 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
2nd Place Solution for VisDA 2021 Challenge -- Universally Domain Adaptive Image Recognition
Oct 27, 2021
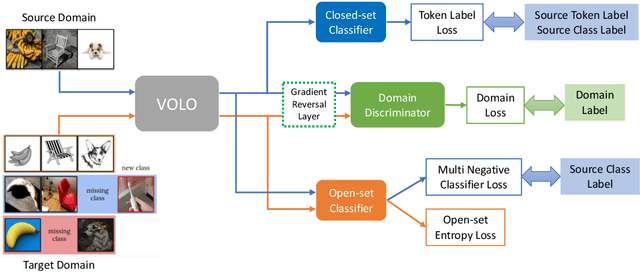
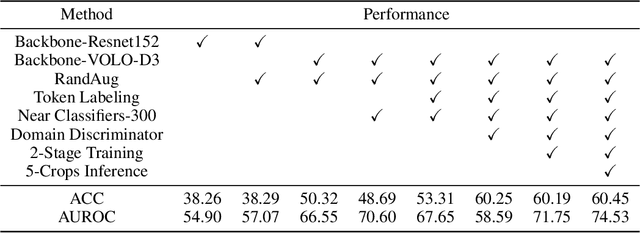
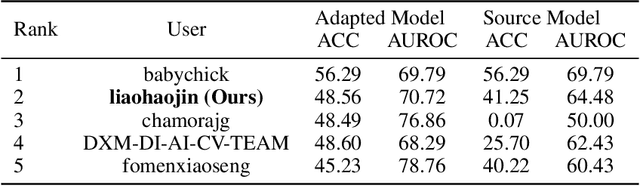
The Visual Domain Adaptation (VisDA) 2021 Challenge calls for unsupervised domain adaptation (UDA) methods that can deal with both input distribution shift and label set variance between the source and target domains. In this report, we introduce a universal domain adaptation (UniDA) method by aggregating several popular feature extraction and domain adaptation schemes. First, we utilize VOLO, a Transformer-based architecture with state-of-the-art performance in several visual tasks, as the backbone to extract effective feature representations. Second, we modify the open-set classifier of OVANet to recognize the unknown class with competitive accuracy and robustness. As shown in the leaderboard, our proposed UniDA method ranks the 2nd place with 48.56% ACC and 70.72% AUROC in the VisDA 2021 Challenge.
Ex-DoF: Expansion of Action Degree-of-Freedom with Virtual Camera Rotation for Omnidirectional Image
Nov 24, 2021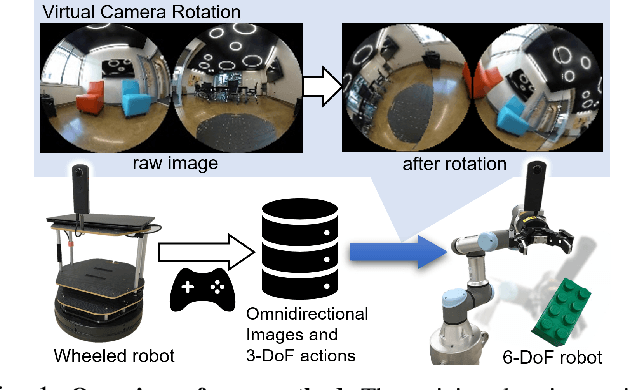
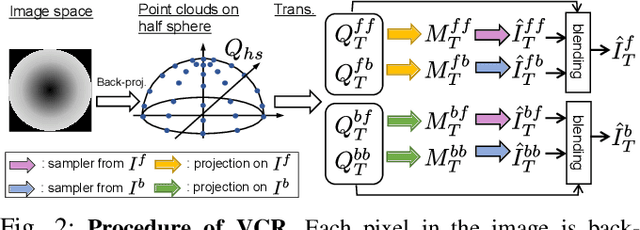
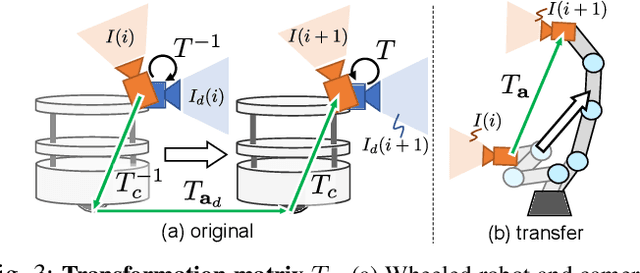
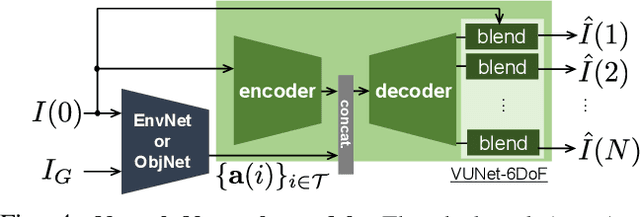
Inter-robot transfer of training data is a little explored topic in learning and vision-based robot control. Thus, we propose a transfer method from a robot with a lower Degree-of-Freedom (DoF) action to one with a higher DoF utilizing an omnidirectional camera. The virtual rotation of the robot camera enables data augmentation in this transfer learning process. In this study, a vision-based control policy for a 6-DoF robot was trained using a dataset collected by a differential wheeled ground robot with only three DoFs. Towards application of robotic manipulations, we also demonstrate a control system of a 6-DoF arm robot using multiple policies with different fields of view to enable object reaching tasks.
