 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Webly Supervised Concept Expansion for General Purpose Vision Models
Feb 04, 2022
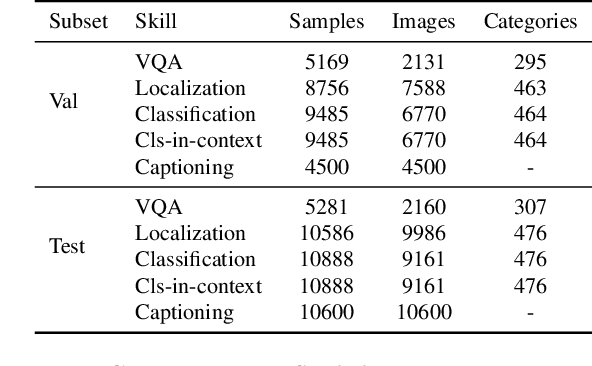
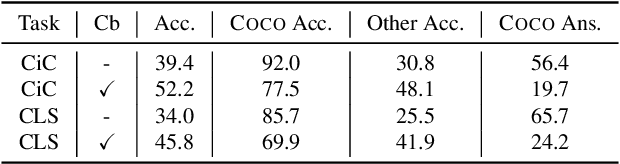
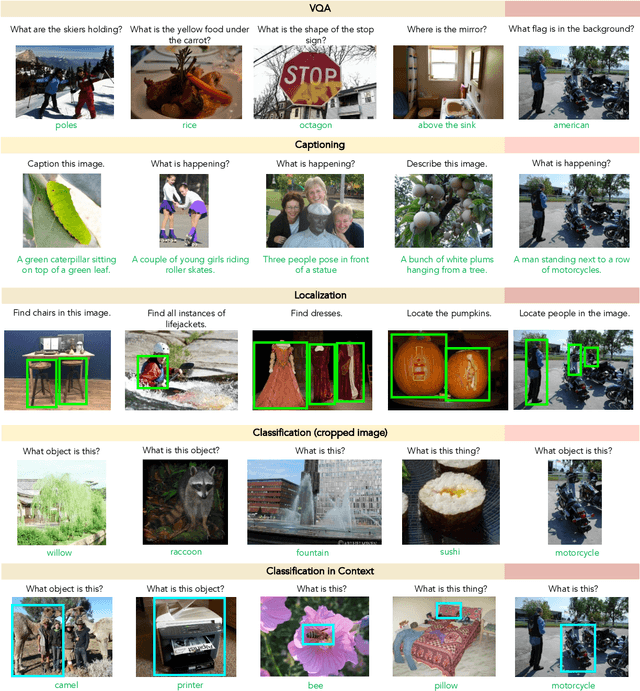
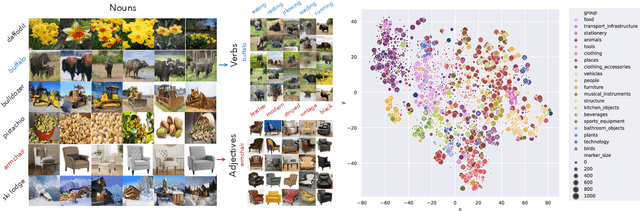
General purpose vision (GPV) systems are models that are designed to solve a wide array of visual tasks without requiring architectural changes. Today, GPVs primarily learn both skills and concepts from large fully supervised datasets. Scaling GPVs to tens of thousands of concepts by acquiring data to learn each concept for every skill quickly becomes prohibitive. This work presents an effective and inexpensive alternative: learn skills from fully supervised datasets, learn concepts from web image search results, and leverage a key characteristic of GPVs -- the ability to transfer visual knowledge across skills. We use a dataset of 1M+ images spanning 10k+ visual concepts to demonstrate webly-supervised concept expansion for two existing GPVs (GPV-1 and VL-T5) on 3 benchmarks - 5 COCO based datasets (80 primary concepts), a newly curated series of 5 datasets based on the OpenImages and VisualGenome repositories (~500 concepts) and the Web-derived dataset (10k+ concepts). We also propose a new architecture, GPV-2 that supports a variety of tasks -- from vision tasks like classification and localization to vision+language tasks like QA and captioning to more niche ones like human-object interaction recognition. GPV-2 benefits hugely from web data, outperforms GPV-1 and VL-T5 across these benchmarks, and does well in a 0-shot setting at action and attribute recognition.
