 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InVA: Integrative Variational Autoencoder for Harmonization of Multi-modal Neuroimaging Data
Feb 05, 2024
There is a significant interest in exploring non-linear associations among multiple images derived from diverse imaging modalities. While there is a growing literature on image-on-image regression to delineate predictive inference of an image based on multiple images, existing approaches have limitations in efficiently borrowing information between multiple imaging modalities in the prediction of an image. Building on the literature of Variational Auto Encoders (VAEs), this article proposes a novel approach, referred to as Integrative Variational Autoencoder (\texttt{InVA}) method, which borrows information from multiple images obtained from different sources to draw predictive inference of an image. The proposed approach captures complex non-linear association between the outcome image and input images, while allowing rapid computation. Numerical results demonstrate substantial advantages of \texttt{InVA} over VAEs, which typically do not allow borrowing information between input images. The proposed framework offers highly accurate predictive inferences for costly positron emission topography (PET) from multiple measures of cortical structure in human brain scans readily available from magnetic resonance imaging (MRI).
CAT-SAM: Conditional Tuning Network for Few-Shot Adaptation of Segmentation Anything Model
Feb 06, 2024The recent Segment Anything Model (SAM) has demonstrated remarkable zero-shot capability and flexible geometric prompting in general image segmentation. However, SAM often struggles when handling various unconventional images, such as aerial, medical, and non-RGB images. This paper presents CAT-SAM, a ConditionAl Tuning network that adapts SAM toward various unconventional target tasks with just few-shot target samples. CAT-SAM freezes the entire SAM and adapts its mask decoder and image encoder simultaneously with a small number of learnable parameters. The core design is a prompt bridge structure that enables decoder-conditioned joint tuning of the heavyweight image encoder and the lightweight mask decoder. The bridging maps the prompt token of the mask decoder to the image encoder, fostering synergic adaptation of the encoder and the decoder with mutual benefits. We develop two representative tuning strategies for the image encoder which leads to two CAT-SAM variants: one injecting learnable prompt tokens in the input space and the other inserting lightweight adapter networks. Extensive experiments over 11 unconventional tasks show that both CAT-SAM variants achieve superior target segmentation performance consistently even under the very challenging one-shot adaptation setup. Project page: \url{https://xiaoaoran.github.io/projects/CAT-SAM}
Inference Stage Denoising for Undersampled MRI Reconstruction
Feb 12, 2024Reconstruction of magnetic resonance imaging (MRI) data has been positively affected by deep learning. A key challenge remains: to improve generalisation to distribution shifts between the training and testing data. Most approaches aim to address this via inductive design or data augmentation. However, they can be affected by misleading data, e.g. random noise, and cases where the inference stage data do not match assumptions in the modelled shifts. In this work, by employing a conditional hyperparameter network, we eliminate the need of augmentation, yet maintain robust performance under various levels of Gaussian noise. We demonstrate that our model withstands various input noise levels while producing high-definition reconstructions during the test stage. Moreover, we present a hyperparameter sampling strategy that accelerates the convergence of training. Our proposed method achieves the highest accuracy and image quality in all settings compared to baseline methods.
Immediate generalisation in humans but a generalisation lag in deep neural networks$\unicode{x2014}$evidence for representational divergence?
Feb 14, 2024Recent research has seen many behavioral comparisons between humans and deep neural networks (DNNs) in the domain of image classification. Often, comparison studies focus on the end-result of the learning process by measuring and comparing the similarities in the representations of object categories once they have been formed. However, the process of how these representations emerge$\unicode{x2014}$that is, the behavioral changes and intermediate stages observed during the acquisition$\unicode{x2014}$is less often directly and empirically compared. Here we report a detailed investigation of how transferable representations are acquired in human observers and various classic and state-of-the-art DNNs. We develop a constrained supervised learning environment in which we align learning-relevant parameters such as starting point, input modality, available input data and the feedback provided. Across the whole learning process we evaluate and compare how well learned representations can be generalized to previously unseen test data. Our findings indicate that in terms of absolute classification performance DNNs demonstrate a level of data efficiency comparable to$\unicode{x2014}$and sometimes even exceeding that$\unicode{x2014}$of human learners, challenging some prevailing assumptions in the field. However, comparisons across the entire learning process reveal significant representational differences: while DNNs' learning is characterized by a pronounced generalisation lag, humans appear to immediately acquire generalizable representations without a preliminary phase of learning training set-specific information that is only later transferred to novel data.
