 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021

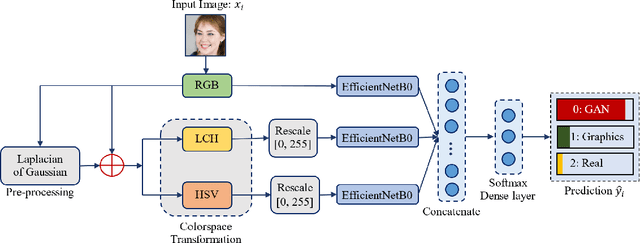
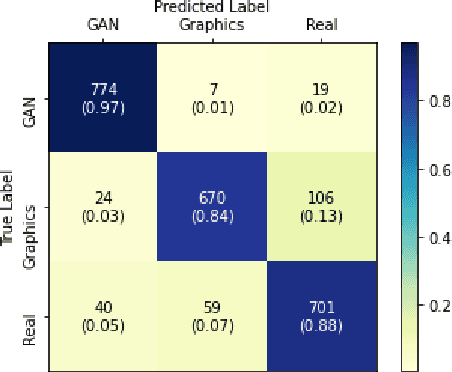
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.
A Content Transformation Block For Image Style Transfer
Mar 18, 2020
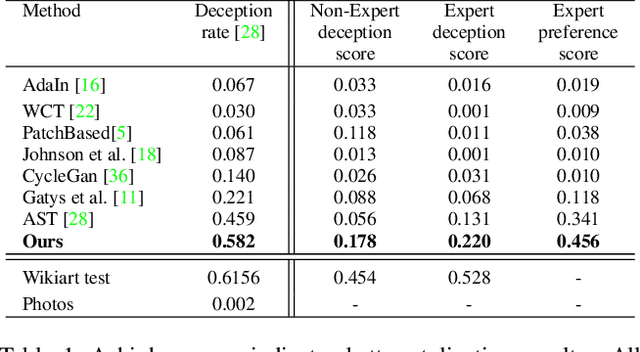
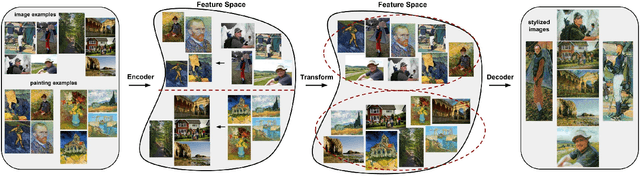
Style transfer has recently received a lot of attention, since it allows to study fundamental challenges in image understanding and synthesis. Recent work has significantly improved the representation of color and texture and computational speed and image resolution. The explicit transformation of image content has, however, been mostly neglected: while artistic style affects formal characteristics of an image, such as color, shape or texture, it also deforms, adds or removes content details. This paper explicitly focuses on a content-and style-aware stylization of a content image. Therefore, we introduce a content transformation module between the encoder and decoder. Moreover, we utilize similar content appearing in photographs and style samples to learn how style alters content details and we generalize this to other class details. Additionally, this work presents a novel normalization layer critical for high resolution image synthesis. The robustness and speed of our model enables a video stylization in real-time and high definition. We perform extensive qualitative and quantitative evaluations to demonstrate the validity of our approach.
