 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning and Crafting for the Wide Multiple Baseline Stereo
Dec 22, 2021

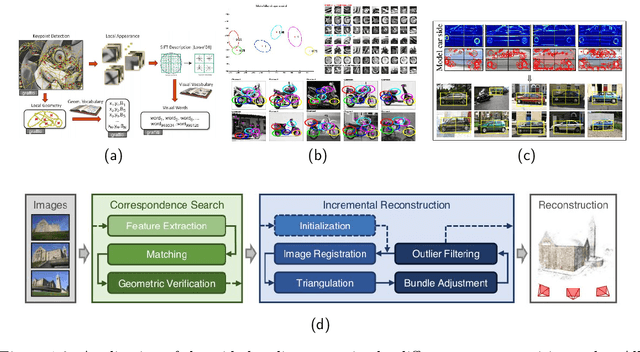
This thesis introduces the wide multiple baseline stereo (WxBS) problem. WxBS, a generalization of the standard wide baseline stereo problem, considers the matching of images that simultaneously differ in more than one image acquisition factor such as viewpoint, illumination, sensor type, or where object appearance changes significantly, e.g., over time. A new dataset with the ground truth, evaluation metric and baselines has been introduced. The thesis presents the following improvements of the WxBS pipeline. (i) A loss function, called HardNeg, for learning a local image descriptor that relies on hard negative mining within a mini-batch and on the maximization of the distance between the closest positive and the closest negative patches. (ii) The descriptor trained with the HardNeg loss, called HardNet, is compact and shows state-of-the-art performance in standard matching, patch verification and retrieval benchmarks. (iii) A method for learning the affine shape, orientation, and potentially other parameters related to geometric and appearance properties of local features. (iv) A tentative correspondences generation strategy which generalizes the standard first to second closest distance ratio is presented. The selection strategy, which shows performance superior to the standard method, is applicable to either hard-engineered descriptors like SIFT, LIOP, and MROGH or deeply learned like HardNet. (v) A feedback loop is introduced for the two-view matching problem, resulting in MODS -- matching with on-demand view synthesis -- algorithm. MODS is an algorithm that handles a viewing angle difference even larger than the previous state-of-the-art ASIFT algorithm, without a significant increase of computational cost over "standard" wide and narrow baseline approaches. Last, but not least, a comprehensive benchmark for local features and robust estimation algorithms is introduced.
Persistent Homology for Breast Tumor Classification using Mammogram Scans
Jan 07, 2022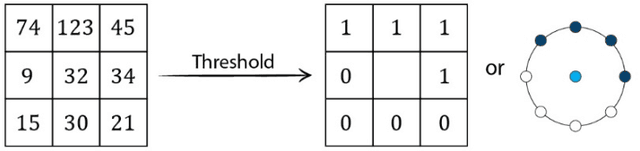
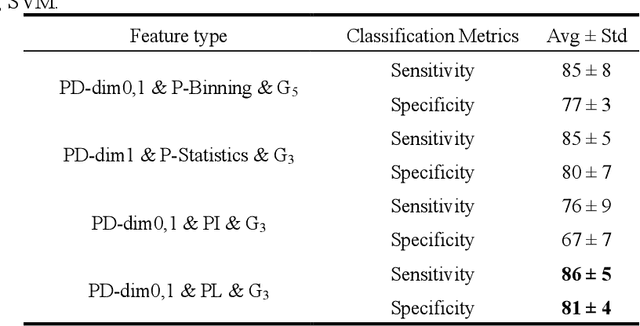

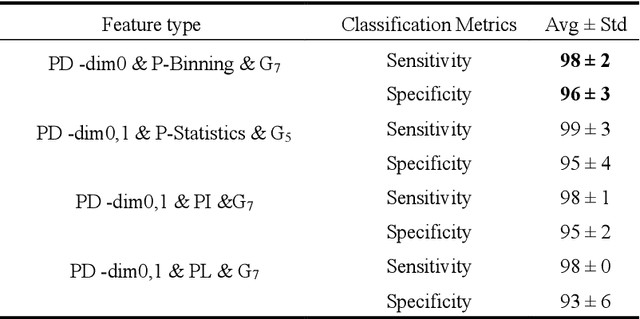
An Important tool in the field topological data analysis is known as persistent Homology (PH) which is used to encode abstract representation of the homology of data at different resolutions in the form of persistence diagram (PD). In this work we build more than one PD representation of a single image based on a landmark selection method, known as local binary patterns, that encode different types of local textures from images. We employed different PD vectorizations using persistence landscapes, persistence images, persistence binning (Betti Curve) and statistics. We tested the effectiveness of proposed landmark based PH on two publicly available breast abnormality detection datasets using mammogram scans. Sensitivity of landmark based PH obtained is over 90% in both datasets for the detection of abnormal breast scans. Finally, experimental results give new insights on using different types of PD vectorizations which help in utilising PH in conjunction with machine learning classifiers.
