 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022
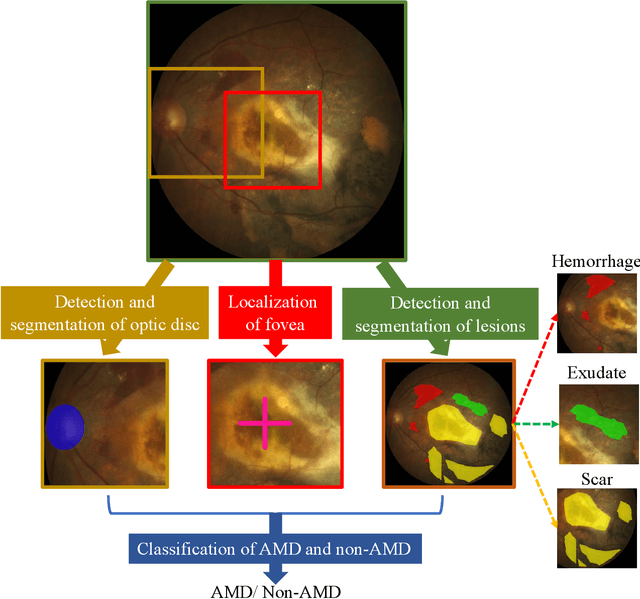

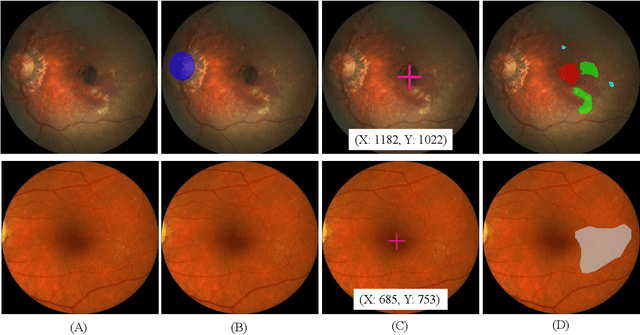
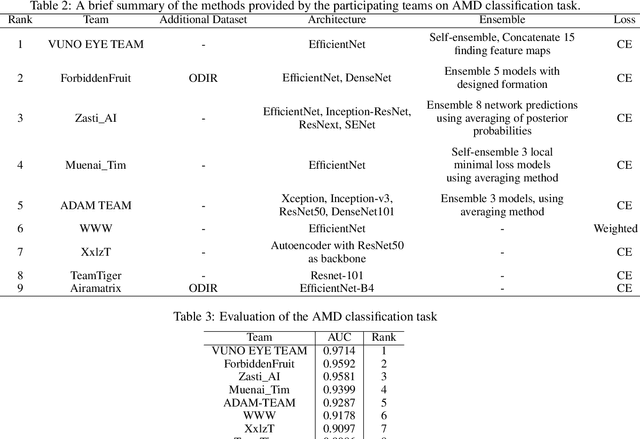
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
May 15, 2021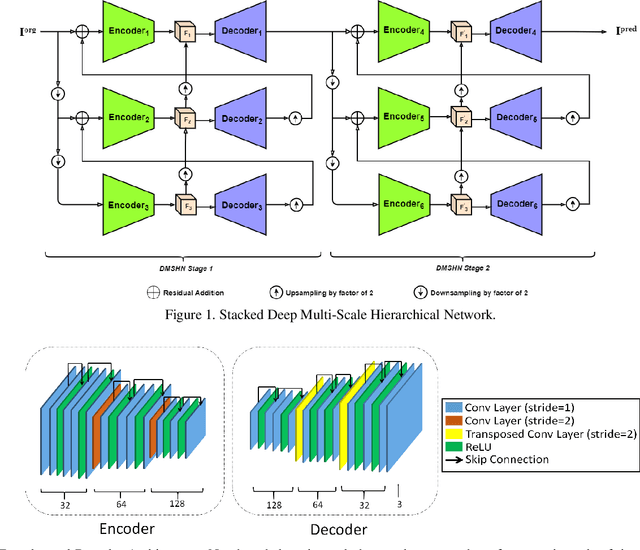
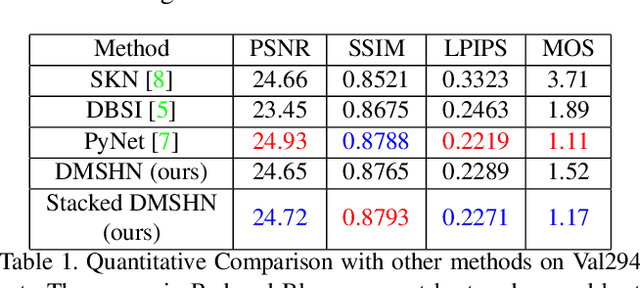
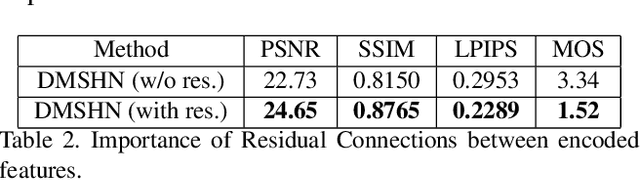

The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.
