 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Operationalizing Convolutional Neural Network Architectures for Prohibited Object Detection in X-Ray Imagery
Oct 10, 2021
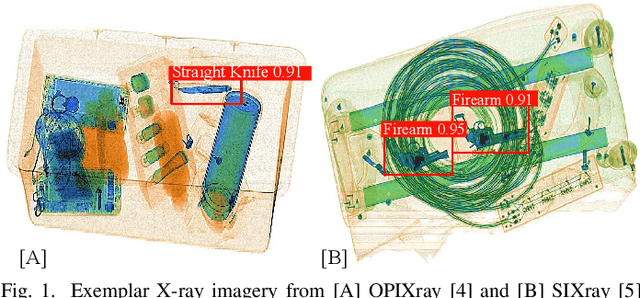
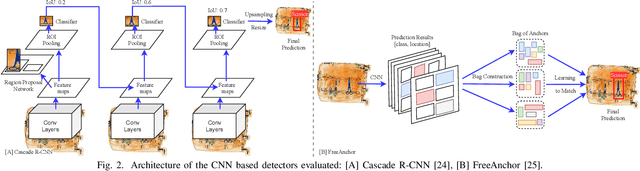
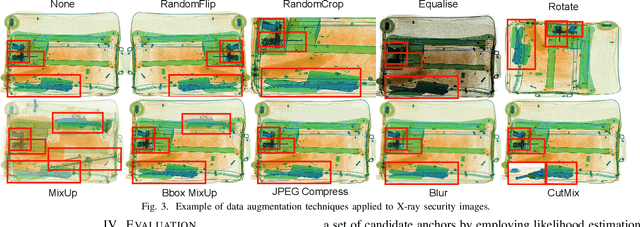
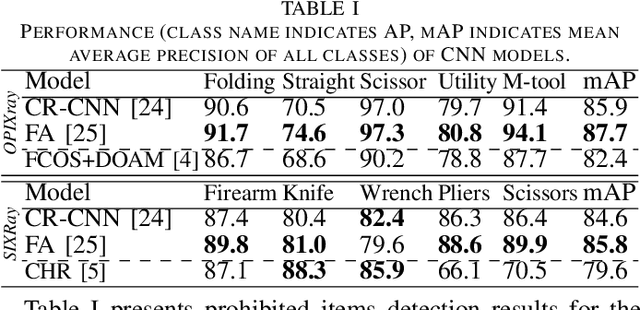
The recent advancement in deep Convolutional Neural Network (CNN) has brought insight into the automation of X-ray security screening for aviation security and beyond. Here, we explore the viability of two recent end-to-end object detection CNN architectures, Cascade R-CNN and FreeAnchor, for prohibited item detection by balancing processing time and the impact of image data compression from an operational viewpoint. Overall, we achieve maximal detection performance using a FreeAnchor architecture with a ResNet50 backbone, obtaining mean Average Precision (mAP) of 87.7 and 85.8 for using the OPIXray and SIXray benchmark datasets, showing superior performance over prior work on both. With fewer parameters and less training time, FreeAnchor achieves the highest detection inference speed of ~13 fps (3.9 ms per image). Furthermore, we evaluate the impact of lossy image compression upon detector performance. The CNN models display substantial resilience to the lossy compression, resulting in only a 1.1% decrease in mAP at the JPEG compression level of 50. Additionally, a thorough evaluation of data augmentation techniques is provided, including adaptions of MixUp and CutMix strategy as well as other standard transformations, further improving the detection accuracy.
