 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
L-SNet: from Region Localization to Scale Invariant Medical Image Segmentation
Feb 11, 2021
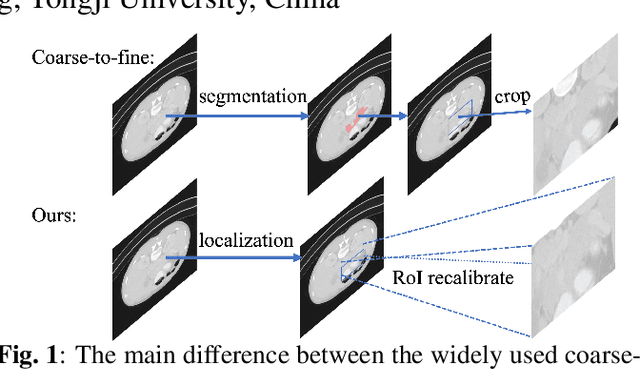
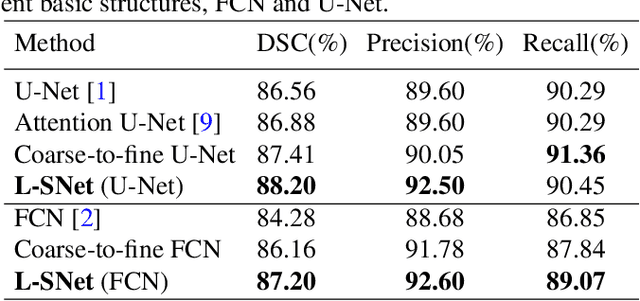
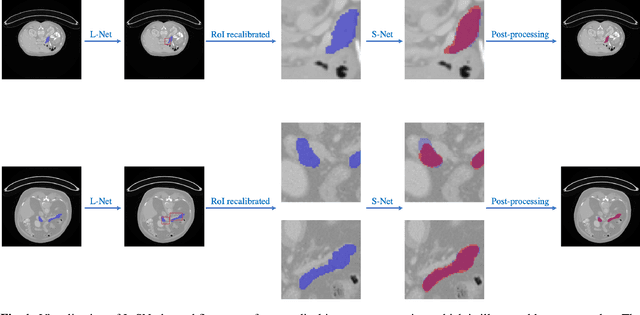
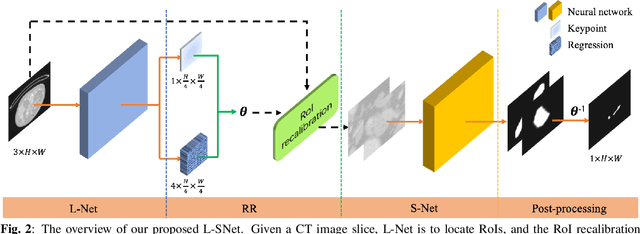
Coarse-to-fine models and cascade segmentation architectures are widely adopted to solve the problem of large scale variations in medical image segmentation. However, those methods have two primary limitations: the first-stage segmentation becomes a performance bottleneck; the lack of overall differentiability makes the training process of two stages asynchronous and inconsistent. In this paper, we propose a differentiable two-stage network architecture to tackle these problems. In the first stage, a localization network (L-Net) locates Regions of Interest (RoIs) in a detection fashion; in the second stage, a segmentation network (S-Net) performs fine segmentation on the recalibrated RoIs; a RoI recalibration module between L-Net and S-Net eliminating the inconsistencies. Experimental results on the public dataset show that our method outperforms state-of-the-art coarse-to-fine models with negligible computation overheads.
