 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Using Partial Monotonicity in Submodular Maximization
Feb 07, 2022
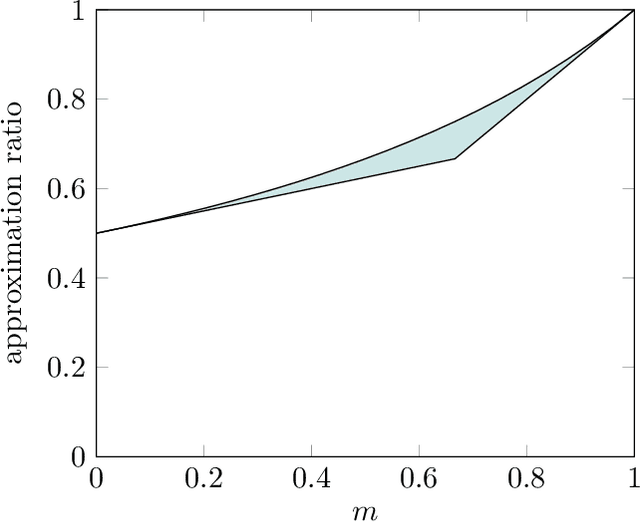
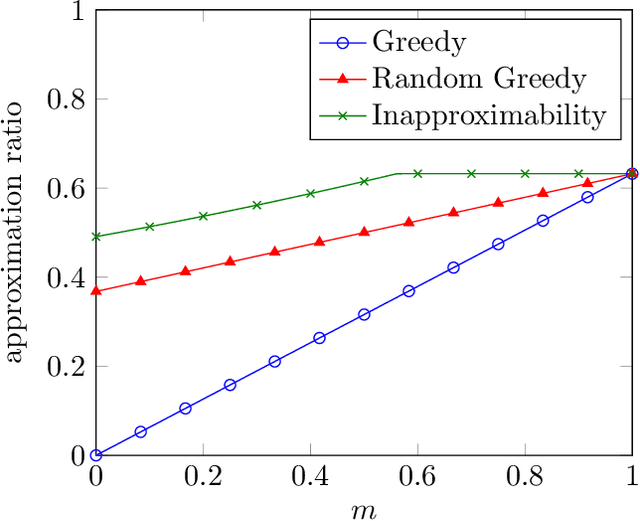
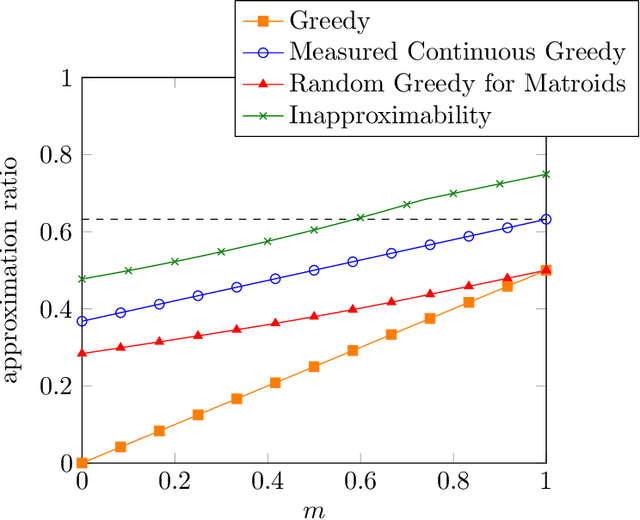
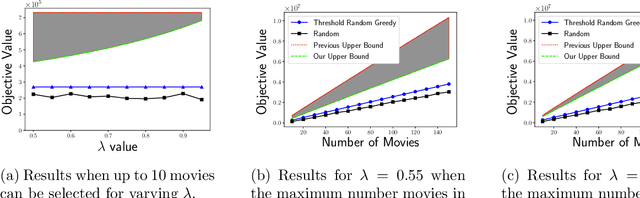
Over the last two decades, submodular function maximization has been the workhorse of many discrete optimization problems in machine learning applications. Traditionally, the study of submodular functions was based on binary function properties. However, such properties have an inherit weakness, namely, if an algorithm assumes functions that have a particular property, then it provides no guarantee for functions that violate this property, even when the violation is very slight. Therefore, recent works began to consider continuous versions of function properties. Probably the most significant among these (so far) are the submodularity ratio and the curvature, which were studied extensively together and separately. The monotonicity property of set functions plays a central role in submodular maximization. Nevertheless, and despite all the above works, no continuous version of this property has been suggested to date (as far as we know). This is unfortunate since submoduar functions that are almost monotone often arise in machine learning applications. In this work we fill this gap by defining the monotonicity ratio, which is a continues version of the monotonicity property. We then show that for many standard submodular maximization algorithms one can prove new approximation guarantees that depend on the monotonicity ratio; leading to improved approximation ratios for the common machine learning applications of movie recommendation, quadratic programming and image summarization.