Image to Bengali Caption Generation Using Deep CNN and Bidirectional Gated Recurrent Unit
Dec 22, 2020
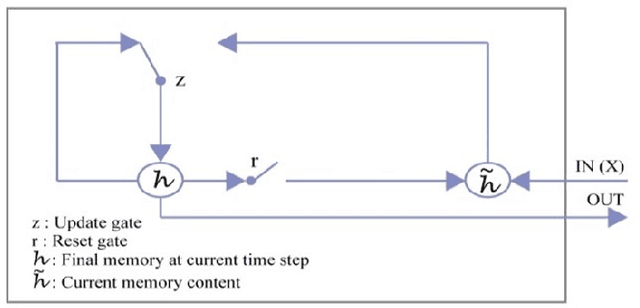

There is very little notable research on generating descriptions of the Bengali language. About 243 million people speak in Bengali, and it is the 7th most spoken language on the planet. The purpose of this research is to propose a CNN and Bidirectional GRU based architecture model that generates natural language captions in the Bengali language from an image. Bengali people can use this research to break the language barrier and better understand each other's perspectives. It will also help many blind people with their everyday lives. This paper used an encoder-decoder approach to generate captions. We used a pre-trained Deep convolutional neural network (DCNN) called InceptonV3image embedding model as the encoder for analysis, classification, and annotation of the dataset's images Bidirectional Gated Recurrent unit (BGRU) layer as the decoder to generate captions. Argmax and Beam search is used to produce the highest possible quality of the captions. A new dataset called BNATURE is used, which comprises 8000 images with five captions per image. It is used for training and testing the proposed model. We obtained BLEU-1, BLEU-2, BLEU-3, BLEU-4 and Meteor is 42.6, 27.95, 23, 66, 16.41, 28.7 respectively.
ODMTCNet: An Interpretable Multi-view Deep Neural Network Architecture for Image Feature Representation
Oct 28, 2021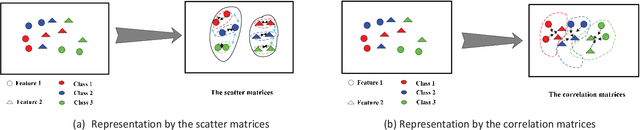
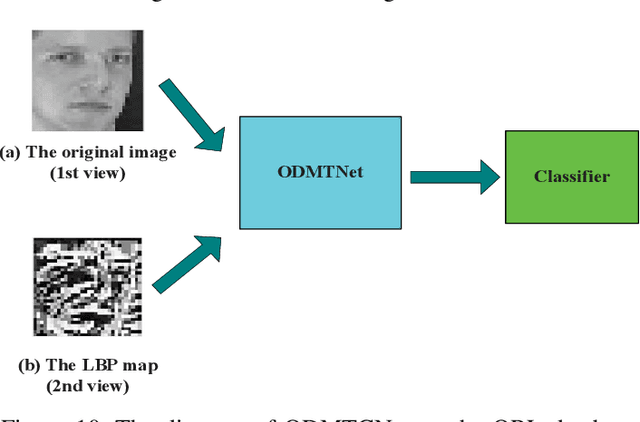

This work proposes an interpretable multi-view deep neural network architecture, namely optimal discriminant multi-view tensor convolutional network (ODMTCNet), by integrating statistical machine learning (SML) principles with the deep neural network (DNN) architecture.
