 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Shape-Biased Domain Generalization via Shock Graph Embeddings
Sep 13, 2021

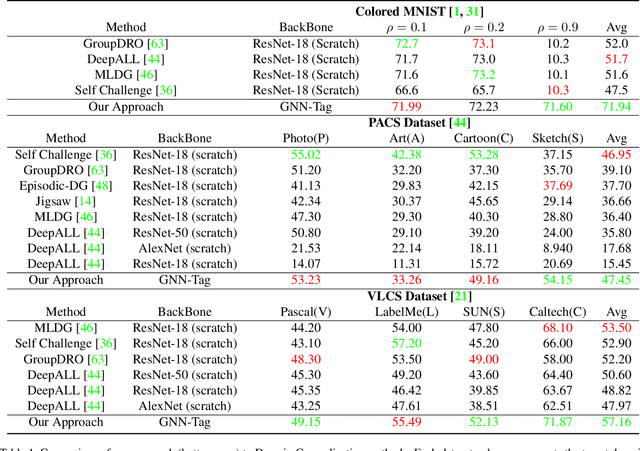

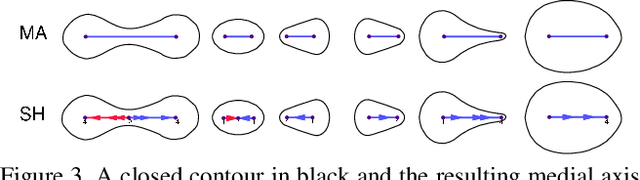
There is an emerging sense that the vulnerability of Image Convolutional Neural Networks (CNN), i.e., sensitivity to image corruptions, perturbations, and adversarial attacks, is connected with Texture Bias. This relative lack of Shape Bias is also responsible for poor performance in Domain Generalization (DG). The inclusion of a role of shape alleviates these vulnerabilities and some approaches have achieved this by training on negative images, images endowed with edge maps, or images with conflicting shape and texture information. This paper advocates an explicit and complete representation of shape using a classical computer vision approach, namely, representing the shape content of an image with the shock graph of its contour map. The resulting graph and its descriptor is a complete representation of contour content and is classified using recent Graph Neural Network (GNN) methods. The experimental results on three domain shift datasets, Colored MNIST, PACS, and VLCS demonstrate that even without using appearance the shape-based approach exceeds classical Image CNN based methods in domain generalization.
