 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Repaint: Improving the Generalization of Down-Stream Visual Tasks by Generating Multiple Instances of Training Examples
Oct 20, 2021
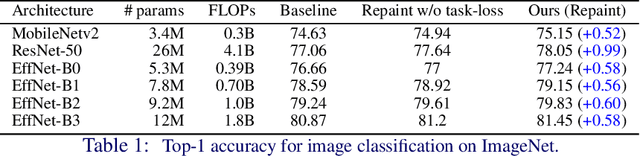
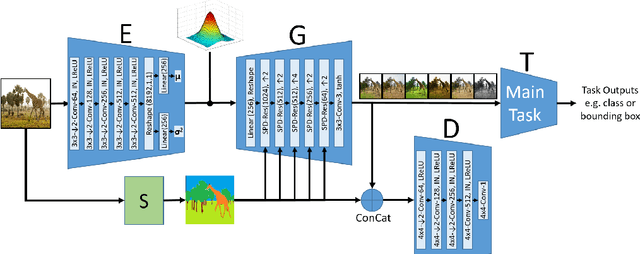
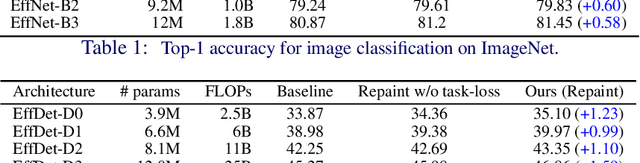
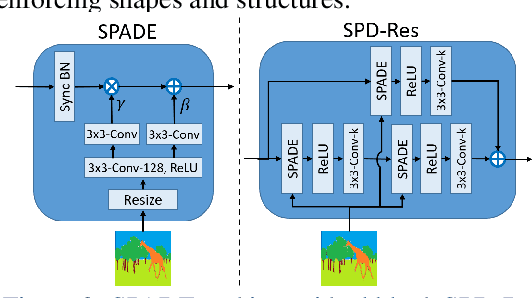
Convolutional Neural Networks (CNNs) for visual tasks are believed to learn both the low-level textures and high-level object attributes, throughout the network depth. This paper further investigates the `texture bias' in CNNs. To this end, we regenerate multiple instances of training examples from each original image, through a process we call `repainting'. The repainted examples preserve the shape and structure of the regions and objects within the scenes, but diversify their texture and color. Our method can regenerate a same image at different daylight, season, or weather conditions, can have colorization or de-colorization effects, or even bring back some texture information from blacked-out areas. The in-place repaint allows us to further use these repainted examples for improving the generalization of CNNs. Through an extensive set of experiments, we demonstrate the usefulness of the repainted examples in training, for the tasks of image classification (ImageNet) and object detection (COCO), over several state-of-the-art network architectures at different capacities, and across different data availability regimes.
