 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probability Distribution on Rooted Trees
Jan 24, 2022
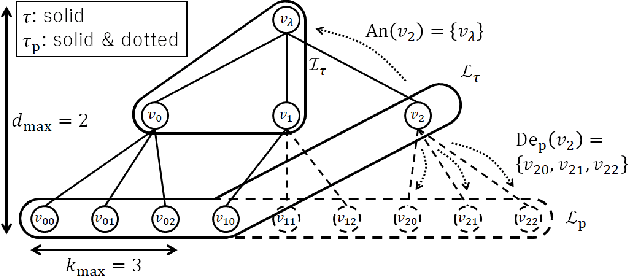
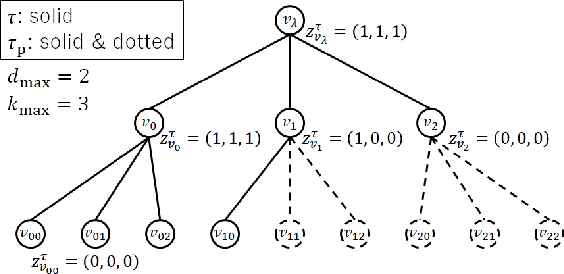
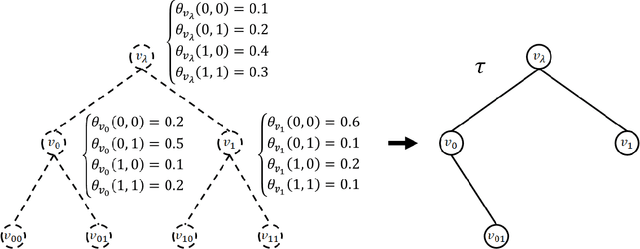
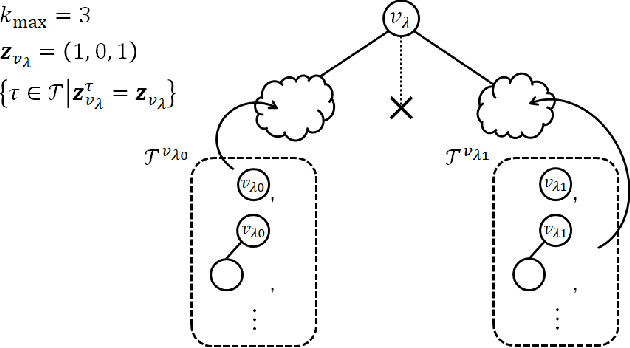
The hierarchical and recursive expressive capability of rooted trees is applicable to represent statistical models in various areas, such as data compression, image processing, and machine learning. On the other hand, such hierarchical expressive capability causes a problem in tree selection to avoid overfitting. One unified approach to solve this is a Bayesian approach, on which the rooted tree is regarded as a random variable and a direct loss function can be assumed on the selected model or the predicted value for a new data point. However, all the previous studies on this approach are based on the probability distribution on full trees, to the best of our knowledge. In this paper, we propose a generalized probability distribution for any rooted trees in which only the maximum number of child nodes and the maximum depth are fixed. Furthermore, we derive recursive methods to evaluate the characteristics of the probability distribution without any approximations.
