 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generative Adversarial Networks for Image and Video Synthesis: Algorithms and Applications
Aug 06, 2020

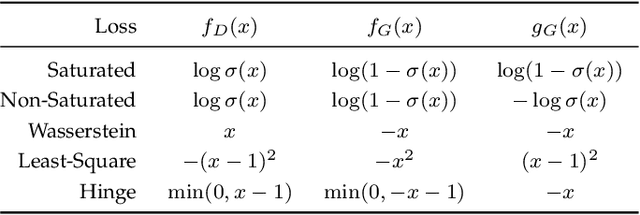

The generative adversarial network (GAN) framework has emerged as a powerful tool for various image and video synthesis tasks, allowing the synthesis of visual content in an unconditional or input-conditional manner. It has enabled the generation of high-resolution photorealistic images and videos, a task that was challenging or impossible with prior methods. It has also led to the creation of many new applications in content creation. In this paper, we provide an overview of GANs with a special focus on algorithms and applications for visual synthesis. We cover several important techniques to stabilize GAN training, which has a reputation for being notoriously difficult. We also discuss its applications to image translation, image processing, video synthesis, and neural rendering.
Learning to Detect Every Thing in an Open World
Dec 03, 2021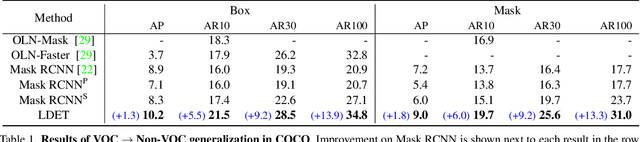
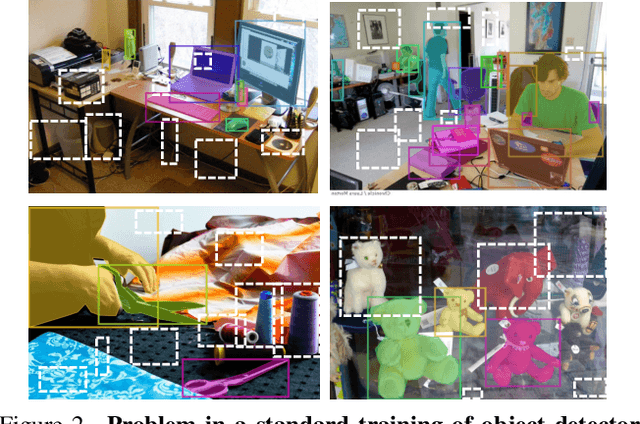
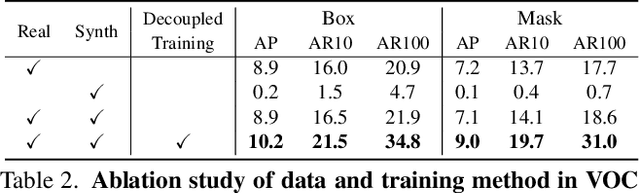
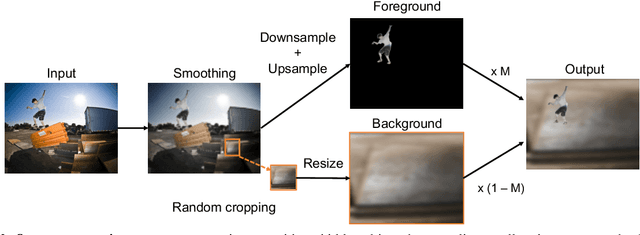
Many open-world applications require the detection of novel objects, yet state-of-the-art object detection and instance segmentation networks do not excel at this task. The key issue lies in their assumption that regions without any annotations should be suppressed as negatives, which teaches the model to treat the unannotated objects as background. To address this issue, we propose a simple yet surprisingly powerful data augmentation and training scheme we call Learning to Detect Every Thing (LDET). To avoid suppressing hidden objects, background objects that are visible but unlabeled, we paste annotated objects on a background image sampled from a small region of the original image. Since training solely on such synthetically augmented images suffers from domain shift, we decouple the training into two parts: 1) training the region classification and regression head on augmented images, and 2) training the mask heads on original images. In this way, a model does not learn to classify hidden objects as background while generalizing well to real images. LDET leads to significant improvements on many datasets in the open world instance segmentation task, outperforming baselines on cross-category generalization on COCO, as well as cross-dataset evaluation on UVO and Cityscapes.
