 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NormalGAN: Learning Detailed 3D Human from a Single RGB-D Image
Jul 30, 2020

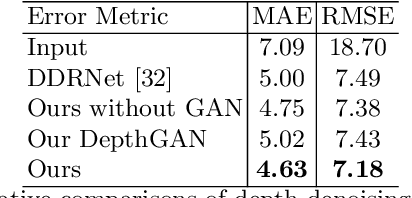
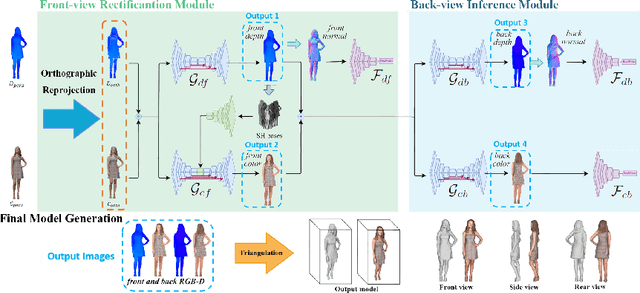

We propose NormalGAN, a fast adversarial learning-based method to reconstruct the complete and detailed 3D human from a single RGB-D image. Given a single front-view RGB-D image, NormalGAN performs two steps: front-view RGB-D rectification and back-view RGBD inference. The final model was then generated by simply combining the front-view and back-view RGB-D information. However, inferring backview RGB-D image with high-quality geometric details and plausible texture is not trivial. Our key observation is: Normal maps generally encode much more information of 3D surface details than RGB and depth images. Therefore, learning geometric details from normal maps is superior than other representations. In NormalGAN, an adversarial learning framework conditioned by normal maps is introduced, which is used to not only improve the front-view depth denoising performance, but also infer the back-view depth image with surprisingly geometric details. Moreover, for texture recovery, we remove shading information from the front-view RGB image based on the refined normal map, which further improves the quality of the back-view color inference. Results and experiments on both testing data set and real captured data demonstrate the superior performance of our approach. Given a consumer RGB-D sensor, NormalGAN can generate the complete and detailed 3D human reconstruction results in 20 fps, which further enables convenient interactive experiences in telepresence, AR/VR and gaming scenarios.
Signature-Graph Networks
Oct 22, 2021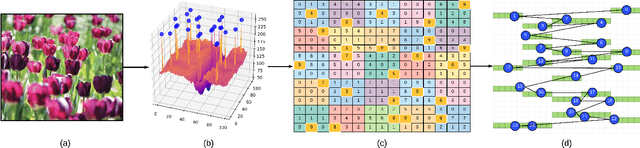
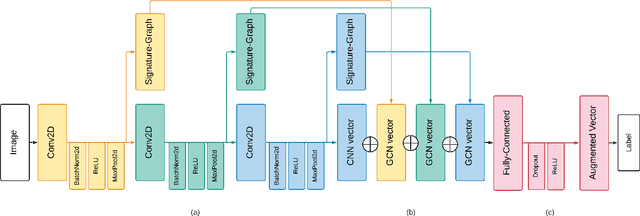
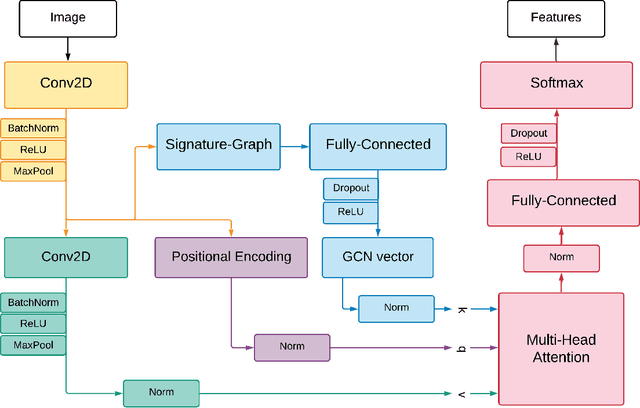
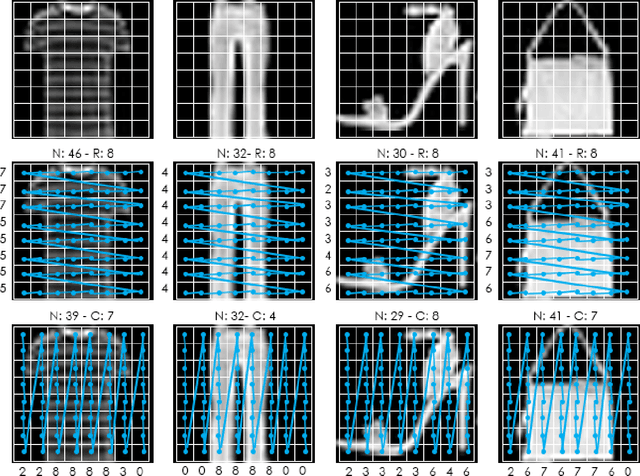
We propose a novel approach for visual representation learning called Signature-Graph Neural Networks (SGN). SGN learns latent global structures that augment the feature representation of Convolutional Neural Networks (CNN). SGN constructs unique undirected graphs for each image based on the CNN feature maps. The feature maps are partitioned into a set of equal and non-overlapping patches. The graph nodes are located on high-contrast sharp convolution features with the local maxima or minima in these patches. The node embeddings are aggregated through novel Signature-Graphs based on horizontal and vertical edge connections. The representation vectors are then computed based on the