DeepKeyGen: A Deep Learning-based Stream Cipher Generator for Medical Image Encryption and Decryption
Dec 21, 2020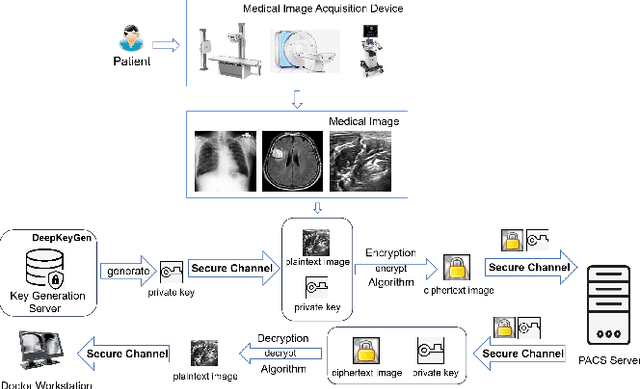
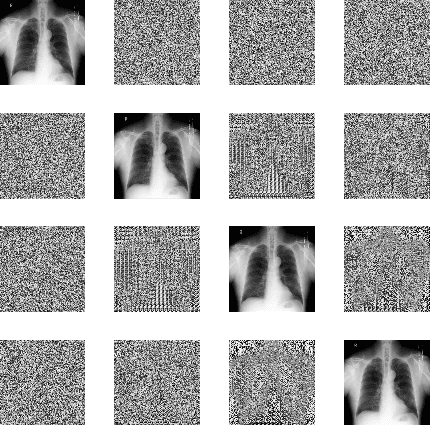

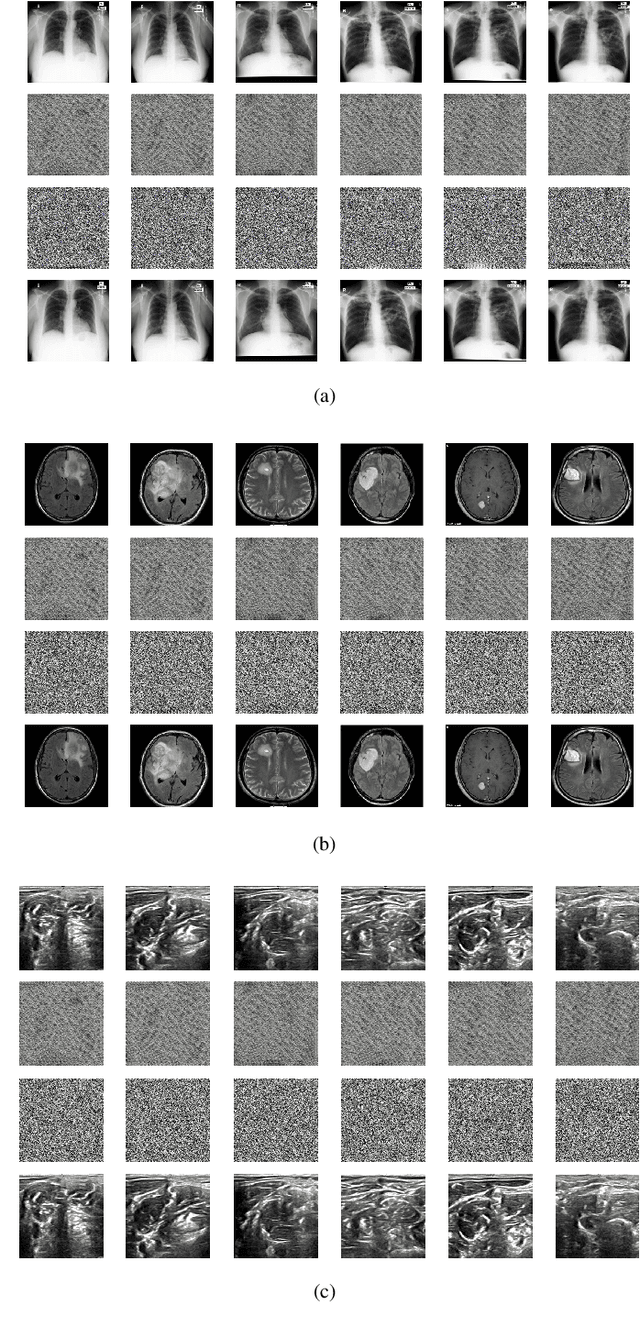
The need for medical image encryption is increasingly pronounced, for example to safeguard the privacy of the patients' medical imaging data. In this paper, a novel deep learning-based key generation network (DeepKeyGen) is proposed as a stream cipher generator to generate the private key, which can then be used for encrypting and decrypting of medical images. In DeepKeyGen, the generative adversarial network (GAN) is adopted as the learning network to generate the private key. Furthermore, the transformation domain (that represents the "style" of the private key to be generated) is designed to guide the learning network to realize the private key generation process. The goal of DeepKeyGen is to learn the mapping relationship of how to transfer the initial image to the private key. We evaluate DeepKeyGen using three datasets, namely: the Montgomery County chest X-ray dataset, the Ultrasonic Brachial Plexus dataset, and the BraTS18 dataset. The evaluation findings and security analysis show that the proposed key generation network can achieve a high-level security in generating the private key.