Self-Supervision based Task-Specific Image Collection Summarization
Jan 01, 2021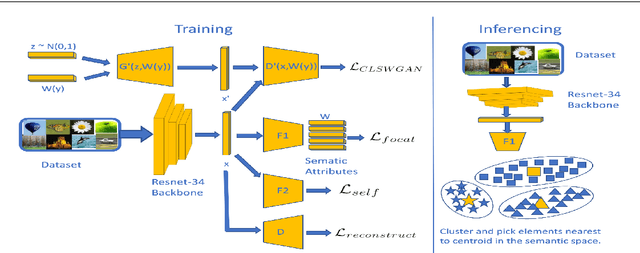
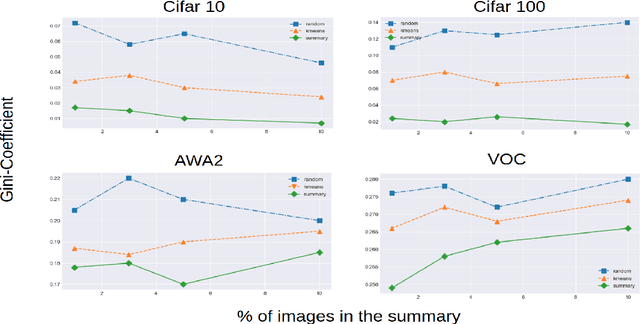
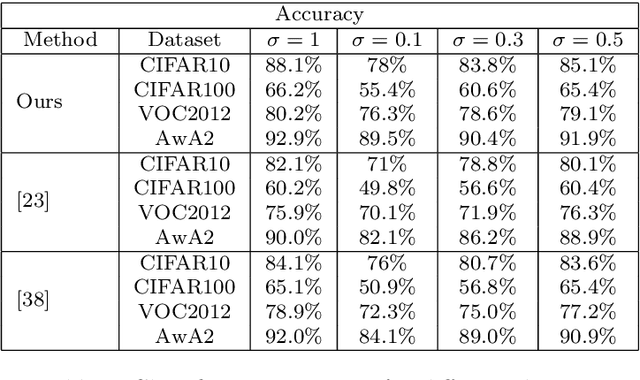
Successful applications of deep learning (DL) requires large amount of annotated data. This often restricts the benefits of employing DL to businesses and individuals with large budgets for data-collection and computation. Summarization offers a possible solution by creating much smaller representative datasets that can allow real-time deep learning and analysis of big data and thus democratize use of DL. In the proposed work, our aim is to explore a novel approach to task-specific image corpus summarization using semantic information and self-supervision. Our method uses a classification-based Wasserstein generative adversarial network (CLSWGAN) as a feature generating network. The model also leverages rotational invariance as self-supervision and classification on another task. All these objectives are added on a features from resnet34 to make it discriminative and robust. The model then generates a summary at inference time by using K-means clustering in the semantic embedding space. Thus, another main advantage of this model is that it does not need to be retrained each time to obtain summaries of different lengths which is an issue with current end-to-end models. We also test our model efficacy by means of rigorous experiments both qualitatively and quantitatively.
