 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semantics-Aware Image to Image Translation and Domain Transfer
Apr 03, 2019

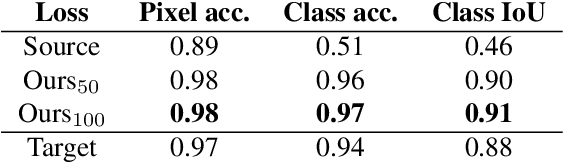
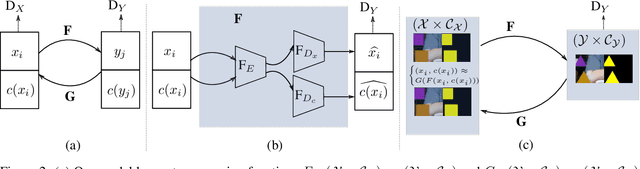
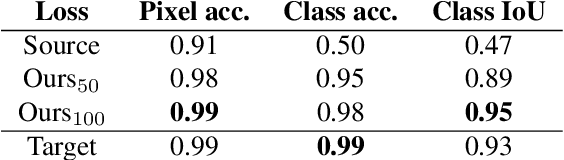
Image to image translation is the problem of transferring an image from a source domain to a target domain. We present a new method to transfer the underlying semantics of an image even when there are geometric changes across the two domains. Specifically, we present a Generative Adversarial Network (GAN) that can transfer semantic information presented as segmentation masks. Our main technical contribution is an encoder-decoder based generator architecture that jointly encodes the image and its underlying semantics and translates both simultaneously to the target domain. Additionally, we propose object transfiguration and cross-domain semantic consistency losses that preserve the underlying semantic labels maps. We demonstrate the effectiveness of our approach in multiple object transfiguration and domain transfer tasks through qualitative and quantitative experiments. The results show that our method is better at transferring image semantics than state of the art image to image translation methods.
RectiNet-v2: A stacked network architecture for document image dewarping
Feb 01, 2021
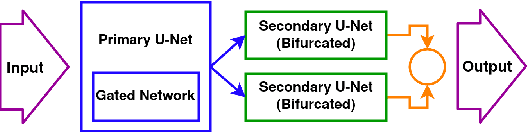
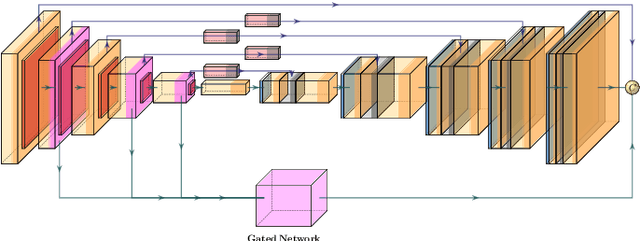
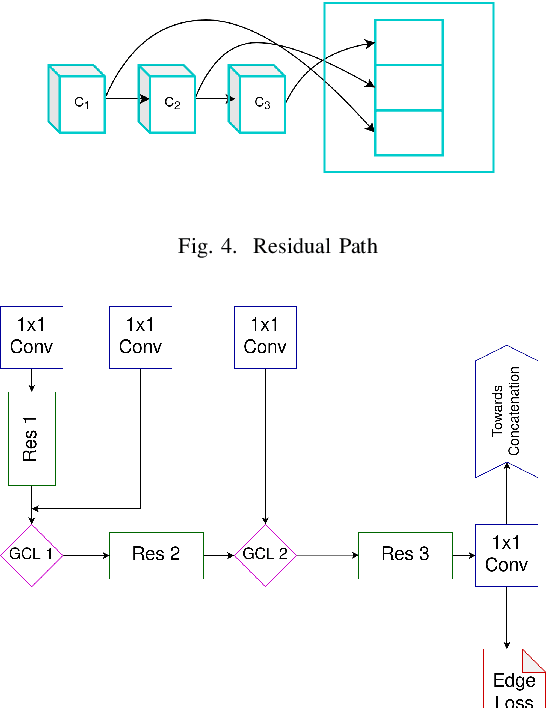
With the advent of mobile and hand-held cameras, document images have found their way into almost every domain. Dewarping of these images for the removal of perspective distortions and folds is essential so that they can be understood by document recognition algorithms. For this, we propose an end-to-end CNN architecture that can produce distortion free document images from warped documents it takes as input. We train this model on warped document images simulated synthetically to compensate for lack of enough natural data. Our method is novel in the use of a bifurcated decoder with shared weights to prevent intermingling of grid coordinates, in the use of residual networks in the U-Net skip connections to allow flow of data from different receptive fields in the model, and in the use of a gated network to help the model focus on structure and line level detail of the document image. We evaluate our method on the DocUNet dataset, a benchmark in this domain, and obtain results comparable to state-of-the-art methods.
