 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Zoom-to-Inpaint: Image Inpainting with High Frequency Details
Dec 17, 2020


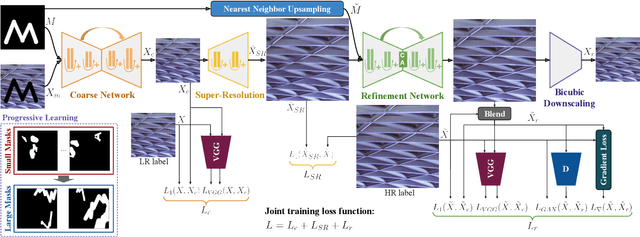
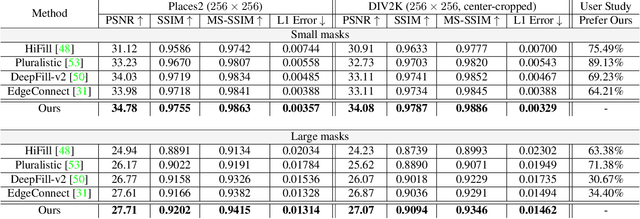
Although deep learning has enabled a huge leap forward in image inpainting, current methods are often unable to synthesize realistic high-frequency details. In this paper, we propose applying super resolution to coarsely reconstructed outputs, refining them at high resolution, and then downscaling the output to the original resolution. By introducing high-resolution images to the refinement network, our framework is able to reconstruct finer details that are usually smoothed out due to spectral bias - the tendency of neural networks to reconstruct low frequencies better than high frequencies. To assist training the refinement network on large upscaled holes, we propose a progressive learning technique in which the size of the missing regions increases as training progresses. Our zoom-in, refine and zoom-out strategy, combined with high-resolution supervision and progressive learning, constitutes a framework-agnostic approach for enhancing high-frequency details that can be applied to other inpainting methods. We provide qualitative and quantitative evaluations along with an ablation analysis to show the effectiveness of our approach, which outperforms state-of-the-art inpainting methods.
On Evaluation Metrics for Graph Generative Models
Jan 24, 2022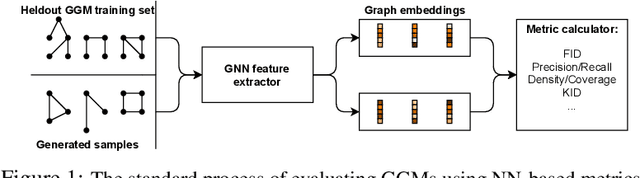
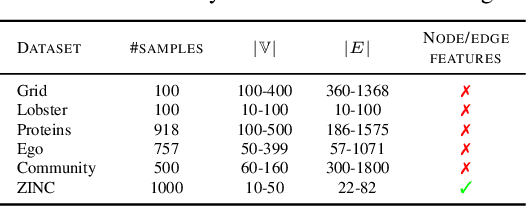
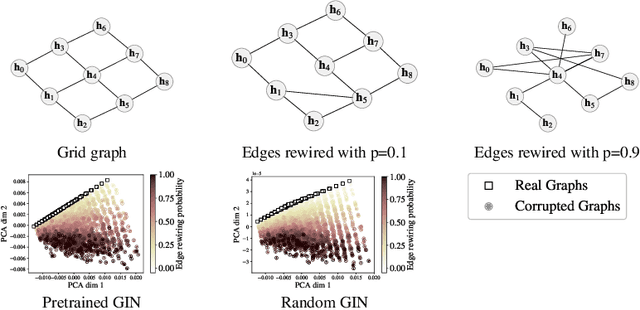

In image generation, generative models can be evaluated naturally by visually inspecting model outputs. However, this is not always the case for graph generative models (GGMs), making their evaluation challenging. Currently, the standard process for evaluating GGMs suffers from three critical limitations: i) it does not produce a single score which makes model selection challenging, ii) in many cases it fails to consider underlying edge and node features, and iii) it is prohibitively slow to perform. In this work, we mitigate these issues by searching for scalar, domain-agnostic, and scalable metrics for evaluating and ranking GGMs. To this end, we study existing GGM metrics and neural-network-based metrics emerging from generative models of images that use embeddings extracted from a task-specific network. Motivated by the power of certain Graph Neural Networks (GNNs) to extract meaningful graph representations without any training, we introduce several metrics based on the features extracted by an untrained random GNN. We design experiments to thoroughly test metrics on their ability to measure the diversity and fidelity of generated graphs, as well as their sample and computational efficiency. Depending on the quantity of samples, we recommend one of two random-GNN-based metrics that we show to be more expressive than pre-existing metrics. While we focus on applying these metrics to GGM evaluation, in practice this enables the ability to easily compute the dissimilarity between any two sets of graphs regardless of domain. Our code is released at: https://github.com/uoguelph-mlrg/GGM-metrics.