spectral Laplacian eigenvalues of the graphs. SGN outperforms existing methods of recent graph convolutional networks, generative adversarial networks, and auto-encoders with image classification accuracy of 99.65% on ASIRRA, 99.91% on MNIST, 98.55% on Fashion-MNIST, 96.18% on CIFAR-10, 84.71% on CIFAR-100, 94.36% on STL10, and 95.86% on SVHN datasets. We also introduce a novel implementation of the state-of-the-art multi-head attention (MHA) on top of the proposed SGN. Adding SGN to MHA improved the image classification accuracy from 86.92% to 94.36% on the STL10 dataset
Unsupervised Landmark Detection Based Spatiotemporal Motion Estimation for 4D Dynamic Medical Images
Sep 30, 2021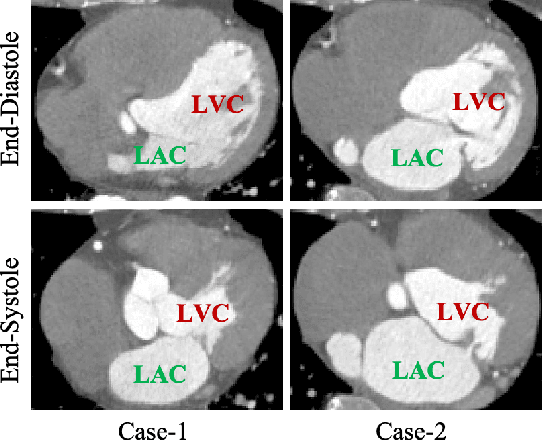

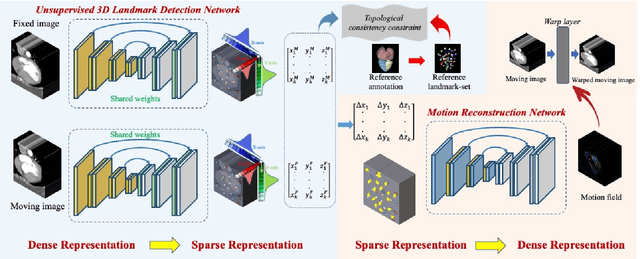
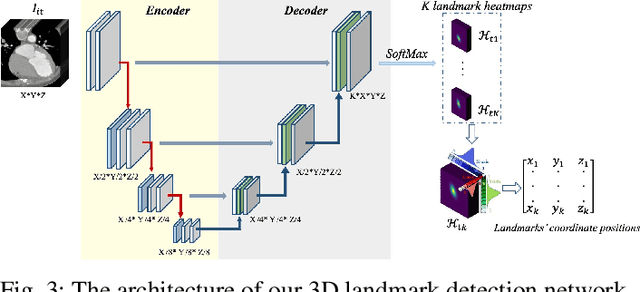
Motion estimation is a fundamental step in dynamic medical image processing for the assessment of target organ anatomy and function. However, existing image-based motion estimation methods, which optimize the motion field by evaluating the local image similarity, are prone to produce implausible estimation, especially in the presence of large motion. In this study, we provide a novel motion estimation framework of Dense-Sparse-Dense (DSD), which comprises two stages. In the first stage, we process the raw dense image to extract sparse landmarks to represent the target organ anatomical topology and discard the redundant information that is unnecessary for motion estimation. For this purpose, we introduce an unsupervised 3D landmark detection network to extract spatially sparse but representative landmarks for the target organ motion estimation. In the second stage, we derive the sparse motion displacement from the extracted sparse landmarks of two images of different time points. Then, we present a motion reconstruction network to construct the motion field by projecting the sparse landmarks displacement back into the dense image domain. Furthermore, we employ the estimated motion field from our two-stage DSD framework as initialization and boost the motion estimation quality in light-weight yet effective iterative optimization. We evaluate our method on two dynamic medical imaging tasks to model cardiac motion and lung respiratory motion, respectively. Our method has produced superior motion estimation accuracy compared to existing comparative methods. Besides, the extensive experimental results demonstrate that our solution can extract well representative anatomical landmarks without any requirement of manual annotation. Our code is publicly available online.