Self-appearance-aided Differential Evolution for Motion Transfer
Oct 09, 2021
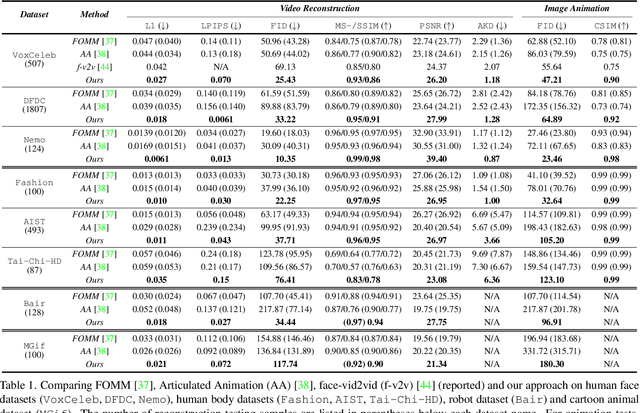
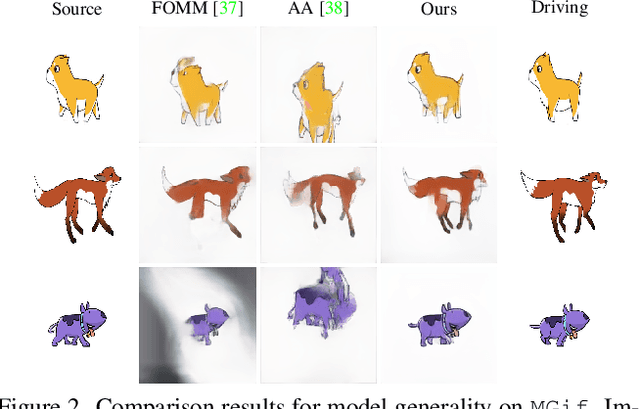
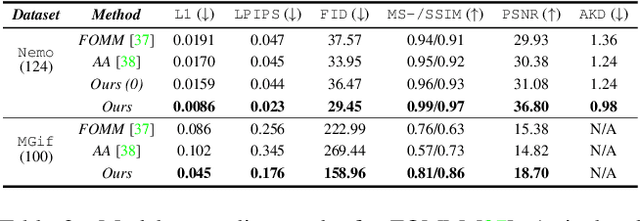
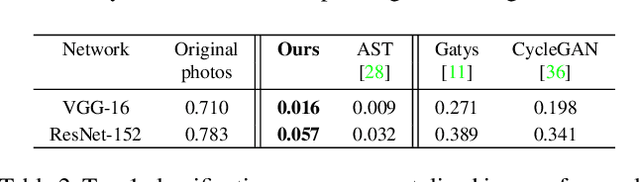
Image animation transfers the motion of a driving video to a static object in a source image, while keeping the source identity unchanged. Great progress has been made in unsupervised motion transfer recently, where no labelled data or ground truth domain priors are needed. However, current unsupervised approaches still struggle when there are large motion or viewpoint discrepancies between the source and driving images. In this paper, we introduce three measures that we found to be effective for overcoming such large viewpoint changes. Firstly, to achieve more fine-grained motion deformation fields, we propose to apply Neural-ODEs for parametrizing the evolution dynamics of the motion transfer from source to driving. Secondly, to handle occlusions caused by large viewpoint and motion changes, we take advantage of the appearance flow obtained from the source image itself ("self-appearance"), which essentially "borrows" similar structures from other regions of an image to inpaint missing regions. Finally, our framework is also able to leverage the information from additional reference views which help to drive the source identity in spite of varying motion state. Extensive experiments demonstrate that our approach outperforms the state-of-the-arts by a significant margin (~40%), across six benchmarks varying from human faces, human bodies to robots and cartoon characters. Model generality analysis indicates that our approach generalises the best across different object categories as well.
Vanishing Point Guided Natural Image Stitching
Apr 06, 2020
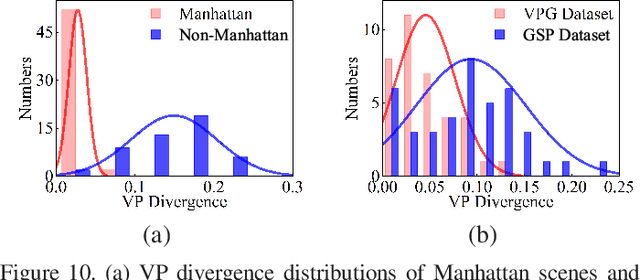
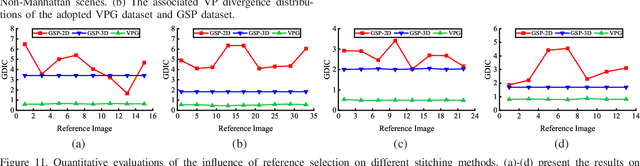

Recently, works on improving the naturalness of stitching images gain more and more extensive attention. Previous methods suffer the failures of severe projective distortion and unnatural rotation, especially when the number of involved images is large or images cover a very wide field of view. In this paper, we propose a novel natural image stitching method, which takes into account the guidance of vanishing points to tackle the mentioned failures. Inspired by a vital observation that mutually orthogonal vanishing points in Manhattan world can provide really useful orientation clues, we design a scheme to effectively estimate prior of image similarity. Given such estimated prior as global similarity constraints, we feed it into a popular mesh deformation framework to achieve impressive natural stitching performances. Compared with other existing methods, including APAP, SPHP, AANAP, and GSP, our method achieves state-of-the-art performance in both quantitative and qualitative experiments on natural image stitching.