AnANet: Modeling Association and Alignment for Cross-modal Correlation Classification
Sep 02, 2021
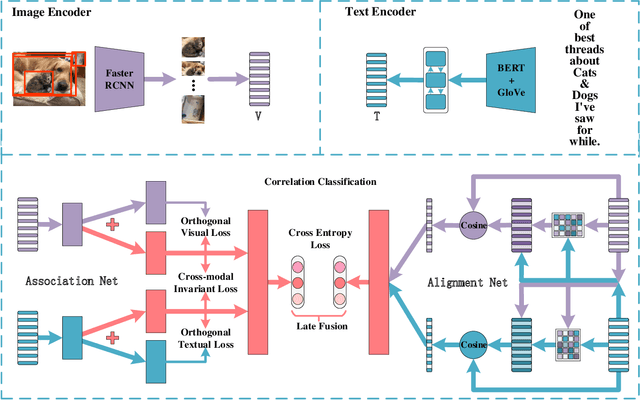

The explosive increase of multimodal data makes a great demand in many cross-modal applications that follow the strict prior related assumption. Thus researchers study the definition of cross-modal correlation category and construct various classification systems and predictive models. However, those systems pay more attention to the fine-grained relevant types of cross-modal correlation, ignoring lots of implicit relevant data which are often divided into irrelevant types. What's worse is that none of previous predictive models manifest the essence of cross-modal correlation according to their definition at the modeling stage. In this paper, we present a comprehensive analysis of the image-text correlation and redefine a new classification system based on implicit association and explicit alignment. To predict the type of image-text correlation, we propose the Association and Alignment Network according to our proposed definition (namely AnANet) which implicitly represents the global discrepancy and commonality between image and text and explicitly captures the cross-modal local relevance. The experimental results on our constructed new image-text correlation dataset show the effectiveness of our model.
Scientific Image Restoration Anywhere
Nov 12, 2019

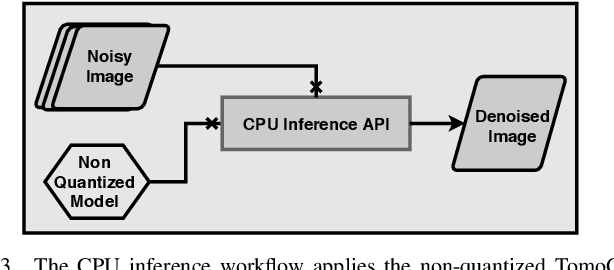
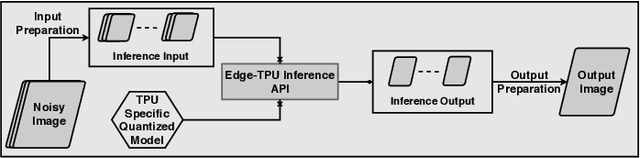
The use of deep learning models within scientific experimental facilities frequently requires low-latency inference, so that, for example, quality control operations can be performed while data are being collected. Edge computing devices can be useful in this context, as their low cost and compact form factor permit them to be co-located with the experimental apparatus. Can such devices, with their limited resources, can perform neural network feed-forward computations efficiently and effectively? We explore this question by evaluating the performance and accuracy of a scientific image restoration model, for which both model input and output are images, on edge computing devices. Specifically, we evaluate deployments of TomoGAN, an image-denoising model based on generative adversarial networks developed for low-dose x-ray imaging, on the Google Edge TPU and NVIDIA Jetson. We adapt TomoGAN for edge execution, evaluate model inference performance, and propose methods to address the accuracy drop caused by model quantization. We show that these edge computing devices can deliver accuracy comparable to that of a full-fledged CPU or GPU model, at speeds that are more than adequate for use in the intended deployments, denoising a 1024 x 1024 image in less than a second. Our experiments also show that the Edge TPU models can provide 3x faster inference response than a CPU-based model and 1.5x faster than an edge GPU-based model. This combination of high speed and low cost permits image restoration anywhere.
