 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Total-Body Low-Dose CT Image Denoising using Prior Knowledge Transfer Technique with Contrastive Regularization Mechanism
Dec 06, 2021
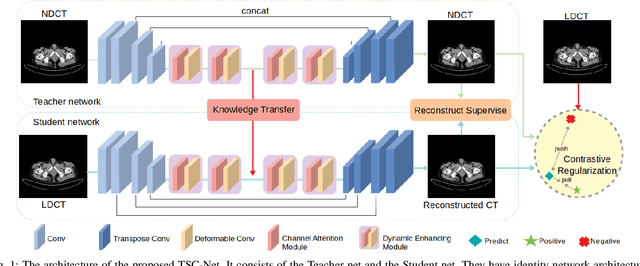
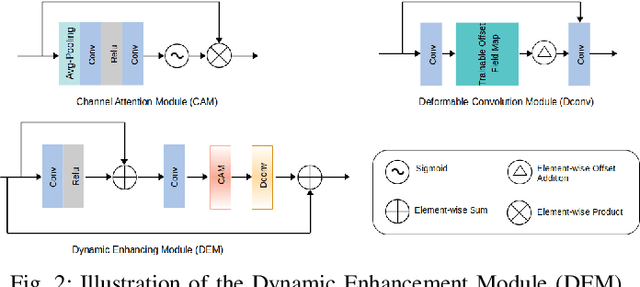

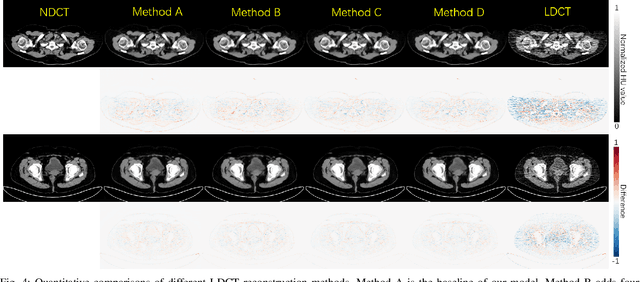
Reducing the radiation exposure for patients in Total-body CT scans has attracted extensive attention in the medical imaging community. Given the fact that low radiation dose may result in increased noise and artifacts, which greatly affected the clinical diagnosis. To obtain high-quality Total-body Low-dose CT (LDCT) images, previous deep-learning-based research work has introduced various network architectures. However, most of these methods only adopt Normal-dose CT (NDCT) images as ground truths to guide the training of the denoising network. Such simple restriction leads the model to less effectiveness and makes the reconstructed images suffer from over-smoothing effects. In this paper, we propose a novel intra-task knowledge transfer method that leverages the distilled knowledge from NDCT images to assist the training process on LDCT images. The derived architecture is referred to as the Teacher-Student Consistency Network (TSC-Net), which consists of the teacher network and the student network with identical architecture. Through the supervision between intermediate features, the student network is encouraged to imitate the teacher network and gain abundant texture details. Moreover, to further exploit the information contained in CT scans, a contrastive regularization mechanism (CRM) built upon contrastive learning is introduced.CRM performs to pull the restored CT images closer to the NDCT samples and push far away from the LDCT samples in the latent space. In addition, based on the attention and deformable convolution mechanism, we design a Dynamic Enhancement Module (DEM) to improve the network transformation capability.