Deep Atrous Guided Filter for Image Restoration in Under Display Cameras
Sep 01, 2020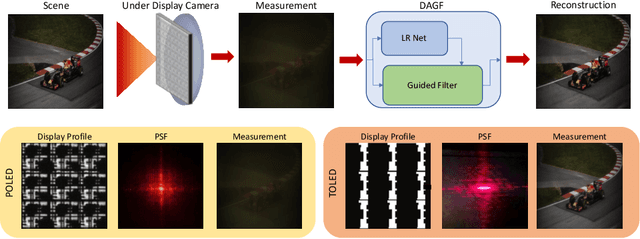
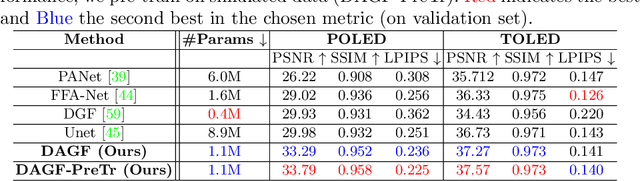
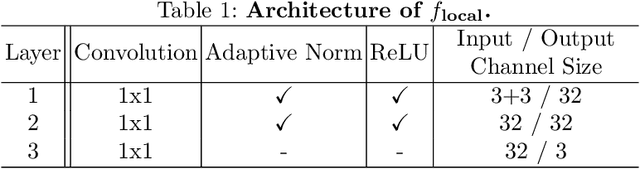

Under Display Cameras present a promising opportunity for phone manufacturers to achieve bezel-free displays by positioning the camera behind semi-transparent OLED screens. Unfortunately, such imaging systems suffer from severe image degradation due to light attenuation and diffraction effects. In this work, we present Deep Atrous Guided Filter (DAGF), a two-stage, end-to-end approach for image restoration in UDC systems. A Low-Resolution Network first restores image quality at low-resolution, which is subsequently used by the Guided Filter Network as a filtering input to produce a high-resolution output. Besides the initial downsampling, our low-resolution network uses multiple, parallel atrous convolutions to preserve spatial resolution and emulates multi-scale processing. Our approach's ability to directly train on megapixel images results in significant performance improvement. We additionally propose a simple simulation scheme to pre-train our model and boost performance. Our overall framework ranks 2nd and 5th in the RLQ-TOD'20 UDC Challenge for POLED and TOLED displays, respectively.
