 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Physics through Images: An Application to Wind-Driven Spatial Patterns
Feb 03, 2022

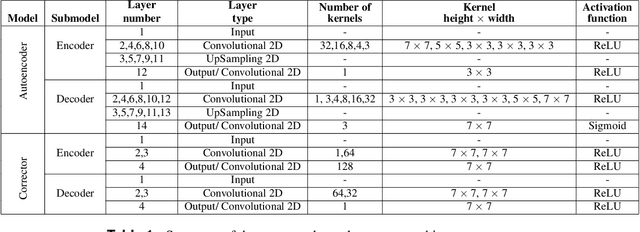
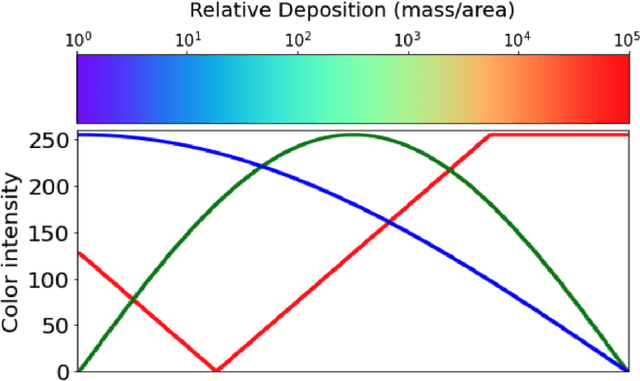
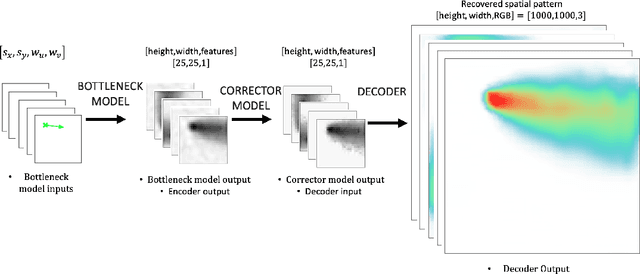
For centuries, scientists have observed nature to understand the laws that govern the physical world. The traditional process of turning observations into physical understanding is slow. Imperfect models are constructed and tested to explain relationships in data. Powerful new algorithms are available that can enable computers to learn physics by observing images and videos. Inspired by this idea, instead of training machine learning models using physical quantities, we trained them using images, that is, pixel information. For this work, and as a proof of concept, the physics of interest are wind-driven spatial patterns. Examples of these phenomena include features in Aeolian dunes and the deposition of volcanic ash, wildfire smoke, and air pollution plumes. We assume that the spatial patterns were collected by an imaging device that records the magnitude of the logarithm of deposition as a red, green, blue (RGB) color image with channels containing values ranging from 0 to 255. In this paper, we explore deep convolutional neural network-based autoencoders to exploit relationships in wind-driven spatial patterns, which commonly occur in geosciences, and reduce their dimensionality. Reducing the data dimension size with an encoder allows us to train regression models linking geographic and meteorological scalar input quantities to the encoded space. Once this is achieved, full predictive spatial patterns are reconstructed using the decoder. We demonstrate this approach on images of spatial deposition from a pollution source, where the encoder compresses the dimensionality to 0.02% of the original size and the full predictive model performance on test data achieves an accuracy of 92%.