ADMM-DAD net: a deep unfolding network for analysis compressed sensing
Oct 13, 2021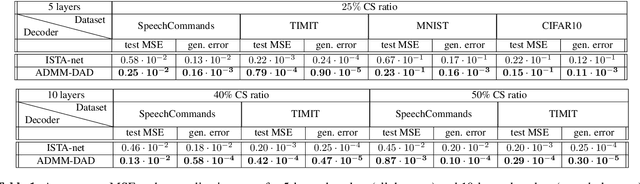
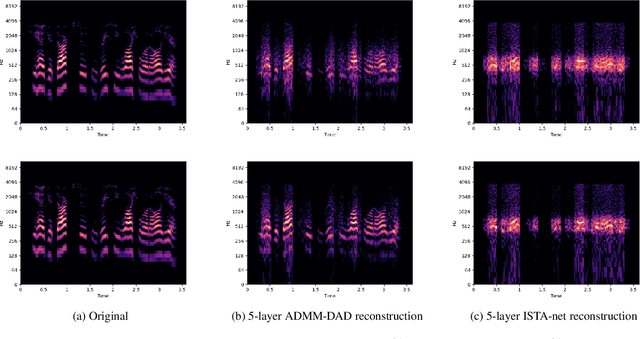

In this paper, we propose a new deep unfolding neural network based on the ADMM algorithm for analysis Compressed Sensing. The proposed network jointly learns a redundant analysis operator for sparsification and reconstructs the signal of interest. We compare our proposed network with a state-of-the-art unfolded ISTA decoder, that also learns an orthogonal sparsifier. Moreover, we consider not only image, but also speech datasets as test examples. Computational experiments demonstrate that our proposed network outperforms the state-of-the-art deep unfolding networks, consistently for both real-world image and speech datasets.
FORML: Learning to Reweight Data for Fairness
Feb 03, 2022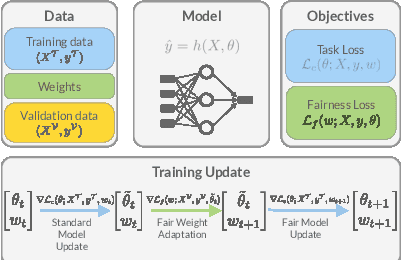

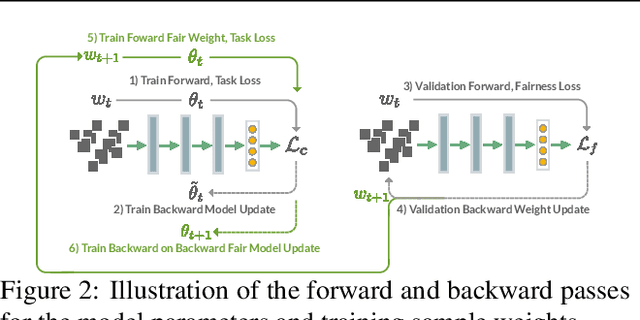
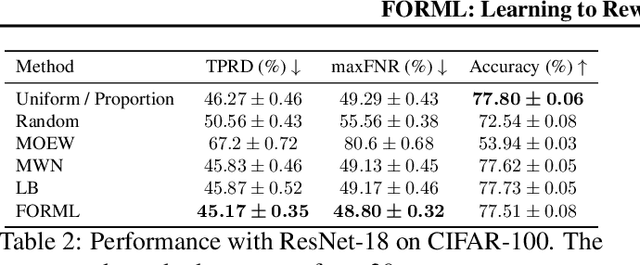
Deployed machine learning models are evaluated by multiple metrics beyond accuracy, such as fairness and robustness. However, such models are typically trained to minimize the average loss for a single metric, which is typically a proxy for accuracy. Training to optimize a single metric leaves these models prone to fairness violations, especially when the population of sub-groups in the training data are imbalanced. This work addresses the challenge of jointly optimizing fairness and predictive performance in the multi-class classification setting by introducing Fairness Optimized Reweighting via Meta-Learning (FORML), a training algorithm that balances fairness constraints and accuracy by jointly optimizing training sample weights and a neural network's parameters. The approach increases fairness by learning to weight each training datum's contribution to the loss according to its impact on reducing fairness violations, balancing the contributions from both over- and under-represented sub-groups. We empirically validate FORML on a range of benchmark and real-world