Decoupling Zero-Shot Semantic Segmentation
Dec 15, 2021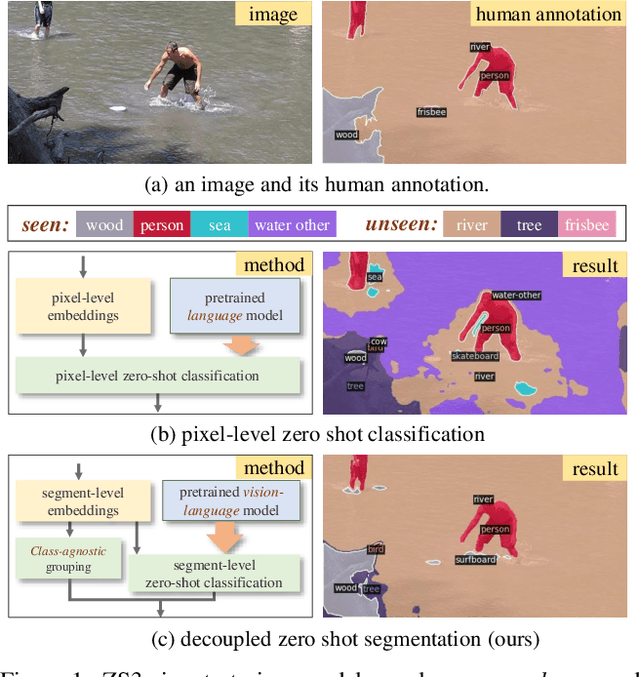
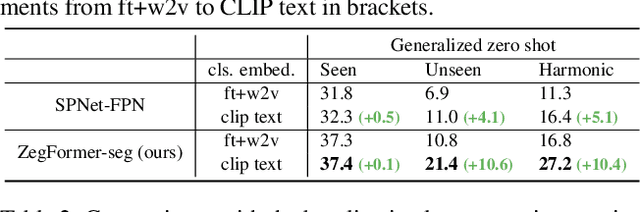
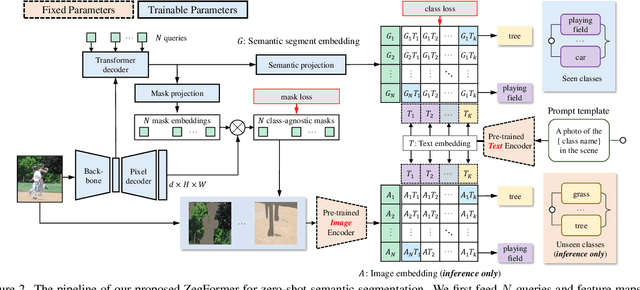
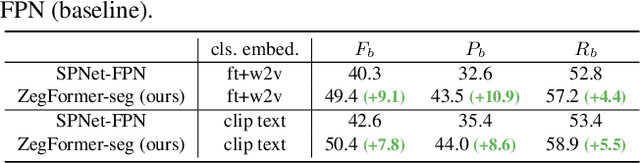
Zero-shot semantic segmentation (ZS3) aims to segment the novel categories that have not been seen in the training. Existing works formulate ZS3 as a pixel-level zero-shot classification problem, and transfer semantic knowledge from seen classes to unseen ones with the help of language models pre-trained only with texts. While simple, the pixel-level ZS3 formulation shows the limited capability to integrate vision-language models that are often pre-trained with image-text pairs and currently demonstrate great potential for vision tasks. Inspired by the observation that humans often perform segment-level semantic labeling, we propose to decouple the ZS3 into two sub-tasks: 1) a class-agnostic grouping task to group the pixels into segments. 2) a zero-shot classification task on segments. The former sub-task does not involve category information and can be directly transferred to group pixels for unseen classes. The latter subtask performs at segment-level and provides a natural way to leverage large-scale vision-language models pre-trained with image-text pairs (e.g. CLIP) for ZS3. Based on the decoupling formulation, we propose a simple and effective zero-shot semantic segmentation model, called ZegFormer, which outperforms the previous methods on ZS3 standard benchmarks by large margins, e.g., 35 points on the PASCAL VOC and 3 points on the COCO-Stuff in terms of mIoU for unseen classes. Code will be released at https://github.com/dingjiansw101/ZegFormer.