Curating Subject ID Labels using Keypoint Signatures
Oct 07, 2021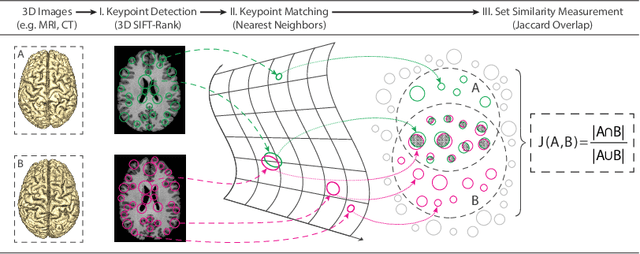
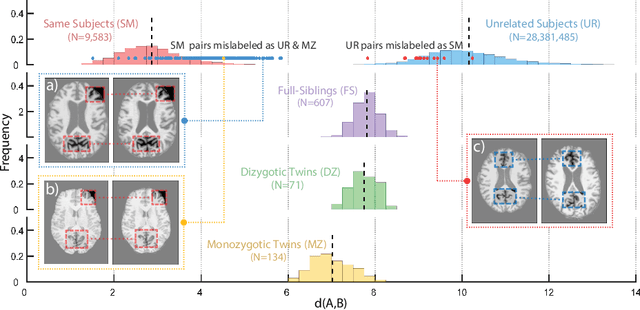
Subject ID labels are unique, anonymized codes that can be used to group all images of a subject while maintaining anonymity. ID errors may be inadvertently introduced manually error during enrollment and may lead to systematic error into machine learning evaluation (e.g. due to double-dipping) or potential patient misdiagnosis in clinical contexts. Here we describe a highly efficient system for curating subject ID labels in large generic medical image datasets, based on the 3D image keypoint representation, which recently led to the discovery of previously unknown labeling errors in widely-used public brain MRI datasets
DuDoTrans: Dual-Domain Transformer Provides More Attention for Sinogram Restoration in Sparse-View CT Reconstruction
Nov 21, 2021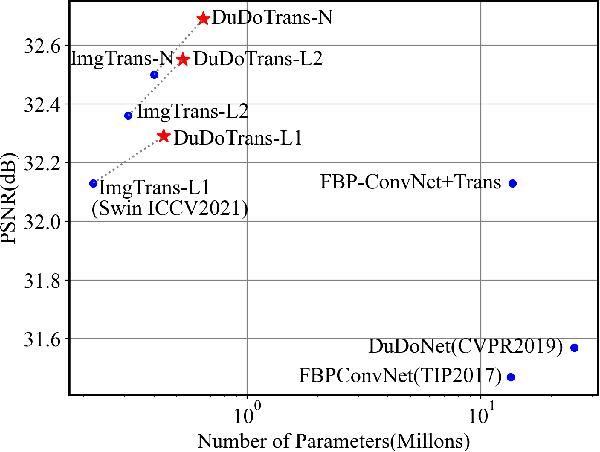
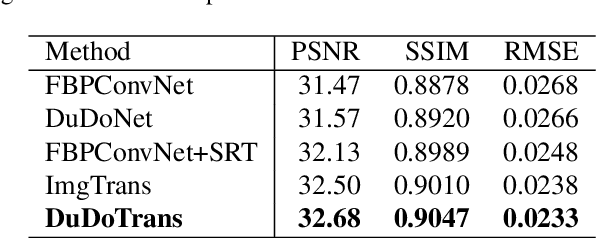
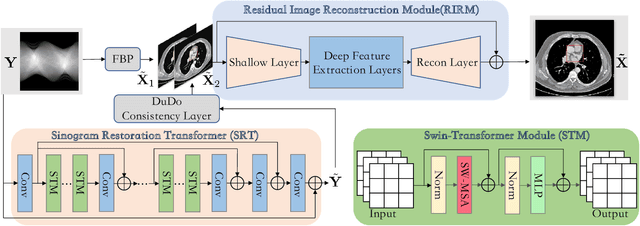
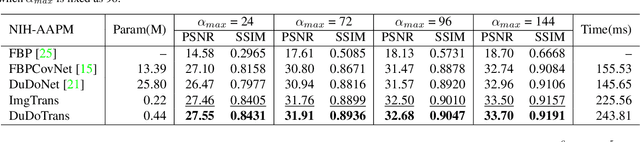
While Computed Tomography (CT) reconstruction from X-ray sinograms is necessary for clinical diagnosis, iodine radiation in the imaging process induces irreversible injury, thereby driving researchers to study sparse-view CT reconstruction, that is, recovering a high-quality CT image from a sparse set of sinogram views. Iterative models are proposed to alleviate the appeared artifacts in sparse-view CT images, but the computation cost is too expensive. Then deep-learning-based methods have gained prevalence due to the excellent performances and lower computation. However, these methods ignore the mismatch between the CNN's \textbf{local} feature extraction capability and the sinogram's \textbf{global} characteristics. To