DSFormer: A Dual-domain Self-supervised Transformer for Accelerated Multi-contrast MRI Reconstruction
Jan 26, 2022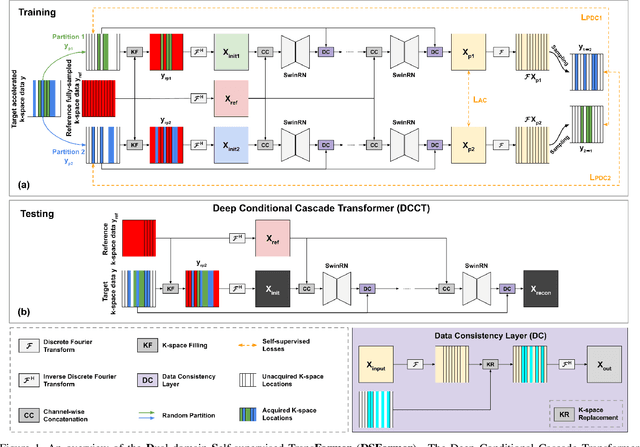
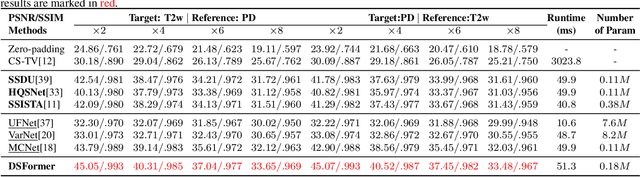
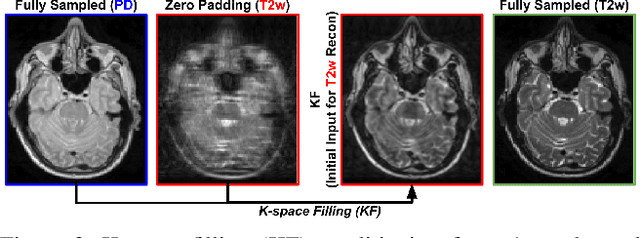
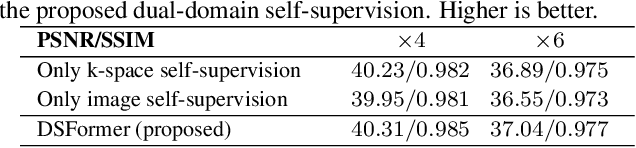
Multi-contrast MRI (MC-MRI) captures multiple complementary imaging modalities to aid in radiological decision-making. Given the need for lowering the time cost of multiple acquisitions, current deep accelerated MRI reconstruction networks focus on exploiting the redundancy between multiple contrasts. However, existing works are largely supervised with paired data and/or prohibitively expensive fully-sampled MRI sequences. Further, reconstruction networks typically rely on convolutional architectures which are limited in their capacity to model long-range interactions and may lead to suboptimal recovery of fine anatomical detail. To these ends, we present a dual-domain self-supervised transformer (DSFormer) for accelerated MC-MRI reconstruction. DSFormer develops a deep conditional cascade transformer (DCCT) consisting of several cascaded Swin transformer reconstruction networks (SwinRN) trained under two deep conditioning strategies to enable MC-MRI information sharing. We further present a dual-domain (image and k-space) self-supervised learning strategy for DCCT to alleviate the costs of acquiring fully sampled training data. DSFormer generates high-fidelity reconstructions which experimentally outperform current fully-supervised baselines. Moreover, we find that DSFormer achieves nearly the same performance when trained either with full supervision or with our proposed dual-domain self-supervision.