Towards the automated large-scale reconstruction of past road networks from historical maps
Feb 11, 2022

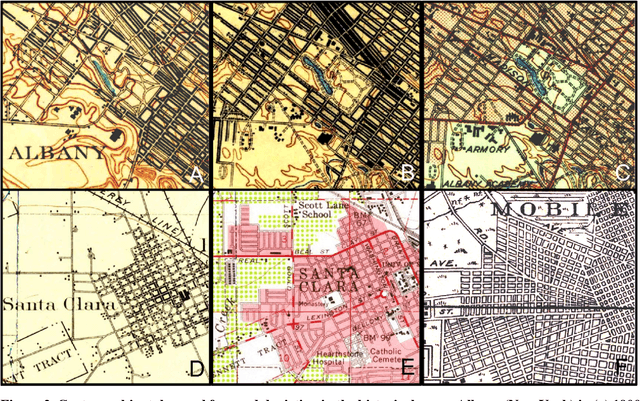

Transportation infrastructure, such as road or railroad networks, represent a fundamental component of our civilization. For sustainable planning and informed decision making, a thorough understanding of the long-term evolution of transportation infrastructure such as road networks is crucial. However, spatially explicit, multi-temporal road network data covering large spatial extents are scarce and rarely available prior to the 2000s. Herein, we propose a framework that employs increasingly available scanned and georeferenced historical map series to reconstruct past road networks, by integrating abundant, contemporary road network data and color information extracted from historical maps. Specifically, our method uses contemporary road segments as analytical units and extracts historical roads by inferring their existence in historical map series based on image processing and clustering techniques. We tested our method on over 300,000 road segments representing more than 50,000 km of the road network in the United States, extending across three study areas that cover 53 historical topographic map sheets dated between 1890 and 1950. We evaluated our approach by comparison to other historical datasets and against manually created reference data, achieving F-1 scores of up to 0.95, and showed that the extracted road network statistics are highly plausible over time, i.e., following general growth patterns. We demonstrated that contemporary geospatial data integrated with information extracted from historical map series open up new avenues for the quantitative analysis of long-term urbanization processes and landscape changes far beyond the era of operational remote sensing and digital cartography.
Effect of Camera's Focal Plane Array Fill Factor on Digital Image Correlation Measurement Accuracy
May 30, 2021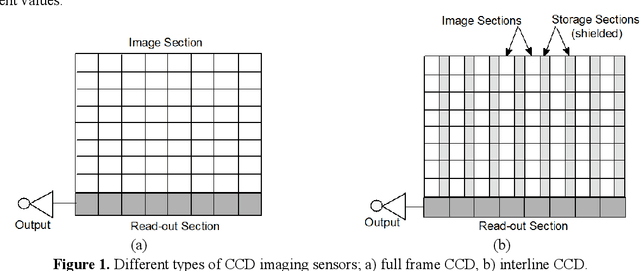

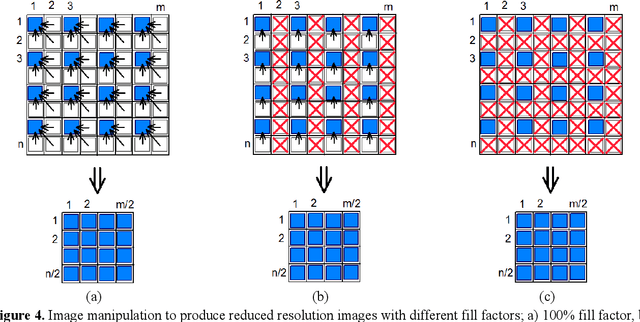
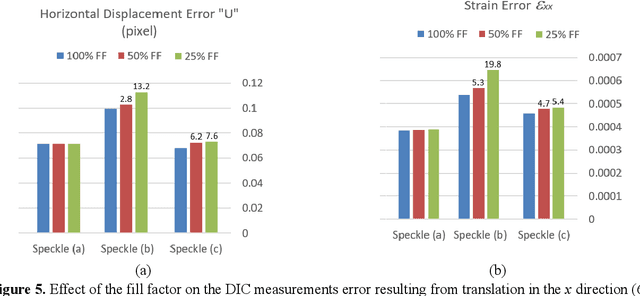
The camera's focal plane array (FPA) fill factor is one of the parameters for digital cameras, though it is not widely known and usually not reported in specs sheets. The fill factor of an imaging sensor is defined as the ratio of a pixel's light sensitive area to its total theoretical area. It is generally believed that the lower fill factor may reduce the accuracy of photogrammetric measurements. But nevertheless, there are no studies addressing the effect of the imaging sensor's fill factor on digital image correlation (DIC) measurement accuracy. We report on research aiming to quantify the effect of fill factor on DIC measurements accuracy in terms of displacement error and strain error. We use rigid-body-translation experiments then numerically modify the recorded images to synthesize three different types of images with 1/4 of the original resolution. Each type of the synthesized images has different value of the fill factor; namely 100%, 50% and 25%. By performing DIC analysis with the same parameters on the three different types of synthesized images, the effect of fill factor on measurement accuracy may be realized. Our results show that the FPA's fill factor can have a significant effect on the accuracy of DIC measurements. This effect is clearly dependent on the type and characteristics of the speckle pattern. The fill factor has a clear effect on measurement error for low contrast speckle patterns and for high contrast speckle patterns (black dots on white background) with small dot size (3 pixels dot diameter). However, when the dot size is large enough (about 7 pixels dot diameter), the fill factor has very minor effect on measurement error.