overcome the problem, we propose \textbf{Du}al-\textbf{Do}main \textbf{Trans}former (\textbf{DuDoTrans}) to simultaneously restore informative sinograms via the long-range dependency modeling capability of Transformer and reconstruct CT image with both the enhanced and raw sinograms. With such a novel design, reconstruction performance on the NIH-AAPM dataset and COVID-19 dataset experimentally confirms the effectiveness and generalizability of DuDoTrans with fewer involved parameters. Extensive experiments also demonstrate its robustness with different noise-level scenarios for sparse-view CT reconstruction. The code and models are publicly available at https://github.com/DuDoTrans/CODE
Improving Depth Estimation using Location Information
Dec 27, 2021
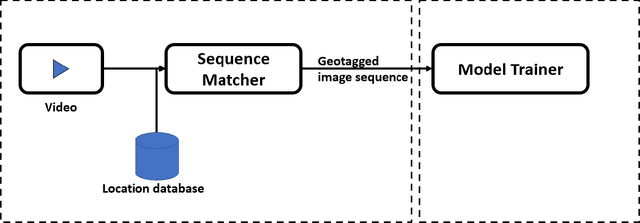
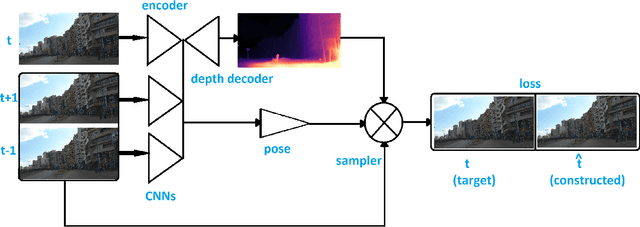
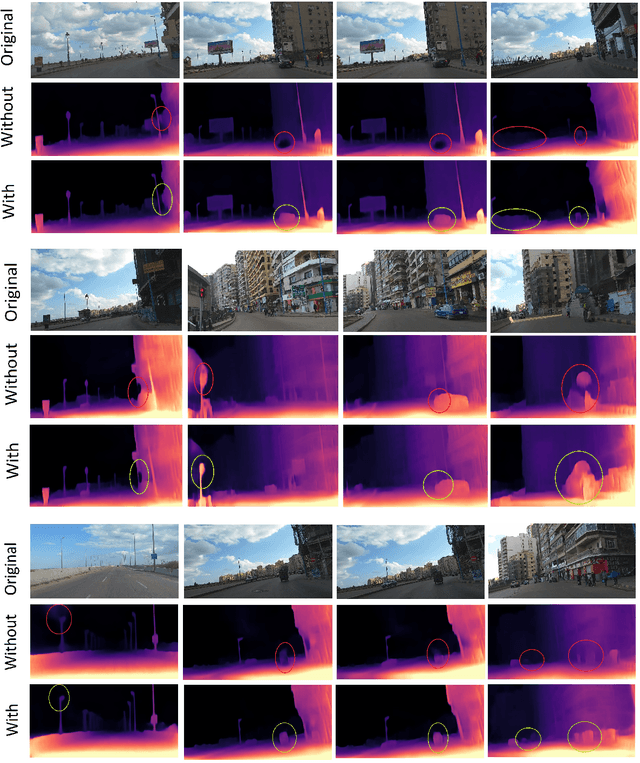
The ability to accurately estimate depth information is crucial for many autonomous applications to recognize the surrounded environment and predict the depth of important objects. One of the most recently used techniques is monocular depth estimation where the depth map is inferred from a single image. This paper improves the self-supervised deep learning techniques to perform accurate generalized monocular depth estimation. The main idea is to train the deep model to take into account a sequence of the different frames, each frame is geotagged with its location information. This makes the model able to enhance depth estimation given area semantics. We demonstrate the effectiveness of our model to improve depth estimation results. The model is trained in a realistic environment and the results show improvements in the depth map after adding the location data to the model training phase.