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021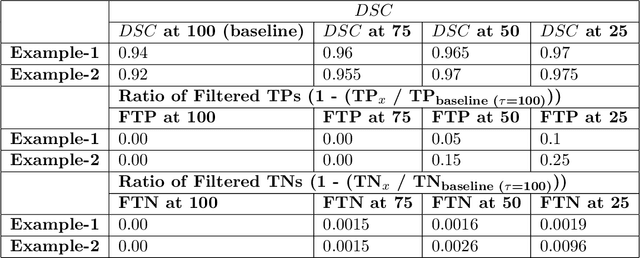
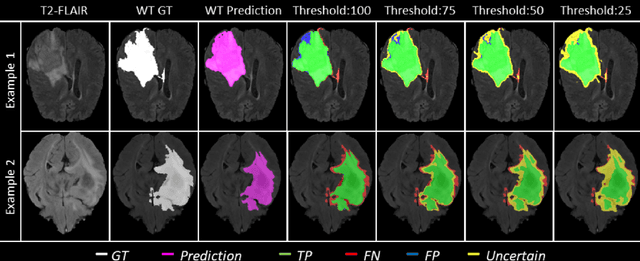
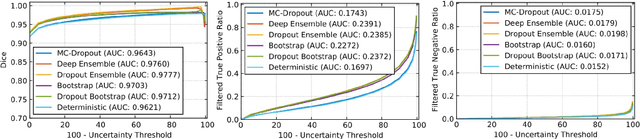
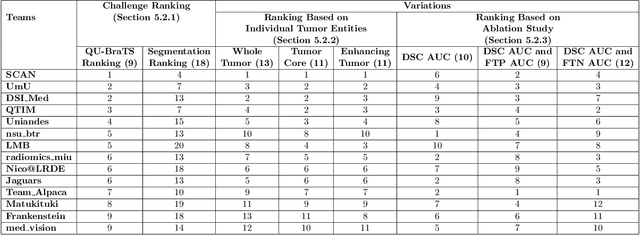
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Semantics-Aware Image to Image Translation and Domain Transfer
Apr 03, 2019
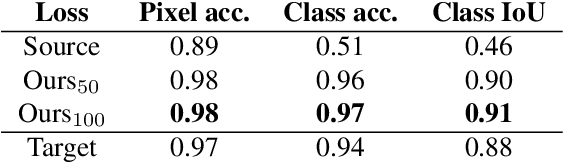
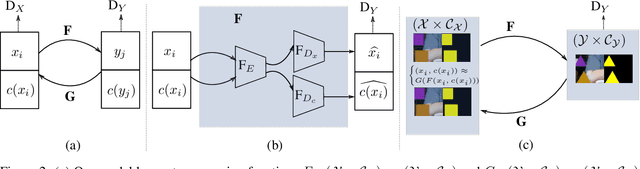
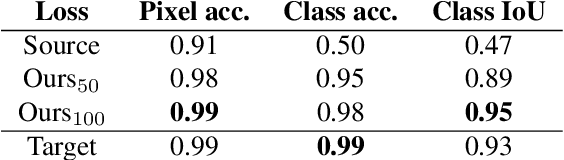
Image to image translation is the problem of transferring an image from a source domain to a target domain. We present a new method to transfer the underlying semantics of an image even when there are geometric changes across the two domains. Specifically, we present a Generative Adversarial Network (GAN) that can transfer semantic information presented as segmentation masks. Our main technical contribution is an encoder-decoder based generator architecture that jointly encodes the image and its underlying semantics and translates both simultaneously to the target domain. Additionally, we propose object transfiguration and cross-domain semantic consistency losses that preserve the underlying semantic labels maps. We demonstrate the effectiveness of our approach in multiple object transfiguration and domain transfer tasks through qualitative and quantitative experiments. The results show that our method is better at transferring image semantics than state of the art image to image translation methods.