Accelerated Alternating Minimization for X-ray Tomographic Reconstruction
Aug 02, 2021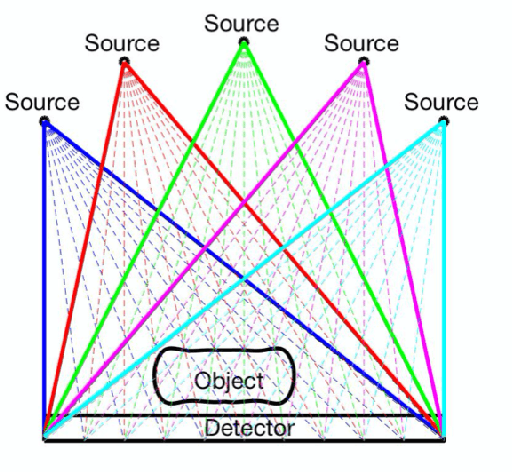

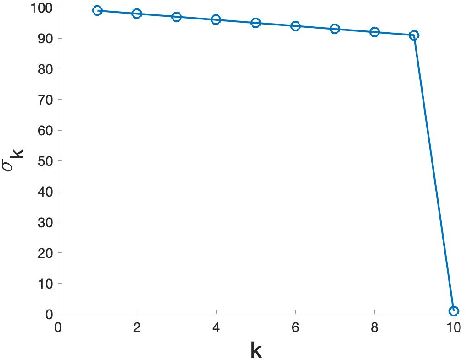
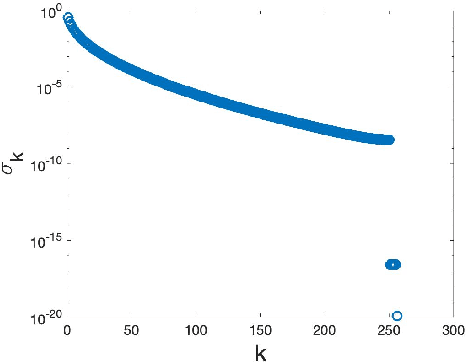
While Computerized Tomography (CT) images can help detect disease such as Covid-19, regular CT machines are large and expensive. Cheaper and more portable machines suffer from errors in geometry acquisition that downgrades CT image quality. The errors in geometry can be represented with parameters in the mathematical model for image reconstruction. To obtain a good image, we formulate a nonlinear least squares problem that simultaneously reconstructs the image and corrects for errors in the geometry parameters. We develop an accelerated alternating minimization scheme to reconstruct the image and geometry parameters.
Deep clustering with fusion autoencoder
Jan 14, 2022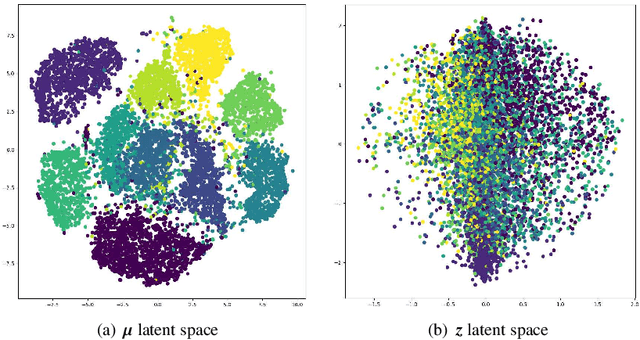
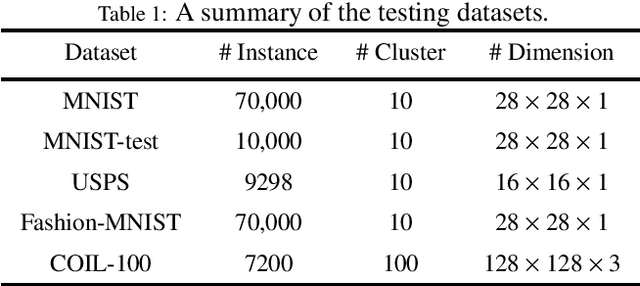
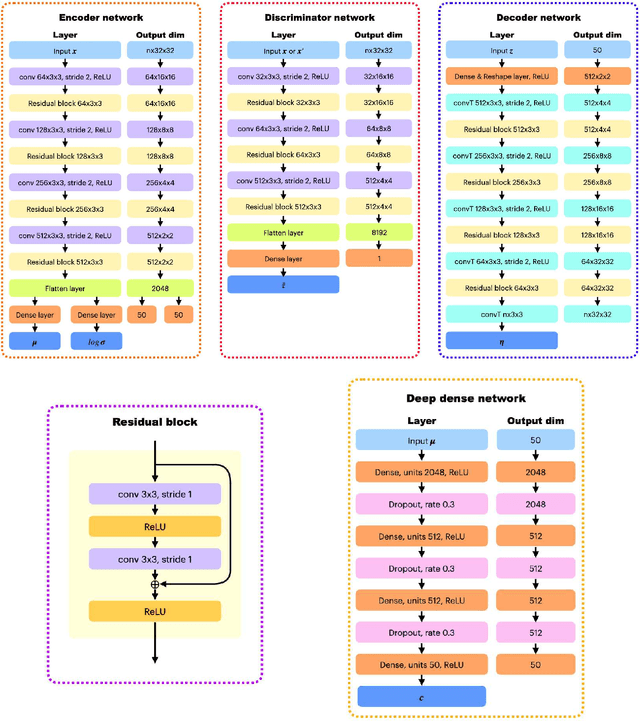
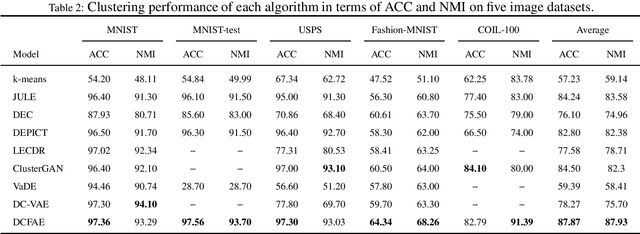
Embracing the deep learning techniques for representation learning in clustering research has attracted broad attention in recent years, yielding a newly developed clustering paradigm, viz. the deep clustering (DC). Typically, the DC models capitalize on autoencoders to learn the intrinsic features which facilitate the clustering process in consequence. Nowadays, a generative model named variational autoencoder (VAE) has got wide acceptance in DC studies. Nevertheless, the plain VAE is insufficient to perceive the comprehensive latent features, leading to the deteriorative clustering performance. In this paper, a novel DC method is proposed to address this issue. Specifically, the generative adversarial network and VAE are coalesced into a new autoencoder called fusion autoencoder (FAE) for discerning