Sinogram upsampling using Primal-Dual UNet for undersampled CT and radial MRI reconstruction
Dec 26, 2021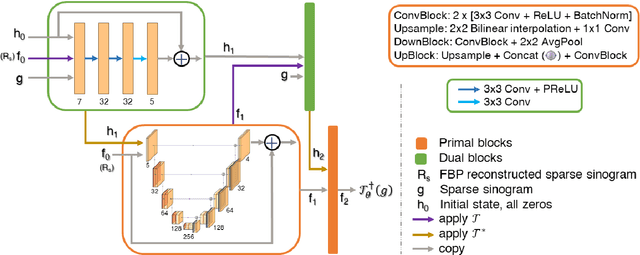
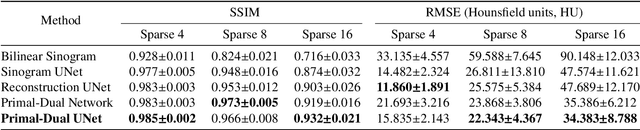
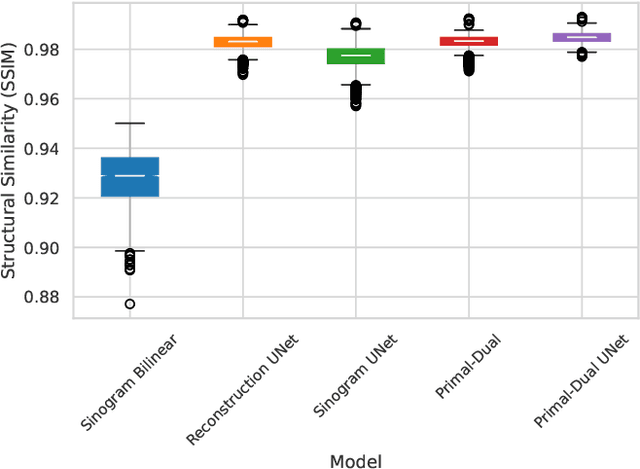
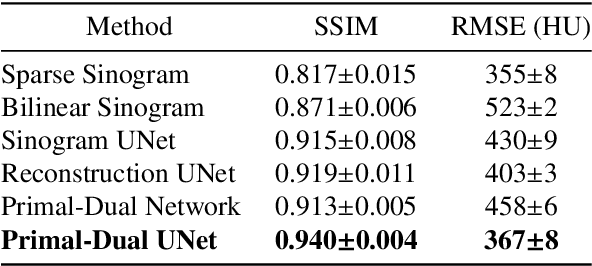
CT and MRI are two widely used clinical imaging modalities for non-invasive diagnosis. However, both of these modalities come with certain problems. CT uses harmful ionising radiation, and MRI suffers from slow acquisition speed. Both problems can be tackled by undersampling, such as sparse sampling. However, such undersampled data leads to lower resolution and introduces artefacts. Several techniques, including deep learning based methods, have been proposed to reconstruct such data. However, the undersampled reconstruction problem for these two modalities was always considered as two different problems and tackled separately by different research works. This paper proposes a unified solution for both sparse CT and undersampled radial MRI reconstruction, achieved by applying Fourier transform-based pre-processing on the radial MRI and then reconstructing both modalities using sinogram upsampling combined with filtered back-projection. The Primal-Dual network is a deep learning based method for reconstructing sparsely-sampled CT data. This paper introduces Primal-Dual UNet, which improves the Primal-Dual network in terms of accuracy and reconstruction speed. The proposed method resulted in an average SSIM of 0.932 while performing sparse CT reconstruction for fan-beam geometry with a sparsity level of 16, achieving a statistically significant improvement over the previous model, which resulted in 0.919. Furthermore, the proposed model resulted in 0.903 and 0.957 average SSIM while reconstructing undersampled brain and abdominal MRI data with an acceleration factor of 16 - statistically significant improvements over the original model, which resulted in 0.867 and 0.949. Finally, this paper shows that the proposed network not only improves the overall image quality, but also improves the image quality for the regions-of-interest; as well as generalises better in presence of a needle.
