 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A novel audio representation using space filling curves
Jan 08, 2022
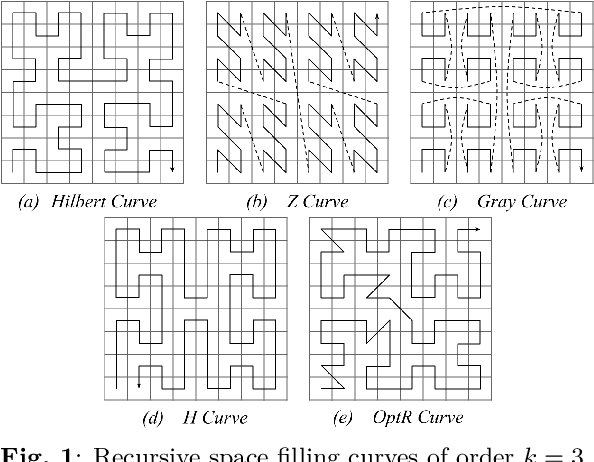
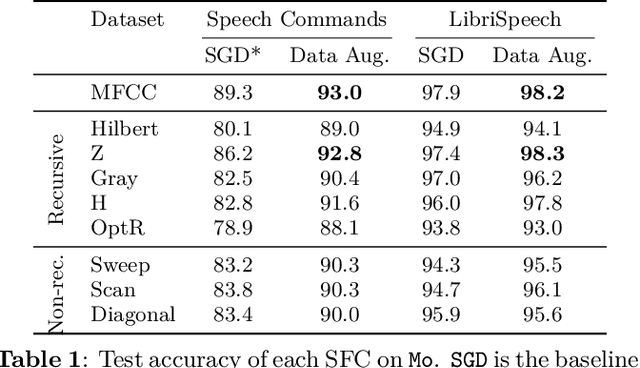
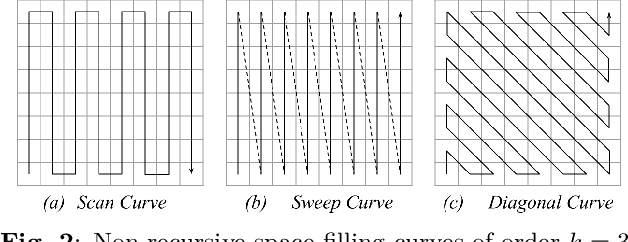
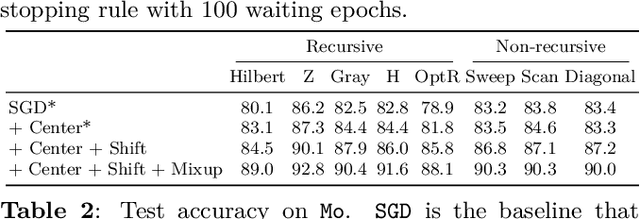
Since convolutional neural networks (CNNs) have revolutionized the image processing field, they have been widely applied in the audio context. A common approach is to convert the one-dimensional audio signal time series to two-dimensional images using a time-frequency decomposition method. Also it is common to discard the phase information. In this paper, we propose to map one-dimensional audio waveforms to two-dimensional images using space filling curves (SFCs). These mappings do not compress the input signal, while preserving its local structure. Moreover, the mappings benefit from progress made in deep learning and the large collection of existing computer vision networks. We test eight SFCs on two keyword spotting problems. We show that the Z curve yields the best results due to its shift equivariance under convolution operations. Additionally, the Z curve produces comparable results to the widely used mel frequency cepstral coefficients across multiple CNNs.