more discriminative representation that benefits the downstream clustering task. Besides, the FAE is implemented with the deep residual network architecture which further enhances the representation learning ability. Finally, the latent space of the FAE is transformed to an embedding space shaped by a deep dense neural network for pulling away different clusters from each other and collapsing data points within individual clusters. Experiment conducted on several image datasets demonstrate the effectiveness of the proposed DC model against the baseline methods.
Robust Deep AUC Maximization: A New Surrogate Loss and Empirical Studies on Medical Image Classification
Dec 06, 2020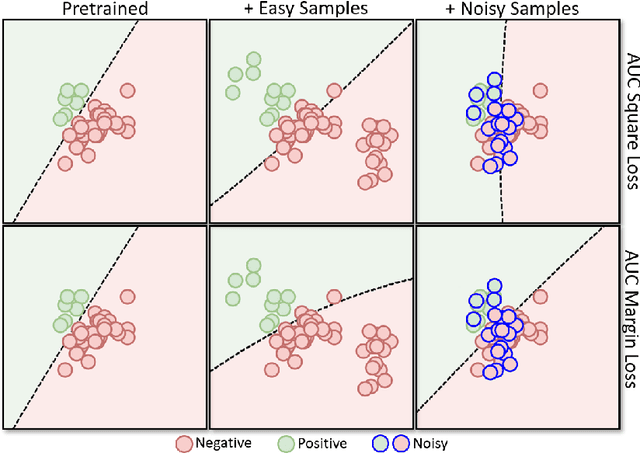
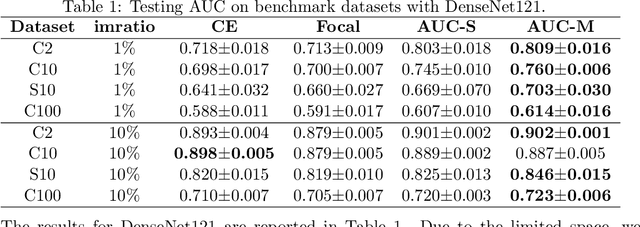
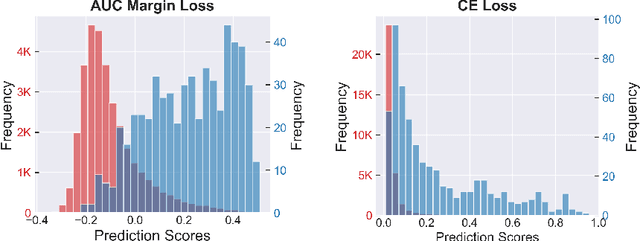
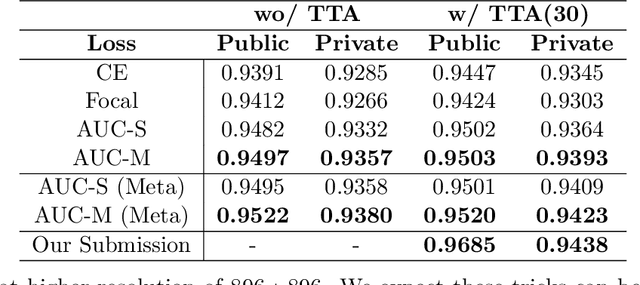
Deep AUC Maximization (DAM) is a paradigm for learning a deep neural network by maximizing the AUC score of the model on a dataset. Most previous works of AUC maximization focus on the perspective of optimization by designing efficient stochastic algorithms, and studies on generalization performance of DAM on difficult tasks are missing. In this work, we aim to make DAM more practical for interesting real-world applications (e.g., medical image classification). First, we propose a new margin-based surrogate loss function for the AUC score (named as the AUC margin loss). It is more robust than the commonly used AUC square loss, while enjoying the same advantage in terms of large-scale stochastic optimization. Second, we conduct empirical studies of our DAM method on difficult medical image classification tasks, namely classification of chest x-ray images for identifying many threatening diseases and classification of images of skin lesions for identifying melanoma. Our DAM method has achieved great