DMF-Net: Dual-Branch Multi-Scale Feature Fusion Network for copy forgery identification of anti-counterfeiting QR code
Jan 19, 2022
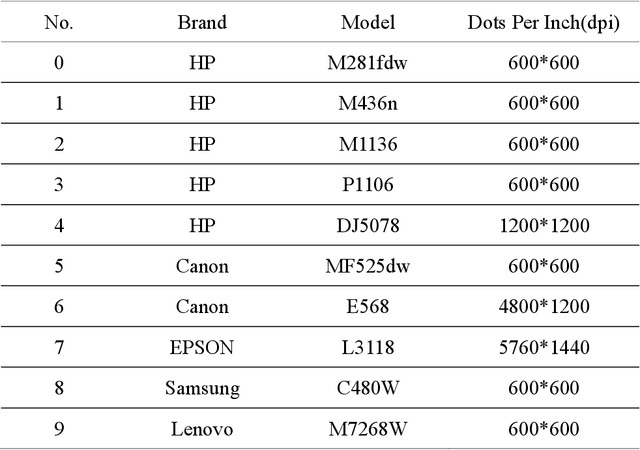

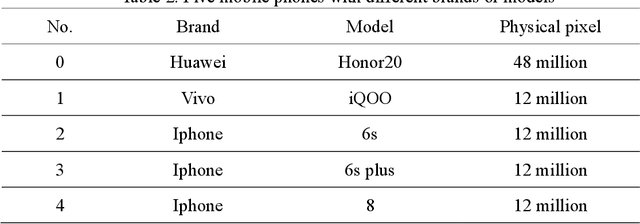
Anti-counterfeiting QR codes are widely used in people's work and life, especially in product packaging. However, the anti-counterfeiting QR code has the risk of being copied and forged in the circulation process. In reality, copying is usually based on genuine anti-counterfeiting QR codes, but the brands and models of copiers are diverse, and it is extremely difficult to determine which individual copier the forged anti-counterfeiting code come from. In response to the above problems, this paper proposes a method for copy forgery identification of anti-counterfeiting QR code based on deep learning. We first analyze the production principle of anti-counterfeiting QR code, and convert the identification of copy forgery to device category forensics, and then a Dual-Branch Multi-Scale Feature Fusion network is proposed. During the design of the network, we conducted a detailed analysis of the data preprocessing layer, single-branch design, etc., combined with experiments, the specific structure of the dual-branch multi-scale feature fusion network is determined. The experimental results show that the proposed method has achieved a high accuracy of copy forgery identification, which exceeds the current series of methods in the field of image forensics.