Integrating Visuospatial, Linguistic and Commonsense Structure into Story Visualization
Oct 21, 2021

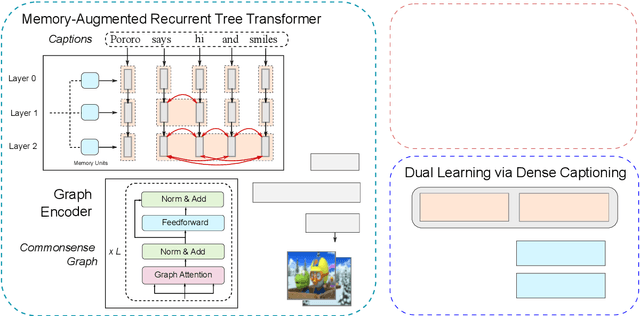
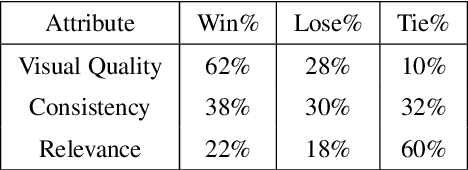
While much research has been done in text-to-image synthesis, little work has been done to explore the usage of linguistic structure of the input text. Such information is even more important for story visualization since its inputs have an explicit narrative structure that needs to be translated into an image sequence (or visual story). Prior work in this domain has shown that there is ample room for improvement in the generated image sequence in terms of visual quality, consistency and relevance. In this paper, we first explore the use of constituency parse trees using a Transformer-based recurrent architecture for encoding structured input. Second, we augment the structured input with commonsense information and study the impact of this external knowledge on the generation of visual story. Third, we also incorporate visual structure via bounding boxes and dense captioning to provide feedback about the characters/objects in generated images within a dual learning setup. We show that off-the-shelf dense-captioning models trained on Visual Genome can improve the spatial structure of images from a different target domain without needing fine-tuning. We train the model end-to-end using intra-story contrastive loss (between words and image sub-regions) and show significant improvements in several metrics (and human evaluation) for multiple datasets. Finally, we provide an analysis of the linguistic and visuo-spatial information. Code and data: https://github.com/adymaharana/VLCStoryGan.