Multi-layer Residual Sparsifying Transform (MARS) Model for Low-dose CT Image Reconstruction
Oct 16, 2020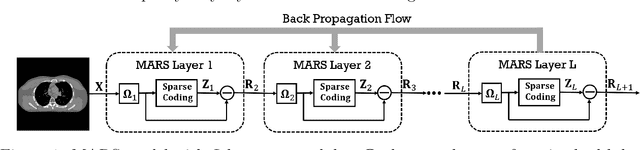
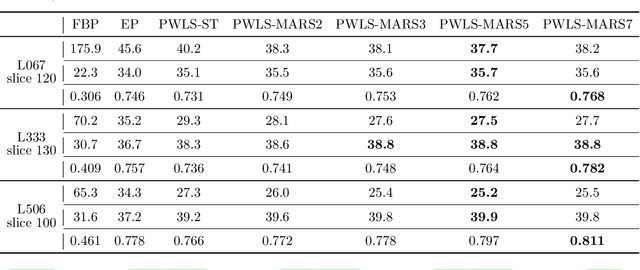
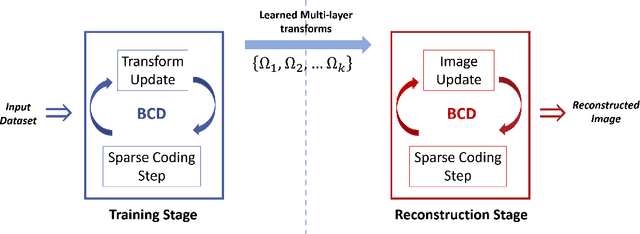
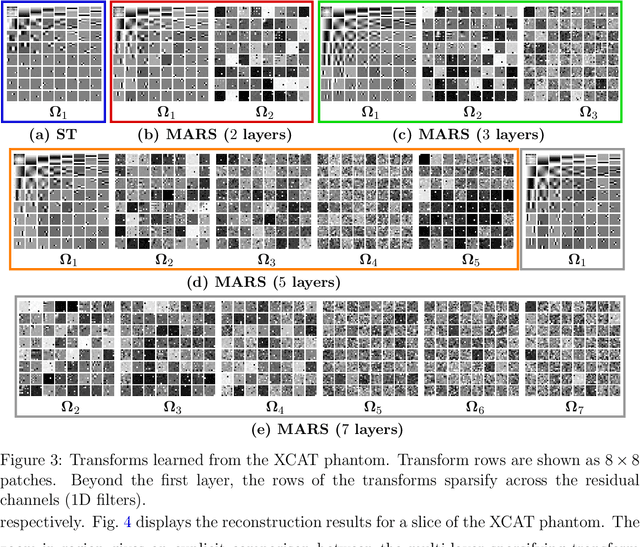
Signal models based on sparse representations have received considerable attention in recent years. On the other hand, deep models consisting of a cascade of functional layers, commonly known as deep neural networks, have been highly successful for the task of object classification and have been recently introduced to image reconstruction. In this work, we develop a new image reconstruction approach based on a novel multi-layer model learned in an unsupervised manner by combining both sparse representations and deep models. The proposed framework extends the classical sparsifying transform model for images to a Multi-lAyer Residual Sparsifying transform (MARS) model, wherein the transform domain data are jointly sparsified over layers. We investigate the application of MARS models learned from limited regular-dose images for low-dose CT reconstruction using Penalized Weighted Least Squares (PWLS) optimization. We propose new formulations for multi-layer transform learning and image reconstruction. We derive an efficient block coordinate descent algorithm to learn the transforms across layers, in an unsupervised manner from limited regular-dose images. The learned model is then incorporated into the low-dose image reconstruction phase. Low-dose CT experimental results with both the XCAT phantom and Mayo Clinic data show that the MARS model outperforms conventional methods such as FBP and PWLS methods based on the edge-preserving (EP) regularizer and the single-layer learned transform (ST) model, especially in terms of reducing noise and maintaining some subtle details.