SCOUTER: Slot Attention-based Classifier for Explainable Image Recognition
Sep 14, 2020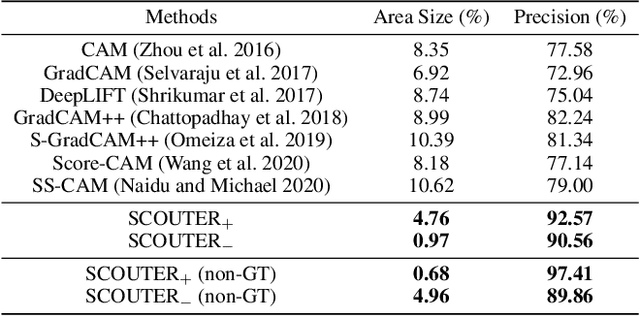
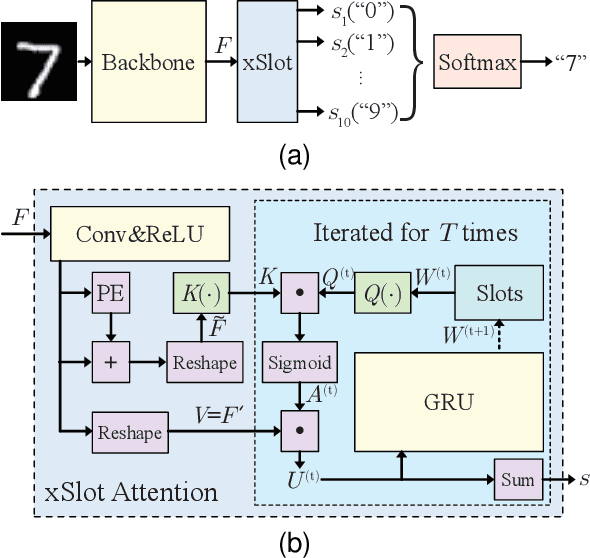
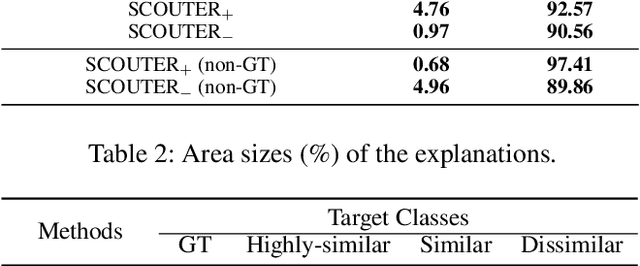

Explainable artificial intelligence is gaining attention. However, most existing methods are based on gradients or intermediate features, which are not directly involved in the decision-making process of the classifier. In this paper, we propose a slot attention-based light-weighted classifier called SCOUTER for transparent yet accurate classification. Two major differences from other attention-based methods include: (a) SCOUTER's explanation involves the final confidence for each category, offering more intuitive interpretation, and (b) all the categories have their corresponding positive or negative explanation, which tells "why the image is of a certain category" or "why the image is not of a certain category." We design a new loss tailored for SCOUTER that controls the model's behavior to switch between positive and negative explanations, as well as the size of explanatory regions. Experimental results show that SCOUTER can give better visual explanations while keeping good accuracy on a large dataset.
