 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Radon cumulative distribution transform subspace modeling for image classification
Apr 07, 2020
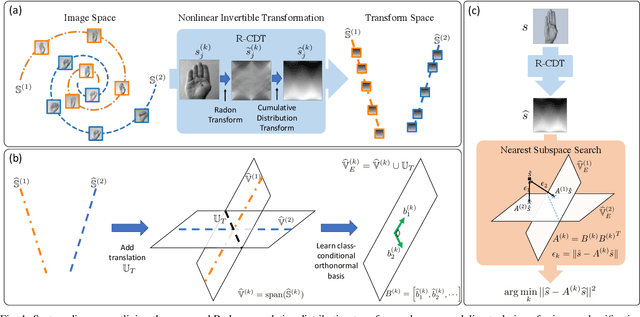
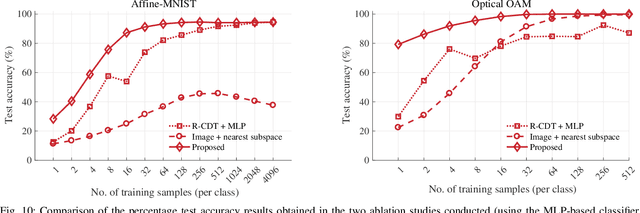
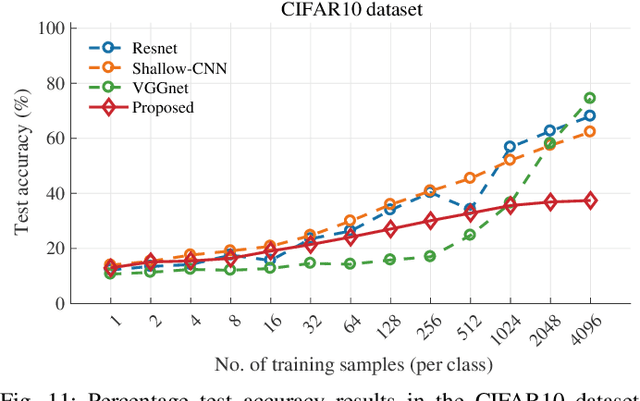
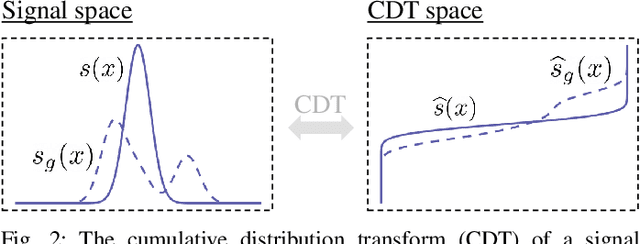
We present a new supervised image classification method for problems where the data at hand conform to certain deformation models applied to unknown prototypes or templates. The method makes use of the previously described Radon Cumulative Distribution Transform (R-CDT) for image data, whose mathematical properties are exploited to express the image data in a form that is more suitable for machine learning. While certain operations such as translation, scaling, and higher-order transformations are challenging to model in native image space, we show the R-CDT can capture some of these variations and thus render the associated image classification problems easier to solve. The method is simple to implement, non-iterative, has no hyper-parameters to tune, it is computationally efficient, and provides competitive accuracies to state-of-the-art neural networks for many types of classification problems, especially in a learning with few labels setting. Furthermore, we show improvements with respect to neural network-based methods in terms of computational efficiency (it can be implemented without the use of GPUs), number of training samples needed for training, as well as out-of-distribution generalization. The Python code for reproducing our results is available at https://github.com/rohdelab/rcdt_ns_classifier.
A Full-Image Full-Resolution End-to-End-Trainable CNN Framework for Image Forgery Detection
Sep 15, 2019



Due to limited computational and memory resources, current deep learning models accept only rather small images in input, calling for preliminary image resizing. This is not a problem for high-level vision problems, where discriminative features are barely affected by resizing. On the contrary, in image forensics, resizing tends to destroy precious high-frequency details, impacting heavily on performance. One can avoid resizing by means of patch-wise processing, at the cost of renouncing whole-image analysis. In this work, we propose a CNN-based image forgery detection framework which makes decisions based on full-resolution information gathered from the whole image. Thanks to gradient checkpointing, the framework is trainable end-to-end with limited memory resources and weak (image-level) supervision, allowing for the joint optimization of all parameters. Experiments on widespread image forensics datasets prove the good performance of the proposed approach, which largely outperforms all baselines and all reference methods.