Learning Deep Image Priors for Blind Image Denoising
Jun 04, 2019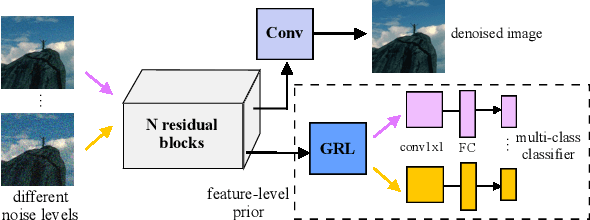
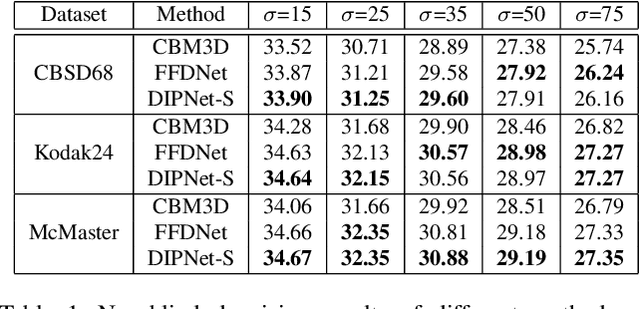
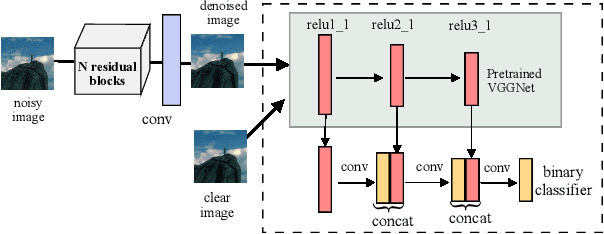
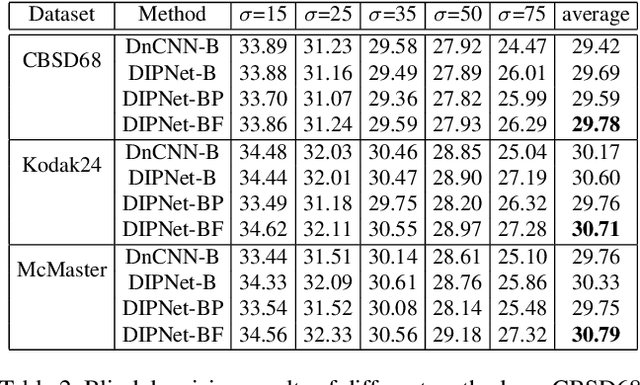
Image denoising is the process of removing noise from noisy images, which is an image domain transferring task, i.e., from a single or several noise level domains to a photo-realistic domain. In this paper, we propose an effective image denoising method by learning two image priors from the perspective of domain alignment. We tackle the domain alignment on two levels. 1) the feature-level prior is to learn domain-invariant features for corrupted images with different level noise; 2) the pixel-level prior is used to push the denoised images to the natural image manifold. The two image priors are based on $\mathcal{H}$-divergence theory and implemented by learning classifiers in adversarial training manners. We evaluate our approach on multiple datasets. The results demonstrate the effectiveness of our approach for robust image denoising on both synthetic and real-world noisy images. Furthermore, we show that the feature-level prior is capable of alleviating the discrepancy between different level noise. It can be used to improve the blind denoising performance in terms of distortion measures (PSNR and SSIM), while pixel-level prior can effectively improve the perceptual quality to ensure the realistic outputs, which is further validated by subjective evaluation.
Towards Understanding Quality Challenges of the Federated Learning: A First Look from the Lens of Robustness
Jan 05, 2022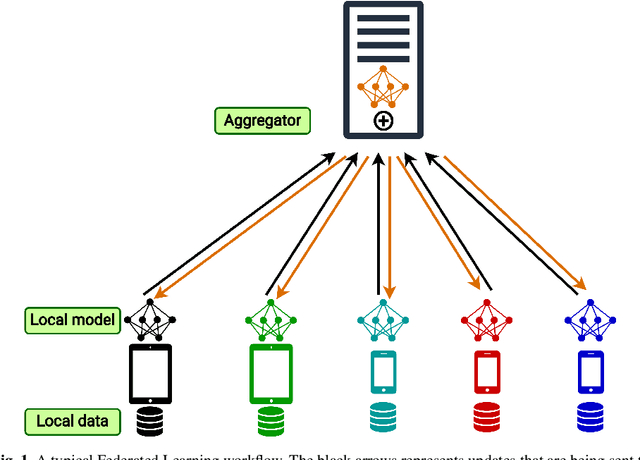
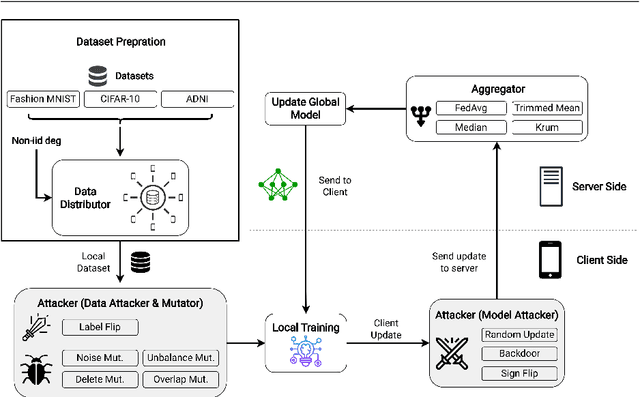
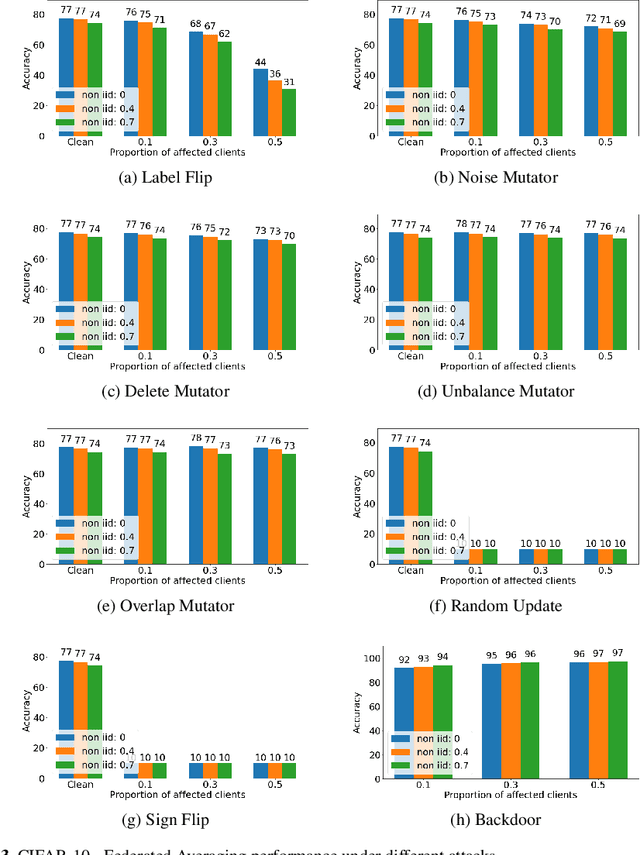