Superpixel Pre-Segmentation of HER2 Slides for Efficient Annotation
Jan 19, 2022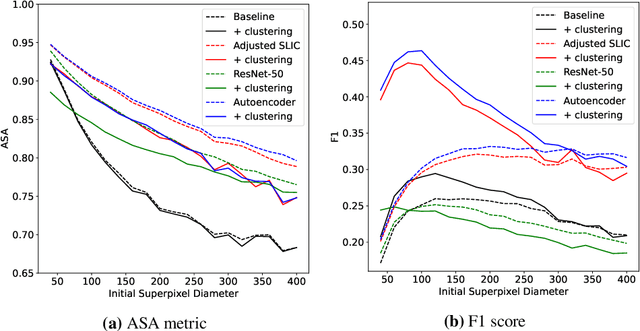
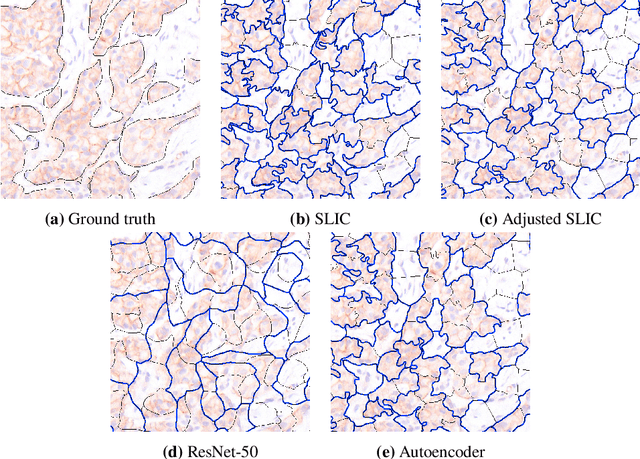
Supervised deep learning has shown state-of-the-art performance for medical image segmentation across different applications, including histopathology and cancer research; however, the manual annotation of such data is extremely laborious. In this work, we explore the use of superpixel approaches to compute a pre-segmentation of HER2 stained images for breast cancer diagnosis that facilitates faster manual annotation and correction in a second step. Four methods are compared: Standard Simple Linear Iterative Clustering (SLIC) as a baseline, a domain adapted SLIC, and superpixels based on feature embeddings of a pretrained ResNet-50 and a denoising autoencoder. To tackle oversegmentation, we propose to hierarchically merge superpixels, based on their content in the respective feature space. When evaluating the approaches on fully manually annotated images, we observe that the autoencoder-based superpixels achieve a 23% increase in boundary F1 score compared to the baseline SLIC superpixels. Furthermore, the boundary F1 score increases by 73% when hierarchical clustering is applied on the adapted SLIC and the autoencoder-based superpixels. These evaluations show encouraging first results for a pre-segmentation for efficient manual refinement without the need for an initial set of annotated training data.
When less is more: Simplifying inputs aids neural network understanding
Jan 19, 2022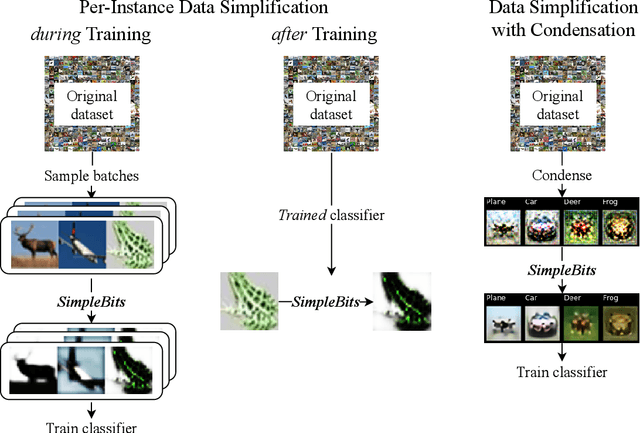

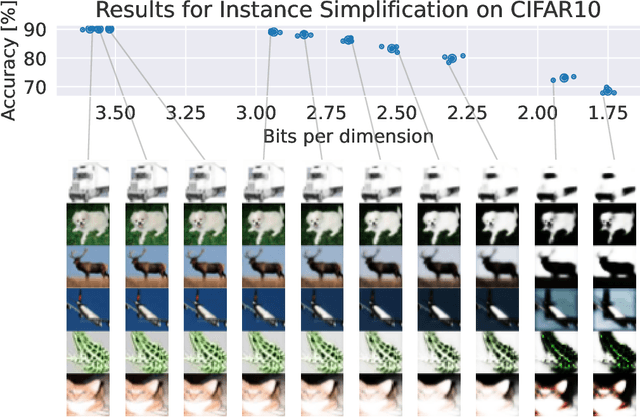
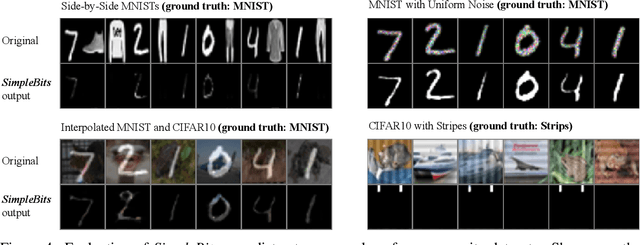
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Image Inpainting by Multiscale Spline Interpolation
Jan 10, 2020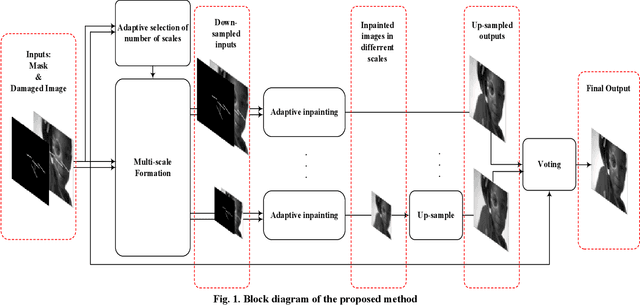
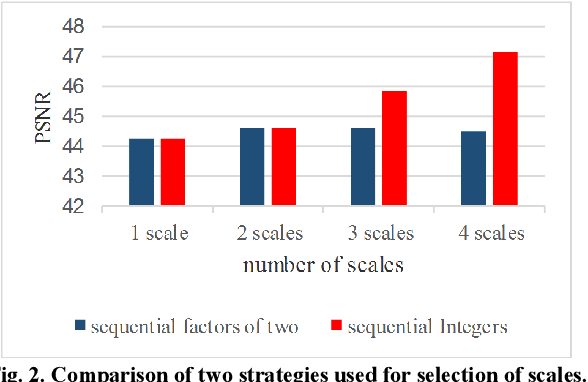
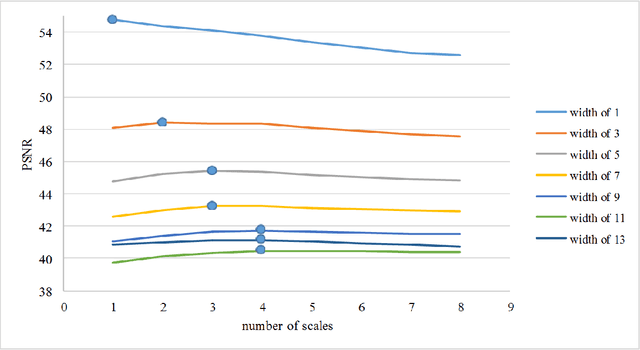