AnANet: Modeling Association and Alignment for Cross-modal Correlation Classification
Sep 02, 2021
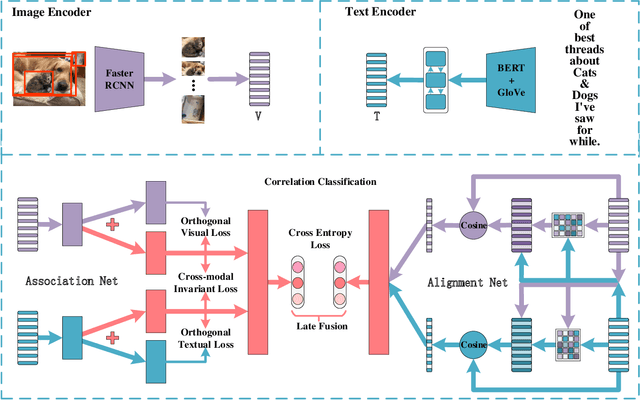

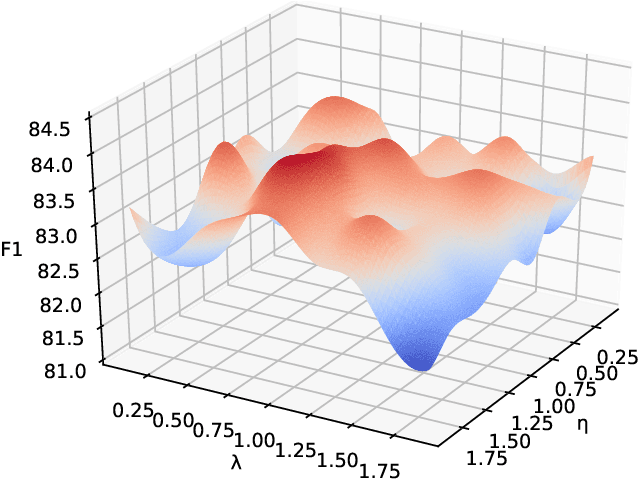
The explosive increase of multimodal data makes a great demand in many cross-modal applications that follow the strict prior related assumption. Thus researchers study the definition of cross-modal correlation category and construct various classification systems and predictive models. However, those systems pay more attention to the fine-grained relevant types of cross-modal correlation, ignoring lots of implicit relevant data which are often divided into irrelevant types. What's worse is that none of previous predictive models manifest the essence of cross-modal correlation according to their definition at the modeling stage. In this paper, we present a comprehensive analysis of the image-text correlation and redefine a new classification system based on implicit association and explicit alignment. To predict the type of image-text correlation, we propose the Association and Alignment Network according to our proposed definition (namely AnANet) which implicitly represents the global discrepancy and commonality between image and text and explicitly captures the cross-modal local relevance. The experimental results on our constructed new image-text correlation dataset show the effectiveness of our model.
