 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Desmoking laparoscopy surgery images using an image-to-image translation guided by an embedded dark channel
Apr 19, 2020
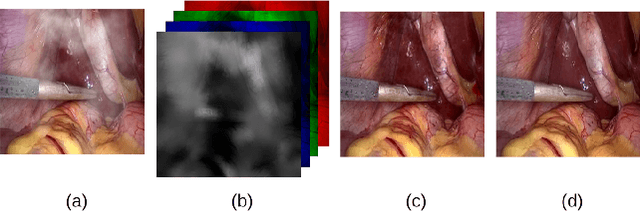
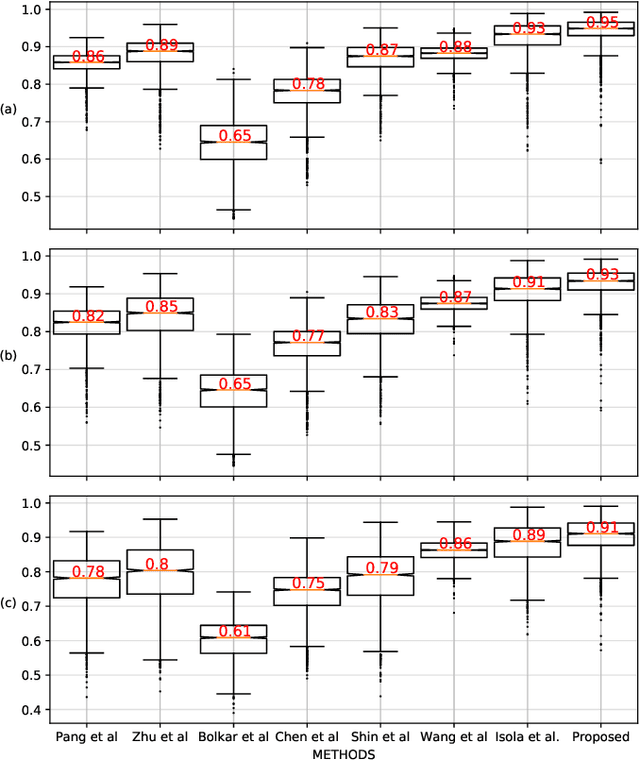
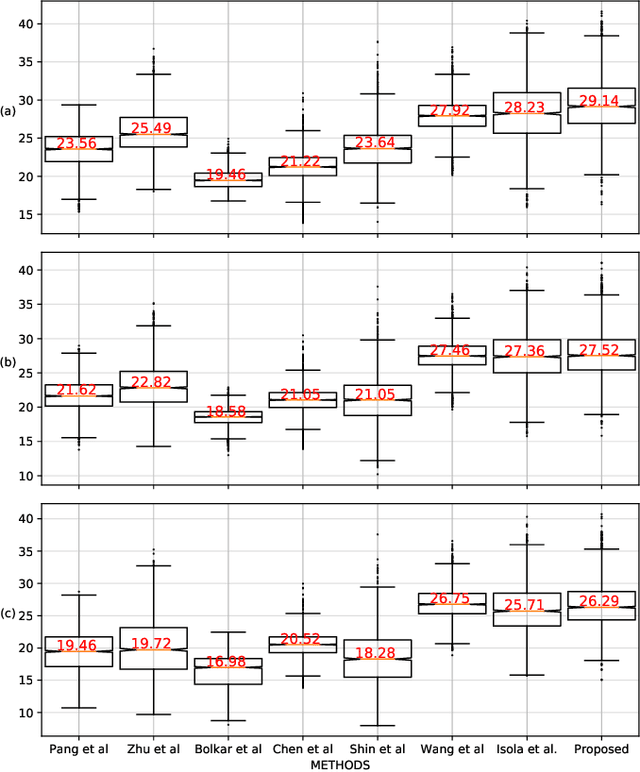
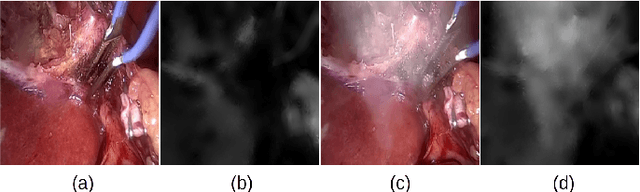
In laparoscopic surgery, the visibility in the image can be severely degraded by the smoke caused by the $CO_2$ injection, and dissection tools, thus reducing the visibility of organs and tissues. This lack of visibility increases the surgery time and even the probability of mistakes conducted by the surgeon, then producing negative consequences on the patient's health. In this paper, a novel computational approach to remove the smoke effects is introduced. The proposed method is based on an image-to-image conditional generative adversarial network in which a dark channel is used as an embedded guide mask. Obtained experimental results are evaluated and compared quantitatively with other desmoking and dehazing state-of-art methods using the metrics of the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM) index. Based on these metrics, it is found that the proposed method has improved performance compared to the state-of-the-art. Moreover, the processing time required by our method is 92 frames per second, and thus, it can be applied in a real-time medical system trough an embedded device.