classification datasets and show that our approach improves equality of opportunity fairness criteria over existing state-of-the-art reweighting methods by approximately 1% on image classification tasks and by approximately 5% on a face attribute prediction task. This improvement is achieved without pre-processing data or post-processing model outputs, without learning an additional weighting function, and while maintaining accuracy on the original predictive metric.
Learning to Represent Image and Text with Denotation Graph
Oct 06, 2020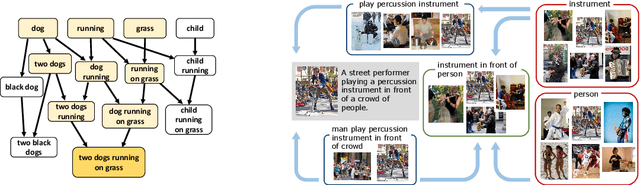

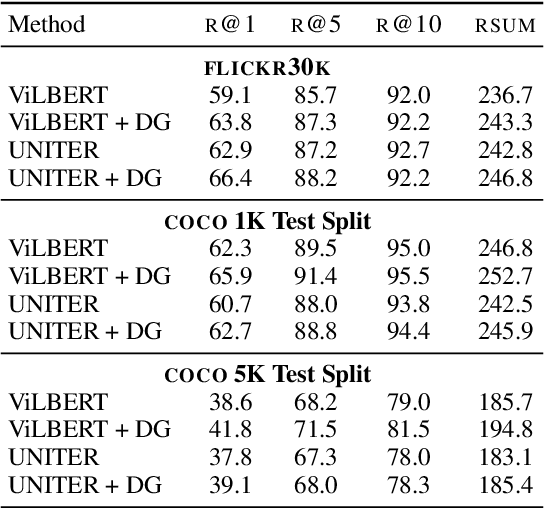
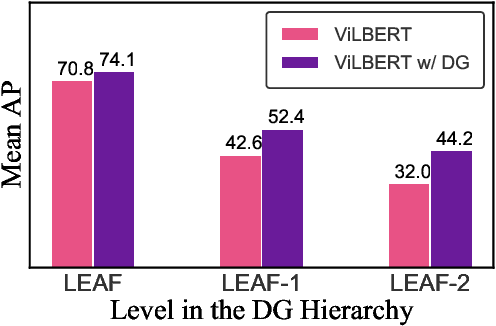
Learning to fuse vision and language information and representing them is an important research problem with many applications. Recent progresses have leveraged the ideas of pre-training (from language modeling) and attention layers in Transformers to learn representation from datasets containing images aligned with linguistic expressions that describe the images. In this paper, we propose learning representations from a set of implied, visually grounded expressions between image and text, automatically mined from those datasets. In particular, we use denotation graphs to represent how specific concepts (such as sentences describing images) can be linked to abstract and generic concepts (such as short phrases) that are also visually grounded. This type of generic-to-specific relations can be discovered using linguistic analysis tools. We propose methods to incorporate such relations into learning representation. We show that state-of-the-art multimodal learning models can be further improved by leveraging automatically harvested structural relations. The representations lead to stronger empirical results on downstream tasks of cross-modal image retrieval, referring expression, and compositional attribute-object recognition. Both our codes and the extracted denotation graphs on the Flickr30K and the COCO datasets are publically available on https://sha-lab.github.io/DG.