RGB-D SLAM Using Attention Guided Frame Association
Jan 28, 2022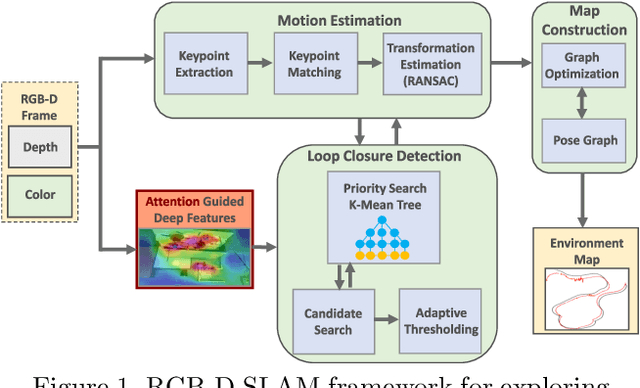
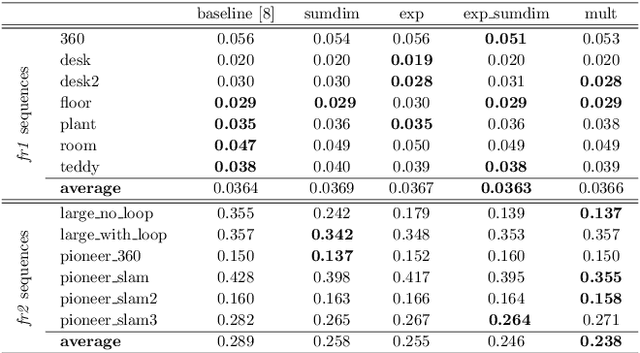
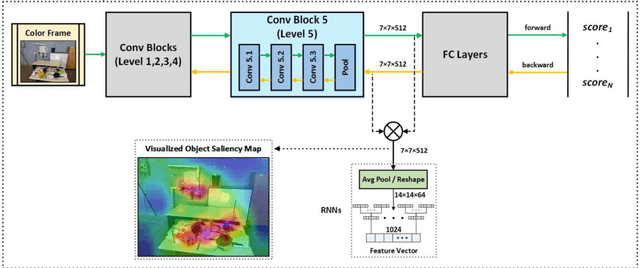
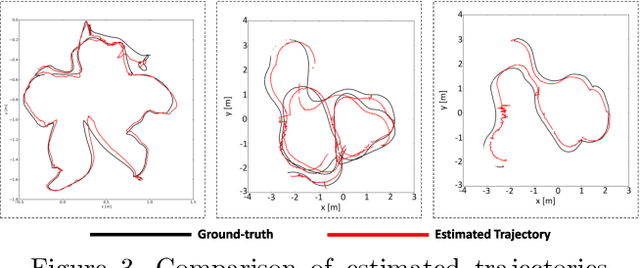
Deep learning models as an emerging topic have shown great progress in various fields. Especially, visualization tools such as class activation mapping methods provided visual explanation on the reasoning of convolutional neural networks (CNNs). By using the gradients of the network layers, it is possible to demonstrate where the networks pay attention during a specific image recognition task. Moreover, these gradients can be integrated with CNN features for localizing more generalized task dependent attentive (salient) objects in scenes. Despite this progress, there is not much explicit usage of this gradient (network attention) information to integrate with CNN representations for object semantics. This can be very useful for visual tasks such as simultaneous localization and mapping (SLAM) where CNN representations of spatially attentive object locations may lead to improved performance. Therefore, in this work, we propose the use of task specific network attention for RGB-D indoor SLAM. To do so, we integrate layer-wise object attention information (layer gradients) with CNN layer representations to improve frame association performance in a state-of-the-art RGB-D indoor SLAM method. Experiments show promising initial results with improved performance.
A Content Transformation Block For Image Style Transfer
Mar 18, 2020
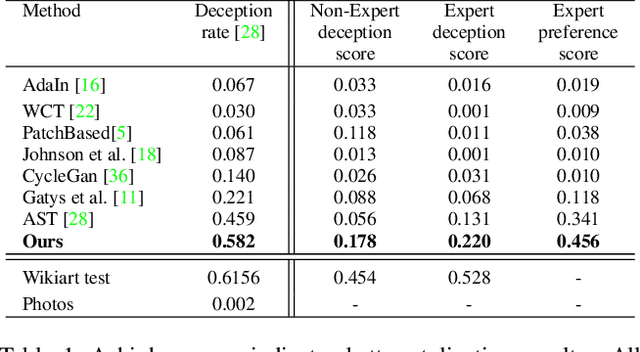
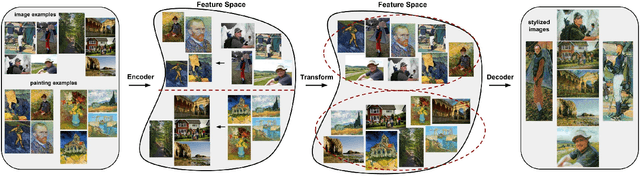
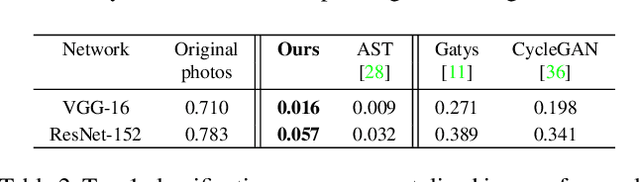
Style transfer has recently received a lot of attention, since it allows to study fundamental challenges in image understanding and synthesis. Recent work has significantly improved the representation of color and texture and computational speed and image resolution. The explicit transformation of image content has, however, been mostly neglected: while artistic style affects formal characteristics of an image, such as color, shape or texture, it also deforms, adds or removes content details. This paper explicitly focuses on a content-and style-aware stylization of a content image. Therefore, we introduce a content transformation module between the encoder and decoder. Moreover, we utilize similar content appearing in photographs and style samples to learn how style alters content details and we generalize this to other class details. Additionally, this work presents a novel normalization layer critical for high resolution image synthesis. The robustness and speed of our model enables a video stylization in real-time and high definition. We perform extensive qualitative and quantitative evaluations to demonstrate the validity of our approach.