RectiNet-v2: A stacked network architecture for document image dewarping
Feb 01, 2021
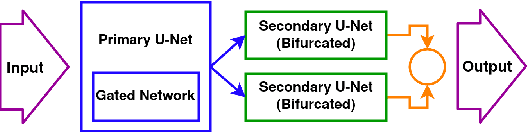
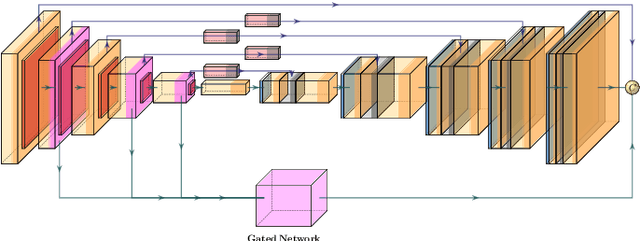
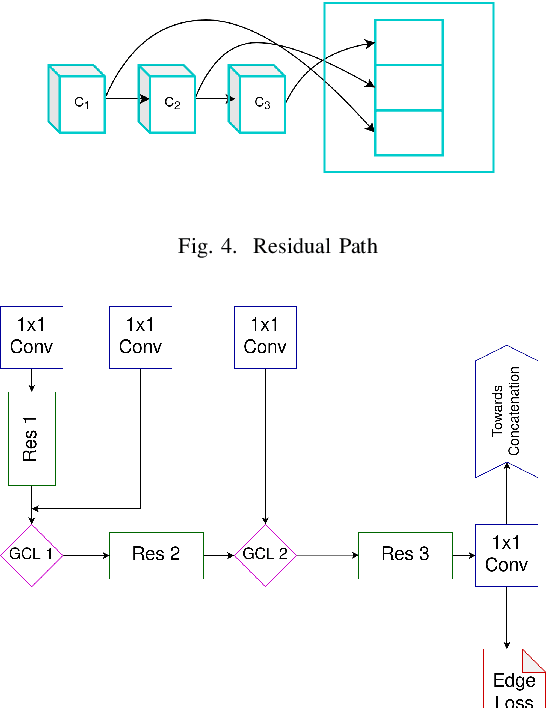
With the advent of mobile and hand-held cameras, document images have found their way into almost every domain. Dewarping of these images for the removal of perspective distortions and folds is essential so that they can be understood by document recognition algorithms. For this, we propose an end-to-end CNN architecture that can produce distortion free document images from warped documents it takes as input. We train this model on warped document images simulated synthetically to compensate for lack of enough natural data. Our method is novel in the use of a bifurcated decoder with shared weights to prevent intermingling of grid coordinates, in the use of residual networks in the U-Net skip connections to allow flow of data from different receptive fields in the model, and in the use of a gated network to help the model focus on structure and line level detail of the document image. We evaluate our method on the DocUNet dataset, a benchmark in this domain, and obtain results comparable to state-of-the-art methods.
CondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems
Dec 01, 2021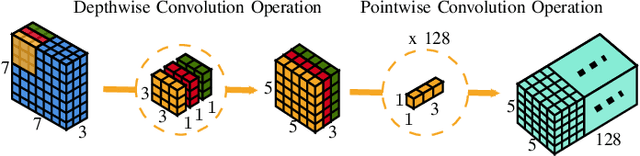
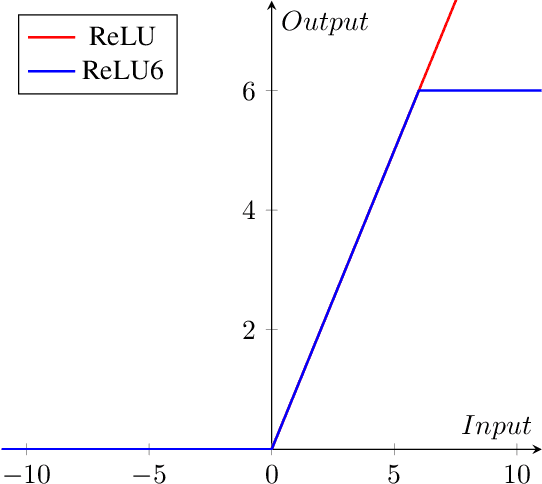
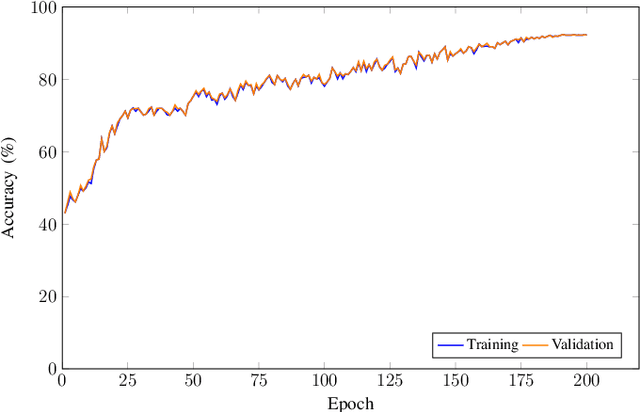

Due to the advent of modern embedded systems and mobile devices with constrained resources, there is a great demand for incredibly efficient deep neural networks for machine learning purposes. There is also a growing concern of privacy and confidentiality of user data within the general public when their data is processed and stored in an external server which has further fueled the need for developing such efficient neural networks for real-time inference on local embedded systems. The scope of our work presented in this paper is limited to image classification using a convolutional neural network. A Convolutional Neural Network (CNN) is a class of Deep Neural Network (DNN) widely used in the analysis of visual images captured by an image sensor, designed to extract information and convert it into meaningful representations for real-time inference of the input data. In this paper, we propose a neoteric variant of deep convolutional neural network architecture to ameliorate the performance of existing CNN architectures for real-time inference on embedded systems. We show that this architecture, dubbed CondenseNeXt, is remarkably efficient in comparison to the baseline neural network architecture, CondenseNet, by reducing trainable parameters and FLOPs required to train the network whilst maintaining a balance between the trained model size of less than 3.0 MB and accuracy trade-off resulting in an unprecedented computational efficiency.