Toward Training at ImageNet Scale with Differential Privacy
Feb 09, 2022
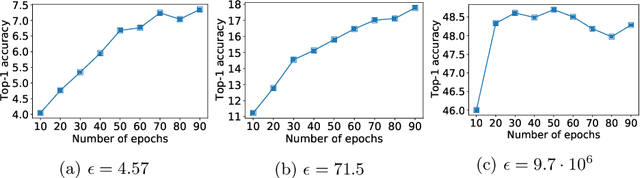
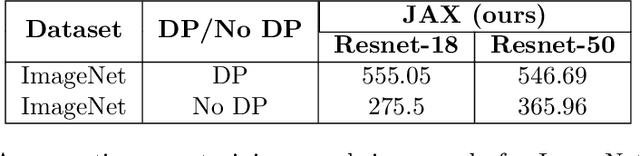
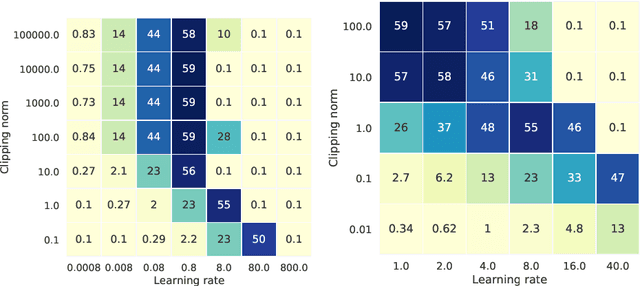
Differential privacy (DP) is the de facto standard for training machine learning (ML) models, including neural networks, while ensuring the privacy of individual examples in the training set. Despite a rich literature on how to train ML models with differential privacy, it remains extremely challenging to train real-life, large neural networks with both reasonable accuracy and privacy. We set out to investigate how to do this, using ImageNet image classification as a poster example of an ML task that is very challenging to resolve accurately with DP right now. This paper shares initial lessons from our effort, in the hope that it will inspire and inform other researchers to explore DP training at scale. We show approaches that help make DP training faster, as well as model types and settings of the training process that tend to work better in the DP setting. Combined, the methods we discuss let us train a Resnet-18 with DP to $47.9\%$ accuracy and privacy parameters $\epsilon = 10, \delta = 10^{-6}$. This is a significant improvement over "naive" DP training of ImageNet models, but a far cry from the $75\%$ accuracy that can be obtained by the same network without privacy. The model we use was pretrained on the Places365 data set as a starting point. We share our code at https://github.com/google-research/dp-imagenet, calling for others to build upon this new baseline to further improve DP at scale.
Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
Mar 28, 2020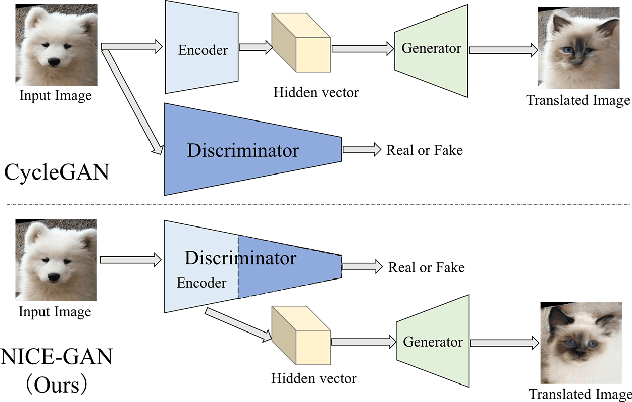
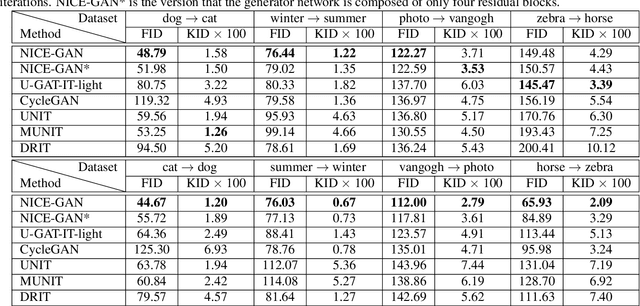
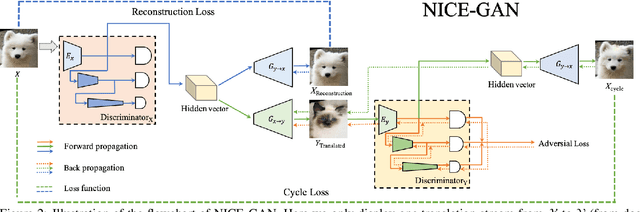
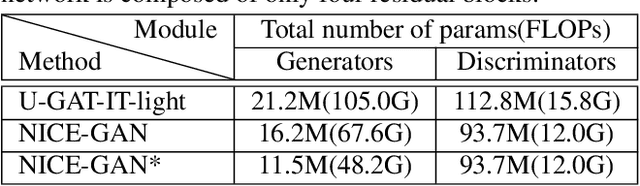
Unsupervised image-to-image translation is a central task in computer vision. Current translation frameworks will abandon the discriminator once the training process is completed. This paper contends a novel role of the discriminator by reusing it for encoding the images of the target domain. The proposed architecture, termed as NICE-GAN, exhibits two advantageous patterns over previous approaches: First, it is more compact since no independent encoding component is required; Second, this plug-in encoder is directly trained by the adversary loss, making it more informative and trained more effectively if a multi-scale discriminator is applied. The main issue in NICE-GAN is the coupling of translation with discrimination along the encoder, which could incur training inconsistency when we play the min-max game via GAN. To tackle this issue, we develop a decoupled training strategy by which the encoder is only trained when maximizing the adversary loss while keeping frozen otherwise. Extensive experiments on four popular benchmarks demonstrate the superior performance of NICE-GAN over state-of-the-art methods in terms of FID, KID, and also human preference. Comprehensive ablation studies are also carried out to isolate the validity of each proposed component. Our codes are available at https://github.com/alpc91/NICE-GAN-pytorch.
