 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Seeing BDD100K in dark: Single-Stage Night-time Object Detection via Continual Fourier Contrastive Learning
Dec 06, 2021


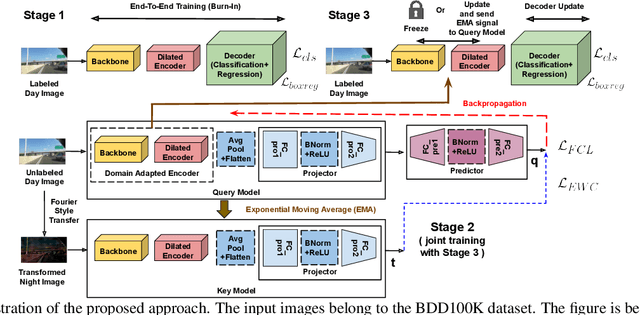
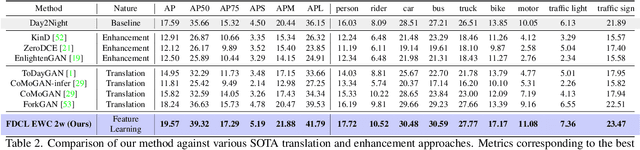
Despite tremendous improvements in state-of-the-art object detectors, addressing object detection in the night-time has been studied only sparsely, that too, via non-uniform evaluation protocols among the limited available papers. In addition to the lack of methods to address this problem, there was also a lack of an adequately large benchmark dataset to study night-time object detection. Recently, the large scale BDD100K was introduced, which, in our opinion, should be chosen as the benchmark, to kickstart research in this area. Now, coming to the methods, existing approaches (limited in number), are mainly either generative image translation based, or image enhancement/ illumination based, neither of which is natural, conforming to how humans see objects in the night time (by focusing on object contours). In this paper, we bridge these 3 gaps: 1. Lack of an uniform evaluation protocol (using a single-stage detector, due to its efficacy, and efficiency), 2. Choice of dataset for benchmarking night-time object detection, and 3. A novel method to address the limitations of current alternatives. Our method leverages a Contrastive Learning based feature extractor, borrowing information from the frequency domain via Fourier transformation, and trained in a continual learning based fashion. The learned features when used for object detection (after fine-tuning the classification and regression layers), help achieve a new state-of-the-art empirical performance, comfortably outperforming an extensive number of competitors.
Unleashing the Potential of Unsupervised Pre-Training with Intra-Identity Regularization for Person Re-Identification
Dec 01, 2021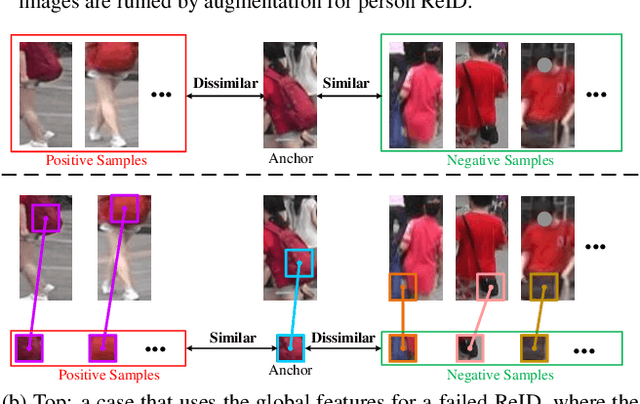
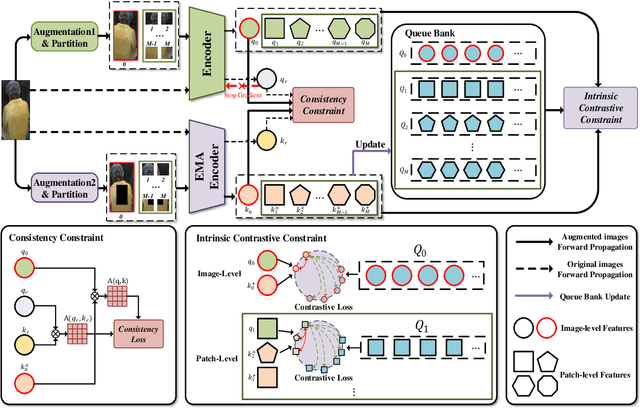
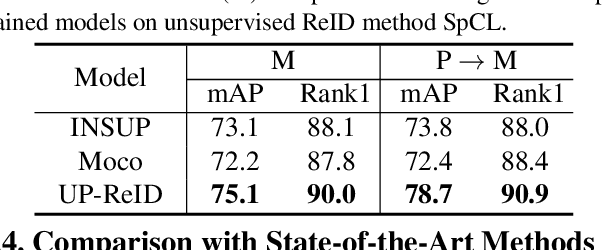
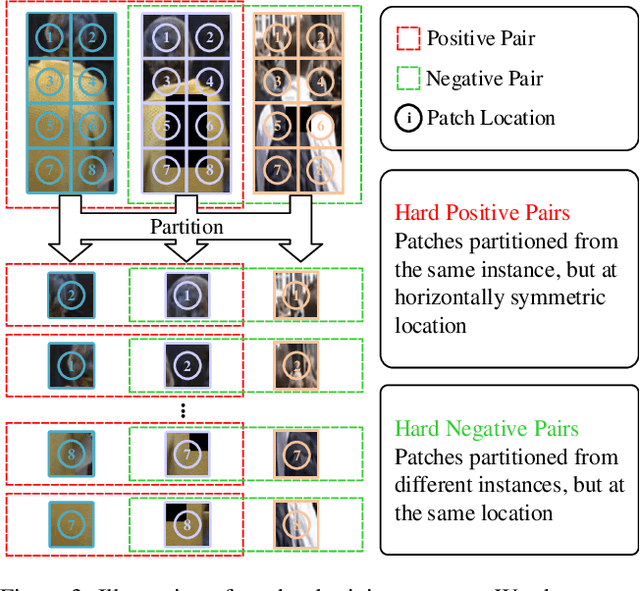