Locally Invariant Explanations: Towards Stable and Unidirectional Explanations through Local Invariant Learning
Jan 28, 2022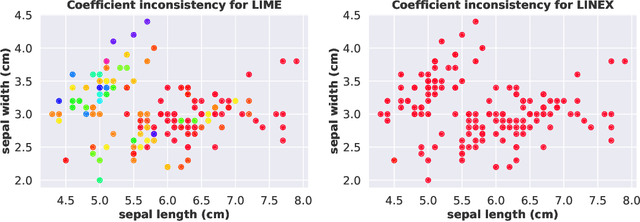



Locally interpretable model agnostic explanations (LIME) method is one of the most popular methods used to explain black-box models at a per example level. Although many variants have been proposed, few provide a simple way to produce high fidelity explanations that are also stable and intuitive. In this work, we provide a novel perspective by proposing a model agnostic local explanation method inspired by the invariant risk minimization (IRM) principle -- originally proposed for (global) out-of-distribution generalization -- to provide such high fidelity explanations that are also stable and unidirectional across nearby examples. Our method is based on a game theoretic formulation where we theoretically show that our approach has a strong tendency to eliminate features where the gradient of the black-box function abruptly changes sign in the locality of the example we want to explain, while in other cases it is more careful and will choose a more conservative (feature) attribution, a behavior which can be highly desirable for recourse. Empirically, we show on tabular, image and text data that the quality of our explanations with neighborhoods formed using random perturbations are much better than LIME and in some cases even comparable to other methods that use realistic neighbors sampled from the data manifold. This is desirable given that learning a manifold to either create