The devil is in the labels: Semantic segmentation from sentences
Feb 04, 2022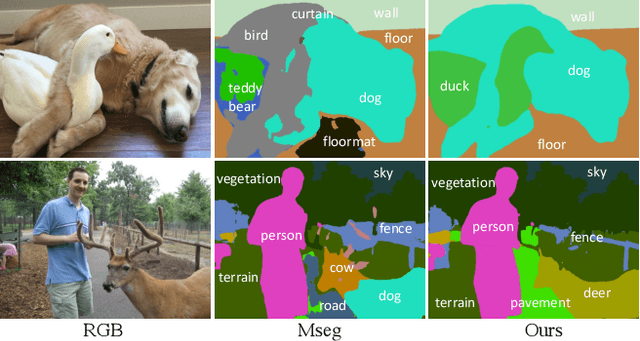
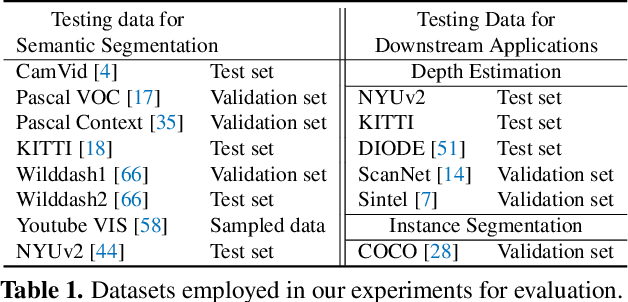
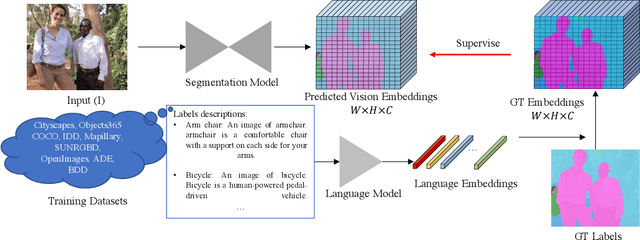
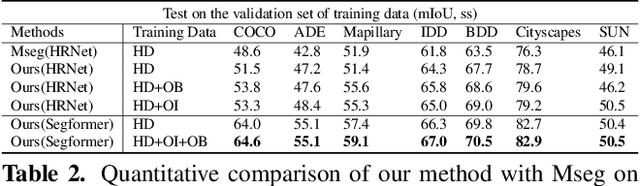
We propose an approach to semantic segmentation that achieves state-of-the-art supervised performance when applied in a zero-shot setting. It thus achieves results equivalent to those of the supervised methods, on each of the major semantic segmentation datasets, without training on those datasets. This is achieved by replacing each class label with a vector-valued embedding of a short paragraph that describes the class. The generality and simplicity of this approach enables merging multiple datasets from different domains, each with varying class labels and semantics. The resulting merged semantic segmentation dataset of over 2 Million images enables training a model that achieves performance equal to that of state-of-the-art supervised methods on 7 benchmark datasets, despite not using any images therefrom. By fine-tuning the model on standard semantic segmentation datasets, we also achieve a significant improvement over the state-of-the-art supervised segmentation on NYUD-V2 and PASCAL-context at 60% and 65% mIoU, respectively. Based on the closeness of language embeddings, our method can even segment unseen labels. Extensive experiments demonstrate strong generalization to unseen image domains and unseen labels, and that the method enables impressive performance improvements in downstream applications, including depth estimation and instance segmentation.
Determination of Fault Location in Transmission Lines with Image Processing and Artificial Neural Networks
Feb 22, 2021
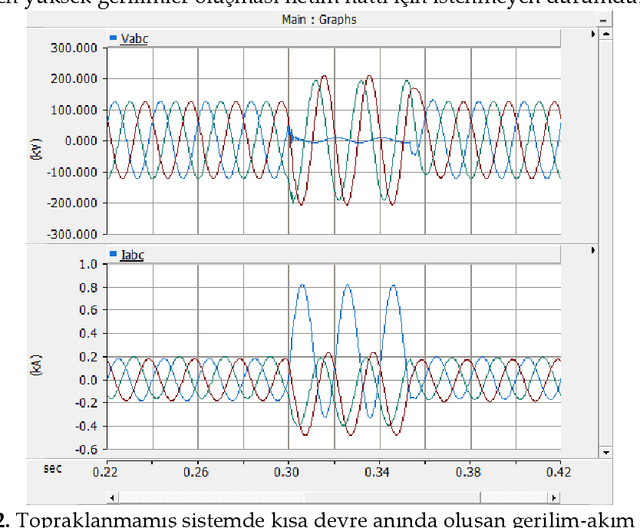
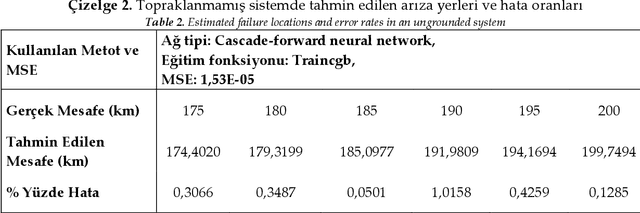
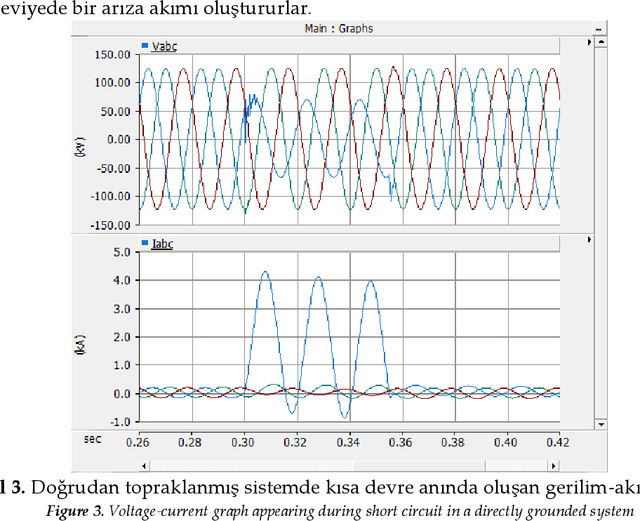
In order to transmit electrical energy in a continuous and quality manner, it is necessary to control it from the point of production to the point of consumption. Therefore, protection of transmission and distribution lines is essential at every stage from production to consumption. The main function of the protection relays in electrical installations should be deactivated