Retinex-inspired Unrolling with Cooperative Prior Architecture Search for Low-light Image Enhancement
Dec 10, 2020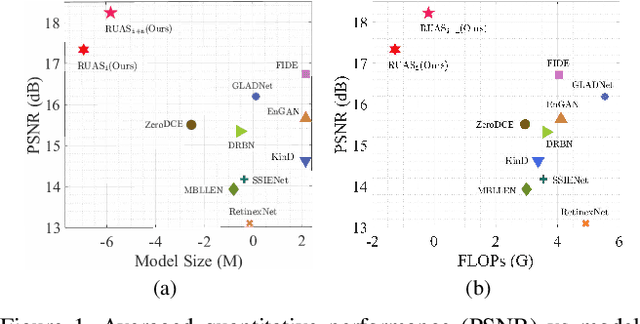

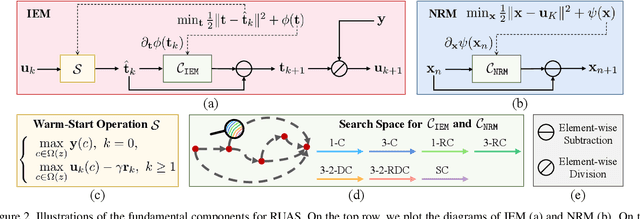

Low-light image enhancement plays very important roles in low-level vision field. Recent works have built a large variety of deep learning models to address this task. However, these approaches mostly rely on significant architecture engineering and suffer from high computational burden. In this paper, we propose a new method, named Retinex-inspired Unrolling with Architecture Search (RUAS), to construct lightweight yet effective enhancement network for low-light images in real-world scenario. Specifically, building upon Retinex rule, RUAS first establishes models to characterize the intrinsic underexposed structure of low-light images and unroll their optimization processes to construct our holistic propagation structure. Then by designing a cooperative reference-free learning strategy to discover low-light prior architectures from a compact search space, RUAS is able to obtain a top-performing image enhancement network, which is with fast speed and requires few computational resources. Extensive experiments verify the superiority of our RUAS framework against recently proposed state-of-the-art methods.
Nonlocal Adaptive Direction-Guided Structure Tensor Total Variation For Image Recovery
Aug 28, 2020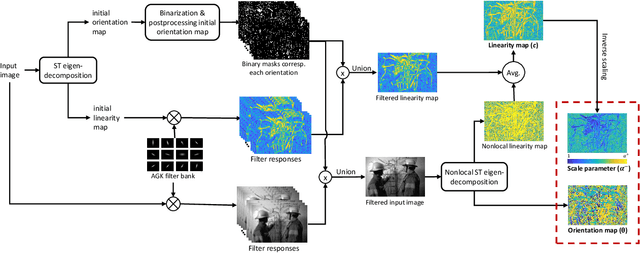
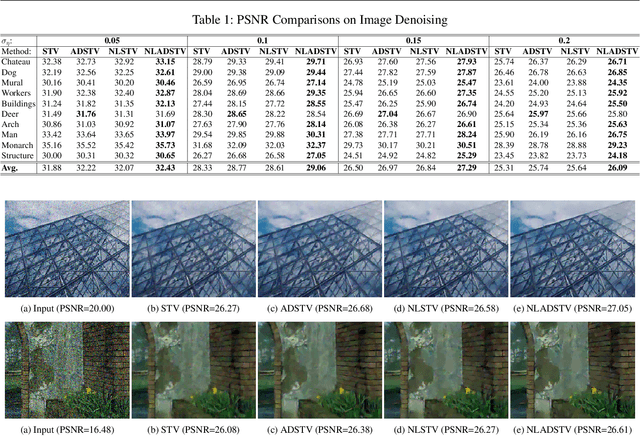

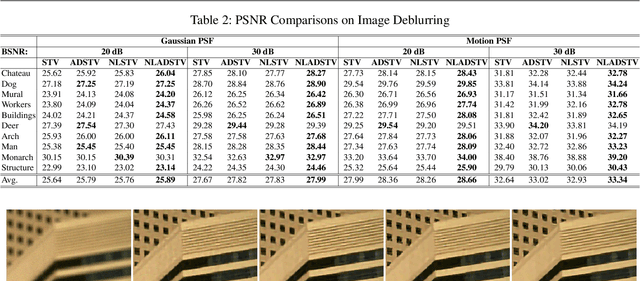
A common strategy in variational image recovery is utilizing the nonlocal self-similarity (NSS) property, when designing energy functionals. One such contribution is nonlocal structure tensor total variation (NLSTV), which lies at the core of this study. This paper is concerned with boosting the NLSTV regularization term through the use of directional priors. More specifically, NLSTV is leveraged so that, at each image point, it gains more sensitivity in the direction that is presumed to have the minimum local variation. The actual difficulty here is capturing this directional information from the corrupted image. In this regard, we propose a method that employs anisotropic Gaussian kernels to estimate directional features to be later used by our proposed model. The experiments validate that our entire two-stage framework achieves better results than the NLSTV model and two other competing local models, in terms of visual and quantitative evaluation.
Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Oct 14, 2021
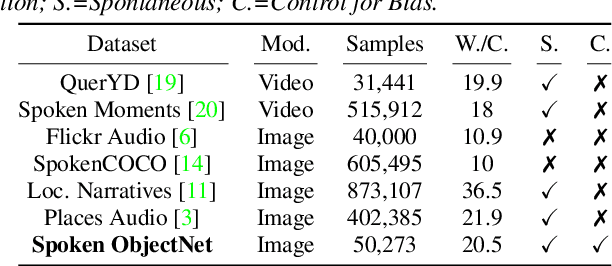