Existing person re-identification (ReID) methods typically directly load the pre-trained ImageNet weights for initialization. However, as a fine-grained classification task, ReID is more challenging and exists a large domain gap between ImageNet classification. Inspired by the great success of self-supervised representation learning with contrastive objectives, in this paper, we design an Unsupervised Pre-training framework for ReID based on the contrastive learning (CL) pipeline, dubbed UP-ReID. During the pre-training, we attempt to address two critical issues for learning fine-grained ReID features: (1) the augmentations in CL pipeline may distort the discriminative clues in person images. (2) the fine-grained local features of person images are not fully-explored. Therefore, we introduce an intra-identity (I$^2$-)regularization in the UP-ReID, which is instantiated as two constraints coming from global image aspect and local patch aspect: a global consistency is enforced between augmented and original person images to increase robustness to augmentation, while an intrinsic contrastive constraint among local patches of each image is employed to fully explore the local discriminative clues. Extensive experiments on multiple popular Re-ID datasets, including PersonX, Market1501, CUHK03, and MSMT17, demonstrate that our UP-ReID pre-trained model can significantly benefit the downstream ReID fine-tuning and achieve state-of-the-art performance. Codes and models will be released to https://github.com/Frost-Yang-99/UP-ReID.
Zoom, Enhance! Measuring Surveillance GAN Up-sampling
Aug 20, 2021
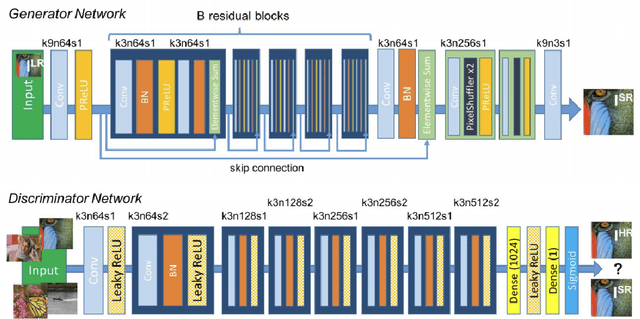
Deep Neural Networks have been very successfully used for many computer vision and pattern recognition applications. While Convolutional Neural Networks(CNNs) have shown the path to state of art image classifications, Generative Adversarial Networks or GANs have provided state of art capabilities in image generation. In this paper we extend the applications of CNNs and GANs to experiment with up-sampling techniques in the domains of security and surveillance. Through this work we evaluate, compare and contrast the state of art techniques in both CNN and GAN based image and video up-sampling in the surveillance domain. As a result of this study we also provide experimental evidence to establish DISTS as a stronger Image Quality Assessment(IQA) metric for comparing GAN Based Image Up-sampling in the surveillance domain.