as soon as possible in the event of short circuits in the system. The most important part of the system is energy transmission lines and distance protection relays that protect these lines. An accurate error location technique is required to make fast and efficient work. Transformer neutral point grounding in transmission lines affects the operation of the zero component current during the single phase to ground short circuit failure of a power system. Considering the relationship between the grounding system and protection systems, an appropriate grounding choice should be made. Artificial neural network (ANN) has been used in order to accurately locate short circuit faults in different grounding systems in transmission lines. Compared with support vector machines (SVM) for testing inside ANN The transmission line model is made in the PSCAD-EMTDC simulation program. Data sets were created by recording the image of the impedance change of the R-X impedance diagram of the distance protection relay in short circuit faults created in different grounding systems. The related focal points in the images are given as an introduction to different ANN models using feature extraction and image processing techniques and the ANN model with the highest fault location estimation accuracy was chosen.
* in Turkish language
Out of distribution detection for skin and malaria images
Nov 02, 2021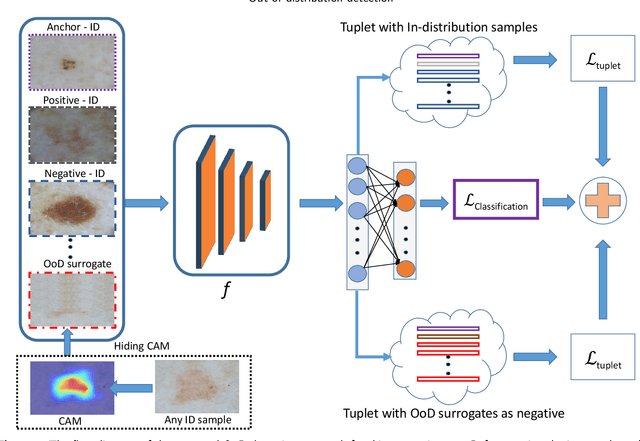
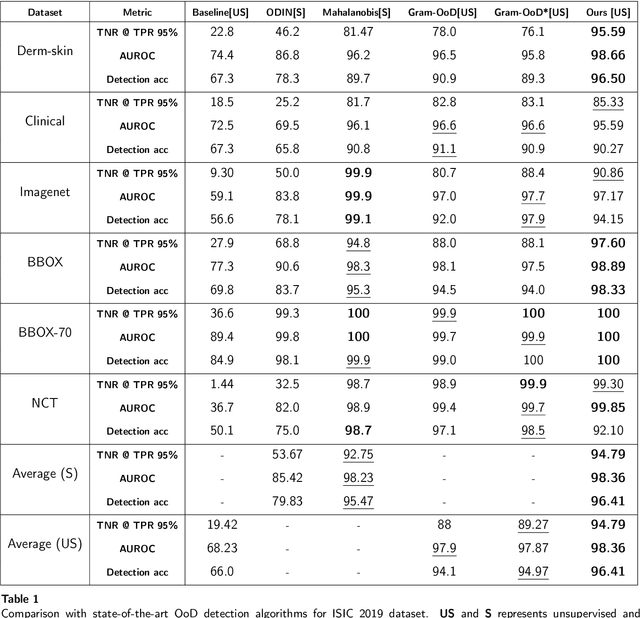
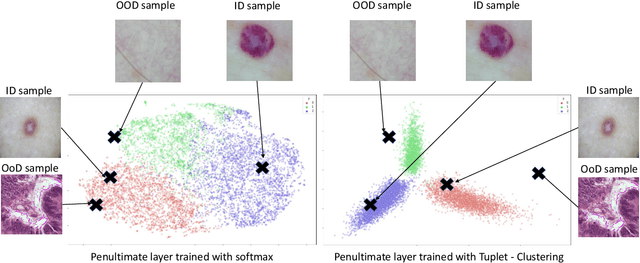
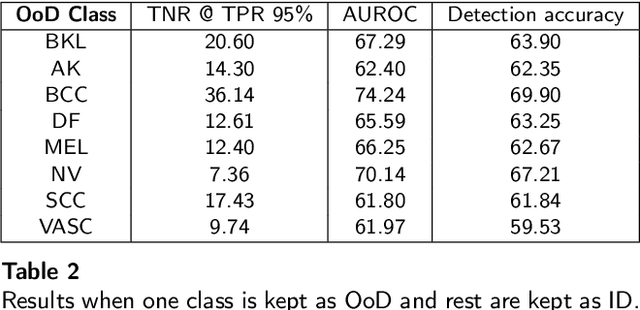
Deep neural networks have shown promising results in disease detection and classification using medical image data. However, they still suffer from the challenges of handling real-world scenarios especially reliably detecting out-of-distribution (OoD) samples. We propose an approach to robustly classify OoD samples in skin and malaria images without the need to access labeled OoD samples during training. Specifically, we use metric learning along with logistic regression to force the deep networks to learn much rich class representative features. To guide the learning process against the OoD examples, we generate ID similar-looking examples by either removing class-specific