Visually-grounded spoken language datasets can enable models to learn cross-modal correspondences with very weak supervision. However, modern audio-visual datasets contain biases that undermine the real-world performance of models trained on that data. We introduce Spoken ObjectNet, which is designed to remove some of these biases and provide a way to better evaluate how effectively models will perform in real-world scenarios. This dataset expands upon ObjectNet, which is a bias-controlled image dataset that features similar image classes to those present in ImageNet. We detail our data collection pipeline, which features several methods to improve caption quality, including automated language model checks. Lastly, we show baseline results on image retrieval and audio retrieval tasks. These results show that models trained on other datasets and then evaluated on Spoken ObjectNet tend to perform poorly due to biases in other datasets that the models have learned. We also show evidence that the performance decrease is due to the dataset controls, and not the transfer setting.
Posterior temperature optimized Bayesian models for inverse problems in medical imaging
Feb 02, 2022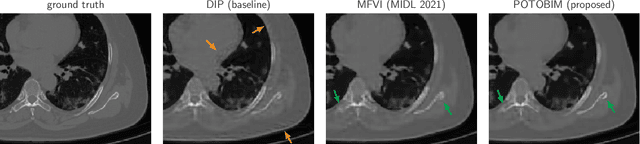
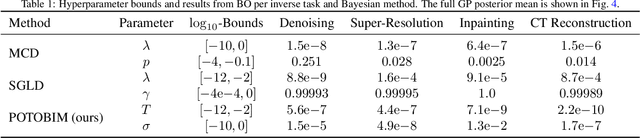
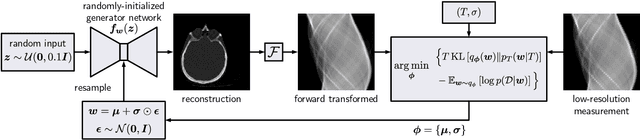
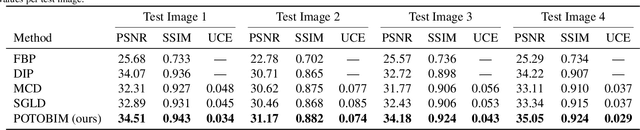
We present Posterior Temperature Optimized Bayesian Inverse Models (POTOBIM), an unsupervised Bayesian approach to inverse problems in medical imaging using mean-field variational inference with a fully tempered posterior. Bayesian methods exhibit useful properties for approaching inverse tasks, such as tomographic reconstruction or image denoising. A suitable prior distribution introduces regularization, which is needed to solve the ill-posed problem and reduces overfitting the data. In practice, however, this often results in a suboptimal posterior temperature, and the full potential of the Bayesian approach is not being exploited. In POTOBIM, we optimize both the parameters of the prior distribution and the posterior temperature with respect to reconstruction accuracy using Bayesian optimization with Gaussian process regression. Our method is extensively evaluated on four different inverse tasks on a variety of modalities with images from public data sets and we demonstrate that an optimized posterior temperature outperforms both non-Bayesian and Bayesian approaches without temperature optimization. The use of an optimized prior distribution and posterior temperature leads to improved accuracy and uncertainty estimation and we show that it is sufficient to find these hyperparameters per task domain. Well-tempered posteriors yield calibrated uncertainty, which increases the reliability in the predictions. Our source code is publicly available at github.com/Cardio-AI/mfvi-dip-mia.