Self-Play Reinforcement Learning for Fast Image Retargeting
Oct 02, 2020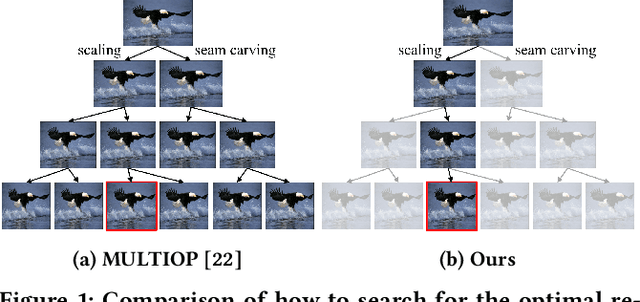
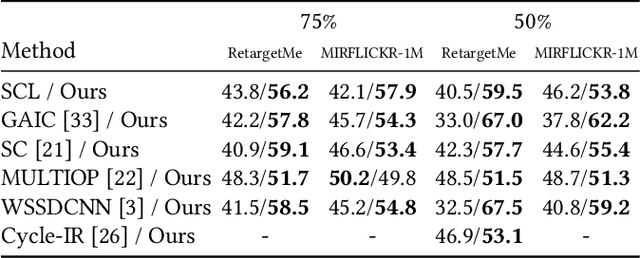
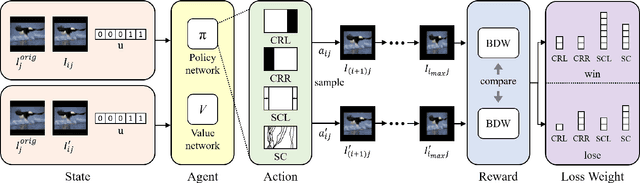
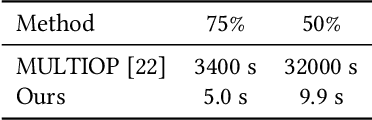
In this study, we address image retargeting, which is a task that adjusts input images to arbitrary sizes. In one of the best-performing methods called MULTIOP, multiple retargeting operators were combined and retargeted images at each stage were generated to find the optimal sequence of operators that minimized the distance between original and retargeted images. The limitation of this method is in its tremendous processing time, which severely prohibits its practical use. Therefore, the purpose of this study is to find the optimal combination of operators within a reasonable processing time; we propose a method of predicting the optimal operator for each step using a reinforcement learning agent. The technical contributions of this study are as follows. Firstly, we propose a reward based on self-play, which will be insensitive to the large variance in the content-dependent distance measured in MULTIOP. Secondly, we propose to dynamically change the loss weight for each action to prevent the algorithm from falling into a local optimum and from choosing only the most frequently used operator in its training. Our experiments showed that we achieved multi-operator image retargeting with less processing time by three orders of magnitude and the same quality as the original multi-operator-based method, which was the best-performing algorithm in retargeting tasks.