realistic neighbors or to project explanations is typically expensive or may even be impossible. Moreover, our algorithm is simple and efficient to train, and can ascertain stable input features for local decisions of a black-box without access to side information such as a (partial) causal graph as has been seen in some recent works.
Dual Path Learning for Domain Adaptation of Semantic Segmentation
Aug 13, 2021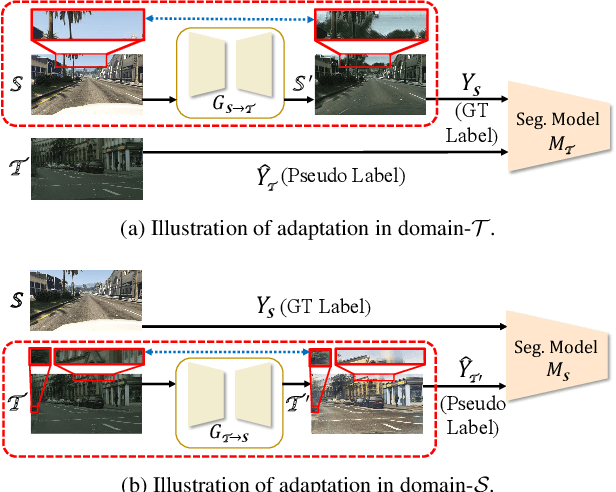
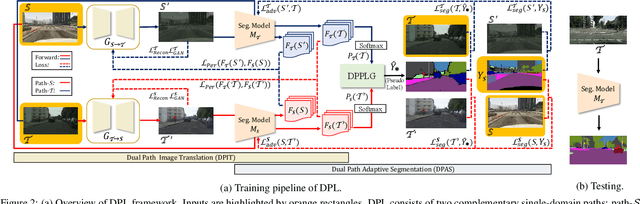
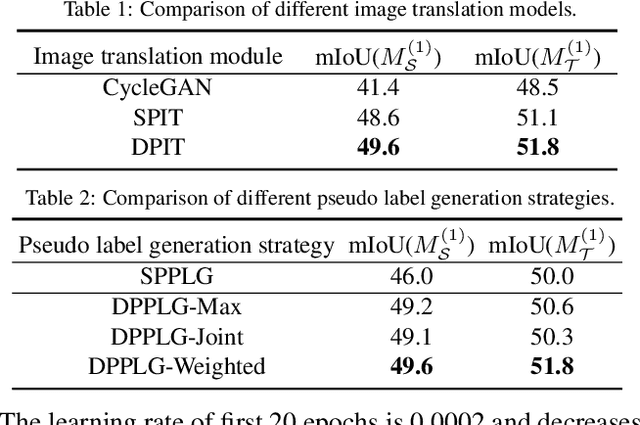
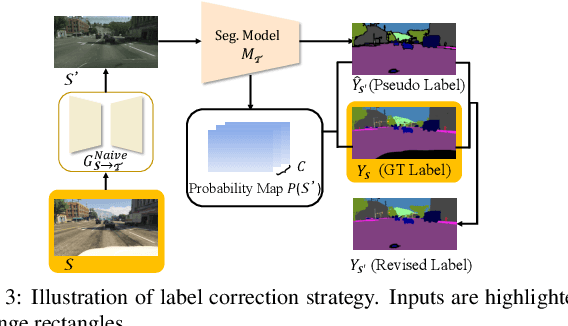
Domain adaptation for semantic segmentation enables to alleviate the need for large-scale pixel-wise annotations. Recently, self-supervised learning (SSL) with a combination of image-to-image translation shows great effectiveness in adaptive segmentation. The most common practice is to perform SSL along with image translation to well align a single domain (the source or target). However, in this single-domain paradigm, unavoidable visual inconsistency raised by image translation may affect subsequent learning. In this paper, based on the observation that domain adaptation frameworks performed in the source and target domain are almost complementary in terms of image translation and SSL, we propose a novel dual path learning (DPL) framework to alleviate visual inconsistency. Concretely, DPL contains two complementary and interactive single-domain adaptation pipelines aligned in source and target domain respectively. The inference of DPL is extremely simple, only one