PhraseCut: Language-based Image Segmentation in the Wild
Aug 03, 2020We consider the problem of segmenting image regions given a natural language phrase, and study it on a novel dataset of 77,262 images and 345,486 phrase-region pairs. Our dataset is collected on top of the Visual Genome dataset and uses the existing annotations to generate a challenging set of referring phrases for which the corresponding regions are manually annotated. Phrases in our dataset correspond to multiple regions and describe a large number of object and stuff categories as well as their attributes such as color, shape, parts, and relationships with other entities in the image. Our experiments show that the scale and diversity of concepts in our dataset poses significant challenges to the existing state-of-the-art. We systematically handle the long-tail nature of these concepts and present a modular approach to combine category, attribute, and relationship cues that outperforms existing approaches.
How Robust are Discriminatively Trained Zero-Shot Learning Models?
Jan 27, 2022
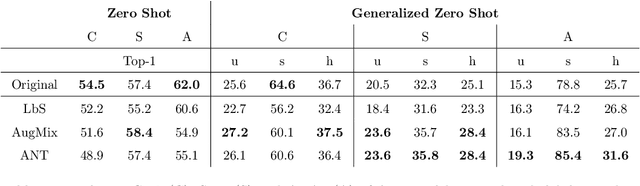
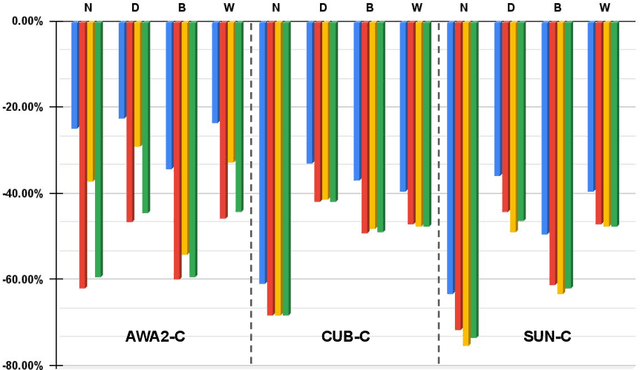
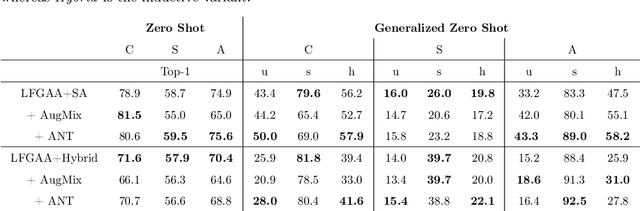
Data shift robustness has been primarily investigated from a fully supervised perspective, and robustness of zero-shot learning (ZSL) models have been largely neglected. In this paper, we present novel analyses on the robustness of discriminative ZSL to image corruptions. We subject several ZSL models to a large set of common corruptions and defenses. In order to realize the corruption analysis, we curate and release the first ZSL corruption robustness datasets SUN-C, CUB-C and AWA2-C. We analyse our results by taking into account the dataset characteristics, class imbalance, class transitions between seen and unseen classes and the discrepancies between ZSL and GZSL performances. Our results show that discriminative ZSL suffers from corruptions and this trend is further exacerbated by the severe class imbalance and model weakness inherent in ZSL methods. We then combine our findings with those based on adversarial attacks in ZSL, and highlight the different effects of corruptions and adversarial examples, such as the pseudo-robustness effect present under adversarial attacks. We also obtain new strong baselines for both models with the defense methods. Finally, our experiments show that although existing methods to improve robustness somewhat work for ZSL models, they do not produce a tangible effect.