Scalable Diffusion Models with State Space Backbone
Feb 08, 2024This paper presents a new exploration into a category of diffusion models built upon state space architecture. We endeavor to train diffusion models for image data, wherein the traditional U-Net backbone is supplanted by a state space backbone, functioning on raw patches or latent space. Given its notable efficacy in accommodating long-range dependencies, Diffusion State Space Models (DiS) are distinguished by treating all inputs including time, condition, and noisy image patches as tokens. Our assessment of DiS encompasses both unconditional and class-conditional image generation scenarios, revealing that DiS exhibits comparable, if not superior, performance to CNN-based or Transformer-based U-Net architectures of commensurate size. Furthermore, we analyze the scalability of DiS, gauged by the forward pass complexity quantified in Gflops. DiS models with higher Gflops, achieved through augmentation of depth/width or augmentation of input tokens, consistently demonstrate lower FID. In addition to demonstrating commendable scalability characteristics, DiS-H/2 models in latent space achieve performance levels akin to prior diffusion models on class-conditional ImageNet benchmarks at the resolution of 256$\times$256 and 512$\times$512, while significantly reducing the computational burden. The code and models are available at: https://github.com/feizc/DiS.
CBVS: A Large-Scale Chinese Image-Text Benchmark for Real-World Short Video Search Scenarios
Jan 25, 2024Vision-Language Models pre-trained on large-scale image-text datasets have shown superior performance in downstream tasks such as image retrieval. Most of the images for pre-training are presented in the form of open domain common-sense visual elements. Differently, video covers in short video search scenarios are presented as user-originated contents that provide important visual summaries of videos. In addition, a portion of the video covers come with manually designed cover texts that provide semantic complements. In order to fill in the gaps in short video cover data, we establish the first large-scale cover-text benchmark for Chinese short video search scenarios. Specifically, we release two large-scale datasets CBVS-5M/10M to provide short video covers, and the manual fine-labeling dataset CBVS-20K to provide real user queries, which serves as an image-text benchmark test in the Chinese short video search field. To integrate the semantics of cover text in the case of modality missing, we propose UniCLIP where cover texts play a guiding role during training, however are not relied upon by inference. Extensive evaluation on CBVS-20K demonstrates the excellent performance of our proposal. UniCLIP has been deployed to Tencent's online video search systems with hundreds of millions of visits and achieved significant gains. The dataset and code are available at https://github.com/QQBrowserVideoSearch/CBVS-UniCLIP.
Another Way to the Top: Exploit Contextual Clustering in Learned Image Coding
Jan 21, 2024While convolution and self-attention are extensively used in learned image compression (LIC) for transform coding, this paper proposes an alternative called Contextual Clustering based LIC (CLIC) which primarily relies on clustering operations and local attention for correlation characterization and compact representation of an image. As seen, CLIC expands the receptive field into the entire image for intra-cluster feature aggregation. Afterward, features are reordered to their original spatial positions to pass through the local attention units for inter-cluster embedding. Additionally, we introduce the Guided Post-Quantization Filtering (GuidedPQF) into CLIC, effectively mitigating the propagation and accumulation of quantization errors at the initial decoding stage. Extensive experiments demonstrate the superior performance of CLIC over state-of-the-art works: when optimized using MSE, it outperforms VVC by about 10% BD-Rate in three widely-used benchmark datasets; when optimized using MS-SSIM, it saves more than 50% BD-Rate over VVC. Our CLIC offers a new way to generate compact representations for image compression, which also provides a novel direction along the line of LIC development.
Benchmarking the Fairness of Image Upsampling Methods
Jan 24, 2024Recent years have witnessed a rapid development of deep generative models for creating synthetic media, such as images and videos. While the practical applications of these models in everyday tasks are enticing, it is crucial to assess the inherent risks regarding their fairness. In this work, we introduce a comprehensive framework for benchmarking the performance and fairness of conditional generative models. We develop a set of metrics$\unicode{x2013}$inspired by their supervised fairness counterparts$\unicode{x2013}$to evaluate the models on their fairness and diversity. Focusing on the specific application of image upsampling, we create a benchmark covering a wide variety of modern upsampling methods. As part of the benchmark, we introduce UnfairFace, a subset of FairFace that replicates the racial distribution of common large-scale face datasets. Our empirical study highlights the importance of using an unbiased training set and reveals variations in how the algorithms respond to dataset imbalances. Alarmingly, we find that none of the considered methods produces statistically fair and diverse results.