salient regions in the image or permuting image parts and distancing them away from in-distribution samples. During inference time, the K-reciprocal nearest neighbor is employed to detect out-of-distribution samples. For skin cancer OoD detection, we employ two standard benchmark skin cancer ISIC datasets as ID, and six different datasets with varying difficulty levels were taken as out of distribution. For malaria OoD detection, we use the BBBC041 malaria dataset as ID and five different challenging datasets as out of distribution. We achieved state-of-the-art results, improving 5% and 4% in TNR@TPR95% over the previous state-of-the-art for skin cancer and malaria OoD detection respectively.
Designing Counterfactual Generators using Deep Model Inversion
Oct 05, 2021
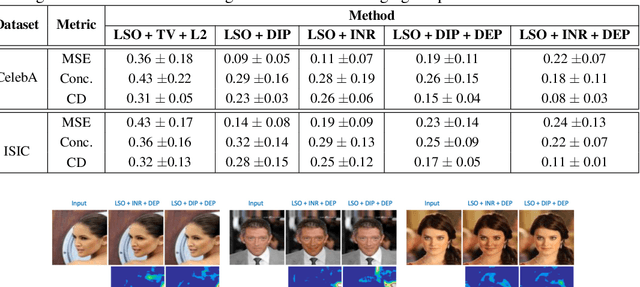
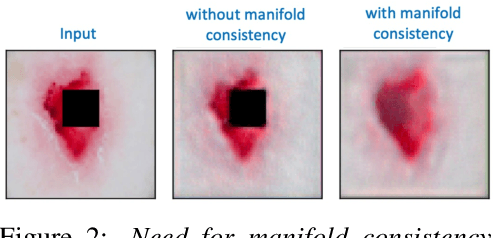

Explanation techniques that synthesize small, interpretable changes to a given image while producing desired changes in the model prediction have become popular for introspecting black-box models. Commonly referred to as counterfactuals, the synthesized explanations are required to contain discernible changes (for easy interpretability) while also being realistic (consistency to the data manifold). In this paper, we focus on the case where we have access only to the trained deep classifier and not the actual training data. While the problem of inverting deep models to synthesize images from the training distribution has been explored, our goal is to develop a deep inversion approach to generate counterfactual explanations for a given query image. Despite their effectiveness in conditional image synthesis, we show that existing deep inversion methods are insufficient for producing meaningful counterfactuals. We propose DISC (Deep Inversion for Synthesizing Counterfactuals) that improves upon deep inversion by utilizing (a) stronger image priors, (b) incorporating a novel manifold consistency objective and (c) adopting a progressive optimization strategy. We find that, in addition to producing visually meaningful explanations, the counterfactuals from DISC are effective at learning classifier decision boundaries and are robust to unknown test-time corruptions.