Image Segmentation Using Deep Learning: A Survey
Jan 18, 2020
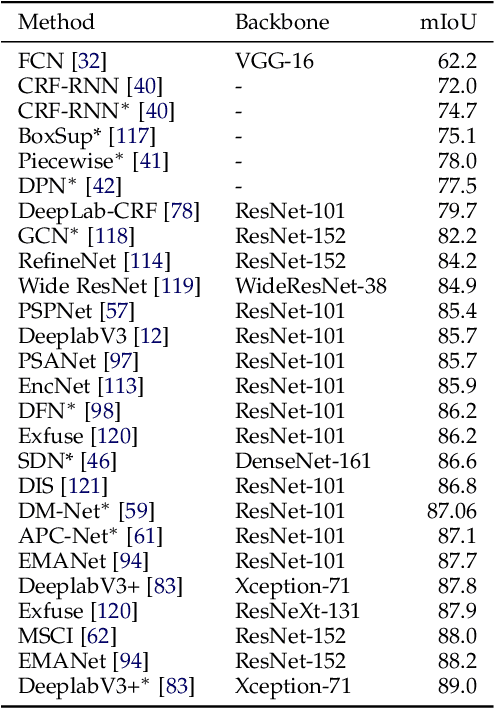
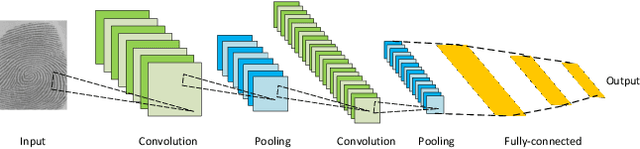
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
Single Image Super-Resolution via a Holistic Attention Network
Aug 20, 2020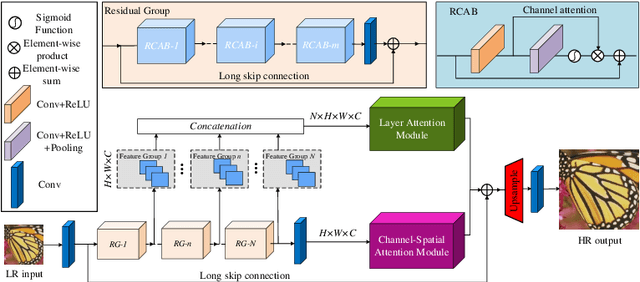

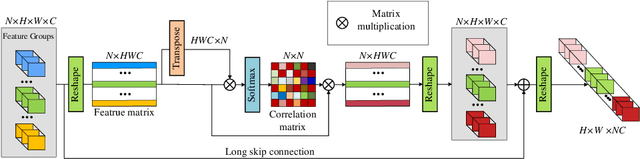

Informative features play a crucial role in the single image super-resolution task. Channel attention has been demonstrated to be effective for preserving information-rich features in each layer. However, channel attention treats each convolution layer as a separate process that misses the correlation among different layers. To address this problem, we propose a new holistic attention network (HAN), which consists of a layer attention module (LAM) and a channel-spatial attention module (CSAM), to model the holistic interdependencies among layers, channels, and positions. Specifically, the proposed LAM adaptively emphasizes hierarchical features by considering correlations among layers. Meanwhile, CSAM learns the confidence at all the positions of each channel to selectively capture more informative features. Extensive experiments demonstrate that the proposed HAN performs favorably against the state-of-the-art single image super-resolution approaches.
Critical configurations for three projective views
Dec 10, 2021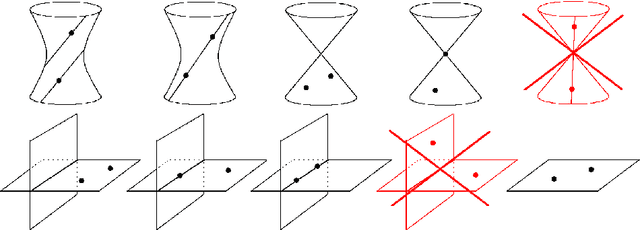
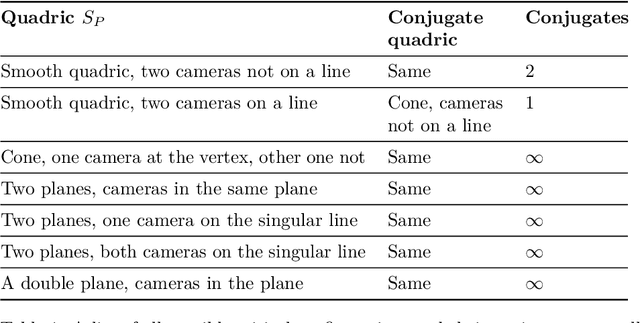
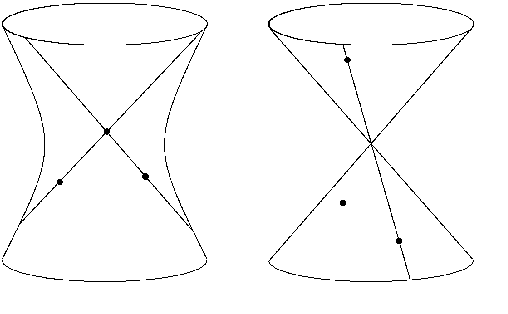
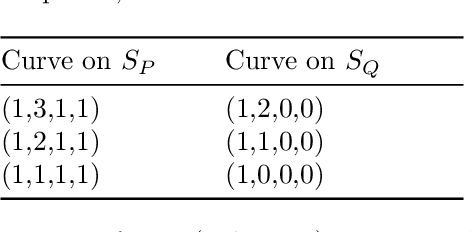
The problem of structure from motion is concerned with recovering the 3-dimensional structure of an object from a set of 2-dimensional images. Generally, all information can be uniquely recovered if enough images and image points are provided, yet there are certain cases where unique recovery is impossible; these are called critical configurations. In this paper we use an algebraic approach to study the critical configurations for three projective cameras. We show that all critical configurations lie on the intersection of quadric surfaces, and classify exactly which intersections constitute a critical configuration.