Machine Learning based Medical Image Deepfake Detection: A Comparative Study
Sep 27, 2021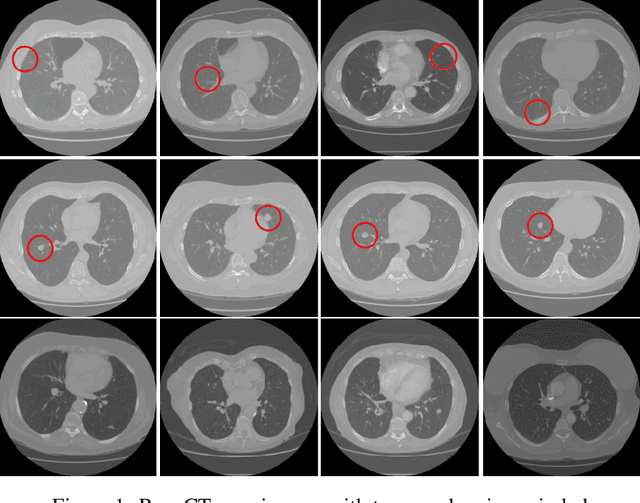
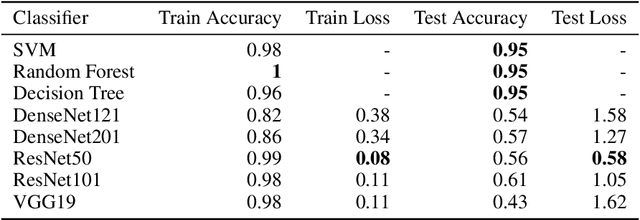
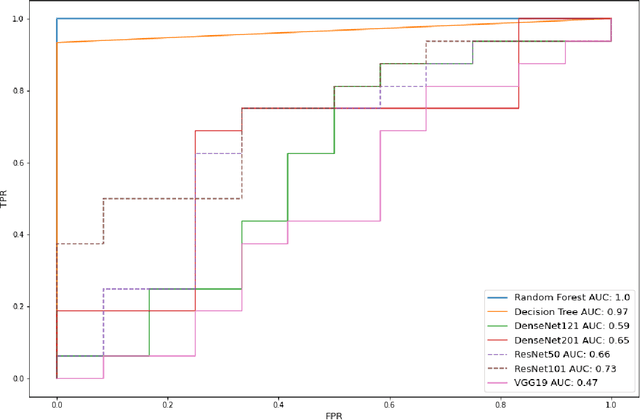
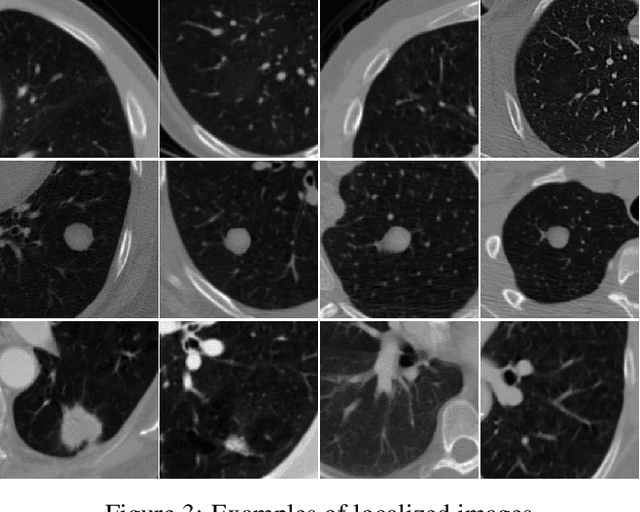
Deep generative networks in recent years have reinforced the need for caution while consuming various modalities of digital information. One avenue of deepfake creation is aligned with injection and removal of tumors from medical scans. Failure to detect medical deepfakes can lead to large setbacks on hospital resources or even loss of life. This paper attempts to address the detection of such attacks with a structured case study. We evaluate different machine learning algorithms and pretrained convolutional neural networks on distinguishing between tampered and untampered data. The findings of this work show near perfect accuracy in detecting instances of tumor injections and removals.
HRFormer: High-Resolution Transformer for Dense Prediction
Nov 07, 2021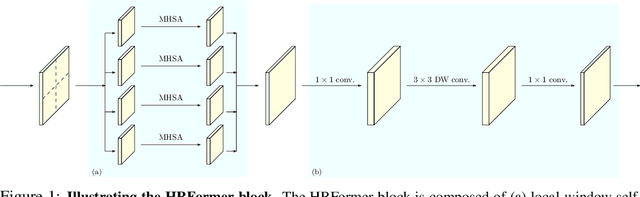
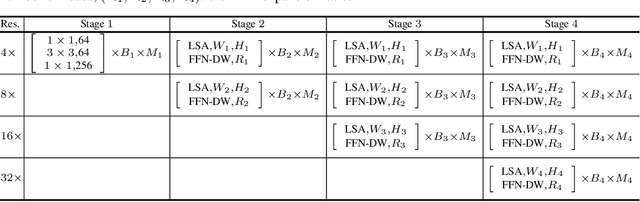


We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformer on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin transformer by $1.3$ AP on COCO pose estimation with $50\%$ fewer parameters and $30\%$ fewer FLOPs. Code is available at: https://github.com/HRNet/HRFormer.