success on these difficult tasks, i.e., the 1st place on Stanford CheXpert competition (by the paper submission date) and Top 1% rank (rank 33 out of 3314 teams) on Kaggle 2020 Melanoma classification competition. We also conduct extensive ablation studies to demonstrate the advantages of the new AUC margin loss over the AUC square loss on benchmark datasets. To the best of our knowledge, this is the first work that makes DAM succeed on large-scale medical image datasets.
Mind the Gap: Domain Gap Control for Single Shot Domain Adaptation for Generative Adversarial Networks
Oct 15, 2021

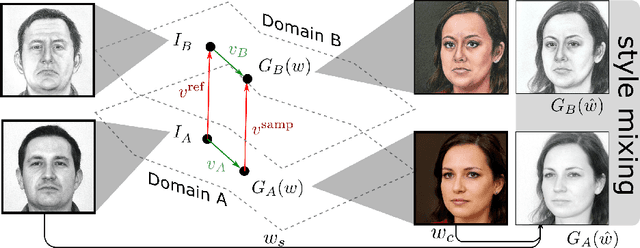
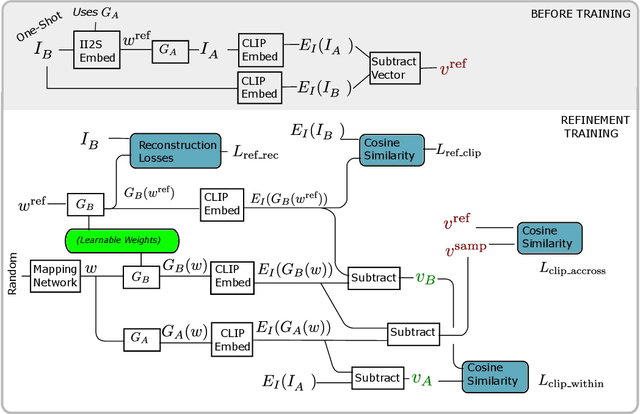
We present a new method for one shot domain adaptation. The input to our method is trained GAN that can produce images in domain A and a single reference image I_B from domain B. The proposed algorithm can translate any output of the trained GAN from domain A to domain B. There are two main advantages of our method compared to the current state of the art: First, our solution achieves higher visual quality, e.g. by noticeably reducing overfitting. Second, our solution allows for more degrees of freedom to control the domain gap, i.e. what aspects of image I_B are used to define the domain B. Technically, we realize the new method by building on a pre-trained StyleGAN generator as GAN and a pre-trained CLIP model for representing the domain gap. We propose several new regularizers for controlling the domain gap to optimize the weights of the pre-trained StyleGAN generator to output images in domain B instead of domain A. The regularizers prevent the optimization from taking on too many attributes of the single reference image. Our results show significant visual improvements over the state of the art as well as multiple applications that highlight improved control.