COVID-19 Deterioration Prediction via Self-Supervised Representation Learning and Multi-Image Prediction
Jan 13, 2021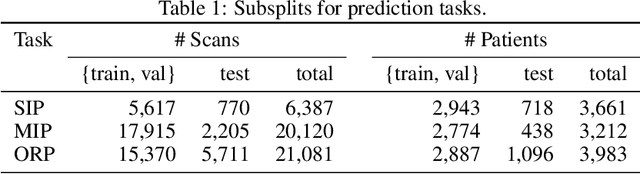
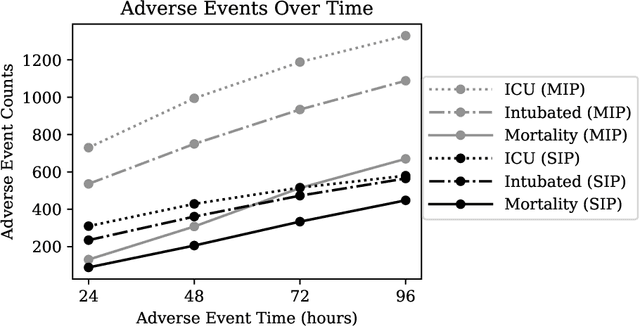
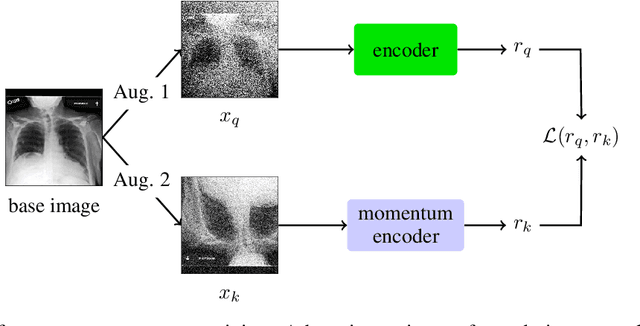
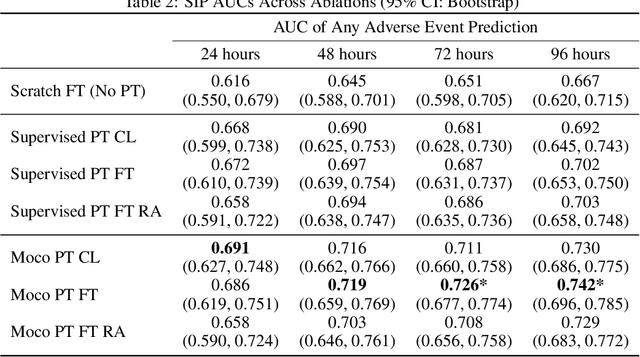
The rapid spread of COVID-19 cases in recent months has strained hospital resources, making rapid and accurate triage of patients presenting to emergency departments a necessity. Machine learning techniques using clinical data such as chest X-rays have been used to predict which patients are most at risk of deterioration. We consider the task of predicting two types of patient deterioration based on chest X-rays: adverse event deterioration (i.e., transfer to the intensive care unit, intubation, or mortality) and increased oxygen requirements beyond 6 L per day. Due to the relative scarcity of COVID-19 patient data, existing solutions leverage supervised pretraining on related non-COVID images, but this is limited by the differences between the pretraining data and the target COVID-19 patient data. In this paper, we use self-supervised learning based on the momentum contrast (MoCo) method in the pretraining phase to learn more general image representations to use for downstream tasks. We present three results. The first is deterioration prediction from a single image, where our model achieves an area under receiver operating characteristic curve (AUC) of 0.742 for predicting an adverse event within 96 hours (compared to 0.703 with supervised pretraining) and an AUC of 0.765 for predicting oxygen requirements greater than 6 L a day at 24 hours (compared to 0.749 with supervised pretraining). We then propose a new transformer-based architecture that can process sequences of multiple images for prediction and show that this model can achieve an improved AUC of 0.786 for predicting an adverse event at 96 hours and an AUC of 0.848 for predicting mortalities at 96 hours. A small pilot clinical study suggested that the prediction accuracy of our model is comparable to that of experienced radiologists analyzing the same information.