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021
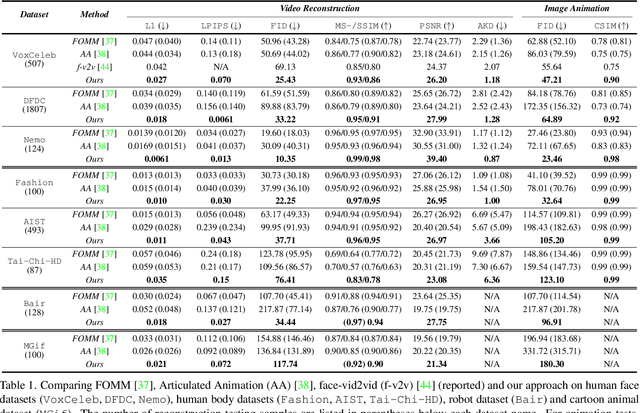
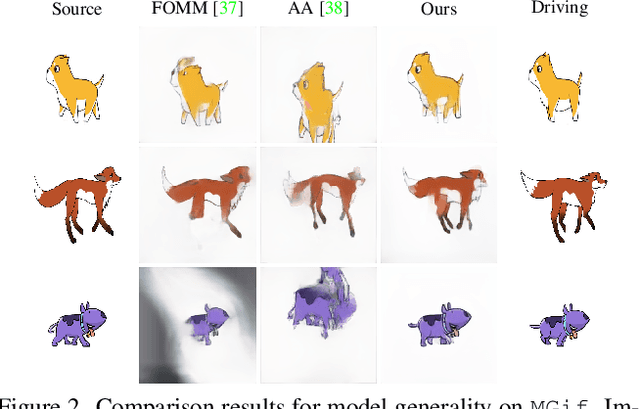
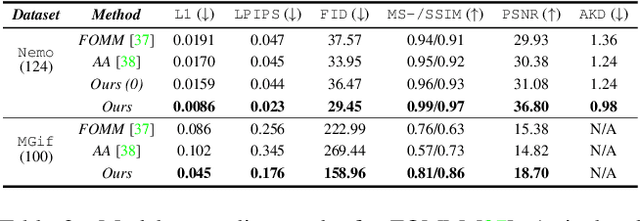
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
NeRF in the Dark: High Dynamic Range View Synthesis from Noisy Raw Images
Nov 26, 2021
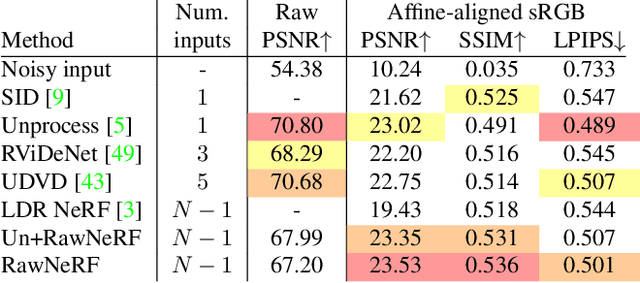
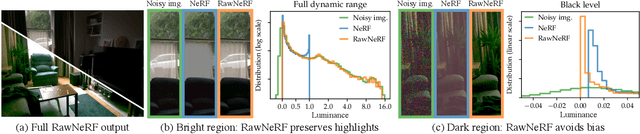
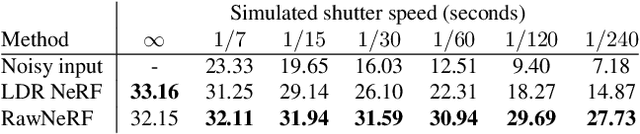
Neural Radiance Fields (NeRF) is a technique for high quality novel view synthesis from a collection of posed input images. Like most view synthesis methods, NeRF uses tonemapped low dynamic range (LDR) as input; these images have been processed by a lossy camera pipeline that smooths detail, clips highlights, and distorts the simple noise distribution of raw sensor data. We modify NeRF to instead train directly on linear raw images, preserving the scene's full dynamic range. By rendering raw output images from the resulting NeRF, we can perform novel high dynamic range (HDR) view synthesis tasks. In addition to changing the camera viewpoint, we can manipulate focus, exposure, and tonemapping after the fact. Although a single raw image appears significantly more noisy than a postprocessed one, we show that NeRF is highly robust to the zero-mean distribution of raw noise. When optimized over many noisy raw inputs (25-200), NeRF produces a scene representation so accurate that its rendered novel views outperform dedicated single and multi-image deep raw denoisers run on the same wide baseline input images. As a result, our method, which we call RawNeRF, can reconstruct scenes from extremely noisy images captured in near-darkness.
