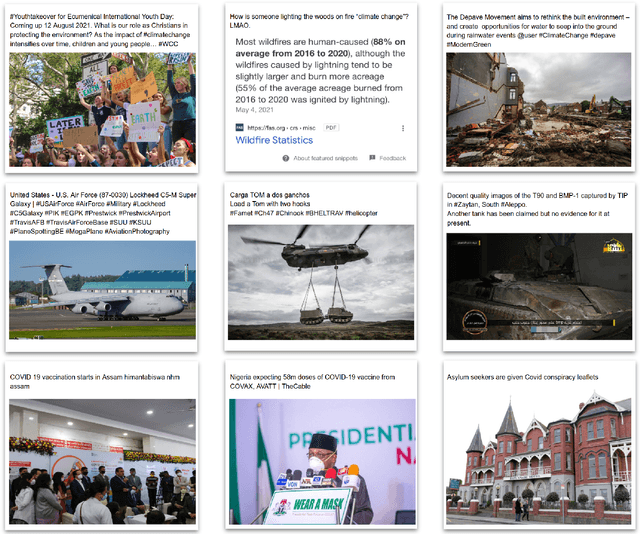
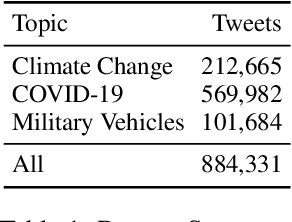
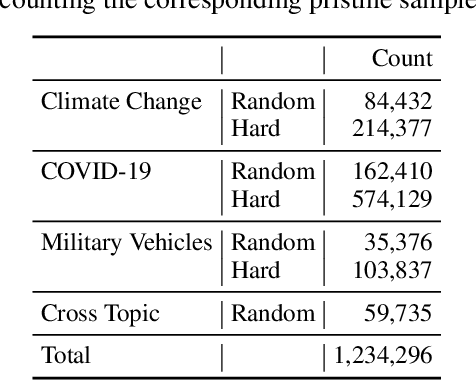

Detecting out-of-context media, such as "miscaptioned" images on Twitter, often requires detecting inconsistencies between the two modalities. This paper describes our approach to the Image-Text Inconsistency Detection challenge of the DARPA Semantic Forensics (SemaFor) Program. First, we collect Twitter-COMMs, a large-scale multimodal dataset with 884k tweets relevant to the topics of Climate Change, COVID-19, and Military Vehicles. We train our approach, based on the state-of-the-art CLIP model, leveraging automatically generated random and hard negatives. Our method is then tested on a hidden human-generated evaluation set. We achieve the best result on the program leaderboard, with 11% detection improvement in a high precision regime over a zero-shot CLIP baseline.
Operationalizing Convolutional Neural Network Architectures for Prohibited Object Detection in X-Ray Imagery
Oct 10, 2021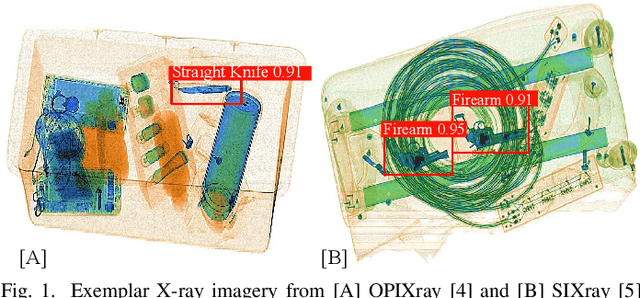
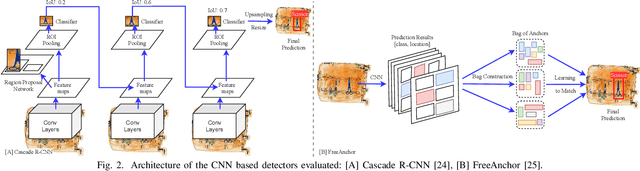
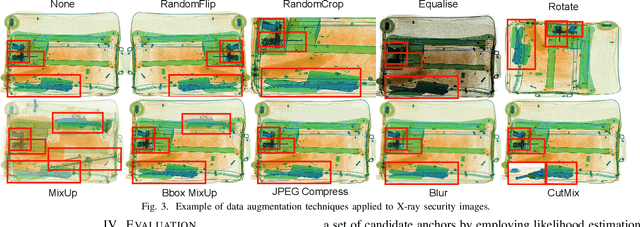
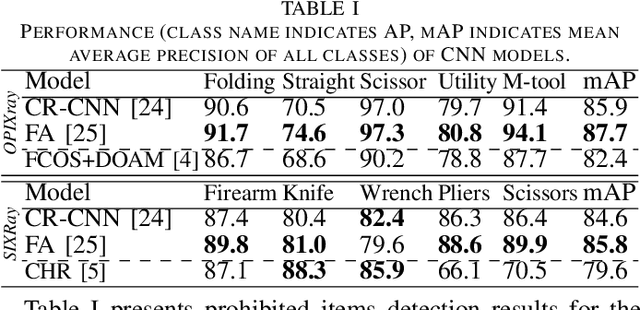
The recent advancement in deep Convolutional Neural Network (CNN) has brought insight into the automation of X-ray security screening for aviation security and beyond. Here, we explore the viability of two recent end-to-end object detection CNN architectures, Cascade R-CNN and FreeAnchor, for prohibited item detection by balancing processing time and the impact of image data compression from an operational viewpoint. Overall, we achieve maximal detection performance using a FreeAnchor architecture with a