Learning to Produce Semi-dense Correspondences for Visual Localization
Feb 13, 2024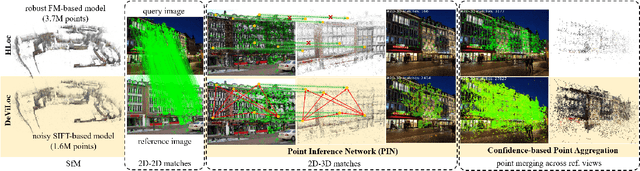
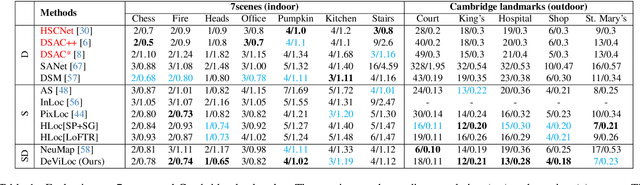
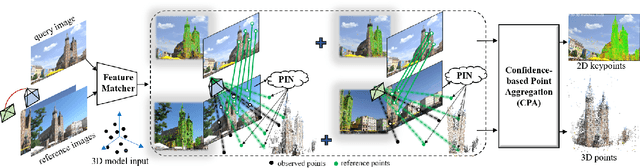
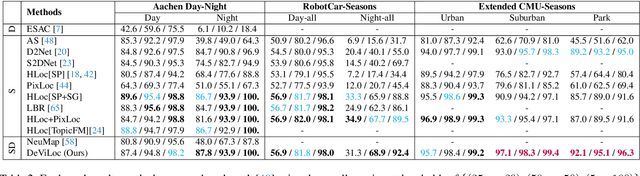
This study addresses the challenge of performing visual localization in demanding conditions such as night-time scenarios, adverse weather, and seasonal changes. While many prior studies have focused on improving image-matching performance to facilitate reliable dense keypoint matching between images, existing methods often heavily rely on predefined feature points on a reconstructed 3D model. Consequently, they tend to overlook unobserved keypoints during the matching process. Therefore, dense keypoint matches are not fully exploited, leading to a notable reduction in accuracy, particularly in noisy scenes. To tackle this issue, we propose a novel localization method that extracts reliable semi-dense 2D-3D matching points based on dense keypoint matches. This approach involves regressing semi-dense 2D keypoints into 3D scene coordinates using a point inference network. The network utilizes both geometric and visual cues to effectively infer 3D coordinates for unobserved keypoints from the observed ones. The abundance of matching information significantly enhances the accuracy of camera pose estimation, even in scenarios involving noisy or sparse 3D models. Comprehensive evaluations demonstrate that the proposed method outperforms other methods in challenging scenes and achieves competitive results in large-scale visual localization benchmarks. The code will be available.
Low-light Stereo Image Enhancement and De-noising in the Low-frequency Information Enhanced Image Space
Jan 15, 2024Unlike single image task, stereo image enhancement can use another view information, and its key stage is how to perform cross-view feature interaction to extract useful information from another view. However, complex noise in low-light image and its impact on subsequent feature encoding and interaction are ignored by the existing methods. In this paper, a method is proposed to perform enhancement and de-noising simultaneously. First, to reduce unwanted noise interference, a low-frequency information enhanced module (IEM) is proposed to suppress noise and produce a new image space. Additionally, a cross-channel and spatial context information mining module (CSM) is proposed to encode long-range spatial dependencies and to enhance inter-channel feature interaction. Relying on CSM, an encoder-decoder structure is constructed, incorporating cross-view and cross-scale feature interactions to perform enhancement in the new image space. Finally, the network is trained with the constraints of both spatial and frequency domain losses. Extensive experiments on both synthesized and real datasets show that our method obtains better detail recovery and noise removal compared with state-of-the-art methods. In addition, a real stereo image enhancement dataset is captured with stereo camera ZED2. The code and dataset are publicly available at: https://www.github.com/noportraits/LFENet.