FPGA-optimized Hardware acceleration for Spiking Neural Networks
Jan 18, 2022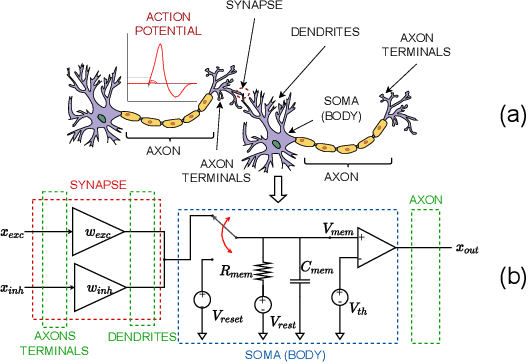
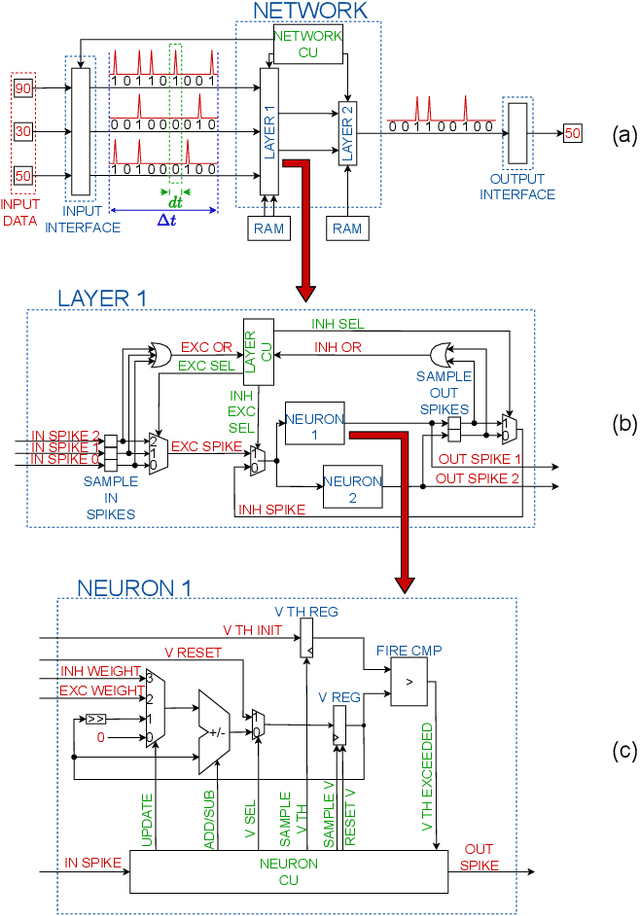
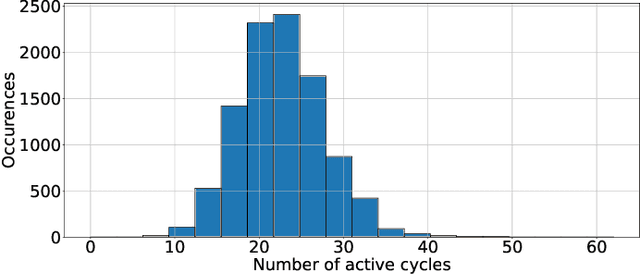
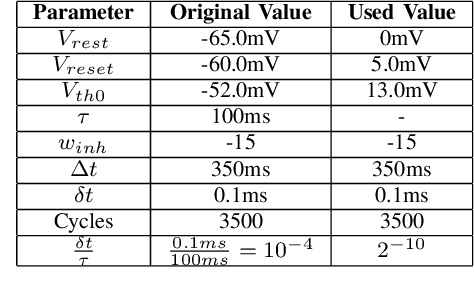
Artificial intelligence (AI) is gaining success and importance in many different tasks. The growing pervasiveness and complexity of AI systems push researchers towards developing dedicated hardware accelerators. Spiking Neural Networks (SNN) represent a promising solution in this sense since they implement models that are more suitable for a reliable hardware design. Moreover, from a neuroscience perspective, they better emulate a human brain. This work presents the development of a hardware accelerator for an SNN, with off-line training, applied to an image recognition task, using the MNIST as the target dataset. Many techniques are used to minimize the area and to maximize the performance, such as the replacement of the multiplication operation with simple bit shifts and the minimization of the time spent on inactive spikes, useless for the update of neurons' internal state. The design targets a Xilinx Artix-7 FPGA, using in total around the 40% of the available hardware resources and reducing the classification time by three orders of magnitude, with a small 4.5% impact on the accuracy, if compared to its software, full precision counterpart.