Encouraging Disentangled and Convex Representation with Controllable Interpolation Regularization
Dec 06, 2021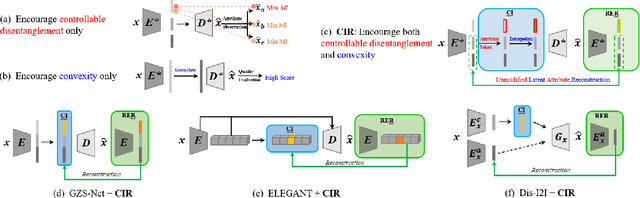
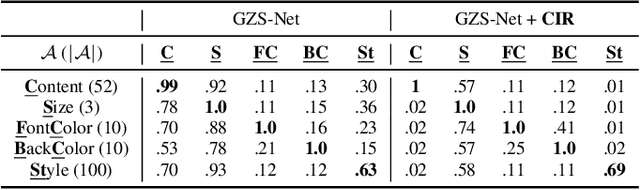

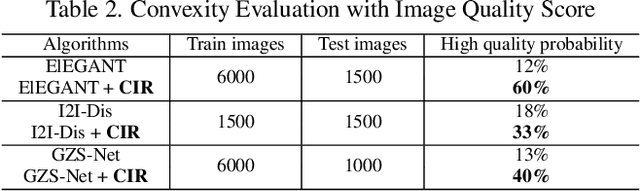
We focus on controllable disentangled representation learning (C-Dis-RL), where users can control the partition of the disentangled latent space to factorize dataset attributes (concepts) for downstream tasks. Two general problems remain under-explored in current methods: (1) They lack comprehensive disentanglement constraints, especially missing the minimization of mutual information between different attributes across latent and observation domains. (2) They lack convexity constraints in disentangled latent space, which is important for meaningfully manipulating specific attributes for downstream tasks. To encourage both comprehensive C-Dis-RL and convexity simultaneously, we propose a simple yet efficient method: Controllable Interpolation Regularization (CIR), which creates a positive loop where the disentanglement and convexity can help each other. Specifically, we conduct controlled interpolation in latent space during training and 'reuse' the encoder to help form a 'perfect disentanglement' regularization. In that case, (a) disentanglement loss implicitly enlarges the potential 'understandable' distribution to encourage convexity; (b) convexity can in turn improve robust and precise disentanglement. CIR is a general module and we merge CIR with three different algorithms: ELEGANT, I2I-Dis, and GZS-Net to show the compatibility and effectiveness. Qualitative and quantitative experiments show improvement in C-Dis-RL and latent convexity by CIR. This further improves downstream tasks: controllable image synthesis, cross-modality image translation and zero-shot synthesis. More experiments demonstrate CIR can also improve other downstream tasks, such as new attribute value mining, data augmentation, and eliminating bias for fairness.
DMF-Net: Dual-Branch Multi-Scale Feature Fusion Network for copy forgery identification of anti-counterfeiting QR code
Jan 19, 2022
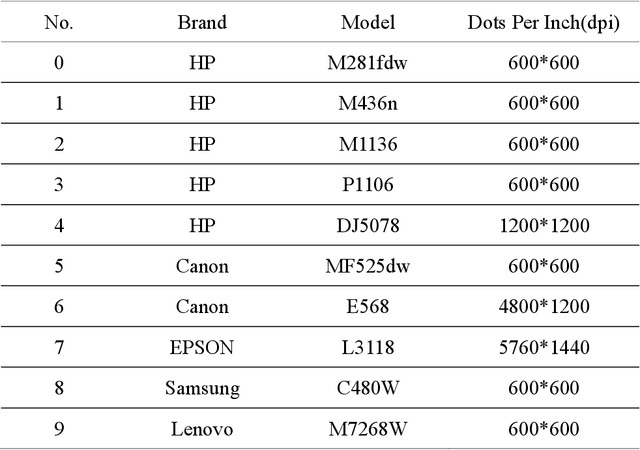

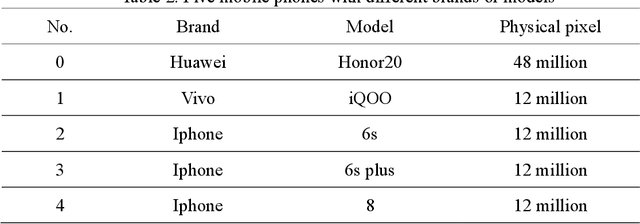
Anti-counterfeiting QR codes are widely used in people's work and life, especially in product packaging. However, the anti-counterfeiting QR code has the risk of being copied and forged in the circulation process. In reality, copying is usually based on genuine anti-counterfeiting QR codes, but the brands and models of copiers are diverse, and it is extremely difficult to determine which individual copier the forged anti-counterfeiting code come from. In response to the above problems, this paper proposes a method for copy forgery identification of anti-counterfeiting QR code based on deep learning. We first analyze the production principle of anti-counterfeiting QR code, and convert the identification of copy forgery to device category forensics, and then a Dual-Branch Multi-Scale Feature Fusion network is proposed. During the design of the network, we conducted a detailed analysis of the data preprocessing layer, single-branch design, etc., combined with experiments, the specific structure of the dual-branch multi-scale feature fusion network is determined. The experimental results show that the proposed method has achieved a high accuracy of copy forgery identification, which exceeds the current series of methods in the field of image forensics.