Ghost Projection
Sep 03, 2021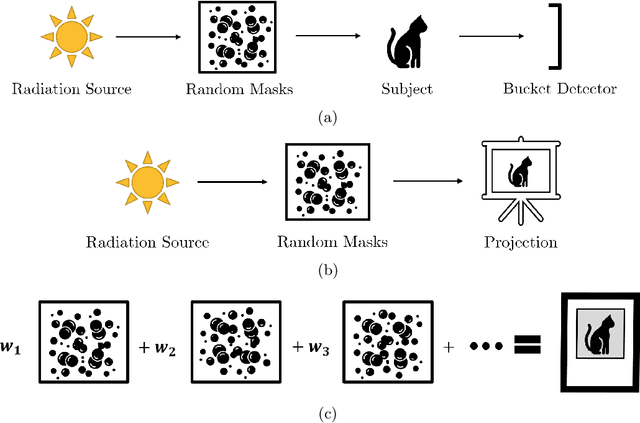
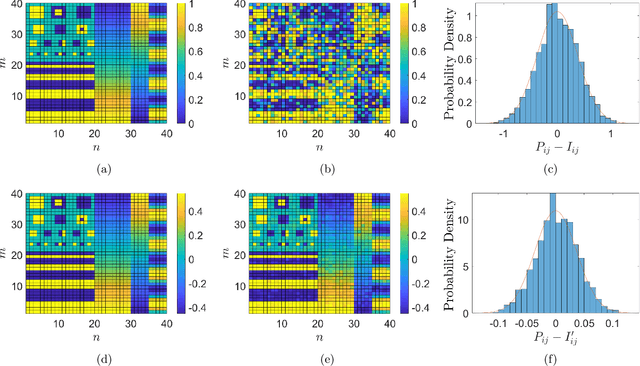
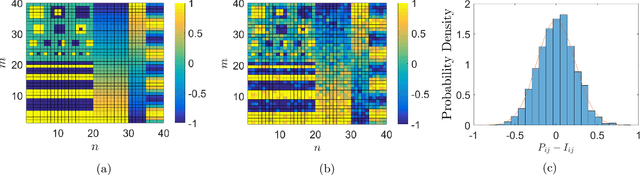
Ghost imaging is a developing imaging technique that employs random masks to image a sample. Ghost projection utilizes ghost-imaging concepts to perform the complementary procedure of projection of a desired image. The key idea underpinning ghost projection is that any desired spatial distribution of radiant exposure may be produced, up to an additive constant, by spatially-uniformly illuminating a set of random masks in succession. We explore three means of achieving ghost projection: (i) weighting each random mask, namely selecting its exposure time, according to its correlation with a desired image, (ii) selecting a subset of random masks according to their correlation with a desired image, and (iii) numerically optimizing a projection for a given set of random masks and desired image. The first two protocols are analytically tractable and conceptually transparent. The third is more efficient but less amenable to closed-form analytical expressions. A comparison with existing image-projection techniques is drawn and possible applications are discussed. These potential applications include: (i) a data projector for matter and radiation fields for which no current data projectors exist, (ii) a universal-mask approach to lithography, (iii) tomographic volumetric additive manufacturing, and (iv) a ghost-projection photocopier.
SimSR: Simple Distance-based State Representation for Deep Reinforcement Learning
Dec 31, 2021
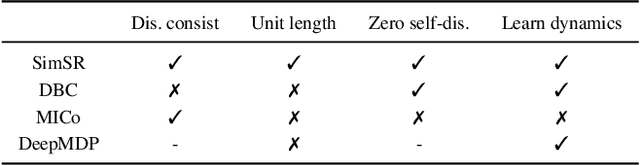


This work explores how to learn robust and generalizable state representation from image-based observations with deep reinforcement learning methods. Addressing the computational complexity, stringent assumptions, and representation collapse challenges in the existing work of bisimulation metric, we devise Simple State Representation (SimSR) operator, which achieves equivalent functionality while reducing the complexity by an order in comparison with bisimulation metric. SimSR enables us to design a stochastic-approximation-based method that can practically learn the mapping functions (encoders) from observations to latent representation space. Besides the theoretical analysis, we experimented and compared our work with recent state-of-the-art solutions in visual MuJoCo tasks. The results show that our model generally achieves better performance and has better robustness and good generalization.