Learning with Less Labels in Digital Pathology via Scribble Supervision from Natural Images
Jan 20, 2022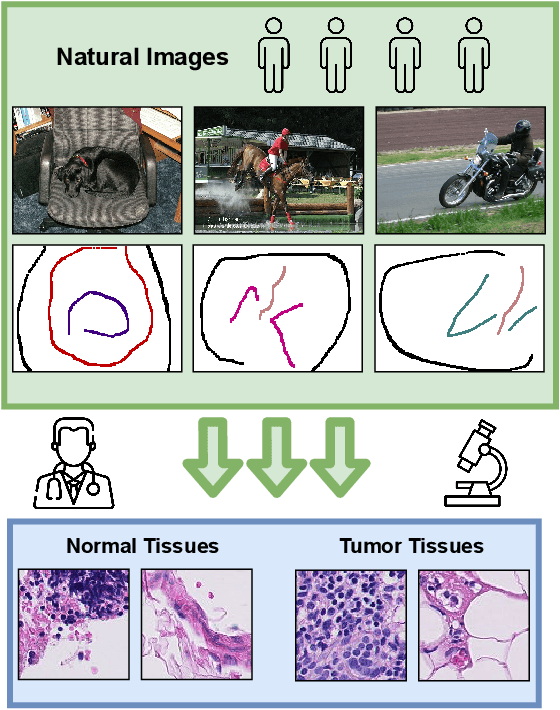
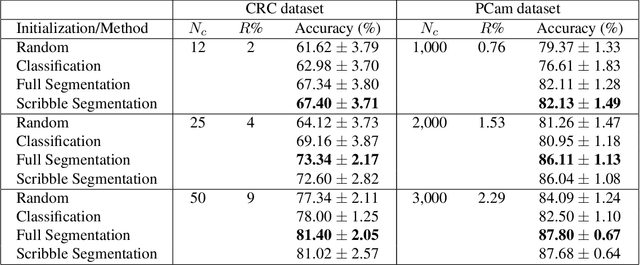
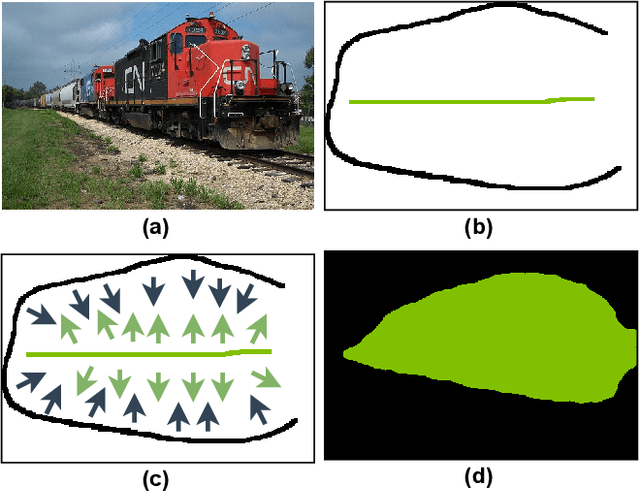

A critical challenge of training deep learning models in the Digital Pathology (DP) domain is the high annotation cost by medical experts. One way to tackle this issue is via transfer learning from the natural image domain (NI), where the annotation cost is considerably cheaper. Cross-domain transfer learning from NI to DP is shown to be successful via class labels. One potential weakness of relying on class labels is the lack of spatial information, which can be obtained from spatial labels such as full pixel-wise segmentation labels and scribble labels. We demonstrate that scribble labels from NI domain can boost the performance of DP models on two cancer classification datasets (Patch Camelyon Breast Cancer and Colorectal Cancer dataset). Furthermore, we show that models trained with scribble labels yield the same performance boost as full pixel-wise segmentation labels despite being significantly easier and faster to collect.