DenseGAP: Graph-Structured Dense Correspondence Learning with Anchor Points
Dec 13, 2021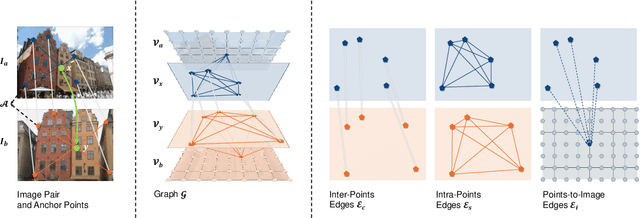
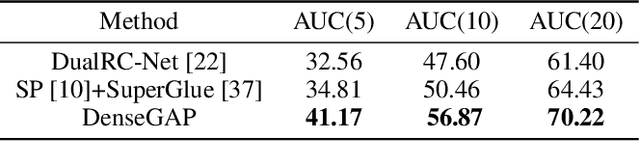

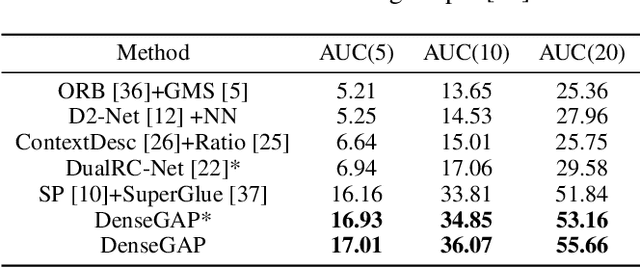
Establishing dense correspondence between two images is a fundamental computer vision problem, which is typically tackled by matching local feature descriptors. However, without global awareness, such local features are often insufficient for disambiguating similar regions. And computing the pairwise feature correlation across images is both computation-expensive and memory-intensive. To make the local features aware of the global context and improve their matching accuracy, we introduce DenseGAP, a new solution for efficient Dense correspondence learning with a Graph-structured neural network conditioned on Anchor Points. Specifically, we first propose a graph structure that utilizes anchor points to provide sparse but reliable prior on inter- and intra-image context and propagates them to all image points via directed edges. We also design a graph-structured network to broadcast multi-level contexts via light-weighted message-passing layers and generate high-resolution feature maps at low memory cost. Finally, based on the predicted feature maps, we introduce a coarse-to-fine framework for accurate correspondence prediction using cycle consistency. Our feature descriptors capture both local and global information, thus enabling a continuous feature field for querying arbitrary points at high resolution. Through comprehensive ablative experiments and evaluations on large-scale indoor and outdoor datasets, we demonstrate that our method advances the state-of-the-art of correspondence learning on most benchmarks.
Locally Weighted Mean Phase Angle (LWMPA) Based Tone Mapping Quality Index (TMQI-3)
Sep 17, 2021



High Dynamic Range (HDR) images are the ones that contain a greater range of luminosity as compared to the standard images. HDR images have a higher detail and clarity of structure, objects, and color, which the standard images lack. HDR images are useful in capturing scenes that pose high brightness, darker areas, and shadows, etc. An HDR image comprises multiple narrow-range-exposure images combined into one high-quality image. As these HDR images cannot be displayed on standard display devices, the real challenge comes while converting these HDR images to Low dynamic range (LDR) images. The conversion of HDR image to LDR image is performed using Tone-mapped operators (TMOs). This conversion results in the loss of much valuable information in structure, color, naturalness, and exposures. The loss of information in the LDR image may not directly be visible to the human eye. To calculate how good an LDR image is after conversion, various metrics have been proposed previously. Some are not noise resilient, some work on separate color channels (Red, Green, and Blue one by one), and some lack capacity to identify the structure. To deal with this problem, we propose a metric in this paper called the Tone Mapping Quality Index (TMQI-3), which evaluates the quality of the LDR image based on its objective score. TMQI-3 is noise resilient, takes account of structure and naturalness, and works on all three color channels combined into one luminosity component. This eliminates the need to use multiple metrics at the same time. We compute results for several HDR and LDR images from the literature and show that our quality index metric performs better than the baseline models.