Adversarial Robustness Against Image Color Transformation within Parametric Filter Space
Nov 12, 2020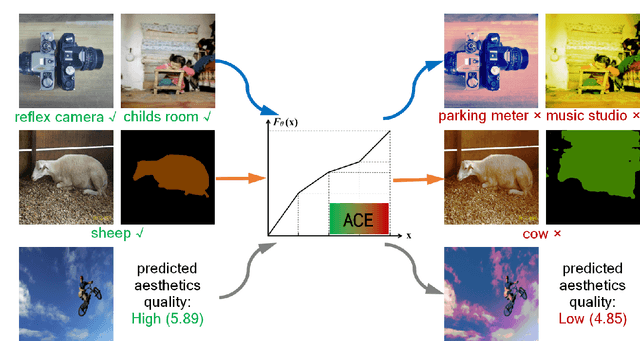
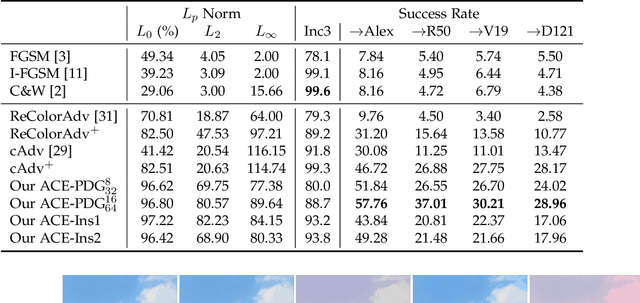
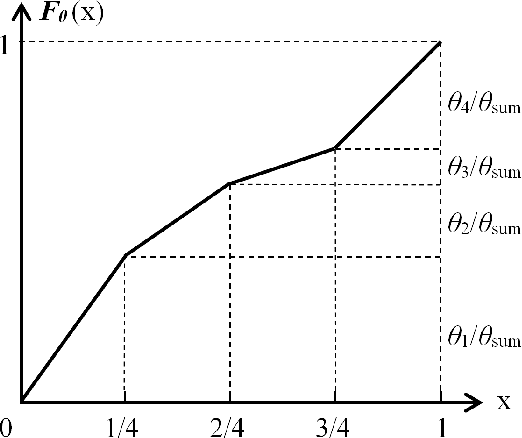

We propose Adversarial Color Enhancement (ACE), a novel approach to generating non-suspicious adversarial images by optimizing a color transformation within a parametric filter space. The filter we use approximates human-understandable color curve adjustment, constraining ACE with a single, continuous function. This property gives rise to a principled adversarial action space explicitly controlled by filter parameters. Existing color transformation attacks are not guided by a parametric space, and, consequently, additional pixel-related constraints such as regularization and sampling are necessary. These constraints make methodical analysis difficult. In this paper, we carry out a systematic robustness analysis of ACE from both the attack and defense perspectives by varying the bound of the color filter parameters. We investigate a general formulation of ACE and also a variant targeting particularly appealing color styles, as achieved with popular image filters. From the attack perspective, we provide extensive experiments on the vulnerability of image classifiers, but also explore the vulnerability of segmentation and aesthetic quality assessment algorithms, in both the white-box and black-box scenarios. From the defense perspective, more experiments provide insight into the stability of ACE against input transformation-based defenses and show the potential of adversarial training for improving model robustness against ACE.
Image Quality Assessment: Unifying Structure and Texture Similarity
Apr 16, 2020
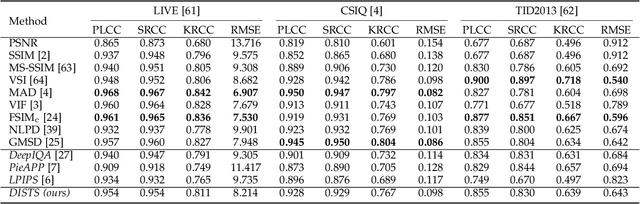

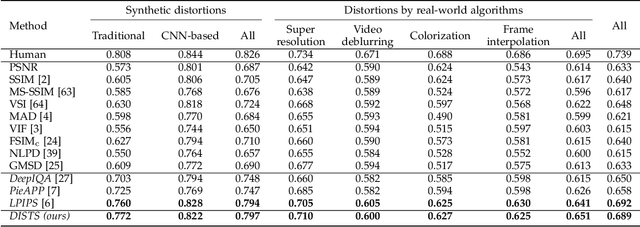
Objective measures of image quality generally operate by making local comparisons of pixels of a "degraded" image to those of the original. Relative to human observers, these measures are overly sensitive to resampling of texture regions (e.g., replacing one patch of grass with another). Here we develop the first full-reference image quality model with explicit tolerance to texture resampling. Using a convolutional neural network, we construct an injective and differentiable function that transforms images to a multi-scale overcomplete representation. We empirically show that the spatial averages of the feature maps in this representation capture texture appearance, in that they provide a set of sufficient statistical constraints to synthesize a wide variety of texture patterns. We then describe an image quality method that combines correlation of these spatial averages ("texture similarity") with correlation of the feature maps ("structure similarity"). The parameters of the proposed measure are jointly optimized to match human ratings of image quality, while minimizing the reported distances between subimages cropped from the same texture images. Experiments show that the optimized method explains human perceptual scores, both on conventional image quality databases, as well as on texture databases. The measure also offers competitive performance on related tasks such as texture classification and retrieval. Finally, we show that our method is relatively insensitive to geometric transformations (e.g., translation and dilation), without use of any specialized training or data augmentation. Code is available at https://github.com/dingkeyan93/DISTS.
