 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Tactile Experience: Estimating Tactile Sensor Output from Depth Sensor Data
Oct 17, 2021
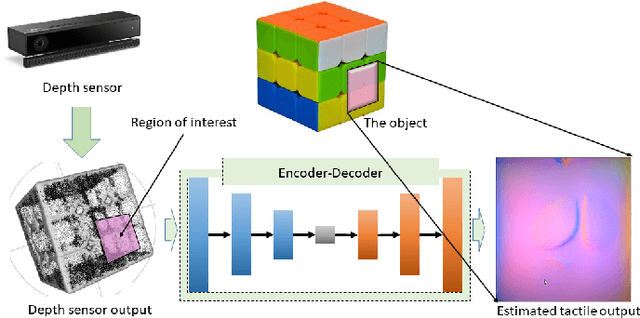

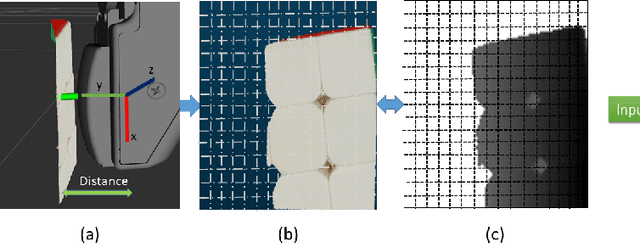
Tactile sensing is inherently contact based. To use tactile data, robots need to make contact with the surface of an object. This is inefficient in applications where an agent needs to make a decision between multiple alternatives that depend the physical properties of the contact location. We propose a method to get tactile data in a non-invasive manner. The proposed method estimates the output of a tactile sensor from the depth data of the surface of the object based on past experiences. An experience dataset is built by allowing the robot to interact with various objects, collecting tactile data and the corresponding object surface depth data. We use the experience dataset to train a neural network to estimate the tactile output from depth data alone. We use GelSight tactile sensors, an image-based sensor, to generate images that capture detailed surface features at the contact location. We train a network with a dataset containing 578 tactile-image to depthmap correspondences. Given a depth-map of the surface of an object, the network outputs an estimate of the response of the tactile sensor, should it make a contact with the object. We evaluate the method with structural similarity index matrix (SSIM), a similarity metric between two images commonly used in image processing community. We present experimental results that show the proposed method outperforms a baseline that uses random images with statistical significance getting an SSIM score of 0.84 +/- 0.0056 and 0.80 +/- 0.0036, respectively.
Enabling Deep Learning on Edge Devices through Filter Pruning and Knowledge Transfer
Jan 22, 2022Deep learning models have introduced various intelligent applications to edge devices, such as image classification, speech recognition, and augmented reality. There is an increasing need of training such models on the devices in order to deliver personalized, responsive, and private learning. To address this need, this paper presents a new solution for deploying and training state-of-the-art models on the resource-constrained devices. First, the paper proposes a novel filter-pruning-based model compression method to create lightweight trainable models from large models trained in the cloud, without much loss of accuracy. Second, it proposes a novel knowledge transfer method to enable the on-device model to update incrementally in real time or near real time using incremental learning on new data and enable the on-device model to learn the unseen categories with the help of the in-cloud model in an unsupervised fashion. The results show that 1) our model compression method can remove up to 99.36% parameters of WRN-28-10, while preserving a Top-1 accuracy of over 90% on CIFAR-10; 2) our knowledge transfer method enables the compressed models to achieve more than 90% accuracy on CIFAR-10 and retain good accuracy on old categories; 3) it allows the compressed models to converge within real time (three to six minutes) on the edge for incremental learning tasks; 4) it enables the model to classify unseen categories of data (78.92% Top-1 accuracy) that it is never trained with.