Longitudinal Image Registration with Temporal-order and Subject-specificity Discrimination
Aug 29, 2020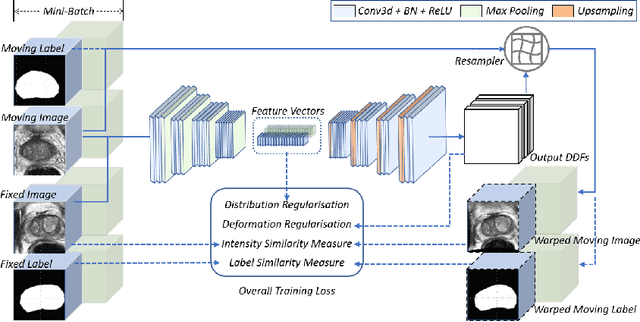

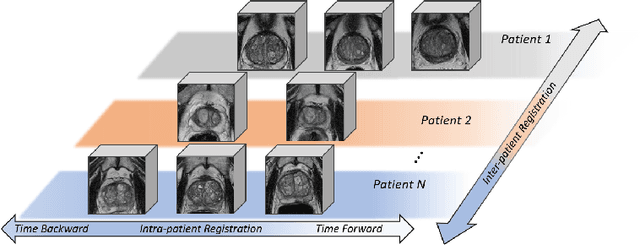
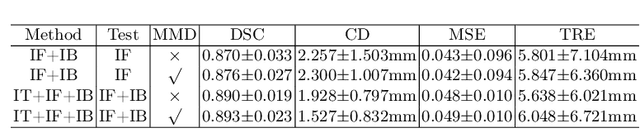
Morphological analysis of longitudinal MR images plays a key role in monitoring disease progression for prostate cancer patients, who are placed under an active surveillance program. In this paper, we describe a learning-based image registration algorithm to quantify changes on regions of interest between a pair of images from the same patient, acquired at two different time points. Combining intensity-based similarity and gland segmentation as weak supervision, the population-data-trained registration networks significantly lowered the target registration errors (TREs) on holdout patient data, compared with those before registration and those from an iterative registration algorithm. Furthermore, this work provides a quantitative analysis on several longitudinal-data-sampling strategies and, in turn, we propose a novel regularisation method based on maximum mean discrepancy, between differently-sampled training image pairs. Based on 216 3D MR images from 86 patients, we report a mean TRE of 5.6 mm and show statistically significant differences between the different training data sampling strategies.
Practical Evaluation of Out-of-Distribution Detection Methods for Image Classification
Jan 07, 2021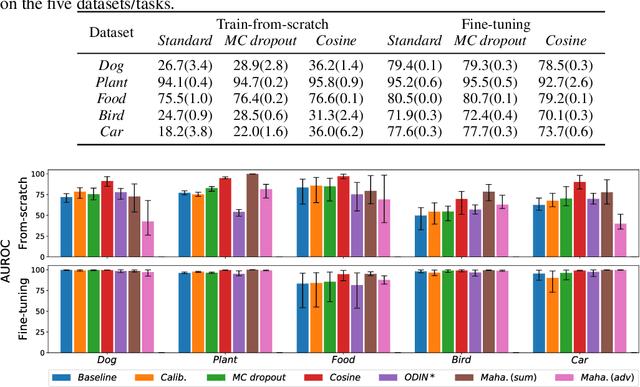
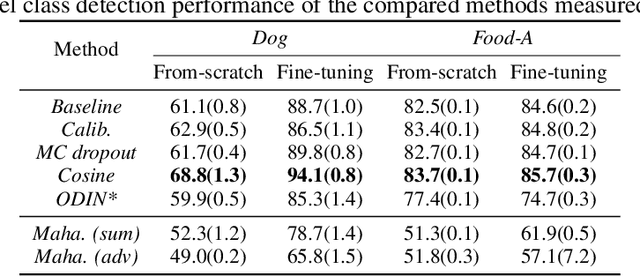
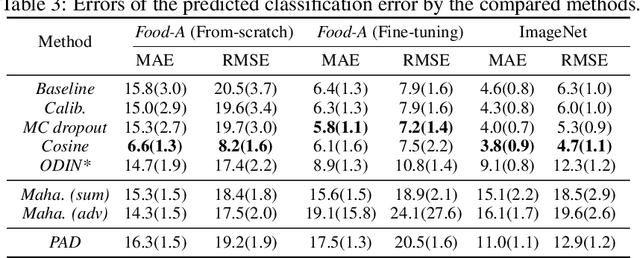
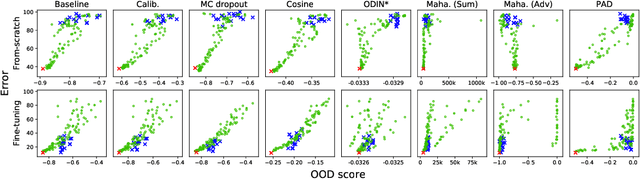
We reconsider the evaluation of OOD detection methods for image recognition. Although many studies have been conducted so far to build better OOD detection methods, most of them follow Hendrycks and Gimpel's work for the method of experimental evaluation. While the unified evaluation method is necessary for a fair comparison, there is a question of if its choice of tasks and datasets reflect real-world applications and if the evaluation results can generalize to other OOD detection application scenarios. In this paper, we experimentally evaluate the performance of representative OOD detection methods for three scenarios, i.e., irrelevant input detection, novel class detection, and domain shift detection, on various datasets and classification tasks. The results show that differences in scenarios and datasets alter the relative performance among the methods. Our results can also be used as a guide for practitioners for the selection of OOD detection methods.