Keypoint-Aligned Embeddings for Image Retrieval and Re-identification
Aug 26, 2020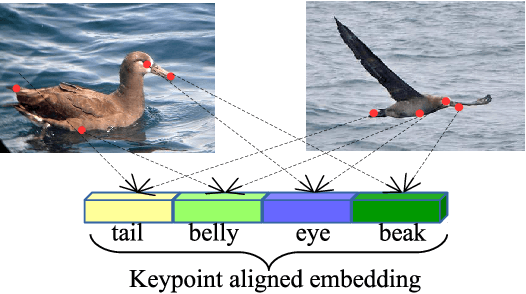
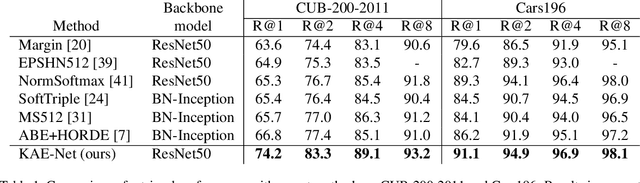
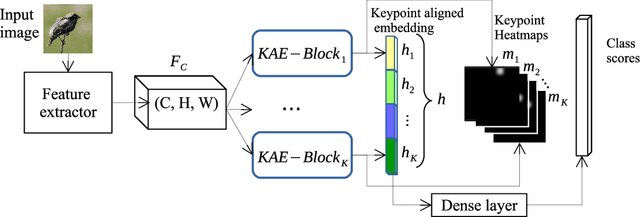
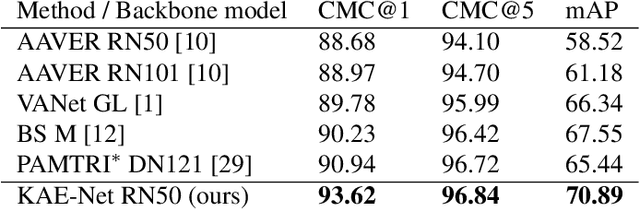
Learning embeddings that are invariant to the pose of the object is crucial in visual image retrieval and re-identification. The existing approaches for person, vehicle, or animal re-identification tasks suffer from high intra-class variance due to deformable shapes and different camera viewpoints. To overcome this limitation, we propose to align the image embedding with a predefined order of the keypoints. The proposed keypoint aligned embeddings model (KAE-Net) learns part-level features via multi-task learning which is guided by keypoint locations. More specifically, KAE-Net extracts channels from a feature map activated by a specific keypoint through learning the auxiliary task of heatmap reconstruction for this keypoint. The KAE-Net is compact, generic and conceptually simple. It achieves state of the art performance on the benchmark datasets of CUB-200-2011, Cars196 and VeRi-776 for retrieval and re-identification tasks.
CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems
Dec 01, 2021
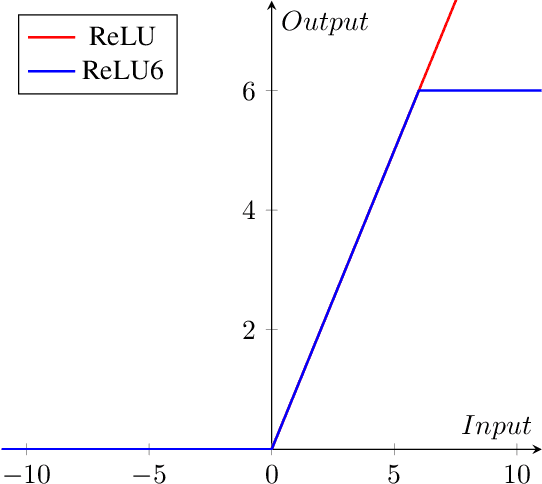
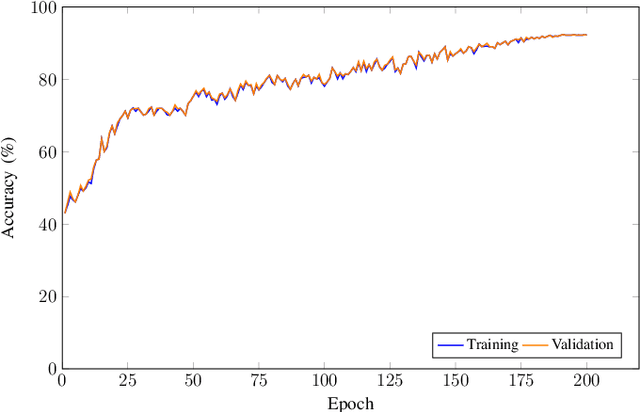

Due to the advent of modern embedded systems and mobile devices with constrained resources, there is a great demand for incredibly efficient deep neural networks for machine learning purposes. There is also a growing concern of privacy and confidentiality of user data within the general public when their data is processed and stored in an external server which has further fueled the need for developing such efficient neural networks for real-time inference on local embedded systems. The scope of our work presented in this paper is limited to image classification using a convolutional neural network. A Convolutional Neural Network (CNN) is a class of Deep Neural Network (DNN) widely used in the analysis of visual images captured by an image sensor, designed to extract information and convert it into meaningful representations for real-time inference of the input data. In this paper, we propose a neoteric variant of deep convolutional neural network architecture to ameliorate the performance of existing CNN architectures for real-time inference on embedded systems. We show that this architecture, dubbed CondenseNeXt, is remarkably efficient in comparison to the baseline neural network architecture, CondenseNet, by reducing trainable parameters and FLOPs required to train the network whilst maintaining a balance between the trained model size of less than 3.0 MB and accuracy trade-off resulting in an unprecedented computational efficiency.