Extracting Deformation-Aware Local Features by Learning to Deform
Nov 20, 2021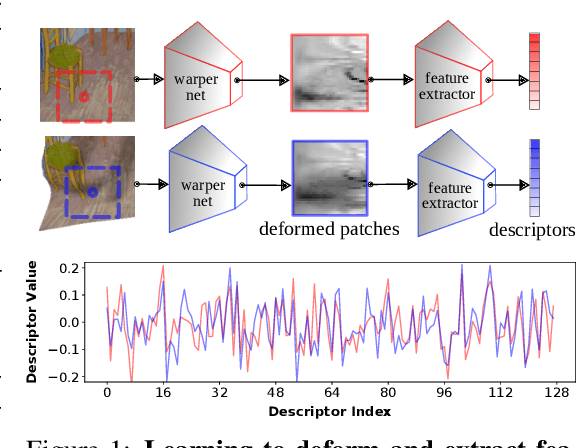
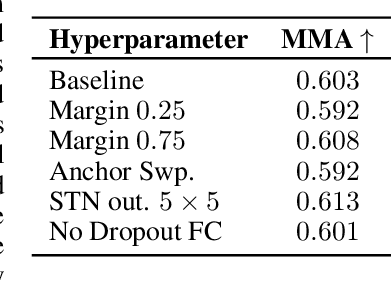

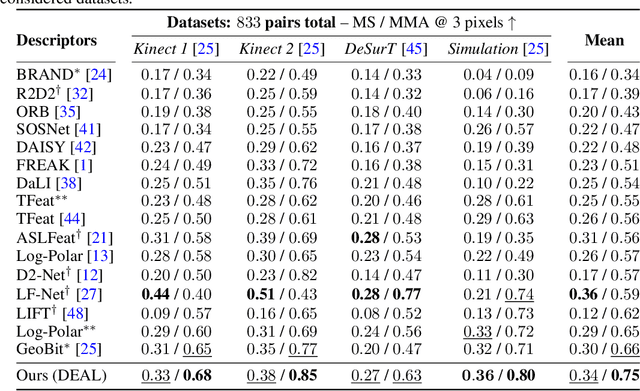
Despite the advances in extracting local features achieved by handcrafted and learning-based descriptors, they are still limited by the lack of invariance to non-rigid transformations. In this paper, we present a new approach to compute features from still images that are robust to non-rigid deformations to circumvent the problem of matching deformable surfaces and objects. Our deformation-aware local descriptor, named DEAL, leverages a polar sampling and a spatial transformer warping to provide invariance to rotation, scale, and image deformations. We train the model architecture end-to-end by applying isometric non-rigid deformations to objects in a simulated environment as guidance to provide highly discriminative local features. The experiments show that our method outperforms state-of-the-art handcrafted, learning-based image, and RGB-D descriptors in different datasets with both real and realistic synthetic deformable objects in still images. The source code and trained model of the descriptor are publicly available at https://www.verlab.dcc.ufmg.br/descriptors/neurips2021.
Learning Disentangled Feature Representation for Hybrid-distorted Image Restoration
Jul 22, 2020
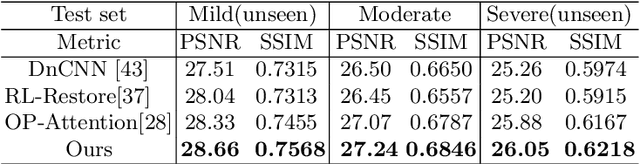
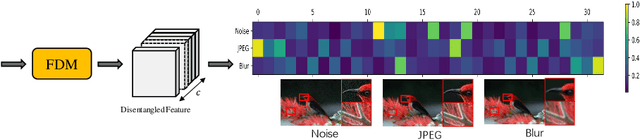

Hybrid-distorted image restoration (HD-IR) is dedicated to restore real distorted image that is degraded by multiple distortions. Existing HD-IR approaches usually ignore the inherent interference among hybrid distortions which compromises the restoration performance. To decompose such interference, we introduce the concept of Disentangled Feature Learning to achieve the feature-level divide-and-conquer of hybrid distortions. Specifically, we propose the feature disentanglement module (FDM) to distribute feature representations of different distortions into different channels by revising gain-control-based normalization. We also propose a feature aggregation module (FAM) with channel-wise attention to adaptively filter out the distortion representations and aggregate useful content information from different channels for the construction of raw image. The effectiveness of the proposed scheme is verified by visualizing the correlation matrix of features and channel responses of different distortions. Extensive experimental results also prove superior performance of our approach compared with the latest HD-IR schemes.