ResNet50 backbone, obtaining mean Average Precision (mAP) of 87.7 and 85.8 for using the OPIXray and SIXray benchmark datasets, showing superior performance over prior work on both. With fewer parameters and less training time, FreeAnchor achieves the highest detection inference speed of ~13 fps (3.9 ms per image). Furthermore, we evaluate the impact of lossy image compression upon detector performance. The CNN models display substantial resilience to the lossy compression, resulting in only a 1.1% decrease in mAP at the JPEG compression level of 50. Additionally, a thorough evaluation of data augmentation techniques is provided, including adaptions of MixUp and CutMix strategy as well as other standard transformations, further improving the detection accuracy.
Improving GAN Equilibrium by Raising Spatial Awareness
Dec 01, 2021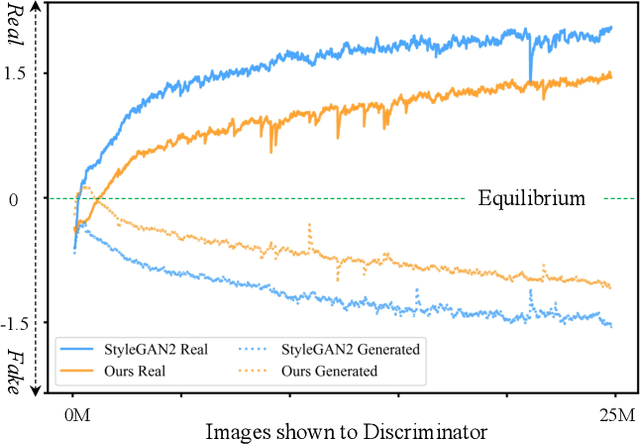
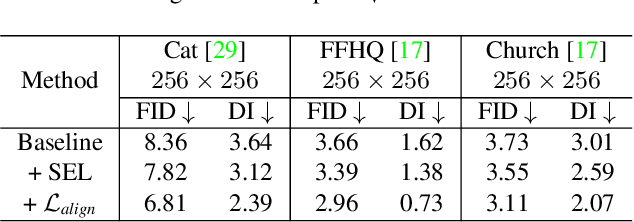
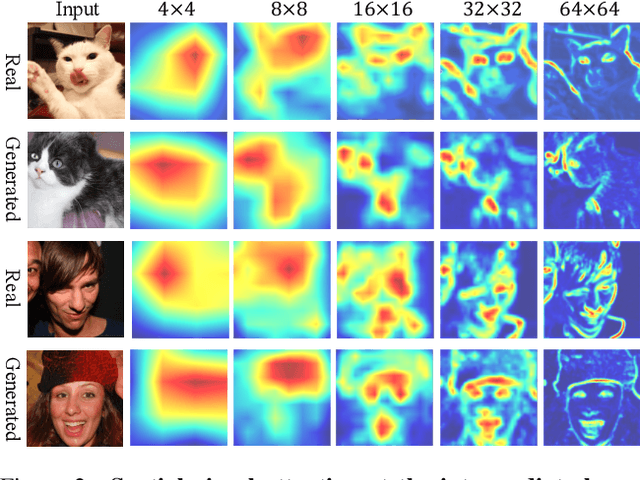

The success of Generative Adversarial Networks (GANs) is largely built upon the adversarial training between a generator (G) and a discriminator (D). They are expected to reach a certain equilibrium where D cannot distinguish the generated images from the real ones. However, in practice it is difficult to achieve such an equilibrium in GAN training, instead, D almost always surpasses G. We attribute this phenomenon to the information asymmetry between D and G. Specifically, we observe that D learns its own visual attention when determining whether an image is real or fake, but G has no explicit clue on which regions to focus on for a particular synthesis. To alleviate the issue of D dominating the competition in GANs, we aim to raise