VIFB: A Visible and Infrared Image Fusion Benchmark
Feb 09, 2020



Visible and infrared image fusion is one of the most important areas in image processing due to its numerous applications. While much progress has been made in recent years with efforts on developing fusion algorithms, there is a lack of code library and benchmark which can gauge the state-of-the-art. In this paper, after briefly reviewing recent advances of visible and infrared image fusion, we present a visible and infrared image fusion benchmark (VIFB) which consists of 21 image pairs, a code library of 20 fusion algorithms and 13 evaluation metrics. We also carry out large scale experiments within the benchmark to understand the performance of these algorithms. By analyzing qualitative and quantitative results, we identify effective algorithms for robust image fusion and give some observations on the status and future prospects of this field. The benchmark, including dataset, code library, evaluation metrics, and results is available upon request.
Few-shot Image Generation with Elastic Weight Consolidation
Dec 04, 2020

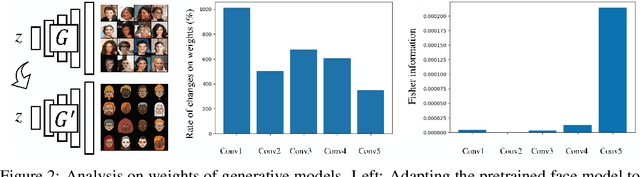
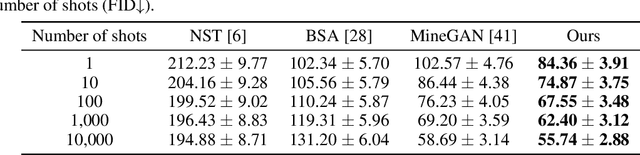
Few-shot image generation seeks to generate more data of a given domain, with only few available training examples. As it is unreasonable to expect to fully infer the distribution from just a few observations (e.g., emojis), we seek to leverage a large, related source domain as pretraining (e.g., human faces). Thus, we wish to preserve the diversity of the source domain, while adapting to the appearance of the target. We adapt a pretrained model, without introducing any additional parameters, to the few examples of the target domain. Crucially, we regularize the changes of the weights during this adaptation, in order to best preserve the information of the source dataset, while fitting the target. We demonstrate the effectiveness of our algorithm by generating high-quality results of different target domains, including those with extremely few examples (e.g., <10). We also analyze the performance of our method with respect to some important factors, such as the number of examples and the dissimilarity between the source and target domain.
