 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SGDFormer: One-stage Transformer-based Architecture for Cross-Spectral Stereo Image Guided Denoising
Mar 30, 2024
Cross-spectral image guided denoising has shown its great potential in recovering clean images with rich details, such as using the near-infrared image to guide the denoising process of the visible one. To obtain such image pairs, a feasible and economical way is to employ a stereo system, which is widely used on mobile devices. Current works attempt to generate an aligned guidance image to handle the disparity between two images. However, due to occlusion, spectral differences and noise degradation, the aligned guidance image generally exists ghosting and artifacts, leading to an unsatisfactory denoised result. To address this issue, we propose a one-stage transformer-based architecture, named SGDFormer, for cross-spectral Stereo image Guided Denoising. The architecture integrates the correspondence modeling and feature fusion of stereo images into a unified network. Our transformer block contains a noise-robust cross-attention (NRCA) module and a spatially variant feature fusion (SVFF) module. The NRCA module captures the long-range correspondence of two images in a coarse-to-fine manner to alleviate the interference of noise. The SVFF module further enhances salient structures and suppresses harmful artifacts through dynamically selecting useful information. Thanks to the above design, our SGDFormer can restore artifact-free images with fine structures, and achieves state-of-the-art performance on various datasets. Additionally, our SGDFormer can be extended to handle other unaligned cross-model guided restoration tasks such as guided depth super-resolution.
RecDiffusion: Rectangling for Image Stitching with Diffusion Models
Mar 28, 2024Image stitching from different captures often results in non-rectangular boundaries, which is often considered unappealing. To solve non-rectangular boundaries, current solutions involve cropping, which discards image content, inpainting, which can introduce unrelated content, or warping, which can distort non-linear features and introduce artifacts. To overcome these issues, we introduce a novel diffusion-based learning framework, \textbf{RecDiffusion}, for image stitching rectangling. This framework combines Motion Diffusion Models (MDM) to generate motion fields, effectively transitioning from the stitched image's irregular borders to a geometrically corrected intermediary. Followed by Content Diffusion Models (CDM) for image detail refinement. Notably, our sampling process utilizes a weighted map to identify regions needing correction during each iteration of CDM. Our RecDiffusion ensures geometric accuracy and overall visual appeal, surpassing all previous methods in both quantitative and qualitative measures when evaluated on public benchmarks. Code is released at https://github.com/lhaippp/RecDiffusion.
StoryImager: A Unified and Efficient Framework for Coherent Story Visualization and Completion
Apr 09, 2024Story visualization aims to generate a series of realistic and coherent images based on a storyline. Current models adopt a frame-by-frame architecture by transforming the pre-trained text-to-image model into an auto-regressive manner. Although these models have shown notable progress, there are still three flaws. 1) The unidirectional generation of auto-regressive manner restricts the usability in many scenarios. 2) The additional introduced story history encoders bring an extremely high computational cost. 3) The story visualization and continuation models are trained and inferred independently, which is not user-friendly. To these ends, we propose a bidirectional, unified, and efficient framework, namely StoryImager. The StoryImager enhances the storyboard generative ability inherited from the pre-trained text-to-image model for a bidirectional generation. Specifically, we introduce a Target Frame Masking Strategy to extend and unify different story image generation tasks. Furthermore, we propose a Frame-Story Cross Attention Module that decomposes the cross attention for local fidelity and global coherence. Moreover, we design a Contextual Feature Extractor to extract contextual information from the whole storyline. The extensive experimental results demonstrate the excellent performance of our StoryImager. The code is available at https://github.com/tobran/StoryImager.
SCINeRF: Neural Radiance Fields from a Snapshot Compressive Image
Mar 29, 2024
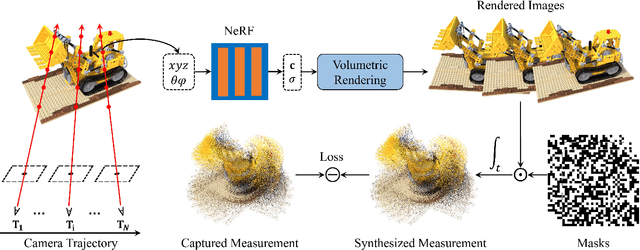


In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene representation from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, which not only reduces storage requirements but also offers potential privacy protection. Inspired by this, to take one step further, our approach builds upon the powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Extensive experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view image synthesis. Moreover, our method also exhibits the ability to restore high frame-rate multi-view consistent images by leveraging SCI and the rendering capabilities of NeRF. The code is available at https://github.com/WU-CVGL/SCINeRF.
Semantically-correlated memories in a dense associative model
Apr 11, 2024I introduce a novel associative memory model named Correlated Dense Associative Memory (CDAM), which integrates both auto- and hetero-association in a unified framework for continuous-valued memory patterns. Employing an arbitrary graph structure to semantically link memory patterns, CDAM is theoretically and numerically analysed, revealing four distinct dynamical modes: auto-association, narrow hetero-association, wide hetero-association, and neutral quiescence. Drawing inspiration from inhibitory modulation studies, I employ anti-Hebbian learning rules to control the range of hetero-association, extract multi-scale representations of community structures in graphs, and stabilise the recall of temporal sequences. Experimental demonstrations showcase CDAM's efficacy in handling real-world data, replicating a classical neuroscience experiment, performing image retrieval, and simulating arbitrary finite automata.
Getting it Right: Improving Spatial Consistency in Text-to-Image Models
Apr 01, 2024One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance. First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships. To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images. Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.