Texture image classification based on a pseudo-parabolic diffusion model
Nov 14, 2020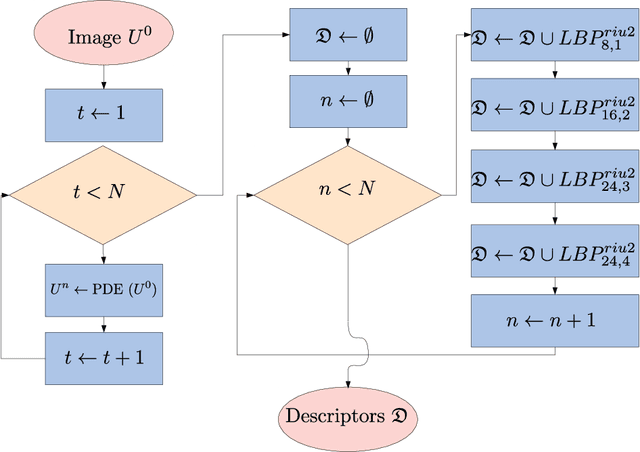
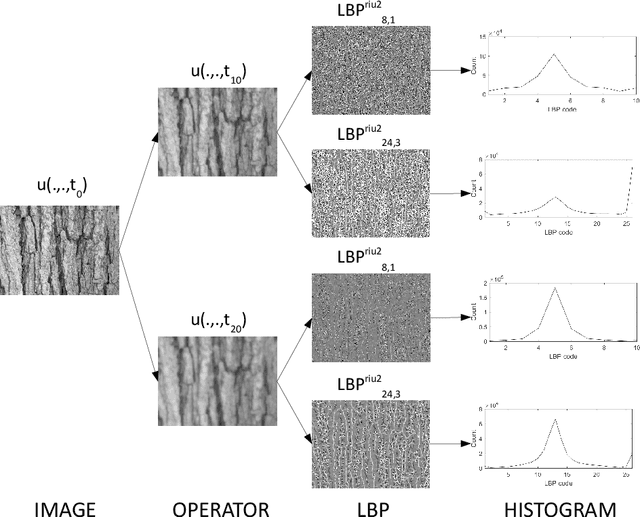
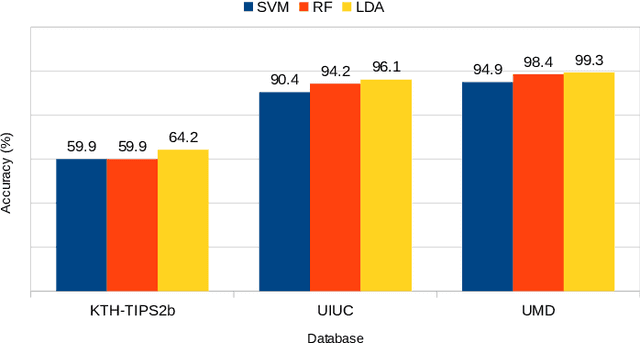
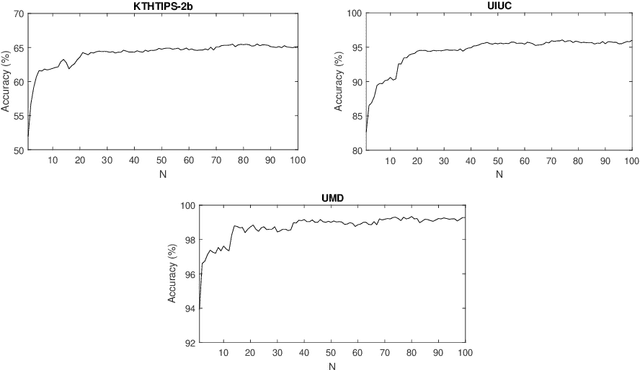
This work proposes a novel method based on a pseudo-parabolic diffusion process to be employed for texture recognition. The proposed operator is applied over a range of time scales giving rise to a family of images transformed by nonlinear filters. Therefore each of those images are encoded by a local descriptor (we use local binary patterns for that purpose) and they are summarized by a simple histogram, yielding in this way the image feature vector. The proposed approach is tested on the classification of well established benchmark texture databases and on a practical task of plant species recognition. In both cases, it is compared with several state-of-the-art methodologies employed for texture recognition. Our proposal outperforms those methods in terms of classification accuracy, confirming its competitiveness. The good performance can be justified to a large extent by the ability of the pseudo-parabolic operator to smooth possibly noisy details inside homogeneous regions of the image at the same time that it preserves discontinuities that convey critical information for the object description. Such results also confirm that model-based approaches like the proposed one can still be competitive with the omnipresent learning-based approaches, especially when the user does not have access to a powerful computational structure and a large amount of labeled data for training.