Federated learning (FL) is a widely adopted distributed learning paradigm in practice, which intends to preserve users' data privacy while leveraging the entire dataset of all participants for training. In FL, multiple models are trained independently on the users and aggregated centrally to update a global model in an iterative process. Although this approach is excellent at preserving privacy by design, FL still tends to suffer from quality issues such as attacks or byzantine faults. Some recent attempts have been made to address such quality challenges on the robust aggregation techniques for FL. However, the effectiveness of state-of-the-art (SOTA) robust FL techniques is still unclear and lacks a comprehensive study. Therefore, to better understand the current quality status and challenges of these SOTA FL techniques in the presence of attacks and faults, in this paper, we perform a large-scale empirical study to investigate the SOTA FL's quality from multiple angles of attacks, simulated faults (via mutation operators), and aggregation (defense) methods. In particular, we perform our study on two generic image datasets and one real-world federated medical image dataset. We also systematically investigate the effect of the distribution of attacks/faults over users and the independent and identically distributed (IID) factors, per dataset, on the robustness results. After a large-scale analysis with 496 configurations, we find that most mutators on each individual user have a negligible effect on the final model. Moreover, choosing the most robust FL aggregator depends on the attacks and datasets. Finally, we illustrate that it is possible to achieve a generic solution that works almost as well or even better than any single aggregator on all attacks and configurations with a simple ensemble model of aggregators.
Can We Find Neurons that Cause Unrealistic Images in Deep Generative Networks?