Fourth-Order Anisotropic Diffusion for Inpainting and Image Compression
Jun 18, 2020

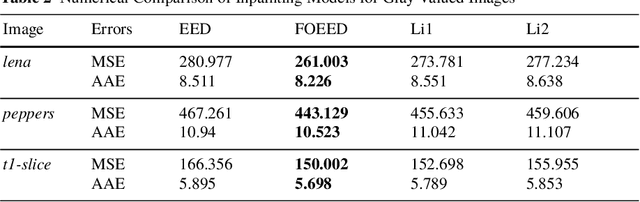

Edge-enhancing diffusion (EED) can reconstruct a close approximation of an original image from a small subset of its pixels. This makes it an attractive foundation for PDE based image compression. In this work, we generalize second-order EED to a fourth-order counterpart. It involves a fourth-order diffusion tensor that is constructed from the regularized image gradient in a similar way as in traditional second-order EED, permitting diffusion along edges, while applying a non-linear diffusivity function across them. We show that our fourth-order diffusion tensor formalism provides a unifying framework for all previous anisotropic fourth-order diffusion based methods, and that it provides additional flexibility. We achieve an efficient implementation using a fast semi-iterative scheme. Experimental results on natural and medical images suggest that our novel fourth-order method produces more accurate reconstructions compared to the existing second-order EED.
Enhance Images as You Like with Unpaired Learning
Oct 04, 2021
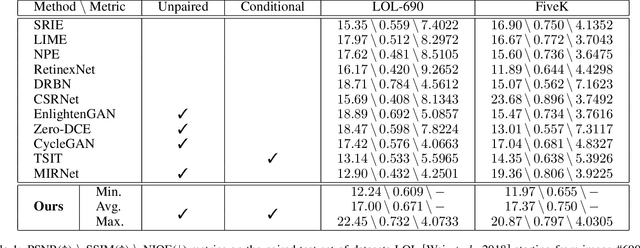

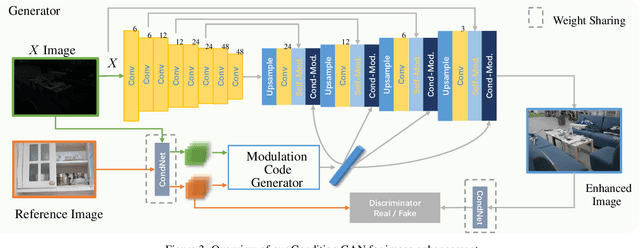
Low-light image enhancement exhibits an ill-posed nature, as a given image may have many enhanced versions, yet recent studies focus on building a deterministic mapping from input to an enhanced version. In contrast, we propose a lightweight one-path conditional generative adversarial network (cGAN) to learn a one-to-many relation from low-light to normal-light image space, given only sets of low- and normal-light training images without any correspondence. By formulating this ill-posed problem as a modulation code learning task, our network learns to generate a collection of enhanced images from a given input conditioned on various reference images. Therefore our inference model easily adapts to various user preferences, provided with a few favorable photos from each user. Our model achieves competitive visual and quantitative results on par with fully supervised methods on both noisy and clean datasets, while being 6 to 10 times lighter than state-of-the-art generative adversarial networks (GANs) approaches.