Deep Auto-encoder with Neural Response
Nov 30, 2021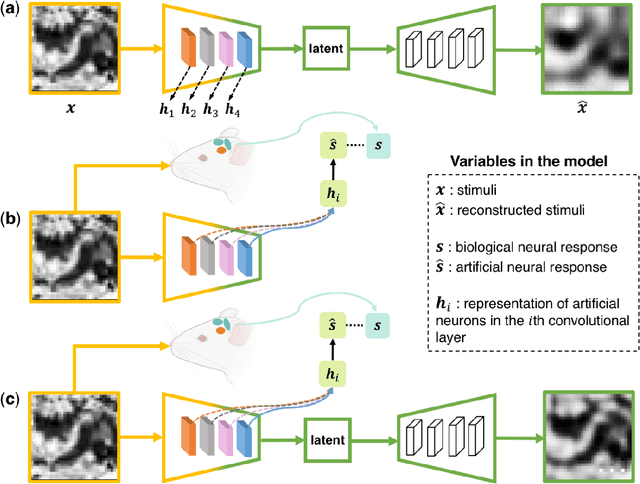
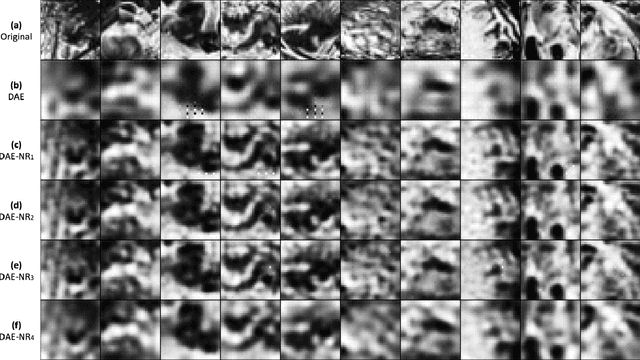
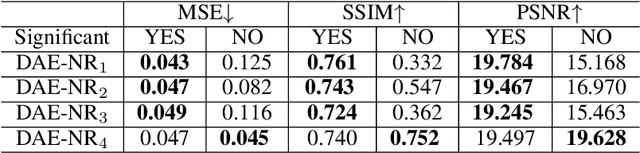
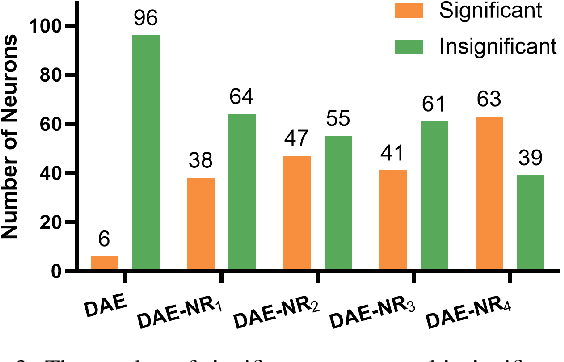
Artificial intelligence and neuroscience are deeply interactive. Artificial neural networks (ANNs) have been a versatile tool to study the neural representation in the ventral visual stream, and the knowledge in neuroscience in return inspires ANN models to improve performance in the task. However, how to merge these two directions into a unified model has less studied. Here, we propose a hybrid model, called deep auto-encoder with the neural response (DAE-NR), which incorporates the information from the visual cortex into ANNs to achieve better image reconstruction and higher neural representation similarity between biological and artificial neurons. Specifically, the same visual stimuli (i.e., natural images) are input to both the mice brain and DAE-NR. The DAE-NR jointly learns to map a specific layer of the encoder network to the biological neural responses in the ventral visual stream by a mapping function and to reconstruct the visual input by the decoder. Our experiments demonstrate that if and only if with the joint learning, DAE-NRs can (i) improve the performance of image reconstruction and (ii) increase the representational similarity between biological neurons and artificial neurons. The DAE-NR offers a new perspective on the integration of computer vision and visual neuroscience.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022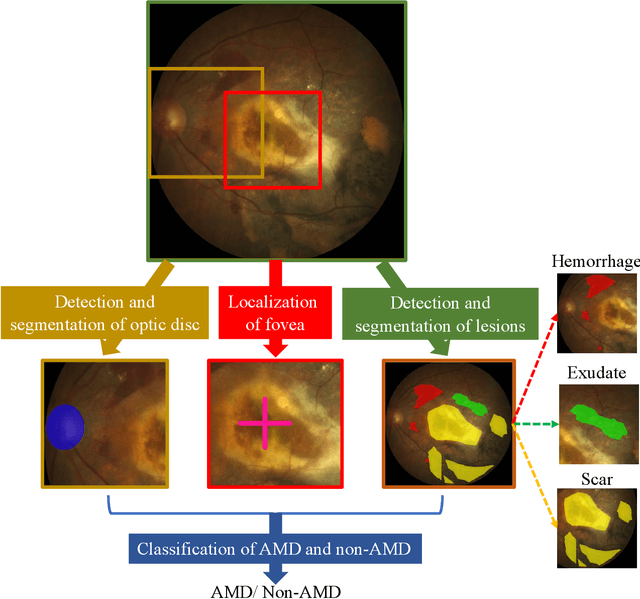