Contrastive Learning Meets Transfer Learning: A Case Study In Medical Image Analysis
Mar 04, 2021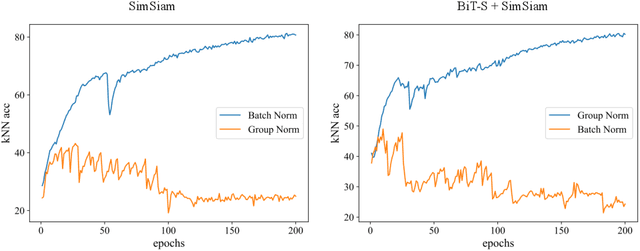
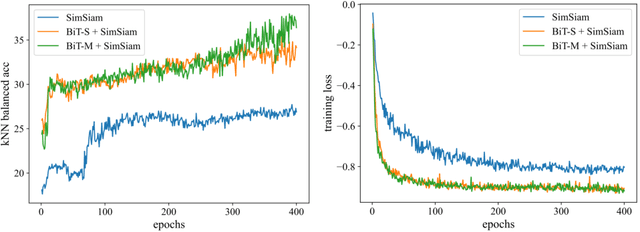
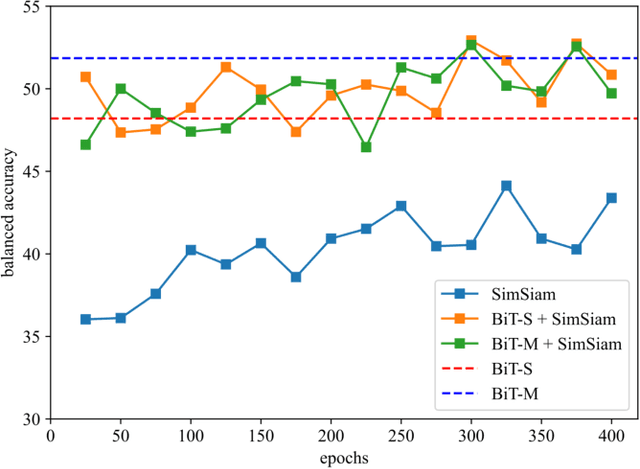

Annotated medical images are typically rarer than labeled natural images since they are limited by domain knowledge and privacy constraints. Recent advances in transfer and contrastive learning have provided effective solutions to tackle such issues from different perspectives. The state-of-the-art transfer learning (e.g., Big Transfer (BiT)) and contrastive learning (e.g., Simple Siamese Contrastive Learning (SimSiam)) approaches have been investigated independently, without considering the complementary nature of such techniques. It would be appealing to accelerate contrastive learning with transfer learning, given that slow convergence speed is a critical limitation of modern contrastive learning approaches. In this paper, we investigate the feasibility of aligning BiT with SimSiam. From empirical analyses, different normalization techniques (Group Norm in BiT vs. Batch Norm in SimSiam) are the key hurdle of adapting BiT to SimSiam. When combining BiT with SimSiam, we evaluated the performance of using BiT, SimSiam, and BiT+SimSiam on CIFAR-10 and HAM10000 datasets. The results suggest that the BiT models accelerate the convergence speed of SimSiam. When used together, the model gives superior performance over both of its counterparts. We hope this study will motivate researchers to revisit the task of aggregating big pre-trained models with contrastive learning models for image analysis.
Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction
Sep 03, 2021
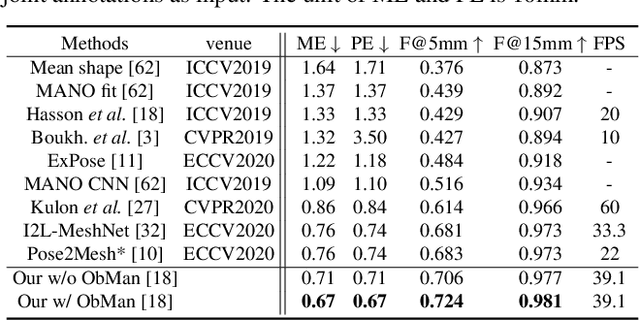
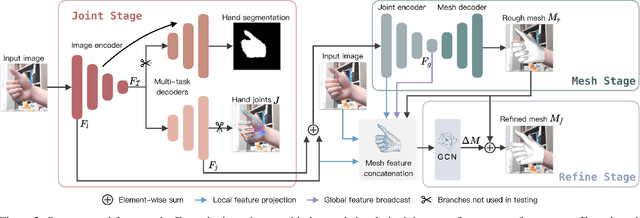
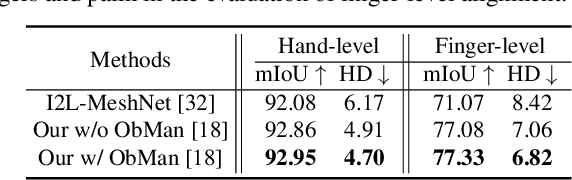
3D hand-mesh reconstruction from RGB images facilitates many applications, including augmented reality (AR). However, this requires not only real-time speed and accurate hand pose and shape but also plausible mesh-image alignment. While existing works already achieve promising results, meeting all three requirements is very challenging. This paper presents a novel pipeline by decoupling the hand-mesh reconstruction task into three stages: a joint stage to predict hand joints and segmentation; a mesh stage to predict a rough hand mesh; and a refine stage to fine-tune it with an offset mesh for mesh-image alignment. With careful design in the network structure and in the loss functions, we can promote high-quality finger-level mesh-image alignment and drive the models together to deliver real-time predictions. Extensive quantitative and qualitative results on benchmark datasets demonstrate that the quality of our results outperforms the state-of-the-art methods on hand-mesh/pose precision and hand-image alignment. In the end, we also showcase several real-time AR scenarios.
Learning Enriched Features for Real Image Restoration and Enhancement
Mar 15, 2020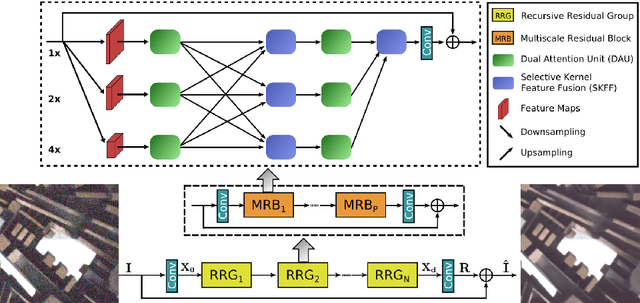

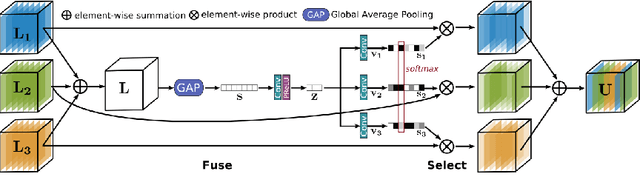
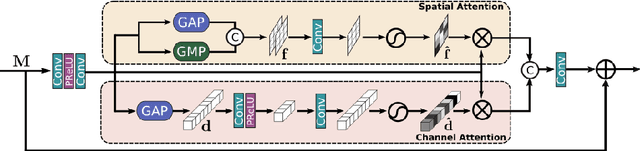
With the goal of recovering high-quality image content from its degraded version, image restoration enjoys numerous applications, such as in surveillance, computational photography, medical imaging, and remote sensing. Recently, convolutional neural networks (CNNs) have achieved dramatic improvements over conventional approaches for image restoration task. Existing CNN-based methods typically operate either on full-resolution or on progressively low-resolution representations. In the former case, spatially precise but contextually less robust results are achieved, while in the latter case, semantically reliable but spatially less accurate outputs are generated. In this paper, we present a novel architecture with the collective goals of maintaining spatially-precise high-resolution representations through the entire network, and receiving strong contextual information from the low-resolution representations. The core of our approach is a multi-scale residual block containing several key elements: (a) parallel multi-resolution convolution streams for extracting multi-scale features, (b) information exchange across the multi-resolution streams, (c) spatial and channel attention mechanisms for capturing contextual information, and (d) attention based multi-scale feature aggregation. In the nutshell, our approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details. Extensive experiments on five real image benchmark datasets demonstrate that our method, named as MIRNet, achieves state-of-the-art results for a variety of image processing tasks, including image denoising, super-resolution and image enhancement.