the spatial awareness of G. Randomly sampled multi-level heatmaps are encoded into the intermediate layers of G as an inductive bias. Thus G can purposefully improve the synthesis of certain image regions. We further propose to align the spatial awareness of G with the attention map induced from D. Through this way we effectively lessen the information gap between D and G. Extensive results show that our method pushes the two-player game in GANs closer to the equilibrium, leading to a better synthesis performance. As a byproduct, the introduced spatial awareness facilitates interactive editing over the output synthesis. Demo video and more results are at https://genforce.github.io/eqgan/.
QMagFace: Simple and Accurate Quality-Aware Face Recognition
Nov 26, 2021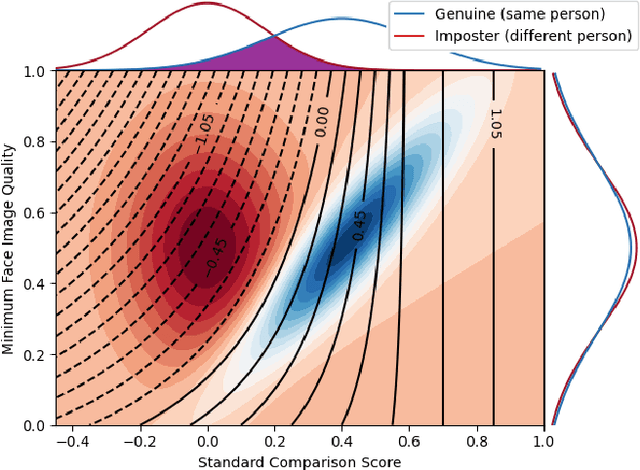
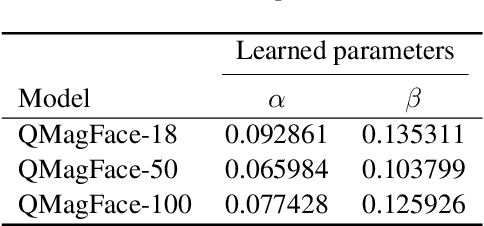
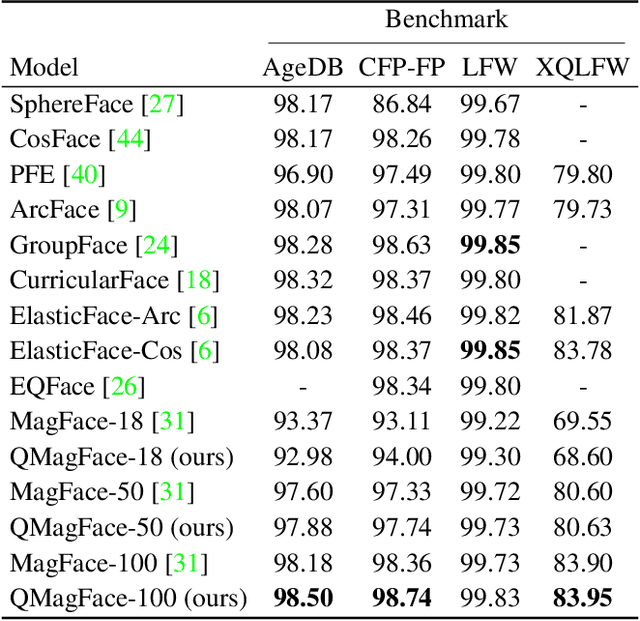
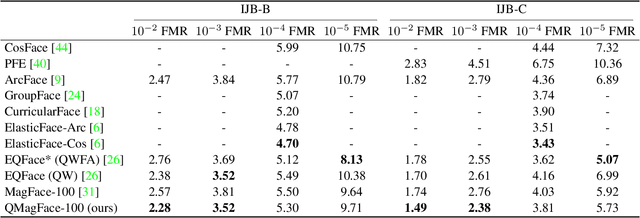
Face recognition systems have to deal with large variabilities (such as different poses, illuminations, and expressions) that might lead to incorrect matching decisions. These variabilities can be measured in terms of face image quality which is defined over the utility of a sample for recognition. Previous works on face recognition either do not employ this valuable information or make use of non-inherently fit quality estimates. In this work, we propose a simple and effective face recognition solution (QMagFace) that combines a quality-aware comparison score with a recognition model based on a magnitude-aware angular margin loss. The proposed approach includes model-specific face image qualities in the comparison process to enhance the recognition performance