Evolutionary Image Transition and Painting Using Random Walks
Mar 02, 2020We present a study demonstrating how random walk algorithms can be used for evolutionary image transition. We design different mutation operators based on uniform and biased random walks and study how their combination with a baseline mutation operator can lead to interesting image transition processes in terms of visual effects and artistic features. Using feature-based analysis we investigate the evolutionary image transition behaviour with respect to different features and evaluate the images constructed during the image transition process. Afterwards, we investigate how modifications of our biased random walk approaches can be used for evolutionary image painting. We introduce an evolutionary image painting approach whose underlying biased random walk can be controlled by a parameter influencing the bias of the random walk and thereby creating different artistic painting effects.
Open-Set Recognition of Breast Cancer Treatments
Jan 09, 2022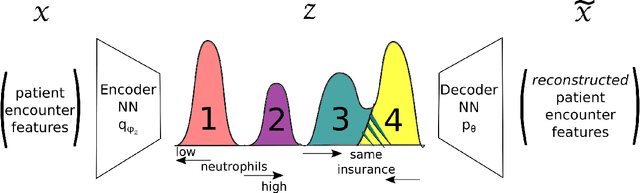

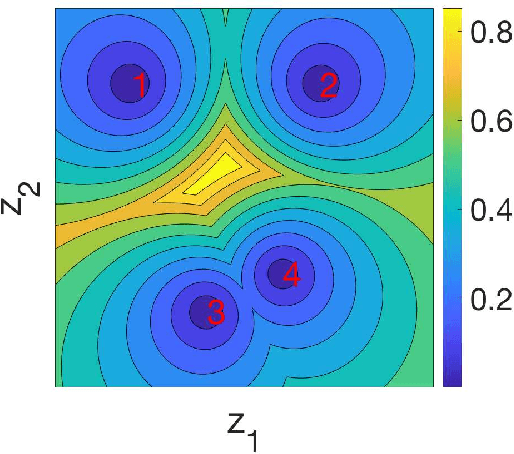
Open-set recognition generalizes a classification task by classifying test samples as one of the known classes from training or "unknown." As novel cancer drug cocktails with improved treatment are continually discovered, predicting cancer treatments can naturally be formulated in terms of an open-set recognition problem. Drawbacks, due to modeling unknown samples during training, arise from straightforward implementations of prior work in healthcare open-set learning. Accordingly, we reframe the problem methodology and apply a recent existing Gaussian mixture variational autoencoder model, which achieves state-of-the-art results for image datasets, to breast cancer patient data. Not only do we obtain more accurate and robust classification results, with a 24.5% average F1 increase compared to a recent method, but we also reexamine open-set recognition in terms of deployability to a clinical setting.