Superpixel Pre-Segmentation of HER2 Slides for Efficient Annotation
Jan 19, 2022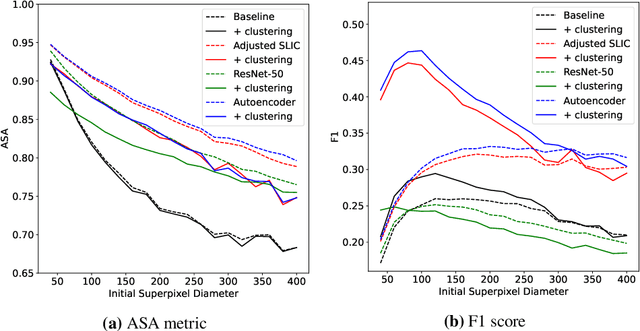
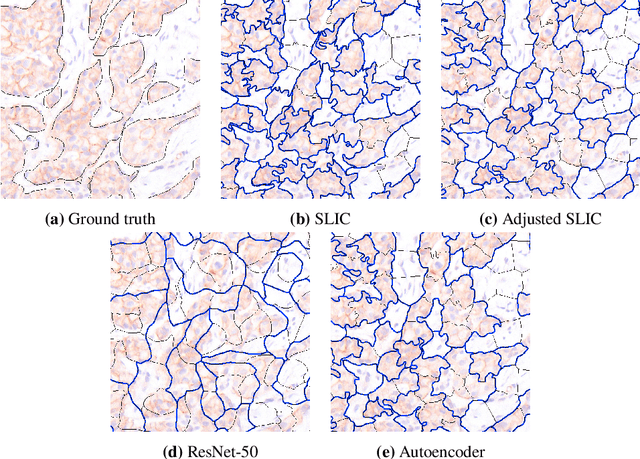
Supervised deep learning has shown state-of-the-art performance for medical image segmentation across different applications, including histopathology and cancer research; however, the manual annotation of such data is extremely laborious. In this work, we explore the use of superpixel approaches to compute a pre-segmentation of HER2 stained images for breast cancer diagnosis that facilitates faster manual annotation and correction in a second step. Four methods are compared: Standard Simple Linear Iterative Clustering (SLIC) as a baseline, a domain adapted SLIC, and superpixels based on feature embeddings of a pretrained ResNet-50 and a denoising autoencoder. To tackle oversegmentation, we propose to hierarchically merge superpixels, based on their content in the respective feature space. When evaluating the approaches on fully manually annotated images, we observe that the autoencoder-based superpixels achieve a 23% increase in boundary F1 score compared to the baseline SLIC superpixels. Furthermore, the boundary F1 score increases by 73% when hierarchical clustering is applied on the adapted SLIC and the autoencoder-based superpixels. These evaluations show encouraging first results for a pre-segmentation for efficient manual refinement without the need for an initial set of annotated training data.