Manas: Mining Software Repositories to Assist AutoML
Dec 06, 2021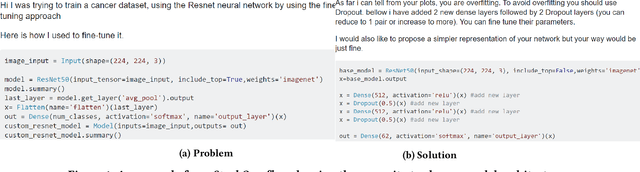
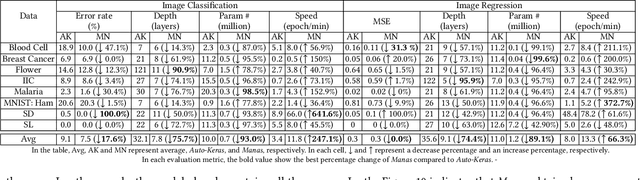
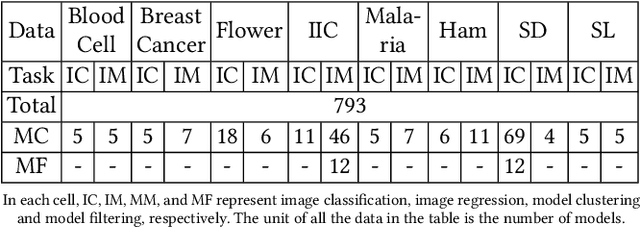
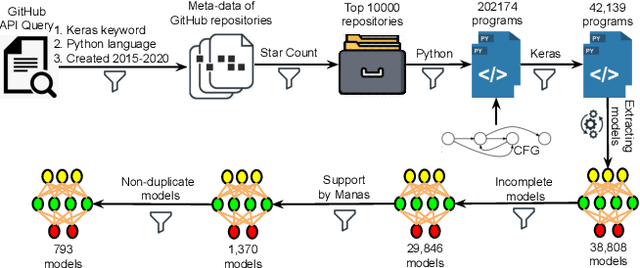
Today deep learning is widely used for building software. A software engineering problem with deep learning is that finding an appropriate convolutional neural network (CNN) model for the task can be a challenge for developers. Recent work on AutoML, more precisely neural architecture search (NAS), embodied by tools like Auto-Keras aims to solve this problem by essentially viewing it as a search problem where the starting point is a default CNN model, and mutation of this CNN model allows exploration of the space of CNN models to find a CNN model that will work best for the problem. These works have had significant success in producing high-accuracy CNN models. There are two problems, however. First, NAS can be very costly, often taking several hours to complete. Second, CNN models produced by NAS can be very complex that makes it harder to understand them and costlier to train them. We propose a novel approach for NAS, where instead of starting from a default CNN model, the initial model is selected from a repository of models extracted from GitHub. The intuition being that developers solving a similar problem may have developed a better starting point compared to the default model. We also analyze common layer patterns of CNN models in the wild to understand changes that the developers make to improve their models. Our approach uses commonly occurring changes as mutation operators in NAS. We have extended Auto-Keras to implement our approach. Our evaluation using 8 top voted problems from Kaggle for tasks including image classification and image regression shows that given the same search time, without loss of accuracy, Manas produces models with 42.9% to 99.6% fewer number of parameters than Auto-Keras' models. Benchmarked on GPU, Manas' models train 30.3% to 641.6% faster than Auto-Keras' models.