Learning Texture Transformer Network for Image Super-Resolution
Jun 22, 2020
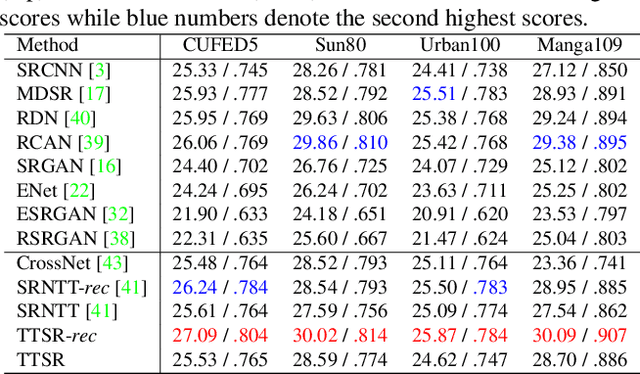
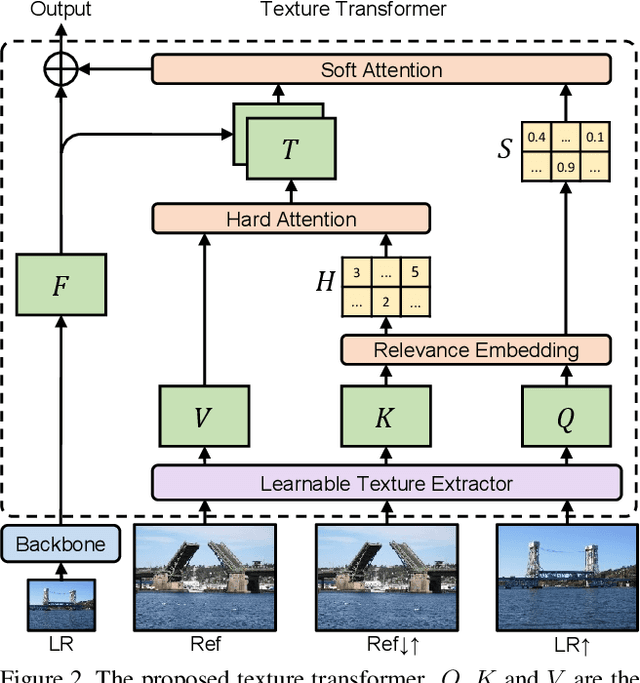
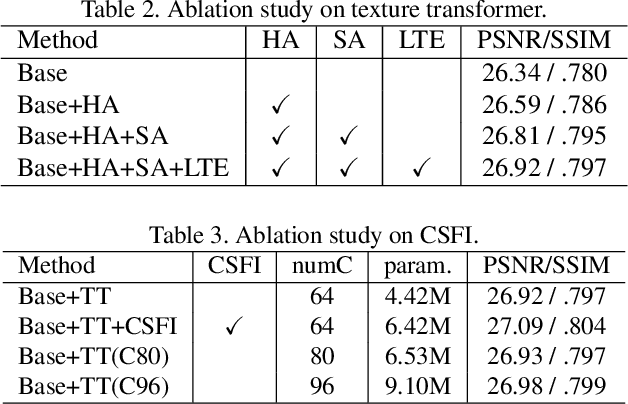
We study on image super-resolution (SR), which aims to recover realistic textures from a low-resolution (LR) image. Recent progress has been made by taking high-resolution images as references (Ref), so that relevant textures can be transferred to LR images. However, existing SR approaches neglect to use attention mechanisms to transfer high-resolution (HR) textures from Ref images, which limits these approaches in challenging cases. In this paper, we propose a novel Texture Transformer Network for Image Super-Resolution (TTSR), in which the LR and Ref images are formulated as queries and keys in a transformer, respectively. TTSR consists of four closely-related modules optimized for image generation tasks, including a learnable texture extractor by DNN, a relevance embedding module, a hard-attention module for texture transfer, and a soft-attention module for texture synthesis. Such a design encourages joint feature learning across LR and Ref images, in which deep feature correspondences can be discovered by attention, and thus accurate texture features can be transferred. The proposed texture transformer can be further stacked in a cross-scale way, which enables texture recovery from different levels (e.g., from 1x to 4x magnification). Extensive experiments show that TTSR achieves significant improvements over state-of-the-art approaches on both quantitative and qualitative evaluations.