segmentation model in the target domain is employed. Novel technologies such as dual path image translation and dual path adaptive segmentation are proposed to make two paths promote each other in an interactive manner. Experiments on GTA5$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes scenarios demonstrate the superiority of our DPL model over the state-of-the-art methods. The code and models are available at: \url{https://github.com/royee182/DPL}
Spectral analysis of re-parameterized light fields
Oct 12, 2021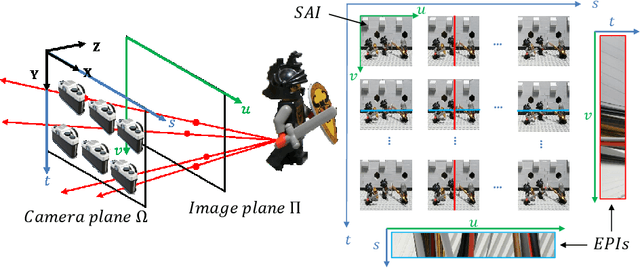
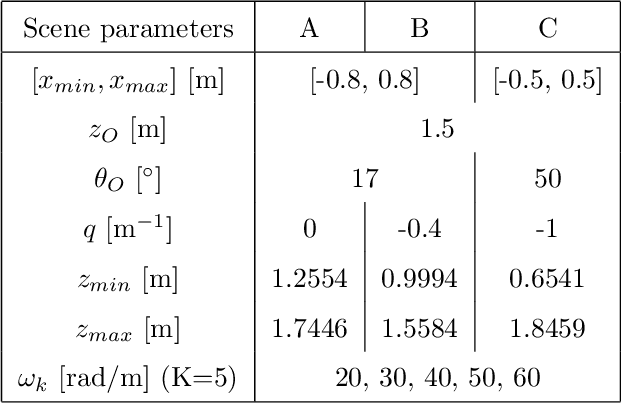
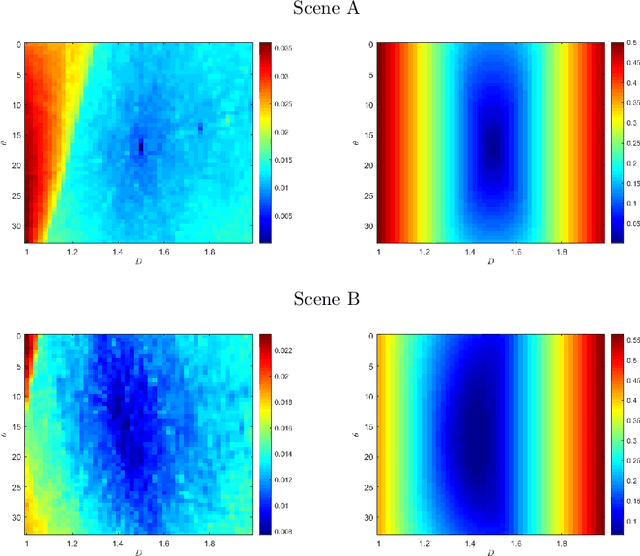
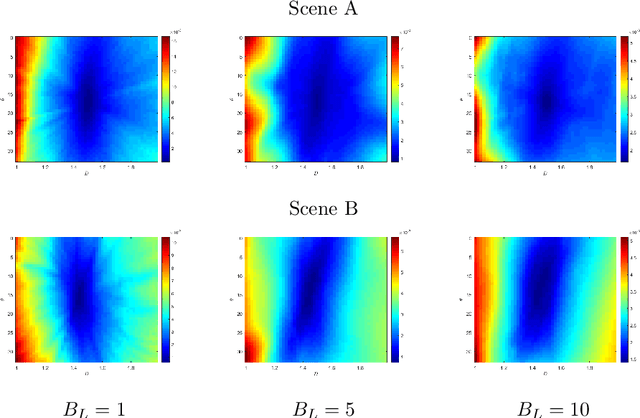
In this paper, we study the spectral properties of re-parameterized light field. Following previous studies of the light field spectrum, which notably provided sampling guidelines, we focus on the two plane parameterization of the light field. However, we introduce additional flexibility by allowing the image plane to be tilted and not only parallel. A formal theoretical analysis is first presented, which shows that more flexible sampling guidelines (i.e. wider camera baselines) can be used to sample the light field when adapting the image plane orientation to the scene geometry. We then present our simulations and results to support these theoretical findings. While the work introduced in this paper is mostly theoretical, we believe these new findings open exciting avenues for more practical application of light fields, such as view synthesis or compact representation.