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
Dec 01, 2021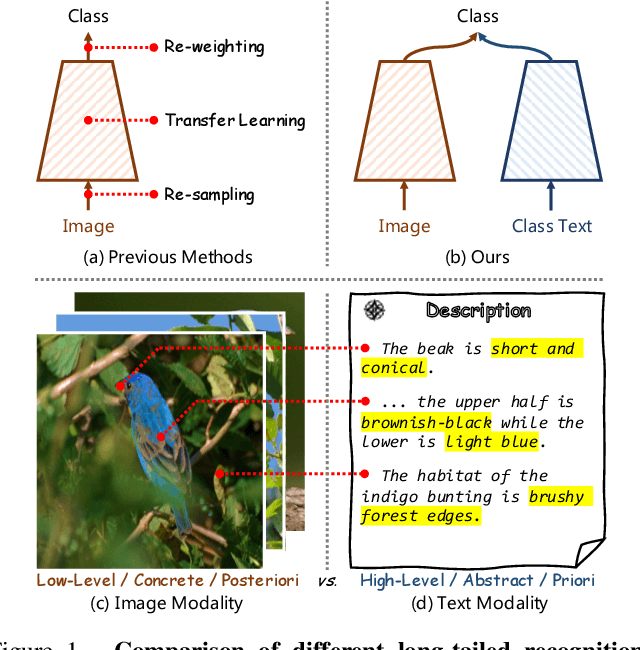
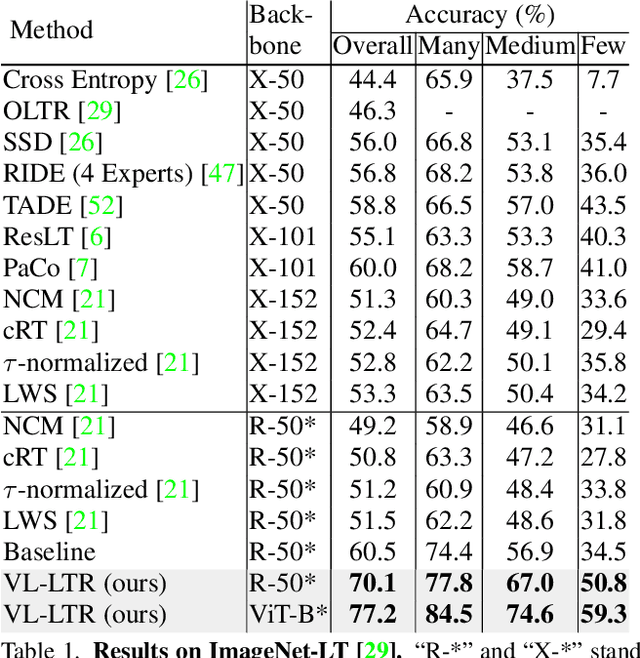
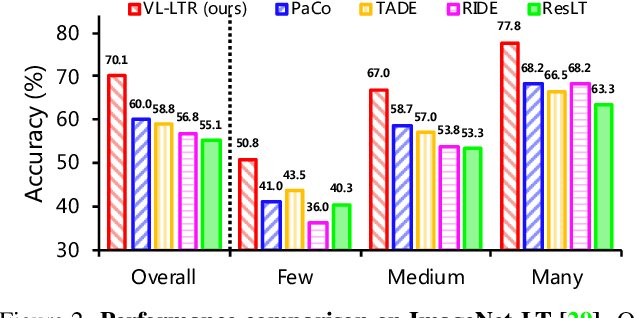
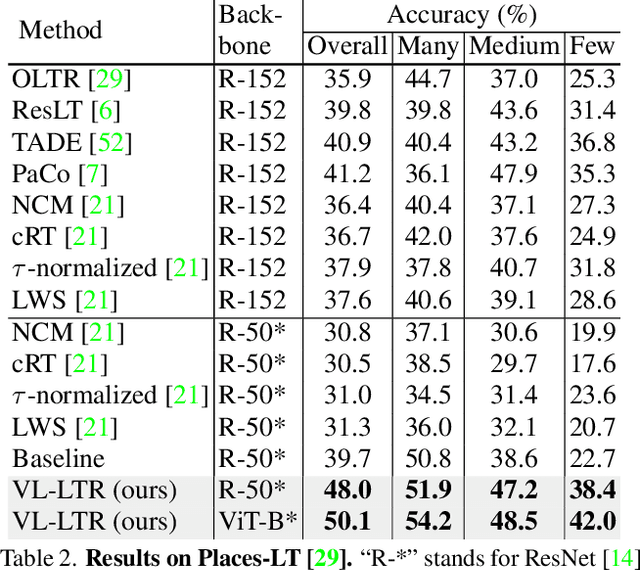
Deep learning-based models encounter challenges when processing long-tailed data in the real world. Existing solutions usually employ some balancing strategies or transfer learning to deal with the class imbalance problem, based on the image modality. In this work, we present a visual-linguistic long-tailed recognition framework, termed VL-LTR, and conduct empirical studies on the benefits of introducing text modality for long-tailed recognition (LTR). Compared to existing approaches, the proposed VL-LTR has the following merits. (1) Our method can not only learn visual representation from images but also learn corresponding linguistic representation from noisy class-level text descriptions collected from the Internet; (2) Our method can effectively use the learned visual-linguistic representation to improve the visual recognition performance, especially for classes with fewer image samples. We also conduct extensive experiments and set the new state-of-the-art performance on widely-used LTR benchmarks. Notably, our method achieves 77.2% overall accuracy on ImageNet-LT, which significantly outperforms the previous best method by over 17 points, and is close to the prevailing performance training on the full ImageNet. Code shall be released.