GmFace: A Mathematical Model for Face Image Representation Using Multi-Gaussian
Aug 03, 2020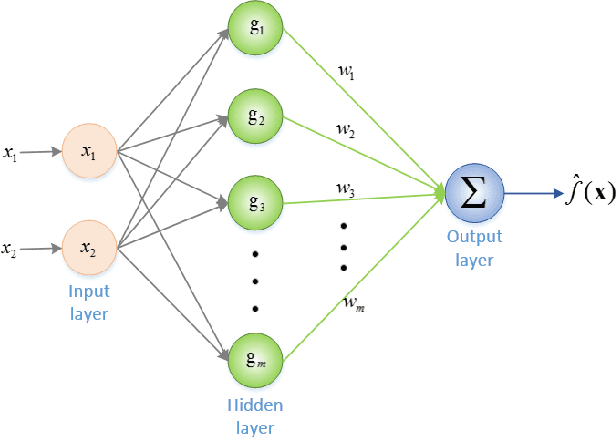
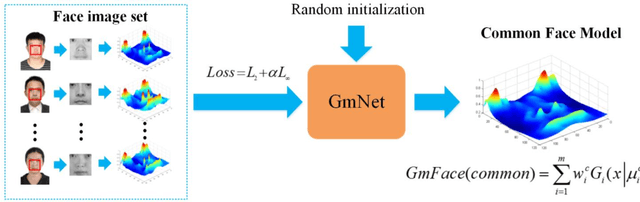
Establishing mathematical models is a ubiquitous and effective method to understand the objective world. Due to complex physiological structures and dynamic behaviors, mathematical representation of the human face is an especially challenging task. A mathematical model for face image representation called GmFace is proposed in the form of a multi-Gaussian function in this paper. The model utilizes the advantages of two-dimensional Gaussian function which provides a symmetric bell surface with a shape that can be controlled by parameters. The GmNet is then designed using Gaussian functions as neurons, with parameters that correspond to each of the parameters of GmFace in order to transform the problem of GmFace parameter solving into a network optimization problem of GmNet. The face modeling process can be described by the following steps: (1) GmNet initialization; (2) feeding GmNet with face image(s); (3) training GmNet until convergence; (4) drawing out the parameters of GmNet (as the same as GmFace); (5) recording the face model GmFace. Furthermore, using GmFace, several face image transformation operations can be realized mathematically through simple parameter computation.
Explaining Convolutional Neural Networks by Tagging Filters
Sep 20, 2021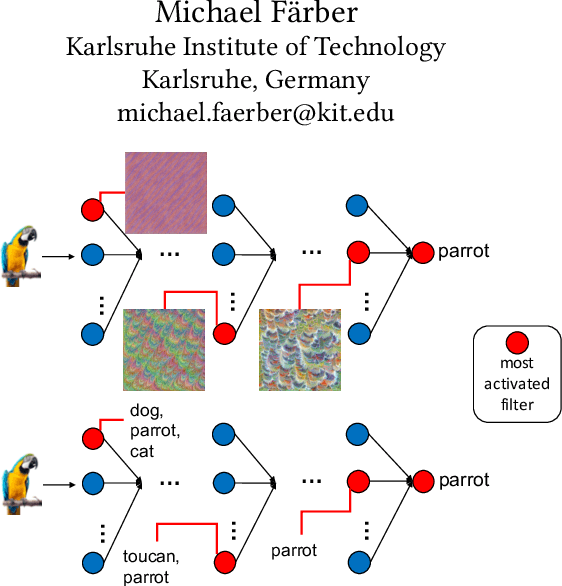
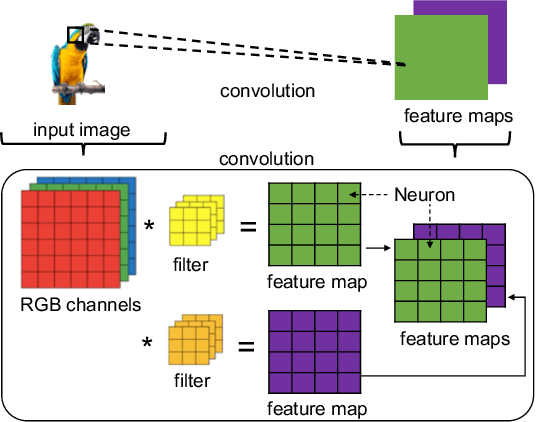

Convolutional neural networks (CNNs) have achieved astonishing performance on various image classification tasks, but it is difficult for humans to understand how a classification comes about. Recent literature proposes methods to explain the classification process to humans. These focus mostly on visualizing feature maps and filter weights, which are not very intuitive for non-experts in analyzing a CNN classification. In this paper, we propose FilTag, an approach to effectively explain CNNs even to non-experts. The idea is that when images of a class frequently activate a convolutional filter, then that filter is tagged with that class. These tags provide an explanation to a reference of a class-specific feature detected by the filter. Based on the tagging, individual image classifications can then be intuitively explained in terms of the tags of the filters that the input image activates. Finally, we show that the tags are helpful in analyzing classification errors caused by noisy input images and that the tags can be further processed by machines.