Boundary Aware Learning for Out-of-distribution Detection
Jan 14, 2022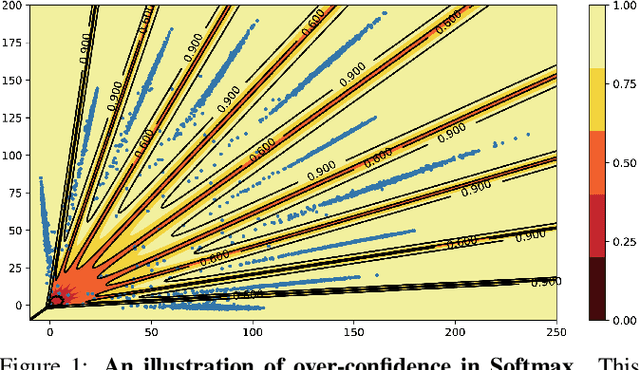
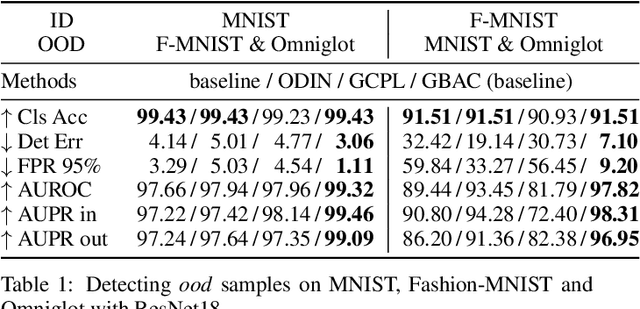
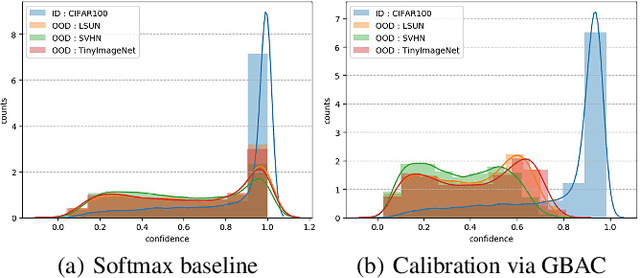
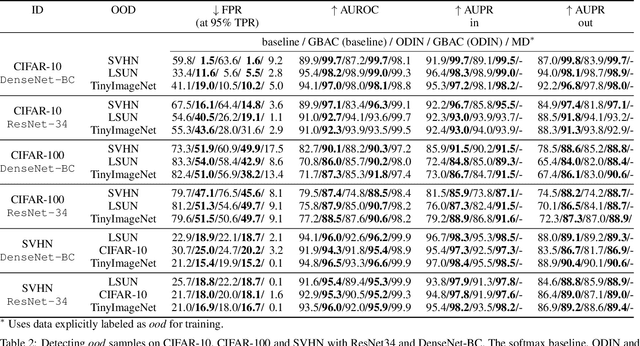
This paper focuses on the problem of detecting out-of-distribution (ood) samples with neural nets. In image recognition tasks, the trained classifier often gives high confidence score for input images which are remote from the in-distribution (id) data, and this has greatly limited its application in real world. For alleviating this problem, we propose a GAN based boundary aware classifier (GBAC) for generating a closed hyperspace which only contains most id data. Our method is based on the fact that the traditional neural net seperates the feature space as several unclosed regions which are not suitable for ood detection. With GBAC as an auxiliary module, the ood data distributed outside the closed hyperspace will be assigned with much lower score, allowing more effective ood detection while maintaining the classification performance. Moreover, we present a fast sampling method for generating hard ood representations which lie on the boundary of pre-mentioned closed hyperspace. Experiments taken on several datasets and neural net architectures promise the effectiveness of GBAC.