Jan 20, 2022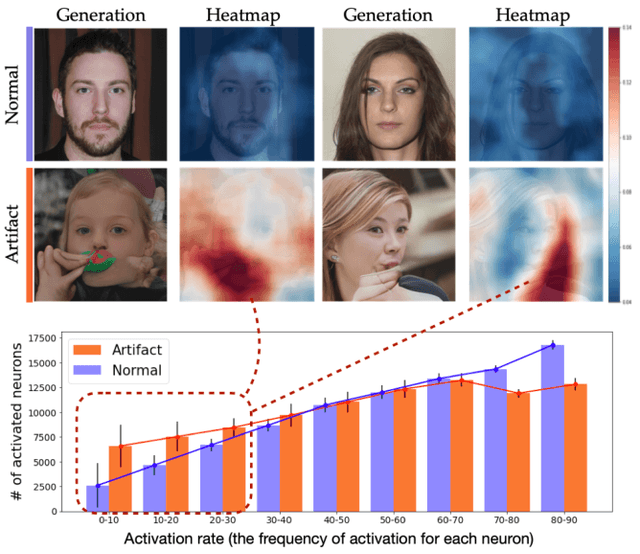
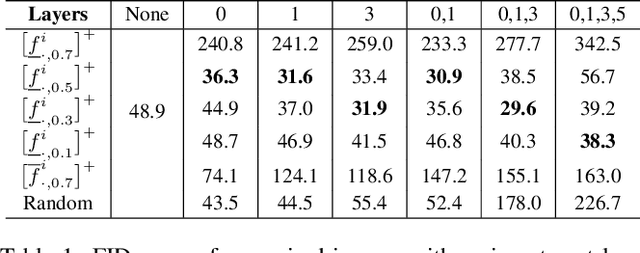
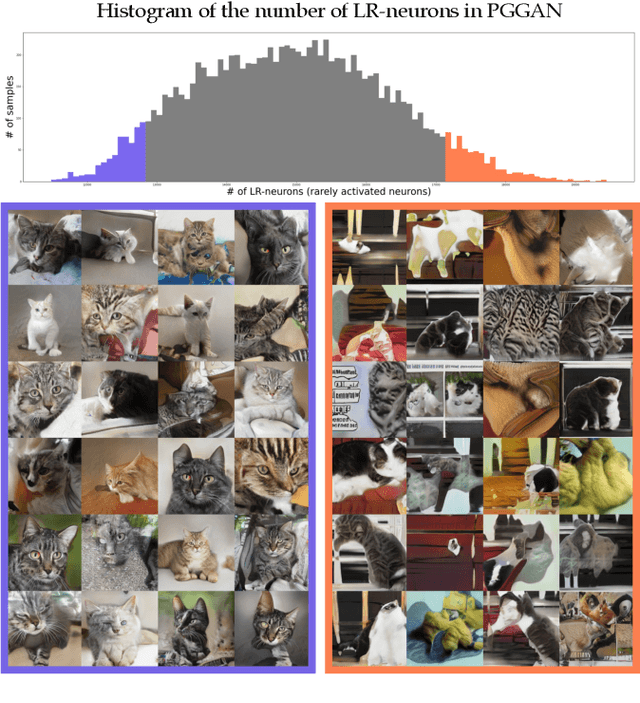
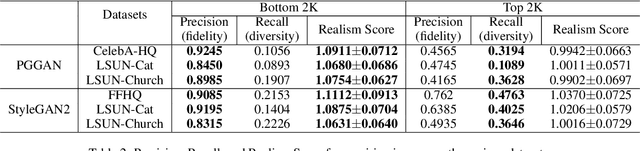
Even though image generation with Generative Adversarial Networks has been showing remarkable ability to generate high-quality images, GANs do not always guarantee photorealistic images will be generated. Sometimes they generate images that have defective or unnatural objects, which are referred to as 'artifacts'. Research to determine why the artifacts emerge and how they can be detected and removed has not been sufficiently carried out. To analyze this, we first hypothesize that rarely activated neurons and frequently activated neurons have different purposes and responsibilities for the progress of generating images. By analyzing the statistics and the roles for those neurons, we empirically show that rarely activated neurons are related to failed results of making diverse objects and lead to artifacts. In addition, we suggest a correction method, called 'sequential ablation', to repair the defective part of the generated images without complex computational cost and manual efforts.