under unconstrained circumstances. Exploiting the linearity between the qualities and their comparison scores induced by the utilized loss, our quality-aware comparison function is simple and highly generalizable. The experiments conducted on several face recognition databases and benchmarks demonstrate that the introduced quality-awareness leads to consistent improvements in the recognition performance. Moreover, the proposed QMagFace approach performs especially well under challenging circumstances, such as cross-pose, cross-age, or cross-quality. Consequently, it leads to state-of-the-art performances on several face recognition benchmarks, such as 98.50% on AgeDB, 83.97% on XQLFQ, and 98.74% on CFP-FP. The code for QMagFace is publicly available.
Distributionally Robust Group Backwards Compatibility
Dec 20, 2021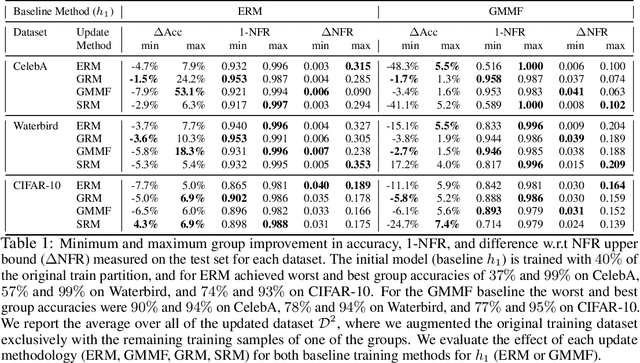
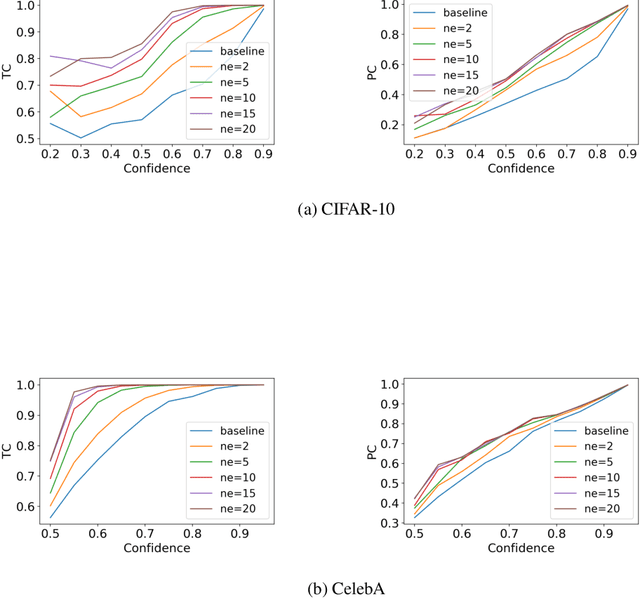
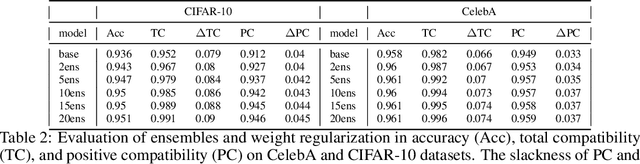

Machine learning models are updated as new data is acquired or new architectures are developed. These updates usually increase model performance, but may introduce backward compatibility errors, where individual users or groups of users see their performance on the updated model adversely affected. This problem can also be present when training datasets do not accurately reflect overall population demographics, with some groups having overall lower participation in the data collection process, posing a significant fairness concern. We analyze how ideas from distributional robustness and minimax fairness can aid backward compatibility in this scenario, and propose two methods to directly address this issue. Our theoretical analysis is backed by experimental results on CIFAR-10, CelebA, and Waterbirds, three standard image classification datasets. Code available at github.com/natalialmg/GroupBC