AttentionGAN: Unpaired Image-to-Image Translation using Attention-Guided Generative Adversarial Networks
Dec 28, 2019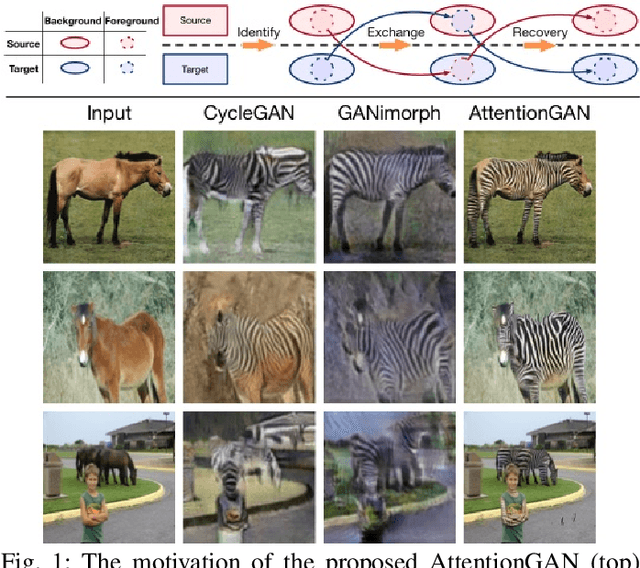



State-of-the-art methods in the unpaired image-to-image translation are capable of learning a mapping from a source domain to a target domain with unpaired image data. Though the existing methods have achieved promising results, they still produce unsatisfied artifacts, being able to convert low-level information while limited in transforming high-level semantics of input images. One possible reason is that generators do not have the ability to perceive the most discriminative semantic parts between the source and target domains, thus making the generated images low quality. In this paper, we propose a new Attention-Guided Generative Adversarial Networks (AttentionGAN) for the unpaired image-to-image translation task. AttentionGAN can identify the most discriminative semantic objects and minimize changes of unwanted parts for semantic manipulation problems without using extra data and models. The attention-guided generators in AttentionGAN are able to produce attention masks via a built-in attention mechanism, and then fuse the generation output with the attention masks to obtain high-quality target images. Accordingly, we also design a novel attention-guided discriminator which only considers attended regions. Extensive experiments are conducted on several generative tasks, demonstrating that the proposed model is effective to generate sharper and more realistic images compared with existing competitive models. The source code for the proposed AttentionGAN is available at https://github.com/Ha0Tang/AttentionGAN.
Single-stage Rotate Object Detector via Two Points with Solar Corona Heatmap
Feb 14, 2022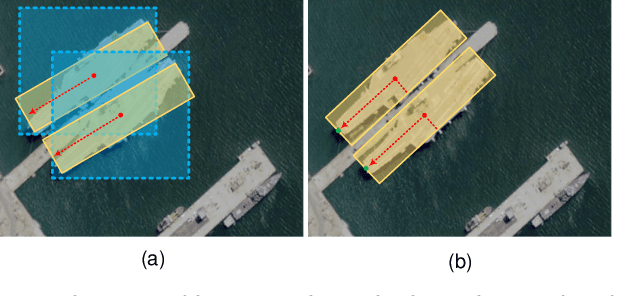

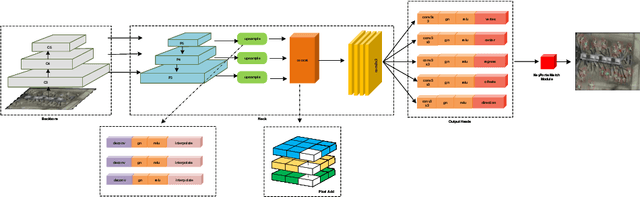
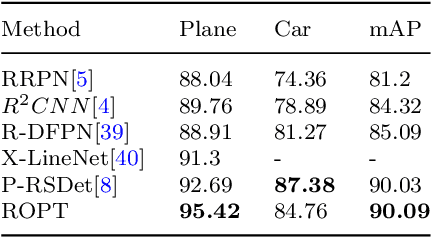
Oriented object detection is a crucial task in computer vision. Current top-down oriented detection methods usually directly detect entire objects, and not only neglecting the authentic direction of targets, but also do not fully utilise the key semantic information, which causes a decrease in detection accuracy. In this study, we developed a single-stage rotating object detector via two points with a solar corona heatmap (ROTP) to detect oriented objects. The ROTP predicts parts of the object and then aggregates them to form a whole image. Herein, we meticulously represent an object in a random direction using the vertex, centre point with width, and height. Specifically, we regress two heatmaps that characterise the relative location of each object, which enhances the accuracy of locating objects and avoids deviations caused by angle predictions. To rectify the central misjudgement of the Gaussian heatmap on high-aspect ratio targets, we designed a solar corona heatmap generation method to improve the perception difference between the central and non-central samples. Additionally, we predicted the vertex relative to the direction of the centre point to connect two key points that belong to the same goal. Experiments on the HRSC 2016, UCASAOD, and DOTA datasets show that our ROTP achieves the most advanced performance with a simpler modelling and less manual intervention.