Reconstructing the Noise Manifold for Image Denoising
Feb 11, 2020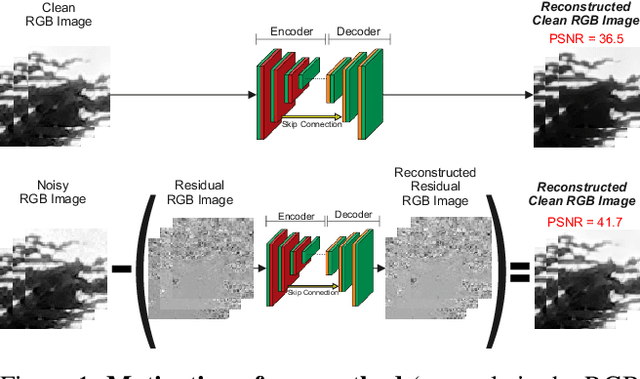
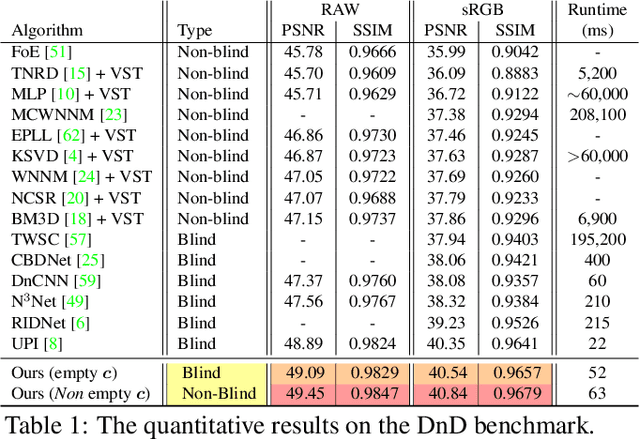
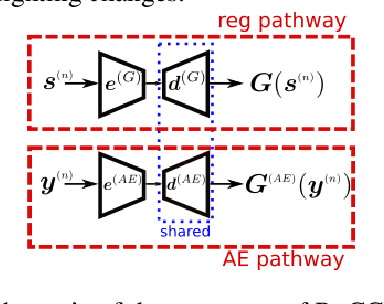
Deep Convolutional Neural Networks (DCNNs) have been successfully used in many low-level vision problems such as image denoising, super-resolution etc. Although the conditional generative adversarial networks (cGAN)[44,16] have led to large improvements in this task, there has been little effort in providing a cGAN with an explicit way of understanding the image noise for object-independent denoising reliable for real-world applications. The task of leveraging structures in the target space (clean image) of the cGAN is very unstable due to the complexity of patterns in natural scenes, so the presence of unnatural artifacts or over-smoothed image areas cannot be avoided. To fill the gap, in this work we introduce the idea of a cGAN which explicitly leverages structure in the image noise space. By using the residual learning in our model, the generator promotes the removal from the noisy image only that information which spans the manifold of the image noise. Based on our experiments, our model significantly outperforms existing state-of-the-art architectures.