Image Reconstruction of Static and Dynamic Scenes through Anisoplanatic Turbulence
Aug 31, 2020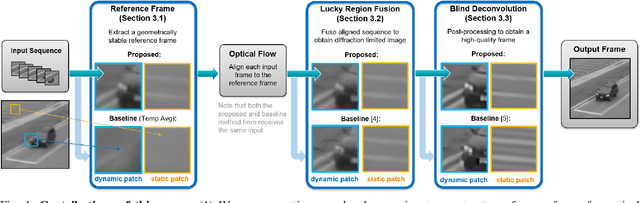
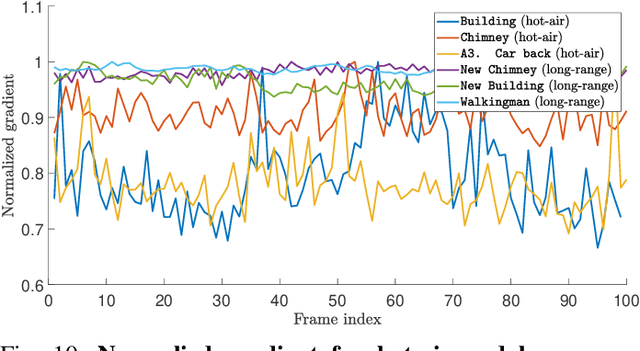
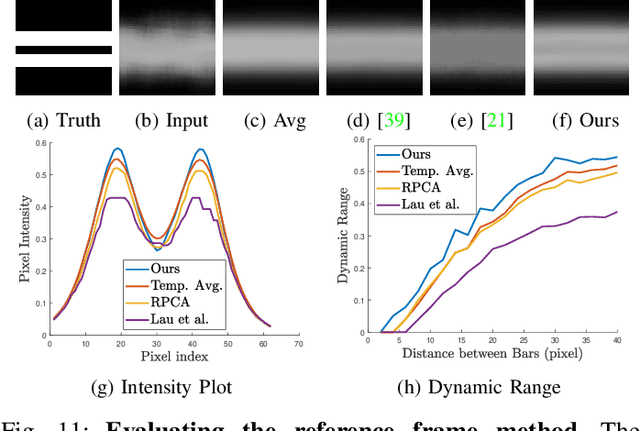

Ground based long-range passive imaging systems often suffer from degraded image quality due to a turbulent atmosphere. While methods exist for removing such turbulent distortions, many are limited to static sequences which cannot be extended to dynamic scenes. In addition, the physics of the turbulence is often not integrated into the image reconstruction algorithms, making the physics foundations of the methods weak. In this paper, we present a unified method for atmospheric turbulence mitigation in both static and dynamic sequences. We are able to achieve better results compared to existing methods by utilizing (i) a novel space-time non-local averaging method to construct a reliable reference frame, (ii) a geometric consistency and a sharpness metric to generate the lucky frame, (iii) a physics-constrained prior model of the point spread function for blind deconvolution. Experimental results based on synthetic and real long-range turbulence sequences validate the performance of the proposed method.
Diagram Image Retrieval using Sketch-Based Deep Learning and Transfer Learning
Apr 22, 2020
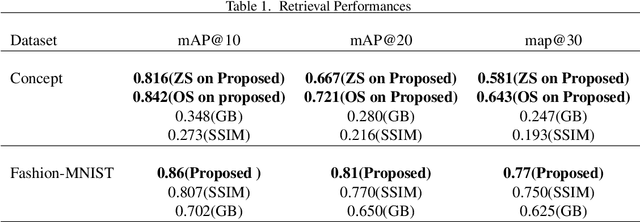

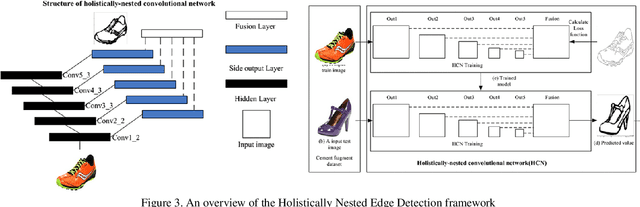
Resolution of the complex problem of image retrieval for diagram images has yet to be reached. Deep learning methods continue to excel in the fields of object detection and image classification applied to natural imagery. However, the application of such methodologies applied to binary imagery remains limited due to lack of crucial features such as textures,color and intensity information. This paper presents a deep learning based method for image-based search for binary patent images by taking advantage of existing large natural image repositories for image search and sketch-based methods (Sketches are not identical to diagrams, but they do share some characteristics; for example, both imagery types are gray scale (binary), composed of contours, and are lacking in texture). We begin by using deep learning to generate sketches from natural images for image retrieval and then train a second deep learning model on the sketches. We then use our small set of manually labeled patent diagram images via transfer learning to adapt the image search from sketches of natural images to diagrams. Our experiment results show the effectiveness of deep learning with transfer learning for detecting near-identical copies in patent images and querying similar images based on content.