An Efficient Cervical Whole Slide Image Analysis Framework Based on Multi-scale Semantic and Spatial Features using Deep Learning
Jun 29, 2021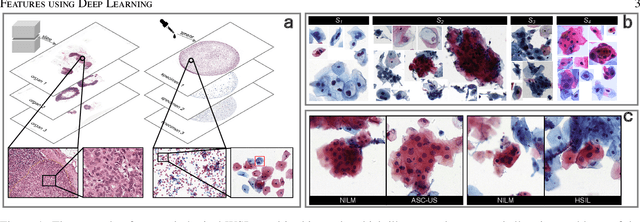
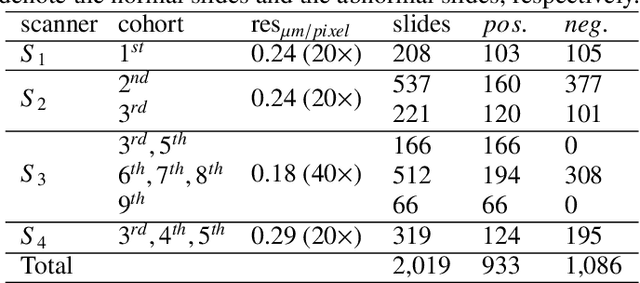
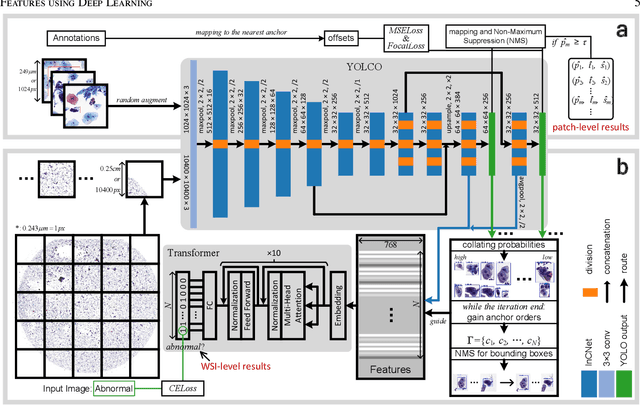
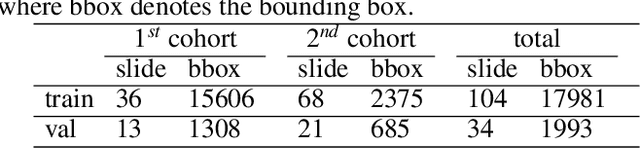
Digital gigapixel whole slide image (WSI) is widely used in clinical diagnosis, and automated WSI analysis is key for computer-aided diagnosis. Currently, analyzing the integrated descriptor of probabilities or feature maps from massive local patches encoded by ResNet classifier is the main manner for WSI-level prediction. Feature representations of the sparse and tiny lesion cells in cervical slides, however, are still challengeable for the under-promoted upstream encoders, while the unused spatial representations of cervical cells are the available features to supply the semantics analysis. As well as patches sampling with overlap and repetitive processing incur the inefficiency and the unpredictable side effect. This study designs a novel inline connection network (InCNet) by enriching the multi-scale connectivity to build the lightweight model named You Only Look Cytopathology Once (YOLCO) with the additional supervision of spatial information. The proposed model allows the input size enlarged to megapixel that can stitch the WSI without any overlap by the average repeats decreased from $10^3\sim10^4$ to $10^1\sim10^2$ for collecting features and predictions at two scales. Based on Transformer for classifying the integrated multi-scale multi-task features, the experimental results appear $0.872$ AUC score better and $2.51\times$ faster than the best conventional method in WSI classification on multicohort datasets of 2,019 slides from four scanning devices.
LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
Mar 29, 2021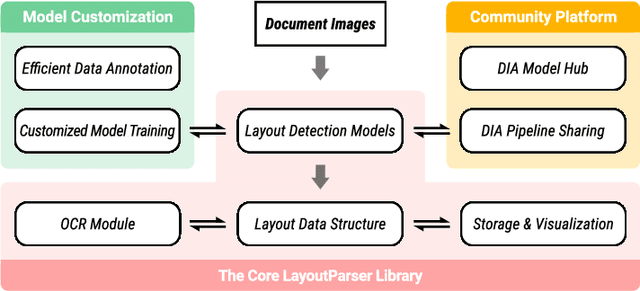
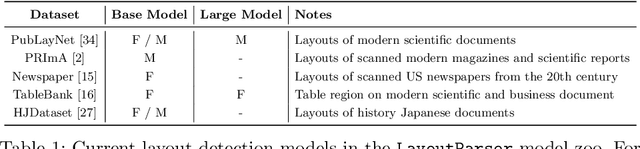
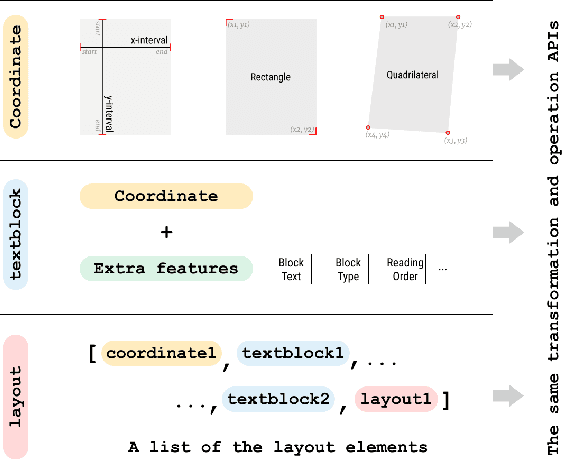
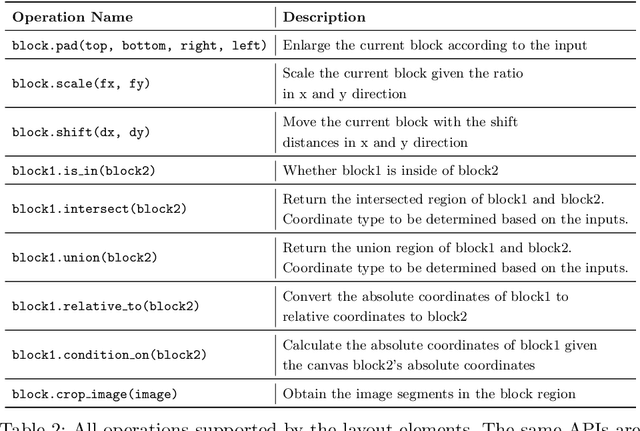
Recent advances in document image analysis (DIA) have been primarily driven by the application of neural networks. Ideally, research outcomes could be easily deployed in production and extended for further investigation. However, various factors like loosely organized codebases and sophisticated model configurations complicate the easy reuse of important innovations by a wide audience. Though there have been on-going efforts to improve reusability and simplify deep learning (DL) model development in disciplines like natural language processing and computer vision, none of them are optimized for challenges in the domain of DIA. This represents a major gap in the existing toolkit, as DIA is central to academic research across a wide range of disciplines in the social sciences and humanities. This paper introduces layoutparser, an open-source library for streamlining the usage of DL in DIA research and applications. The core layoutparser library comes with a set of simple and intuitive interfaces for applying and customizing DL models for layout detection, character recognition, and many other document processing tasks. To promote extensibility, layoutparser also incorporates a community platform for sharing both pre-trained models and full document digitization pipelines. We demonstrate that layoutparser is helpful for both lightweight and large-scale digitization pipelines in real-word use cases. The library is publicly available at https://layout-parser.github.io/.