Improving the repeatability of deep learning models with Monte Carlo dropout
Feb 15, 2022
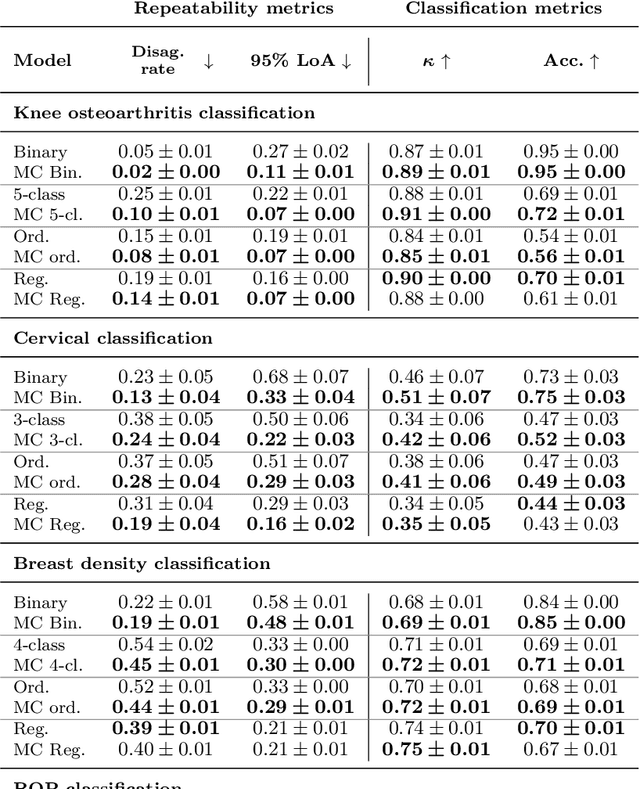
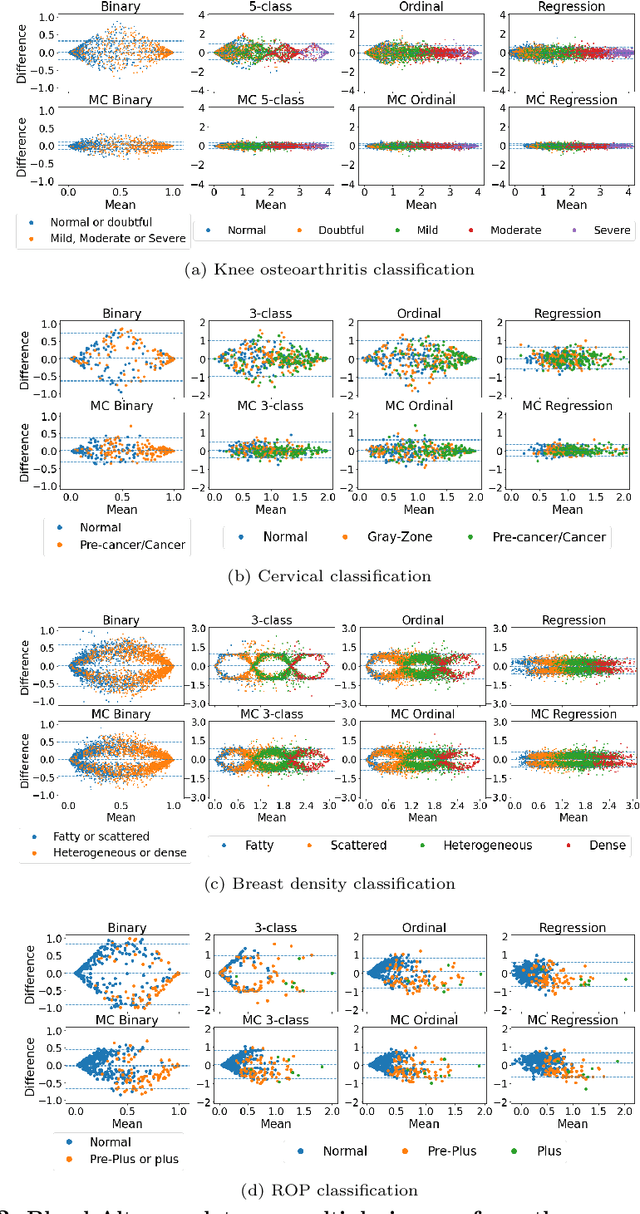
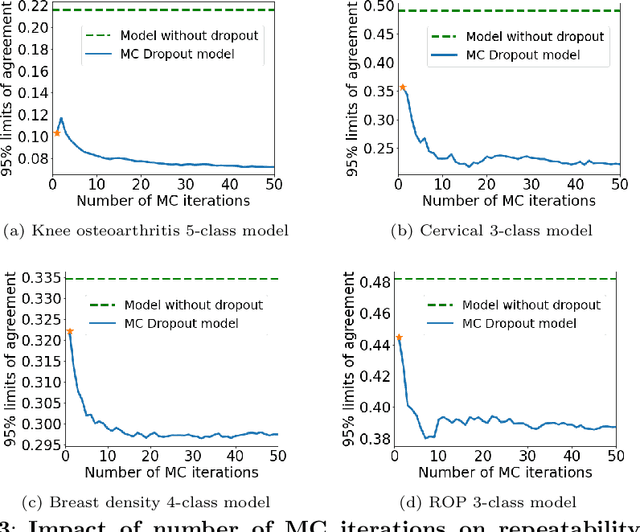
The integration of artificial intelligence into clinical workflows requires reliable and robust models. Repeatability is a key attribute of model robustness. Repeatable models output predictions with low variation during independent tests carried out under similar conditions. During model development and evaluation, much attention is given to classification performance while model repeatability is rarely assessed, leading to the development of models that are unusable in clinical practice. In this work, we evaluate the repeatability of four model types (binary classification, multi-class classification, ordinal classification, and regression) on images that were acquired from the same patient during the same visit. We study the performance of binary, multi-class, ordinal, and regression models on four medical image classification tasks from public and private datasets: knee osteoarthritis, cervical cancer screening, breast density estimation, and retinopathy of prematurity. Repeatability is measured and compared on ResNet and DenseNet architectures. Moreover, we assess the impact of sampling Monte Carlo dropout predictions at test time on classification performance and repeatability. Leveraging Monte Carlo predictions significantly increased repeatability for all tasks on the binary, multi-class, and ordinal models leading to an average reduction of the 95\% limits of agreement by 16% points and of the disagreement rate by 7% points. The classification accuracy improved in most settings along with the repeatability. Our results suggest that beyond about 20 Monte Carlo iterations, there is no further gain in repeatability. In addition to the higher test-retest agreement, Monte Carlo predictions were better calibrated which leads to output probabilities reflecting more accurately the true likelihood of being correctly classified.