Source Free Domain Adaptation with Image Translation
Aug 17, 2020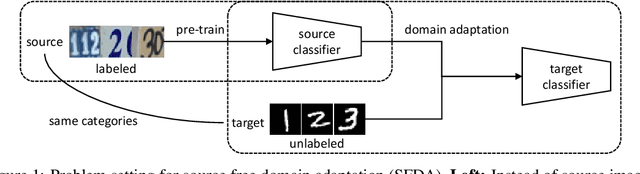

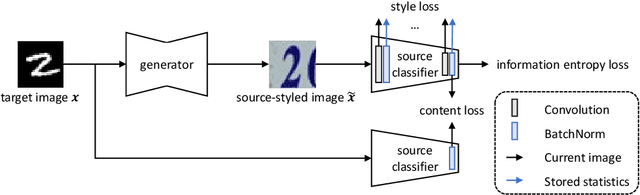
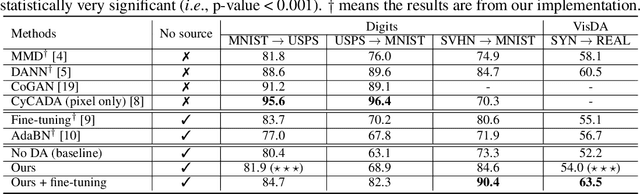
Effort in releasing large-scale datasets may be compromised by privacy and intellectual property considerations. A feasible alternative is to release pre-trained models instead. While these models are strong on their original task (source domain), their performance might degrade significantly when deployed directly in a new environment (target domain), which might not contain labels for training under realistic settings. Domain adaptation (DA) is a known solution to the domain gap problem, but usually requires labeled source data. In this paper, we study the problem of source free domain adaptation (SFDA), whose distinctive feature is that the source domain only provides a pre-trained model, but no source data. Being source free adds significant challenges to DA, especially when considering that the target dataset is unlabeled. To solve the SFDA problem, we propose an image translation approach that transfers the style of target images to that of unseen source images. To this end, we align the batch-wise feature statistics of generated images to that stored in batch normalization layers of the pre-trained model. Compared with directly classifying target images, higher accuracy is obtained with these style transferred images using the pre-trained model. On several image classification datasets, we show that the above-mentioned improvements are consistent and statistically significant.
CAN3D: Fast 3D Medical Image Segmentation via Compact Context Aggregation
Sep 22, 2021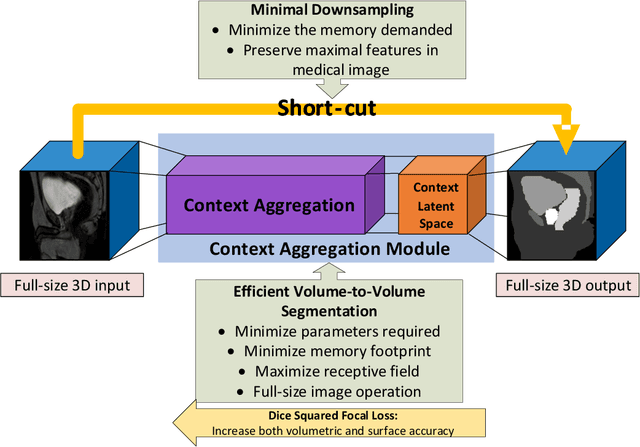

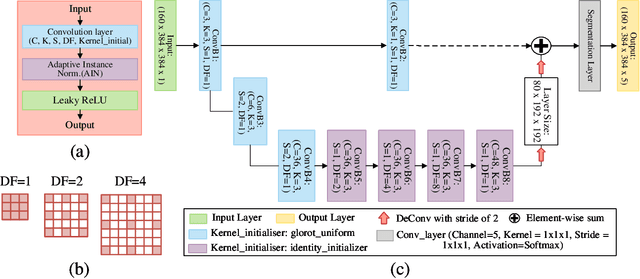
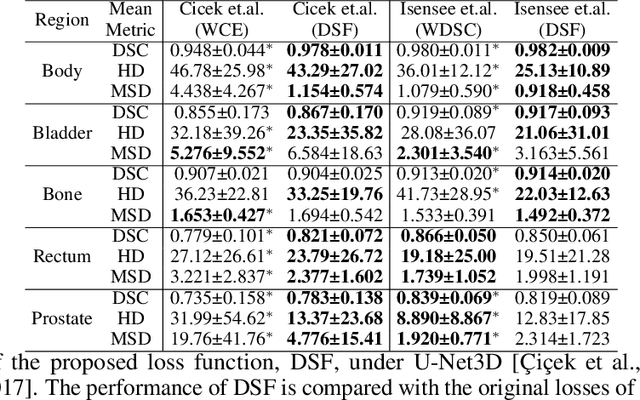
Direct automatic segmentation of objects from 3D medical imaging, such as magnetic resonance (MR) imaging, is challenging as it often involves accurately identifying a number of individual objects with complex geometries within a large volume under investigation. To address these challenges, most deep learning approaches typically enhance their learning capability by substantially increasing the complexity or the number of trainable parameters within their models. Consequently, these models generally require long inference time on standard workstations operating clinical MR systems and are restricted to high-performance computing hardware due to their large memory requirement. Further, to fit 3D dataset through these large models using limited computer memory, trade-off techniques such as patch-wise training