Learning strides in convolutional neural networks
Feb 03, 2022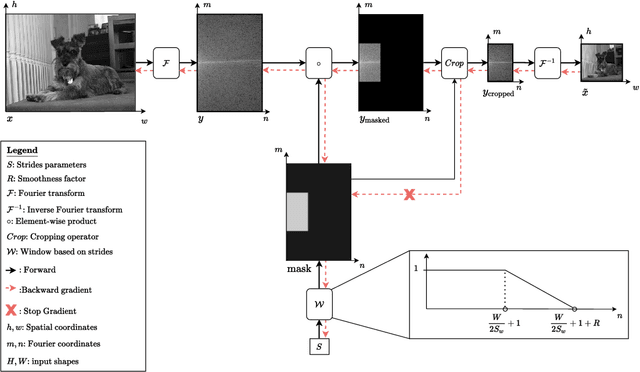
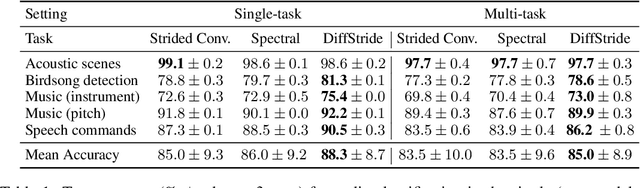
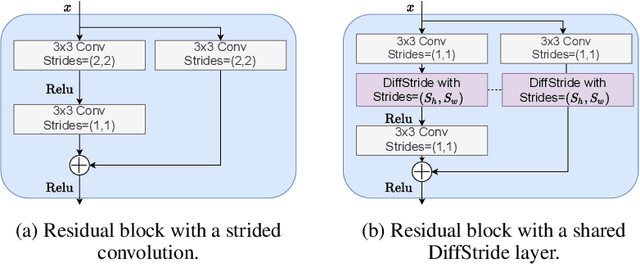
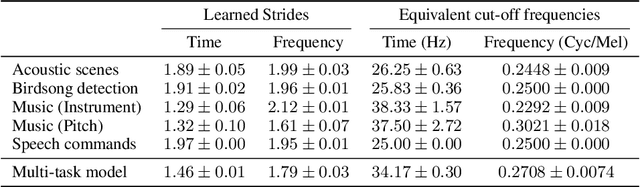
Convolutional neural networks typically contain several downsampling operators, such as strided convolutions or pooling layers, that progressively reduce the resolution of intermediate representations. This provides some shift-invariance while reducing the computational complexity of the whole architecture. A critical hyperparameter of such layers is their stride: the integer factor of downsampling. As strides are not differentiable, finding the best configuration either requires cross-validation or discrete optimization (e.g. architecture search), which rapidly become prohibitive as the search space grows exponentially with the number of downsampling layers. Hence, exploring this search space by gradient descent would allow finding better configurations at a lower computational cost. This work introduces DiffStride, the first downsampling layer with learnable strides. Our layer learns the size of a cropping mask in the Fourier domain, that effectively performs resizing in a differentiable way. Experiments on audio and image classification show the generality and effectiveness of our solution: we use DiffStride as a drop-in replacement to standard downsampling layers and outperform them. In particular, we show that introducing our layer into a ResNet-18 architecture allows keeping consistent high performance on CIFAR10, CIFAR100 and ImageNet even when training starts from poor random stride configurations. Moreover, formulating strides as learnable variables allows us to introduce a regularization term that controls the computational complexity of the architecture. We show how this regularization allows trading off accuracy for efficiency on ImageNet.
Multi-Stage Residual Hiding for Image-into-Audio Steganography
Jan 06, 2021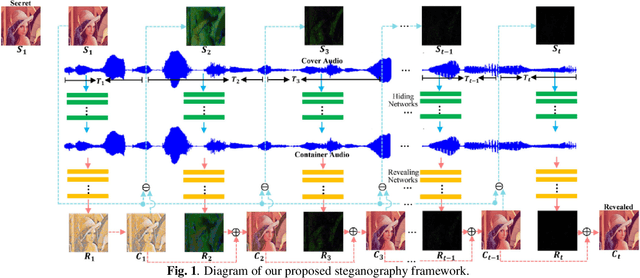
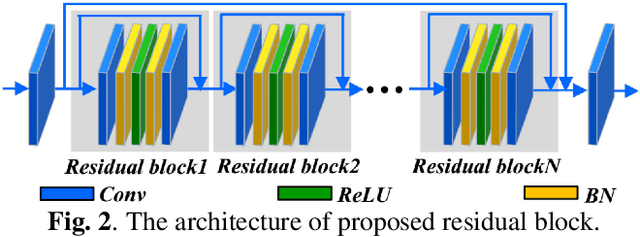
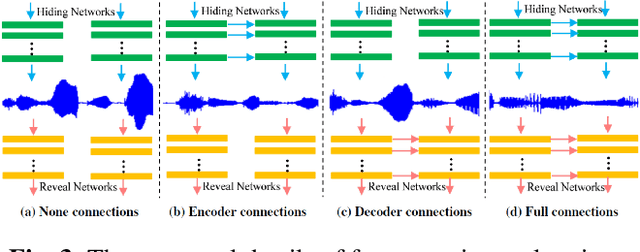
The widespread application of audio communication technologies has speeded up audio data flowing across the Internet, which made it a popular carrier for covert communication. In this paper, we present a cross-modal steganography method for hiding image content into audio carriers while preserving the perceptual fidelity of the cover audio. In our framework, two multi-stage networks are designed: the first network encodes the decreasing multilevel residual errors inside different audio subsequences with the corresponding stage sub-networks, while the second network decodes the residual errors from the modified carrier with the corresponding stage sub-networks to produce the final revealed results. The multi-stage design of proposed framework not only make the controlling of payload capacity more flexible, but also make hiding easier because of the gradual sparse characteristic of residual errors. Qualitative experiments suggest that modifications to the carrier are unnoticeable by human listeners and that the decoded images are highly intelligible.