R-MNet: A Perceptual Adversarial Network for Image Inpainting
Aug 11, 2020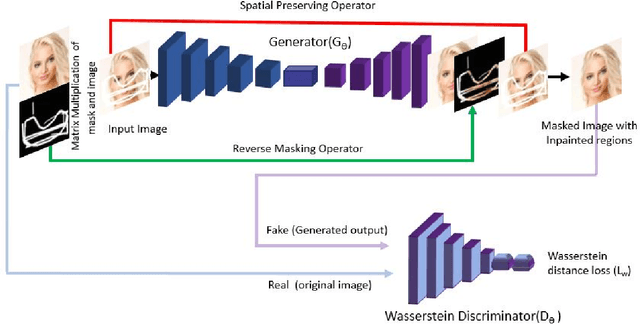
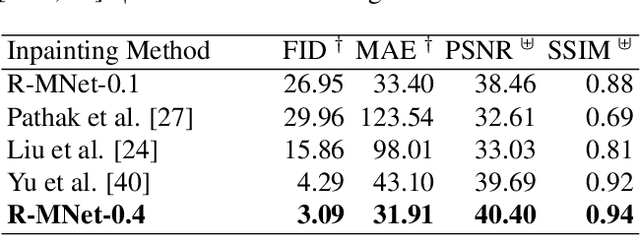
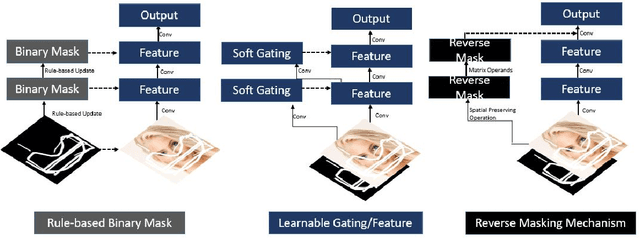

Facial image inpainting is a problem that is widely studied, and in recent years the introduction of Generative Adversarial Networks, has led to improvements in the field. Unfortunately some issues persists, in particular when blending the missing pixels with the visible ones. We address the problem by proposing a Wasserstein GAN combined with a new reverse mask operator, namely Reverse Masking Network (R-MNet), a perceptual adversarial network for image inpainting. The reverse mask operator transfers the reverse masked image to the end of the encoder-decoder network leaving only valid pixels to be inpainted. Additionally, we propose a new loss function computed in feature space to target only valid pixels combined with adversarial training. These then capture data distributions and generate images similar to those in the training data with achieved realism (realistic and coherent) on the output images. We evaluate our method on publicly available dataset, and compare with state-of-the-art methods. We show that our method is able to generalize to high-resolution inpainting task, and further show more realistic outputs that are plausible to the human visual system when compared with the state-of-the-art methods.