A Closer Look at Art Mediums: The MAMe Image Classification Dataset
Jul 27, 2020
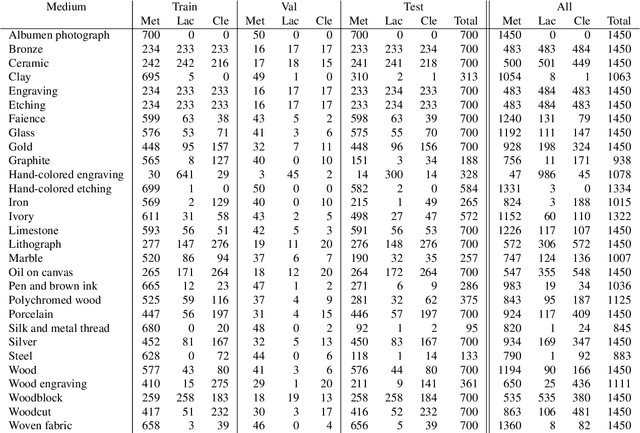
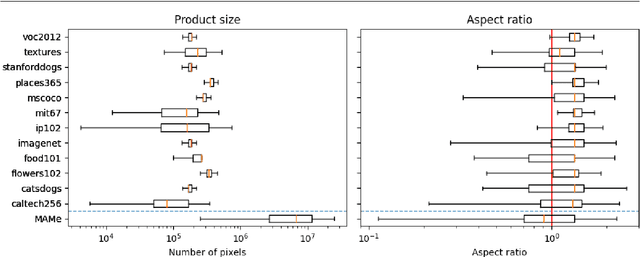
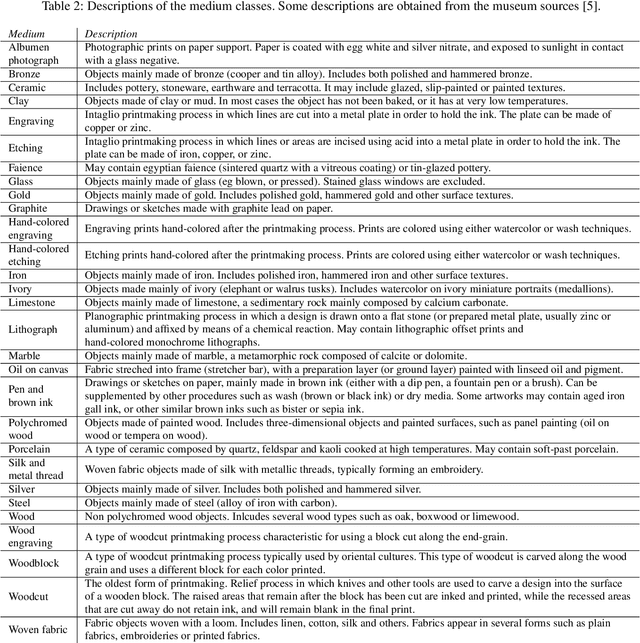
Art is an expression of human creativity, skill and technology. An exceptionally rich source of visual content. In the context of AI image processing systems, artworks represent one of the most challenging domains conceivable: Properly perceiving art requires attention to detail, a huge generalization capacity, and recognizing both simple and complex visual patterns. To challenge the AI community, this work introduces a novel image classification task focused on museum art mediums, the MAMe dataset. Data is gathered from three different museums, and aggregated by art experts into 29 classes of medium (i.e. materials and techniques). For each class, MAMe provides a minimum of 850 images (700 for training) of high-resolution and variable shape. The combination of volume, resolution and shape allows MAMe to fill a void in current image classification challenges, empowering research in aspects so far overseen by the research community. After reviewing the singularity of MAMe in the context of current image classification tasks, a thorough description of the task is provided, together with dataset statistics. Baseline experiments are conducted using well-known architectures, to highlight both the feasibility and complexity of the task proposed. Finally, these baselines are inspected using explainability methods and expert knowledge, to gain insight on the challenges that remain ahead.