PatchGame: Learning to Signal Mid-level Patches in Referential Games
Nov 02, 2021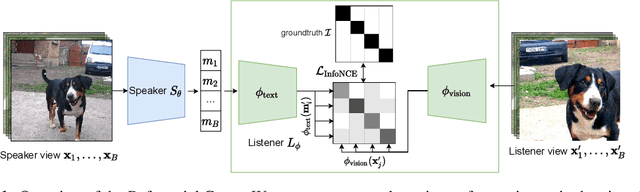
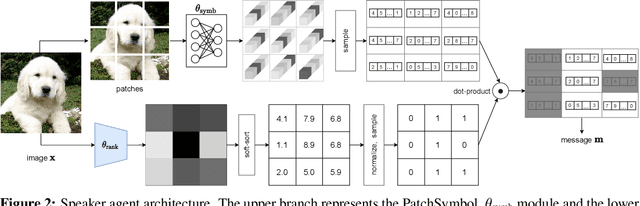


We study a referential game (a type of signaling game) where two agents communicate with each other via a discrete bottleneck to achieve a common goal. In our referential game, the goal of the speaker is to compose a message or a symbolic representation of "important" image patches, while the task for the listener is to match the speaker's message to a different view of the same image. We show that it is indeed possible for the two agents to develop a communication protocol without explicit or implicit supervision. We further investigate the developed protocol and show the applications in speeding up recent Vision Transformers by using only important patches, and as pre-training for downstream recognition tasks (e.g., classification). Code available at https://github.com/kampta/PatchGame.
PGL: Prior-Guided Local Self-supervised Learning for 3D Medical Image Segmentation
Nov 25, 2020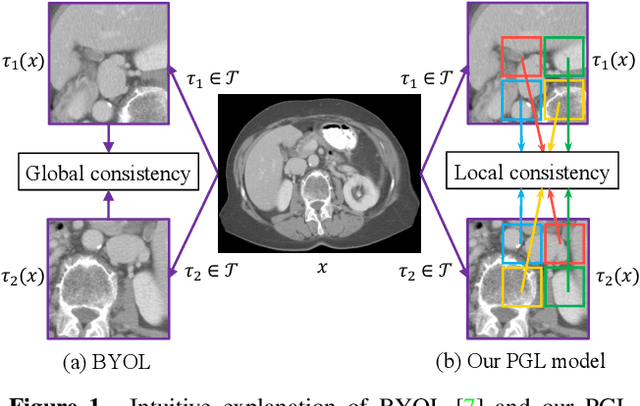
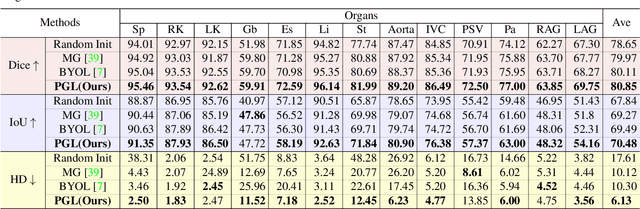
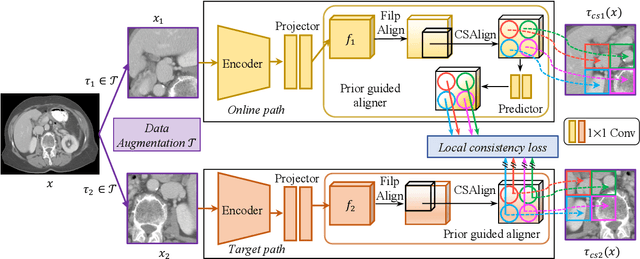
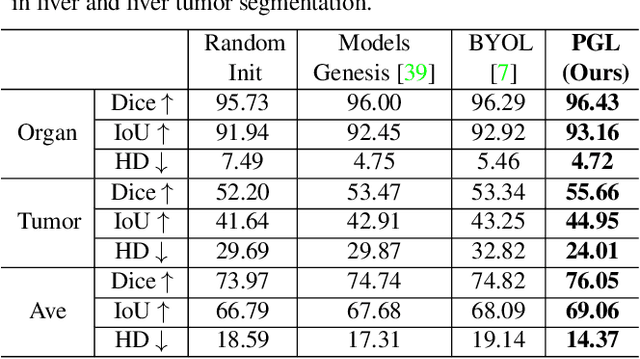
It has been widely recognized that the success of deep learning in image segmentation relies overwhelmingly on a myriad amount of densely annotated training data, which, however, are difficult to obtain due to the tremendous labor and expertise required, particularly for annotating 3D medical images. Although self-supervised learning (SSL) has shown great potential to address this issue, most SSL approaches focus only on image-level global consistency, but ignore the local consistency which plays a pivotal role in capturing structural information for dense prediction tasks such as segmentation. In this paper, we propose a PriorGuided Local (PGL) self-supervised model that learns the region-wise local consistency in the latent feature space. Specifically, we use the spatial transformations, which produce different augmented views of the same image, as a prior to deduce the location relation between two views, which is then used to align