Sentiment Analysis of Fashion Related Posts in Social Media
Nov 15, 2021
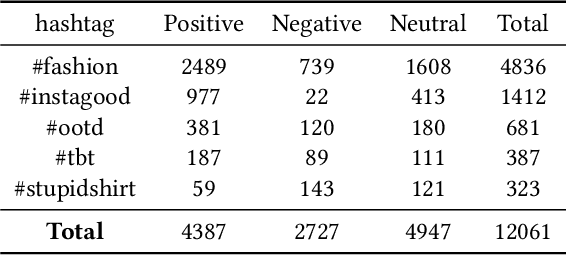
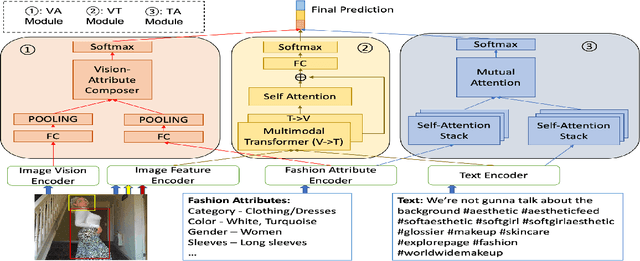
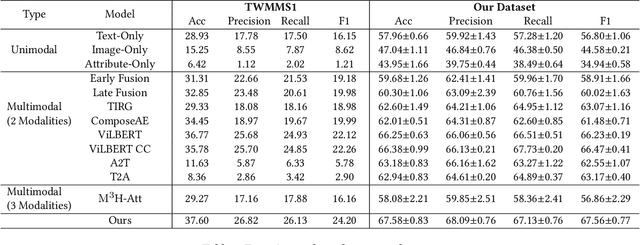
The role of social media in fashion industry has been blooming as the years have continued on. In this work, we investigate sentiment analysis for fashion related posts in social media platforms. There are two main challenges of this task. On the first place, information of different modalities must be jointly considered to make the final predictions. On the second place, some unique fashion related attributes should be taken into account. While most existing works focus on traditional multimodal sentiment analysis, they always fail to exploit the fashion related attributes in this task. We propose a novel framework that jointly leverages the image vision, post text, as well as fashion attribute modality to determine the sentiment category. One characteristic of our model is that it extracts fashion attributes and integrates them with the image vision information for effective representation. Furthermore, it exploits the mutual relationship between the fashion attributes and the post texts via a mutual attention mechanism. Since there is no existing dataset suitable for this task, we prepare a large-scale sentiment analysis dataset of over 12k fashion related social media posts. Extensive experiments are conducted to demonstrate the effectiveness of our model.
Self-Supervision based Task-Specific Image Collection Summarization
Dec 19, 2020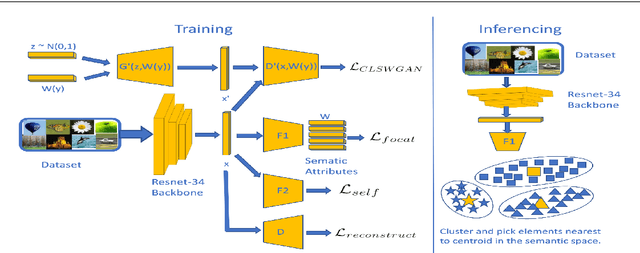
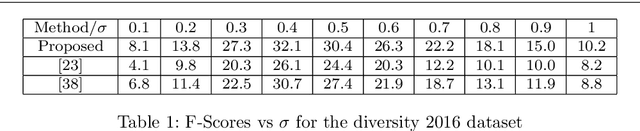
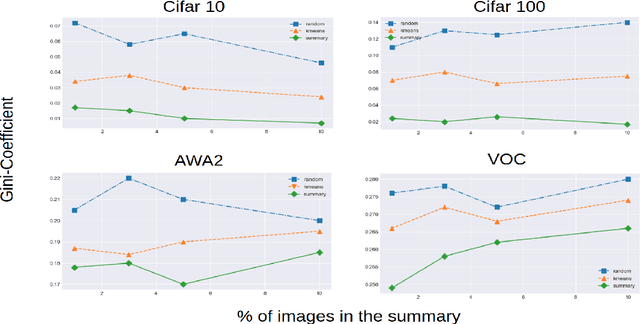
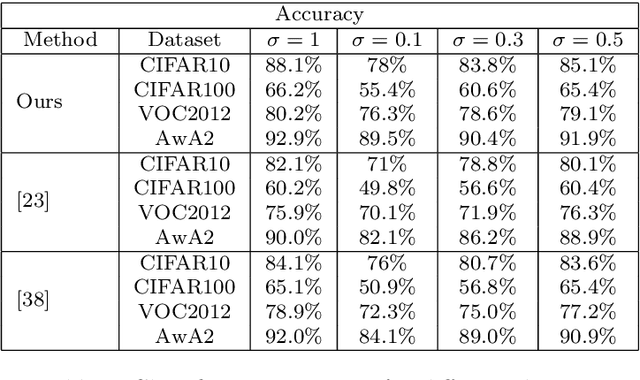
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
Virtual Adversarial Training for Semi-supervised Breast Mass Classification
Jan 25, 2022This study aims to develop a novel computer-aided diagnosis (CAD) scheme for mammographic breast mass classification using semi-supervised learning. Although supervised deep learning has achieved huge success across various medical image analysis tasks, its success relies on large amounts of high-quality annotations, which can be challenging to acquire in practice. To overcome this limitation, we propose employing a semi-supervised method, i.e., virtual adversarial training (VAT), to leverage and learn useful information underlying in unlabeled data for better classification of breast masses. Accordingly, our VAT-based models have two types of losses, namely supervised and virtual adversarial losses. The former loss acts as in supervised classification, while the latter loss aims at enhancing model robustness against virtual adversarial perturbation, thus improving model generalizability. To evaluate the performance of our VAT-based CAD scheme, we retrospectively assembled a total of 1024 breast mass images, with equal number of benign and malignant masses. A large CNN and a small CNN were used in this investigation, and both were trained with and without the adversarial loss. When the labeled ratios were 40% and 80%, VAT-based CNNs delivered the highest classification accuracy of 0.740 and 0.760, respectively. The experimental results suggest that the VAT-based CAD scheme can effectively utilize meaningful knowledge from unlabeled data to better classify mammographic breast mass images.