Autoencoding Video Latents for Adversarial Video Generation
Jan 18, 2022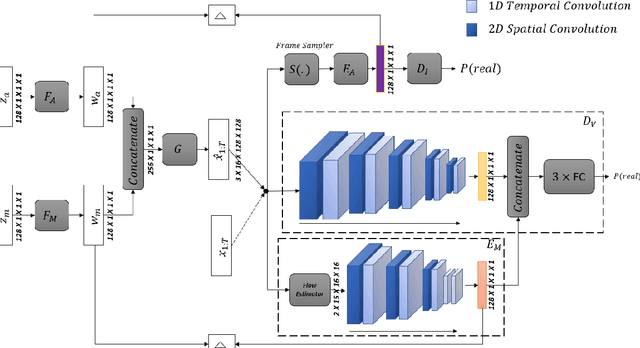
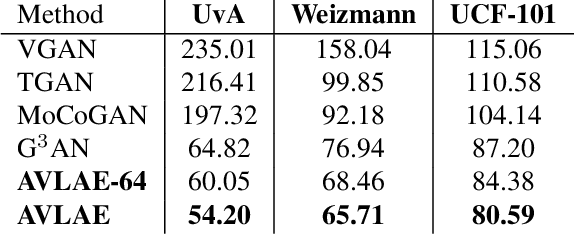
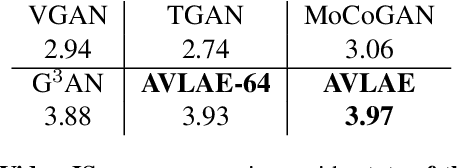

Given the three dimensional complexity of a video signal, training a robust and diverse GAN based video generative model is onerous due to large stochasticity involved in data space. Learning disentangled representations of the data help to improve robustness and provide control in the sampling process. For video generation, there is a recent progress in this area by considering motion and appearance as orthogonal information and designing architectures that efficiently disentangle them. These approaches rely on handcrafting architectures that impose structural priors on the generator to decompose appearance and motion codes in the latent space. Inspired from the recent advancements in the autoencoder based image generation, we present AVLAE (Adversarial Video Latent AutoEncoder) which is a two stream latent autoencoder where the video distribution is learned by adversarial training. In particular, we propose to autoencode the motion and appearance latent vectors of the video generator in the adversarial setting. We demonstrate that our approach learns to disentangle motion and appearance codes even without the explicit structural composition in the generator. Several experiments with qualitative and quantitative results demonstrate the effectiveness of our method.
Incorporating Image Gradients as Secondary Input Associated with Input Image to Improve the Performance of the CNN Model
Jun 05, 2020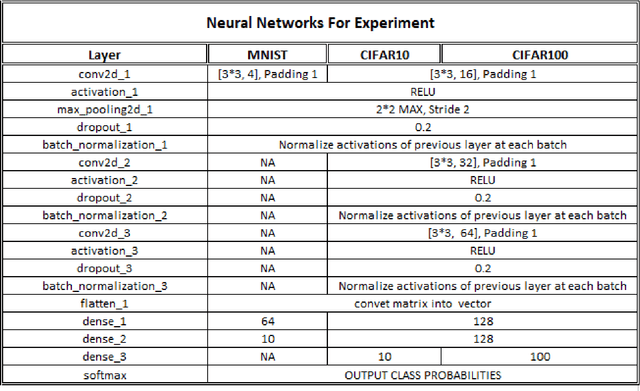
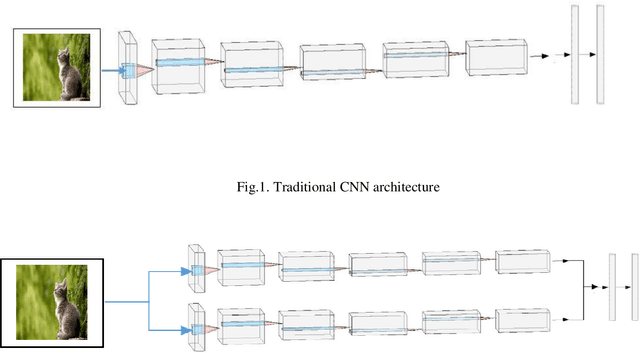
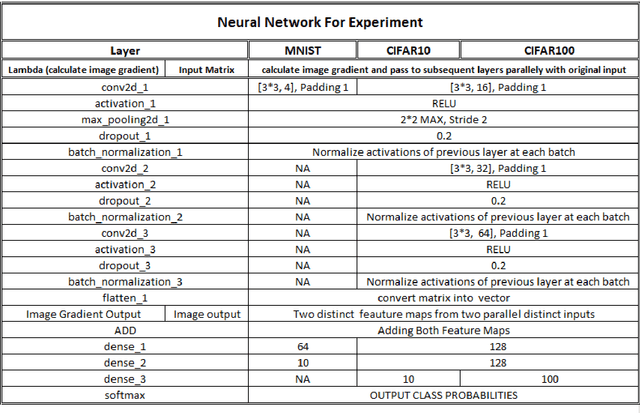
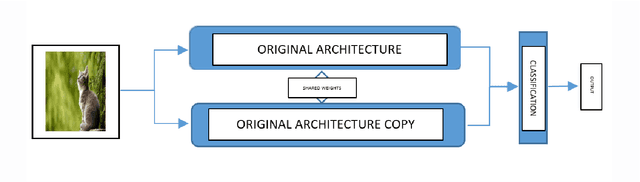