Autonomous, Mobile Manipulation in a Wall-building Scenario: Team LARICS at MBZIRC 2020
Jan 28, 2022

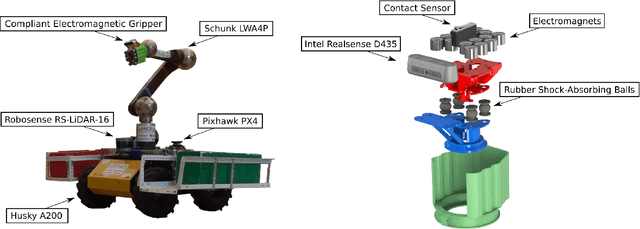
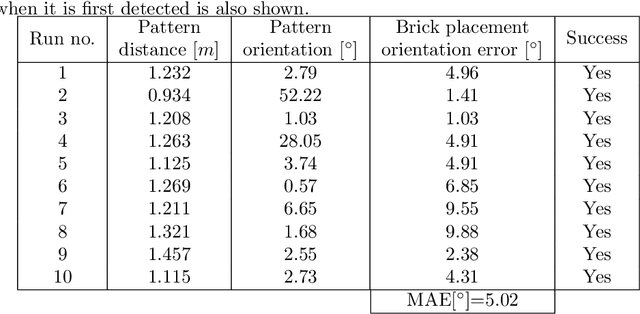
In this paper we present our hardware design and control approaches for a mobile manipulation platform used in Challenge 2 of the MBZIRC 2020 competition. In this challenge, a team of UAVs and a single UGV collaborate in an autonomous, wall-building scenario, motivated by construction automation and large-scale robotic 3D printing. The robots must be able, autonomously, to detect, manipulate, and transport bricks in an unstructured, outdoor environment. Our control approach is based on a state machine that dictates which controllers are active at each stage of the Challenge. In the first stage our UGV uses visual servoing and local controllers to approach the target object without considering its orientation. The second stage consists of detecting the object's global pose using OpenCV-based processing of RGB-D image and point-cloud data, and calculating an alignment goal within a global map. The map is built with Google Cartographer and is based on onboard LIDAR, IMU, and GPS data. Motion control in the second stage is realized using the ROS Move Base package with Time-Elastic Band trajectory optimization. Visual servo algorithms guide the vehicle in local object-approach movement and the arm in manipulating bricks. To ensure a stable grasp of the brick's magnetic patch, we developed a passively-compliant, electromagnetic gripper with tactile feedback. Our fully-autonomous UGV performed well in Challenge 2 and in post-competition evaluations of its brick pick-and-place algorithms.