Progressive observation of Covid-19 vaccination effects on skin-cellular structures by use of Intelligent Laser Speckle Classification (ILSC)
Oct 31, 2021
We have made a progressive observation of Covid-19 Astra Zeneca Vaccination effect on Skin cellular network and properties by use of well established Intelligent Laser Speckle Classification (ILSC) image based technique and managed to distinguish between three different subjects groups via their laser speckle skin image samplings such as early-vaccinated, late-vaccinated and non-vaccinated individuals. The results have proven that the ILSC technique in association with the optimised Bayesian network is capable of classifying skin changes of vaccinated and non-vaccinated individuals and also of detecting progressive development made on skin cellular properties for a month period.
An Optimal Control Framework for Joint-channel Parallel MRI Reconstruction without Coil Sensitivities
Sep 20, 2021
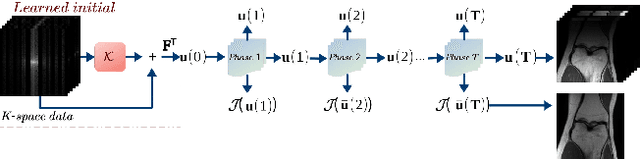
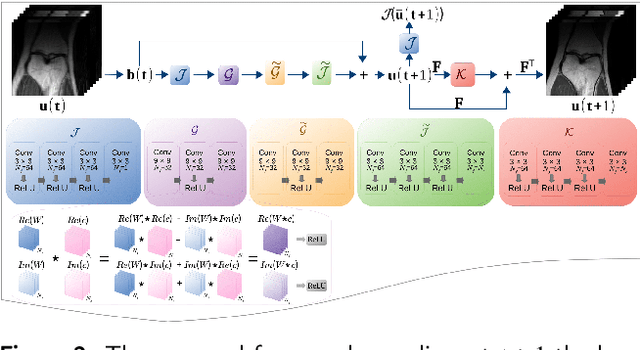
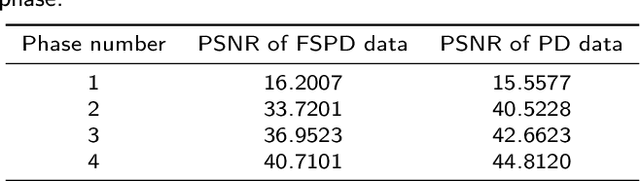
Goal: This work aims at developing a novel calibration-free fast parallel MRI (pMRI) reconstruction method incorporate with discrete-time optimal control framework. The reconstruction model is designed to learn a regularization that combines channels and extracts features by leveraging the information sharing among channels of multi-coil images. We propose to recover both magnitude and phase information by taking advantage of structured multiplayer convolutional networks in image and Fourier spaces. Methods: We develop a novel variational model with a learnable objective function that integrates an adaptive multi-coil image combination operator and effective image regularization in the image and Fourier spaces. We cast the reconstruction network as a structured discrete-time optimal control system, resulting in an optimal control formulation of parameter training where the parameters of the objective function play the role of control variables. We demonstrate that the Lagrangian method for solving the control problem is equivalent to back-propagation, ensuring the local convergence of the training algorithm. Results: We conduct a large number of numerical experiments of the proposed method with comparisons to several state-of-the-art pMRI reconstruction networks on real pMRI datasets. The numerical results demonstrate the promising performance of the proposed method evidently. Conclusion: The proposed method provides a general deep network design and training framework for efficient joint-channel pMRI reconstruction. Significance: By learning multi-coil image combination operator and performing regularizations in both image domain and k-space domain, the proposed method achieves a highly efficient image reconstruction network for pMRI.