Robust Edge-Direct Visual Odometry based on CNN edge detection and Shi-Tomasi corner optimization
Oct 21, 2021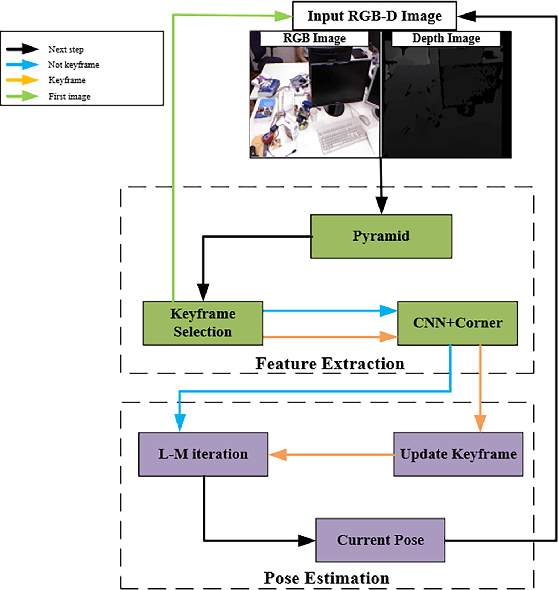
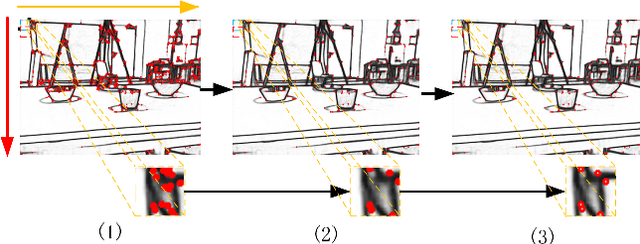
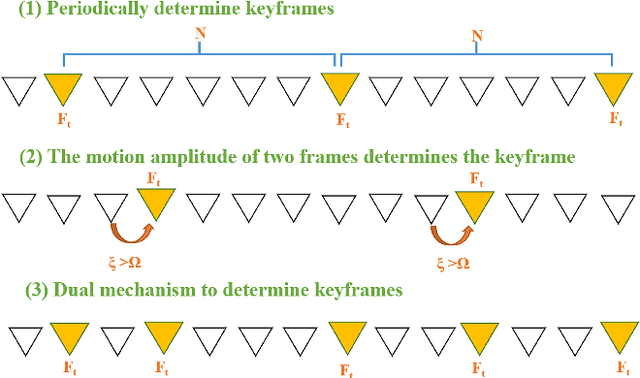
In this paper, we propose a robust edge-direct visual odometry (VO) based on CNN edge detection and Shi-Tomasi corner optimization. Four layers of pyramids were extracted from the image in the proposed method to reduce the motion error between frames. This solution used CNN edge detection and Shi-Tomasi corner optimization to extract information from the image. Then, the pose estimation is performed using the Levenberg-Marquardt (LM) algorithm and updating the keyframes. Our method was compared with the dense direct method, the improved direct method of Canny edge detection, and ORB-SLAM2 system on the RGB-D TUM benchmark. The experimental results indicate that our method achieves better robustness and accuracy.