are often used which sacrifice the fine-scale geometric information from input images which could be clinically significant for diagnostic purposes. To address these challenges, we present a compact convolutional neural network with a shallow memory footprint to efficiently reduce the number of model parameters required for state-of-art performance. This is critical for practical employment as most clinical environments only have low-end hardware with limited computing power and memory. The proposed network can maintain data integrity by directly processing large full-size 3D input volumes with no patches required and significantly reduces the computational time required for both training and inference. We also propose a novel loss function with extra shape constraint to improve the accuracy for imbalanced classes in 3D MR images.
Iterative Network for Image Super-Resolution
May 20, 2020
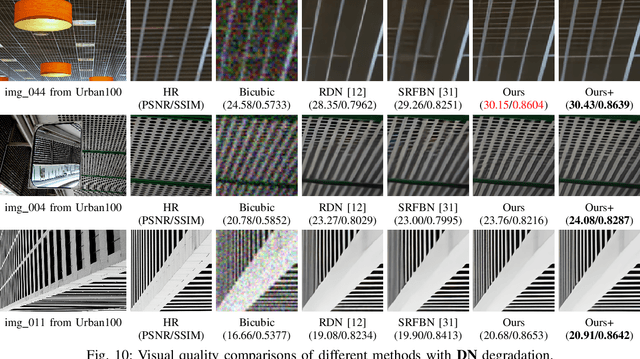
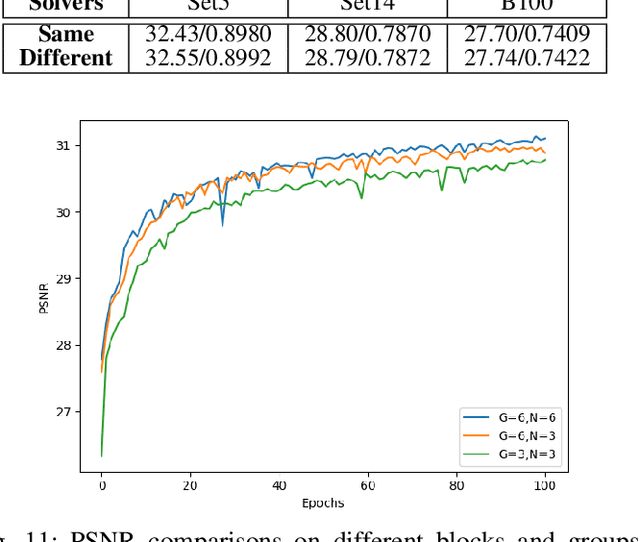
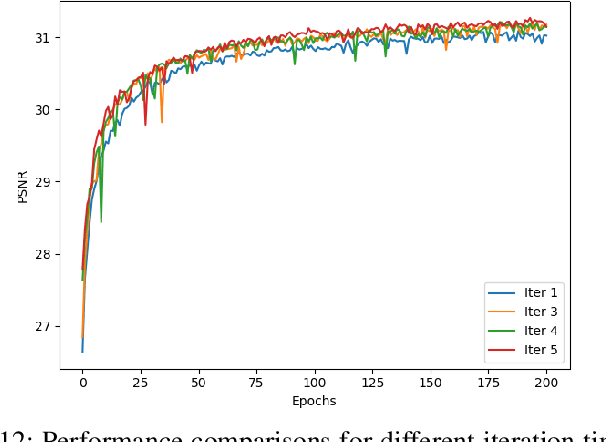
Single image super-resolution (SISR), as a traditional ill-conditioned inverse problem, has been greatly revitalized by the recent development of convolutional neural networks (CNN). These CNN-based methods generally map a low-resolution image to its corresponding high-resolution version with sophisticated network structures and loss functions, showing impressive performances. This paper proposes a substantially different approach relying on the iterative optimization on HR space with an iterative super-resolution network (ISRN). We first analyze the observation model of image SR problem, inspiring a feasible solution by mimicking and fusing each iteration in a more general and efficient manner. Considering the drawbacks of batch normalization, we propose a feature normalization (FNorm) method to regulate the features in network. Furthermore, a novel block with F-Norm is developed to improve the network representation, termed as FNB. Residual-in-residual structure is proposed to form a very deep network, which groups FNBs with a long skip connection for better information delivery and stabling the training phase. Extensive experimental results on testing benchmarks with bicubic (BI) degradation show our ISRN can not only recover more structural information, but also achieve competitive or better PSNR/SSIM results with much fewer parameters compared to other works. Besides BI, we simulate the real-world degradation with blur-downscale (BD) and downscalenoise (DN). ISRN and its extension ISRN+ both achieve better performance than others with BD and DN degradation models.