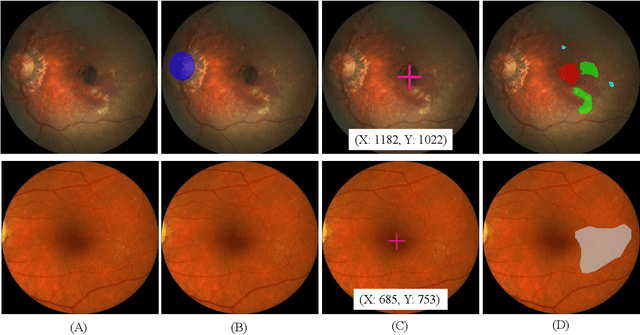
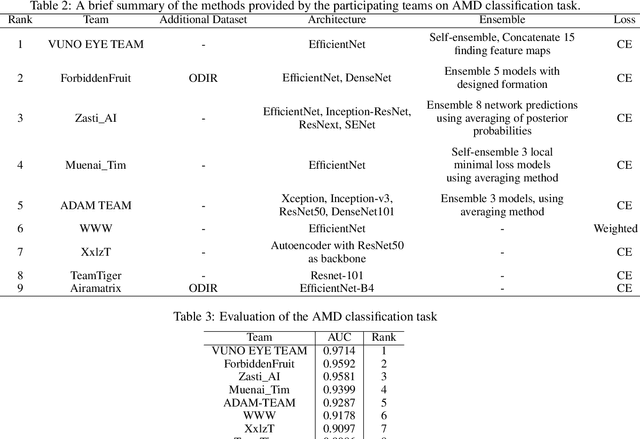
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
Deep Models for Visual Sentiment Analysis of Disaster-related Multimedia Content
Nov 30, 2021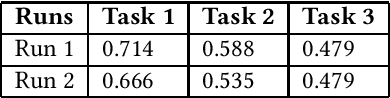
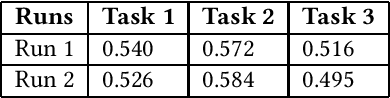
This paper presents a solutions for the MediaEval 2021 task namely "Visual Sentiment Analysis: A Natural Disaster Use-case". The task aims to extract and classify sentiments perceived by viewers and the emotional message conveyed by natural disaster-related images shared on social media. The task is composed of three sub-tasks including, one single label multi-class image classification task, and, two multi-label multi-class image classification tasks, with different sets of labels. In our proposed solutions, we rely mainly on two different state-of-the-art models namely, Inception-v3 and VggNet-19, pre-trained on ImageNet, which are fine-tuned for each of the three task using different strategies. Overall encouraging results are obtained on all the three tasks. On the single-label classification task (i.e. Task 1), we obtained the weighted average F1-scores of 0.540 and 0.526 for the Inception-v3 and VggNet-19 based solutions, respectively. On the multi-label classification i.e., Task 2 and Task 3, the weighted F1-score of our Inception-v3 based solutions was 0.572 and 0.516, respectively. Similarly, the weighted F1-score of our VggNet-19 based solution on Task 2 and Task 3 was 0.584 and 0.495, respectively.