A Comprehensive Review of Computer-aided Whole-slide Image Analysis: from Datasets to Feature Extraction, Segmentation, Classification, and Detection Approaches
Feb 21, 2021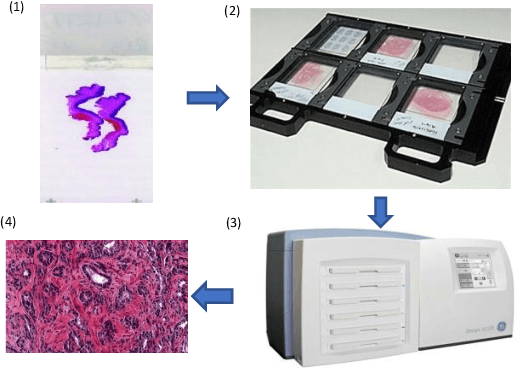
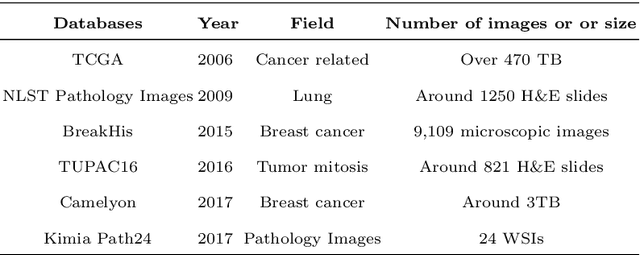
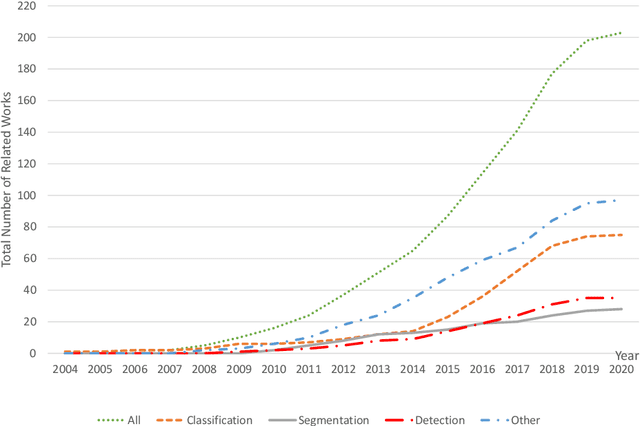

With the development of computer-aided diagnosis (CAD) and image scanning technology, Whole-slide Image (WSI) scanners are widely used in the field of pathological diagnosis. Therefore, WSI analysis has become the key to modern digital pathology. Since 2004, WSI has been used more and more in CAD. Since machine vision methods are usually based on semi-automatic or fully automatic computers, they are highly efficient and labor-saving. The combination of WSI and CAD technologies for segmentation, classification, and detection helps histopathologists obtain more stable and quantitative analysis results, save labor costs and improve diagnosis objectivity. This paper reviews the methods of WSI analysis based on machine learning. Firstly, the development status of WSI and CAD methods are introduced. Secondly, we discuss publicly available WSI datasets and evaluation metrics for segmentation, classification, and detection tasks. Then, the latest development of machine learning in WSI segmentation, classification, and detection are reviewed continuously. Finally, the existing methods are studied, the applicabilities of the analysis methods are analyzed, and the application prospects of the analysis methods in this field are forecasted.