PE-former: Pose Estimation Transformer
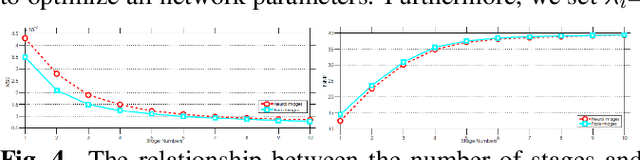
Dec 09, 2021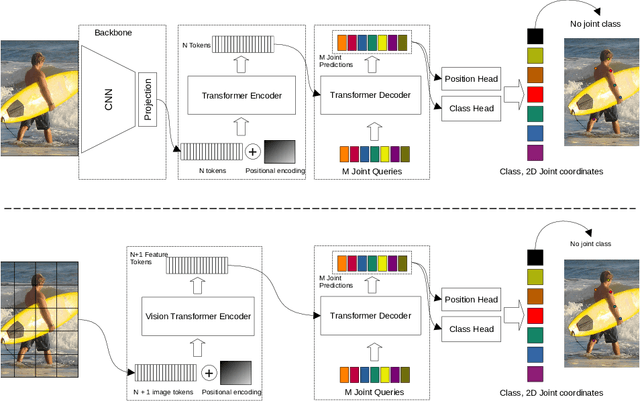
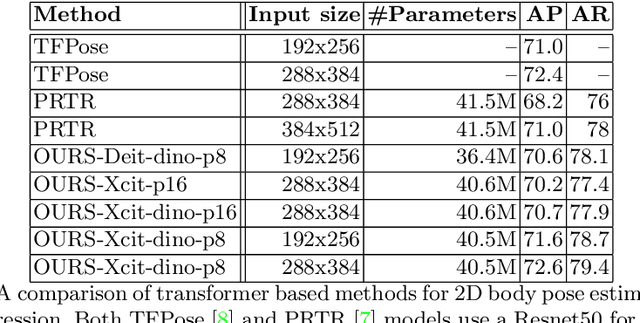
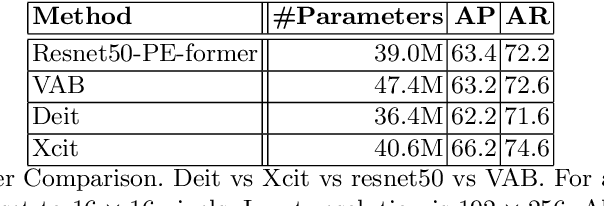
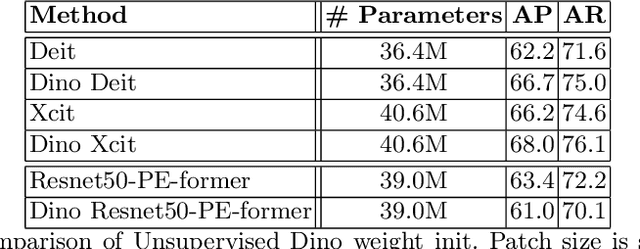
Vision transformer architectures have been demonstrated to work very effectively for image classification tasks. Efforts to solve more challenging vision tasks with transformers rely on convolutional backbones for feature extraction. In this paper we investigate the use of a pure transformer architecture (i.e., one with no CNN backbone) for the problem of 2D body pose estimation. We evaluate two ViT architectures on the COCO dataset. We demonstrate that using an encoder-decoder transformer architecture yields state of the art results on this estimation problem.