Image Formation Model Guided Deep Image Super-Resolution
Aug 25, 2019
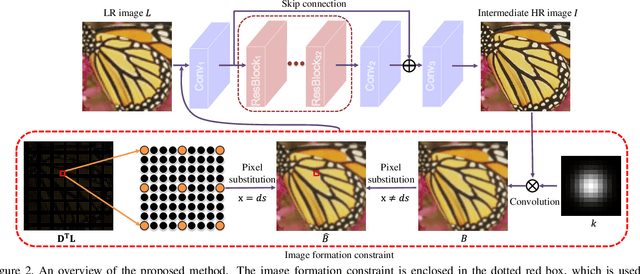


We present a simple and effective image super-resolution algorithm that imposes an image formation constraint on the deep neural networks via pixel substitution. The proposed algorithm first uses a deep neural network to estimate intermediate high-resolution images, blurs the intermediate images using known blur kernels, and then substitutes values of the pixels at the un-decimated positions with those of the corresponding pixels from the low-resolution images. The output of the pixel substitution process strictly satisfies the image formation model and is further refined by the same deep neural network in a cascaded manner. The proposed framework is trained in an end-to-end fashion and can work with existing feed-forward deep neural networks for super-resolution and converges fast in practice. Extensive experimental results show that the proposed algorithm performs favorably against state-of-the-art methods.
DenseTact: Optical Tactile Sensor for Dense Shape Reconstruction
Jan 04, 2022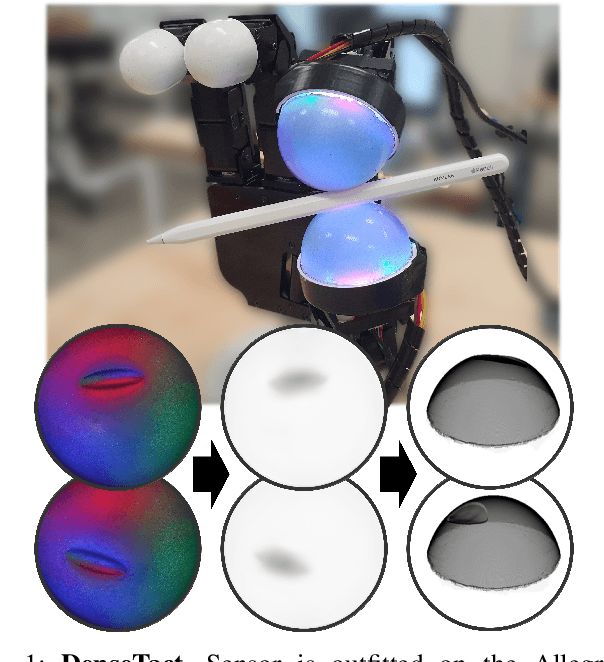
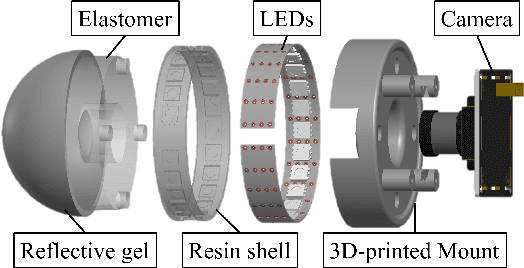
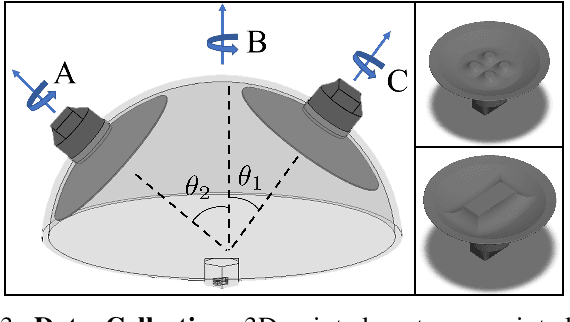
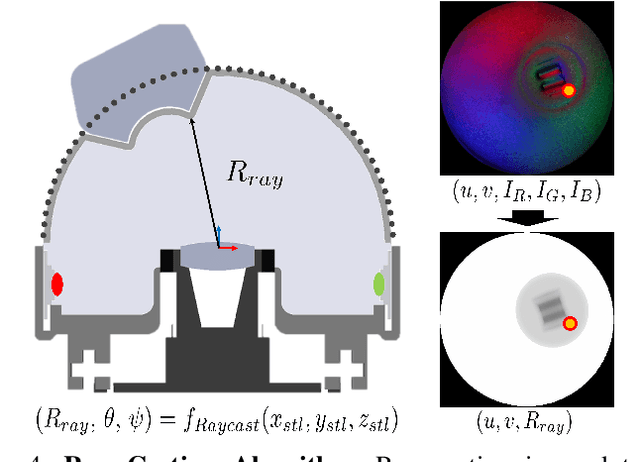
Increasing the performance of tactile sensing in robots enables versatile, in-hand manipulation. Vision-based tactile sensors have been widely used as rich tactile feedback has been shown to be correlated with increased performance in manipulation tasks. Existing tactile sensor solutions with high resolution have limitations that include low accuracy, expensive components, or lack of scalability. In this paper, an inexpensive, scalable, and compact tactile sensor with high-resolution surface deformation modeling for surface reconstruction of the 3D sensor surface is proposed. By measuring the image from the fisheye camera, it is shown that the sensor can successfully estimate the