C-Net: A Reliable Convolutional Neural Network for Biomedical Image Classification
Oct 30, 2020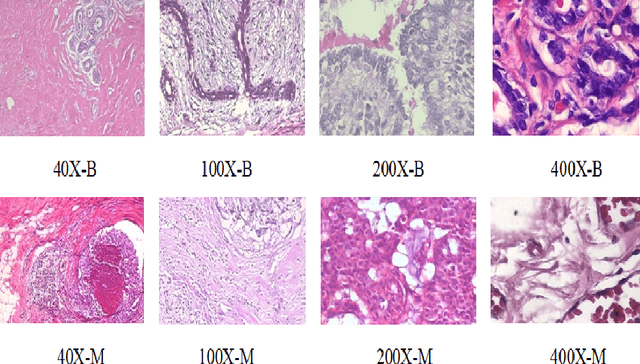
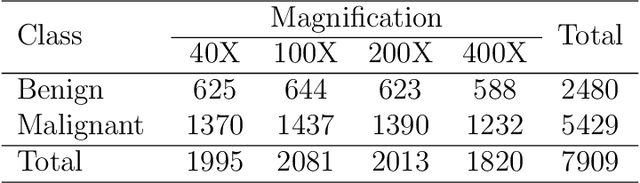
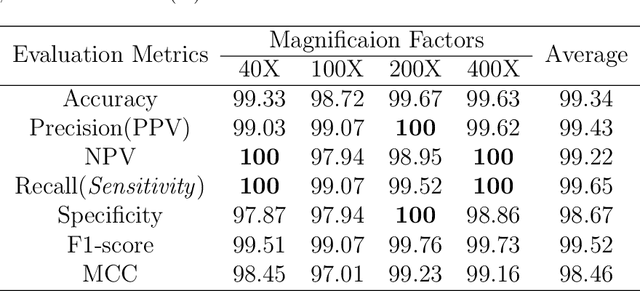
Cancers are the leading cause of death in many developed countries. Early diagnosis plays a crucial role in having proper treatment for this debilitating disease. The automated classification of the type of cancer is a challenging task since pathologists must examine a huge number of histopathological images to detect infinitesimal abnormalities. In this study, we propose a novel convolutional neural network (CNN) architecture composed of a Concatenation of multiple Networks, called C-Net, to classify biomedical images. In contrast to conventional deep learning models in biomedical image classification, which utilize transfer learning to solve the problem, no prior knowledge is employed. The model incorporates multiple CNNs including Outer, Middle, and Inner. The first two parts of the architecture contain six networks that serve as feature extractors to feed into the Inner network to classify the images in terms of malignancy and benignancy. The C-Net is applied for histopathological image classification on two public datasets, including BreakHis and Osteosarcoma. To evaluate the performance, the model is tested using several evaluation metrics for its reliability. The C-Net model outperforms all other models on the individual metrics for both datasets and achieves zero misclassification.
Spherical Image Generation from a Single Normal Field of View Image by Considering Scene Symmetry
Jan 09, 2020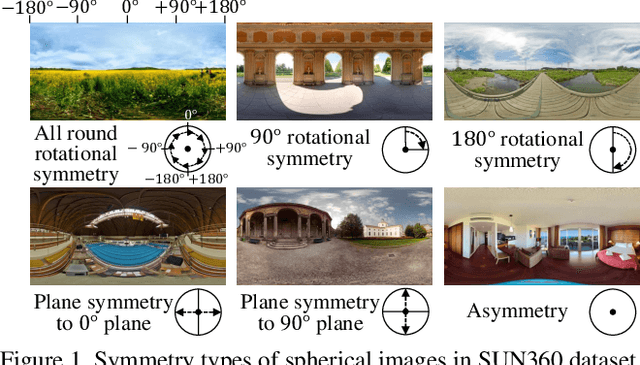
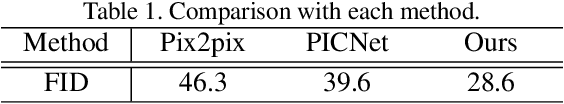
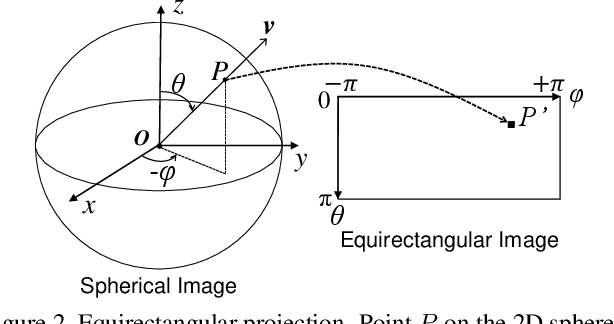

Spherical images taken in all directions (360 degrees) allow representing the surroundings of the subject and the space itself, providing an immersive experience to the viewers. Generating a spherical image from a single normal-field-of-view (NFOV) image is convenient and considerably expands the usage scenarios because there is no need to use a specific panoramic camera or take images from multiple directions; however, it is still a challenging and unsolved problem. The primary challenge is controlling the high degree of freedom involved in generating a wide area that includes the all directions of the desired plausible spherical image. On the other hand, scene symmetry is a basic property of the global structure of the spherical images, such as rotation