CNN is very popular neural network architecture in modern days. It is primarily most used tool for vision related task to extract the important features from the given image. Moreover, CNN works as a filter to extract the important features using convolutional operation in distinct layers. In existing CNN architectures, to train the network on given input, only single form of given input is fed to the network. In this paper, new architecture has been proposed where given input is passed in more than one form to the network simultaneously by sharing the layers with both forms of input. We incorporate image gradient as second form of the input associated with the original input image and allowing both inputs to flow in the network using same number of parameters to improve the performance of the model for better generalization. The results of the proposed CNN architecture, applying on diverse set of datasets such as MNIST, CIFAR10 and CIFAR100 show superior result compared to the benchmark CNN architecture considering inputs in single form.
A Robust Imbalanced SAR Image Change Detection Approach Based on Deep Difference Image and PCANet
Mar 03, 2020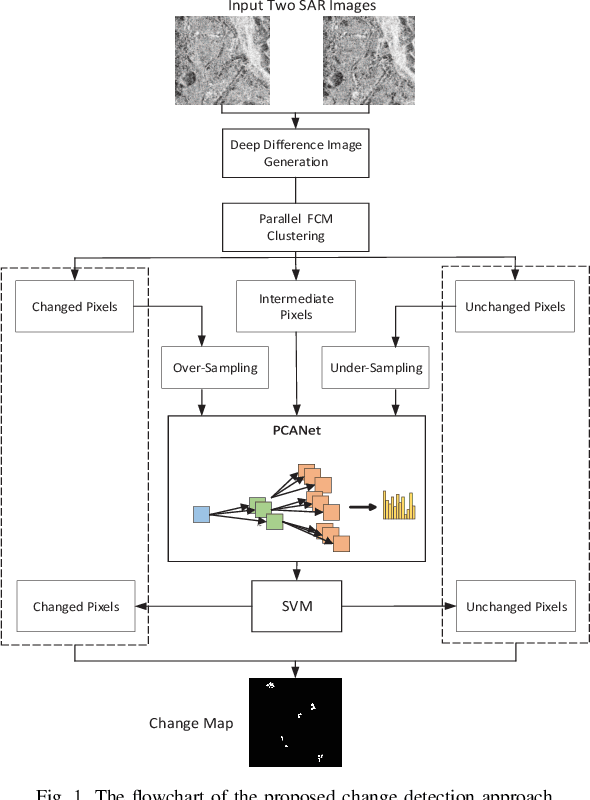
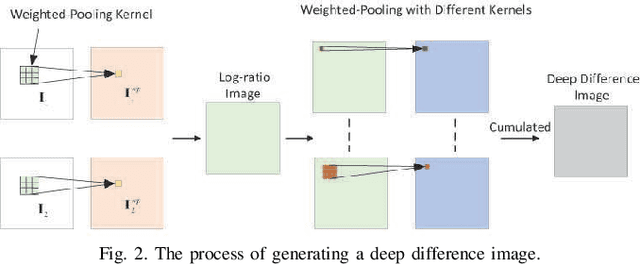

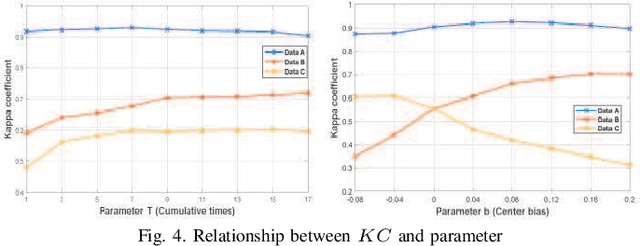
In this research, a novel robust change detection approach is presented for imbalanced multi-temporal synthetic aperture radar (SAR) image based on deep learning. Our main contribution is to develop a novel method for generating difference image and a parallel fuzzy c-means (FCM) clustering method. The main steps of our proposed approach are as follows: 1) Inspired by convolution and pooling in deep learning, a deep difference image (DDI) is obtained based on parameterized pooling leading to better speckle suppression and feature enhancement than traditional difference images. 