Exploring Self-attention for Image Recognition
Apr 28, 2020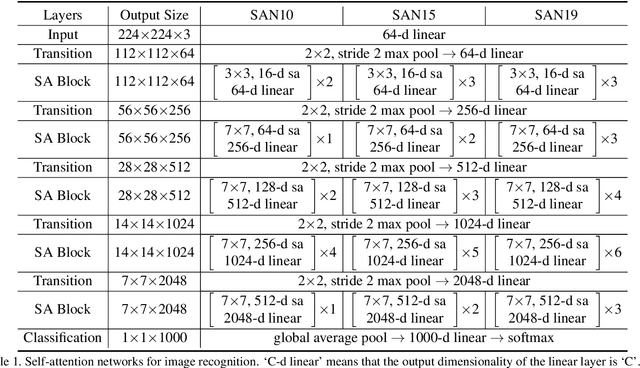
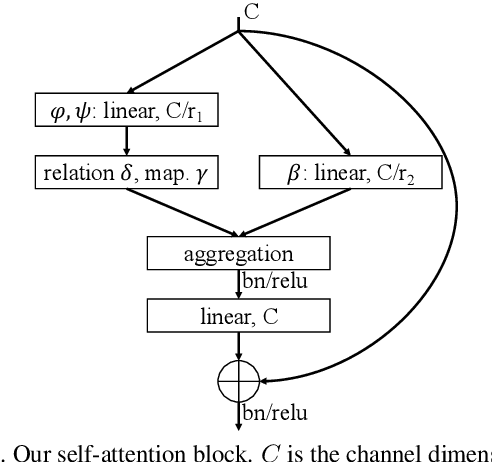


Recent work has shown that self-attention can serve as a basic building block for image recognition models. We explore variations of self-attention and assess their effectiveness for image recognition. We consider two forms of self-attention. One is pairwise self-attention, which generalizes standard dot-product attention and is fundamentally a set operator. The other is patchwise self-attention, which is strictly more powerful than convolution. Our pairwise self-attention networks match or outperform their convolutional counterparts, and the patchwise models substantially outperform the convolutional baselines. We also conduct experiments that probe the robustness of learned representations and conclude that self-attention networks may have significant benefits in terms of robustness and generalization.
When less is more: Simplifying inputs aids neural network understanding
Jan 19, 2022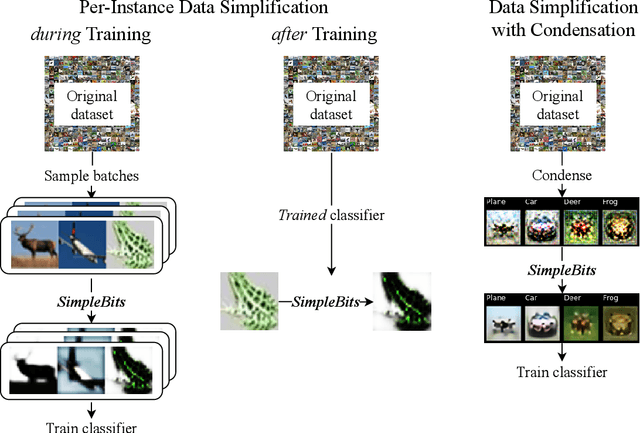

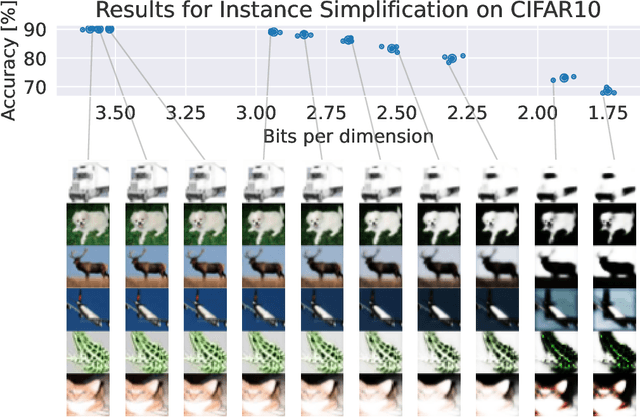
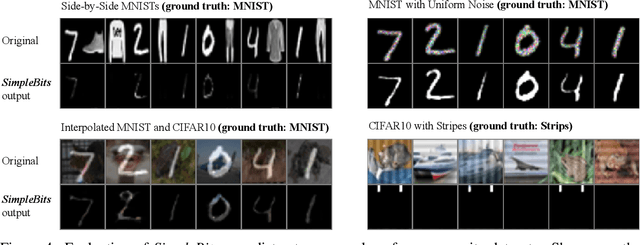
How do neural network image classifiers respond to simpler and simpler inputs? And what do such responses reveal about the learning process? To answer these questions, we need a clear measure of input simplicity (or inversely, complexity), an optimization objective that correlates with simplification, and a framework to incorporate such objective into training and inference. Lastly we need a variety of testbeds to experiment and evaluate the impact of such simplification on learning. In this work, we measure simplicity with the encoding bit size given by a pretrained generative model, and minimize the bit size to simplify inputs in training and inference. We investigate the effect of such simplification in several scenarios: conventional training, dataset condensation and post-hoc explanations. In all settings, inputs are simplified along with the original classification task, and we investigate the trade-off between input simplicity and task performance. For images with injected distractors, such simplification naturally removes superfluous information. For dataset condensation, we find that inputs can be simplified with almost no accuracy degradation. When used in post-hoc explanation, our learning-based simplification approach offers a valuable new tool to explore the basis of network decisions.