Reversible adversarial examples against local visual perturbation
Oct 06, 2021
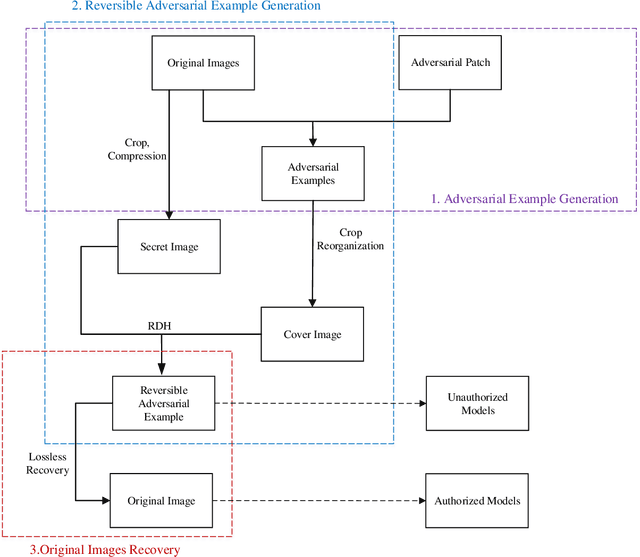

Recently, studies have indicated that adversarial attacks pose a threat to deep learning systems. However, when there are only adversarial examples, people cannot get the original images, so there is research on reversible adversarial attacks. However, the existing strategies are aimed at invisible adversarial perturbation, and do not consider the case of locally visible adversarial perturbation. In this article, we generate reversible adversarial examples for local visual adversarial perturbation, and use reversible data embedding technology to embed the information needed to restore the original image into the adversarial examples to generate examples that are both adversarial and reversible. Experiments on ImageNet dataset show that our method can restore the original image losslessly while ensuring the attack capability.
Deep Metric Learning for Ground Images
Sep 03, 2021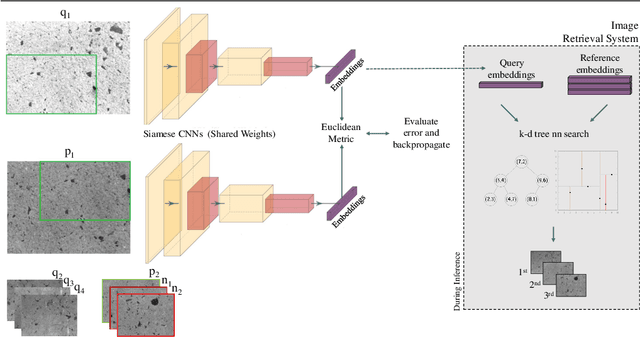
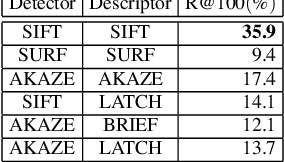

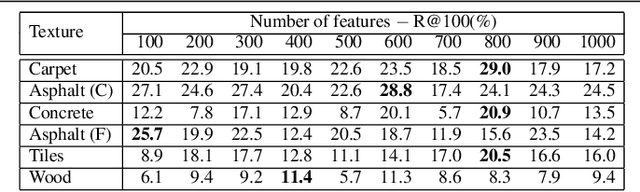
Ground texture based localization methods are potential prospects for low-cost, high-accuracy self-localization solutions for robots. These methods estimate the pose of a given query image, i.e. the current observation of the ground from a downward-facing camera, in respect to a set of reference images whose poses are known in the application area. In this work, we deal with the initial localization task, in which we have no prior knowledge about the current robot positioning. In this situation, the localization method would have to consider all available reference images. However, in order to reduce computational effort and the risk of receiving a wrong result, we would like to consider only those reference images that are actually overlapping with the query image. For this purpose, we propose a deep metric learning approach that retrieves the most similar reference images to the query image. In contrast to existing approaches to image retrieval for ground images, our approach achieves significantly better recall performance and improves the localization performance of a state-of-the-art ground texture based localization method.