surface deformation in real-time (1.8ms) by using deep convolutional neural networks. This sensor in its design and sensing abilities represents a significant step toward better object in-hand localization, classification, and surface estimation all enabled by high-resolution shape reconstruction.
Design of magnetic coupling-based anti-biofouling mechanism for underwater optical sensors
Jan 28, 2022

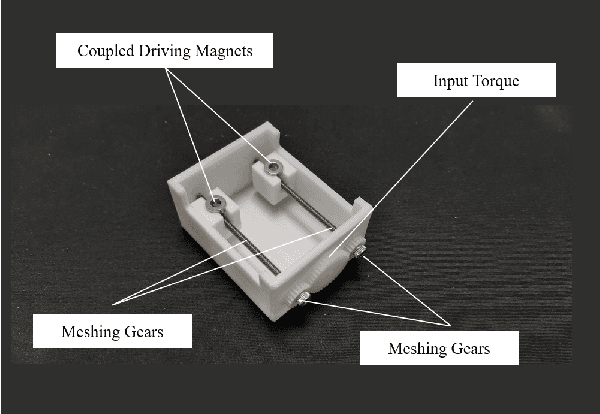
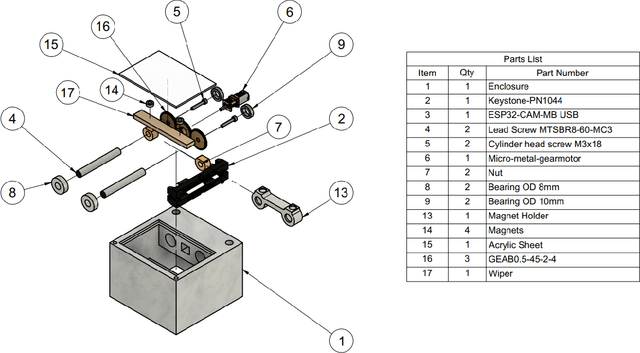
Water monitoring is crucial for environmental monitoring, transportation, energy and telecommunication. One of the main problems in aquatic environmental monitoring is biofouling. The simplest method among the current antifouling strategies is the use of wiper technologies like brushes and wipers which apply mechanical pressure. In designing built-in strategies however, manufacturers usually build the sensor around the biofouling system. The current state-of-the-art is a fully integrated central wiper in the sensor that enables cleaning of all probes mounted on the sonde. Improvements in antifouling strategies lag rapid advancements in sensor technologies such as in miniaturization, specialization, and costs. Hence, improving built-in designs by decreasing size and complexity will decrease maintenance and overall costs. This design is targeted for the EU project Robocoenosis since bio-hybrid systems in this project incorporate living organisms. This technology targets selective proliferation of the organisms which only prevents biofilms on components where they are unwanted. Beyond this, the use of autonomous activation based on image processing may likely be advantageous for minimizing the need for human inspection and maintenance. In addition to Robocoenosis, we also aim at incorporating this design in another project entitled Heterogeneous Swarm of Underwater Autonomous Vehicles where a swarm of heterogeneous underwater robotic fish is being developed.