AGA-GAN: Attribute Guided Attention Generative Adversarial Network with U-Net for Face Hallucination
Nov 20, 2021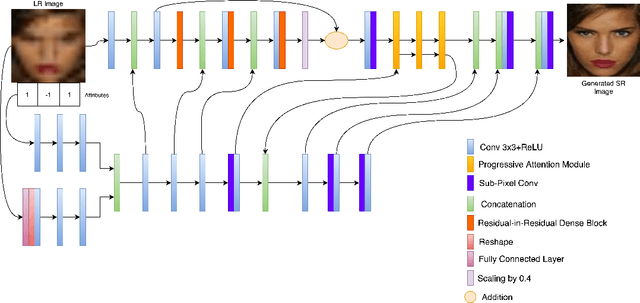
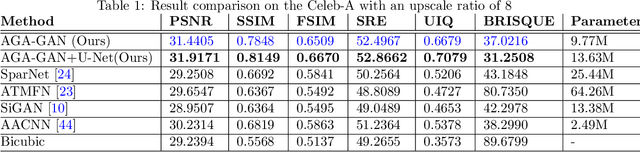
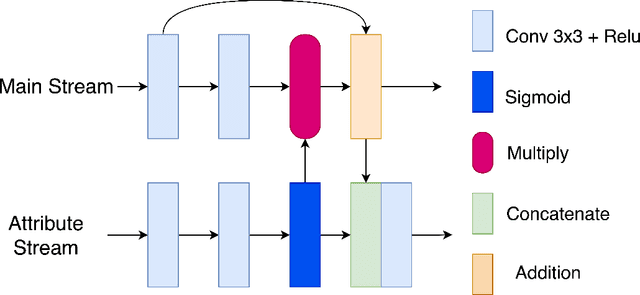
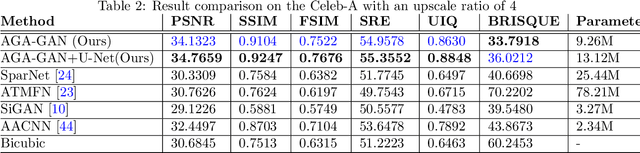
The performance of facial super-resolution methods relies on their ability to recover facial structures and salient features effectively. Even though the convolutional neural network and generative adversarial network-based methods deliver impressive performances on face hallucination tasks, the ability to use attributes associated with the low-resolution images to improve performance is unsatisfactory. In this paper, we propose an Attribute Guided Attention Generative Adversarial Network which employs novel attribute guided attention (AGA) modules to identify and focus the generation process on various facial features in the image. Stacking multiple AGA modules enables the recovery of both high and low-level facial structures. We design the discriminator to learn discriminative features exploiting the relationship between the high-resolution image and their corresponding facial attribute annotations. We then explore the use of U-Net based architecture to refine existing predictions and synthesize further facial details. Extensive experiments across several metrics show that our AGA-GAN and AGA-GAN+U-Net framework outperforms several other cutting-edge face hallucination state-of-the-art methods. We also demonstrate the viability of our method when every attribute descriptor is not known and thus, establishing its application in real-world scenarios.
Encouraging Disentangled and Convex Representation with Controllable Interpolation Regularization
Dec 06, 2021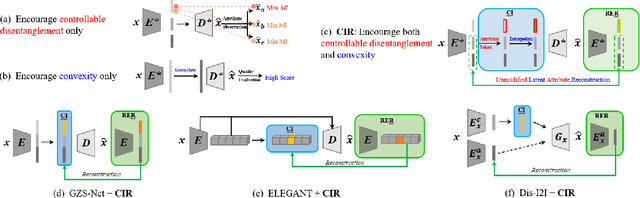
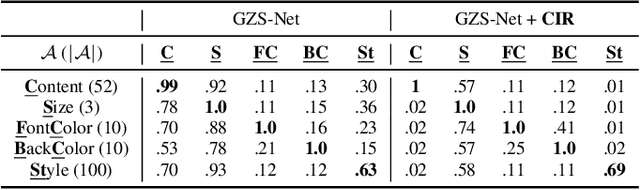

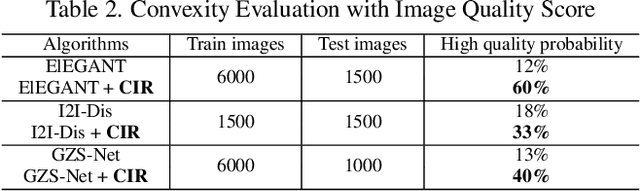
We focus on controllable disentangled representation learning (C-Dis-RL), where users can control the partition of the disentangled latent space to factorize dataset attributes (concepts) for downstream tasks. Two general problems remain under-explored in current methods: (1) They lack comprehensive disentanglement constraints, especially missing the minimization of mutual information between different attributes across latent and observation domains. (2) They lack convexity constraints in disentangled latent space, which is important for meaningfully manipulating specific attributes for downstream tasks. To encourage both comprehensive C-Dis-RL and convexity simultaneously, we propose a simple yet efficient method: Controllable Interpolation Regularization (CIR), which creates a positive loop where the disentanglement and convexity can help each other. Specifically, we conduct controlled interpolation in latent space during training and 'reuse' the encoder to help form a 'perfect disentanglement' regularization. In that case, (a) disentanglement loss implicitly enlarges the potential 'understandable' distribution to encourage convexity; (b) convexity can in turn improve robust and precise disentanglement. CIR is a general module and we merge CIR with three different algorithms: ELEGANT, I2I-Dis, and GZS-Net to show the compatibility and effectiveness. Qualitative and quantitative experiments show improvement in C-Dis-RL and latent convexity by CIR. This further improves downstream tasks: controllable image synthesis, cross-modality image translation and zero-shot synthesis. More experiments demonstrate CIR can also improve other downstream tasks, such as new attribute value mining, data augmentation, and eliminating bias for fairness.