On the Post-hoc Explainability of Deep Echo State Networks for Time Series Forecasting, Image and Video Classification
Feb 17, 2021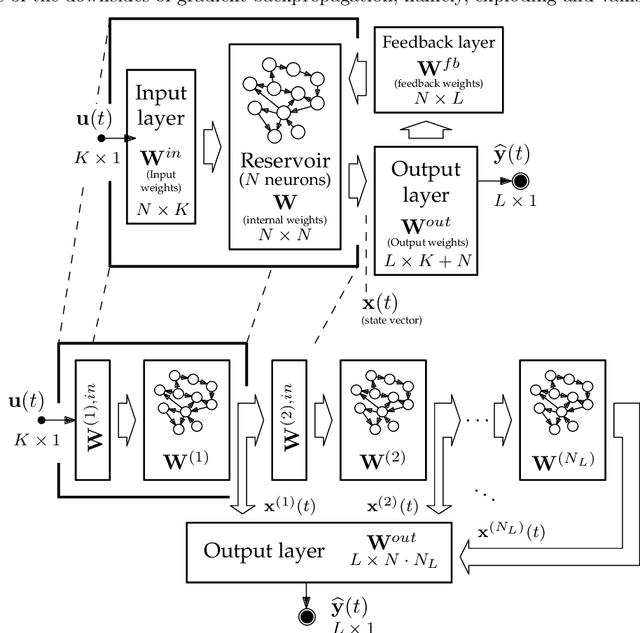
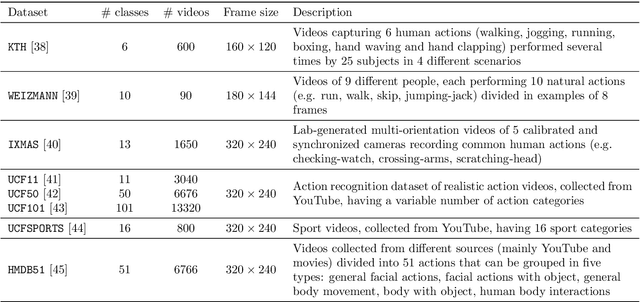
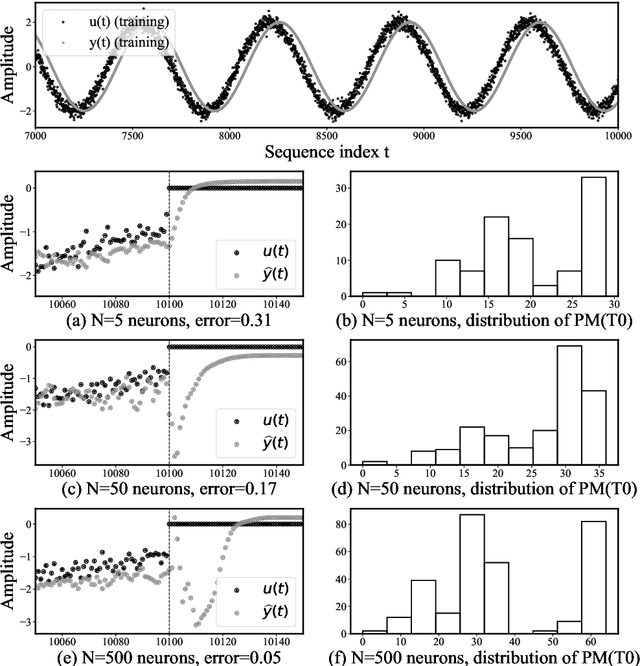
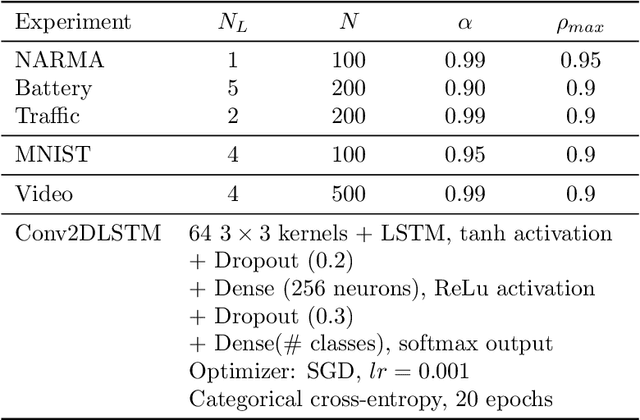
Since their inception, learning techniques under the Reservoir Computing paradigm have shown a great modeling capability for recurrent systems without the computing overheads required for other approaches. Among them, different flavors of echo state networks have attracted many stares through time, mainly due to the simplicity and computational efficiency of their learning algorithm. However, these advantages do not compensate for the fact that echo state networks remain as black-box models whose decisions cannot be easily explained to the general audience. This work addresses this issue by conducting an explainability study of Echo State Networks when applied to learning tasks with time series, image and video data. Specifically, the study proposes three different techniques capable of eliciting understandable information about the knowledge grasped by these recurrent models, namely, potential memory, temporal patterns and pixel absence effect. Potential memory addresses questions related to the effect of the reservoir size in the capability of the model to store temporal information, whereas temporal patterns unveils the recurrent relationships captured by the model over time. Finally, pixel absence effect attempts at evaluating the effect of the absence of a given pixel when the echo state network model is used for image and video classification. We showcase the benefits of our proposed suite of techniques over three different domains of applicability: time series modeling, image and, for the first time in the related literature, video classification. Our results reveal that the proposed techniques not only allow for a informed understanding of the way these models work, but also serve as diagnostic tools capable of detecting issues inherited from data (e.g. presence of hidden bias).