2) Two different parameter Sigmoid nonlinear mapping are applied to the DDI to get two mapped DDIs. Parallel FCM are utilized on these two mapped DDIs to obtain three types of pseudo-label pixels, namely, changed pixels, unchanged pixels, and intermediate pixels. 3) A PCANet with support vector machine (SVM) are trained to classify intermediate pixels to be changed or unchanged. Three imbalanced multi-temporal SAR image sets are used for change detection experiments. The experimental results demonstrate that the proposed approach is effective and robust for imbalanced SAR data, and achieve up to 99.52% change detection accuracy superior to most state-of-the-art methods.
MDS-Net: A Multi-scale Depth Stratification Based Monocular 3D Object Detection Algorithm
Jan 12, 2022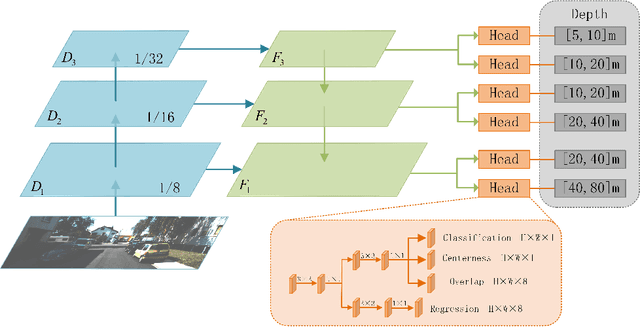
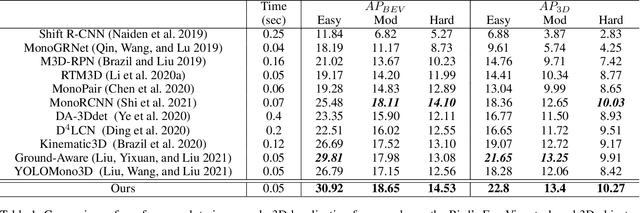
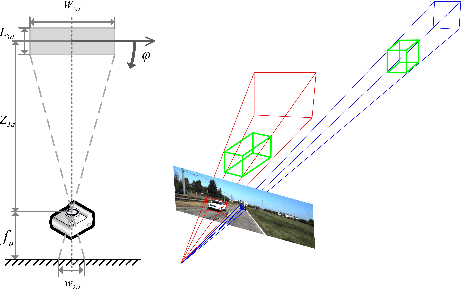

Monocular 3D object detection is very challenging in autonomous driving due to the lack of depth information. This paper proposes a one-stage monocular 3D object detection algorithm based on multi-scale depth stratification, which uses the anchor-free method to detect 3D objects in a per-pixel prediction. In the proposed MDS-Net, a novel depth-based stratification structure is developed to improve the network's ability of depth prediction by establishing mathematical models between depth and image size of objects. A new angle loss function is then developed to further improve the accuracy of the angle prediction and increase the convergence speed of training. An optimized soft-NMS is finally applied in the post-processing stage to adjust the confidence of candidate boxes. Experiments on the KITTI benchmark show that the MDS-Net outperforms the existing monocular 3D detection methods in 3D detection and BEV detection tasks while fulfilling real-time requirements.