Single Image Dehazing Algorithm Based on Sky Region Segmentation
Jul 10, 2020
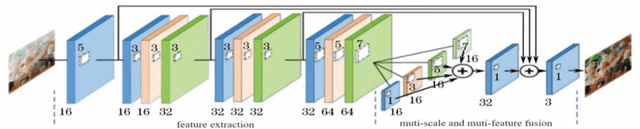
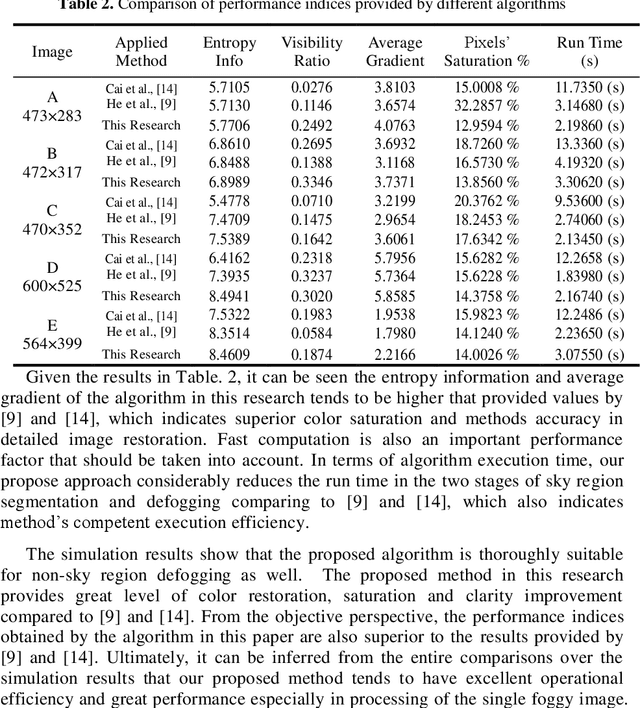
In this paper a hybrid image defogging approach based on region segmentation is proposed to address the dark channel priori algorithm's shortcomings in de-fogging the sky regions. The preliminary stage of the proposed approach focuses on the segmentation of sky and non-sky regions in a foggy image taking the advantageous of Meanshift and edge detection with embedded confidence. In the second stage, an improved dark channel priori algorithm is employed to defog the non-sky region. Ultimately, the sky area is processed by DehazeNet algorithm, which relies on deep learning Convolutional Neural Networks. The simulation results show that the proposed hybrid approach in this research addresses the problem of color distortion associated with sky regions in foggy images. The approach greatly improves the image quality indices including entropy information, visibility ratio of the edges, average gradient, and the saturation percentage with a very fast computation time, which is a good indication of the excellent performance of this model.
Distinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021
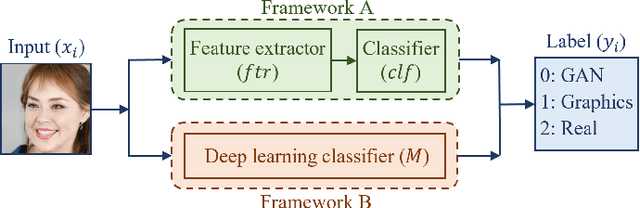
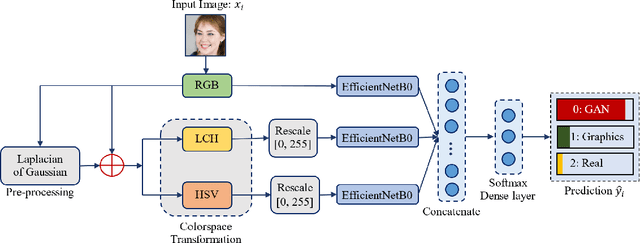
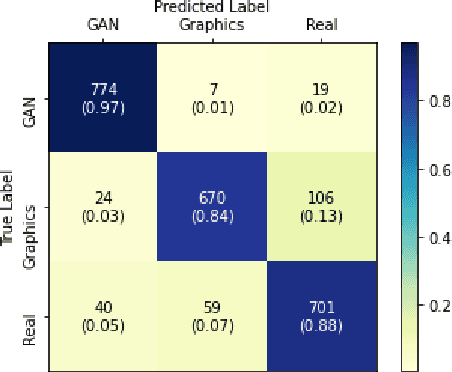
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.
A novel network training approach for open set image recognition
Sep 27, 2021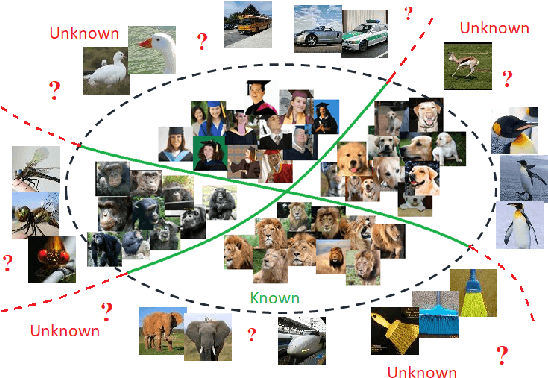
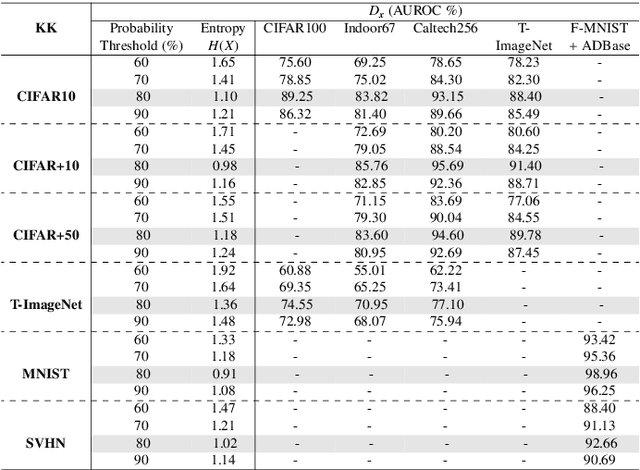
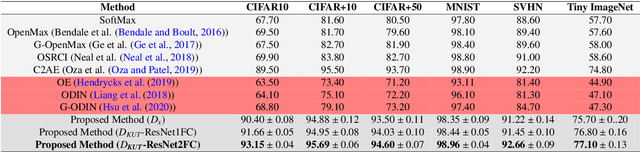
Convolutional Neural Networks (CNNs) are commonly designed for closed set arrangements, where test instances only belong to some "Known Known" (KK) classes used in training. As such, they predict a class label for a test sample based on the distribution of the KK classes. However, when used under the Open Set Recognition (OSR) setup (where an input may belong to an "Unknown Unknown" or UU class), such a network will always classify a test instance as one of the KK classes even if it is from a UU class. As a solution, recently, data augmentation based on Generative Adversarial Networks(GAN) has been used. In this work, we propose a novel approach for mining a "Known UnknownTrainer" or KUT set and design a deep OSR Network (OSRNet) to harness this dataset. The goal isto teach OSRNet the essence of the UUs through KUT set, which is effectively a collection of mined "hard Known Unknown negatives". Once trained, OSRNet can detect the UUs while maintaining high classification accuracy on KKs. We evaluate OSRNet on six benchmark datasets and demonstrate it outperforms contemporary OSR methods.