symmetry, plane symmetry and asymmetry. We propose a method to generate spherical image from a single NFOV image, and control the degree of freedom of the generated regions using scene symmetry. We incorporate scene-symmetry parameters as latent variables into conditional variational autoencoders, following which we learn the conditional probability of spherical images for NFOV images and scene symmetry. Furthermore, the probability density functions are represented using neural networks, and scene symmetry is implemented using both circular shift and flip of the hidden variables. Our experiments show that the proposed method can generate various plausible spherical images, controlled from symmetric to asymmetric.
Active Deep Densely Connected Convolutional Network for Hyperspectral Image Classification
Sep 01, 2020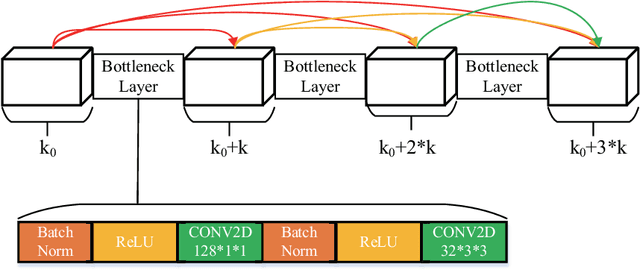

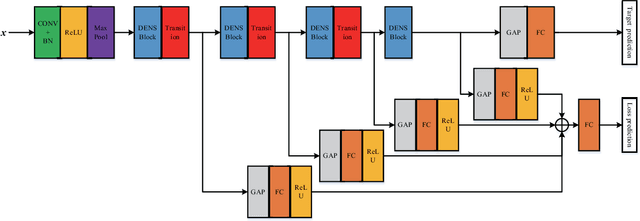
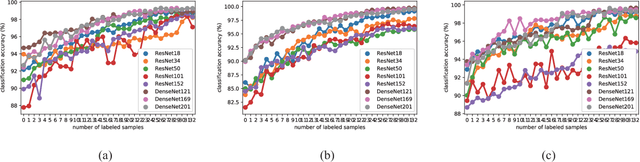
Deep learning based methods have seen a massive rise in popularity for hyperspectral image classification over the past few years. However, the success of deep learning is attributed greatly to numerous labeled samples. It is still very challenging to use only a few labeled samples to train deep learning models to reach a high classification accuracy. An active deep-learning framework trained by an end-to-end manner is, therefore, proposed by this paper in order to minimize the hyperspectral image classification costs. First, a deep densely connected convolutional network is considered for hyperspectral image classification. Different from the traditional active learning methods, an additional network is added to the designed deep densely connected convolutional network to predict the loss of input samples. Then, the additional network could be used to suggest unlabeled samples that the deep densely connected convolutional network is more likely to produce a wrong label. Note that the additional network uses the intermediate features of the deep densely connected convolutional network as input. Therefore, the proposed method is an end-to-end framework. Subsequently, a few of the selected samples are labelled manually and added to the training samples. The deep densely connected convolutional network is therefore trained using the new training set. Finally, the steps above are repeated to train the whole framework iteratively. Extensive experiments illustrates that the method proposed could reach a high accuracy in classification after selecting just a few samples.