Contextual Similarity Aggregation with Self-attention for Visual Re-ranking
Oct 26, 2021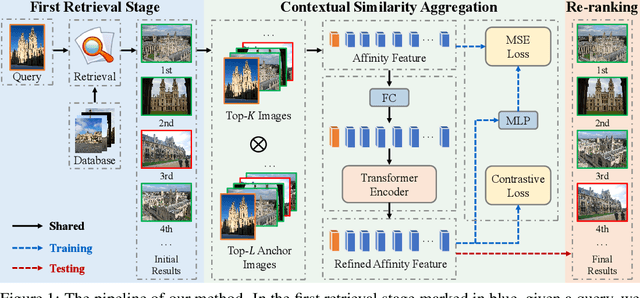
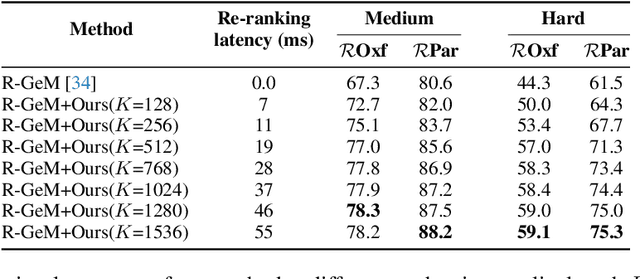
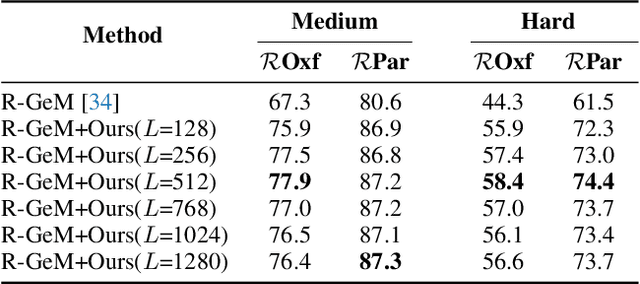
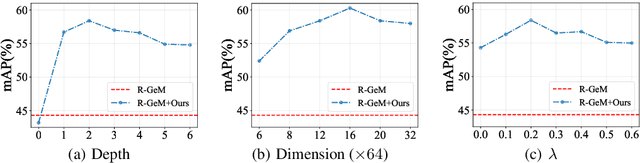
In content-based image retrieval, the first-round retrieval result by simple visual feature comparison may be unsatisfactory, which can be refined by visual re-ranking techniques. In image retrieval, it is observed that the contextual similarity among the top-ranked images is an important clue to distinguish the semantic relevance. Inspired by this observation, in this paper, we propose a visual re-ranking method by contextual similarity aggregation with self-attention. In our approach, for each image in the top-K ranking list, we represent it into an affinity feature vector by comparing it with a set of anchor images. Then, the affinity features of the top-K images are refined by aggregating the contextual information with a transformer encoder. Finally, the affinity features are used to recalculate the similarity scores between the query and the top-K images for re-ranking of the latter. To further improve the robustness of our re-ranking model and enhance the performance of our method, a new data augmentation scheme is designed. Since our re-ranking model is not directly involved with the visual feature used in the initial retrieval, it is ready to be applied to retrieval result lists obtained from various retrieval algorithms. We conduct comprehensive experiments on four benchmark datasets to demonstrate the generality and effectiveness of our proposed visual re-ranking method.
Neural Manifold Clustering and Embedding
Jan 24, 2022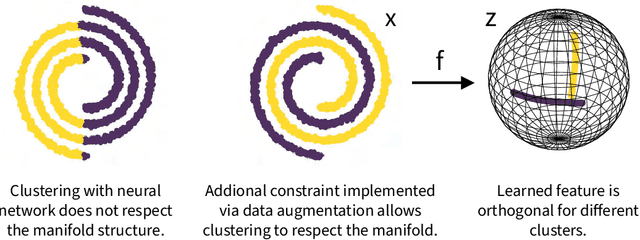



Given a union of non-linear manifolds, non-linear subspace clustering or manifold clustering aims to cluster data points based on manifold structures and also learn to parameterize each manifold as a linear subspace in a feature space. Deep neural networks have the potential to achieve this goal under highly non-linear settings given their large capacity and flexibility. We argue that achieving manifold clustering with neural networks requires two essential ingredients: a domain-specific constraint that ensures the identification of the manifolds, and a learning algorithm for embedding each manifold to a linear subspace in the feature space. This work shows that many constraints can be implemented by data augmentation. For subspace feature learning, Maximum Coding Rate Reduction (MCR$^2$) objective can be used. Putting them together yields {\em Neural Manifold Clustering and Embedding} (NMCE), a novel method for general purpose manifold clustering, which significantly outperforms autoencoder-based deep subspace clustering. Further, on more challenging natural image datasets, NMCE can also outperform other algorithms specifically designed for clustering. Qualitatively, we demonstrate that NMCE learns a meaningful and interpretable feature space. As the formulation of NMCE is closely related to several important Self-supervised learning (SSL) methods, we believe this work can help us build a deeper understanding on SSL representation learning.