the feature maps of the same local region but being extracted on two views. Next, we construct a local consistency loss to minimize the voxel-wise discrepancy between the aligned feature maps. Thus, our PGL model learns the distinctive representations of local regions, and hence is able to retain structural information. This ability is conducive to downstream segmentation tasks. We conducted an extensive evaluation on four public computerized tomography (CT) datasets that cover 11 kinds of major human organs and two tumors. The results indicate that using pre-trained PGL model to initialize a downstream network leads to a substantial performance improvement over both random initialization and the initialization with global consistency-based models. Code and pre-trained weights will be made available at: https://git.io/PGL.
SwiftSRGAN -- Rethinking Super-Resolution for Efficient and Real-time Inference
Nov 29, 2021
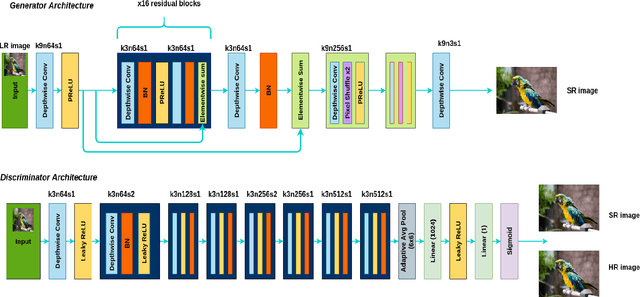


In recent years, there have been several advancements in the task of image super-resolution using the state of the art Deep Learning-based architectures. Many super-resolution-based techniques previously published, require high-end and top-of-the-line Graphics Processing Unit (GPUs) to perform image super-resolution. With the increasing advancements in Deep Learning approaches, neural networks have become more and more compute hungry. We took a step back and, focused on creating a real-time efficient solution. We present an architecture that is faster and smaller in terms of its memory footprint. The proposed architecture uses Depth-wise Separable Convolutions to extract features and, it performs on-par with other super-resolution GANs (Generative Adversarial Networks) while maintaining real-time inference and a low memory footprint. A real-time super-resolution enables streaming high resolution media content even under poor bandwidth conditions. While maintaining an efficient trade-off between the accuracy and latency, we are able to produce a comparable performance model which is one-eighth (1/8) the size of super-resolution GANs and computes 74 times faster than super-resolution GANs.