Get Fooled for the Right Reason: Improving Adversarial Robustness through a Teacher-guided Curriculum Learning Approach
Oct 30, 2021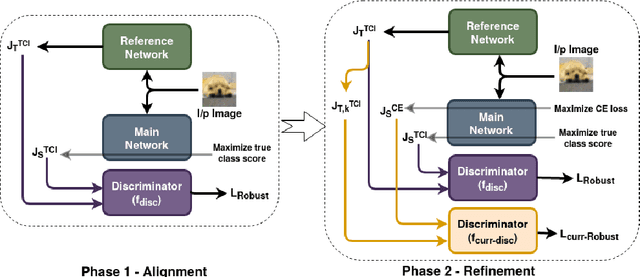
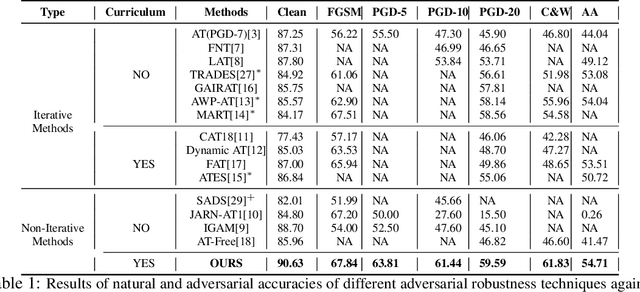
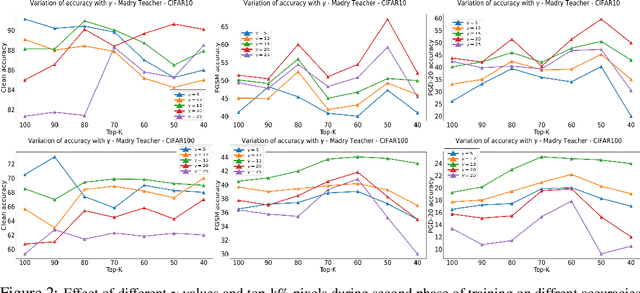
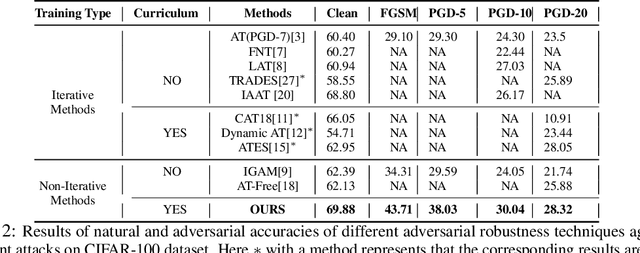
Current SOTA adversarially robust models are mostly based on adversarial training (AT) and differ only by some regularizers either at inner maximization or outer minimization steps. Being repetitive in nature during the inner maximization step, they take a huge time to train. We propose a non-iterative method that enforces the following ideas during training. Attribution maps are more aligned to the actual object in the image for adversarially robust models compared to naturally trained models. Also, the allowed set of pixels to perturb an image (that changes model decision) should be restricted to the object pixels only, which reduces the attack strength by limiting the attack space. Our method achieves significant performance gains with a little extra effort (10-20%) over existing AT models and outperforms all other methods in terms of adversarial as well as natural accuracy. We have performed extensive experimentation with CIFAR-10, CIFAR-100, and TinyImageNet datasets and reported results against many popular strong adversarial attacks to prove the effectiveness of our method.