Recovering the missing regions of an image is a task that is called image inpainting. Depending on the shape of missing areas, different methods are presented in the literature. One of the challenges of this problem is extracting features that lead to better results. Experimental results show that both global and local features are useful for this purpose. In this paper, we propose a multi-scale image inpainting method that utilizes both local and global features. The first step of this method is to determine how many scales we need to use, which depends on the width of the lines in the map of the missing region. Then we apply adaptive image inpainting to the damaged areas of the image, and the lost pixels are predicted. Each scale is inpainted and the result is resized to the original size. Then a voting process produces the final result. The proposed method is tested on damaged images with scratches and creases. The metric that we use to evaluate our approach is PSNR. On average, we achieved 1.2 dB improvement over some existing inpainting approaches.
Deep Joint Demosaicing and High Dynamic Range Imaging within a Single Shot
Nov 14, 2021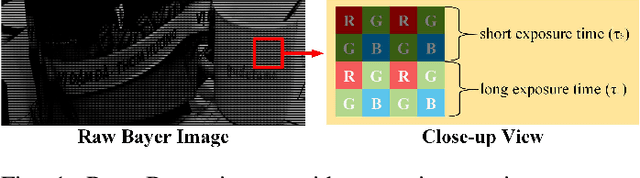
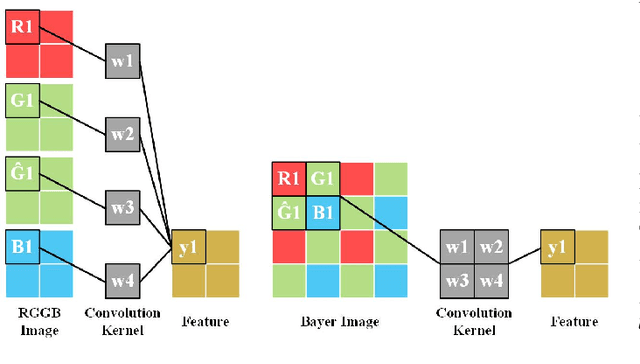


Spatially varying exposure (SVE) is a promising choice for high-dynamic-range (HDR) imaging (HDRI). The SVE-based HDRI, which is called single-shot HDRI, is an efficient solution to avoid ghosting artifacts. However, it is very challenging to restore a full-resolution HDR image from a real-world image with SVE because: a) only one-third of pixels with varying exposures are captured by camera in a Bayer pattern, b) some of the captured pixels are over- and under-exposed. For the former challenge, a spatially varying convolution (SVC) is designed to process the Bayer images carried with varying exposures. For the latter one, an exposure-guidance method is proposed against the interference from over- and under-exposed pixels. Finally, a joint demosaicing and HDRI deep learning framework is formalized to include the two novel components and to realize an end-to-end single-shot HDRI. Experiments indicate that the proposed end-to-end framework avoids the problem of cumulative errors and surpasses the related state-of-the-art methods.