Hiding Images into Images with Real-world Robustness
Oct 12, 2021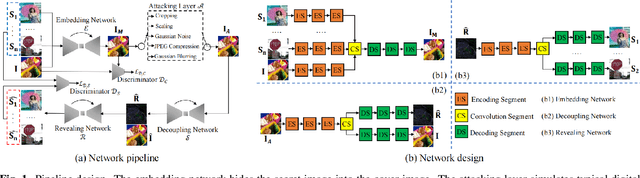
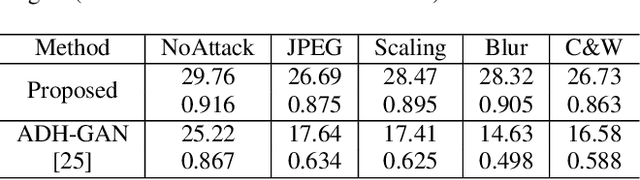


The existing image embedding networks are basically vulnerable to malicious attacks such as JPEG compression and noise adding, not applicable for real-world copyright protection tasks. To solve this problem, we introduce a generative deep network based method for hiding images into images while assuring high-quality extraction from the destructive synthesized images. An embedding network is sequentially concatenated with an attack layer, a decoupling network and an image extraction network. The addition of decoupling network learns to extract the embedded watermark from the attacked image. We also pinpoint the weaknesses of the adversarial training for robustness in previous works and build our improved real-world attack simulator. Experimental results demonstrate the superiority of the proposed method against typical digital attacks by a large margin, as well as the performance boost of the recovered images with the aid of progressive recovery strategy. Besides, we are the first to robustly hide three secret images.
Person Detection in Collaborative Group Learning Environments Using Multiple Representations
Dec 22, 2021
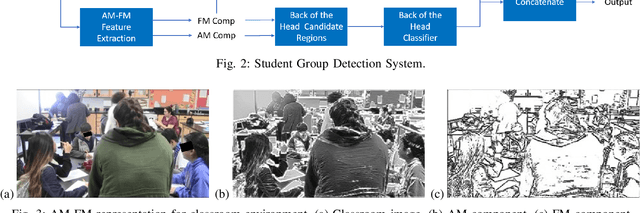
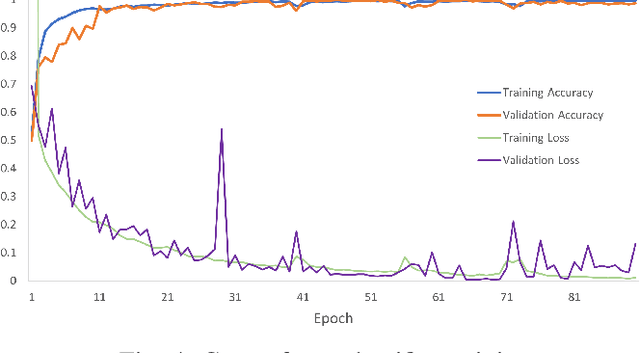
We introduce the problem of detecting a group of students from classroom videos. The problem requires the detection of students from different angles and the separation of the group from other groups in long videos (one to one and a half hours). We use multiple image representations to solve the problem. We use FM components to separate each group from background groups, AM-FM components for detecting the back-of-the-head, and YOLO for face detection. We use classroom videos from four different groups to validate our approach. Our use of multiple representations is shown to be significantly more accurate than the use of YOLO alone.