Nuclei Grading of Clear Cell Renal Cell Carcinoma in Histopathological Image by Composite High-Resolution Network
Jun 20, 2021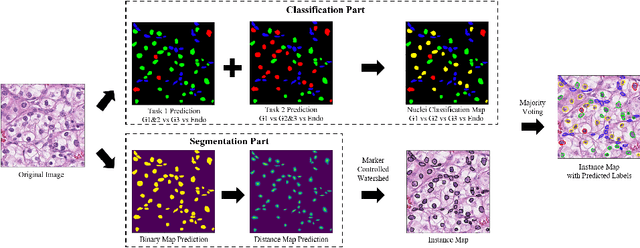

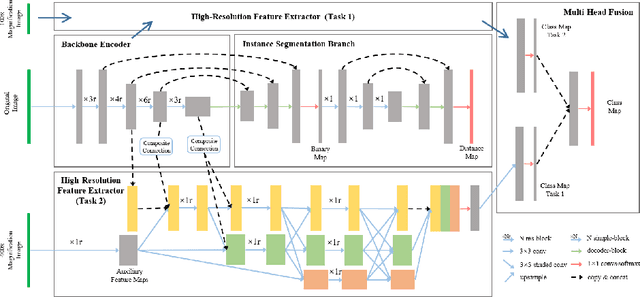

The grade of clear cell renal cell carcinoma (ccRCC) is a critical prognostic factor, making ccRCC nuclei grading a crucial task in RCC pathology analysis. Computer-aided nuclei grading aims to improve pathologists' work efficiency while reducing their misdiagnosis rate by automatically identifying the grades of tumor nuclei within histopathological images. Such a task requires precisely segment and accurately classify the nuclei. However, most of the existing nuclei segmentation and classification methods can not handle the inter-class similarity property of nuclei grading, thus can not be directly applied to the ccRCC grading task. In this paper, we propose a Composite High-Resolution Network for ccRCC nuclei grading. Specifically, we propose a segmentation network called W-Net that can separate the clustered nuclei. Then, we recast the fine-grained classification of nuclei to two cross-category classification tasks, based on two high-resolution feature extractors (HRFEs) which are proposed for learning these two tasks. The two HRFEs share the same backbone encoder with W-Net by a composite connection so that meaningful features for the segmentation task can be inherited for the classification task. Last, a head-fusion block is applied to generate the predicted label of each nucleus. Furthermore, we introduce a dataset for ccRCC nuclei grading, containing 1000 image patches with 70945 annotated nuclei. We demonstrate that our proposed method achieves state-of-the-art performance compared to existing methods on this large ccRCC grading dataset.
STALP: Style Transfer with Auxiliary Limited Pairing
Oct 20, 2021We present an approach to example-based stylization of images that uses a single pair of a source image and its stylized counterpart. We demonstrate how to train an image translation network that can perform real-time semantically meaningful style transfer to a set of target images with similar content as the source image. A key added value of our approach is that it considers also consistency of target images during training. Although those have no stylized counterparts, we constrain the translation to keep the statistics of neural responses compatible with those extracted from the stylized source. In contrast to concurrent techniques that use a similar input, our approach better preserves important visual characteristics of the source style and can deliver temporally stable results without the need to explicitly handle temporal consistency. We demonstrate its practical utility on various applications including video stylization, style transfer to panoramas, faces, and 3D models.