The Role of Stem Noise in Visual Perception and Image Quality Measurement
Apr 11, 2020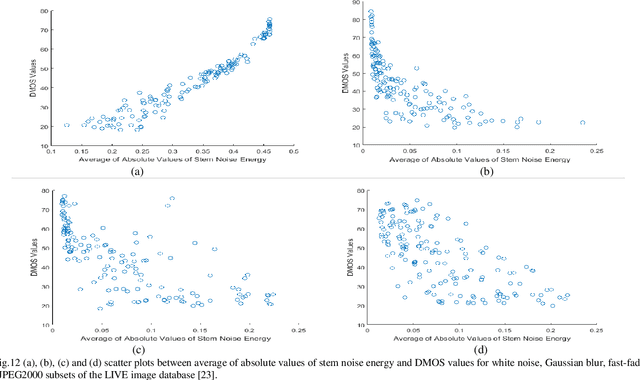

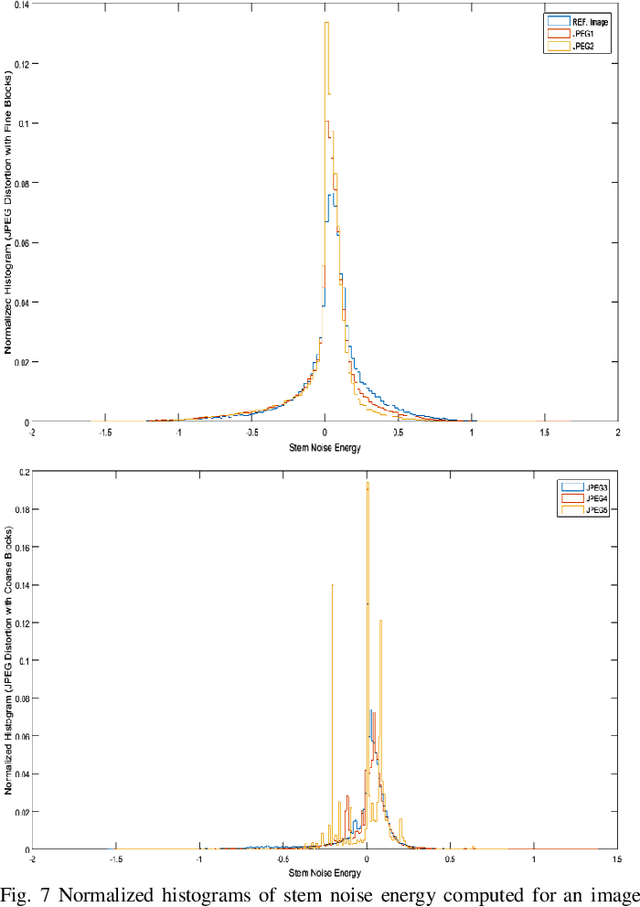
This paper considers reference free quality assessment of distorted and noisy images. Specifically, it considers the first and second order statistics of stem noise that can be evaluated given any image. In the research field of Image quality Assessment (IQA), the stem noise is defined as the input of an Auto Regressive (AR) process, from which a low-energy and de-correlated version of the image can be recovered. To estimate the AR model parameters and associated stem noise energy, the Yule-walker equations are used such that the accompanying Auto Correlation Function (ACF) coefficients can be treated as model parameters for image reconstruction. To characterize systematic signal dependent and signal independent distortions, the mean and variance of stem noise can be evaluated over the image. Crucially, this paper shows that these statistics have a predictive validity in relation to human ratings of image quality. Furthermore, under certain kinds of image distortion, stem noise statistics show very significant correlations with established measures of image quality.