Self-Supervised 3D Face Reconstruction via Conditional Estimation
Oct 10, 2021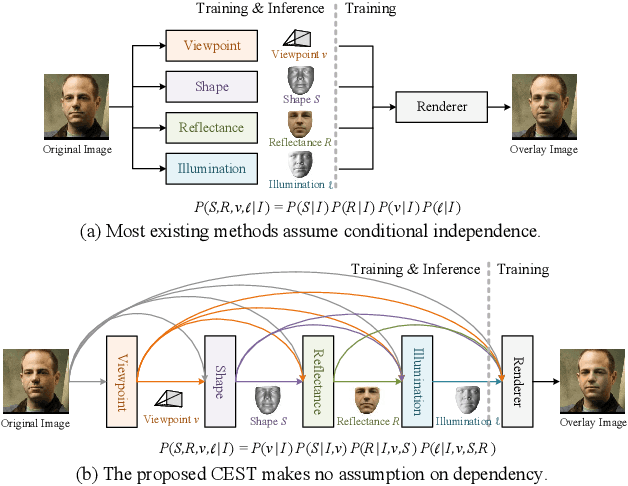

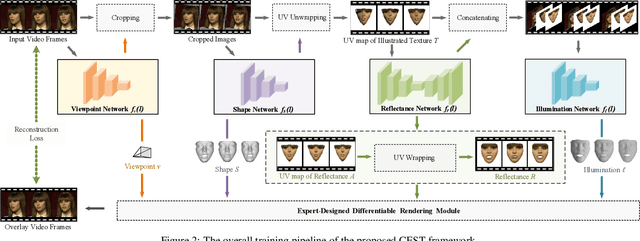
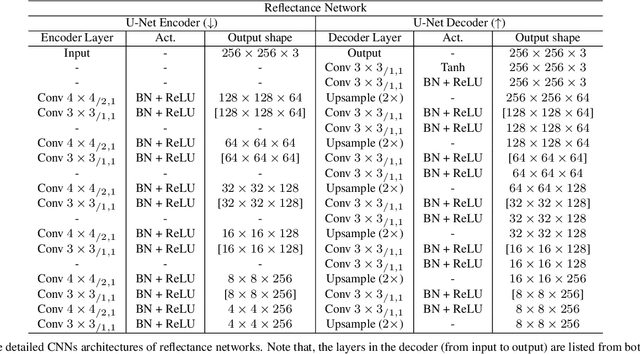
We present a conditional estimation (CEST) framework to learn 3D facial parameters from 2D single-view images by self-supervised training from videos. CEST is based on the process of analysis by synthesis, where the 3D facial parameters (shape, reflectance, viewpoint, and illumination) are estimated from the face image, and then recombined to reconstruct the 2D face image. In order to learn semantically meaningful 3D facial parameters without explicit access to their labels, CEST couples the estimation of different 3D facial parameters by taking their statistical dependency into account. Specifically, the estimation of any 3D facial parameter is not only conditioned on the given image, but also on the facial parameters that have already been derived. Moreover, the reflectance symmetry and consistency among the video frames are adopted to improve the disentanglement of facial parameters. Together with a novel strategy for incorporating the reflectance symmetry and consistency, CEST can be efficiently trained with in-the-wild video clips. Both qualitative and quantitative experiments demonstrate the effectiveness of CEST.