VPFNet: Improving 3D Object Detection with Virtual Point based LiDAR and Stereo Data Fusion
Dec 01, 2021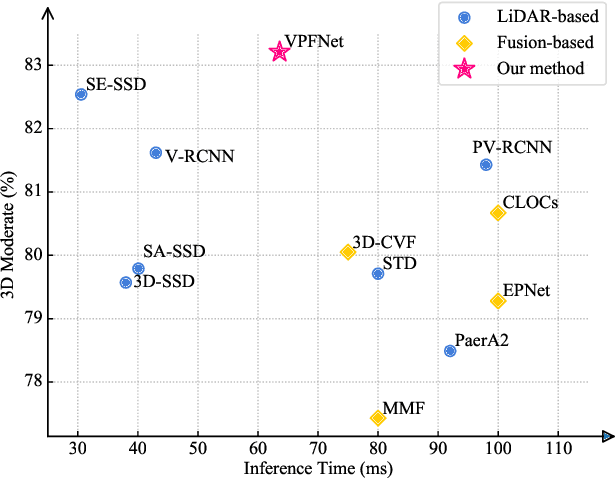

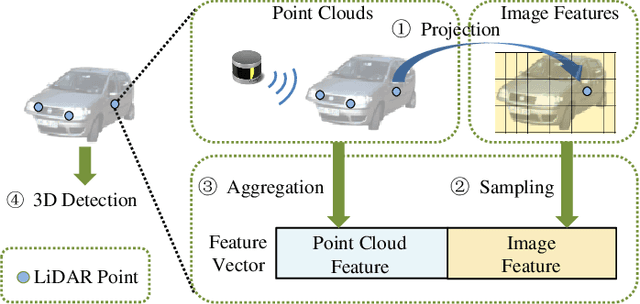
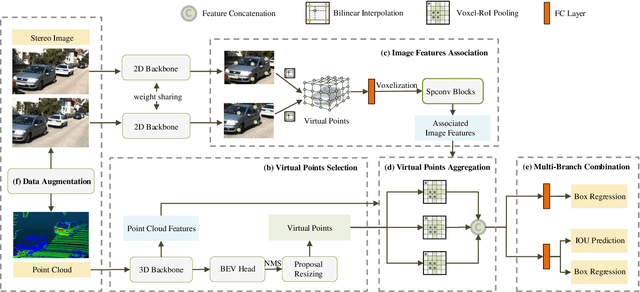
It has been well recognized that fusing the complementary information from depth-aware LiDAR point clouds and semantic-rich stereo images would benefit 3D object detection. Nevertheless, it is not trivial to explore the inherently unnatural interaction between sparse 3D points and dense 2D pixels. To ease this difficulty, the recent proposals generally project the 3D points onto the 2D image plane to sample the image data and then aggregate the data at the points. However, this approach often suffers from the mismatch between the resolution of point clouds and RGB images, leading to sub-optimal performance. Specifically, taking the sparse points as the multi-modal data aggregation locations causes severe information loss for high-resolution images, which in turn undermines the effectiveness of multi-sensor fusion. In this paper, we present VPFNet -- a new architecture that cleverly aligns and aggregates the point cloud and image data at the `virtual' points. Particularly, with their density lying between that of the 3D points and 2D pixels, the virtual points can nicely bridge the resolution gap between the two sensors, and thus preserve more information for processing. Moreover, we also investigate the data augmentation techniques that can be applied to both point clouds and RGB images, as the data augmentation has made non-negligible contribution towards 3D object detectors to date. We have conducted extensive experiments on KITTI dataset, and have observed good performance compared to the state-of-the-art methods. Remarkably, our VPFNet achieves 83.21\% moderate 3D AP and 91.86\% moderate BEV AP on the KITTI test set, ranking the 1st since May 21th, 2021. The network design also takes computation efficiency into consideration -- we can achieve a FPS of 15 on a single NVIDIA RTX 2080Ti GPU. The code will be made available for reproduction and further investigation.