Seeing BDD100K in dark: Single-Stage Night-time Object Detection via Continual Fourier Contrastive Learning
Dec 06, 2021

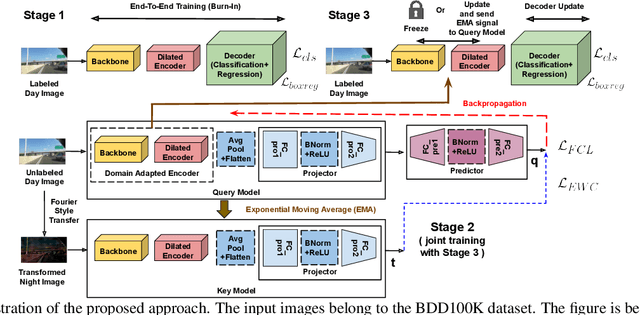
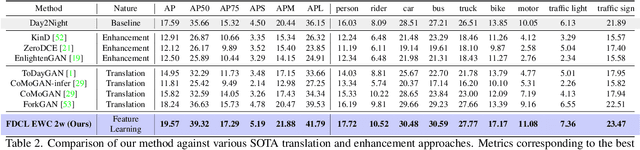
Despite tremendous improvements in state-of-the-art object detectors, addressing object detection in the night-time has been studied only sparsely, that too, via non-uniform evaluation protocols among the limited available papers. In addition to the lack of methods to address this problem, there was also a lack of an adequately large benchmark dataset to study night-time object detection. Recently, the large scale BDD100K was introduced, which, in our opinion, should be chosen as the benchmark, to kickstart research in this area. Now, coming to the methods, existing approaches (limited in number), are mainly either generative image translation based, or image enhancement/ illumination based, neither of which is natural, conforming to how humans see objects in the night time (by focusing on object contours). In this paper, we bridge these 3 gaps: 1. Lack of an uniform evaluation protocol (using a single-stage detector, due to its efficacy, and efficiency), 2. Choice of dataset for benchmarking night-time object detection, and 3. A novel method to address the limitations of current alternatives. Our method leverages a Contrastive Learning based feature extractor, borrowing information from the frequency domain via Fourier transformation, and trained in a continual learning based fashion. The learned features when used for object detection (after fine-tuning the classification and regression layers), help achieve a new state-of-the-art empirical performance, comfortably outperforming an extensive number of competitors.