Deep Reparametrization of Multi-Frame Super-Resolution and Denoising
Aug 18, 2021
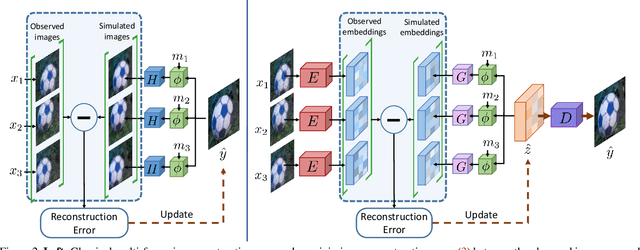


We propose a deep reparametrization of the maximum a posteriori formulation commonly employed in multi-frame image restoration tasks. Our approach is derived by introducing a learned error metric and a latent representation of the target image, which transforms the MAP objective to a deep feature space. The deep reparametrization allows us to directly model the image formation process in the latent space, and to integrate learned image priors into the prediction. Our approach thereby leverages the advantages of deep learning, while also benefiting from the principled multi-frame fusion provided by the classical MAP formulation. We validate our approach through comprehensive experiments on burst denoising and burst super-resolution datasets. Our approach sets a new state-of-the-art for both tasks, demonstrating the generality and effectiveness of the proposed formulation.
Understanding of Emotion Perception from Art
Oct 13, 2021
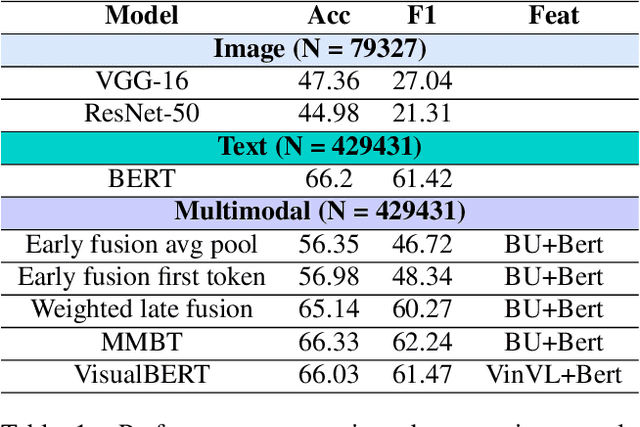

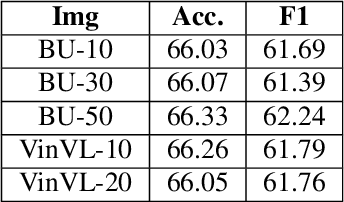
Computational modeling of the emotions evoked by art in humans is a challenging problem because of the subjective and nuanced nature of art and affective signals. In this paper, we consider the above-mentioned problem of understanding emotions evoked in viewers by artwork using both text and visual modalities. Specifically, we analyze images and the accompanying text captions from the viewers expressing emotions as a multimodal classification task. Our results show that single-stream multimodal transformer-based models like MMBT and VisualBERT perform better compared to both image-only models and dual-stream multimodal models having separate pathways for text and image modalities. We also observe improvements in performance for extreme positive and negative emotion classes, when a single-stream model like MMBT is compared with a text-only transformer model like BERT.
Enabling Deep Learning on Edge Devices through Filter Pruning and Knowledge Transfer
Jan 22, 2022Deep learning models have introduced various intelligent applications to edge devices, such as image classification, speech recognition, and augmented reality. There is an increasing need of training such models on the devices in order to deliver personalized, responsive, and private learning. To address this need, this paper presents a new solution for deploying and training state-of-the-art models on the resource-constrained devices. First, the paper proposes a novel filter-pruning-based model compression method to create lightweight trainable models from large models trained in the cloud, without much loss of accuracy. Second, it proposes a novel knowledge transfer method to enable the on-device model to update incrementally in real time or near real time using incremental learning on new data and enable the on-device model to learn the unseen categories with the help of the in-cloud model in an unsupervised fashion. The results show that 1) our model compression method can remove up to 99.36% parameters of WRN-28-10, while preserving a Top-1 accuracy of over 90% on CIFAR-10; 2) our knowledge transfer method enables the compressed models to achieve more than 90% accuracy on CIFAR-10 and retain good accuracy on old categories; 3) it allows the compressed models to converge within real time (three to six minutes) on the edge for incremental learning tasks; 4) it enables the model to classify unseen categories of data (78.92% Top-1 accuracy) that it is never trained with.