KiU-Net: Overcomplete Convolutional Architectures for Biomedical Image and Volumetric Segmentation
Oct 04, 2020
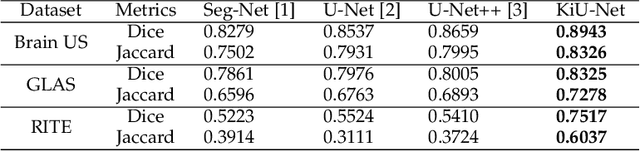


Most methods for medical image segmentation use U-Net or its variants as they have been successful in most of the applications. After a detailed analysis of these "traditional" encoder-decoder based approaches, we observed that they perform poorly in detecting smaller structures and are unable to segment boundary regions precisely. This issue can be attributed to the increase in receptive field size as we go deeper into the encoder. The extra focus on learning high level features causes the U-Net based approaches to learn less information about low-level features which are crucial for detecting small structures. To overcome this issue, we propose using an overcomplete convolutional architecture where we project our input image into a higher dimension such that we constrain the receptive field from increasing in the deep layers of the network. We design a new architecture for image segmentation- KiU-Net which has two branches: (1) an overcomplete convolutional network Kite-Net which learns to capture fine details and accurate edges of the input, and (2) U-Net which learns high level features. Furthermore, we also propose KiU-Net 3D which is a 3D convolutional architecture for volumetric segmentation. We perform a detailed study of KiU-Net by performing experiments on five different datasets covering various image modalities like ultrasound (US), magnetic resonance imaging (MRI), computed tomography (CT), microscopic and fundus images. The proposed method achieves a better performance as compared to all the recent methods with an additional benefit of fewer parameters and faster convergence. Additionally, we also demonstrate that the extensions of KiU-Net based on residual blocks and dense blocks result in further performance improvements. The implementation of KiU-Net can be found here: https://github.com/jeya-maria-jose/KiU-Net-pytorch
XGPT: Cross-modal Generative Pre-Training for Image Captioning
Mar 04, 2020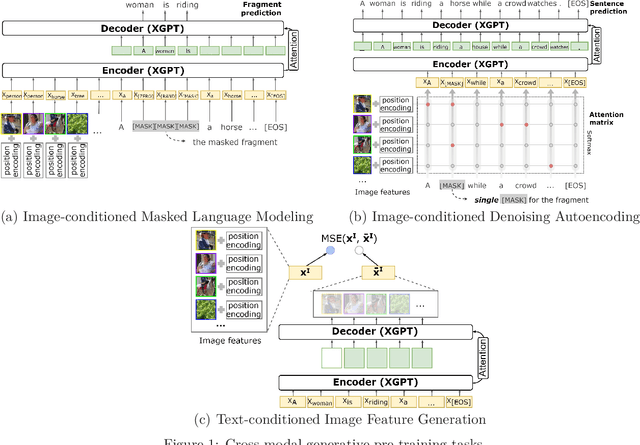
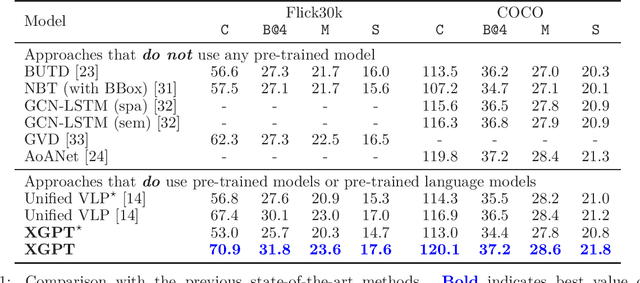
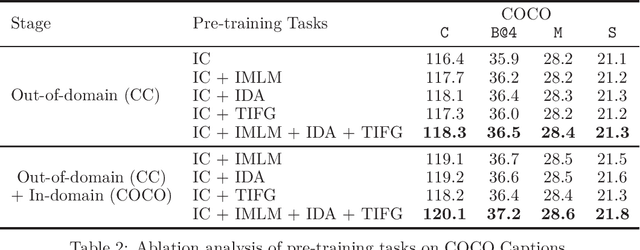
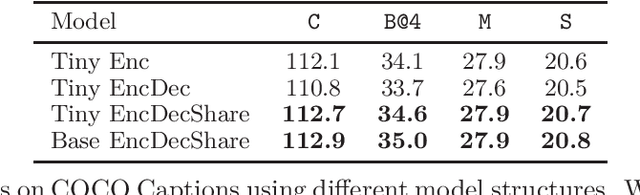
While many BERT-based cross-modal pre-trained models produce excellent results on downstream understanding tasks like image-text retrieval and VQA, they cannot be applied to generation tasks directly. In this paper, we propose XGPT, a new method of Cross-modal Generative Pre-Training for Image Captioning that is designed to pre-train text-to-image caption generators through three novel generation tasks, including Image-conditioned Masked Language Modeling (IMLM), Image-conditioned Denoising Autoencoding (IDA), and Text-conditioned Image Feature Generation (TIFG). As a result, the pre-trained XGPT can be fine-tuned without any task-specific architecture modifications to create state-of-the-art models for image captioning. Experiments show that XGPT obtains new state-of-the-art results on the benchmark datasets, including COCO Captions and Flickr30k Captions. We also use XGPT to generate new image captions as data augmentation for the image retrieval task and achieve significant improvement on all recall metrics.