Twitter-COMMs: Detecting Climate, COVID, and Military Multimodal Misinformation
Dec 16, 2021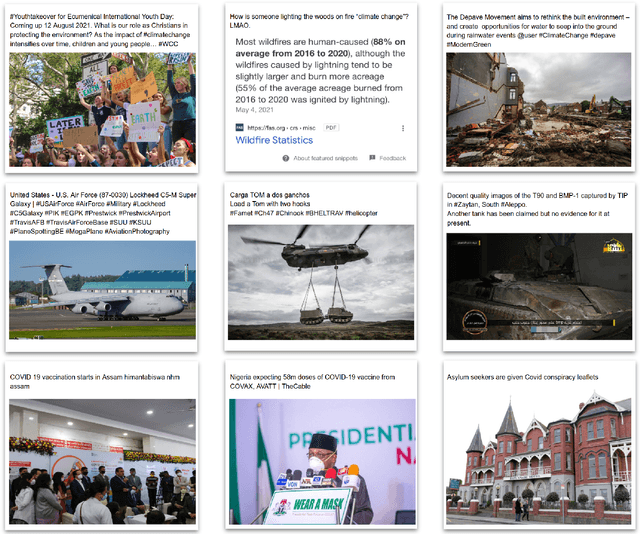
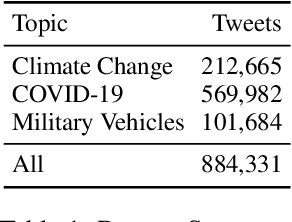
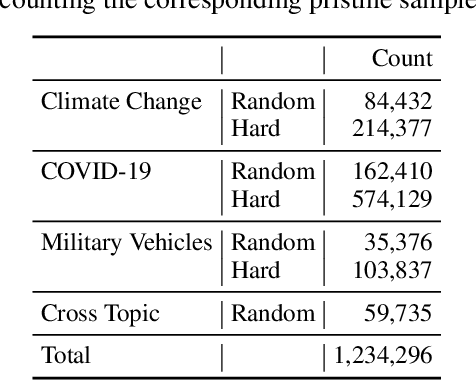

Detecting out-of-context media, such as "miscaptioned" images on Twitter, often requires detecting inconsistencies between the two modalities. This paper describes our approach to the Image-Text Inconsistency Detection challenge of the DARPA Semantic Forensics (SemaFor) Program. First, we collect Twitter-COMMs, a large-scale multimodal dataset with 884k tweets relevant to the topics of Climate Change, COVID-19, and Military Vehicles. We train our approach, based on the state-of-the-art CLIP model, leveraging automatically generated random and hard negatives. Our method is then tested on a hidden human-generated evaluation set. We achieve the best result on the program leaderboard, with 11% detection improvement in a high precision regime over a zero-shot CLIP baseline.