An Image Encryption Scheme Based on Chaotic Logarithmic Map and Key Generation using Deep CNN
Dec 28, 2020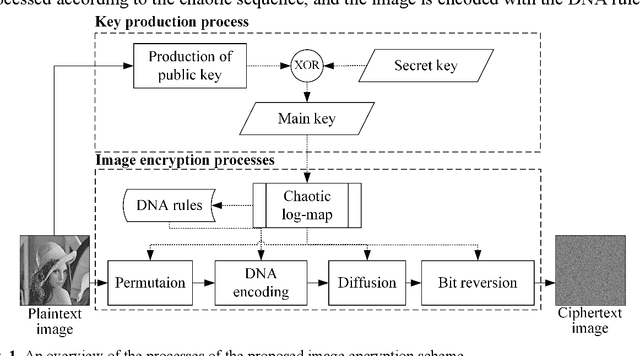
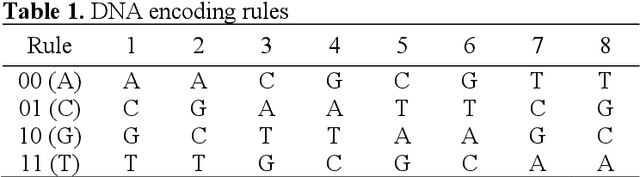
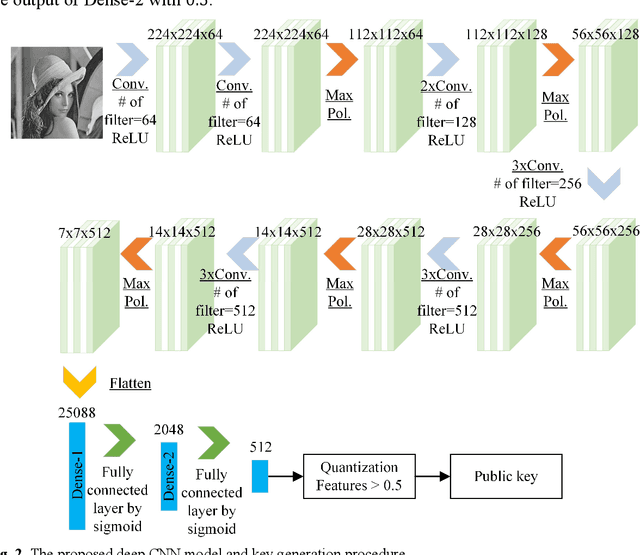
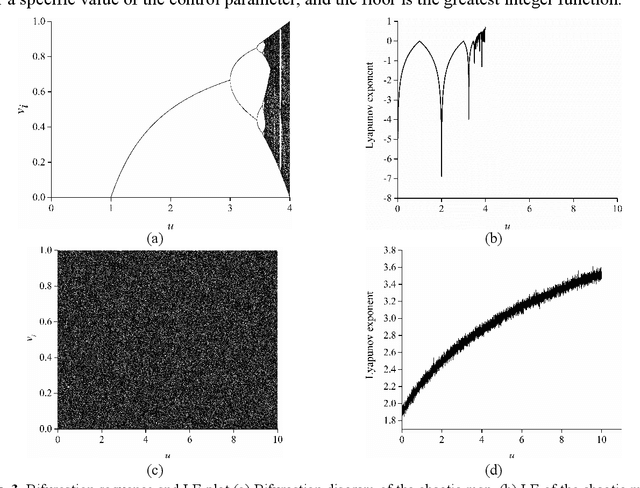
A secure and reliable image encryption scheme is presented in this study. The encryption scheme hereby introduces a novel chaotic log-map, deep convolution neural network (CNN) model for key generation, and bit reversion operation for the manipulation process. Thanks to the sensitive key generation, initial values and control parameters are produced for the hyperchaotic log-map, and thus a diverse chaotic sequence is achieved for encrypting operations. The scheme then encrypts the images by scrambling and manipulating the pixels of images through four operations: permutation, DNA encoding, diffusion, and bit reversion. The encryption scheme is precisely examined for the well-known images in terms of various analyses such as keyspace, key sensitivity, information entropy, histogram, correlation, differential attack, noisy attack, and cropping attack. To corroborate the scheme, the visual and numerical results are even compared with available outcomes of the state of the art. Therefore, the proposed log-map based image encryption scheme is successfully verified and validated by the superior absolute and comparative results.