ESTAN: Enhanced Small Tumor-Aware Network for Breast Ultrasound Image Segmentation
Sep 27, 2020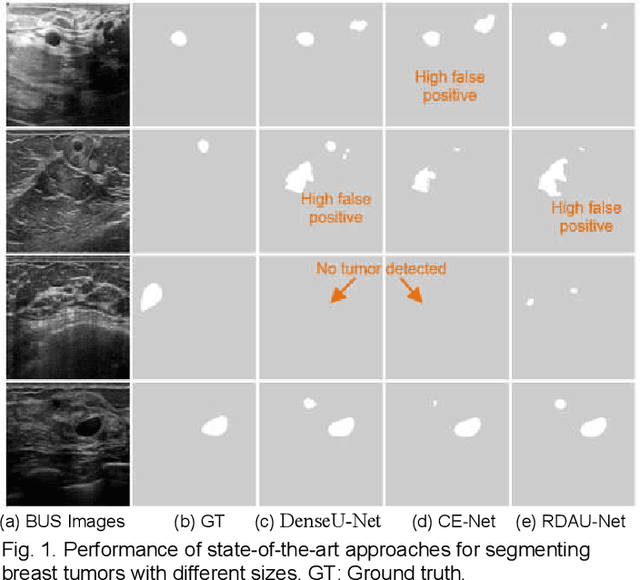
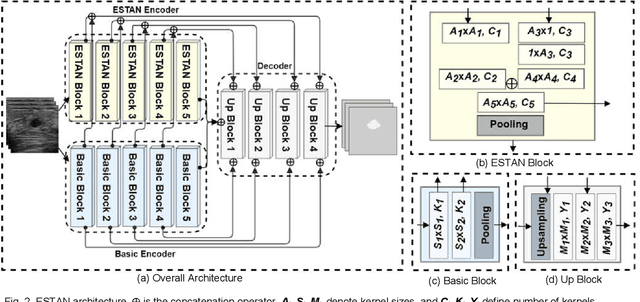
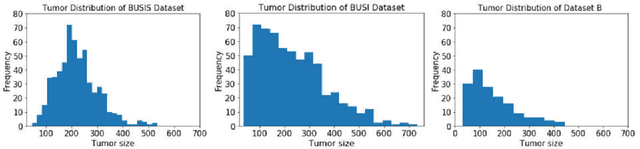
Breast tumor segmentation is a critical task in computer-aided diagnosis (CAD) systems for breast cancer detection because accurate tumor size, shape and location are important for further tumor quantification and classification. However, segmenting small tumors in ultrasound images is challenging, due to the speckle noise, varying tumor shapes and sizes among patients, and the existence of tumor-like image regions. Recently, deep learning-based approaches have achieved great success for biomedical image analysis, but current state-of-the-art approaches achieve poor performance for segmenting small breast tumors. In this paper, we propose a novel deep neural network architecture, namely Enhanced Small Tumor-Aware Network (ESTAN), to accurately and robustly segment breast tumors. ESTAN introduces two encoders to extract and fuse image context information at different scales and utilizes row-column-wise kernels in the encoder to adapt to breast anatomy. We validate the proposed approach and compare it to nine state-of-the-art approaches on three public breast ultrasound datasets using seven quantitative metrics. The results demonstrate that the proposed approach achieves the best overall performance and outperforms all other approaches on small tumor segmentation.