DTGAN: Dual Attention Generative Adversarial Networks for Text-to-Image Generation
Nov 05, 2020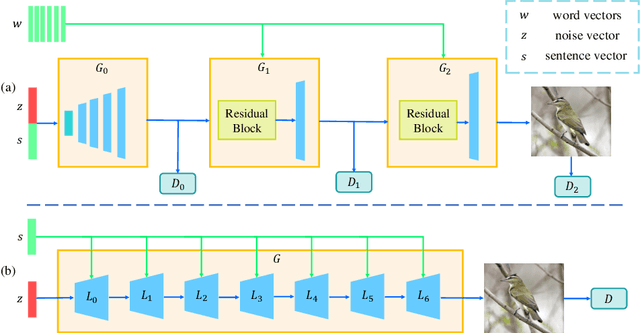
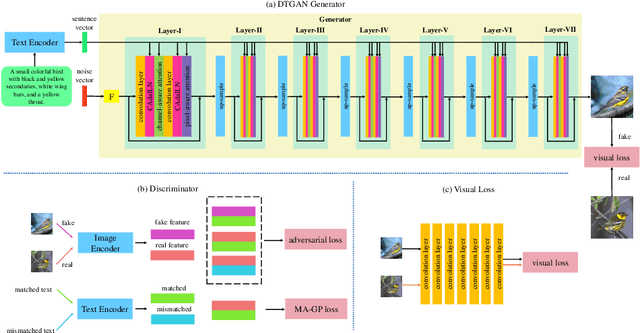
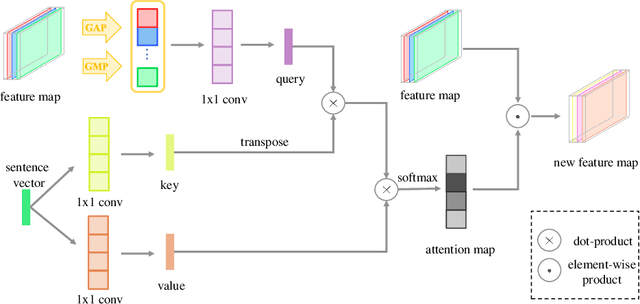
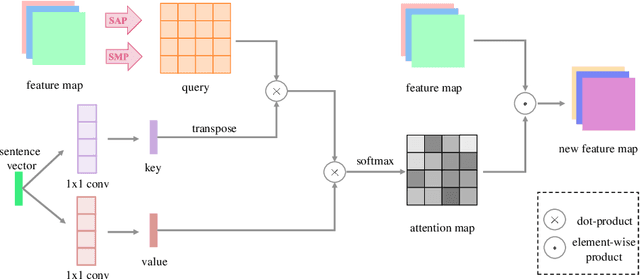
Most existing text-to-image generation methods adopt a multi-stage modular architecture which has three significant problems: (1) Training multiple networks can increase the run time and affect the convergence and stability of the generative model; (2) These approaches ignore the quality of early-stage generator images; (3) Many discriminators need to be trained. To this end, we propose the Dual Attention Generative Adversarial Network (DTGAN) which can synthesize high quality and visually realistic images only employing a single generator/discriminator pair. The proposed model introduces channel-aware and pixel-aware attention modules that can guide the generator to focus on text-relevant channels and pixels based on the global sentence vector and to fine-tune original feature maps using attention weights. Also, Conditional Adaptive Instance-Layer Normalization (CAdaILN) is presented to help our attention modules flexibly control the amount of change in shape and texture by the input natural-language description. Furthermore, a new type of visual loss is utilized to enhance the image quality by ensuring the vivid shape and the perceptually uniform color distributions of generated images. Experimental results on benchmark datasets demonstrate the superiority of our proposed method compared to the state-of-the-art models with a multi-stage framework. Visualization of the attention maps shows that the channel-aware attention module is able to localize the discriminative regions, while the pixel-aware attention module has the ability to capture the globally visual contents for the generation of an image.