Unimodal Face Classification with Multimodal Training
Dec 08, 2021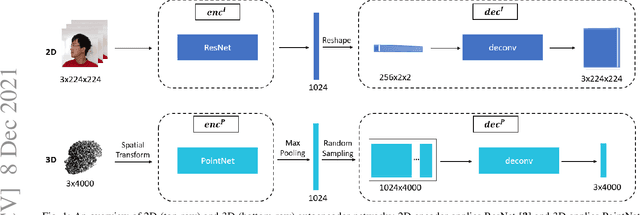
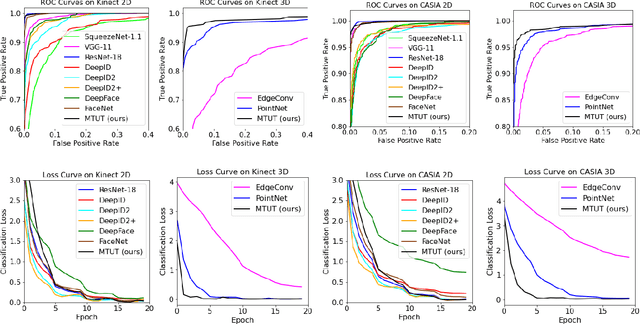
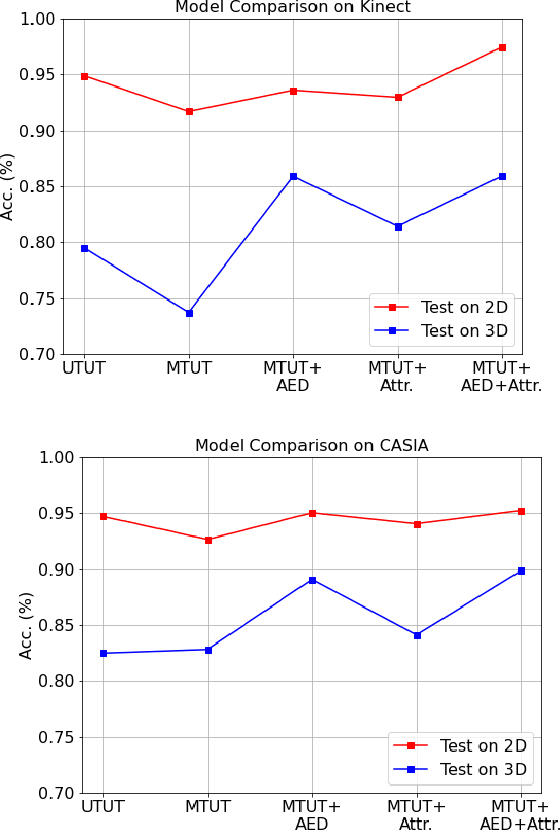
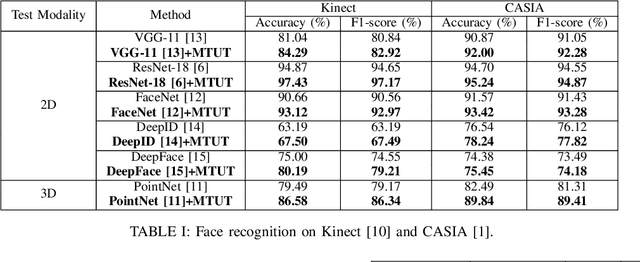
Face recognition is a crucial task in various multimedia applications such as security check, credential access and motion sensing games. However, the task is challenging when an input face is noisy (e.g. poor-condition RGB image) or lacks certain information (e.g. 3D face without color). In this work, we propose a Multimodal Training Unimodal Test (MTUT) framework for robust face classification, which exploits the cross-modality relationship during training and applies it as a complementary of the imperfect single modality input during testing. Technically, during training, the framework (1) builds both intra-modality and cross-modality autoencoders with the aid of facial attributes to learn latent embeddings as multimodal descriptors, (2) proposes a novel multimodal embedding divergence loss to align the heterogeneous features from different modalities, which also adaptively avoids the useless modality (if any) from confusing the model. This way, the learned autoencoders can generate robust embeddings in single-modality face classification on test stage. We evaluate our framework in two face classification datasets and two kinds of testing input: (1) poor-condition image and (2) point cloud or 3D face mesh, when both 2D and 3D modalities are available for training. We experimentally show that our MTUT framework consistently outperforms ten baselines on 2D and 3D settings of both datasets.