Self-Supervision based Task-Specific Image Collection Summarization
Dec 26, 2020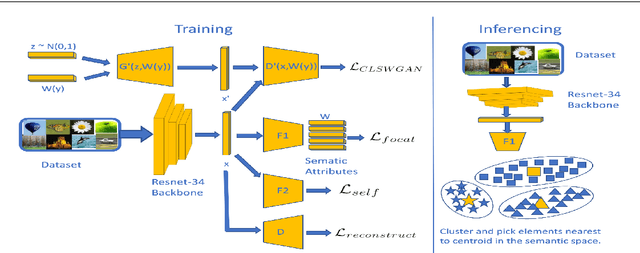
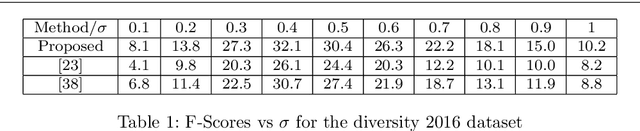
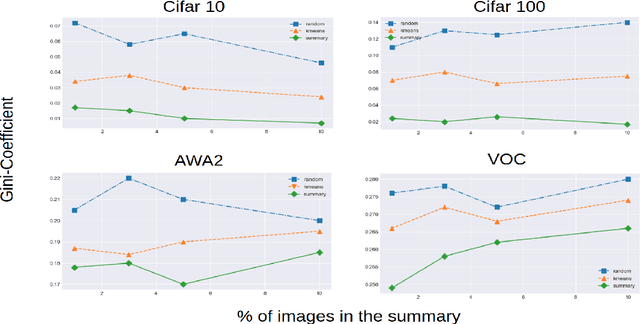
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
A Novel adaptive optimization of Dual-Tree Complex Wavelet Transform for Medical Image Fusion
Jul 22, 2020
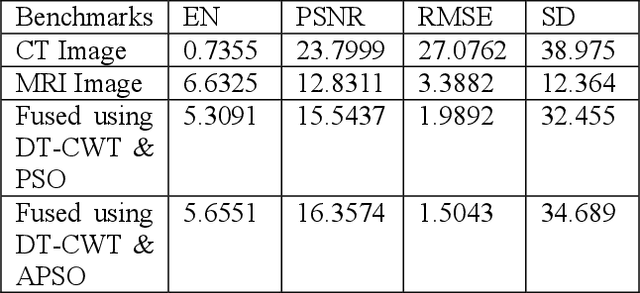
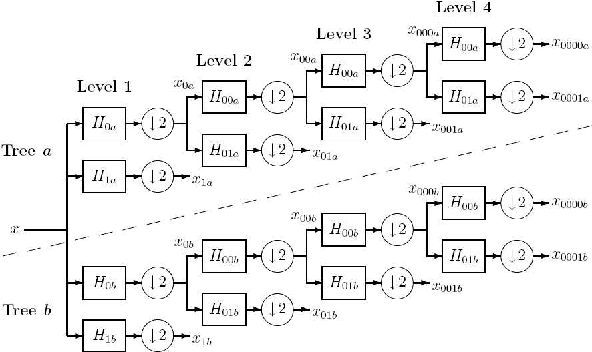
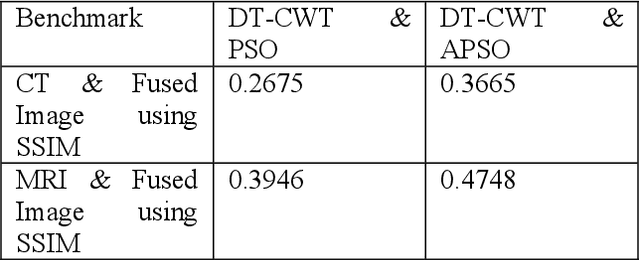
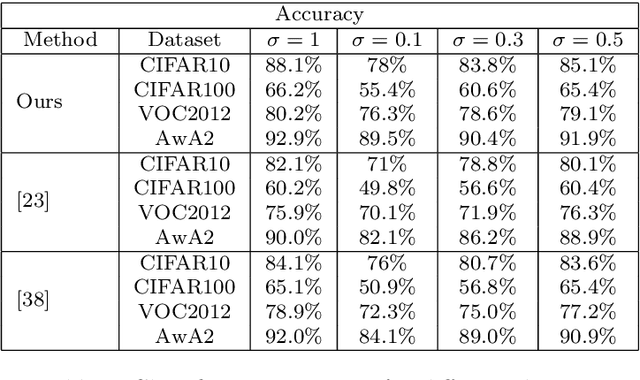
In recent years, many research achievements are made in the medical image fusion field. Fusion is basically extraction of best of inputs and conveying it to the output. Medical Image fusion means that several of various modality image information is comprehended together to form one image to express its information. The aim of image fusion is to integrate complementary and redundant information. In this paper, a multimodal image fusion algorithm based on the dual-tree complex wavelet transform (DT-CWT) and adaptive particle swarm optimization (APSO) is proposed. Fusion is achieved through the formation of a fused pyramid using the DTCWT coefficients from the decomposed pyramids of the source images. The coefficients are fused by the weighted average method based on pixels, and the weights are estimated by the APSO to gain optimal fused images. The fused image is obtained through conventional inverse dual-tree complex wavelet