CropDefender: deep watermark which is more convenient to train and more robust against cropping
Sep 12, 2021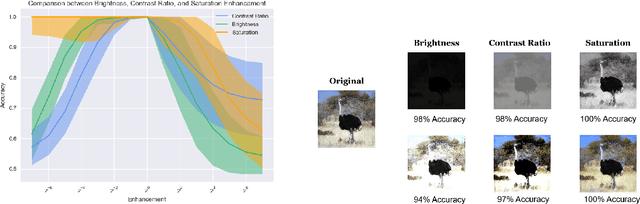
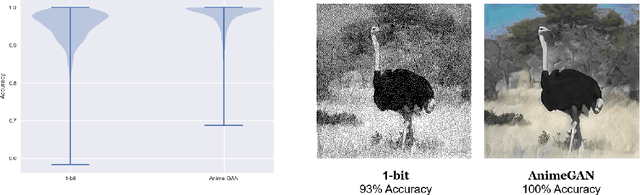
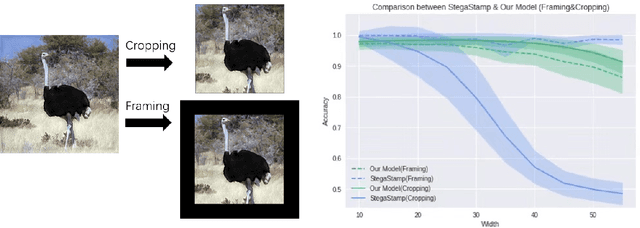
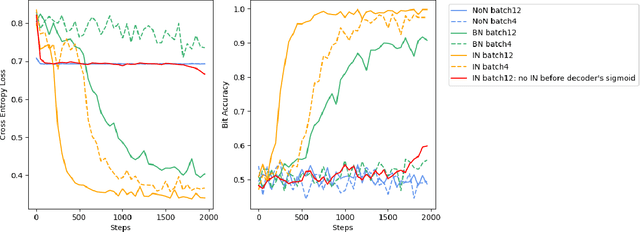
Digital image watermarking, which is a technique for invisibly embedding information into an image, is used in fields such as property rights protection. In recent years, some research has proposed the use of neural networks to add watermarks to natural images. We take StegaStamp as an example for our research. Whether facing traditional image editing methods, such as brightness, contrast, saturation adjustment, or style change like 1-bit conversion, GAN, StegaStamp has robustness far beyond traditional watermarking techniques, but it still has two drawbacks: it is vulnerable to cropping and is hard to train. We found that the causes of vulnerability to cropping is not the loss of information on the edge, but the movement of watermark position. By explicitly introducing the perturbation of cropping into the training, the cropping resistance is significantly improved. For the problem of difficult training, we introduce instance normalization to solve the vanishing gradient, set losses' weights as learnable parameters to reduce the number of hyperparameters, and use sigmoid to restrict pixel values of the generated image.
Self-Supervised Deep Blind Video Super-Resolution
Jan 19, 2022
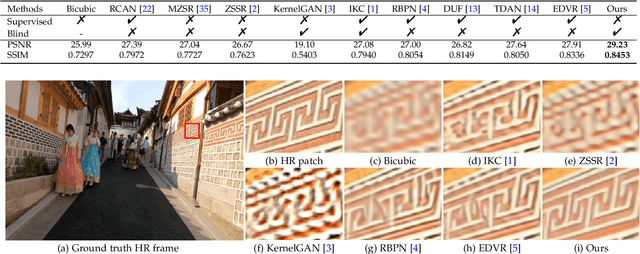
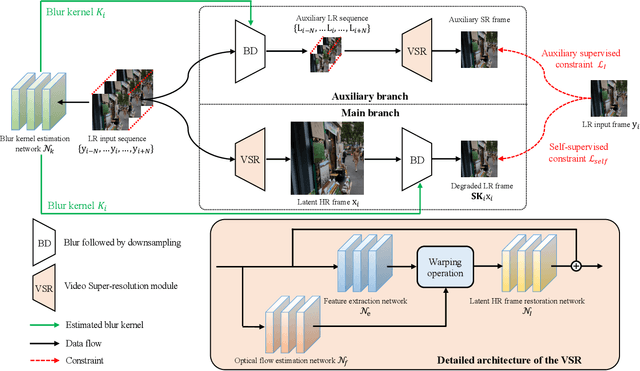
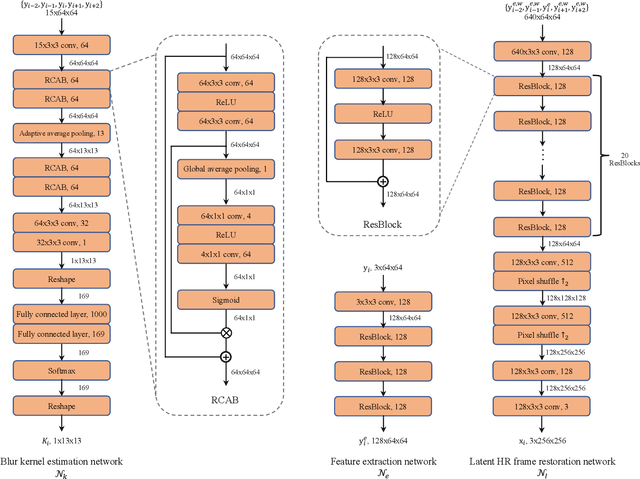
Existing deep learning-based video super-resolution (SR) methods usually depend on the supervised learning approach, where the training data is usually generated by the blurring operation with known or predefined kernels (e.g., Bicubic kernel) followed by a decimation operation. However, this does not hold for real applications as the degradation process is complex and cannot be approximated by these idea cases well. Moreover, obtaining high-resolution (HR) videos and the corresponding low-resolution (LR) ones in real-world scenarios is difficult. To