Image Quality Assessment: Unifying Structure and Texture Similarity
Apr 16, 2020
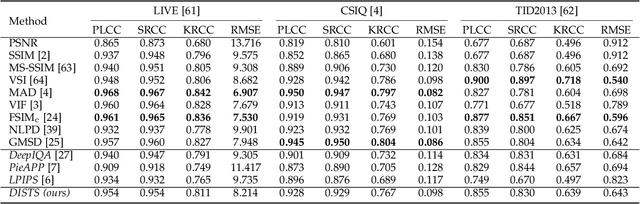

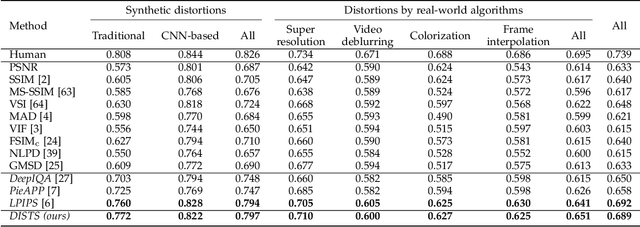
Objective measures of image quality generally operate by making local comparisons of pixels of a "degraded" image to those of the original. Relative to human observers, these measures are overly sensitive to resampling of texture regions (e.g., replacing one patch of grass with another). Here we develop the first full-reference image quality model with explicit tolerance to texture resampling. Using a convolutional neural network, we construct an injective and differentiable function that transforms images to a multi-scale overcomplete representation. We empirically show that the spatial averages of the feature maps in this representation capture texture appearance, in that they provide a set of sufficient statistical constraints to synthesize a wide variety of texture patterns. We then describe an image quality method that combines correlation of these spatial averages ("texture similarity") with correlation of the feature maps ("structure similarity"). The parameters of the proposed measure are jointly optimized to match human ratings of image quality, while minimizing the reported distances between subimages cropped from the same texture images. Experiments show that the optimized method explains human perceptual scores, both on conventional image quality databases, as well as on texture databases. The measure also offers competitive performance on related tasks such as texture classification and retrieval. Finally, we show that our method is relatively insensitive to geometric transformations (e.g., translation and dilation), without use of any specialized training or data augmentation. Code is available at https://github.com/dingkeyan93/DISTS.