Drone Object Detection Using RGB/IR Fusion
Jan 11, 2022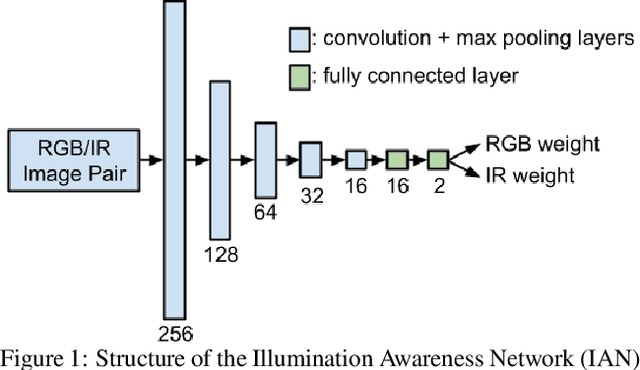
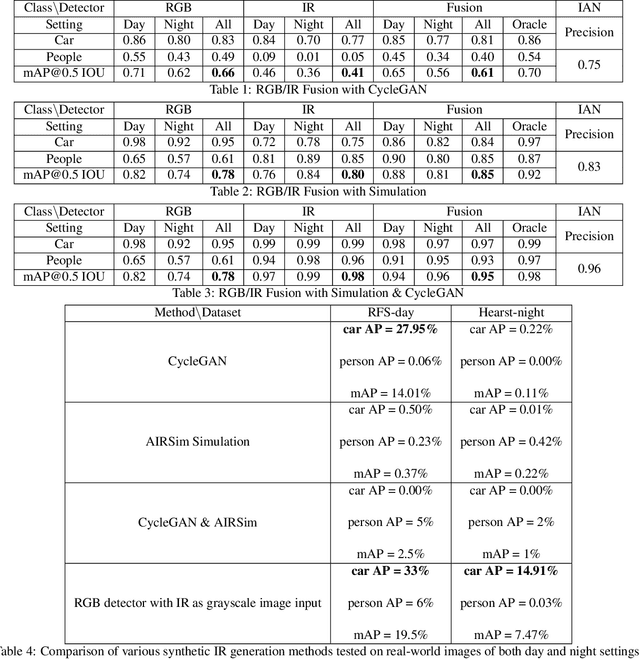
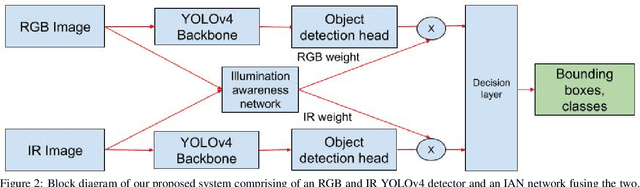

Object detection using aerial drone imagery has received a great deal of attention in recent years. While visible light images are adequate for detecting objects in most scenarios, thermal cameras can extend the capabilities of object detection to night-time or occluded objects. As such, RGB and Infrared (IR) fusion methods for object detection are useful and important. One of the biggest challenges in applying deep learning methods to RGB/IR object detection is the lack of available training data for drone IR imagery, especially at night. In this paper, we develop several strategies for creating synthetic IR images using the AIRSim simulation engine and CycleGAN. Furthermore, we utilize an illumination-aware fusion framework to fuse RGB and IR images for object detection on the ground. We characterize and test our methods for both simulated and actual data. Our solution is implemented on an NVIDIA Jetson Xavier running on an actual drone, requiring about 28 milliseconds of processing per RGB/IR image pair.