CropDefender: deep watermark which is more convenient to train and more robust against cropping
Sep 12, 2021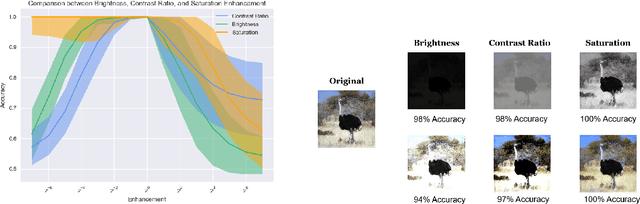
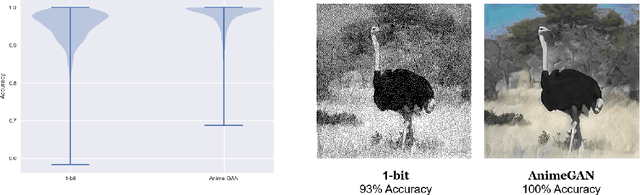
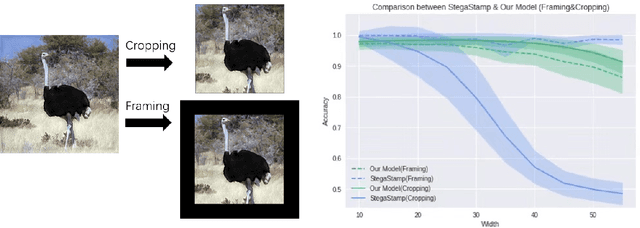
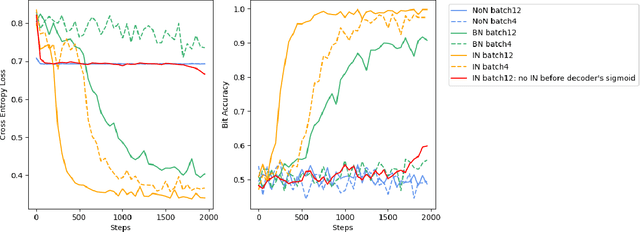
Digital image watermarking, which is a technique for invisibly embedding information into an image, is used in fields such as property rights protection. In recent years, some research has proposed the use of neural networks to add watermarks to natural images. We take StegaStamp as an example for our research. Whether facing traditional image editing methods, such as brightness, contrast, saturation adjustment, or style change like 1-bit conversion, GAN, StegaStamp has robustness far beyond traditional watermarking techniques, but it still has two drawbacks: it is vulnerable to cropping and is hard to train. We found that the causes of vulnerability to cropping is not the loss of information on the edge, but the movement of watermark position. By explicitly introducing the perturbation of cropping into the training, the cropping resistance is significantly improved. For the problem of difficult training, we introduce instance normalization to solve the vanishing gradient, set losses' weights as learnable parameters to reduce the number of hyperparameters, and use sigmoid to restrict pixel values of the generated image.
EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection
Jul 17, 2020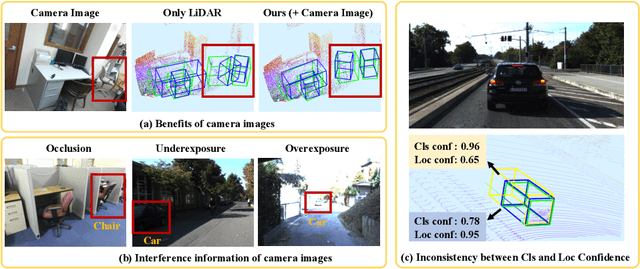
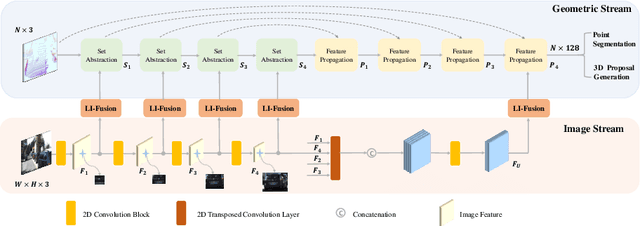
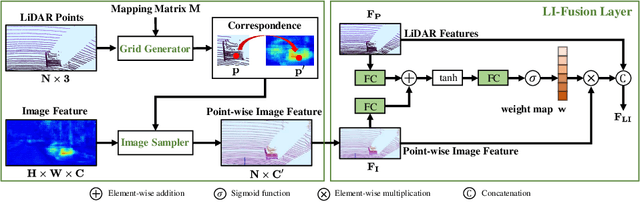

In this paper, we aim at addressing two critical issues in the 3D detection task, including the exploitation of multiple sensors~(namely LiDAR point cloud and camera image), as well as the inconsistency between the localization and classification confidence. To this end, we propose a novel fusion module to enhance the point features with semantic image features in a point-wise manner without any image annotations. Besides, a consistency enforcing loss is employed to explicitly encourage the consistency of both the localization and classification confidence. We design an end-to-end learnable framework named EPNet to integrate these two components. Extensive experiments on the KITTI and SUN-RGBD datasets demonstrate the superiority of EPNet over the state-of-the-art methods. Codes and models are available at: \url{https://github.com/happinesslz/EPNet}.