Aerial Images Meet Crowdsourced Trajectories: A New Approach to Robust Road Extraction
Nov 30, 2021
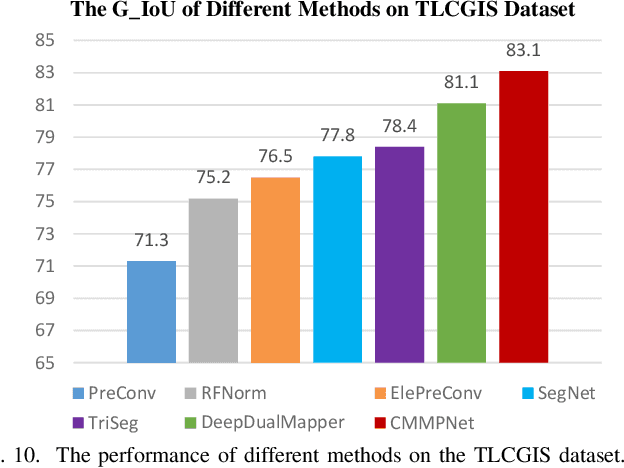
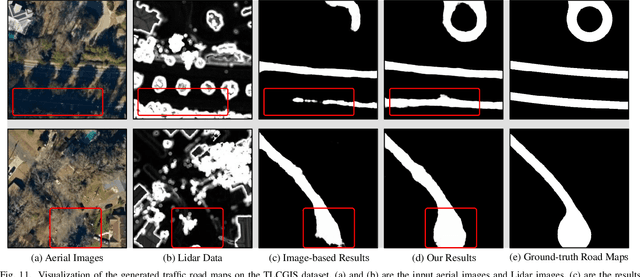
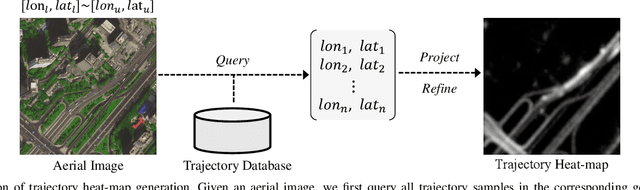
Land remote sensing analysis is a crucial research in earth science. In this work, we focus on a challenging task of land analysis, i.e., automatic extraction of traffic roads from remote sensing data, which has widespread applications in urban development and expansion estimation. Nevertheless, conventional methods either only utilized the limited information of aerial images, or simply fused multimodal information (e.g., vehicle trajectories), thus cannot well recognize unconstrained roads. To facilitate this problem, we introduce a novel neural network framework termed Cross-Modal Message Propagation Network (CMMPNet), which fully benefits the complementary different modal data (i.e., aerial images and crowdsourced trajectories). Specifically, CMMPNet is composed of two deep Auto-Encoders for modality-specific representation learning and a tailor-designed Dual Enhancement Module for cross-modal representation refinement. In particular, the complementary information of each modality is comprehensively extracted and dynamically propagated to enhance the representation of another modality. Extensive experiments on three real-world benchmarks demonstrate the effectiveness of our CMMPNet for robust road extraction benefiting from blending different modal data, either using image and trajectory data or image and Lidar data. From the experimental results, we observe that the proposed approach outperforms current state-of-the-art methods by large margins.
Attention-based network for low-light image enhancement
May 20, 2020
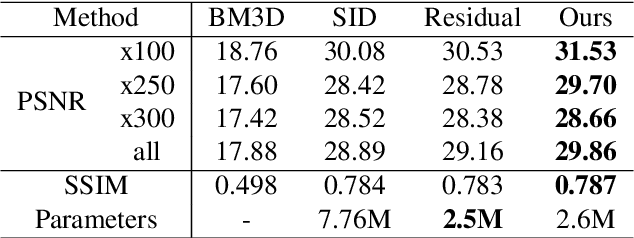
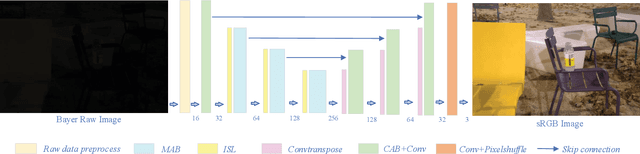

The captured images under low light conditions often suffer insufficient brightness and notorious noise. Hence, low-light image enhancement is a key challenging task in computer vision. A variety of methods have been proposed for this task, but these methods often failed in an extreme low-light environment and amplified the underlying noise in the input image. To address such a difficult problem, this paper presents a novel attention-based neural network to generate high-quality enhanced low-light images from the raw sensor data. Specifically, we first employ attention strategy (i.e. channel attention and spatial attention modules) to suppress undesired chromatic aberration and noise. The channel attention module guides the network to refine redundant colour features. The spatial attention module focuses on denoising by taking advantage of the non-local correlation in the image. Furthermore, we propose a new pooling layer, called inverted shuffle layer, which adaptively selects useful information from previous features. Extensive experiments demonstrate the superiority of the proposed network in terms of suppressing the chromatic aberration and noise artifacts in enhancement, especially when the low-light image has severe noise.