overcome these problems, we propose a self-supervised learning method to solve the blind video SR problem, which simultaneously estimates blur kernels and HR videos from the LR videos. As directly using LR videos as supervision usually leads to trivial solutions, we develop a simple and effective method to generate auxiliary paired data from original LR videos according to the image formation of video SR, so that the networks can be better constrained by the generated paired data for both blur kernel estimation and latent HR video restoration. In addition, we introduce an optical flow estimation module to exploit the information from adjacent frames for HR video restoration. Experiments show that our method performs favorably against state-of-the-art ones on benchmarks and real-world videos.
Adversarial Code Learning for Image Generation
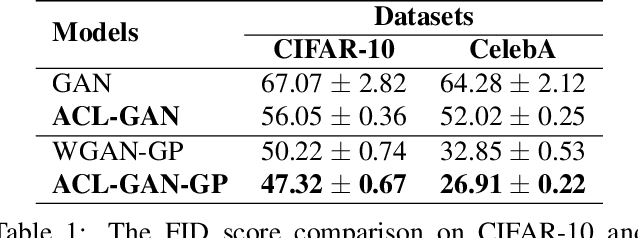
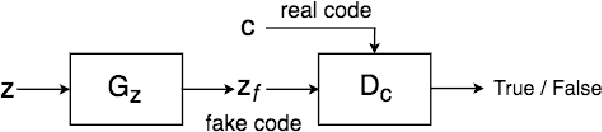
Jan 30, 2020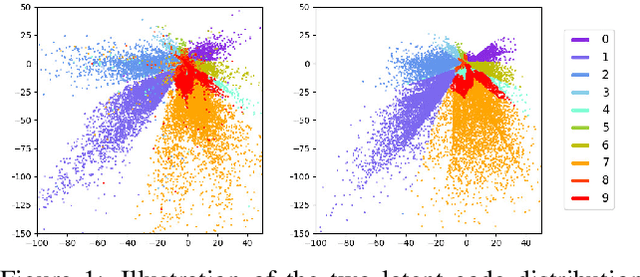

We introduce the "adversarial code learning" (ACL) module that improves overall image generation performance to several types of deep models. Instead of performing a posterior distribution modeling in the pixel spaces of generators, ACLs aim to jointly learn a latent code with another image encoder/inference net, with a prior noise as its input. We conduct the learning in an adversarial learning process, which bears a close resemblance to the original GAN but again shifts the learning from image spaces to prior and latent code spaces. ACL is a portable module that brings up much more flexibility and possibilities in generative model designs. First, it allows flexibility to convert non-generative models like Autoencoders and standard classification models to decent generative models. Second, it enhances existing GANs' performance by generating meaningful codes and images from any part of the prior. We have incorporated our ACL module with the aforementioned frameworks and have performed experiments on synthetic, MNIST, CIFAR-10, and CelebA datasets. Our models have achieved significant improvements which demonstrated the generality for image generation tasks.