Texture image classification based on a pseudo-parabolic diffusion model
Nov 14, 2020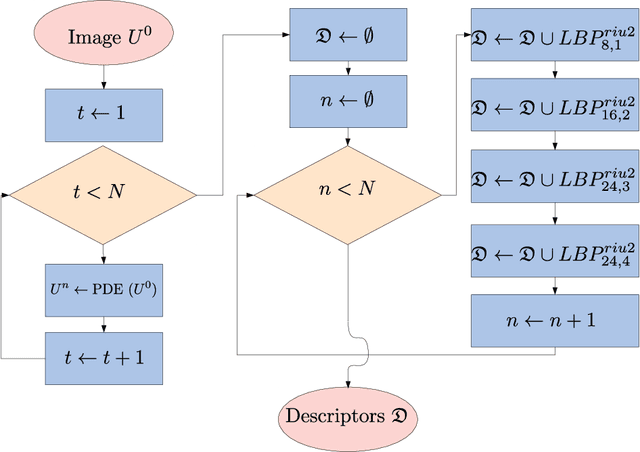
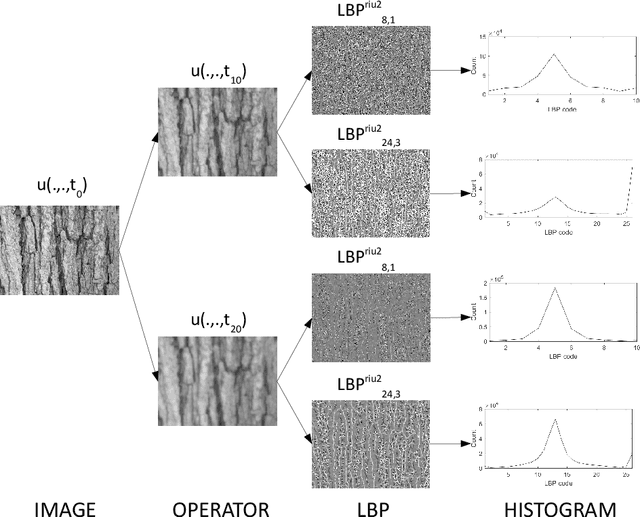
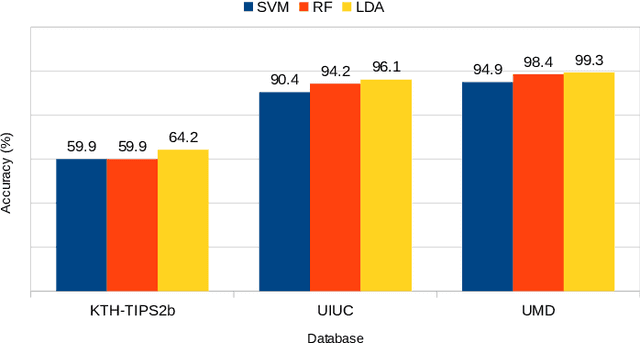
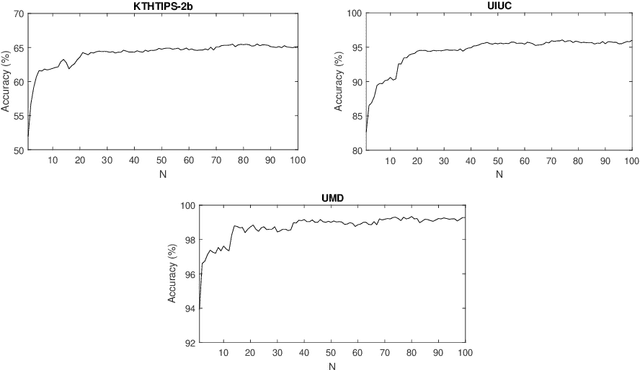
This work proposes a novel method based on a pseudo-parabolic diffusion process to be employed for texture recognition. The proposed operator is applied over a range of time scales giving rise to a family of images transformed by nonlinear filters. Therefore each of those images are encoded by a local descriptor (we use local binary patterns for that purpose) and they are summarized by a simple histogram, yielding in this way the image feature vector. The proposed approach is tested on the classification of well established benchmark texture databases and on a practical task of plant species recognition. In both cases, it is compared with several state-of-the-art methodologies employed for texture recognition. Our proposal outperforms those methods in terms of classification accuracy, confirming its competitiveness. The good performance can be justified to a large extent by the ability of the pseudo-parabolic operator to smooth possibly noisy details inside homogeneous regions of the image at the same time that it preserves discontinuities that convey critical information for the object description. Such results also confirm that model-based approaches like the proposed one can still be competitive with the omnipresent learning-based approaches, especially when the user does not have access to a powerful computational structure and a large amount of labeled data for training.