Learning RAW-to-sRGB Mappings with Inaccurately Aligned Supervision
Aug 18, 2021
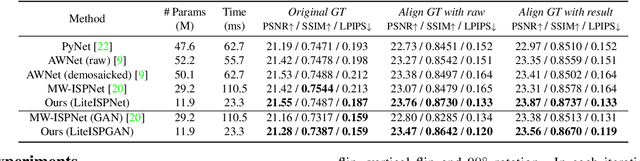
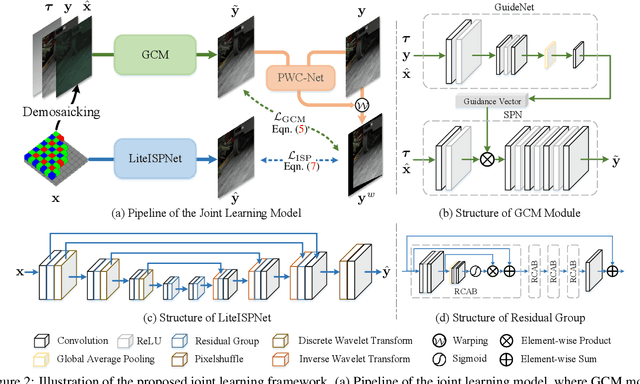
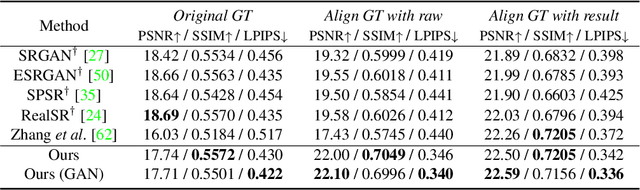
Learning RAW-to-sRGB mapping has drawn increasing attention in recent years, wherein an input raw image is trained to imitate the target sRGB image captured by another camera. However, the severe color inconsistency makes it very challenging to generate well-aligned training pairs of input raw and target sRGB images. While learning with inaccurately aligned supervision is prone to causing pixel shift and producing blurry results. In this paper, we circumvent such issue by presenting a joint learning model for image alignment and RAW-to-sRGB mapping. To diminish the effect of color inconsistency in image alignment, we introduce to use a global color mapping (GCM) module to generate an initial sRGB image given the input raw image, which can keep the spatial location of the pixels unchanged, and the target sRGB image is utilized to guide GCM for converting the color towards it. Then a pre-trained optical flow estimation network (e.g., PWC-Net) is deployed to warp the target sRGB image to align with the GCM output. To alleviate the effect of inaccurately aligned supervision, the warped target sRGB image is leveraged to learn RAW-to-sRGB mapping. When training is done, the GCM module and optical flow network can be detached, thereby bringing no extra computation cost for inference. Experiments show that our method performs favorably against state-of-the-arts on ZRR and SR-RAW datasets. With our joint learning model, a light-weight backbone can achieve better quantitative and qualitative performance on ZRR dataset. Codes are available at https://github.com/cszhilu1998/RAW-to-sRGB.