RSMamba: Remote Sensing Image Classification with State Space Model
Mar 28, 2024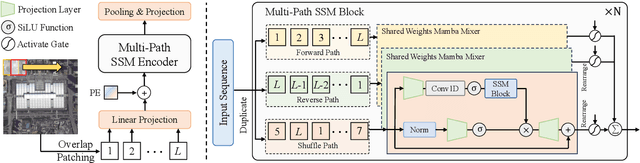
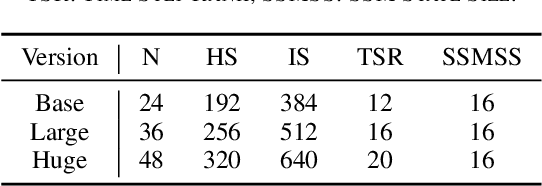
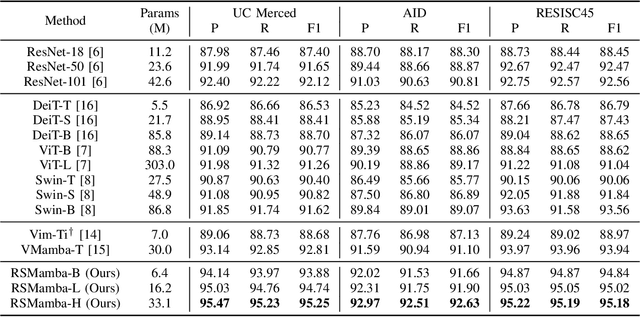
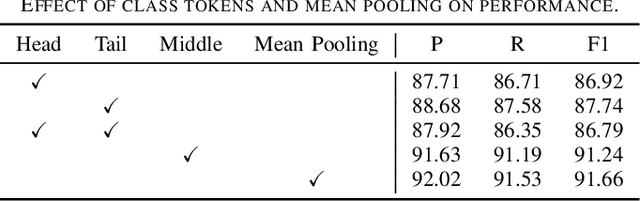
Remote sensing image classification forms the foundation of various understanding tasks, serving a crucial function in remote sensing image interpretation. The recent advancements of Convolutional Neural Networks (CNNs) and Transformers have markedly enhanced classification accuracy. Nonetheless, remote sensing scene classification remains a significant challenge, especially given the complexity and diversity of remote sensing scenarios and the variability of spatiotemporal resolutions. The capacity for whole-image understanding can provide more precise semantic cues for scene discrimination. In this paper, we introduce RSMamba, a novel architecture for remote sensing image classification. RSMamba is based on the State Space Model (SSM) and incorporates an efficient, hardware-aware design known as the Mamba. It integrates the advantages of both a global receptive field and linear modeling complexity. To overcome the limitation of the vanilla Mamba, which can only model causal sequences and is not adaptable to two-dimensional image data, we propose a dynamic multi-path activation mechanism to augment Mamba's capacity to model non-causal data. Notably, RSMamba maintains the inherent modeling mechanism of the vanilla Mamba, yet exhibits superior performance across multiple remote sensing image classification datasets. This indicates that RSMamba holds significant potential to function as the backbone of future visual foundation models. The code will be available at \url{https://github.com/KyanChen/RSMamba}.
JSTR: Judgment Improves Scene Text Recognition
Apr 09, 2024In this paper, we present a method for enhancing the accuracy of scene text recognition tasks by judging whether the image and text match each other. While previous studies focused on generating the recognition results from input images, our approach also considers the model's misrecognition results to understand its error tendencies, thus improving the text recognition pipeline. This method boosts text recognition accuracy by providing explicit feedback on the data that the model is likely to misrecognize by predicting correct or incorrect between the image and text. The experimental results on publicly available datasets demonstrate that our proposed method outperforms the baseline and state-of-the-art methods in scene text recognition.
Mitigating Challenges of the Space Environment for Onboard Artificial Intelligence: Design Overview of the Imaging Payload on SpIRIT
Apr 12, 2024Artificial intelligence (AI) and autonomous edge computing in space are emerging areas of interest to augment capabilities of nanosatellites, where modern sensors generate orders of magnitude more data than can typically be transmitted to mission control. Here, we present the hardware and software design of an onboard AI subsystem hosted on SpIRIT. The system is optimised for on-board computer vision experiments based on visible light and long wave infrared cameras. This paper highlights the key design choices made to maximise the robustness of the system in harsh space conditions, and their motivation relative to key mission requirements, such as limited compute resources, resilience to cosmic radiation, extreme temperature variations, distribution shifts, and very low transmission bandwidths. The payload, called Loris, consists of six visible light cameras, three infrared cameras, a camera control board and a Graphics Processing Unit (GPU) system-on-module. Loris enables the execution of AI models with on-orbit fine-tuning as well as a next-generation image compression algorithm, including progressive coding. This innovative approach not only enhances the data processing capabilities of nanosatellites but also lays the groundwork for broader applications to remote sensing from space.
Scaling (Down) CLIP: A Comprehensive Analysis of Data, Architecture, and Training Strategies
Apr 12, 2024This paper investigates the performance of the Contrastive Language-Image Pre-training (CLIP) when scaled down to limited computation budgets. We explore CLIP along three dimensions: data, architecture, and training strategies. With regards to data, we demonstrate the significance of high-quality training data and show that a smaller dataset of high-quality data can outperform a larger dataset with lower quality. We also examine how model performance varies with different dataset sizes, suggesting that smaller ViT models are better suited for smaller datasets, while larger models perform better on larger datasets with fixed compute. Additionally, we provide guidance on when to choose a CNN-based architecture or a ViT-based architecture for CLIP training. We compare four CLIP training strategies - SLIP, FLIP, CLIP, and CLIP+Data Augmentation - and show that the choice of training strategy depends on the available compute resource. Our analysis reveals that CLIP+Data Augmentation can achieve comparable performance to CLIP using only half of the training data. This work provides practical insights into how to effectively train and deploy CLIP models, making them more accessible and affordable for practical use in various applications.