transform reconstruction process. Experiment results show that the proposed method based on adaptive particle swarm optimization algorithm is remarkably better than the method based on particle swarm optimization. The resulting fused images are compared visually and through benchmarks such as Entropy (E), Peak Signal to Noise Ratio, (PSNR), Root Mean Square Error (RMSE), Standard deviation (SD) and Structure Similarity Index Metric (SSIM) computations.
Artifacts in optical projection tomography due to refractive index mismatch: model and correction
Dec 24, 2021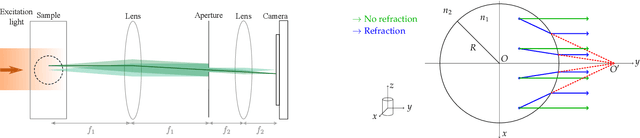

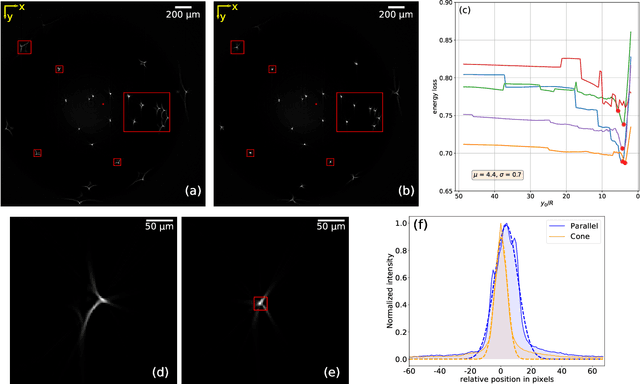
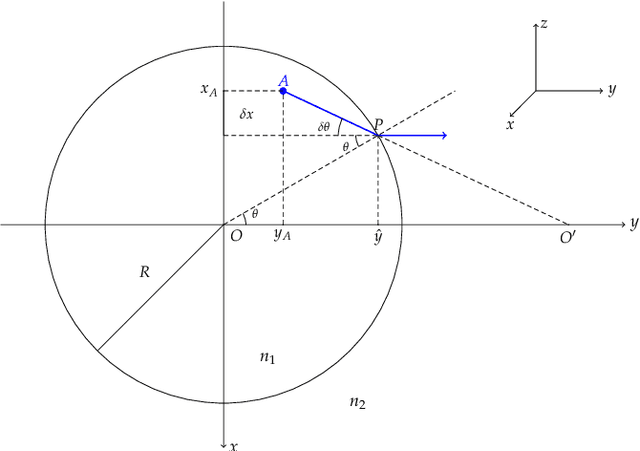
Optical Projection Tomography (OPT) is a powerful tool for 3D imaging of mesoscopic samples, thus of great importance to image whole organs for the study of various disease models in life sciences. OPT is able to achieve resolution at a few tens of microns over a large sample volume of several cubic centimeters. However, the reconstructed OPT images often suffer from artifacts caused by different kinds of physical miscalibration. This work focuses on the refractive index (RI) mismatch between the rotating object and the surrounding medium. We derive a 3D cone beam forward model to approximate the effect of RI mismatch and implement a fast and efficient reconstruction method to correct the induced seagull-shaped artifacts on experimental images of fluorescent beads.