Cross-domain Correspondence Learning for Exemplar-based Image Translation
Apr 12, 2020
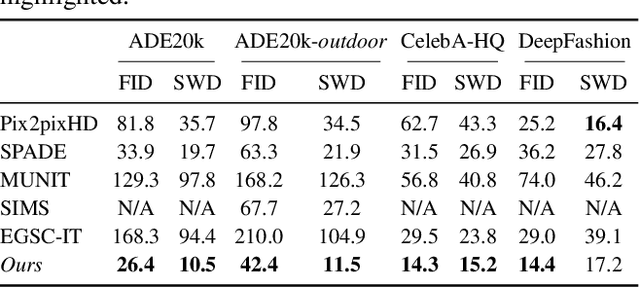
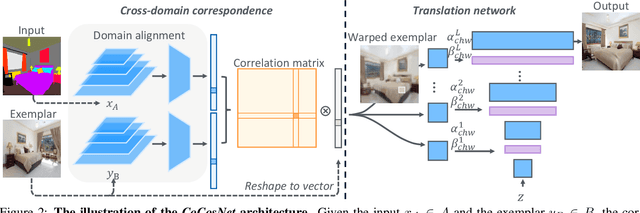
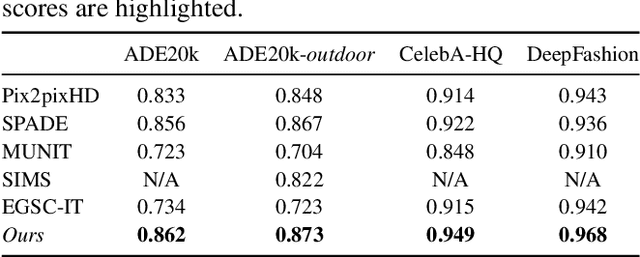
We present a general framework for exemplar-based image translation, which synthesizes a photo-realistic image from the input in a distinct domain (e.g., semantic segmentation mask, or edge map, or pose keypoints), given an exemplar image. The output has the style (e.g., color, texture) in consistency with the semantically corresponding objects in the exemplar. We propose to jointly learn the crossdomain correspondence and the image translation, where both tasks facilitate each other and thus can be learned with weak supervision. The images from distinct domains are first aligned to an intermediate domain where dense correspondence is established. Then, the network synthesizes images based on the appearance of semantically corresponding patches in the exemplar. We demonstrate the effectiveness of our approach in several image translation tasks. Our method is superior to state-of-the-art methods in terms of image quality significantly, with the image style faithful to the exemplar with semantic consistency. Moreover, we show the utility of our method for several applications
* Accepted as a CVPR 2020 oral paper
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021

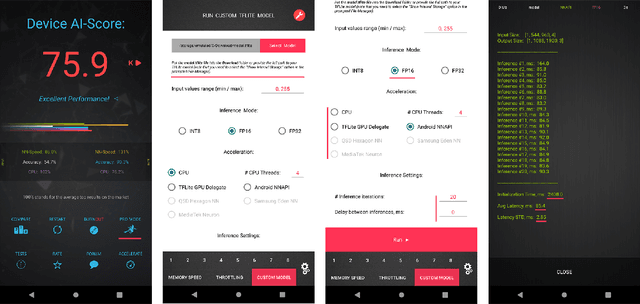

Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
Rank4Class: A Ranking Formulation for Multiclass Classification
Dec 17, 2021
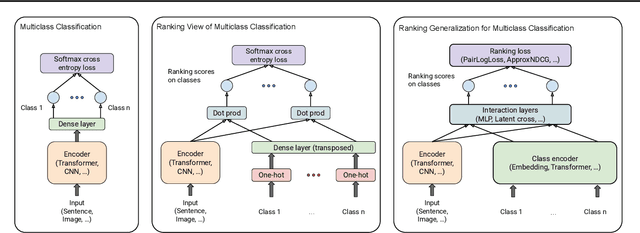
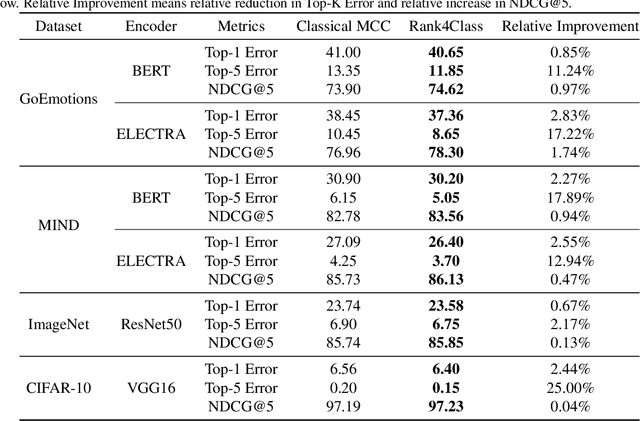
Multiclass classification (MCC) is a fundamental machine learning problem which aims to classify each instance into one of a predefined set of classes. Given an instance, a classification model computes a score for each class, all of which are then used to sort the classes. The performance of a classification model is usually measured by Top-K Accuracy/Error (e.g., K=1 or 5). In this paper, we do not aim to propose new neural representation learning models as most recent works do, but to show that it is easy to boost MCC performance with a novel formulation through the lens of ranking. In particular, by viewing MCC as to rank classes for an instance, we first argue that ranking metrics, such as Normalized Discounted Cumulative Gain (NDCG), can be more informative than existing Top-K metrics. We further demonstrate that the dominant neural MCC architecture can be formulated as a neural ranking framework with a specific set of design choices. Based on such generalization, we show that it is straightforward and intuitive to leverage techniques from the rich information retrieval literature to improve the MCC performance out of the box. Extensive empirical results on both text and image classification tasks with diverse datasets and backbone models (e.g., BERT and ResNet for text and image classification) show the value of our proposed framework.