Image Segmentation Using Deep Learning: A Survey
Jan 18, 2020
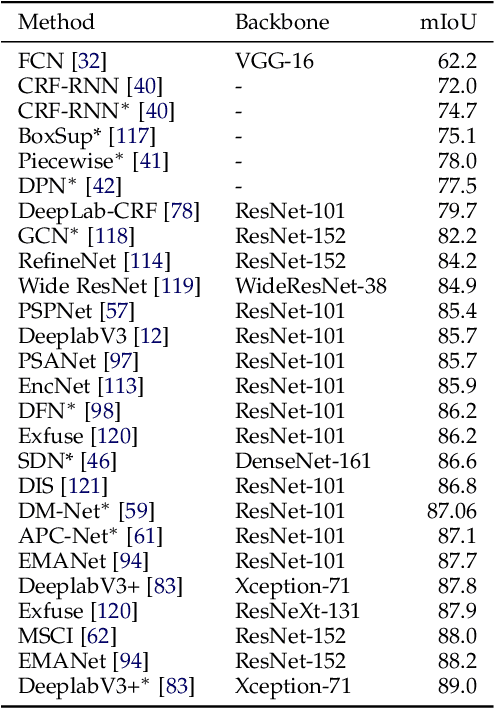
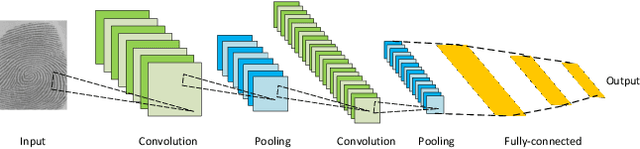
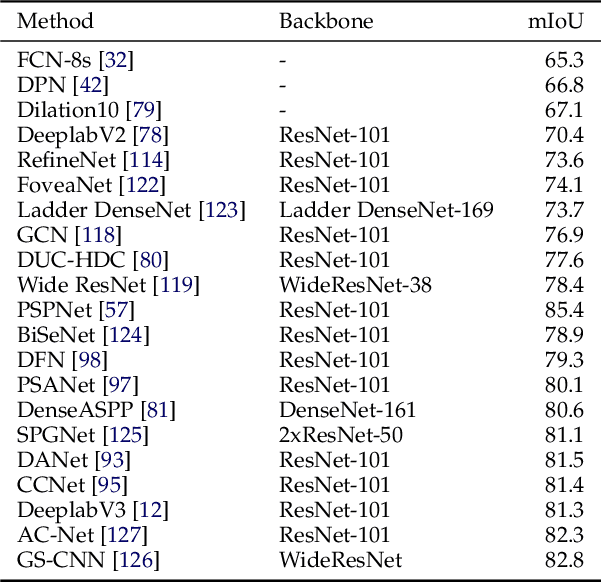
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.