Unsupervised Landmark Detection Based Spatiotemporal Motion Estimation for 4D Dynamic Medical Images
Oct 12, 2021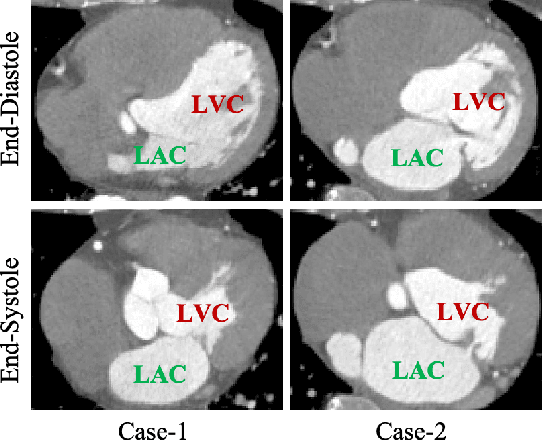

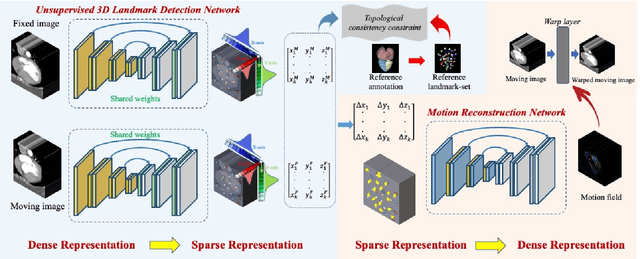
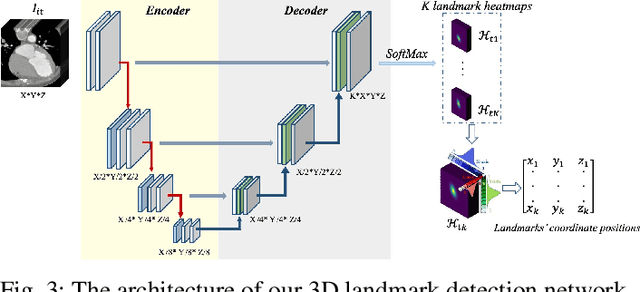
Motion estimation is a fundamental step in dynamic medical image processing for the assessment of target organ anatomy and function. However, existing image-based motion estimation methods, which optimize the motion field by evaluating the local image similarity, are prone to produce implausible estimation, especially in the presence of large motion. In this study, we provide a novel motion estimation framework of Dense-Sparse-Dense (DSD), which comprises two stages. In the first stage, we process the raw dense image to extract sparse landmarks to represent the target organ anatomical topology and discard the redundant information that is unnecessary for motion estimation. For this purpose, we introduce an unsupervised 3D landmark detection network to extract spatially sparse but representative landmarks for the target organ motion estimation. In the second stage, we derive the sparse motion displacement from the extracted sparse landmarks of two images of different time points. Then, we present a motion reconstruction network to construct the motion field by projecting the sparse landmarks displacement back into the dense image domain. Furthermore, we employ the estimated motion field from our two-stage DSD framework as initialization and boost the motion estimation quality in light-weight yet effective iterative optimization. We evaluate our method on two dynamic medical imaging tasks to model cardiac motion and lung respiratory motion, respectively. Our method has produced superior motion estimation accuracy compared to existing comparative methods. Besides, the extensive experimental results demonstrate that our solution can extract well representative anatomical landmarks without any requirement of manual annotation. Our code is publicly available online.